
کش در واقع یک لایه ی حافظه است که مابین حافظه اصلی (RAM) و واحد پردازش (CPU)، یا هر قطعه ای که نیاز به دریافت مکرر داده دارد، قرار می گیرد و وظیفه آن دسترسی سریع تر به داده هاست.
در واقع کش را مثل یک کوله پشتی 🎒 نگاه کنید که در عین حجم کم، وسایل پرکاربرد تر و حیاتی تر خود را در آن نگه میدارید تا دسترسی آسان تر و سریع تر به آن داشته باشید.
اصولا مکانیزم کش دارای ۳ سطح رایج است: L1 - L2 - L3
هرچه به سطوح پایین تر می رویم به حافظه اصلی نزدیک تر می شویم. طبعا با افزایش حجم حافظه کش سرعت دسترسی کمتر می شود و باید زمان بیشتری منتظر بمانیم تا داده مد نظر ما از کش خوانده شود.
در تصویر زیر اطلاعات عمومی سطوح مختلف کش آورده شده است:
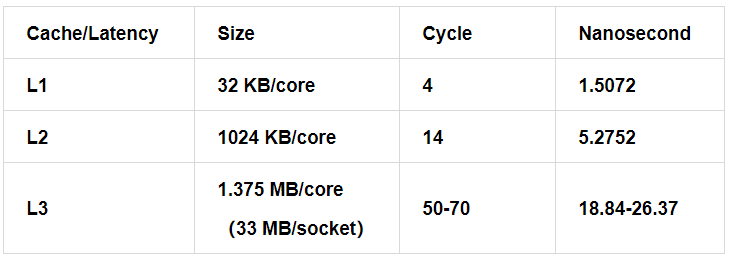
همانطور که می بینید در سطوح پایین تر، حجم کش افزایش می یابد و مدت زمان بیشتری برای hit شدن صرف خواهد شد. حال این پرسش مطرح می شود که hit به چه معناست؟ در ادامه به این موضوع میپردازیم...
کوله پشتی را بخاطر بیاورید.🤔
وقتی شما به دنبال وسیله ای در کوله تان باشید ۲ حالت رخ میدهد:
۱) آن را با صرف زمان کمی یافت میکنید (Hit)
۲) آن را در کوله یافت نمی کنید (Miss) و مجبور می شوید بروید در چمدانتان آن را پیدا کرده و برای استفاده های بعدی تان آن را در کوله بگذارید.
سیستم کش هم همینگونه است. اگر CPU داده مخصوصی را درخواست کند، ابتدا در کش به دنبال آن می گردد و اگر درخواستش Hit شود یعنی آن را پیدا کرده است. ولی اگر آن را یافت نکند، بدین معناست که درخواستش Miss شده و مجبور میشود به حافظه اصلی برود و آنجا با صرف زمان بیشتر به دنبال داده خود بگردد و وقتی آن را پیدا کرد، جهت استفاده های بعدی خود آن را در کش ذخیره کند.
حال سوالی که پیش می آید این است که کوله پشتی ما حجم مشخصی دارد و نمی توانیم هرچقدر دلمان خواست در آن وسیله بریزیم. اگر کوله مان پر بود چگونه جایگزین کنیم؟جواب را در ادامه خواهیم دید...
روش های متعددی برای جایگزینی در کش وجود دارد که من اینجا چند مورد از رایج ترین ها را نام می برم:
۱) سیاست LRU
مخفف Least Recently Used هست بدین معنا که شما داده (ها) ای را که از نظر زمانی زودتر استفاده کرده اید را خارج می کنید. منظور از زودتر، تایمی است که آن داده توسط یک درخواست Hit شده باشد. بعنوان مثال اگر بین ۳ داده a,b,c هر کدام به ترتیب در زمان های 2s , 17s و 8s از کش خوانده شده باشند، داده b چون خیلی قبل تر از دو داده دیگر خوانده و استفاده شده است از کش خارج شده و داده دیگری جای آن را می گیرد.
۲) سیاست MRU
مخفف Most Recently Used هست که مشابه روش قبلی است با این تفاوت که داده ای را جایگزین میکنیم که از نظر تعدد، بیشترین درخواست را از سمت CPU داشته است.در واقع پر استفاده ترین داده را حذف میکنیم.
۳) سیاست FIFO
مخفف First In First Out می باشد که یعنی مثل صف نانوایی 🫓افراد به ترتیب وارد شدن در صف خارج میشوند. در کش هم همینگونه عمل میشود و در صورت پر شدن آن، داده ها به ترتیب ذخیره شدن شان در کش از آن خارج می شوند.
۴) سیاست Random Replacement
همانگونه که از نامش مشخص است درین روش هر بار بصورت تصادفی داده ای را جایگزین میکنیم
درین مقاله به جزییات پیاده سازی این سیاست ها نمی پردازم و توضیح آن را به شرط حیات در مقاله دیگری شرح خواهم داد.
جزییات و روش های تکمیلی را در این لینک مشاهده کنید.