تحلیل متون ادبی با استفاده از روشهای محاسباتی در سالهای اخیر به یکی از شاخههای جذاب پژوهشی در حوزه پردازش زبان طبیعی و علوم شبکه تبدیل شده است. در این پژوهش تلاش شده تا ساختار معنایی و واژگانی غزلیات حافظ شیرازی با بهرهگیری از مدلهای شبکههای پیچیده مورد بررسی قرار گیرد. در این چارچوب، واژگان به عنوان گرههای شبکه و همرخدادی آنها در سطح بیتهای شعر به عنوان یالهای ارتباطی مدلسازی شدهاند.
برای انجام این پژوهش ابتدا مجموعهای از غزلیات حافظ از پایگاه داده گنجور استخراج گردید. پس از پیشپردازش زبانی شامل نرمالسازی، توکنسازی و حذف واژگان دستوری شبکه همرخدادی واژگان ساخته شد. سپس شاخصهای مختلف تحلیل شبکه از جمله درجه مرکزیّت، بینابینی یالها، چگالی شبکه، ضریب خوشهبندی و توزیع درجه مورد محاسبه قرار گرفتند. بعلاوه با استفاده از الگوریتم تشخیص اجتماع، خوشههای معنایی غالب در شعر حافظ استخراج گردید.
نتایج نشان میدهد شبکه واژگان حافظ دارای ساختاری ناهمگن و نزدیک به شبکههای مقیاسآزاد است و برخی واژگان نقش هستههای معنایی را ایفا میکنند. همچنین بررسی همبستگی واژگان پرتکرار نشان داد که مفاهیم کلیدی شعر حافظ الزاما به صورت همزمان در یک بیت ظاهر نمیشوند و ساختار معنایی شعر حافظ از نوعی توزیع مفهومی گسترده پیروی میکند.
ادبیات فارسی یکی از غنیترین منابع فرهنگی و زبانی در جهان به شمار میرود و آثار شاعرانی مانند حافظ، سعدی، مولوی و صائب تبریزی بخش مهمی از هویت ادبی و فکری جامعه ایرانی را شکل دادهاند. در میان این شاعران، حافظ شیرازی جایگاه ویژهای دارد بهگونهای که شعر او نه تنها از نظر زیباییشناسی بلکه از نظر لایههای پیچیده مفهومی و نمادین نیز مورد توجه پژوهشگران قرار گرفته است.
در سالهای گذشته تحلیل آثار ادبی عمدتا بر پایه روشهای سنتی و تفسیری انجام میشد. این روشها گرچه بسیار ارزشمند هستند اما به دلیل ماهیت کیفی خود معمولا امکان تحلیل ساختارهای کلان و الگوهای پنهان در مقیاس بزرگ را فراهم نمیکنند. با پیشرفت علوم داده و پردازش زبان طبیعی، امکان بررسی متون ادبی از دیدگاههای کمی و ساختاری فراهم شده است.
یکی از رویکردهای نوظهور در تحلیل متون، استفاده از نظریه شبکههای پیچیده است. در این رویکرد، متن به عنوان مجموعهای از عناصر مرتبط در نظر گرفته میشود که میتوان آن را به صورت یک گراف مدلسازی کرد. در چنین مدلی، واژگان به عنوان گرهها و ارتباط بین آنها به عنوان یالها تعریف میشوند. پژوهشهای مختلف نشان دادهاند که شبکههای زبانی دارای ویژگیهایی مشابه شبکههای طبیعی و اجتماعی هستند و معمولا ساختارهایی مانند توزیع درجه نامتوازن و خوشهبندی معنایی را نشان میدهند [1].
در حوزه ادبیات فارسی نیز تلاشهایی برای تحلیل شبکهای متون انجام شده است اما هنوز بسیاری از آثار کلاسیک به صورت سیستماتیک مورد بررسی قرار نگرفتهاند. غزلیات حافظ به دلیل تنوع مفهومی و پیچیدگی ساختار زبانی، نمونهای مناسب برای چنین تحلیلی محسوب میشود.
هدف اصلی این پژوهش بررسی ساختار همرخدادی واژگان در غزلیات حافظ و تحلیل ویژگیهای شبکه حاصل از آن است. به طور خاص، در این تحقیق سعی شده است به پرسشهای زیر پاسخ داده شود:
آیا شبکه واژگان حافظ دارای ساختار مقیاسآزاد است؟
کدام واژگان نقش هستههای مفهومی را ایفا میکنند؟
آیا واژگان مهم معمولاً در یک بیت با یکدیگر ظاهر میشوند؟
خوشههای معنایی غالب در شعر حافظ کدامند؟
برای پاسخ به این پرسشها از ترکیبی از روشهای پردازش زبان طبیعی و تحلیل شبکه استفاده شده است.
در دو دهه اخیر، پیشرفت چشمگیر در حوزههای پردازش زبان طبیعی، علم داده و نظریه شبکههای پیچیده باعث شده است تحلیل متون از چارچوبهای سنتی فاصله گرفته و وارد فازهای محاسباتی و دادهمحور شود. یکی از شاخههای مهم این حوزه، تحلیل ساختار شبکهای زبان است که زبان را به عنوان سیستمی از عناصر مرتبط در نظر میگیرد.
