من این پست رو برای یک تمرین درسی نوشتم، ولی راستش موقع جمعکردنش متوجه شدم خیلی از این مفاهیم فقط «واژههای مد روز» نیستن؛ هر کدومشون جواب یه مشکل واقعی تو پروژههای نرمافزاریه.
توی این پست هدفم این نیست که وارد جزئیات عمیق بشم (چون هر کدوم میتونه یک درس یا حداقل یک فصل از یک درس باشه)، فقط میخواستم یه دید کلی و قابل گفتوگو داشته باشم؛ نه در حد حفظکردن اسمها، بلکه در حدی که بشه دربارهشون حداقل کوتاه حرف زد و ارتباطشون رو با پروژههای واقعی فهمید. برای همین اینجا سعی کردم ۲۰ مفهوم مهم در مهندسی و معماری نرمافزار رو نه خیلی تخصصی و سنگین، بلکه خلاصه و کاربردی مرور کنم.
( ایندفعه سبک نوشتهم با نوشتههای همیشگیم متفاوته و مربوط به رشتهی تخصصیم هست. 😉 و با اجازهتون من یکسری از نوشتههای قبیلم رو هم حذف کردم و شاید بعدا دوباره به اشتراکشون بذارم. )
بریم شروع کنیم:

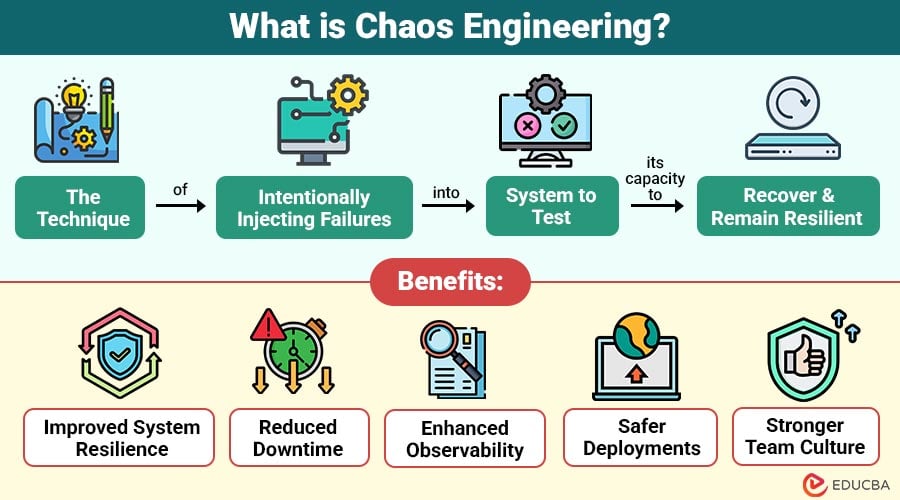
Chaos Engineering یعنی بهجای اینکه منتظر بمونیم "یک روزی، روزگاری" سیستم تو بحران کم بیاره، از اونجایی که بهترین دفاع حملهست خودمون زودتر یک کاری کنیم که کم بیاره!😌 چطوری؟
یعنی خودمون با برنامهریزی و کنترل، یه مقدار آشوب درست کنیم و ببینیم چی میشه. مثلاً عمداً یک سرویس رو قطع کنیم، یا ارتباط شبکه رو کند کنیم، یا یک نود رو از دسترس خارج کنیم؛ بعد بررسی کنیم که سیستم همچنان جواب میده یا نه.
این کار مخصوصاً تو سامانههای توزیعشده و میکروسرویسها خیلی معنی پیدا میکنه، چون شکستها معمولاً زنجیرهای هستن: یک سرویس میخوابه و چند سرویس دیگه رو هم با خودش پایین میکشه.
نکتهٔ مهم اینه که Chaos Engineering خرابکاری نیست؛ آزمایش تابآوریه. خروجیش هم میتونه مواردی مثل: منطقیتر شدن time-outها، باشه. خلاصهش اینکه: سیستم رو تو دنیای واقعیتر تست میکنیم، نه تو حالت ایدهآل. ( بالاخره از قدیم گفتن دنیای فیلم و کتاب با واقعیت خیلی فرق داره😄)
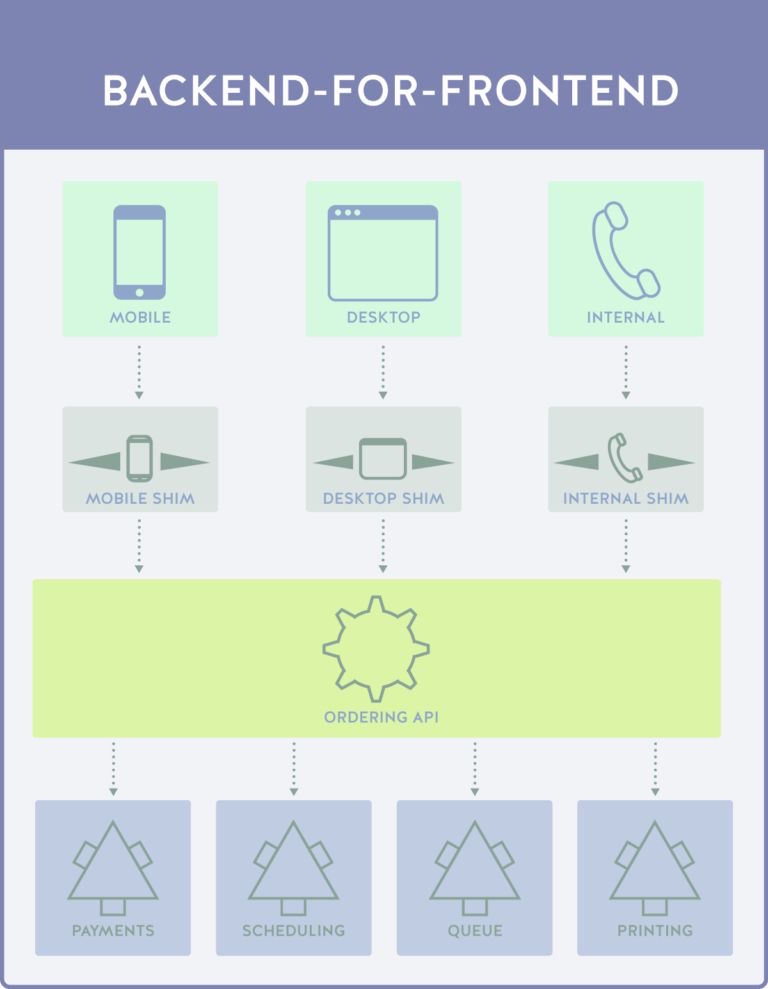
BFF یک ایده ساده ولی کاربردیه که میگه برای هر نوع فرانت (مثلاً موبایل، وب، پنل ادمین) یک backend متناسب با همون فرانت داشته باشیم. چون واقعاً نیازهای اینها یکی نیست. موبایل معمولاً دیتای خلاصهتر و سبکتر میخواد، پنل ادمین شاید جزئیات بیشتر.
اگر یک backend عمومی داشته باشیم، معمولاً یا فرانتها مجبور میشن داده اضافه بگیرن (و خودشون الکی پردازش کنن)، یا backend پر از شرط و if میشه که برای هر کلاینت یک مدل بده، ولی BFF این شلوغی رو جمعوجور میکنه.
