
مقدمه: ظهور عصر جدید در بازیابی اطلاعات
در چارچوب تحقیقات آکادمیک و حرفهای، «بازیابی اطلاعات (Information Retrieval – IR) به فرآیند به دست آوردن اطلاعات مرتبط از مجموعههای بزرگ منابع بر اساس درخواست کاربر اطلاق میشود، در حالی که «هوش مصنوعی» (Artificial Intelligence - AI) به شبیهسازی هوش انسانی در ماشینها برای یادگیری، استدلال و حل مسئله اشاره دارد. رشد تصاعدی محتوای دیجیتال در دوران معاصر، پدیدهای به نام «سرریز اطلاعات» را به وجود آورده که چالشهای جدی برای محققان در جهت یافتن منابع مرتبط ایجاد کرده است. برای مقابله با این چالشها، نیاز به سازوکارهای فیلتر و بازیابی پیچیدهتر، ضروری شده است. تاریخچه هوش مصنوعی، که با آزمون تورینگ در دهه ۱۹۵۰ آغاز شد، دورهای از رکود معروف به «زمستان هوش مصنوعی » را تجربه کرد. با این حال، پیشرفتهای اخیر در یادگیری عمیق، دسترسی به دادههای انبوه و افزایش قدرت محاسباتی، به تجدید حیات این حوزه منجر شده است. این تحولات، هوش مصنوعی را به عنوان یک نیروی دگرگونکننده برای حل چالشهای مدرن بازیابی اطلاعات مطرح کرده و راه را برای توسعه سیستمهای مقیاسپذیر، دقیق و هوشمند هموار ساخته است. درک این تحول، مستلزم بررسی دقیق گذار از سیستمهای سنتی به پارادایمهای جدید مبتنی بر هوش مصنوعی است.
۱. گذار از سیستمهای سنتی به سیستمهای هوشمند: یک تحلیل مقایسهای
برای درک کامل نوآوریهای هوش مصنوعی در حوزه بازیابی اطلاعات، درک استراتژیک محدودیتهای سیستمهای سنتی امری ضروری است. این سیستمها، با وجود نقش بنیادین خود در دهههای گذشته، دیگر قادر به پاسخگویی به نیازهای پیچیده محققان در عصر دیجیتال نیستند. تحلیل چالشهای این سیستمها، اهمیت گذار به پارادایمهای هوشمند را آشکار میسازد.
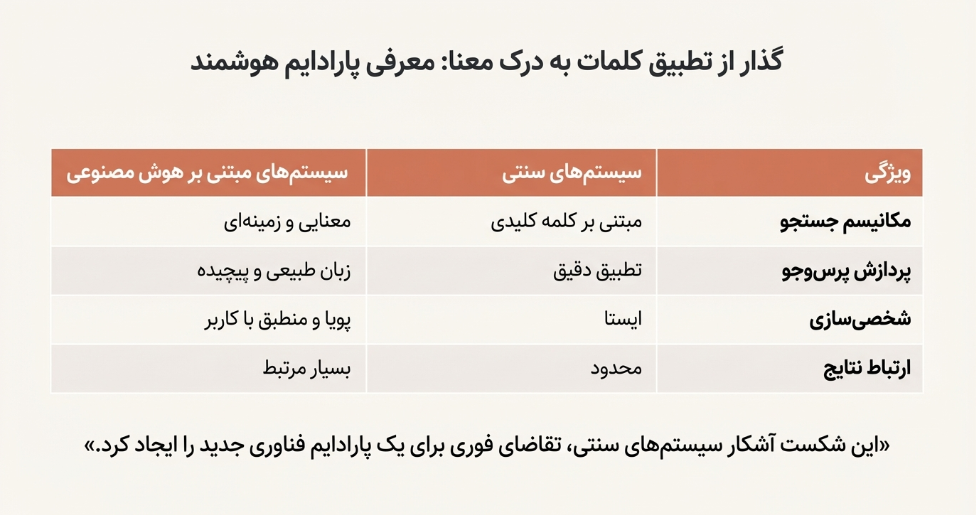
چالشهای اصلی سیستمهای بازیابی اطلاعات سنتی عبارتند از:
سرریز داده و رتبهبندی ضعیف ارتباط: الگوریتمهای سنتی که عمدتاً بر تطبیق کلمات کلیدی تکیه دارند، در مواجهه با حجم عظیم دادههای آکادمیک، در ارائه نتایج دقیق و مرتبط ناتوان هستند. این رویکرد سادهانگارانه، کاربران را با انبوهی از اطلاعات غیرمرتبط مواجه میکند و فرآیند تحقیق را کند و ناکارآمد میسازد.