تحلیل شبکهای زبان بر این فرض استوار است که واژگان و مفاهیم در یک متن به صورت مستقل عمل نمیکنند، بلکه در قالب مجموعهای از روابط پیچیده ظاهر میشوند. در این رویکرد، واژگان به عنوان گرههای شبکه و ارتباط میان آنها به عنوان یال تعریف میشود. این ارتباط میتواند بر اساس همرخدادی واژگان در جمله، پاراگراف یا سایر واحدهای متنی تعریف شود.
مطالعات اولیه در این زمینه نشان دادند که شبکههای زبانی اغلب دارای ویژگیهایی مشابه شبکههای پیچیده طبیعی هستند. برای مثال، Ferrer i Cancho و Solé نشان دادند که شبکه واژگان زبان انسانی دارای ساختار مقیاسآزاد است، به این معنا که تعداد کمی از واژگان دارای ارتباطات بسیار زیاد هستند، در حالی که اکثر واژگان ارتباطات محدودی دارند [1].
همچنین تحقیقات بعدی نشان دادند که شبکههای زبانی معمولا دارای ویژگی جهان کوچک (Small-World) هستند. این ویژگی بیان میکند که فاصله میان گرهها در چنین شبکههایی نسبتا کوتاه است و در عین حال خوشهبندی معنایی بالایی وجود دارد [2]. چنین ساختاری در بسیاری از سیستمهای طبیعی و اجتماعی نیز مشاهده شده است.
شعر به دلیل ساختار فشرده و استفاده گسترده از نمادها و استعارهها، یکی از پیچیدهترین انواع متون زبانی محسوب میشود. این ویژگی باعث شده است تحلیل شعر با استفاده از روشهای محاسباتی چالشبرانگیز باشد. با این حال پژوهشهای متعددی نشان دادهاند که تحلیل شبکهای میتواند ابزار مناسبی برای بررسی ساختار شعر باشد.
در برخی مطالعات، همرخدادی واژگان در سطح بیت یا مصرع به عنوان معیار ارتباط در نظر گرفته شده است. این رویکرد به ویژه در تحلیل شعر کلاسیک کاربرد دارد زیرا بیت در بسیاری از سبکهای شعری فارسی واحد معنایی مستقلی محسوب میشود.
برخی پژوهشگران نشان دادهاند که شبکه واژگان در شعر اغلب دارای خوشههای معنایی متمایز است که بیانگر موضوعات اصلی شعر هستند. برای مثال خوشههایی مربوط به عشق، عرفان، طبیعت یا مفاهیم اجتماعی میتوانند در شبکه واژگان ظاهر شوند [5].
در حوزه ادبیات فارسی، پژوهشهای محاسباتی نسبتا محدودتر بودهاند اما در سالهای اخیر رشد قابل توجهی داشتهاند. برخی مطالعات به تحلیل سبکشناسی آثار شاعران فارسی با استفاده از روشهای پردازش زبان طبیعی پرداختهاند. این مطالعات نشان دادهاند که هر شاعر دارای الگوی واژگانی و ساختار معنایی خاص خود است.
در پژوهشی که بر روی آثار مولوی انجام شد، شبکه همرخدادی واژگان مورد بررسی قرار گرفت و نتایج نشان داد که مفاهیم عرفانی نقش مرکزی در شبکه معنایی اشعار مولوی دارند [6]. همچنین در مطالعاتی دیگر، ساختار شبکهای اشعار سعدی و فردوسی مورد بررسی قرار گرفته و تفاوتهای سبکشناسی میان این شاعران تحلیل شده است.
با وجود این تلاشها، بررسی جامع شبکه واژگان در غزلیات حافظ هنوز به صورت محدود انجام شده است. پیچیدگی زبانی و استفاده گسترده از نمادها در شعر حافظ باعث شده است تحلیل ساختاری این آثار همچنان به عنوان یک چالش پژوهشی مطرح باشد.
مرور پژوهشهای پیشین نشان میدهد که تحلیل شبکهای میتواند ابزار قدرتمندی برای بررسی ساختار متون زبانی و ادبی باشد. با این حال در بسیاری از مطالعات تمرکز بر زبانهای اروپایی بوده و ادبیات فارسی کمتر مورد توجه قرار گرفته است. همچنین در اغلب پژوهشها تحلیل شبکهای در سطح جمله یا متن کامل انجام شده و بررسی همرخدادی واژگان در سطح بیت شعر کمتر مورد مطالعه قرار گرفته است.
پژوهش حاضر تلاش میکند با تمرکز بر غزلیات حافظ، این خلأ پژوهشی را تا حدی پوشش دهد. در این تحقیق با استفاده از ترکیب روشهای پردازش زبان طبیعی و تحلیل شبکههای پیچیده، ساختار معنایی شعر حافظ مورد بررسی قرار گرفته است. علاوه بر این با تحلیل شاخصهایی مانند همبستگی واژگان پرتکرار و کشف خوشههای معنایی، تلاش شده است تصویری جامعتر از ساختار مفهومی این آثار ارائه شود.
در این پژوهش برای تحلیل ساختار واژگانی غزلیات حافظ از ترکیب روشهای پردازش زبان طبیعی و تحلیل شبکههای پیچیده استفاده شده است. روند انجام پژوهش شامل چند مرحله اصلی بوده است که از جمعآوری دادهها آغاز شده و تا تحلیل ساختار شبکه واژگان ادامه یافته است. در ادامه هر یک از این مراحل به صورت جداگانه توضیح داده میشود.