البته اینم بگم که باید دقت کنیم که زیادهروی نکنیم. مثلا اگر هر تیم برای خودش بدون هماهنگی یک BFF بسازه، نگهداری سخت میشه. ولی وقتی واقعاً چند نوع کلاینت با نیاز جدی متفاوت داریم، BFF کمک میکنه APIها تمیزتر و تجربهٔ توسعه بهتر بشه.
AI4SE یعنی هوش مصنوعی به کمک مهندسی نرمافزار بیاد.
حالا تو چه چیزهایی؟ چیزهایی مثل تولید کد، پیشنهاد تست، تحلیل لاگ، پیدا کردن الگوهای باگ، یا حتی کمک به مستندسازی. چیزی شبیه یک دستیار که کارهای تکراری رو سبک میکنه.
و این درسته که ابزارهای AI میتونن سرعت رو زیاد کنن، اما اگر بیدقت استفاده بشن، کیفیت رو هم میتونن پایین بیارن. مثلاً ممکنه کدی پیشنهاد بدن که از نظر امنیتی مشکل داشته باشه یا با استانداردهای پروژه نخونه.
به نظرم استفادهٔ درست از AI4SE اینطوریه که بهعنوان ابزار کمککار نگاهش کنیم، نه بخشی که مسئولیت میپذیره. یعنی خروجیها باید بازبینی بشن، تست بشن و با فهم دامنه تطبیق داده بشن. تو پروژهٔ واقعی، ارزش AI وقتی بیشتره که کنار مهندس خوب قرار بگیره؛ نه وقتی قرار باشه جای خود مهندسی رو پر کنه.
تو بخش قبلی AI به کمک SE اومد. اما خب چطوری باید اون هوش مصنوعی ساخته بشه که حالا بعدش بتونه به کمک بیاد؟!🤔
این بخش همین سوال رو جواب میده. SE4AI یعنی مهندسی نرمافزار برای ساخت سیستمهای هوش مصنوعی. فرق اصلیاش با نرمافزار سنتی اینه که فقط با کد طرف نیستیم؛ داده، مدل، آموزش، ارزیابی، استقرار و پایش هم بخشی از محصول هستن.
مثلاً یک مدل ممکنه تو آزمایشگاه عالی باشه، ولی بعد از استقرار، بهخاطر تغییر رفتار کاربران یا تغییر دادههای ورودی، کمکم کیفیتش بیاد پایین. این یعنی ما باید چرخهٔ عمر مدل رو هم مدیریت کنیم: نسخهبندی داده و مدل، تست، مانیتورینگ drift، و برنامه برای retrain.
SE4AI یادآوری میکنه سیستم AI هم باید مثل هر نرمافزار جدی، قابل نگهداری و قابل اعتماد طراحی بشه. اگر این نگاه نباشه، پروژهها معمولاً بعد از دموی اولیه گیر میکنن مثلا یک مدل داریم که روی لپتاپ خوبه، ولی در محصول واقعی پایدار نیست.
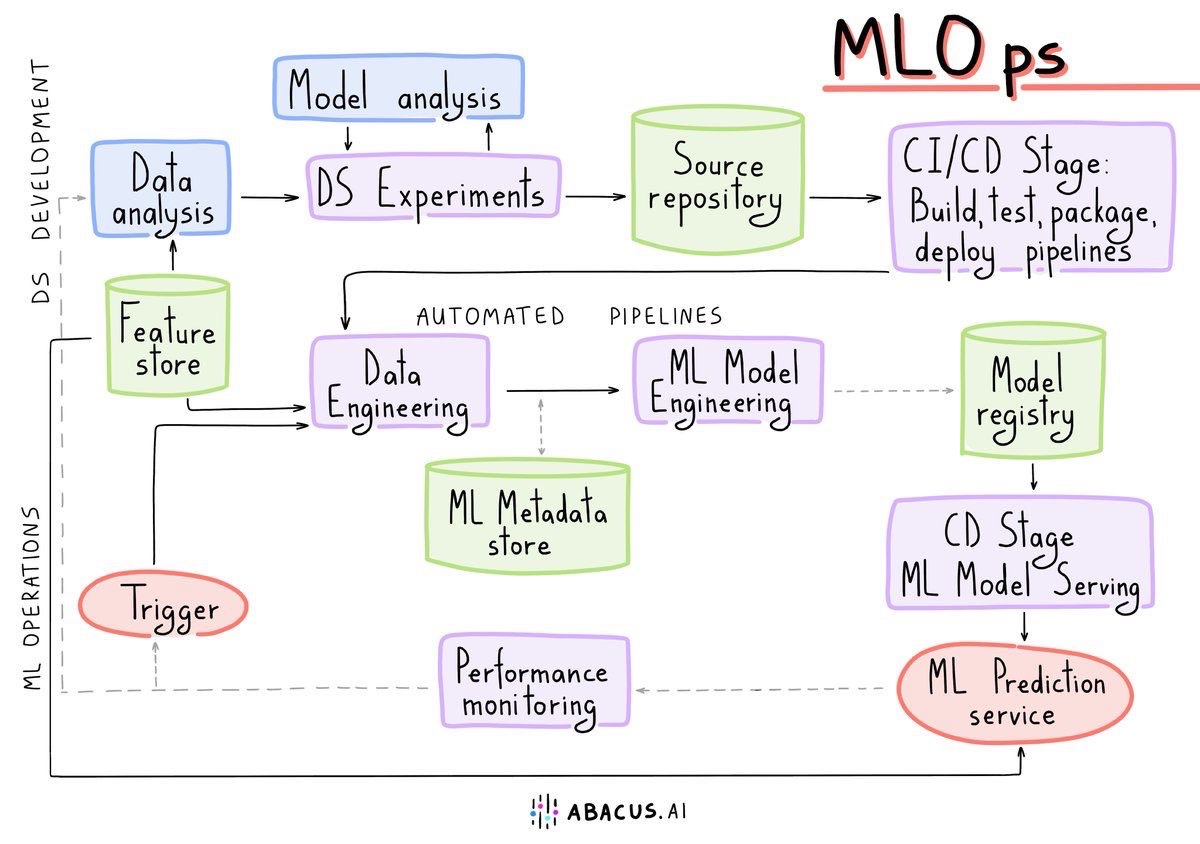
MLOps رو میشه نسخهٔ عملیاتی یادگیری ماشین دونست؛ همون چیزی که میگه ساخت مدل پایان کار نیست، اتفاقاً تازه شروع چالشهاست. ( که مدل آسان نمود اول ولی افتاد مشکلها😭)
در پروژهٔ ML باید مشخص باشه داده از کجا میاد، چطور تمیز میشه، مدل چطور آموزش میبینه، چطور ارزیابی میشه، کِی مستقر میشه و بعد از استقرار چطور پایش میشه. اگر این مسیر اتومات و قابل تکرار نباشه، خیلی راحت میرسیم به وضعیتی مثل: «این مدل روی سیستم من کار میکرد!» ( یادش به خیر توی کارشناسی وقتی کد رو مینوشتیم ولی کار نمیکرد و روز تحویل پروژه هم قصد از تک و تو افتادن نداشتیم، از این جمله زیاد استفاده میکردیم🫠 کد رو سیستم من کار کرد میکرد!😌)
خب از خاطرات کارشناسی من بگذریم، میخواستم این رو بگم که MLOps کمک میکنه pipeline داشته باشیم، یعنی: آموزش، تست، استقرار، مانیتورینگ، و در صورت نیاز retrain. از نظر من نقطهٔ طلایی MLOps جاییه که تیم بتونه تغییرات داده و مدل رو مثل تغییرات کد مدیریت کنه.
