
سلام.
اگه همین سوال عنوان مقاله رو از هوش مصنوعی بپرسی خیلی مبهم بهت توضیح میده
خوندی متن رو؟ خیلی گُنگ بود نه؟ ببین اگه بخوام خیلی ساده و کاربردی بهت توضیح بدم میرم سراغ یه مثال که بگیری ماجرا رو. ببین فرض کن شب قبل خواب دعا کردی که خدایا پولدارم کن و صبح که از خواب بیداری میشی میبینی مدیر شرکت اسنپی و امروز اون روزیه که برای تقدیر از رانندهها و افزایش روحیشون باید بهشون جایزه بدی تا نرن توی تپسی مشغول به کار شن. حساب شرکت رو چک میکنی و میبینی انگار اونقدرا پولدار نیستی که به همه رانندههات جایزه بدی 🎁 و حالا که اونقدرا حساب شرکت توش پول نیست باید سعی کنی به جای همه به بهترین رانندههات جایزه بدی. خب الان از کجا میتونی بفهمی که کدوم رانندهها کارشون خوب بوده و لایق دریافت جایزن؟ بر اساس چی باید تصمیم بگیری؟
ظاهر راننده؟
نوع ماشینش؟
رفتار راننده با مسافرا؟
تعداد سفرهاشون؟
سلامت خودرو؟
میبینی؟ پارامترهای انتخاب راننده مناسب خیلی زیاده و حالا اگه تعداد رانندهها هم زیاد باشه، عملاً انتخاب افرادی که لایق دریافت جایزن ممکن نیست و خب زمان خیلی زیادی میبره ( مو پول ازِت خواستوم خدا خو ای چکاریه؟ ). ببین اگه مثلاً استاد دانشگاه بودی، براساس نمره امتحان ۳۰ تا دانشجویی که داشتی راحت انتخاب میکردی که چه کسی لایق ارفاقه و تصمیم سختی نبود، اما اینجا با کلی ویژگی مختلف طرفیم و عملا گیر میکنی. اینجا علم داده یا (Data Science) وارد میشه و میاد بر اساس اطلاعاتی که از هر راننده داریم تصمیمگیری میکنه برامون که به کی جایزه بدیم. یعنی چی دقیقاً؟
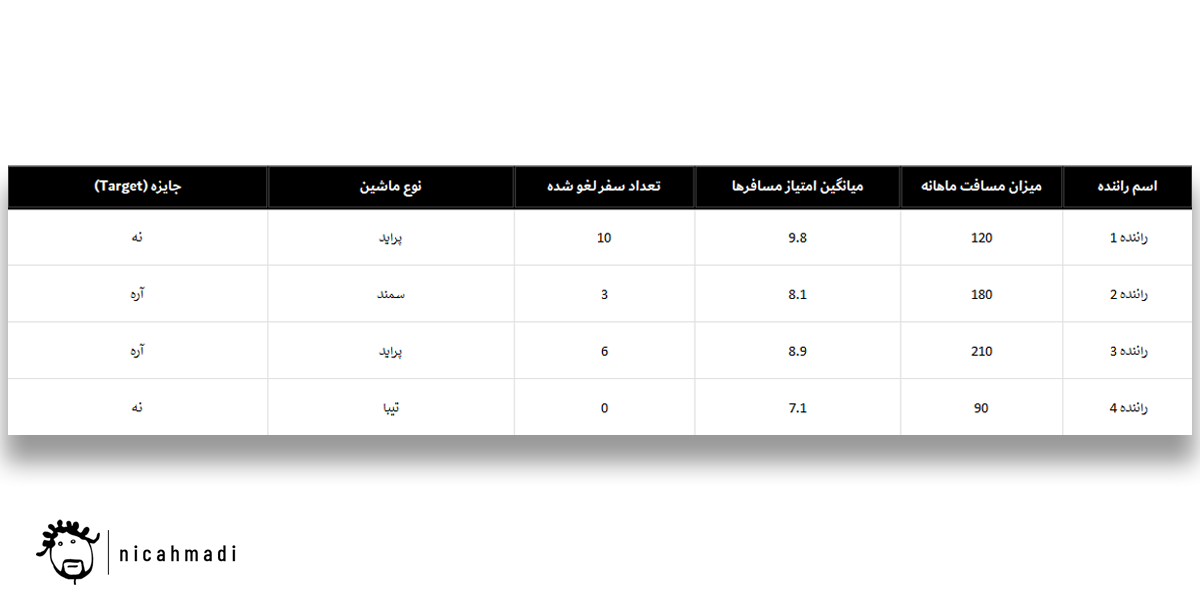
ببین یکی از کارمندات توی اسنپ کارش اینه که یه فایل اکسل بسازه و از تمام ویژگی های رانندت اطلاعاتش رو یادداشت کنه، مثلا میانگین مسافتی که ماه قبل رفته چقدر بوده، میانگین امتیاز مسافرهاش چقدر بوده، تعداد سفرهای لغو شدهای که داشته چقدر بوده و غیره. هر ستون توی فایل اکسل کارمندت، یه ویژگی از رانندته تا کار تو رو برای انتخاب بهترینها راحت کنه. به این ستونها صفت هم گفته میشه به انگلیسی میگن (Feature). ببین جدول کارمندت اینجوریه:
🚗 میانگین مسافت طیشده در ماه:
راننده ۱: ۱۲۰ کیلومتر
راننده ۲: ۱۸۰ کیلومتر