در نخستین مرحله، لازم بود مجموعهای نسبتا کامل و قابل اتکا از غزلیات حافظ تهیه شود. در ابتدا تلاش شد دادهها از طریق API پایگاه گنجور استخراج شوند. گنجور یکی از مهمترین منابع دیجیتال شعر فارسی است که مجموعه بزرگی از آثار شاعران کلاسیک را در اختیار پژوهشگران قرار میدهد.
با این حال استفاده مستقیم از API این سامانه با محدودیتهایی همراه بود. مهمترین چالشها شامل موارد زیر بود:
زمانبر بودن فرآیند دریافت تعداد زیاد غزل
ناپایداری اتصال شبکه در برخی درخواستها
بازگشت ناقص دادهها در برخی موارد
محدودیتهای نرخ درخواست (Rate Limit)
به همین دلیل برای افزایش پایداری و تکرارپذیری پژوهش از نسخه پایگاه داده SQLite که شامل مجموعه کامل غزلیات حافظ بود استفاده شد. این پایگاه داده شامل اطلاعاتی مانند شناسه شعر، شماره مصرع، موقعیت مصرع و متن آن بود.
در این پژوهش فقط غزلیات حافظ مورد استفاده قرار گرفت و سایر قالبهای شعری حذف شدند. مجموعا حدود ۴۹۵ غزل در تحلیل لحاظ شد.
یکی از تصمیمهای مهم در تحلیل شبکهای متون، تعیین واحد تحلیل است. در این پژوهش واحد تحلیل بیت شعر در نظر گرفته شد. دلیل این انتخاب آن است که در شعر فارسی، بیت اغلب یک واحد معنایی نسبتا مستقل محسوب میشود. برای تشکیل بیتها، مصرعهای متوالی هر غزل با یکدیگر ترکیب شدند. به این ترتیب، هر بیت به عنوان یک قطعه متنی مستقل برای استخراج واژگان در نظر گرفته شد.
متون خام شعری معمولا شامل انواع مختلفی از نویسهها، علائم نگارشی و تنوع نوشتاری هستند. بنابراین پیشپردازش زبانی یکی از مراحل کلیدی در این پژوهش محسوب میشود.
در این مرحله از کتابخانه Hazm استفاده شد که یکی از ابزارهای رایج برای پردازش زبان فارسی است. مراحل پیشپردازش شامل موارد زیر بود:
pip install hazm from hazm import Normalizer, word_tokenize
در این مرحله،اشکال مختلف یک نویسه به شکل استاندارد تبدیل شد. برای مثال تفاوتهای نگارشی حروف «ی» و «ک» یا فاصلههای اضافی حذف شدند. این کار باعث شد واژگان مشابه به عنوان یک گره واحد در شبکه در نظر گرفته شوند.
درین بخش هر بیت به مجموعهای از واژگان مجزا تبدیل شد. توکنسازی به ما اجازه داد ساختار واژگانی هر بیت را استخراج کنیم.
یکی از چالشهای تحلیل شبکه واژگان، حضور کلمات بسیار پرتکرار اما کممعنا مانند حروف اضافه و ضمایر است. وجود این واژگان باعث میشود ساختار شبکه تحت تأثیر عناصر غیرمفهومی قرار گیرد.
به همین دلیل مجموعهای از واژگان دستوری فارسی به صورت دستی تعریف و از دادهها حذف شد. این مجموعه شامل کلماتی مانند «و»، «به»، «از»، «در»، «که» و موارد مشابه بود:
STOPWORDS = set([ "و","به","از","در","که","را","با","بر","این","آن", "تا","چو","ز","است","بود","شد","ای", "من","تو","ما","او","شان","ش","ام","ات","اش", "هر","هم","یا","اگر","نیز","جز","گر","چنین","چنان" ])
پس از پیشپردازش دادهها، شبکه همرخدادی واژگان ساخته شد. در این شبکه:
هر واژه به عنوان یک گره در نظر گرفته شد
اگر دو واژه در یک بیت ظاهر میشدند، میان آنها یال ایجاد میشد
برای جلوگیری از ایجاد ارتباطات ضعیف یا تصادفی، تنها یالهایی در شبکه لحاظ شدند که تعداد همرخدادی آنها حداقل سه بار در کل مجموعه اشعار مشاهده شده بود. این آستانه باعث شد شبکه حاصل ساختار معنادارتری داشته باشد.
DB_PATH = "hafez.db" EDGE_THRESHOLD = 3
برای پیادهسازی شبکه از کتابخانه NetworkX استفاده شد که یکی از ابزارهای استاندارد در تحلیل شبکههای پیچیده محسوب میشود.
پس از ساخت شبکه، چندین شاخص مهم شبکه محاسبه شد تا ویژگیهای ساختاری آن بررسی شود.
این شاخص نشان میدهد هر واژه با چند واژه دیگر ارتباط دارد. واژگانی که درجه بالاتری دارند، معمولا نقش مفاهیم مرکزی در متن را ایفا میکنند.
این معیار نشان میدهد کدام ارتباطها نقش پل میان بخشهای مختلف شبکه را دارند. یالهایی با مقدار بینابینی بالا معمولاً نشاندهنده ارتباط میان حوزههای معنایی مختلف هستند.
چگالی شبکه نسبت تعداد یالهای موجود به حداکثر تعداد یالهای ممکن را نشان میدهد. این شاخص نشان میدهد شبکه تا چه حد متراکم یا پراکنده است.
