با رشد سریع دنیای مهندسی نرمافزار، هر روزه با اصطلاحات و مفاهیم جدیدی مواجه میشیم.
در این پست، قراره به طور خلاصه، به 20 مورد از مهمترین، مدرنترین و البته پرکاربردترین مفاهیم این حوزه بپردازیم؛ مفاهیمی که از معماریهای توزیعشده تا تقاطع جذاب هوش مصنوعی و مهندسی نرمافزار رو در بر میگیرن.
این لیست یک «نقشه راه» جامع برای برنامهنویسان، معماران و مهندسان نرمافزار و دانشجوهاست!
در پستهای آینده هم، عمیقتر شده و تکتک این موضوعات رو با جزئیات فنیتر، چالشهای پیادهسازی و نمونههای واقعی بررسی خواهیم کرد.

Chaos Engineering
مفهوم مهندسی آشوب/Chaos Engineering، به منظور اینه که به جای منتظر موندن برای وقوع یک خطای واقعی در سیستم، خودمون اون خطا رو به صورت کنترل شده به سیستم اعمال کنیم تا میزان مقاومتش رو سنجیده و افزایش بدیم. با این کار میتونیم تاب آوری/tolerance سیستممون رو در زمان اجرا (runtime) و در محیط production ارتقا داده و قابلیت دسترس پذیری/availability رو در سطوح بالا محقق کنیم.
این رویکرد پیشگیرانه ریشه در تجربهای از خرابی سه روزه در سال 2008 در نتفلیکس/Netflix داره که برای مقابله با اون، در سال 2010، ابزاری به نام Chaos Monkey توسط نتفلیکس توسعه یافت تا بتونه چالشهای مربوط به انعطافپذیری/flexibility سیستمهای توزیع شده و مقیاسوسیع در بستر ابر رو برطرف کنه.
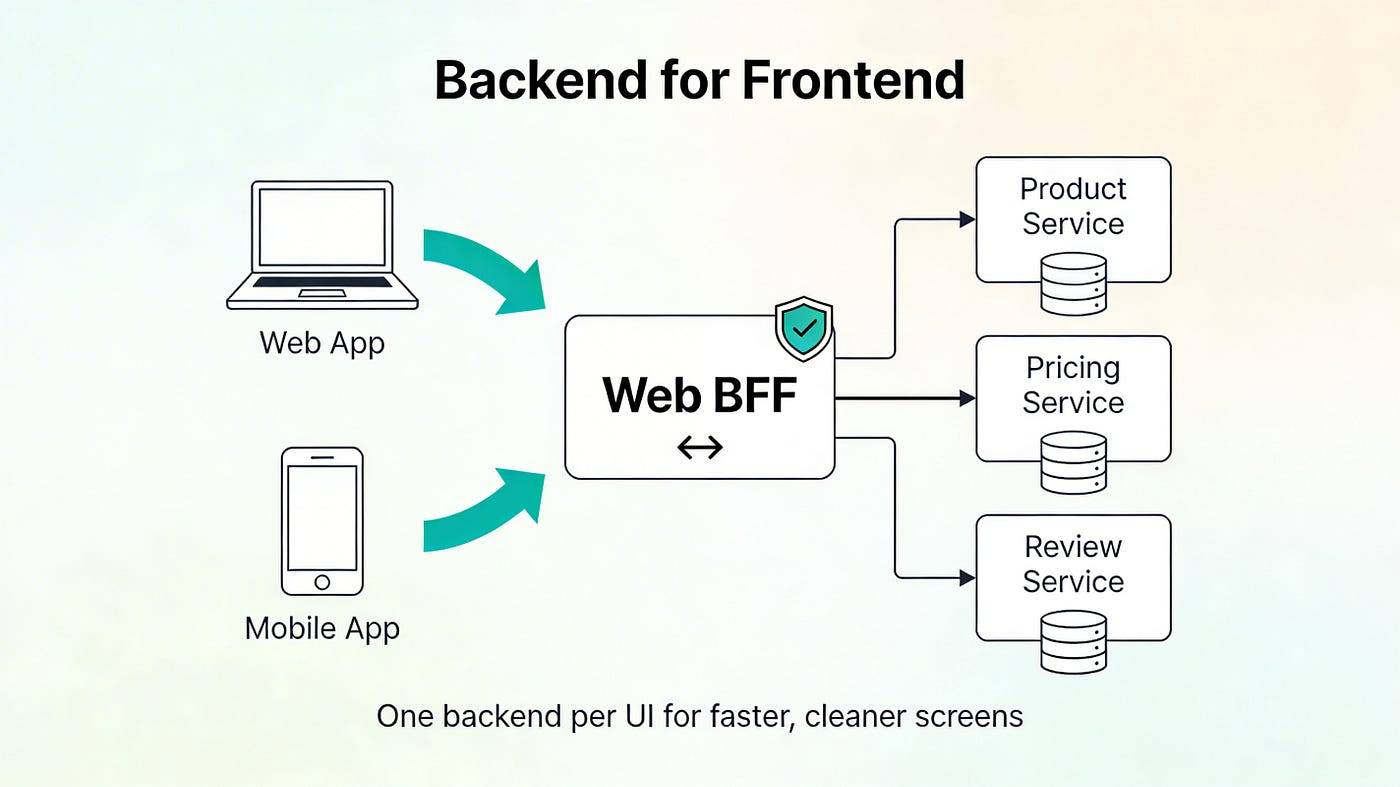
Backend for Frontend
الگوی معماری Backend for Frontend، یک الگوی طراحی توزیع شده برای پاسخگویی به نیازهای ناشی از گستردگی و تنوع دستگاههای کلاینت در سیستمهای میکروسرویسه که به جای استفاده از یک API واحد و عمومی برای تمام کلاینتها، یک backend اختصاصی و جداگانه رو برای هر UI منحصر به فرد توسعه میده.
این الگوی معماری گلوگاههای سازمانی رو از بین برده و به تیمهای frontend استقلال بالایی در بهروزرسانی رابطهای کاربری اعطا میکنه که باعث میشه با تغییر در هر frontend، سایر frontها تحت تاثیر قرار نگیرن.
