حرف دلی با خواننده: ابتدا ایده تحلیل متن و پیدا کردن ساختار رابطه ای بین جملات و گفتگو ها در ذهنم درخشید و با جستجو در بین کتاب های مورد علاقه خود به سه کتاب یکی بینوایان، یکی شاهنامه و دیگری قرآن مجید.
اما چه شد که قرآن را انتخاب کردم؟
ساده ترین دلیل این است که کارهای انجام شده درباره قرآن بسیار زیاد است. و فرصت مقایسه با Ground truth آماده تر.
دشواری هایی هم داشت. که یکی از آن ها در دسترس نبودن برخی از منابع، نبودن روش های پردازش زبان عربی آزاد و ...
نتیجه کار از نتیجه مورد علاقه من بسیار فاصله دارد و در همین ابتدا میگویم که شما هم مثل من از این خروجی ها ناامید خواهید شد.
نویسنده: محمدجواد محسنیان
این مقاله به بررسی روابط بین آیات قرآن (جملات کتب) با استفاده از علم شبکههای پیچیده میپردازد. نویسنده با بهرهگیری از روشهای مختلف پردازش زبان طبیعی، از جمله تحلیل ترجمه انگلیسی قرآن و استخراج ریشه کلمات عربی، سعی در کشف ساختارهای ارتباطی میان آیات دارد. هدف این مطالعه، ایجاد شبکهای از آیات و تحلیل آن برای درک بهتر مفاهیم و ارتباطات درونمتنی قرآن است. نتایج اولیه نشاندهنده وجود الگوهای پیچیده و روابط معنادار بین آیات است که میتواند به پژوهشهای آینده در زمینه تحلیل متن کتب کمک کند.
با پیشرفت فناوری، هر روز کشفیات جالب و جدیدی انجام میشود و این کشفیات افکار ما را روشن میکند. ما درجستجوی کشف روابط جدید به کتابی مراجعه کردیم که تاکنون ارزش علمی و معنوی خود را بارها اثبات کرده است. یکی از منابع گرانبهای دانش، قرآن کریم است که با حکمت عمیق و نور پاک خود، بشریت را هدایت میکند. وابزار ما که یکی از پیشرفتهای زیبا و عمیق در فناوریست، علم شبکه یا هنر تحلیل روابط است.
در جستجوی دانش بیشتر، در این مقاله از اصول علم شبکه برای کشف آیات مشابه در قرآن و محتوای آن(؟) استفاده میشود. فصلهای این نوشتار به شرح زیر است:
I. مقدمهای بر علم شبکه و قرآن
II. کارهای مرتبط و مرور پیشرفتهایی که ما را به اینجا رساندهاند
III. روششناسی و توضیح آنچه توسط نویسنده انجام شده است
IV. آزمایشها و نتایج - این بخش جذابترین قسمت مقاله است و به چگونگی انجام کار میپردازد
V. کارهای آینده
یادگیری عمیق
یادگیری عمیق به طور قابل توجهی زمینه طبقهبندی متن را با استفاده از معماریهای پیچیده شبکه عصبی برای کشف الگوهای پیچیده و روابط درون دادههای متنی پیشرفت داده است. به عنوان مثال، Doc2Vec، یک تکنیک قدرتمند یادگیری عمیق است که مدل Word2Vecرا گسترش میدهد تا نمایشهای بردار برای اسناد کامل تولید کند و معنا و روابط معنایی و زمینهای را به دست آورد.
شبکه های عصبی جان تازه ای به پردازش زبان طبیعی به شیوه جدید دادند. و با تولید embedding از متون میتوانند تحلیل متن را ساده تر کنند.
علم شبکه
علم شبکه یک حوزه بینرشتهای حیاتی است که با تحلیل روابط بین گرهها (entities) در شبکهها، بینشهایی در مورد ساختار و دینامیک سیستمهای پیچیده ارائه میدهد. مدل باراباشی-آلبرت (BA) ویژگیهای شبکههای بدون مقیاس(scale-free) را برجسته میکند که توزیع درجهای با قانون نمایی و حضور هابها (گرههایی با تعداد اتصالات بسیار زیاد) را نشان میدهد. این درک برای تحلیل شبکههای دنیای واقعی مانند اینترنت و شبکههای اجتماعی بسیار مهم است.
