تحلیل اکتشافی یکی از مهمترین قدمها در حل هر مسئلهی دادهکاوی است.
در این مرحله، شما به بررسی الگوهای موجود در دادهها میپردازید تا درک عمیقتری از مسئله پیدا کرده و مسیر درستی برای مراحل بعدی انتخاب کنید.

فرض کنید یک گراف ساده و بدون جهت به شما داده شده و تعدادی رأس خاص (دارای رفتاری خاص) در آن مشخص شدهاند.
سؤال این است:
چطور میتوان سایر رأسهایی که "شبیه" به این رأسها هستند را در گراف پیدا کرد؟
یکی از ایدههای ساده و کاربردی برای تحلیل رفتار رأسها، بررسی Graphletهایی است که آنها در آنها ظاهر میشوند.
📌 Graphlet گرافی با n رأس است که غیر همریخت با دیگر گرافهای مشابهش با n رأس است. یعنی اگر رئوس بدون نام باشند، نتوانیم با تغییر شکل یا بازچینی به گرافی دیگر برسیم.

مشخص کردن اینکه رأسهای خاص، در چه Graphletهایی (و چند بار) ظاهر میشوند.
بررسی رأسهای دیگر و مقایسه توزیع Graphletهای آنها با رأسهای خاص.
یافتن شباهت یا تفاوت در این توزیعها.
برای ساخت نمونههایی از Graphletها:
یک رأس تصادفی از میان رأسهایی که رفتارشان برای ما مهم است انتخاب میکنیم.
یکی از همسایههای این رأس را برمیداریم.
سپس یکی از همسایههای دو رأس فعلی (اتحادشان) را که هنوز انتخاب نشدهاند، انتخاب میکنیم.
این روند را تا حداکثر kk بار ادامه میدهیم (اینجا k=6k=6) تا به حداکثر اندازهی Graphlet مورد نظر برسیم.
در نهایت، یک زیرگراف القایی میسازیم (یعنی گرافی که فقط شامل رأسهای انتخابشده و یالهای بین آنهاست).
هر Graphlet تولیدشده باید به یک شناسه یکتا تبدیل شود (برای شمارش دقیق).
برای ذخیرهسازی، از یک ساختار دیکشنری یا hashmap استفاده میکنیم که شمارش تعداد تکرار هر Graphlet را نگه دارد.
در نهایت، با تقسیم تعداد تکرارها بر تعداد کل نمونهها، توزیع احتمال ظاهر شدن هر Graphlet را محاسبه میکنیم.
بزرگترین چالش اینجاست که باید مراقب باشیم گرافهای همریخت را دوبار نشماریم!
برای حل این مشکل، دو راهکار داریم:
در حالتی که محل رأس خاص برای ما اهمیت ندارد (یعنی همه رأسها یکسان فرض میشوند)،
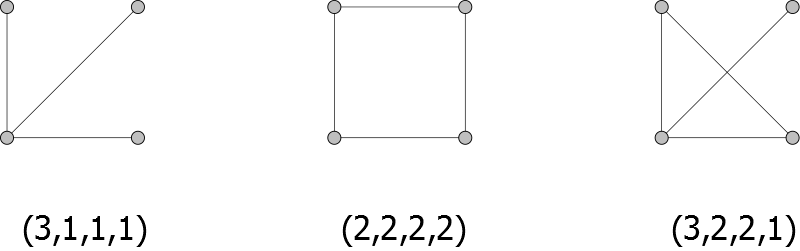
میتوانیم از بردار درجات مرتبشده رأسها بهعنوان نماینده گراف استفاده کنیم.
کافیست درجهی هر رأس را بگیریم و به صورت مرتبشده کنار هم قرار دهیم.
این بردار تا حد زیادی یکتا است و میتوان با الگوریتم Havel-Hakimi گراف متناظر با آن را نیز بازیابی کرد.
⚠️ این روش زمانی مناسب است که نخواهیم رأس خاص را دنبال کنیم. (در بیشتر مواقع این کافی نیست.)