برای مثال، SoundCloud با پیادهسازی این الگو تونست APIهای خودش رو برای هر نوع کلاینت جداگانه بهینه کند، و بدون نیاز به هماهنگیهای پیچیده، قابلیت تحمل خطا/resiliency و سرعت توسعه رو بهبود ببخشه.
Artificial Intelligence for Software Engineering (AI4SE)
اصطلاح AI4SE، به معنای هوش مصنوعی در خدمت مهندسی نرمافزاره که به کاربرد الگوریتمها و توانمندیهای هوش مصنوعی برای بهبود فرایندهای توسعه نگهداری و تست نرمافزار اشاره کرده و در راستای خودکارسازی ارتقا و بهینهسازی فرایندهای گوناگون چرخه حیات توسعه نرمافزار به کمک هوش مصنوعیه.
ابزارهایی مثل GitHub Copilot، Cursor AI و Amazon CodeWhisperer نمونههای بارز AI4SE هستن که میتونن کد رو به صورت خودکار تولید کنن، تستهای نرمافزاری به ویژه unit testها رو بنویسن، باگها را شناسایی و حتی رفع کرده و مستندات فنی رو استخراج کنن.
Software Engineering for Artificial Intelligence (SE4AI)
در نقطه مقابل، SE4AI به معنای مهندسی نرمافزار در خدمت هوش مصنوعیه و روی توسعه سیستمهای مبتنی بر هوش مصنوعی با استانداردها و متدولوژیهای مهندسی نرمافزار رای ساخت استقرار نظارت و مدیریت این سیستمها تمرکز دارد تا reliability، security و scalability رو محقق کنه.
یکی از چالشهای اصلی SE4AI، استقرار و عملیاتی کردن مدلهای هوش مصنوعی در محیط واقعیه. تحقیقات نشون میده که توسعه یک مدل AI فقط ۲۰ تا ۳۰ درصد کار رو تشکیل میدهه و مابقی زمان، صرف یکپارچهسازی، تست، نظارت و نگهداری آن میشه. اینجاست که مفاهیمی مثل MLOps (که در بخش بعد به اون میپردازیم) و تکنیکهای مهندسی نرمافزار وارد عمل میشن.
در واقع SE4AI به ما یاد میده که باید مدلهای AI رو همانند کدهای نرمافزاری، تحت کنترل نسخه قرار دهیم، خطوط لوله استقرار خودکار برای اونها تعریف کنیم و عملکردشون رو در محیط تولید به طور مداوم پایش کنیم.
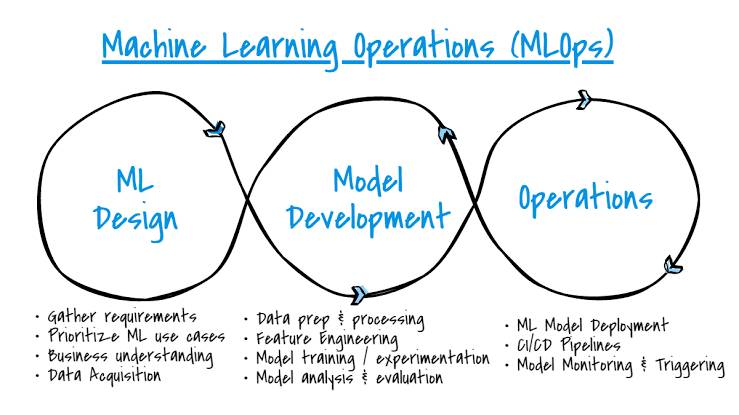
Machine Learning Operations (MLOps)
این اصطلاح که برگرفته و با الهام از DevOps هست و به مجموعه شیوهها، ابزارها و فرهنگ توسعه گفته میشه که چرخه حیات کامل سیستمهای یادگیری ماشین رو خودکارسازی، یکپارچهسازی و مدیریت میکنه، از جمعآوری داده و آموزش مدل تا استقرار، نظارت و بازآموزی (relearn) مداوم اون.
تفاوت اصلی MLOps با DevOps در ماهیت پروژههاست. در DevOps، ما با کد و نرمافزارهای قطعی/deterministic سر و کار داریم که اگر یک بار درست کار کنه، همیشه درست کار خواهد کرد؛ ولی در MLOps، سیستمها، غیرقطعی/nondeterministic و وابسته به داده هستن. مدلها میتونن با تغییر داده یا تغییر روابط به مرور زمان خراب بشم، بدون اینکه حتی یک خط از کدشون تغییر کرده باشد. MLOps برای حل این چالشها راهکارهای مشخصی ارائه میده.
پلتفرمهای تراز اول MLOps نظیر Amazon SageMaker خطوط لوله جامعی رو برای مدیریت این فرآیندها ارائه میدن که ثبات/stability و قابلیت اطمینان/reliability سیستمهای هوشمند رو در مقیاس سازمانی تضمین میکنن.