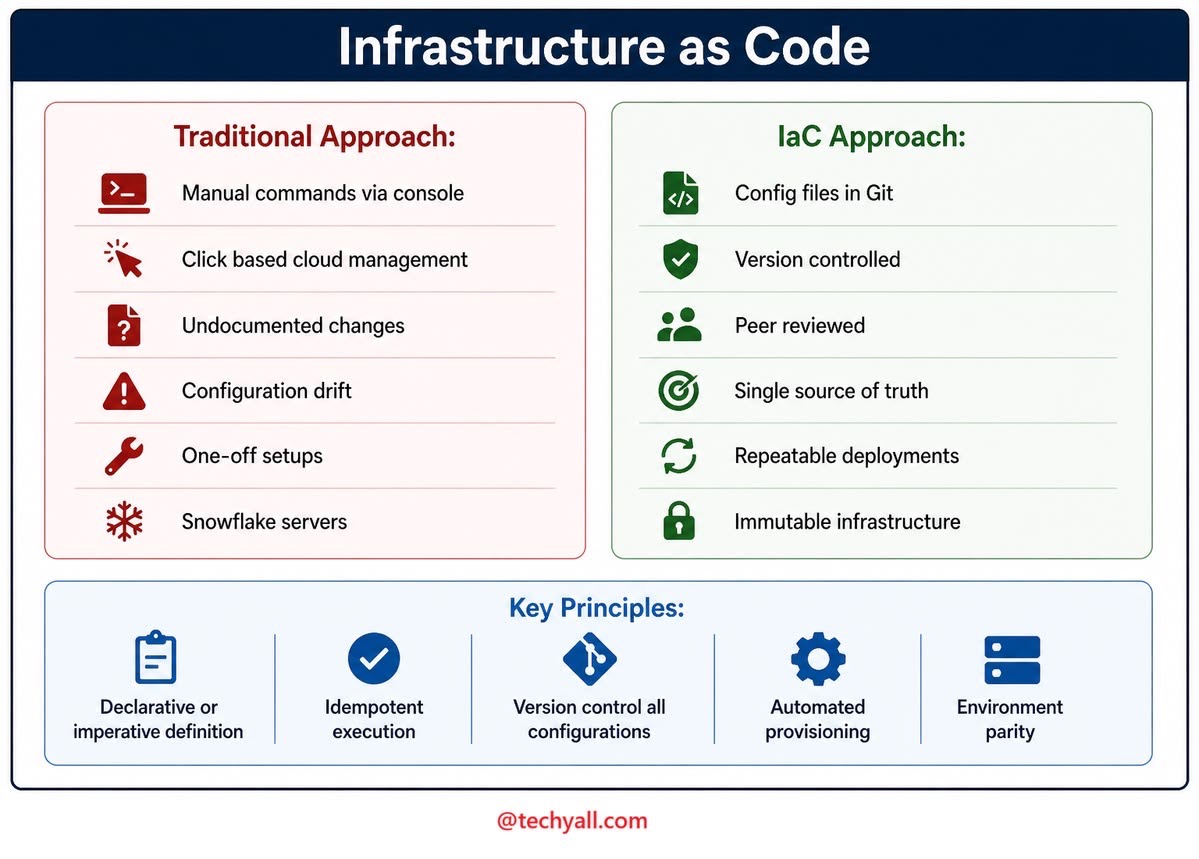
IaC میگه که زیرساخت رو مثل کد مدیریت کنیم. یعنی بهجای اینکه دستی سرور بسازیم، پورت باز کنیم، یا تنظیمات شبکه و منابع ابری رو یکییکی انجام بدیم، همه چیز رو با فایل و کد تعریف میکنیم.
اهمیتش چیه؟ روشنه: تکرارپذیری. اگر امروز یک محیط staging ساختیم، فردا هم میتونیم همون رو بسازیم، بدون اینکه ده تا تنظیم رو یادمون بره. بهعلاوه چون کد در repo میاد، تغییرات قابل بازبینی میشن و تاریخچه هم داریم.
تو دنیای DevOps و کلاد، IaC عملاً تبدیل به یک پایهٔ جدی شده و ابزارهایی مثل Terraform هم برای همین معروف شدن.
اینطوری بگم که IaC کمک میکنه زیرساخت از "کار دستی و پراکنده" تبدیل بشه به "فرایند مهندسیشده" و این موضوع در پروژههای واقعی خیلی فرق ایجاد میکنه.
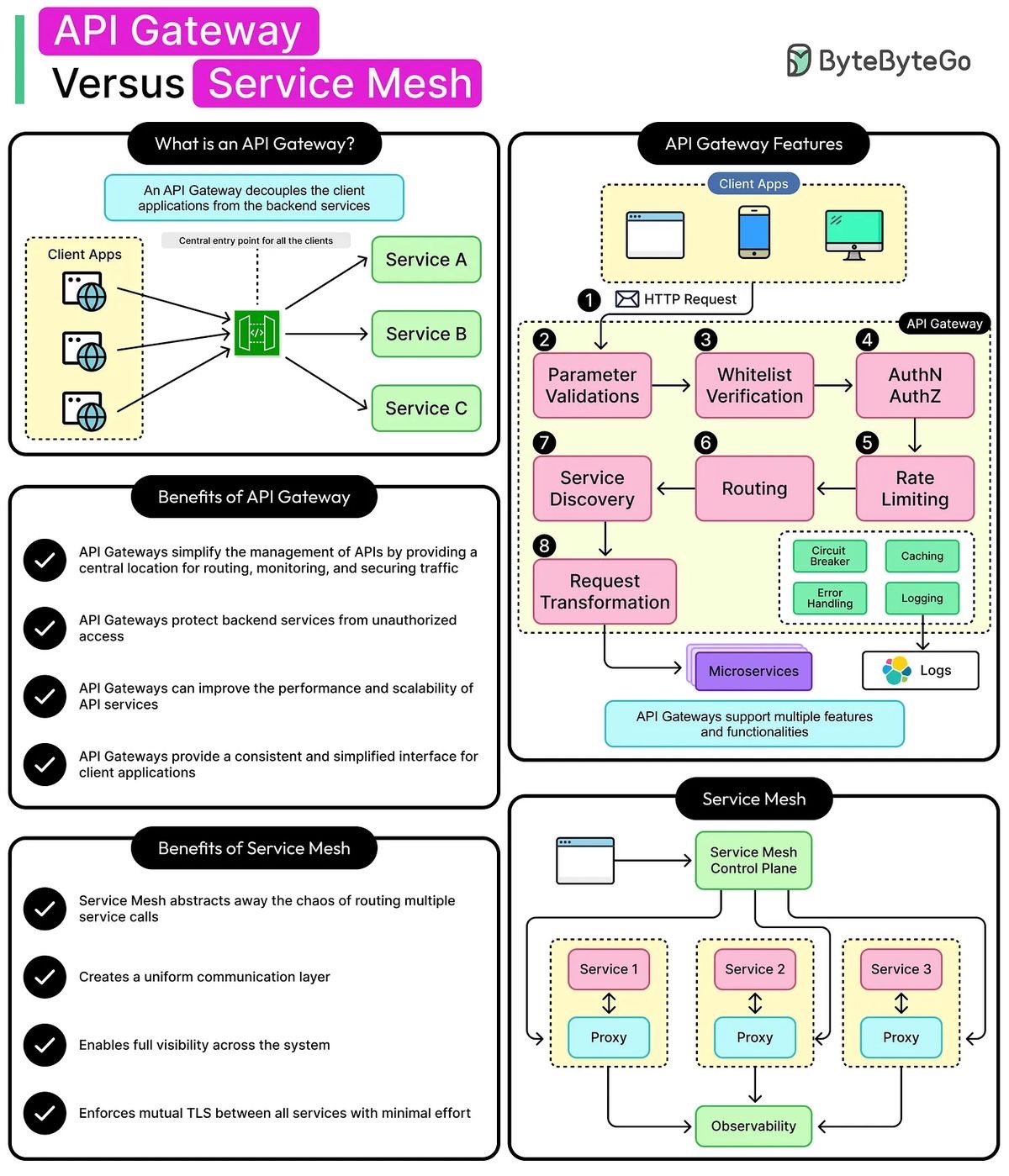
اگر سیستم رو مثل یک مکانی تصور کنیم که یک در داره، API Gateway معمولاً جلوی درِ سیستم میایسته. یعنی درخواستهای بیرونی اول از gateway رد میشن و اونجا کارهایی مثل احراز هویت، rate limiting، مسیریابی و حتی یکپارچهسازی پاسخ انجام میشه.