راننده ۳: ۲۱۰ کیلومتر
راننده ۴: ۹۰ کیلومتر
⭐ امتیاز مسافر:
راننده ۱: ۹.۸
راننده ۲: ۸.۱
راننده ۳: ۸.۹
راننده ۴: ۷.۱
❌ تعداد سفرهای لغوشده راننده:
راننده ۱: ۱۰ بار
راننده ۲: ۳ بار
راننده ۳: ۶ بار
راننده ۴: ۰ بار
🚙 نوع ماشین راننده:
راننده ۱: پژو
راننده ۲: سمند
راننده ۳: پراید
راننده ۴: تیبا
یه ستون مهم دیگه هم اون ته داریم به اسم هدف یا (Target) که فقط دو حالت میگیره، آره یا نه یعنی «آیا این راننده باید جایزه بگیره یا نه» و آره یا نه بودن این ستون رو هم خودت براساس اطلاعات ستونهای دیگه تصمیم میگیری، فایل اکسلت تقریبا چنین چیزی در اومده در آخر کار👇🏼
حالا که اطلاعاتی از هر راننده بر اساس ویژگیهای توی جدول داریم، راحت میتونیم تصمیم بگیریم که کدوم راننده استحقاق دریافت جایزه رو داره و کدوم یکی نداره، اما این روش وقتی جواب میده که مثل جدول بالا تعداد رانندهها کم باشه و اگر زمانی ما مثلا ۱۰۰۰ تا راننده داشته باشیم، تصمیمگیری و مقایسه این رانندهها با هم خیلی زمانبر میشه. راهحل چیه؟
اینجا ماشین لرنینگ مثل یک چکش از جعبه ابزار علم داده میتونه بهمون کمک میکنه. چجوری؟
الان دیگه به جای ۴ تا راننده ۱۰۰۰ تا راننده داریم و باید به بهترین هاشون جایزه بدیم، برای استفاده از ابزار ماشین لرنینگ مطابق زیر و قدم به قدم میریم جلو:
۱: یه تعداد شانسی از بین اون ۱۰۰۰ تا راننده انتخاب میکنیم (مثلا ۱۰۰ تا راننده رو شانسی انتخاب میکنیم).
۲: اینجا براساس ویژگیهایی که توی اکسل کارمندمون بود مشخص میکنیم کدوم راننده ها از بین این ۱۰۰ تا راننده لایق گرفتن جایزن و توی سطر هدف یا (Target) مینویسم آره یا نه
۳: خروجی فایل اکسلی که تکمیل کردیم رو میدیم به یک الگوریتم تا بر اساس اون یاد بگیره که ما چه ویژگیهایی رو در رانندهها دیدیم که تصمیم گرفتیم راننده بر اساس اونها جایزه بگیره.
۴: الگوریتم شروع میکنه به یادگیری و بعد از یه مدت به ما یه فایل میده که بهش میگیم فایل مدل.
ببین این فایل مدله تقریبا حکایت دانشآموزی رو داره که بعد از چند جلسه کلاس املاء، میدونه املای صحیح یک کلمه دقیقاً چجوریه، مثلاً اگر توی دفتر مشق رفیقش ببینه نوشته «توجیح» میفهمه اشتباه نوشته و اگر نوشته باشه «توجیه» میگه ایول این کلمه رو درست نوشتی.