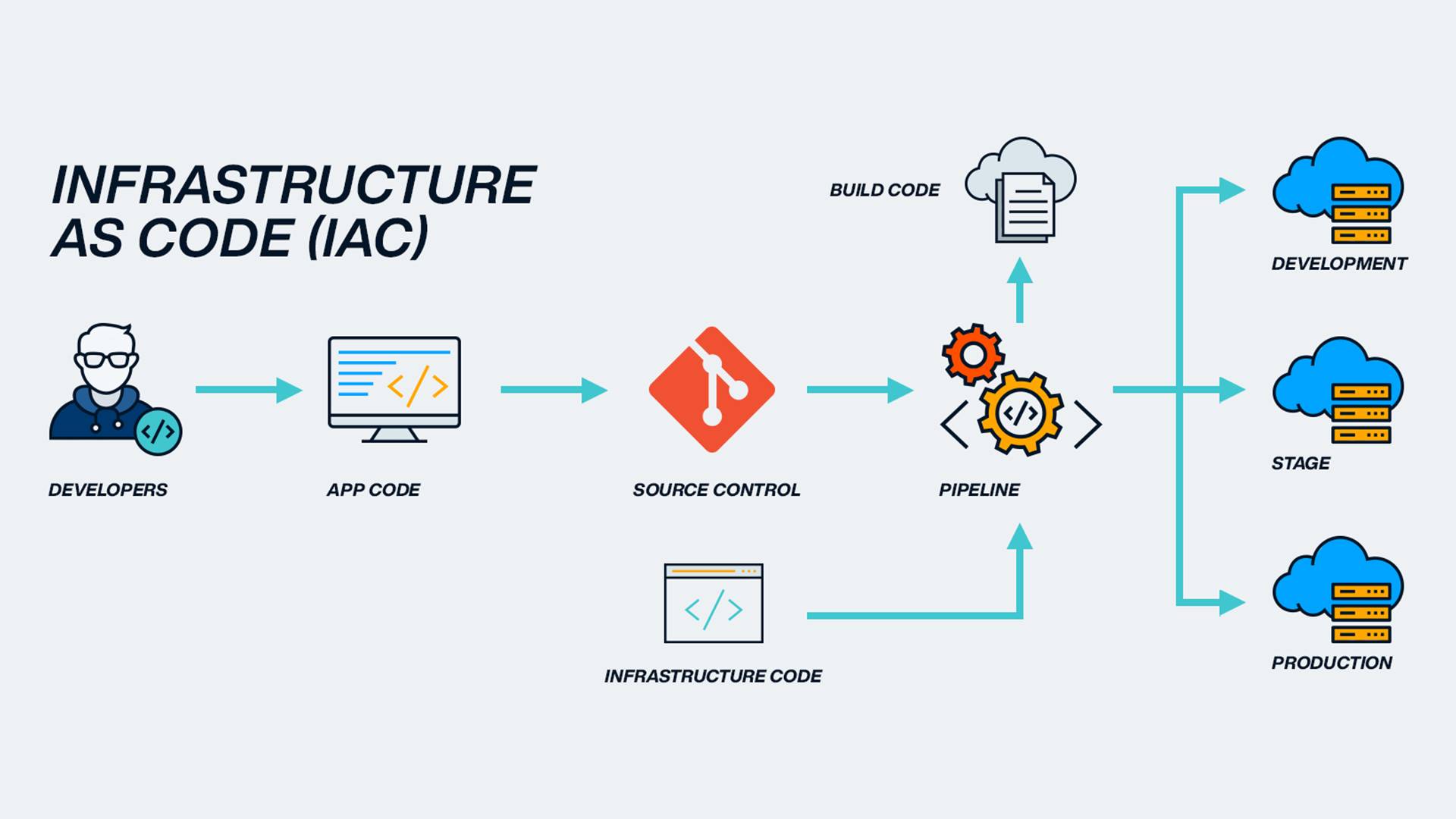
Infrastructure as Code
مفهوم Infrastructure as Code یا زیرساخت به عنوان کد، به این معناست که به جای تنظیم دستی و کلیک کردن در پنلهای ابری برای ساخت سرور یا شبکهها، کل زیرساختمون رو با کدهای متنی و خوانا برای ماشین (مثل YAML یا HCL) توصیف کنیم. این کار باعث میشه خطاهای انسانی به حداقل برسه و محیطهای توسعه، تست و production کاملاً شبیه به هم باشن.این رویکرد دو مدل اصلی داره: یا به صورت اعلامی/declarative (مثل ابزارهای Terraform و CloudFormation) فقط به سیستم میگیم چه وضعیت نهایی رو میخوایم، یا به صورت دستوری/imperative (مثل AWS CDK) با زبانهای برنامهنویسی رایج مثل پایتون زیرساخت رو مینویسیم. از اونجایی که این فایلها مثل کدهای نرمافزاری وارد مخازن مانیتورنگ و کنترل نسخه (Git) میشن، میتونیم براشون تاریخچه تغییرات، requests و تستهای خودکار داشته باشیم و استقرار رو کاملاً خودکار (CI/CD) پیش ببریم.
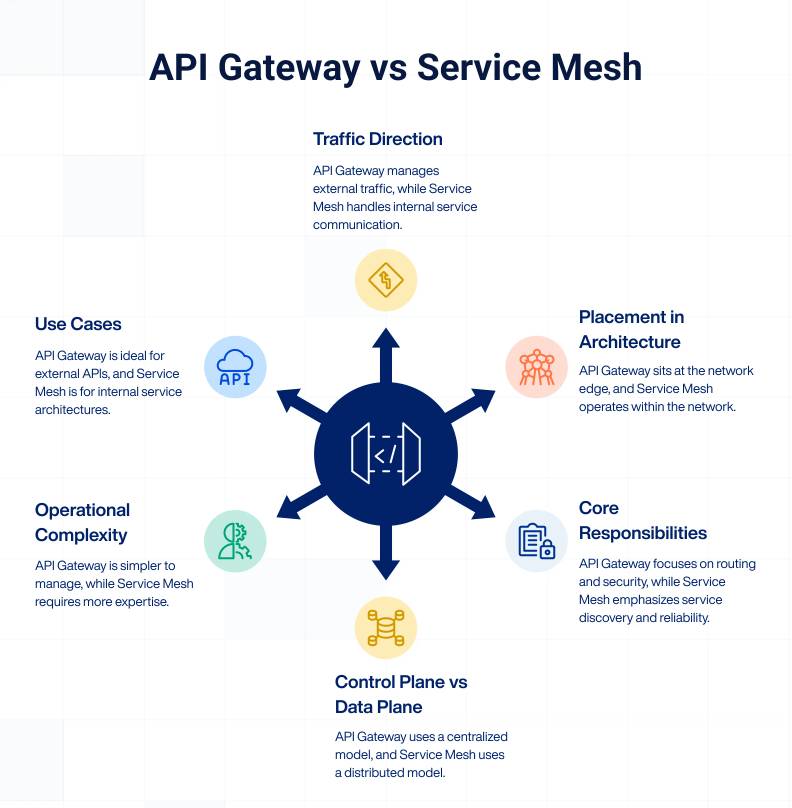
API Gateway & Service Mesh
توی معماری میکروسرویس، برای مدیریت ارتباطات از دو الگوی API Gateway و Service Mesh استفاده میشه که هر کدوم لایهها و اهداف متفاوتی دارن. الگوی API Gateway مثل یک درگاه ورودی واحد برای کلاینتهای خارجی عمل میکنه و ترافیک شمال-جنوب/North-South رو مدیریت میکنه؛ یعنی کارهایی مثل احراز هویت، محدودیت نرخ درخواست/rate limiting، کش کردن و مسیریابی رو قبل از رسیدن درخواست به داخل سیستم متمرکز میکنه.