در مقابل Service Mesh بیشتر داخل سیستم معنی داره؛ جایی که سرویسها با هم حرف میزنن. تو میکروسرویسها، ارتباطات داخلی زیاد میشه و اگر هر سرویس خودش بخواد retry، timeout، TLS، observability و… رو پیاده کنه، کدها شلوغ و ناهماهنگ میشن، پس مش میاد که اینها رو یکدست کنه.
اگر بخوام کوتاه بگم: gateway برای ترافیک ورودی از بیرونه، mesh برای ترافیک بین سرویسهای داخله. البته اینم بگم اگه سیستم ساده باشه، ممکنه فقط پیچیدگی رو اضافه کنن. ولی در مقیاس بزرگ، جلوی خیلی دردسرها رو میگیرن.
CQRS میگه کار "نوشتن" و "خوندن" داده رو از هم جدا کنیم. یعنی بخش command مسئول تغییر وضعیت باشه (با قوانین کسبوکار و اعتبارسنجی)، و بخش query برای خوندن و نمایش دادهها بهینه بشه.
این جداسازی وقتی جذاب میشه که نیازهای خوندن و نوشتن واقعاً متفاوت باشن. مثلاً یک سیستم که گزارشگیری سنگین داره ولی نوشتنهاش کمتره؛ یا برعکس، ثبتهای زیاد داره ولی query ساده.
مشکلی که CQRS داره اینه که اگر بیدلیل بیاد وسط، پروژه رو پیچیده میکنه و مثل یک ابزار تخصصی هست که باید درست استفاده بشه؛ این ابزار وقتی مسئله واقعاً بزرگ و چندلایه شد، ارزشش معلوم میشه. برای پروژههای کوچیکتر معمولاً همون مدل یکپارچه کافیه.
معماری رویدادمحور یعنی سیستم رو بر اساس رخدادها بچینیم. هر وقت چیز مهمی رخ داد، یک event منتشر میشه و هر سرویس که لازم داره، واکنش نشون میده.
اگر بخوام مثال بزنم اینطوری فرض کنید که در یک فروشگاه آنلاین، "ثبت سفارش" یک رویداده. بعد سرویس پرداخت، انبار و ارسال میتونن هر کدوم جداگانه براساس اون event کار خودشون رو انجام بدن. جنبه مثبتش اینه که سرویسها کمتر به هم گره میخورن و هر کدوم مستقلتر رشد میکنه.
ولی چالش EDA معمولاً در ردیابی و دیباگ خودشو نشون میده. چون جریان کار پخش میشه و اگر observability درست نباشه، پیدا کردن اینکه "کجا مشکل هست" سخت میشه. با این حال، برای سیستمهایی که رشد میکنن و نیاز به اتصال نرم بین سرویسها دارن، EDA یکی از انتخابهای جدی و رایجه.
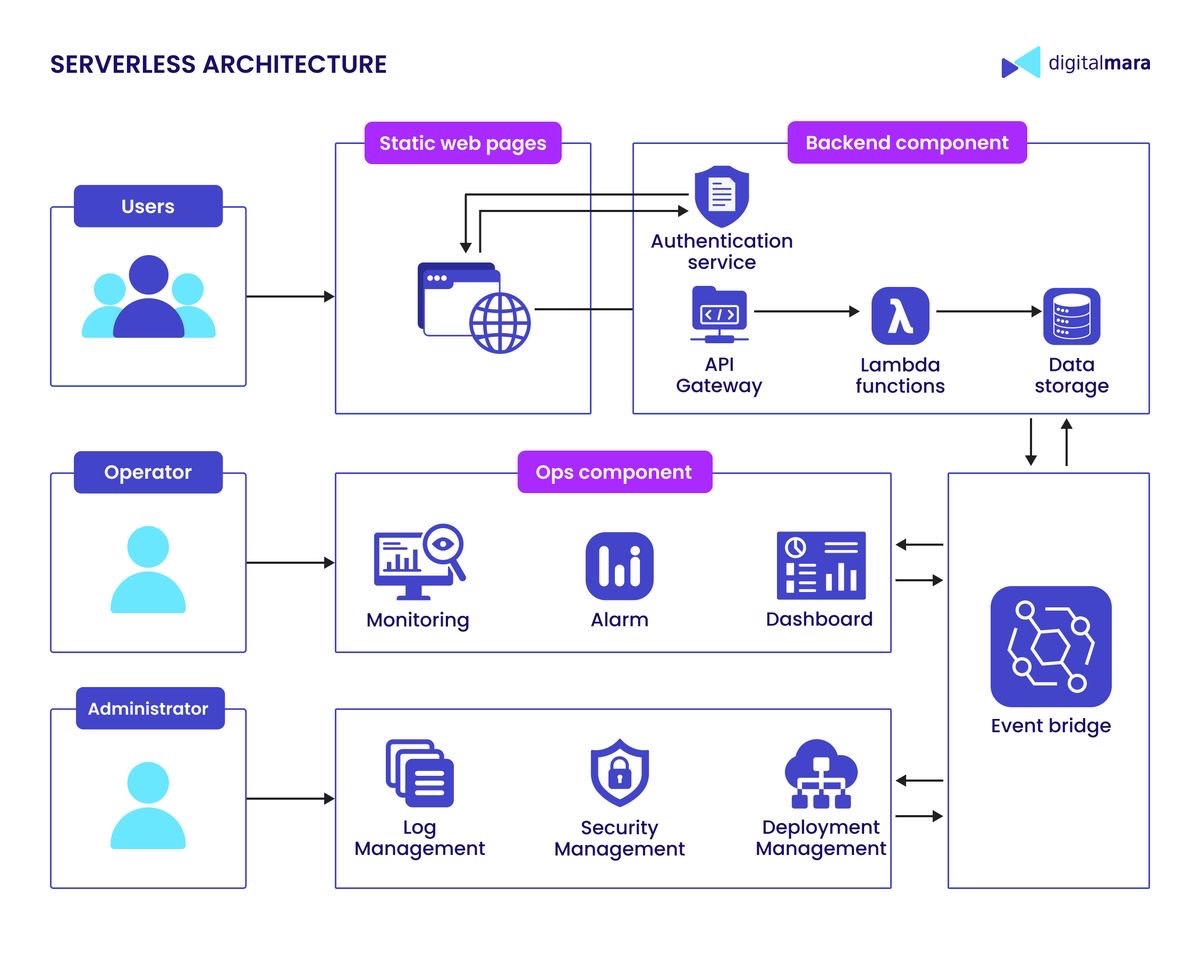
Serverless یعنی کمتر درگیر سرور شو. نه اینکه سرور وجود نداره؛ وجود داره، ولی مدیریت و مقیاسدهیاش عمدتاً با ارائهدهندهٔ کلاد انجام میشه. معمولاً هم با توابع یا سرویسهایی که با رویداد فعال میشن سروکار داریم.