محدودیتهای درک معنایی: این سیستمها به جای معنا، بر تطبیق واژگان متمرکز هستند. آنها کلمات را مطابقت میدهند، نه مفاهیم را؛ به همین دلیل در درک قصد، زمینه و روابط معنایی در پس پرسوجوهای پیچیده کاربران شکست میخورند و در پاسخ به پرسوجوهای چندوجهی دانشگاهی، نتایج ضعیفی ارائه میدهند.
فقدان شخصیسازی و انطباقپذیری: رویکرد «یک اندازه برای همه» در سیستمهای سنتی، نیازهای متنوع کاربران آکادمیک (از دانشجویان مبتدی تا محققان باتجربه) را برآورده نمیکند. این سیستمها توانایی تطبیق نتایج بر اساس تاریخچه جستجو، علایق پژوهشی یا سطح دانش کاربر را ندارند.
کیفیت و ناهماهنگی فرادادهها: بازیابی مؤثر در سیستمهای سنتی به شدت به فرادادههای دقیق و ساختاریافته وابسته است. با این حال، خطاهای انسانی، استانداردهای متفاوت نمایهسازی و فرادادههای ناقص یا نادرست، کشف منابع مرتبط را مختل کرده و باعث میشود مقالات ارزشمند از دید کاربران پنهان بمانند.
چالشهای مقیاسپذیری و یکپارچهسازی: بسیاری از سیستمهای قدیمی برای مدیریت مجموعههای کوچک و ساختاریافته طراحی شدهاند و در مدیریت حجم عظیم و قالبهای متنوع محتوای دیجیتال مدرن (مانند چندرسانهایها و مجموعه دادهها) با مشکلات جدی در مقیاسپذیری و یکپارچهسازی مواجه هستند.
همانطور که در جدول ۱ نشان داده شده است، تفاوتهای کلیدی بین این دو رویکرد بنیادین است:
جدول ۱: مقایسه سیستمهای بازیابی اطلاعات سنتی و مبتنی بر هوش مصنوعی
پارادایمی که بر مجموعهای از ابزارهای مبتنی بر هوش مصنوعی بنا شده و قادر به درک معنا، زمینه و قصد کاربر است.
۲. فناوریهای کلیدی هوش مصنوعی در تحول بازیابی اطلاعات
مجموعهای از فناوریهای هوش مصنوعی به صورت همافزا عمل میکنند تا سیستمهای بازیابی اطلاعات دقیقتر، کارآمدتر و کاربرمحورتر را ایجاد کنند. این فناوریها با فراتر رفتن از تطبیق ساده کلمات کلیدی، درک عمیقتری از محتوا و قصد کاربر را ممکن میسازند و قابلیتهای جدیدی را برای سازماندهی، شخصیسازی و کشف اطلاعات فراهم میآورند.