از طرف دیگه، Service Mesh روی ترافیک شرق-غرب/East-West یعنی ارتباطات بین خود میکروسرویسها در داخل سیستم تمرکز داره. این الگو با قرار دادن یک پراکسی سبک (معروف به Sidecar مثل Envoy) کنار هر سرویس، بدون نیاز به تغییر در کدهای اصلی برنامه، امکاناتی مثل امنیت (رمزنگاری mTLS)، پایداری (circuit breaker) و مانیتورینگ رو برای ارتباطات داخلی cluster تضمین میکنه.
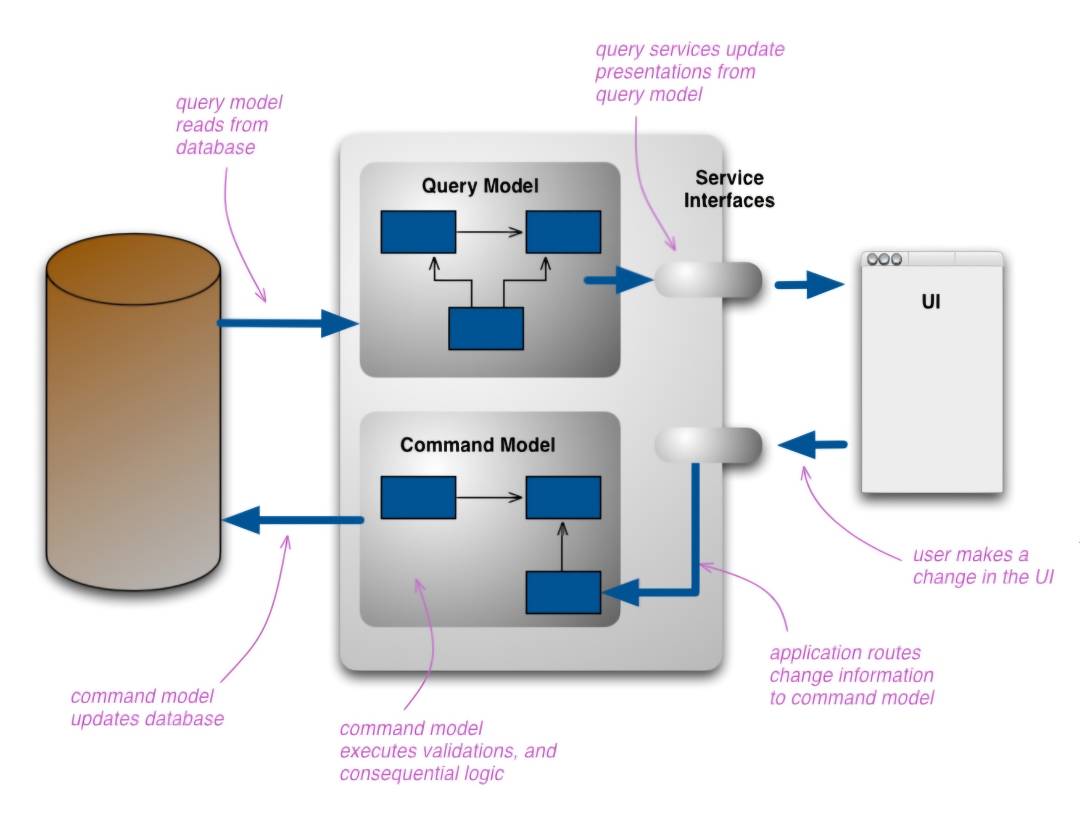
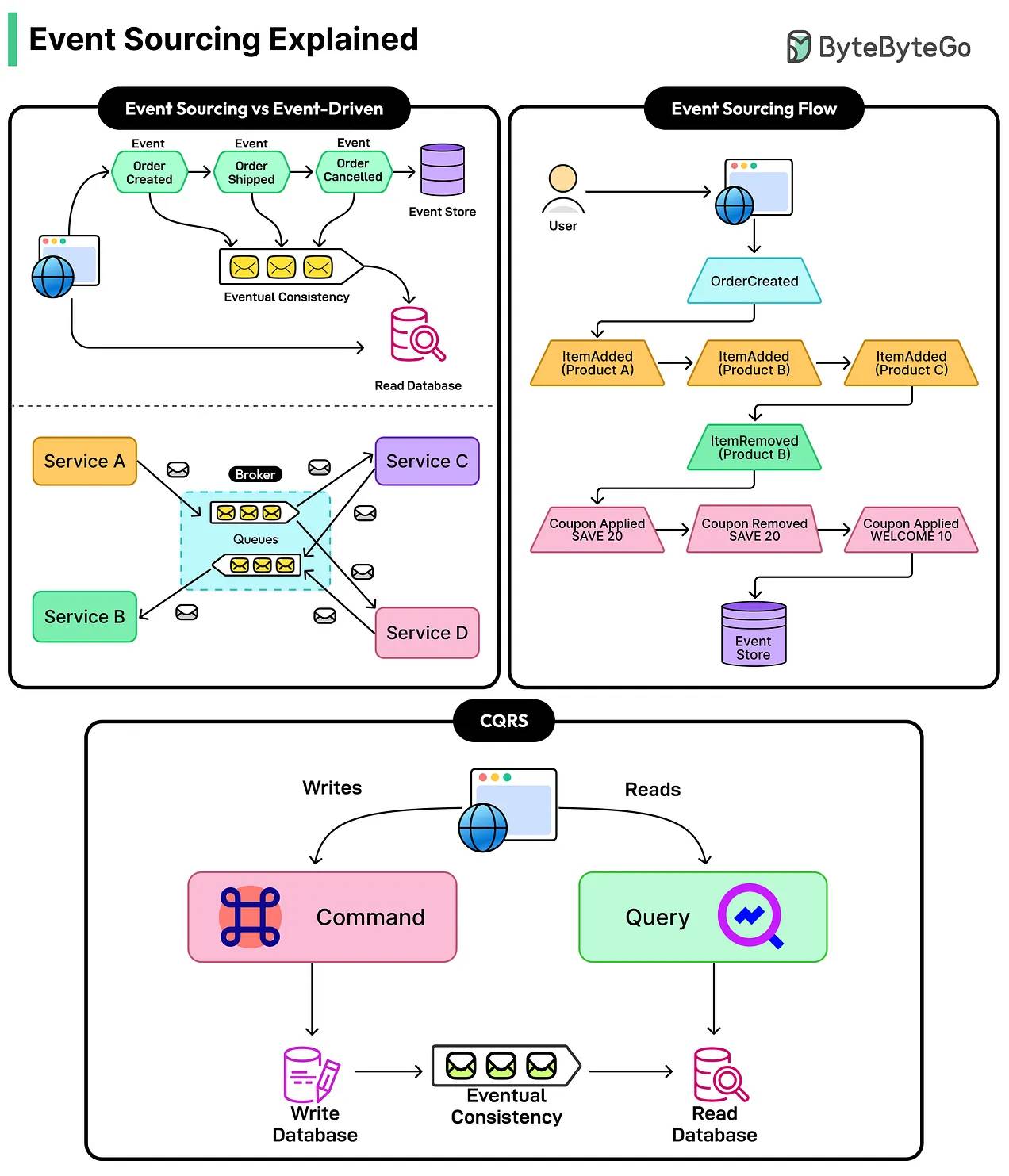
Command Query Responsibility Segregation (CQRS)
در بسیاری از سیستمهای سنتی، خوندن و نوشتن دادهها هر دو از یک مدل داده و یک پایگاه داده استفاده میکنن. این روش تا جایی که میزان خوندن و نوشتن متوازنه و پیچیدگی کمی داره، به خوبی کار میکنه، ولی زمانی که یک عملیات در سیستم نیاز به بهینهسازیهای کاملاً متفاوتی داشته باشه، مثلا تو سیستمهای پیچیده که نرخ خوندن و نوشتن خیلی متفاوته (همچون شبکههای اجتماعی)، این روش باعث افت کارایی و پیچیدگی میشه.