این شاخص میزان تمایل واژگان به تشکیل گروههای معنایی محلی را نشان میدهد. مقدار بالای این شاخص نشاندهنده وجود خوشههای مفهومی در متن است.
این معیار نشان میدهد فاصله میان واژگان مختلف در شبکه به طور متوسط چقدر است. این شاخص برای بررسی ویژگی جهان کوچک شبکه مورد استفاده قرار میگیرد.
برای بررسی اینکه آیا واژگان کلیدی شعر حافظ معمولاً همراه با یکدیگر ظاهر میشوند یا خیر، ماتریس همرخدادی واژگان پرتکرار ساخته شد. سپس با محاسبه همبستگی میان این واژگان، میزان ارتباط آنها تحلیل شد. نتایج این بخش به صورت نقشه حرارتی نمایش داده شد.
برای شناسایی حوزههای معنایی غالب در شعر حافظ، از الگوریتم Louvain استفاده شد. این الگوریتم یکی از روشهای شناختهشده برای تشخیص اجتماعات در شبکههای بزرگ است و تلاش میکند گرههایی را که ارتباط بیشتری با یکدیگر دارند در یک گروه قرار دهد.
خوشههای استخراج شده به عنوان نماینده موضوعات مفهومی شعر حافظ مورد تحلیل قرار گرفتند.
برای درک بهتر ساختار شبکه، گراف واژگان مهم و همچنین ساختار کلی شبکه با استفاده از الگوریتم چیدمان فنری ترسیم شد. یکی از چالشهای این مرحله، نمایش صحیح واژگان فارسی بود که با استفاده از ابزارهای اصلاح راستبهچپ متن حل شد.
این پژوهش با وجود تلاش برای ارائه تحلیلی جامع، دارای محدودیتهایی نیز بوده است. مهمترین محدودیتها شامل موارد زیر است:
استفاده از فقط یک شاعر به دلیل محدودیت منابع داده
احتمال حذف برخی واژگان معنادار در فرآیند حذف کلمات دستوری
وابستگی نتایج به آستانه انتخاب شده برای ایجاد یالها
محدودیت ابزارهای موجود برای پردازش زبان فارسی
با وجود این محدودیتها روش ارائه شده چارچوبی مناسب برای تحلیل شبکهای متون ادبی فارسی فراهم میکند.
پس از اجرای مراحل پیشپردازش و ساخت شبکه همرخدادی واژگان، ساختار حاصل مورد تحلیل قرار گرفت. هدف این بخش بررسی ویژگیهای ساختاری شبکه، استخراج واژگان کلیدی، تحلیل ارتباط میان مفاهیم و ارزیابی کارایی روش پیشنهادی است.
پس از پردازش حدود ۴۹۵ غزل حافظ و استخراج بیتها، شبکه همرخدادی واژگان ساخته شد. در این شبکه، هر واژه به عنوان یک گره و ارتباط همرخدادی آنها در سطح بیت به عنوان یال در نظر گرفته شد.
نتایج اولیه نشان داد که شبکه حاصل دارای تعداد قابل توجهی گره و یال است که بیانگر تنوع واژگانی بالا در غزلیات حافظ است. این موضوع نشان میدهد حافظ در عین استفاده از مفاهیم تکرارشونده، دامنه واژگانی گستردهای را به کار برده است.
Ghazals: 495 Total bayts: 4192 Nodes: 1218 Edges: 5908
همچنین مشاهده شد که شبکه دارای ساختاری ناهمگن است؛ به این معنا که برخی واژگان ارتباطات بسیار زیادی دارند، در حالی که بسیاری از واژگان تنها با تعداد محدودی از واژگان دیگر مرتبط هستند. چنین الگویی معمولا در شبکههای زبانی طبیعی مشاهده میشود [1].

چگالی شبکه یکی از شاخصهایی است که میزان اتصال میان گرهها را نشان میدهد. نتایج نشان داد که شبکه واژگان حافظ دارای چگالی نسبتاً پایین است. این موضوع نشان میدهد که هر واژه لزوما با همه واژگان دیگر ارتباط ندارد و شبکه دارای ساختاری پراکنده اما سازمانیافته است.
چگالی پایین در شبکههای زبانی معمولا نشانه وجود ساختار معنایی پیچیده است. در چنین شبکههایی، واژگان تمایل دارند در قالب خوشههای معنایی ظاهر شوند و ارتباط میان خوشهها از طریق تعداد محدودی از واژگان برقرار میشود.
Density: 0.007971363537623136
نتایج نشان داد ضریب خوشهبندی شبکه مقدار قابل توجهی دارد. این شاخص نشان میدهد واژگانی که با یک واژه خاص ارتباط دارند، معمولا با یکدیگر نیز مرتبط هستند.
این ویژگی بیانگر وجود ساختارهای معنایی محلی در شعر حافظ است. به عبارت دیگر واژگان مرتبط با یک مفهوم خاص معمولا در کنار یکدیگر ظاهر میشوند و مجموعههایی از مفاهیم مرتبط را تشکیل میدهند.
چنین الگویی با نتایج پژوهشهای قبلی در زمینه شبکههای زبانی همخوانی دارد و نشان میدهد زبان طبیعی تمایل دارد ساختاری خوشهای داشته باشد [2].
Average clustering: 0.4019691595929732
بررسی طول مسیر متوسط میان گرهها نشان داد فاصله مفهومی میان واژگان در شبکه نسبتا کوتاه است. این ویژگی نشاندهنده وجود خاصیت جهان کوچک در شبکه واژگان حافظ است.