۲.۱. یادگیری ماشین و شبکههای عصبی
مدلهای یادگیری عمیق و شبکههای عصبی، هسته اصلی سیستمهای بازیابی اطلاعات مدرن را تشکیل میده مدلهایی مانند:
BERT (Bidirectional Encoder Representations from Transformers) با تحلیل زمینه کلمات در یک پرسوجو، امکان جستجوی معنایی را فراهم میکنند. برخلاف سیستمهای سنتی که کلمات را به صورت مجزا پردازش میکنند، BERT میتواند تفاوت معنایی بین کلماتی مانند «lead» (به معنای رهبری کردن) و «lead» (به معنای فلز سرب) را بر اساس جمله تشخیص دهد. این توانایی درک زمینهای، دقت جستجو را به شدت افزایش میدهد. با این حال، قدرت این مدلها ناشی از پیچیدگی ذاتی آنهاست که درک فرآیند تصمیمگیریشان را برای انسان دشوار میسازد و به چالش «جعبه سیاه» که در ادامه بررسی میشود، دامن میزند. همچنین، اتکای این مدلها به دادههای آموزشی عظیم، آنها را در برابر بازتولید سوگیریهای موجود در دادهها آسیبپذیر میکند.
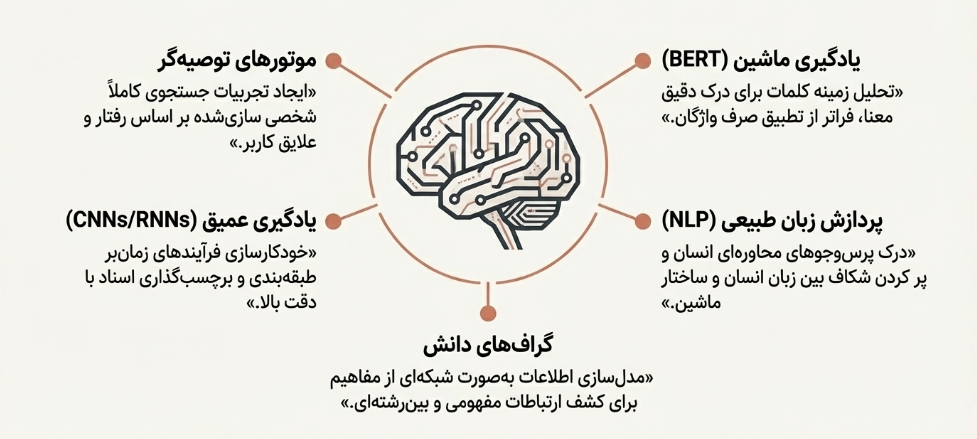
۲.۲. پردازش زبان طبیعی (NLP) برای جستجوی پیشرفته
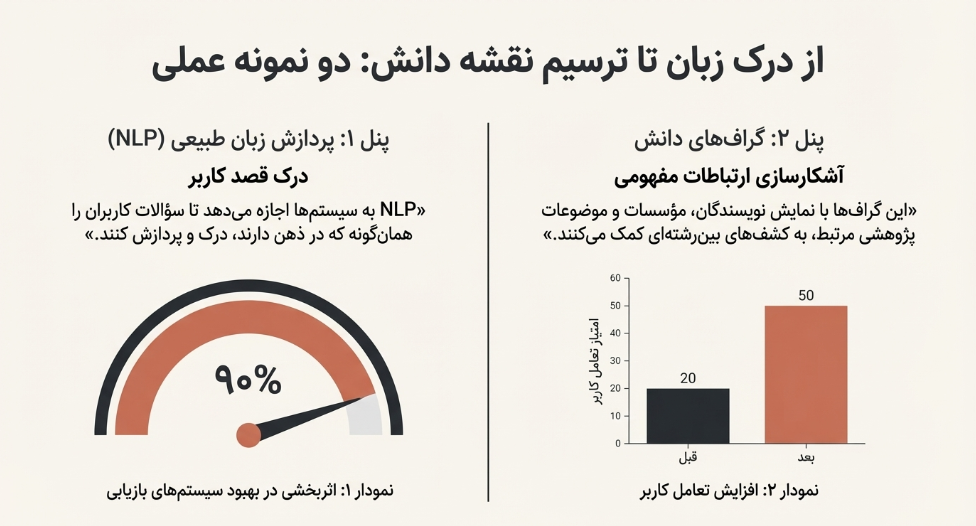
پردازش زبان طبیعی (NLP) به سیستمها اجازه میدهد تا پرسوجوهای محاورهای و زبان طبیعی انسان را درک کرده و پردازش کنند. این فناوری شکاف بین زبان پیچیده انسانی و ساختار دادهای ماشین را پر میکند و به کاربران امکان میدهد تا سؤالات خود را همانگونه که در ذهن دارند، مطرح کنند. همانطور که در نمودار 1 نشان داده شده است، «جستجوی متنی (NLP)» با اثربخشی نزدیک به ۹۰ درصد، یکی از مؤثرترین فناوریها در بهبود سیستمهای بازیابی اطلاعات آکادمیک است.