با CQRS، ما سیستم رو به دو بخش مجزا تقسیم میکنیم که حتی میتونن دیتابیسهای فیزیکی جداگانهای داشته باشن؛ یکی برای نوشتن که منطق پیچیده کسبوکار رو هندل میکنه و یکی برای خوندن که برای سرعت بالا و جستجو بهینهسازی شده. این دو بخش معمولاً از طریق رویدادها/events به صورت ناهمگام با هم در ارتباطن (که باعث پایداری نهایی/Eventual Consistency میشه)، ولی به خاطر پیچیدگی بالایی که داره، برای پروژههای ساده و معمولی به هیچ وجه توصیه نمیشه.
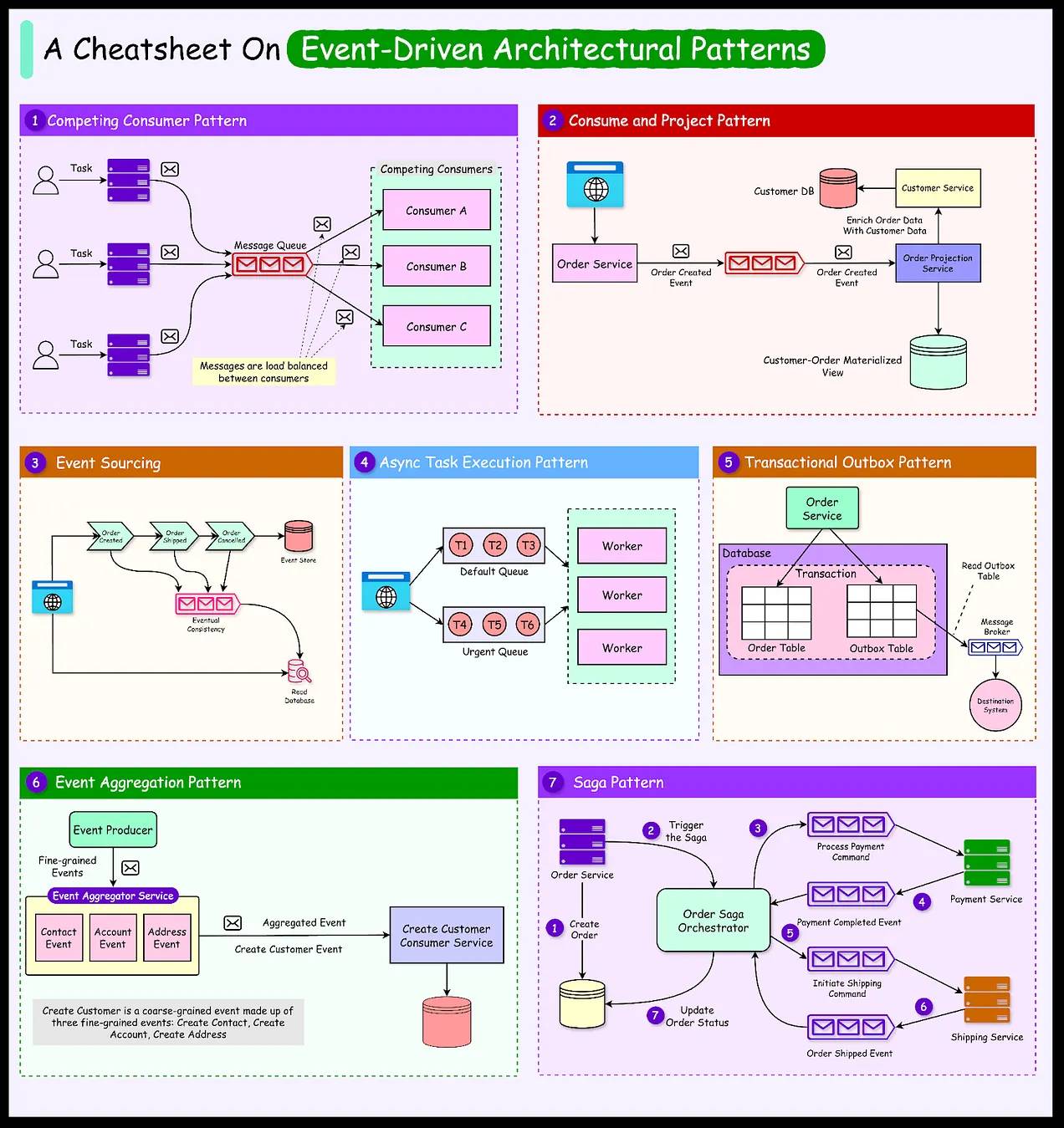
Event-Driven Architecture (EDA)
در معماریهای سنتی مبتنی بر درخواست/request-driven، یک کامپوننت، معمولا به صورت همگام و به طور مستقیم کامپوننت دیگه رو صدا میزنه و منتظر پاسخ میمونه؛ ولی در معماری رویداد-محور (EDA)، این رابطه وارونه میشوه: به جای اینکه یک سرویس، سرویس دیگه رو صدا بزنه، رویدادها/events رو منتشر میکنه که بیانگر اتفاقیه که قبلاً رخ داده یا کاریه که انجام داده. بنابراین، سایر سرویسها بدون اینکه بدونن چه کسی رویداد را منتشر کرده، به اون گوش میدن و در صورت لزوم واکنش نشان میدن.