Average path length (largest component): 2.817502228257377
خاصیت جهان کوچک بیان میکند که هر واژه میتواند از طریق تعداد محدودی از ارتباطها به سایر واژگان مرتبط شود. این ویژگی در بسیاری از شبکههای طبیعی و اجتماعی نیز مشاهده شده است و نشاندهنده کارآمدی ساختار شبکه در انتقال معنا است.
یکی از مهمترین نتایج این پژوهش مربوط به توزیع درجه گرهها بود. نمودار توزیع درجه نشان داد که تعداد کمی از واژگان دارای درجه بسیار بالا هستند، در حالی که اکثر واژگان درجه پایینی دارند.
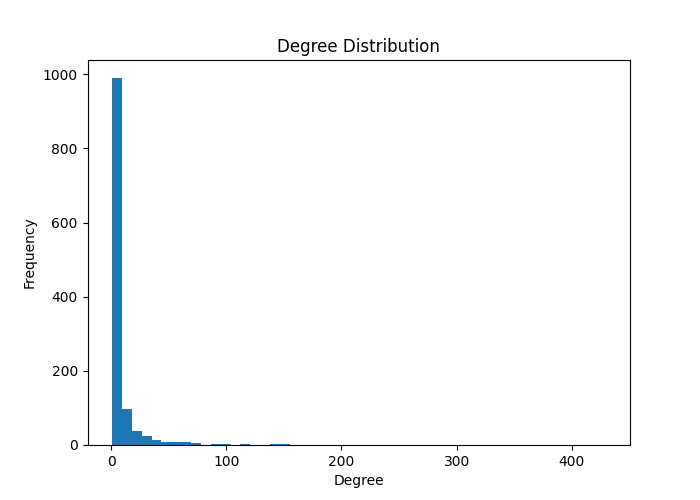
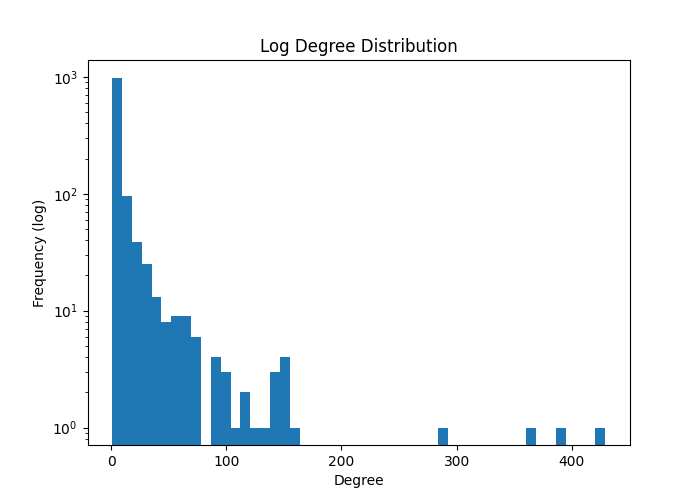
این الگو نشان میدهد شبکه واژگان حافظ دارای ساختاری نزدیک به شبکههای مقیاسآزاد است. در چنین شبکههایی، برخی گرهها نقش هستههای مرکزی را ایفا میکنند و حذف آنها میتواند ساختار شبکه را به شدت تحت تأثیر قرار دهد. وجود چنین ساختاری در شبکه واژگان شعر حافظ نشان میدهد برخی مفاهیم کلیدی نقش بسیار مهمی در شکلدهی ساختار معنایی اشعار دارند.
بر اساس معیار درجه مرکزیّت، مجموعهای از واژگان به عنوان گرههای مهم شبکه شناسایی شدند. این واژگان اغلب شامل مفاهیمی بودند که در شعر حافظ نقش محوری دارند.
Top words: دل چه حافظ سر چون گل نیست دست جان باد چشم عشق نه روی کرد خوش یار خود غم جام زلف کار کن گفت دوست همه خاک دارد جهان صبا
تحلیل این واژگان نشان داد که بسیاری از آنها به حوزههایی مانند عشق، عرفان، رندی و مفاهیم نمادین مرتبط هستند. این نتیجه با دیدگاههای سنتی در تفسیر شعر حافظ همخوانی دارد و نشان میدهد تحلیل شبکهای میتواند به شناسایی مفاهیم مرکزی متن کمک کند.
در مرحله بعد، یالهایی که دارای مقدار بینابینی بالایی بودند مورد بررسی قرار گرفتند. این یالها معمولا ارتباط میان خوشههای معنایی مختلف را برقرار میکنند.
Top bridging edges: حافظ <-> مشو : 0.00560636311691804 چه <-> خاتم : 0.004833010188179768 مشو <-> ایمن : 0.004833010188179768 گل <-> خار : 0.004833010188179768 عشق <-> بحر : 0.004259116997441751 چه <-> شمع : 0.004190140400875639 شراب <-> دل : 0.004040334444791181 چه <-> خیر : 0.00385926842138339 چه <-> نظر : 0.0035149072269120216 حافظ <-> نظر : 0.003234567825025546 چه <-> زنخدان : 0.00323035839129578 سر <-> کون : 0.0032247052902707003 شراب <-> حریف : 0.0032247052902707 دل <-> حرم : 0.0032247052902707 دل <-> نگهدار : 0.0032247052902707 یار <-> مدام : 0.0032247052902707 نه <-> آنم : 0.0032247052902707 جام <-> کنیم : 0.0032247052902707 صد <-> سال : 0.0032247052902707 زر <-> سیم : 0.0032247052902707
نتایج نشان داد برخی ارتباطها نقش پل مفهومی میان حوزههای معنایی متفاوت را دارند. برای مثال، ارتباط میان واژگان مرتبط با عشق و مفاهیم عرفانی در بسیاری از موارد از طریق تعداد محدودی واژه برقرار شده است. این موضوع نشان میدهد شعر حافظ دارای ساختاری چندلایه است که مفاهیم مختلف را به صورت غیرمستقیم به یکدیگر مرتبط میکند.