۲.۳. گرافهای دانش و هستیشناسیها برای اطلاعات زمینهای
گرافهای دانش، اطلاعات را به صورت شبکهای از مفاهیم و روابط بین آنها مدلسازی میکنند. این ساختار به سیستمهای بازیابی اطلاعات اجازه میدهد تا نتایجی را ارائه دهند که نه تنها به طور مستقیم با پرسوجو مرتبط هستند، بلکه ارتباطات مفهومی و بینرشتهای را نیز آشکار میسازند. برای مثال، جستجو برای یک محقق میتواند به نمایش نویسندگان مرتبط، مؤسسات کلیدی و موضوعات پژوهشی مرتبط منجر شود. همانطور که در نمودار ۲ نشان داده شده است، پیادهسازی این فناوری، امتیاز تعامل کاربر را از ۲۰ به ۵۰ افزایش داده است.
۲.۴ یادگیری عمیق برای طبقهبندی و برچسبگذاری اسناد
مدلهای یادگیری عمیق مانند شبکههای عصبی کانولوشنی (CNNs)، که در تحلیل دادههای بصری تبحر دارند، و شبکههای عصبی بازگشتی (RNNs)، که برای پردازش دادههای متوالی مانند متن مناسب هستند، فرآیندهای زمانبر و مستعد خطای نمایهسازی و برچسبگذاری فراداده را خودکار میکنند. این مدلها میتوانند با تحلیل محتوای کامل اسناد، آنها را با دقت بالا دستهبندی کرده و برچسبهای موضوعی مناسب را اختصاص دهند. مطالعات نشان میدهند که این رویکرد، دقت برچسبگذاری را تا ۲۰ درصد بهبود بخشیده و به کشفپذیری بهتر منابع کمک میکند.
۲.۵. موتورهای توصیهگر برای شخصیسازی
موتورهای توصیهگر با استفاده از تکنیکهایی مانند فیلترینگ مشارکتی (پیشنهاد بر اساس رفتار کاربران مشابه) و فیلترینگ مبتنی بر محتوا (پیشنهاد بر اساس ویژگیهای منابع)، تجربیات جستجوی کاملاً شخصیسازیشدهای را ایجاد میکنند. این سیستمها تاریخچه جستجو، مقالات خواندهشده و علایق کاربر را تحلیل کرده و منابع جدیدی را پیشنهاد میدهند. این قابلیت، اگرچه بسیار مؤثر است، اما مستقیماً به چالشهای حریم خصوصی دادهها گره میخورد، زیرا همان دادههایی که این شخصیسازی دقیق را ممکن میسازند، ریسکهای امنیتی و اخلاقی ایجاد میکنند.
این فناوریها به طور مستقیم بر تجربه کاربران در محیطهای آکادمیک تأثیر گذاشته و فرآیندهای تحقیق را متحول کردهاند.
۳. تأثیر و کاربردهای عملی در محیطهای آکادمیک
ارزیابی تأثیرات ملموس هوش مصنوعی بر کاربران و مؤسسات، بهویژه کتابخانههای دانشگاهی، برای درک ارزش واقعی این فناوریها ضروری است. فراتر از بهبودهای فنی، هوش مصنوعی فرآیندهای تحقیق و خدمات اطلاعاتی را به شکل بنیادین دگرگون کرده است. تحلیل موضوعی ۴۱ مقاله بررسیشده در یک مرور نظاممند PRISMA، تصویری واضح از این تحولات در سه حوزه اصلی ارائه میدهد.