این رویکرد وابستگی و coupling بین سرویسها رو از بین میبره و به خاطر استفاده از یک واسط پیام (Message Broker)، مقیاسپذیری افقی/horizontal scalability و resiliency فوقالعادهای به سیستم میده. یعنی حتی اگر سرویس دریافتکننده در دسترس نباشه، پیام تو صف میمونه تا بعداً پردازش بشه؛ هرچند دیباگ کردن این سیستمهای توزیعشده و مدیریت ترتیب رویدادها چالشهای خاص خودش رو داره.
این معماری مبنای بسیاری از سیستمهای بزرگ مانند Netflix، Uber و سیستمهای تریدینگه.
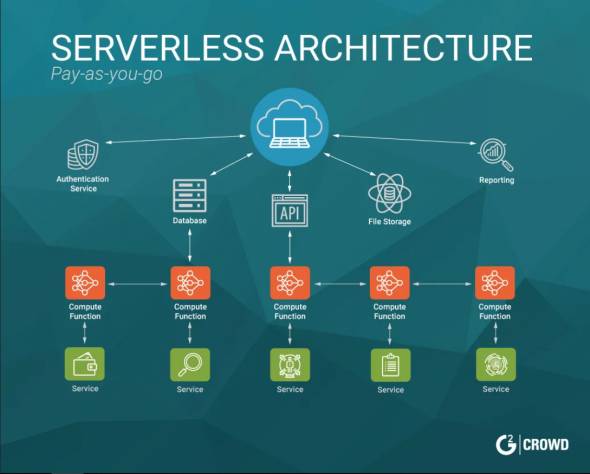
Serverless Architecture
در معماری سنتی، شما باید سرور (مجازی یا فیزیکی) رو تهیه، پیکربندی و مدیریت کنید. در Serverless Architecture، شما فقط کدتون رو مینویسید و پلتفرم ابری (مثل AWS Lambda، Azure Functions یا Google Cloud Functions)، مسئولیت اجرا، scaling و مدیریت زیرساخت رو بر عهده میگیره و مدل پرداخت به صورت micro-billing هست؛ یعنی فقط به اندازه همون چند میلیثانیهای که کدمون اجرا شده پول میدیم و نیازی به سرورهای همیشه روشن نیست.
پس معماری بدون سرور به این معنی نیست که واقعاً سروری وجود نداره، بلکه یعنی مدیریت سختافزار، مقیاسپذیری و نگهداری زیرساخت کاملاً به عهده شرکت ارائهدهنده ابریه و ما به عنوان توسعهدهنده فقط روی نوشتن منطق تجاری کدمون تمرکز میکنیم.
این معماری معمولاً با مدل Function-as-a-Service (FaaS) مثل AWS Lambda پیاده میشه که کدمون فقط در پاسخ به یک رویداد خاص (مثل درخواست HTTP) اجرا میشه.
با این حال، محدودیتهایی مثل زمان اجرای کوتاه و مشکل cold start (تاخیر در اولین اجرای کد بعد از یک مدت بیکاری) از چالشهای اصلی این الگو به حساب میان.
API-first Approach
رویکرد API-first به این تاکید داره که قبل از اینکه حتی یک خط کد بکاند بنویسیم، اول در مورد شکل و مشخصات API با تمام تیمها به توافق میرسیم، اون رو مستند کرده و در specification قرار میدیم و با استانداردهایی مثل OpenAPI یا GraphQL Schema اون رو طراحی میکنیم.
خوبی این روش اینه که تیمهای frontend و backend میتونن با استفاده از دادههای شبیهسازیشده (به کمک mock server) به صورت کاملاً موازی کارشون رو پیش ببرن. این کار هم هماهنگی بین تیمها و سرعت عرضه محصول به بازار رو بالا میبره، هم جلوی ناهماهنگیهای مخرب رو تو مراحل نهایی ادغام و یکپارچهسازی سیستم میگیره.