برای بررسی میزان همظهوری واژگان مهم، ماتریس همبستگی میان واژگان مرکزی ساخته شد. نتایج این تحلیل نشان داد که بسیاری از واژگان کلیدی الزاماً به صورت همزمان در یک بیت ظاهر نمیشوند.
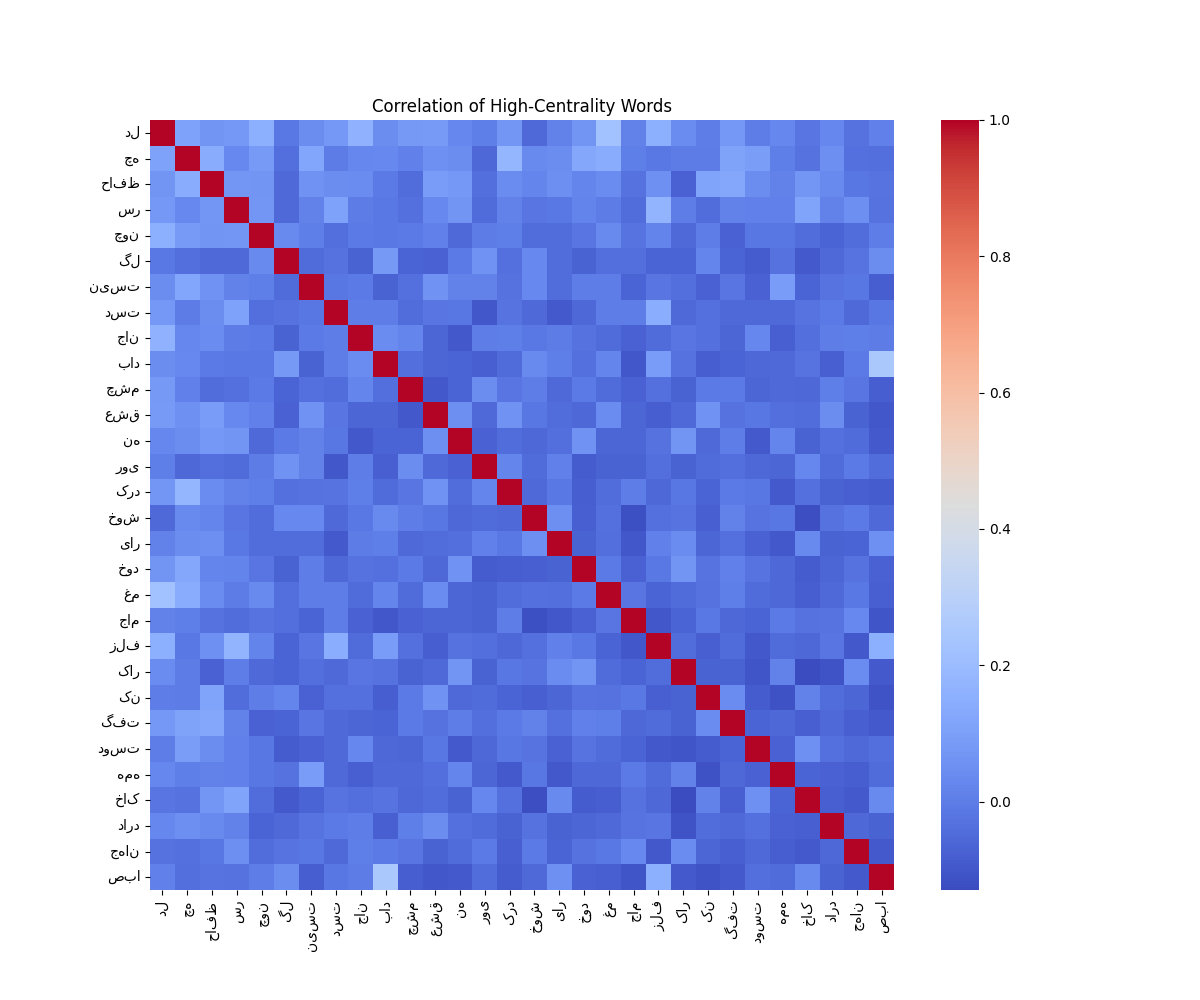
این یافته نشان میدهد مفاهیم مرکزی شعر حافظ به صورت توزیعشده در کل مجموعه اشعار حضور دارند و وابستگی آنها به یکدیگر بیشتر در سطح کلان متن قابل مشاهده است تا در سطح یک بیت خاص.
با استفاده از الگوریتم تشخیص اجتماع، چندین خوشه معنایی در شبکه واژگان شناسایی شد. بررسی واژگان هر خوشه نشان داد که این گروهها اغلب نماینده حوزههای مفهومی مشخصی هستند.
