اول از همه بیایم با هم بررسی کنیم ببینیم این RAG خودش چیه که RAGASش چی باشه :-):-):-)
مرغ چیه که کله پاچش چی باشه، چه ربطی داشت :-)
اما خود RAG یعنی چی ؟
خیلی خیلی خلاصه شو بخوام بگم RAG سیستمیه که در اون:
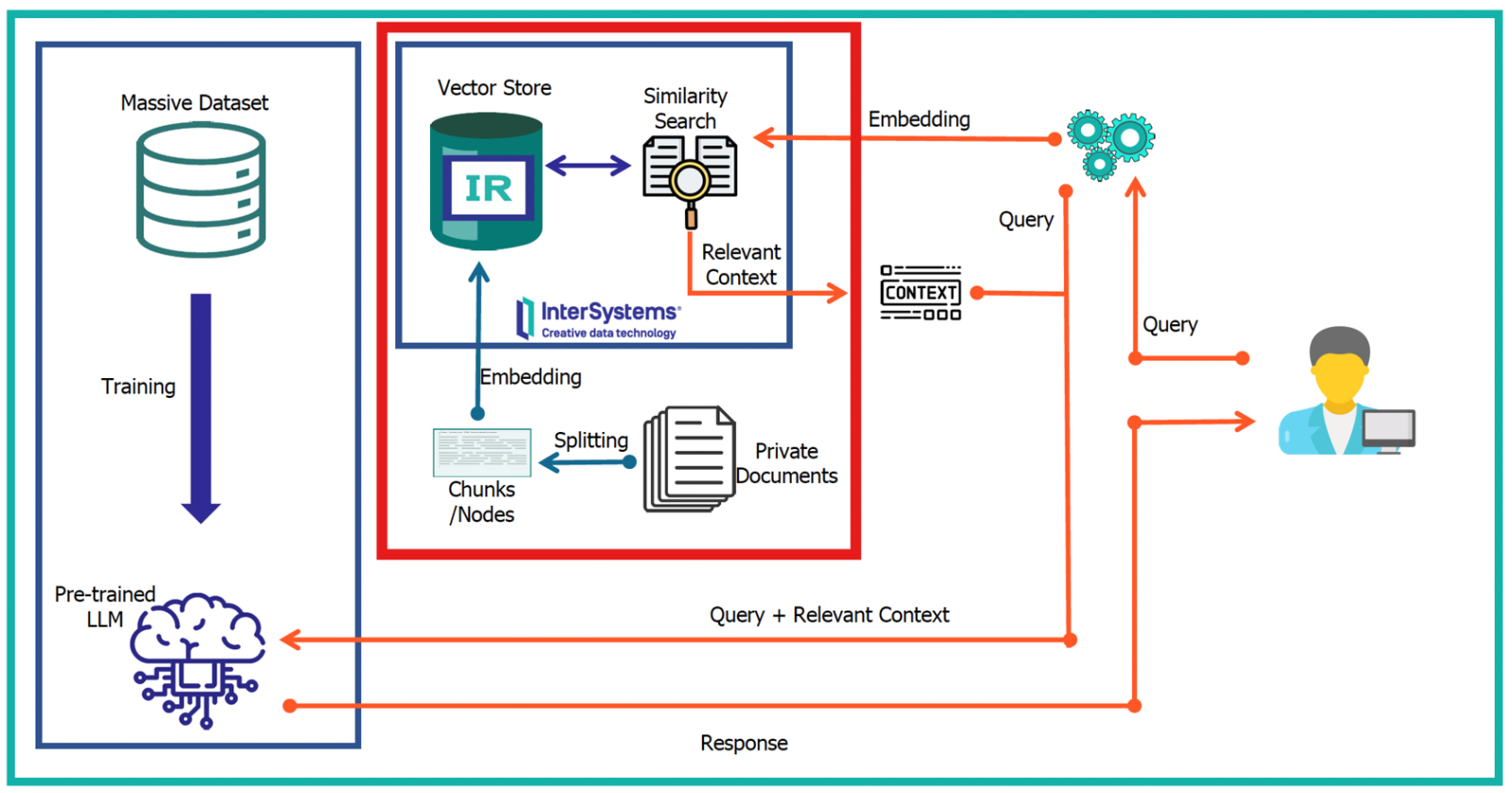
یوزر سوال مدنظرشو می پرسه که بصورت کوئری میره سمت لایه Retriever، بعدش Context مدنظر بازیابی میشه و پاس داده میشه سمت LLM Prompt و در نهایت Response برمیگرده سمت کاربر.
البته خیلی خلاصه گفتم و ستون فقرات معماری RAG سه لایه Retrieval, Augmentation و Generation قرار داره که در جای خودش مفصل راجع بهشون صحبت می کنم براتون رفقا.
و اما RAGAS
ببین خیلی ساده:
RAGAS = ابزار ارزیابی سیستمهای RAG به حساب میآد.
بالاخره باید یه حساب کتابی روی دیتایی که جنریت می کنه باشه مگه نه؟ نمیشه که الابختکی، مملکت قانون داره!