خوبی Serverless اینه که سریع راه میافته و برای بارهای متغیر میتونه اقتصادی باشه؛ چون هزینه بر اساس استفاده محاسبه میشه. اما خب محدودیت هم داره، مثلا اینکه زمان اجرای هر تابع محدود میشه، و گاهی هم lock-in نسبت به پلتفرم ایجاد میشه.
من Serverless رو اینطور میبینم که اگر مسئلهات رویدادمحوره، یا سرویسهای کوچیک و مستقل میخوای، عالیه. اما اگر پردازش سنگین و پیوسته داری، باید حسابی شیش و بش کنی که واقعاً بهصرفه و مناسب هست یا نه.
API-first یعنی اول قرارداد رو ببندیم، بعد بریم سراغ پیادهسازی. یعنی مشخص کنیم endpointها چی هستن، ورودی/خروجیها چیه، خطاها چطور برمیگردن، و نسخهبندی چطور انجام میشه.
این نگاه چند تا فایده داره: فرانتاند میتونه همزمان کار کنه، تستها میتونن زودتر نوشته بشن، و تیمها کمتر وسط راه برداشتهای متفاوت پیدا میکنن.
ابزارهایی مثل OpenAPI کمک میکنن این قرارداد دقیق و قابل استفاده باشه. به نظرم API-first یک جور نظم فکری هم هست و بهجای اینکه API آخر کار و با عجله دربیاد، از اول به عنوان ستون ارتباطی سیستم جدی گرفته میشه.
تو پروژههای واقعی، خیلی وقتها اختلافها و دوبارهکاریها دقیقاً از همینجا شروع میشن که API درست تعریف نشده یا دیر تعریف شده.
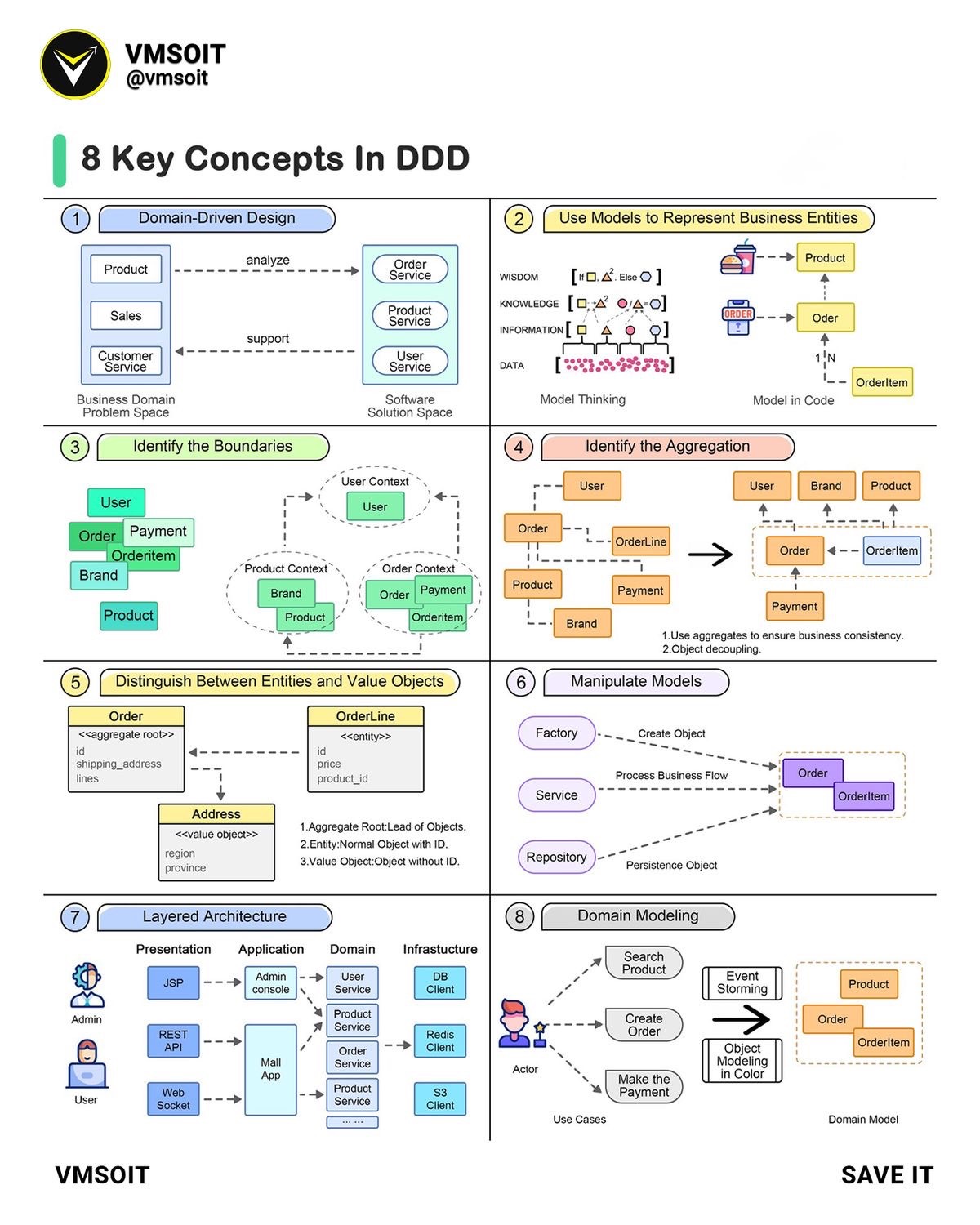
DDD به زبان ساده میگه: نرمافزار رو حول "دامنهٔ واقعی کسبوکار" طراحی کن، نه حول دیتابیس یا تکنولوژی. یعنی اول ببین مسئله چی هست، بازیگرهاش کی هستن، مفاهیم اصلی چی هستن، بعد براساس اونها مدل بساز.
یکی از نقاط قوت DDD اینه که تیم فنی و تیم کسبوکار رو مجبور میکنه یک زبان مشترک داشته باشن، این موضوع در پروژههای پیچیده، جلوی سوءتفاهمهای گرونقیمت رو میگیره.