Communities: 18 Community 7 ['آسان', 'اول', 'عشق', 'زان', 'مرا', 'دم', 'راه', 'نبود', 'خود', 'همه', 'کارم', 'نهان', 'ببین', 'ره', 'کار', 'رندی', 'کاین', 'برون', 'پرده', 'راز'] Community 1 ['افتاد', 'شب', 'کجا', 'کز', 'کجاست', 'آفتاب', 'روی', 'چراغ', 'کدام', 'جمال', 'حسن', 'ماه', 'صبحگاهی', 'آینه', 'روز', 'جلوه', 'خوبت', 'رخ', 'عکس', 'کرشمه'] Community 2 ['ولی', 'چه', 'آخر', 'کی', 'تقوا', 'سماع', 'صلاح', 'دریابد', 'دوست', 'کنار', 'حاجت', 'داشت', 'لطف', 'ندانم', 'باشد', 'سود', 'ده', 'حال', 'زاهد', 'رندان'] Community 3 ['خون', 'آب', 'رنگ', 'چشم', 'سیه', 'مژه', 'مست', 'دلم', 'خانه', 'خمار', 'تیر', 'دیده', 'چوگان', 'گوی', 'ارغوان', 'شیوه', 'باز', 'ابروی', 'کمان', 'نقش'] Community 4 ['بوی', 'صبا', 'تاب', 'طره', 'منزل', 'باد', 'خوشش', 'یاد', 'خال', 'دست', 'خط', 'یار', 'خوش', 'دراز', 'مرغ', 'دام', 'سهی', 'آورد', 'بلبل', 'گل']
برای مثال، برخی خوشهها شامل واژگان مرتبط با مفاهیم عرفانی و معنوی بودند، در حالی که برخی دیگر به مفاهیم عشق، می و رندی اشاره داشتند. وجود چنین خوشههایی نشان میدهد شعر حافظ از ساختاری مفهومی و نظاممند برخوردار است.
مصورسازی شبکه واژگان و خوشههای معنایی دید بهتری نسبت به ساختار کلی شعر حافظ ارائه داد. در این تصاویر، خوشههای معنایی به صورت گروههایی از گرههای متراکم مشاهده شدند که توسط تعداد محدودی یال به یکدیگر متصل بودند.


در فرآیند انجام پژوهش، برخی محدودیتهای عملی نیز وجود داشت. مهمترین چالشها شامل موارد زیر بود:
کامل نبودن برخی پایگاههای داده شعری
زمانبر بودن دریافت دادهها از API گنجور
محدودیت ابزارهای پردازش زبان فارسی
نیاز به تعریف دستی واژگان دستوری
به دلیل این محدودیتها، تحلیل شبکه تنها بر روی غزلیات حافظ انجام شد. با این حال، چارچوب ارائه شده قابلیت تعمیم به سایر شاعران را دارد.
نتایج کلی پژوهش نشان میدهد شبکه واژگان غزلیات حافظ دارای ویژگیهای زیر است:
ساختار ناهمگن و نزدیک به شبکههای مقیاسآزاد
وجود خوشههای معنایی مشخص
حضور واژگان مرکزی با نقش مفهومی مهم
ارتباط غیرمستقیم میان حوزههای معنایی مختلف
این نتایج نشان میدهد تحلیل شبکهای میتواند ابزار مؤثری برای درک ساختار مفهومی آثار ادبی باشد.
در این پژوهش تلاش شد ساختار واژگانی غزلیات حافظ با استفاده از روشهای تحلیل شبکههای پیچیده مورد بررسی قرار گیرد. هدف اصلی این تحقیق ارائه تصویری ساختاری از روابط میان واژگان شعر حافظ و بررسی نحوه شکلگیری مفاهیم در این آثار بود. برای دستیابی به این هدف، ابتدا مجموعهای از غزلیات حافظ استخراج و پس از انجام مراحل پیشپردازش زبانی، شبکه همرخدادی واژگان در سطح بیت ساخته شد. سپس با استفاده از شاخصهای مختلف تحلیل شبکه، ساختار این شبکه مورد ارزیابی قرار گرفت.
نتایج بهدستآمده نشان داد که شبکه واژگان حافظ دارای ساختاری ناهمگن و مشابه شبکههای مقیاسآزاد است. این ویژگی نشان میدهد برخی واژگان نقش بسیار مهمی در سازماندهی معنایی اشعار دارند. چنین الگویی پیشتر در تحلیل شبکههای زبانی نیز مشاهده شده و نشاندهنده ماهیت خودسازمانیافته زبان طبیعی است [1].
یکی دیگر از نتایج مهم پژوهش، مشاهده مقدار قابل توجه ضریب خوشهبندی در شبکه بود. این موضوع نشان داد واژگان مرتبط با یک مفهوم خاص تمایل دارند در قالب گروههای معنایی ظاهر شوند. وجود این خوشهها بیانگر آن است که شعر حافظ صرفا مجموعهای از واژگان پراکنده نیست، بلکه ساختاری نظاممند و چندلایه دارد.
تحلیل توزیع درجه شبکه نیز نشان داد که تعداد محدودی از واژگان دارای ارتباطات بسیار گسترده هستند، در حالی که اکثر واژگان ارتباطات محدودتری دارند. این نتیجه با یافتههای پژوهشهای قبلی در حوزه شبکههای زبانی همخوانی دارد و نشان میدهد متون ادبی نیز از الگوهای ساختاری مشابه سایر سیستمهای پیچیده پیروی میکنند [2].