اما RAGAS میاد بررسی میکنه:
Retriever (بخش سرچ) خوب کار میکنه؟
LLM (بخش پاسخگویی) چقدر درست جواب میده؟
و نوآوری این معماری در اینه
بدون اینکه نیاز به دیتای لیبلخورده سنگین داشته باشی
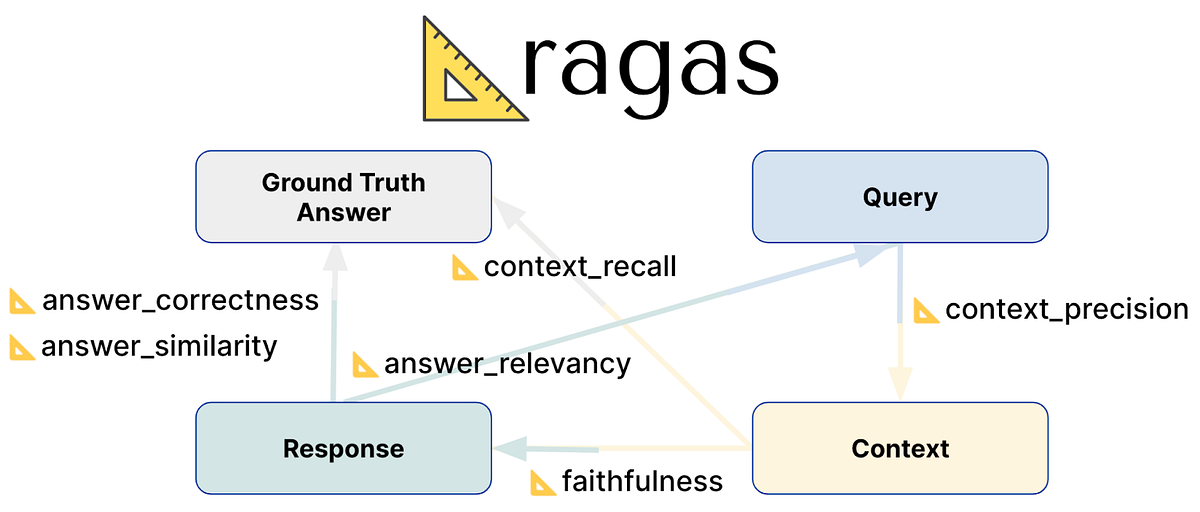
RAGAS چندتا معیار خیلی مهم داره که کل سیستم رو میسنجه:
جواب LLM چقدر به context وفاداره؟
یعنی:
آیا جواب از خودش چیزی ساخته؟ خدایی نکرده دچار hallucination نشده باشه، بچم توهم نزده باشه بره قاطی مرغا :-)
یا واقعاً از متنی که خودمون به سیستم دادیم برای تولید جواب استفاده کرده؟
Context:
محمدتقی بهجت 2 شهریور 1295 به دنیا آمد
جواب خوب:
2 شهریور 1295 : درست
جواب بد:
22 ممهر 1299 : مدل توهم زده و از خودش دَر وَکِردِه (بَرَرِه ای گفتم :-)
جواب رو میشکنه به جملههای کوچیک
هر جمله رو چک میکنه:
آیا از context قابل استنتاجه؟
درصد جملههای درست = امتیاز
خروجی هم بین 0 تا 1
جواب اصلاً به سوال ربط داره یا نه؟
سوال:
ایران کجاست و پایتختش چیه؟
جواب ضعیف:
ایران در آسیا است (نیمهکاره)
جواب خوب:
ایران در غرب آسیا است و تهران پایتخت آن است
این قسمت خیلی جالبه
از روی جواب، چندتا سوال مصنوعی ساخته میشه (با LLM)
بعد این سوالها با سوال اصلی مقایسه میشن (embedding similarity)
اگر شبیه بودن: یعنی جواب مرتبطه
Retriever همه اطلاعات لازم رو آورده یا نه؟
یعنی:
چیزی که برای جواب لازم بوده
واقعاً تو context بوده یا نه
یه جواب مرجع و صحیح داریم که بهش میگیم ground truth همون رفرنس خودمون.
اون رو تبدیل میکنه به چند claim یا همون ادعا
چک میکنه آیا همه این claimها تو context هستن؟
اگر یه چیز مهم جا مونده باشه، recall میاد پایین
از بین contextهایی که آوردی، چندتاش واقعاً مفیدن؟
یعنی:
noise داری یا نه (دیتای غیر مرتبط و به درد نخور رو بهش میگیم نویزی)
irrelevant chunk آوردی یا نه
اگر 5 تا متن آوردی:
2 تا مفید و 3 تا بیربط، در نتیجه precision پایین
برای هر chunk بررسی میکنه:
آیا به جواب ربط داره یا نه
بعد میانگین میگیره
متریک چی رو میسنجه:
Faithfulness
آیا جواب دروغ گفته؟
Answer Relevancy
آیا جواب به سوال ربط داره؟
Context Recall
چیزی جا نیفتاده؟
Context Precision
چیز اضافه آورده؟
این 4 تا در واقع 2 تا لایه دارن:
Context Recall
Context Precision
Faithfulness
Answer Relevancy
یعنی RAGAS کل pipeline رو end-to-end بررسی میکنه
from ragas import evaluate score = evaluate( dataset, metrics=[faithfulness, answer_correctness] )
دیتاست شامل:
question
answer
contexts
ground_truth
فرض کن میخوای RAG برای شرکت تون بسازی، اینطوری استفاده میشه:
LLM داره hallucinate میکنه
راهکارش:
prompt بهتر
citation forcing
chain-of-thought محدود
retriever چیزای مهم رو پیدا نکرده
راهکارش
embedding بهتر
chunking بهتر
top-k بیشتر
noise زیاده
راهکارش:
reranker
filtering
hybrid search
جواب پرت میده
راهکارش:
prompt engineering
instruction tuning
امیدوارم این مقاله براتون سودمند واقع شده باشه، سوالی داشتید در خدمتتون هستم و خوشحال میشم بتونم کمکی باشم براتون در این مسیر طولانی LLMها.