DDD البته برای هر پروژهای هم لازم نیست. اگر مسئله سادهست، ممکنه سربار بده. ولی برای سیستمهایی که قوانین کسبوکار زیاد دارن و قرار نیست مثلا تو دو ماه جمع بشن، DDD کمک میکنه معماری معنیدار داشته باشیم؛ معماریای که با رشد پروژه، کمتر فرو میریزه.
Hexagonal Architecture میخواد هستهٔ برنامه رو از دنیای بیرون جدا کنه. یعنی منطق اصلی سیستم نباید به دیتابیس، فریمورک، UI یا سرویسهای بیرونی گره بخوره. ( بندهخدا آقای مارتین توی کتاب Clean Architecture فصل به فصل روی این موضوع تاکید میکنه😊)
ایدهٔ پورت و آداپتور از همینجا میاد. یعنی هسته فقط "پورت" تعریف میکنه (چه چیزی لازم دارم)، و بیرونش آداپتور مینویسیم (چطور تأمینش میکنم). اگر امروز دیتابیس PostgreSQL هست، فردا ممکنه عوض شه؛ هسته نباید بیدی باشه که با این بادها بلرزه.🍃🌪
این معماری برای تست هم خیلی خوبه، چون میتونیم آداپتورهای فیک بسازیم و منطق اصلی رو مستقل تست کنیم.
من برداشت شخصیام اینه که Hexagonal بیشتر از هر چیز یک یادآوریه که اصل برنامه باید مستقل بمونه. تکنولوژیها میآن و میرن، ولی منطق دامنه اگر تمیز طراحی بشه، عمر بیشتری میکنه.

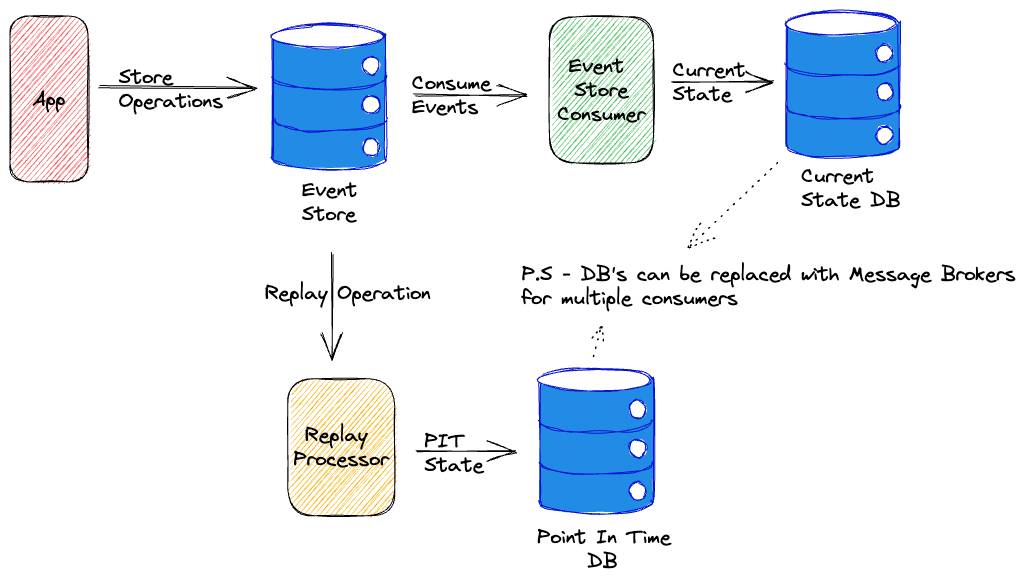
Event Sourcing میگه بهجای اینکه فقط وضعیت نهایی رو ذخیره کنیم، رویدادهایی که اون وضعیت رو ساختن هم ذخیره بشن.
مثلاً بهجای اینکه فقط بگیم موجودی حساب الآن ۵ میلیون است، رویدادهای واریز و برداشت رو نگه داریم. اینطوری هم تاریخچه داریم، هم اگر بخوایم میتونیم وضعیت رو دوباره از روی رویدادها بسازیم.
مزیت بزرگش برای سیستمهایی مثل مالی، حسابرسی، یا هر چیزی که در اون "ردپا" مهمه مشخص میشه. چون دقیق متوجه میشیم چه اتفاقی چه زمانی افتاده.
اما خب هزینه هم داره مثلا اینکه طراحی رویدادها باید دقیق باشه، تعداد رویدادها زیاد میشه، replay و snapshot وارد ماجرا میشن و پیچیدگی بالا میره.
بنابراین من Event Sourcing رو برای جاهایی منطقی میدونم که تاریخچه خودش ارزشه، نه فقط یک امکان اضافی.
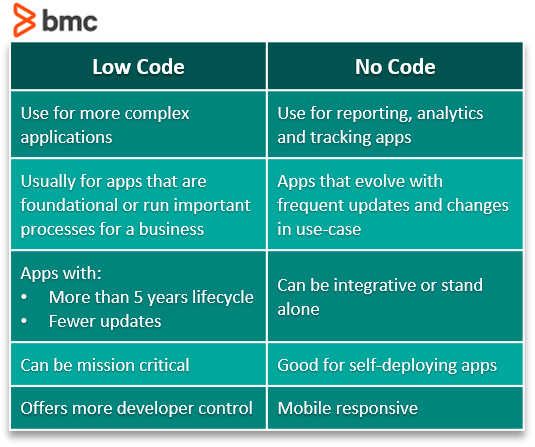
Low-code و No-code شاید چوب جادویی پری داستان سیندرلا نباشن و تو یک ثانیه همه چیز رو زیر و رو کنن، ✨️🪄ولی واقعاً میتونن سرعت رو بالا ببرن، مخصوصاً برای نیازهای داخلی سازمان، فرمها، اتوماسیونهای ساده، یا داشبوردها.
در Low-code هنوز کمی کدنویسی داریم، ولی در No-code هدف اینه که حتی آدم غیر فنی هم بتونه یک خروجی قابل استفاده بسازه.
مزیت اصلیش هم زمان هست. خیلی کارها که قبلاً باید یک تیم توسعه انجام میداد، اینجا سریعتر راه میافته.
ولی خب محدودیت هم داریم. اونم اینکه: اگر پروژه خیلی خاص، پیچیده یا نیازمند کنترل دقیق امنیت/کارایی باشه، ممکنه پلتفرم دست و پات رو ببنده.
جمعبندی من اینه که Low/No-code برای حل سریع یک نیاز مشخص عالیه، ولی برای ساخت محصول پیچیده و قابل گسترش باید با احتیاط واردش شد و از اول محدودیتها رو پذیرفت.
BPMS یعنی سیستمهایی که کمک میکنن فرایندهای کسبوکار رو مدل کنیم، اجرا کنیم، پایش کنیم و بهترش کنیم.
تو سازمانها معمولاً کارها مرحلهای هستن: ثبت درخواست، بررسی، تأیید، ارجاع، انجام، بستن. اگر اینها فقط تو ذهن آدمها یا تو پیامهای پراکنده باشه، هم کند میشه، هم پیگیریشون سخته. پس BPMS میاد این جریان رو استاندارد میکنه و BPMN هم یکی از استانداردهای رایج برای مدلسازی همین فرایندهاست.