۳.۱. بهبود فرآیندهای جستجو و روشهای تحقیق
ابزارهای مبتنی بر هوش مصنوعی، دقت، کارایی و شخصیسازی جستجوی آکادمیک را به سطح جدیدی ارتقا دادهاند. سیستمهای جستجوی معنایی و موتورهای توصیهگر به محققان کمک میکنند تا با سرعت بیشتری به منابع مرتبط دست یابند. علاوه بر این، هوش مصنوعی نقش فزایندهای در خودکارسازی وظایف پژوهشی ایفا میکند. ابزارهای هوشمند میتوانند به طور خودکار مرور ادبیات انجام دهند، شکافهای تحقیقاتی موجود در یک حوزه را شناسایی کنند و حتی در تدوین فرضیهها به محققان یاری رسانند.
۳.۲. تحول در خدمات کتابخانهای
کتابخانههای دانشگاهی به عنوان مراکز نوآوری در پذیرش هوش مصنوعی عمل کردهاند. کاربردهای عملی این فناوری در کتابخانهها شامل نمایهسازی خودکار، مدیریت مراجع، بایگانی دیجیتال و دستیاران مجازی (چتباتها) است. این کاربردها نه تنها کارایی عملیاتی کتابخانهها را افزایش داده، بلکه به کتابداران اجازه میدهد تا بر روی ارائه خدمات مشاورهای تخصصیتر به محققان تمرکز کنند.
۳.۳. ارزیابی مزایای قابلسنجش
تأثیر هوش مصنوعی در محیطهای آکادمیک با معیارهای کمی قابلتوجهی قابل سنجش است:
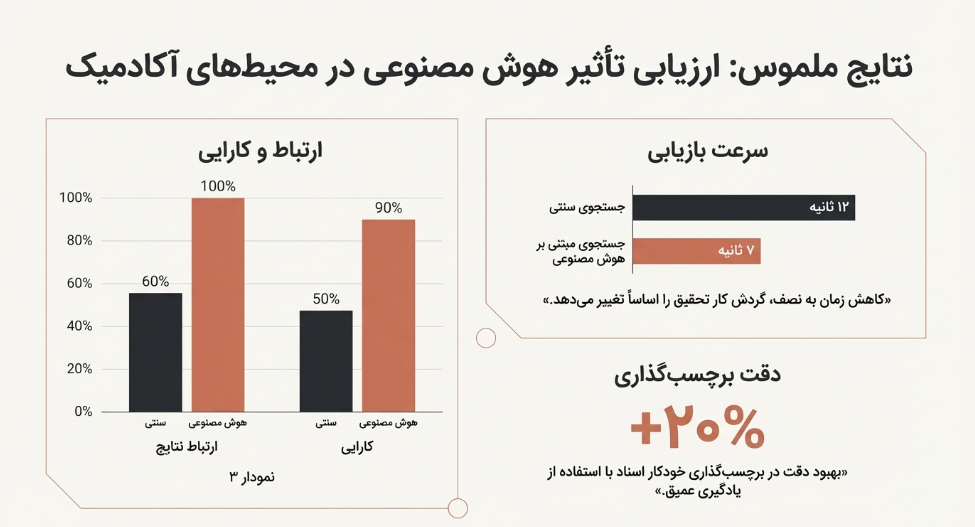
افزایش ارتباط و کارایی جستجو: همانطور که در نمودار ۳ نشان داده شده، با پیادهسازی سیستمهای مبتنی بر هوش مصنوعی، ارتباط نتایج از حدود ۶۰٪ به ۱۰۰٪ و کارایی از حدود ۵۰٪ به ۹۰٪ افزایش یافته است.