علاوه بر این، کار واتس و اشتروگاتز در سال 1998 در مورد شبکههای جهانی کوچک(small-world)، اهمیت طول مسیر متوسط کوتاه را برجسته میکند و نشان میدهد که چگونه شبکهها میتوانند گرههای مختلف را به طور کارآمد متصل کنند در حالی که خوشهبندی بالایی را حفظ میکنند. به طور کلی، این نظریههای بنیادین درک ما از رفتار شبکههای پیچیده را افزایش میدهند و پیشرفت در برنامههای مختلف، از جمله تحلیل شبکههای اجتماعی و انتشار اطلاعات را تسهیل میکنند.
کارهای مرتبط با قرآن
مطالعات مرتبط با قرآن شامل طیف وسیعی از تحقیقات بینرشتهای است که ابعاد زبانی، تاریخی و الهیاتی متن را بررسی میکند. قرآن به دلیل ارزش زبانی و معنوی آن شناخته شده است. این کتاب شامل دانش و موضوعاتی است که جنبههای مختلف زندگی مردم را اداره میکند. به دست آوردن و کدگذاری این دانش کار آسانی نیست به دلیل همپوشانی معانی در اسناد و تحلیلهای آن. قرآن موضوع بسیاری از مطالعات پردازش زبان طبیعی (NLP) بوده است. چندین مطالعه در مورد استخراج متن، تحلیل معنایی و مدلسازی موضوع با قرآن انجام شده است.
کاری که شما انجام دادید
هدف کار بنده ایجاد شبکه روابط آیات قرآن با یکدیگر و تحلیل آن بود(که این بخش را به پژوهشها و پژوهشگران آینده میسپارم) و برای این کار 3+1 روش امتحان کردم.
با استفاده از دادههای طبقه بندی شده در سایت قرآن طبقه بندی شده quranclassified و ایجاد پایگاه داده ای از این مطالب یک شبکه بر این اساس ساختم.

لازم به ذکر است گزینه های بهتری برای افزایش کیفیت محک نیز وجود داشت که یکی از آنها استفاده از تفاسیر قرآن میباشد که ازین نظر منابع جامع و غنی وجود دارد اما نسخه الکترونیکی یا پایگاه داده ای آزاد نیافتم و با مکاتبه ای که با موسسه inoor هم داشتم برای در اختیار گرفتن برخی از این نسخ الکترونیکی نتوانستم مجابشان کنم.
در این مورد بدلیل اینکه روشهای NLP در زبان عربی به اندازه کافی به صورت آزاد رشد نکرده بود. تصمیم گرفتم تا با تحلیل ترجمه انگلیسی رایج آن برگرفته از دیتاستی در کگل imrankhan197/the-quran-dataset با دو روش لغوی و معنایی بپردازم. برای روش لغوی TF-IDF که یکی از معروف ترین روش های بازیابی اطلاعات است. و برای تحلیل معنایی از بردارسازی با مدل معنایی BERT استفاده کنم. و با کنار هم قرار دادن این دوبردار برای هر آیه یک بردار مشخصه بسازم و با شباهت گیری بین بردار ها به نتیجه نسبتا خوبی برسم ولی از آنجا که زبان اصلی کتاب عربی است و پیچیدگی و ظرافت های خودش را دارد به سراغ روش بعدی رفتم.
این روش با پیدا کردن ریشه کلمات چه اسم، چه فعل آن ها را با هم مقایسه میکند آیاتی که بیشترین ریشه کلمه مشابه داشته باشند، درنتیجه شباهت های بیشتری هم ممکن است داشته باشند.
این روش وقت بسیار زیادی از من گرفت چرا که علی رغم وجود روش های پیشین quran-mojam مثل این مورد یا کارهای موسسه inoor و غیره. هیچکدام مجموعه دادهای برای توسعه دهندگان عرضه نکرده بودند و من سعی کردم با کمک افراد خبره دیگر مهندس مهدی باغکی و مهندس امیرمحمد امامی خودمان اینکار را از پایه انجام بدهیم ولی من ادامه ندادم و برای خودم با روش استخراج از وب مجموعه دادهای فراهم کردم.