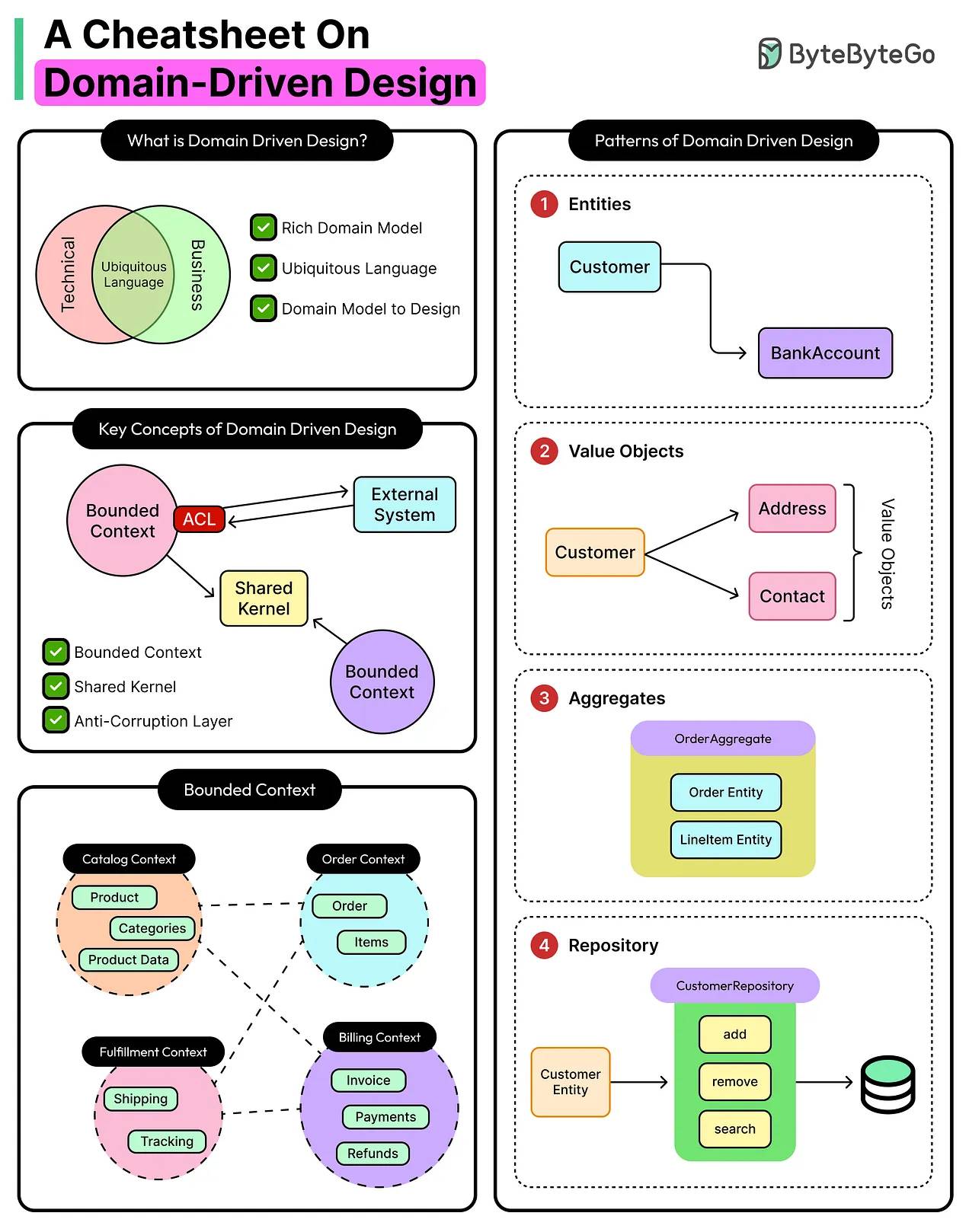
Domain-Driven Design (DDD)
طراحی مبتنی بر دامنه (DDD) یا بهتر بگم دامنهرانه، یک متدولوژی برای مدلسازی سیستمهای نرمافزاری پیچیده بر اساس قلمرو business domain و business logic است، نه بر اساس جزئیات فنی مانند DB یا framework.
این روش، سیستم رو به بخشهای مستقل و کوچکتری به نام bounded context تقسیم میکنه که هر کدوم مدل ذهنی و مفاهیم خاص خودشون رو دارن.
مهمترین اصل DDD در سطح استراتژیک، استفاده از یک زبان یکسان/Ubiquitous Language بین تیم فنی و کارشناسان کسبوکاره تا هیچ ابهامی تو ارتباطات و کدنویسی پیش نیاد. تو سطح تاکتیکی هم با مفاهیمی مثل موجودیتها، value objects و aggregates، منطق کسبوکار رو طوری پیاده میکنه که از تبدیل شدن سیستم به یک ساختار درهمتنیده و مخرب (Big Ball of Mud) جلوگیری بشه.
پیادهسازی DDD معمولاً منجر به یک معماری لایهای تمیز/clean architecture میشه که در اون domain layer کاملاً از لایههای زیرساخت (DB، UI، و...) جدا هست. این جداسازی باعث میشود منطق کسبوکار «قلب» نرمافزار باقی بمونه و تحت تأثیر تغییرات فنی قرار نگیره.
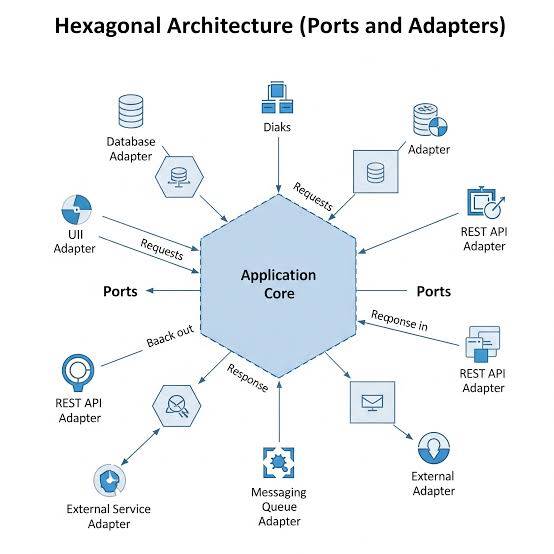
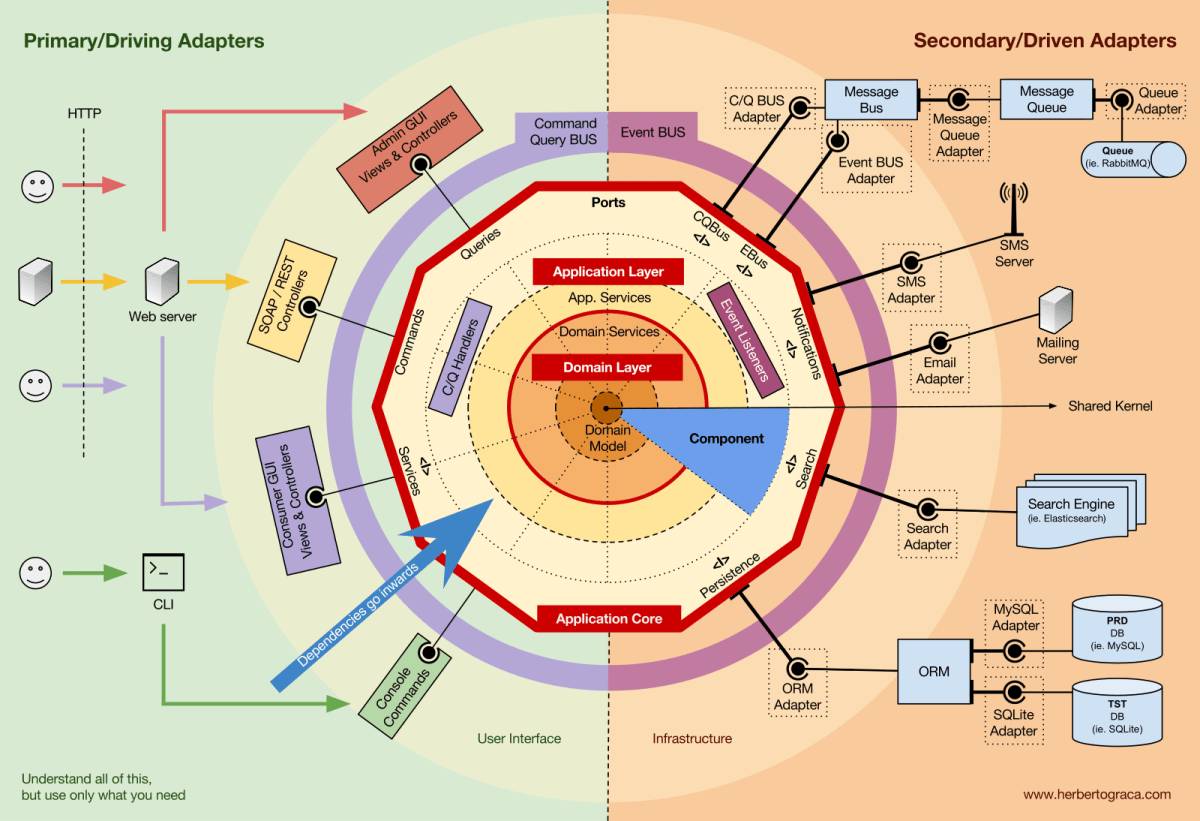
Hexagonal Architecture
معماری ششضلعی که بهش الگوی Ports and Adapters هم میگن، دقیقاً برای این ابداع شده که هسته مرکزی و منطق کسبوکار سیستم رو از تکنولوژیهای بیرونی (مثل DBs و web framewors) کاملاً ایزوله کنه.
تو این الگو که پایه معماری تمیز هم هست، ارتباط سیستم با دنیای بیرون فقط از طریق واسطهای انتزاعی به نام درگاه/port و پیادهسازیهای ملموس اونها یعنی آداپتور/adapter انجام میشه. این ساختار باعث میشه که بتونیم کل منطق هسته رو بدون نیاز به شبکه یا دیتابیس واقعی تست کنیم و اگر روزی خواستیم framework یا DB رو عوض کنیم، این کار رو بدون تغییر دادن حتی یک خط از کدهای هسته انجام بدیم.
پس معماری ششضلعی، برای پروژههای بلندمدتی که نیاز به انعطافپذیری/flexibility، قابلیت نگهداری/maintainability و قابلیت تست/testability بالا دارن، ایدهآله.
پ.ن: مفهوم Ports and Adapters، از اون مفاهیم و نکات کلیدی تو مهندسی نرمافزاره که همونطور که اینجا هم توضیح دادم، portها، واسط/interfaceهای زبان برنامهنویسی هستن که در لایه هسته تعریف میشن و مشخص میکنند که سیستم چه خدماتی باید ارائه بده؛ adapterها هم پیادهسازی این واسطها در لایه زیرساخت هستن.