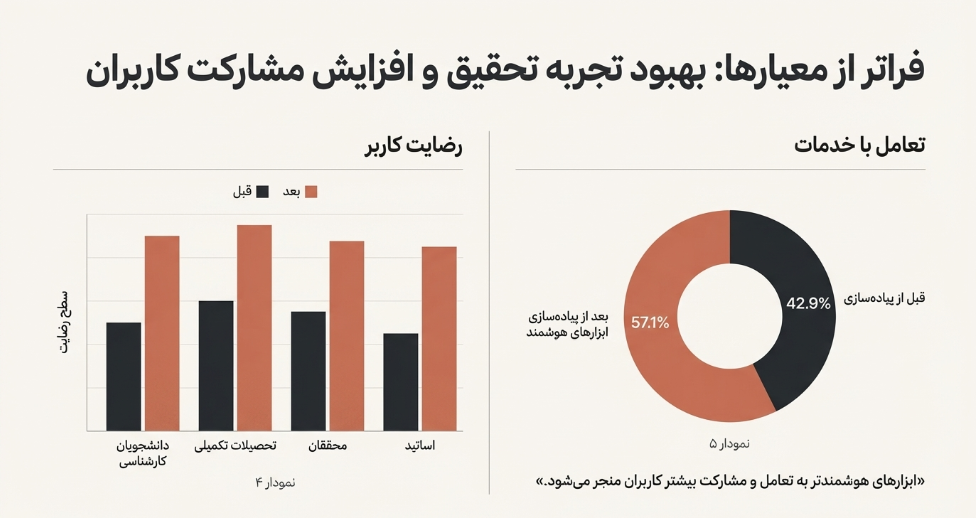
افزایش رضایت کاربر: نمودار ۴ نشان میدهد که رضایت در میان تمام گروههای کاربری، از جمله دانشجویان کارشناسی، تحصیلات تکمیلی، محققان و اساتید، پس از پیادهسازی شخصیسازی مبتنی بر هوش مصنوعی به طور قابلتوجهی افزایش یافته است.
کاهش زمان بازیابی: دادهها نشان میدهند که جستجوی مبتنی بر هوش مصنوعی (۷ ثانیه) و جستجوی مبتنی بر NLP (۶ ثانیه) به مراتب سریعتر از جستجوی سنتی (۱۲ ثانیه) هستند. این کاهش تقریباً به نصف، تنها یک مزیت جزئی نیست؛ بلکه با امکان تکرار سریعتر ایدهها، گردش کار تحقیق را اساساً تغییر داده و سرعت اکتشافات را افزایش میدهد.
افزایش استفاده از کتابخانه: نمودار ۵ نشان میدهد که سهم استفاده از خدمات کتابخانه پس از پیادهسازی ابزارهای هوشمند از ۴۲.۹٪ به ۵۷.۱٪ افزایش یافته است که نشاندهنده تعامل و مشارکت بیشتر کاربران است.
با وجود این مزایای چشمگیر، این فناوریهای قدرتمند چالشها و ملاحظات اخلاقی مهمی را به همراه دارند که نیازمند بررسی دقیق هستند.
۴. چالشها و ملاحظات اخلاقی در پیادهسازی هوش مصنوعی

برای تضمین پذیرش مسئولانه و پایدار هوش مصنوعی در بازیابی اطلاعات، پرداختن به چالشهای فنی و اخلاقی آن از اهمیت حیاتی برخوردار است. نادیده گرفتن این مسائل میتواند منجر به تضعیف اعتماد کاربران، تداوم نابرابریها و ایجاد خطرات پیشبینینشده شود.