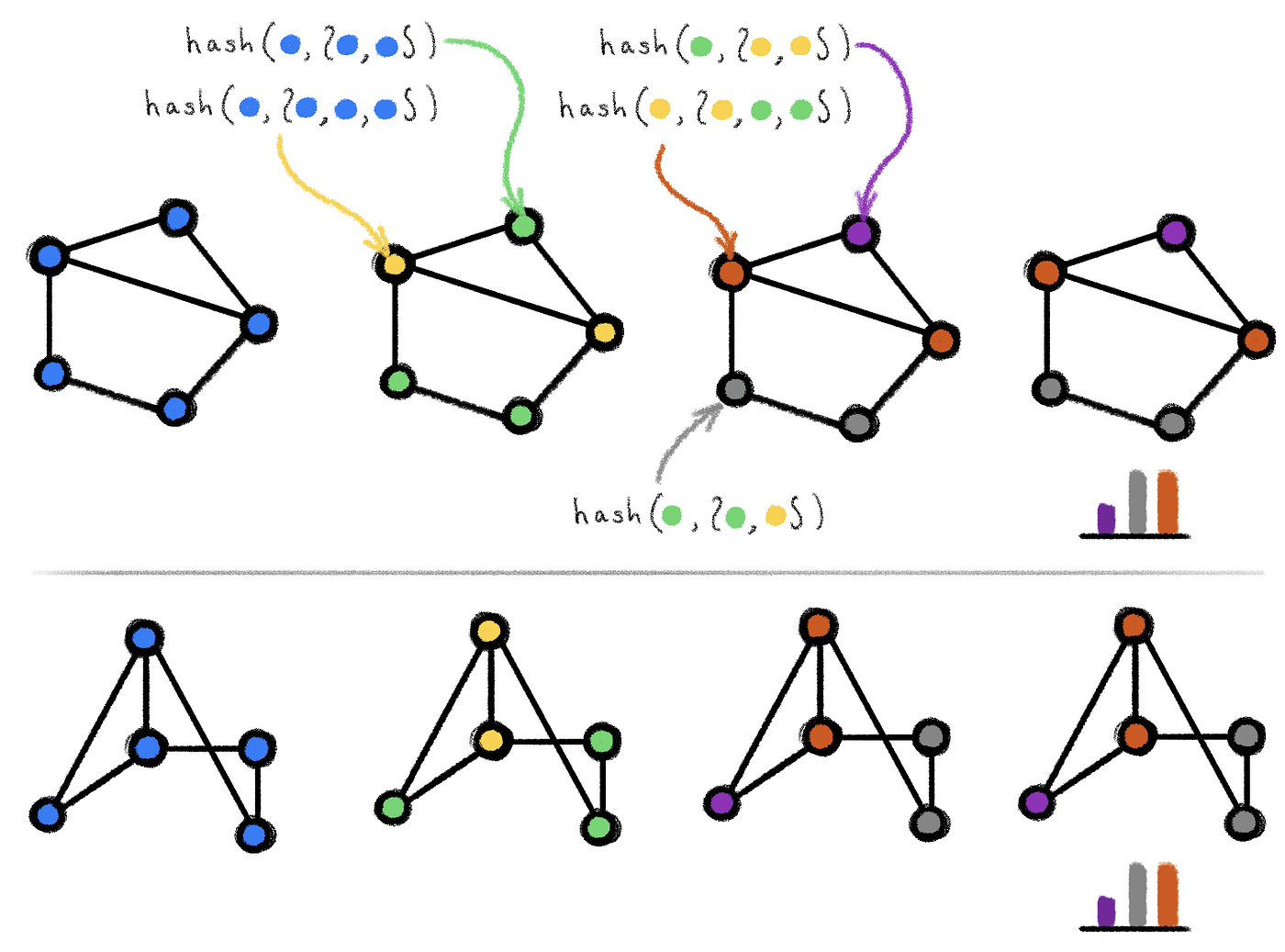
در حالتی که راس خاص اهمیت دارد و میخواهیم تقارن بین رأسها را هم بشکنیم، از الگوریتم Color-Refinement استفاده میکنیم.
به هر رأس یک رنگ اولیه نسبت داده میشود (مثلاً بر اساس خاص بودن یا نبودن).
سپس در طی چند مرحله، رنگها را بر اساس همسایهها بهروزرسانی میکنیم تا به یک امضای یکتا برای گراف برسیم.
یک آرایهی seen_colors میسازیم و تمام خانههایش را صفر میگذاریم.
به ازای هر رنگ اولیه، مقدار متناظر در seen_colors را ++ میکنیم.
الف) برای هر رأس:
لیستی از رنگ همسایههایش را بهدست میآوریم و صعودی مرتب میکنیم.
عدد رنگ خودش را به ابتدای این لیست اضافه میکنیم.
ب) یک تابع رنگساز (Aggregation Function) روی این لیست اعمال میکنیم:
اگر این لیست قبلاً رنگی داشته، همان رنگ را برمیگردانیم.
در غیر این صورت یک رنگ جدید اختصاص داده و آن را ذخیره میکنیم.
ج) برای هر رنگی که در این مرحله استفاده شده، seen_colors[color]++ انجام میدهیم.
اگر Graphletهایی با اندازهی kk در نظر داریم، کافیست الگوریتم را تا k+1k+1 بار اجرا کنیم.
از این مرحله به بعد، رنگها همگرا شدهاند و تغییری نمیکنند.
در نهایت، بردار seen_colors بهعنوان نماینده یکتای گراف استفاده میشود.
نویسنده: علی صدفی
ویراستار: ChatGPT