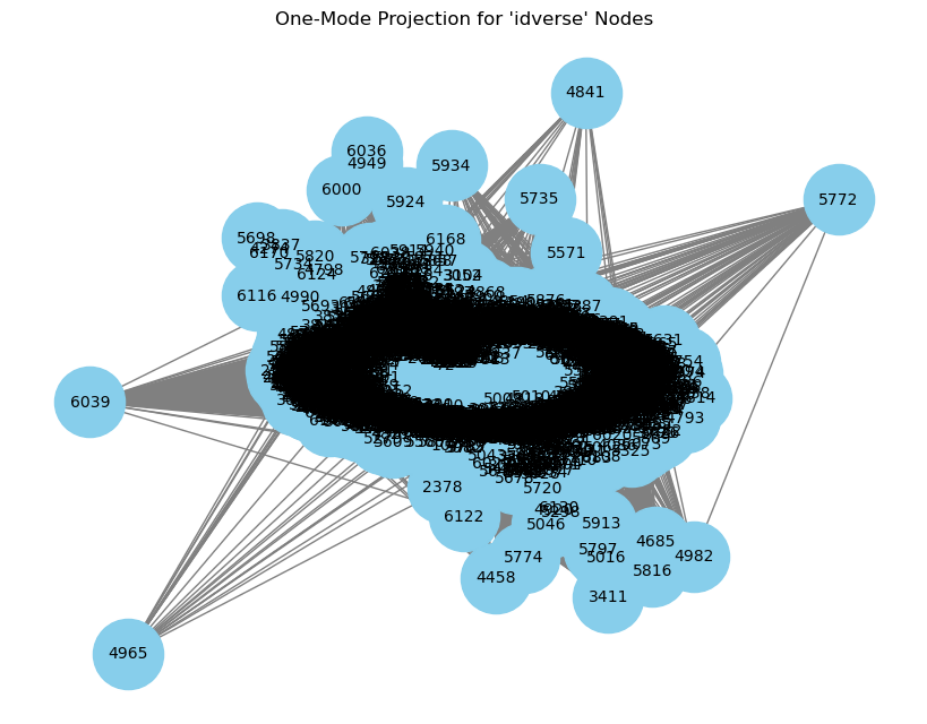
این روش نتیجه مطلوبی نداشت و بطور متوسط (average degree) برای هر آیه 4000، رابطه معرفی میکرد. البته این واضح است که بدلیل پرتکرار بودن برخی کلمات این رابطه ها بوجود میآیند و بنده سعی داشتم تا با شباهت ژاکارد به یال ها وزن دهی کنم ولی چون از نظر محاسباتی بهینه نبود متاسفانه خروجی ناکاملی دارم.
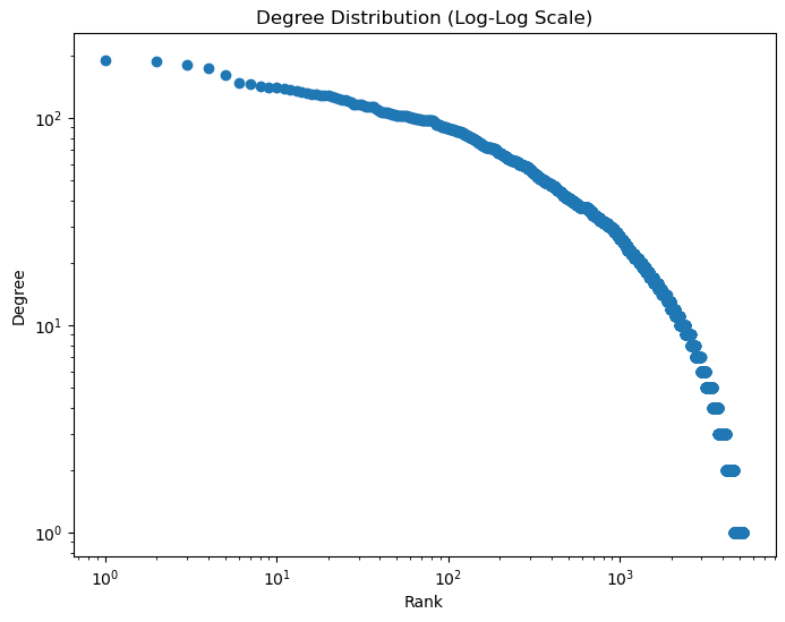
اما روش آخر که مطمئن ترین برخورد من با مسئله بود. با استفاده از API سایت OpenAI از بهترین و آخرین مدل Embedding که از زبانهای غیر انگلیسی نیز پشتیبانی میکرد-text embedding 3 large- استفاده کردم. و با کاهش ابعاد بردارهای خروجی برای هر آیه به 256 و شباهت گیری کسینوسی و اقلیدسی شبکه ای دیگر از آیات مشابه آماده کردم.