۴.۱. سوگیری الگوریتمی و انصاف
سیستمهای هوش مصنوعی از دادههای موجود یاد میگیرند و اگر این دادهها حاوی سوگیریهای تاریخی یا اجتماعی باشند، الگوریتمها نیز همان سوگیریها را بازتولید و تقویت خواهند کرد. این امر که مستقیماً از اتکای مدلهای یادگیری ماشین به دادههای آموزشی نشأت میگیرد، میتواند منجر به نتایج ناعادلانه شود. یافتههای یک مرور نظاممند نشان میدهد که تقریباً ۷۵٪ از مطالعات بررسیشده، نگرانیهای مربوط به کیفیت داده یا سوگیری را تأیید کردهاند.
۴.۲. حریم خصوصی و امنیت دادهها
سیستمهای هوش مصنوعی، به ویژه موتورهای توصیهگر، برای ارائه خدمات شخصیسازیشده به دادههای رفتار و ترجیحات کاربران نیاز دارند. این نیاز، نگرانیهای جدی در مورد حریم خصوصی ایجاد میکند. جمعآوری و تحلیل دادههای کاربران باید با رعایت کامل مقررات حفاظت از دادهها مانند GDPR و با شفافیت کامل انجام شود. ایجاد تعادل بین ارائه خدمات هوشمند و حفاظت از حریم خصوصی افراد، یکی از بزرگترین چالشها در این حوزه است.
۴.۳. تفسیرپذیری و شفافیت (مشکل "جعبه سیاه")
بسیاری از مدلهای پیشرفته هوش مصنوعی، بهویژه مدلهای یادگیری عمیق مانند BERT، به عنوان «جعبه سیاه» عمل میکنند؛ به این معنا که فرآیند تصمیمگیری آنها برای انسان قابل درک نیست. این عدم شفافیت که ناشی از پیچیدگی ذاتی این مدلهاست، اعتبارسنجی نتایج و اعتماد به سیستم را دشوار میسازد. بر اساس تحلیلها، ۶۰٪ از مطالعات، مسائل مربوط به تفسیرپذیری مدل را به عنوان یک چالش کلیدی برجسته کردهاند.
۴.۴. اعتماد و پذیرش کاربر
در نهایت، موفقیت سیستمهای بازیابی اطلاعات مبتنی بر هوش مصنوعی به اعتماد و پذیرش کاربران بستگی دارد. عواملی مانند شفافیت در نحوه عملکرد الگوریتمها، پاسخگویی در قبال خطاها و طراحی اخلاقی که کنترل را در دست کاربر قرار میدهد، برای جلب این اعتماد ضروری هستند. بدون وجود این عناصر، کاربران ممکن است در برابر پذیرش این فناوریها مقاومت کنند.
پرداختن به این چالشها، زمینه را برای ترسیم مسیر آینده و ارائه توصیههایی برای حرکت رو به جلو فراهم میکند.
۵. مسیر پیش رو: آینده و توصیهها
برای بهرهبرداری کامل از پتانسیل هوش مصنوعی و در عین حال کاهش خطرات آن، نگاهی استراتژیک به آینده و روندهای نوظهور ضروری است. این نگاه به ذینفعان کمک میکند تا نوآوریها را به شیوهای مسئولانه هدایت کرده و سیستمهای اطلاعاتی آینده را به گونهای شکل دهند که هم هوشمند و هم قابل اعتماد باشند.