مدلی که ما که از الگوریتم گرفتیم حالا میتونه برای اون ۹۰۰ نفر باقیمونده تصمیم بگیره، و بگه که کدوم یکی از رانندهها لایق گرفتن جایزن و کدوما نیستن و توی خروجی یه فایل اکسل بده از افرادی که لایق جایزه گرفتنن. مدله از کجا فهمید؟ از اون ۱۰۰ نفری که وقت گذاشتیم و تعیین کردیم که کدومشون لایق جایزه گرفتنن کدوم نه. انگار حالا مدل حکم دانش آموز املایی رو داره که فهمیده راننده چه ویژگیهای رو داشته باشه در مقایسه با بقیه خوب حساب میشه.
اینجا سوالی که پیش میاد اینه که ممکنه مدل ما اشتباه کنه؟چون اولا نسبت ۱۰۰ نفر بنظر شاید کم باشه در قیاس با اون ۱۰۰۰ نفر، یا اینکه بعضی از رانندهها شاید ویژگیهایی بیشتری نسبت به اون چیزی که توی جدول داریم داشته باشن، یا اصلا کارمندت یه جاهایی اشتباه کرده و ویژگی هارو به درستی برای بعضی رانندهها وارد نکرده. جوابمون چیه؟ آره ممکنه مدل اشتباه کنه، چرا؟ به همهی این دلایلی که گفتیم و کلی دلیل دیگه و از همین اول در نظر بگیر که هیچ مدلی قرار نیست ۱۰۰٪ بدون خطا کار کنه ولی خب کلی راه هست که بتونی خطاهاش رو برطرف کنی تا نزدیک بشه به مقدار کارکرد ۱۰۰٪ بدون خطا. چرا مهمه که بدون خطا کار کنه؟ چون وقتی که میخوای بین ۱۰۰۰ تا راننده انتخاب کنی که چه کسی جایزه بگیره، حق کسی ضایع نشه.
این کل ماجرا بود.
اگه دقت کرده باشی، همهچیز به دادهها و اطلاعاتی که کارمندت از رانندهها داشت ربط داره و این نشون میده چقدر اهمیت دادهها زیاده و دلیل اینکه به این حوزه میگن علم داده همینه. کلا علم داده از جمع آوری دیتا تا اینکه تشخیص بدی کجاها کارمندت خطا کرده، یا مدلی بسازی که براساس اون جایزه بدی، نظر رانندههات رو درباره جایزههاشون دربیاری و ببینی راضی بودن یا نه کاربرد داره. عمدتا خروجی کار رو هم روی نمودار نشون میدن که تحلیل و بررسیش راحت باشه و خب اینم باز خودش بخشی از علم دادهاست؛ چی رو میشه ترسیم کرد روی نمودار؟ اینکه آیا رانندههات راضی بودن از نوع تصمیم گیریت بابت انتخاب فرد شایسته برای جایزه، یا از جایزههایی که بهشون دادی راضین یا نه. باز ممکنه بگی خب که چی به فرض راضی باشن یا نباشن، ببین هدف همه ماجرا اینه که تو دربیاری که با وجود این طرح تشویقی که گذاشتی تا به رانندههات جایزه بدی، آیا بازم رانندههات سراغ کار کردن توی تپسی میرن یا نه؛ هدف کلی تر؟ شما نبودی پول میخواستی؟ فک کردی پول مف میدن به کسی؟ دادا راننده هات برن بدبختی باز باید بشینی دعا کنی.
ماشین لرنینگ یکی از ابزارهای این زمینس و کلی ابزار دیگه وجود داره که باید وارد این حیطه بشی و کار کنی باهاشون تا در نهایت ازت به عنوان (Data Scientist) یا دانشمند داده (ماضی غیر بعید) یاد بشه.
صفحه رو که دنبال کنی و پستهای بعدی رو که بخونی به مرور وارد جزئیات میشیم چون هنوز کلی ابزار دیگه غیر از یادگیری ماشین (Machine Learning) و کلی راه پول حلال در آوردن دیگه غیر از مهندس داده بودن وجود داره که خوبه دربارشون بدونی.