مزیتش اینه که یک نقشهٔ قابل مشاهده از کارها میده مثل اینکه معلومه الآن درخواست کجاست و گلوگاه کجاست. البته پیادهسازی BPMS اگر بدون درک درست فرایند انجام بشه، فقط بوروکراسی دیجیتال تولید میکنه. ولی اگر درست استفاده بشه، هم شفافیت میده هم قابلیت بهینهسازی.
Message Queue برای وقتی خوبه که نمیخوایم سرویسها به شکل مستقیم و همزمان همدیگه رو صدا بزنن. پیام میره تو صف، و سرویس مصرفکننده هر وقت آماده بود برمیداره و پردازش میکنه.
این کار چند تا نتیجهٔ خوب داره: فشار ترافیک پخش میشه، سیستم مقاومتر میشه، و سرویسها کمتر به هم وابسته میشن.
Kafka معمولاً برای سناریوهای event streaming و حجم بالا خیلی معروفه (و اینکه eventها قابل نگهداری و replay هستن). RabbitMQ بیشتر تو پیامرسانی صفمحور سنتی، routing و الگوهای انعطافپذیر پیام محبوبه.
البته صف پیام هم دردسرهای خودش رو داره مثل پیام تکراری، ترتیب پیامها، retry، و مدیریت خطا. ولی در سیستمهای واقعی، همین صفها خیلی وقتها ناجی سیستم میشن، مخصوصاً وقتی بار نوسانی داریم یا نمیخوایم یک سرویس کند کل سیستم رو کند کنه.
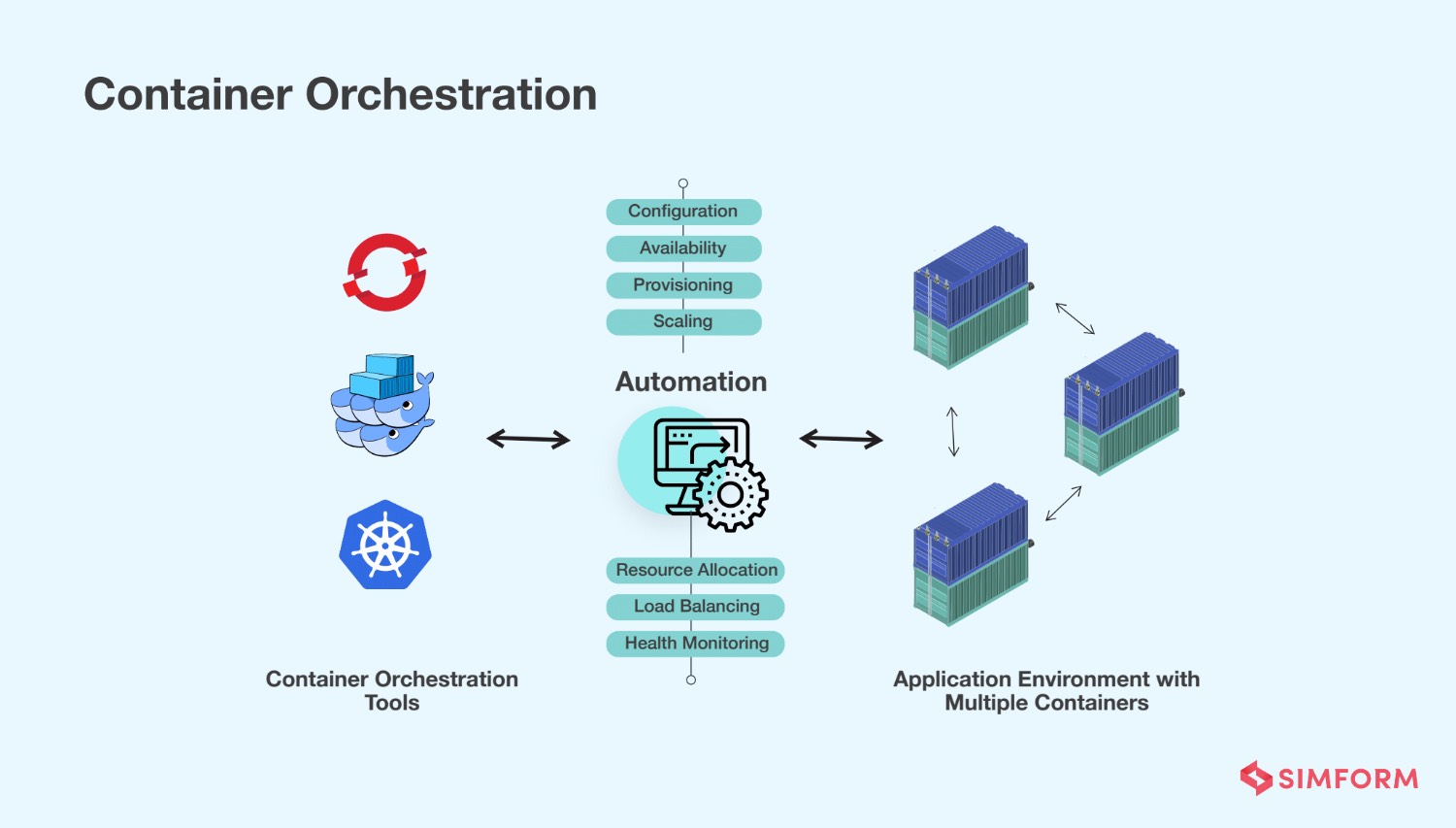
کانتینر یعنی برنامه رو با وابستگیهاش بستهبندی کنیم تا هر جا اجرا شد، تقریباً همون رفتار رو داشته باشه. Docker اینجا خیلی معروفه و خیلی از مشکلهای "روی سیستم من کار میکرد" رو کمتر میکنه.
حالا اگر تعداد کانتینرها زیاد شد، تازه داستان مدیریت شروع میشه مواردی مثل کجا اجرا بشن؟ اگر یکی افتاد چی؟ چطور مقیاس بدیم؟ آپدیت بدون downtime چطور؟
اینجاست که Kubernetes وارد میشه و نقش orchestrator رو بازی میکنه: استقرار، مقیاسدهی، self-healing rolling update و… .
به نظرم Docker و Kubernetes برای تیمهایی که سیستمشون رو به سمت مقیاس و پایداری میبرن ابزارهای خیلی مهمیان، ولی یک نکته مهم هم دارن: اگر پروژه کوچک باشه، ممکنه overhead زیادی ایجاد کنن. یعنی باید واقعاً ببینیم نیاز داریم یا فقط برای اینکه از قافله عقب نمونیم طبق مد روز جلو میریم!
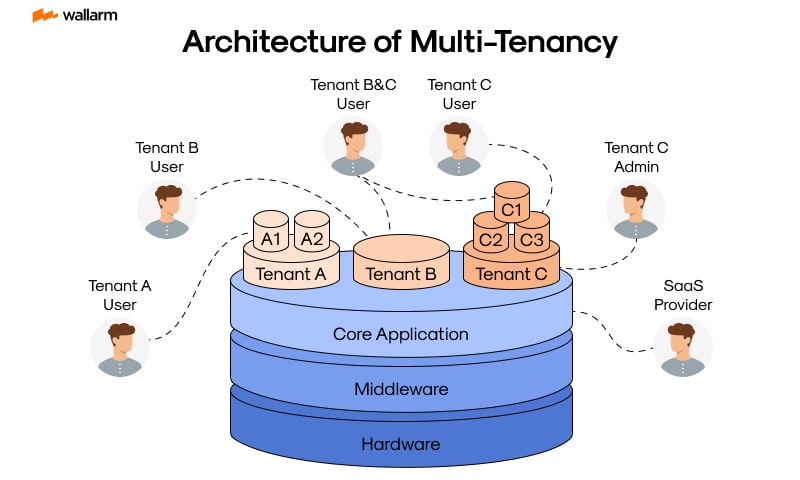
Multi-Tenancy یعنی یک نرمافزار واحد به چند مشتری/سازمان خدمت بده، اما دادهها و تنظیمات هر کدوم جدا بمونه. این الگو تو SaaS خیلی رایجه.