بررسی یالهای دارای بینابینی بالا نشان داد برخی ارتباطها نقش پل مفهومی میان حوزههای معنایی مختلف را ایفا میکنند. این یافته نشان میدهد مفاهیم موجود در شعر حافظ به صورت مجزا عمل نمیکنند، بلکه از طریق مجموعهای از ارتباطهای غیرمستقیم به یکدیگر متصل هستند.
تحلیل همبستگی واژگان پرتکرار نیز نشان داد که واژگان کلیدی شعر حافظ الزاما در یک بیت به طور همزمان ظاهر نمیشوند. این موضوع نشان میدهد حافظ مفاهیم مرکزی خود را در سراسر مجموعه اشعار توزیع کرده است و از تکرار مستقیم آنها در یک ساختار محدود پرهیز کرده است. چنین رویکردی میتواند یکی از دلایل عمق معنایی و چندلایه بودن شعر حافظ باشد.
از دیگر دستاوردهای مهم این پژوهش، شناسایی خوشههای معنایی در شبکه واژگان بود. بررسی این خوشهها نشان داد مفاهیمی مانند عشق، عرفان، رندی و نمادهای اجتماعی در ساختار شعر حافظ نقش محوری دارند. این نتیجه با تفسیرهای سنتی از شعر حافظ همخوانی دارد، اما تحلیل شبکهای امکان مشاهده این ساختارها را به صورت کمی فراهم میکند.
با وجود نتایج قابل توجه، این پژوهش دارای محدودیتهایی نیز بوده است. مهمترین محدودیت مربوط به دسترسی به دادههای کامل برای سایر شاعران بود. در ابتدا برنامهریزی شده بود تحلیل مقایسهای میان چند شاعر کلاسیک فارسی انجام شود، اما محدودیتهای فنی و زمانبر بودن دریافت دادهها از API گنجور باعث شد تمرکز پژوهش بر غزلیات حافظ محدود شود. با این حال، چارچوب ارائه شده در این تحقیق قابلیت تعمیم به سایر مجموعههای شعری را دارد.
از سوی دیگر، حذف واژگان دستوری اگرچه باعث افزایش کیفیت تحلیل معنایی شد، اما احتمال حذف برخی واژگان دارای نقش بلاغی را نیز به همراه داشت. همچنین انتخاب آستانه برای ایجاد یالها میتواند بر ساختار نهایی شبکه تأثیر بگذارد و نتایج را تا حدی وابسته به تنظیم پارامترها کند.
با توجه به نتایج این پژوهش، مسیرهای متعددی برای تحقیقات آینده قابل پیشنهاد است. یکی از مهمترین این مسیرها انجام تحلیل مقایسهای میان شاعران مختلف فارسی است. چنین مطالعهای میتواند تفاوتهای سبکشناسی میان شاعران را از منظر شبکهای آشکار کند.مسیر دیگر، ترکیب تحلیل شبکه با روشهای مدلسازی موضوعی مانند LDA است. این ترکیب میتواند امکان برچسبگذاری دقیقتر خوشههای معنایی را فراهم کند و درک عمیقتری از ساختار مفهومی شعر ارائه دهد.
همچنین بررسی تکامل شبکه واژگان در دورههای مختلف زندگی شاعران میتواند دیدگاه جدیدی درباره تغییر سبک ادبی آنها ارائه کند. علاوه بر این، استفاده از روشهای یادگیری عمیق و مدلهای زبانی پیشرفته میتواند به استخراج روابط معنایی پیچیدهتر میان واژگان کمک کند.
در مجموع، نتایج این پژوهش نشان میدهد تحلیل شبکهای ابزار قدرتمندی برای مطالعه متون ادبی است و میتواند دیدگاهی مکمل برای روشهای سنتی تحلیل ادبی فراهم کند. ترکیب این رویکردها میتواند به درک عمیقتر ساختار زبان و ادبیات فارسی کمک کند.

[1] R. Ferrer-i-Cancho and R. V. Solé, “The small world of human language,” Proceedings of the Royal Society B, vol. 268, no. 1482, pp. 2261–2265, 2001.
[2] M. Newman, Networks: An Introduction. Oxford University Press, 2018.
[3] D. R. Amancio, E. G. Altmann, O. N. Oliveira Jr., and L. F. Costa, “Comparing intermittency and network measurements of words and their dependence on authorship,” New Journal of Physics, vol. 13, 2011.
[4] M. Stella, M. De Domenico, and A. Baronchelli, “Network analysis of narrative structures in literary texts,” EPJ Data Science, vol. 7, no. 1, 2018.
[5] J. Liu, Y. Wang, and Z. Zhang, “Complex network analysis of literary texts: A review,” Information Sciences, vol. 512, pp. 236–249, 2020.
[6] H. Alikhani and M. Ghiasi, “Computational analysis of Persian poetic texts using complex networks,” Digital Scholarship in the Humanities, vol. 36, no. 3, pp. 610–624, 2021.
[7] S. Bird, E. Klein, and E. Loper, Natural Language Processing with Python. O’Reilly Media, 2020.
[8] T. Mikolov et al., “Efficient estimation of word representations in vector space,” arXiv preprint arXiv:1301.3781, 2013.
[9] V. Blondel et al., “Fast unfolding of communities in large networks,” Journal of Statistical Mechanics, 2008.
[10] A. B. Parsa and M. Amini, “Recent advances in Persian NLP and digital humanities,” ACM Computing Surveys, 2023.