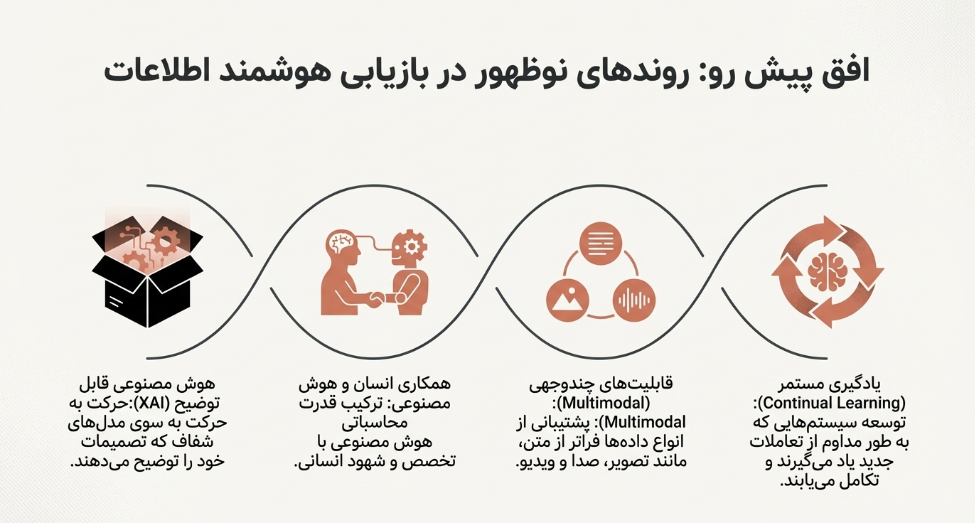
روندهای نوظهور کلیدی در سیستمهای بازیابی اطلاعات مبتنی بر هوش مصنوعی شامل موارد زیر است:
1. مدلهای ترکیبی هوش مصنوعی: ادغام روشهای مختلف هوش مصنوعی برای بهبود عملکرد.
2. هوش مصنوعی قابل توضیح (XAI): تمرکز بر مدلهای شفاف که توضیحات روشنی برای تصمیمات خود ارائه میدهند.
3. یادگیری مستمر: توسعه سیستمهایی که به طور مداوم از تعاملات جدید یاد میگیرند.
4. قابلیتهای چندوجهی: پشتیبانی از انواع دادههای مختلف فراتر از متن (مانند تصویر و صدا).
5. همکاری انسان و هوش مصنوعی: تقویت فرآیندهای تصمیمگیری با ترکیب قدرت محاسباتی هوش مصنوعی با تخصص انسانی.
بر اساس یافتههای مرور نظاممند (PRISMA)، توصیههای عملی زیر برای ذینفعان ارائه میشود:
برای محققان: تشویق به تمرکز بر ادغام هوش مصنوعی در فرآیندهای اصلی تحقیق و توسعه چارچوبهایی برای استفاده شفاف و اخلاقی.
برای کتابخانهها و مؤسسات آموزشی: توصیه به استفاده از ادبیات موجود برای هدایت پذیرش ابزارهای مبتنی بر هوش مصنوعی برای بهبود ارائه خدمات.
برای سیاستگذاران و ذینفعان: فراخوان برای همکاری در ایجاد استانداردها و سیاستهایی برای استفاده مسئولانه از هوش مصنوعی، با پرداختن به مسائلی مانند حریم خصوصی دادهها، سوگیری و تفسیرپذیری.
این توصیهها چارچوبی برای حرکت به سوی آیندهای هوشمندتر در دسترسی به اطلاعات فراهم میکند.
نتیجهگیری: شکلدهی به آینده دسترسی هوشمند به اطلاعات
شواهد نشان میدهند که هوش مصنوعی صرفاً یک بهروزرسانی تدریجی نیست، بلکه یک بازمعماری بنیادین در دسترسی به اطلاعات است. این فناوری با غلبه بر محدودیتهای سیستمهای سنتی، کارایی، دقت و شخصیسازی را به سطوح بیسابقهای رسانده است. با این حال، همین ابزارهای قدرتمند، چالشهای اخلاقی مهمی از جمله سوگیری الگوریتمی، نقض حریم خصوصی و عدم شفافیت را به همراه دارند. بنابراین، وظیفه اصلی در دهه آینده، نه صرفاً پیادهسازی این فناوریها، بلکه راهبری آنهاست؛ یعنی ساختن چارچوبهای اخلاقی و شفافی که برای هدایت این سیستمهای قدرتمند به سوی اهداف عادلانه و قابل اعتماد ضروری است. ایجاد تعادل بین نوآوری فناورانه و نظارت مسئولانه، آیندهای را رقم خواهد زد که در آن دسترسی به اطلاعات، هوشمند، منصفانه و قابل اعتماد باشد.