اما سؤال اصلی اینجاست: جداسازی چقدر باشه؟ بعضیها برای هر tenant دیتابیس جدا میدن، بعضیها schema جدا، بعضیها هم همه رو تو یک دیتابیس نگه میدارن ولی با کلید tenant جدا میکنن. هر کدوم مزایا و هزینههای خودش رو داره.
مزیت واضحش کاهش هزینه و سادهتر شدن نگهداریه؛ چون یک محصول داریم نه ده تا.
ولی حساسیت امنیتی بالا میره. نشت اطلاعات بین tenantها فاجعه است. علاوه بر اون، باید مراقب باشیم یک tenant پرمصرف باعث افت سرویس برای بقیه نشه.
به نظرم Multi-Tenancy جایی موفقه که از اول طراحیاش جدی گرفته بشه، نه اینکه وسط راه تصمیم بگیریم حالا چند مشتری همزمان بیاریم روی همین سیستم.
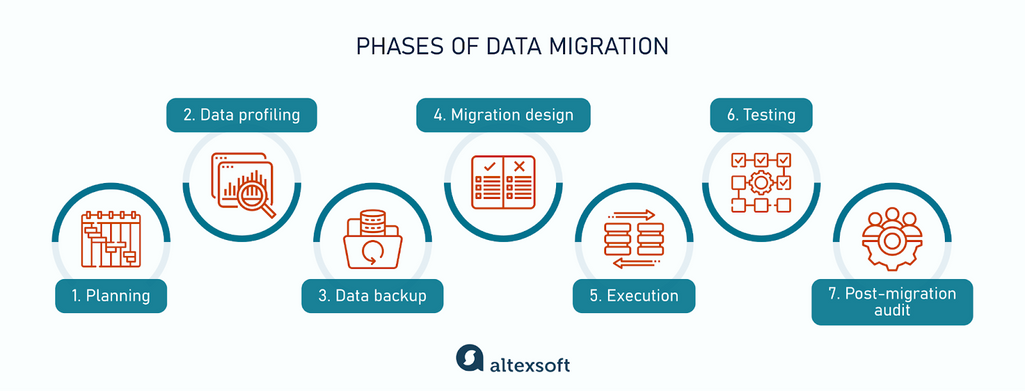
Data Migration معمولاً وقتی میاد وسط که داریم سیستم رو عوض میکنیم مثل تغییر دیتابیس، رفتن به کلاد، ادغام دو سامانه، یا جایگزینی یک نرمافزار جدید.
مهاجرت داده فقط کپی کردن نیست. معمولاً باید دادهها تمیز بشن، تبدیل ساختار انجام بشه، دادههای تکراری یا خراب مدیریت بشن و بعد از انتقال هم validation جدی داشته باشیم. حتی خیلی وقتها باید برنامهٔ rollback داشته باشیم که اگر چیزی خراب شد، برگردیم عقب.
چالش اصلی اینه که داده سرمایه است. اگر اشتباه منتقل بشه، ممکنه سیستم جدید از همون روز اول بیاعتماد بشه.
من این بخش رو یکی از حساسترین قسمتهای پروژه میدونم، چون ممکنه تو ظاهر کار فنیِ حاشیهای به نظر بیاد، اما اگر خراب انجام بشه اثرش روی کسبوکار مستقیمه: گزارشها غلط میشن، سابقهها میپرن، یا تصمیمها بر اساس دادهٔ اشتباه گرفته میشن.
این ۲۰ مفهوم رو اگر بخوام در یک جمله جمع کنم: همهشون دارن کمک میکنن سیستمها «در دنیای واقعی» بهتر دووم بیارن؛ چه از نظر مقیاس، چه پایداری، چه سرعت تغییر، چه مدیریت پیچیدگی.
برای من مرور این مفاهیم یک پیام واضح داشت اونم اینکه: معماری و مهندسی نرمافزار فقط انتخاب تکنولوژی نیست؛ بیشتر هنر تصمیمگرفتن در برابر محدودیتهاست.
اگر بعداً بخوام عمیقتر ادامه بدم، احتمالاً چند تا موضوع مثل DDD، EDA، CQRS و MLOps رو انتخاب میکنم و با مثالهای واقعیتر و مطالعهٔ case-study جلو میرم، چون اینها تو پروژههای بزرگ خیلی پررنگتر میشن.
من تا امروز نوشتههای مختلفی رو تو شبکههای اجتماعیم به اشتراک گذاشتم و میذارم، اما این اولین بار بود که متنی مرتبط با حوزهٔ تخصصی خودم را بهصورت عمومی منتشر میکنم. برای همین، این نوشته برای من یک تجربه تازه و ارزشمند بود و امیدوارم برای شما هم مفید و خوندنی بوده باشه.
در پایان، لازم میدونم از استاد عزیزم دکتر صادق علیاکبری، از اساتید گروه نرمافزار دانشکده مهندسی کامپیوتر دانشگاه شهید بهشتی، تشکر کنم که باعث شدن این مدل نوشتن رو هم تجربه کنم.
در این نوشته سعی کردم برداشت کوتاه و شخصی خودم رو از هر کدوم از این مفاهیم بنویسم و در ادامه هم بخشی از منابعی رو که برای جمعآوری اطلاعات ازشون استفاده کردم، آوردم.
ممنونم از وقتی که برای خوندن این مطلب گذاشتید.
تنتون سالم و دلتون گرم و آروم🧡
منابع:
- Martin Fowler, *Architecture & Enterprise Patterns*: https://martinfowler.com/
- Microsoft Learn, Architecture Patterns and Guides: https://learn.microsoft.com/
- Principles of Chaos Engineering: https://principlesofchaos.org/
- Google Cloud, MLOps Overview: https://cloud.google.com/architecture/mlops-continuous-delivery-and-automation-pipelines-in-machine-learning
- Istio Documentation: https://istio.io/latest/docs/
- OpenAPI Initiative: https://www.openapis.org/
- Alistair Cockburn, Hexagonal Architecture: https://alistair.cockburn.us/hexagonal-architecture/
- Apache Kafka Documentation: https://kafka.apache.org/documentation/
- RabbitMQ Documentation: https://www.rabbitmq.com/documentation.html
- Docker Documentation: https://docs.docker.com/
- Kubernetes Documentation: https://kubernetes.io/docs/
- OMG BPMN Standard: https://www.omg.org/spec/BPMN/
- AWS Serverless: https://docs.aws.amazon.com/serverless/
- Microsoft Data Migration: https://learn.microsoft.com/en-us/data-migration/
- Open AI : https://openai.com/
- Claude :https://claude.com/