میخواستم با روشی مشابه روش کلاینبرگ با استفاده از خوشه بندی بردار ها فاصله هر دو آیه را بیابم و سپس با احتمالی مرتبط با فاصله آیاتی که خارج از GCC هستند را به گونهای به گراف متصل کنم ولی باز هم نتوانستم.
1+ روش LLM
همه با خبر هستیم که مدلهای زبانی بزرگ چه مقدار در توسعه نرمافزار و همچنین بهبود دقت نتایج در کارهای مرتبط و غیرمرتبط با صنعت نرمافزار مفید هستند.
روشی که میتوانستم انجام بدهم ولی ندادم -به دلیل وقت و هزینه API - این بود که با مهندسی prompt و به ازای ورودی هر آیه از مدل زبانی بخواهم تا tone موضوعات کلیدی اشخاص و اماکن و موجودیتها را مشخص کند و سپس با مقایسه این بردارها یک شبکه چند لایه بسازم هر لایه بر اساس یک نوع ارتباط. لایهای برای ارتباط موجودیتها مثل اشخاص، لایهای دیگر برای ارتباط معنایی، دیگری برای ارتباط از نوع موضوع و ... .
ارزيابیها
در روش بیسلاین یا محک
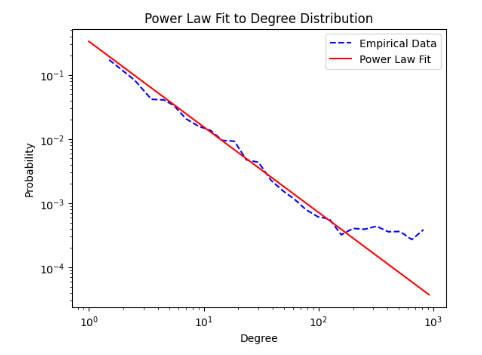
Power-law exponent: 7.4078574279741805 Number of nodes in GCC: 2211 Average degree of GCC: 46.288557213930346 Average shortest path length of GCC: 3.0334424136004468 Diameter of GCC: 9 Assortativity of GCC: 0.5345262693060804
در روش ترجمه انگلیسی
Estimated alpha: 1.333990434077387 Average Clustering Coefficient: 0.5543 Overall Average Path Length across components: 1.0751
در روش ریشه کلمات
که به دلیل مشکلات پردازش خروجی برای عرضه ندارم
در روش Embedding
nodes in GCC = 4979 Number of nodes: 5261 Number of edges: 42404 Average degree: 16.12 Average clustering coefficient: 0.30 Alpha (power law exponent): 2.98 Xmin: 31.0 Loglikelihood ratio (power law vs exponential): -24.22 p-value: 0.01
برای خروجی و نتیجهگیریبهتر بود تا با جدولی این مقادیر مقایسه شوند ولی چون کار را به صورت پراکنده پیش برده بودم(یعنی میزان دانشم در ابتدای کار بسیار کمتر از حالا بود) و از نظر محاسباتی این اجراها زمانبر هستند نتایج را اینگونه ارائه دادم.
جمعبندی
برای جمعبندی هم زود است و هم دیر چرا که تحلیل معنایی و مفهومی این شبکه های تولید شده چه میشود؟ و هم زمان کافی برای آن نیست پس دیر هم شده.
اما به عنوان کسی که بیشتر از 150 ساعت روی این موضوع وقت گذاشته میتوانم بگویم شبکههای آیات قرآنی که من ساختم ساختار شبکه های پیچیده را به طور کامل ندارند. ولی میتوانم امیدوار باشم که با کار بیشتر و شناسایی ویژگی های دقیقتر بهتر و کاملتر میتوان یک نتیجه گیری دیگری ارائه داد در رد یا اثبات فرضیه من.