Event Sourcing
در این الگو، به جای اینکه فقط وضعیت فعلی یک موجودیت رو ذخیره کنیم، تمام رویدادهای غیرقابل تغییری که باعث تغییر وضعیت شدن رو به ترتیب در یک لاگ افزایشی/append-only به نام event store ذخیره میکنیم.
حالا، برای به دست آوردن آخرین وضعیت یک داده، سیستم باید رویدادهای گذشته رو از ابتدا بازپخش کرده و از روی اونها وضعیت رو محاسبه کنه.
اگرچه این کار برای حجم دادههای بالا نیازمند تکنیکهایی مثل ذخیره موقت/snapshot هست، اما مزایای بینظیری مثل داشتن تاریخچه کامل تغییرات و قابلیت بازبینی/auditability، بازگردانی وضعیت سیستم به هر نقطه زمانی در گذشته و هماهنگی کاملاً طبیعی با الگوی CQRS رو بهمون میده.
پ.ن: اتفاقا Uncle Bob در کتاب Clean Architecture، مفهوم event sourcing را به عنوان یکی از کاربردهای functional programming معرفی میکنه و استدلال میکنه که اگر ما به جای ذخیره آخرین وضعیت دادهها، تمام رویدادها را به صورت تغییرناپذیر/Immutable ذخیره کنیم، نه تنها هیچ دادهای را از دست نمیدهیم، بلکه مشکلاتی مثل بنبستها/deadlocks و تداخلهای همزمانی/concurrency در سیستمهای پیچیده به طور کلی حذف میشه.
Low-code/No-code platforms
پلتفرمهای LC/NC سیستمهایی هستن که به توسعهدهندهها و افراد غیرفنی اجازه میدن با استفاده از واسطهای گرافیکی Drag-and-Drop، پیکربندی ساده و با کمترین نیاز به کدنویسی دستی، اپلیکیشن بسازن. ابزارهای No-code بیشتر برای افراد غیرفنی/citizen developers هدفگذاری شدن، در حالی که ابزارهای Low-code به برنامهنویسها این امکان رو میدن که تو بخشهای پیچیدهتر، کدهای سفارشی خودشون رو هم تزریق کنن.
با اینکه این پلتفرمها زمان و هزینه تحویل پروژه رو به شدت کاهش میدن، اما چالشهای بزرگی هم برای معماری سازمان دارن؛ مشکلاتی مثل قفلشدگی شدید به پلتفرم ارائهدهنده/vendor lock-in، رشد اپلیکیشنهای خارج از نظارت امنیتی سازمان (Shadow IT) و ناتوانی در پشتیبانی از تراکنشهای بسیار سنگین باعث میشه که جایگزین کاملی برای توسعه سیستمهای اصلی و پیچیده نباشن.
Business Process Management Systems (BPMS)
در بسیاری از سازمانهای بزرگ، فرآیندهای اصلی کسبوکار از چندین مرحله تشکیل شده که توسط افراد مختلف و گاهی با فاصله زمانی زیاد انجام میشه. سیستمهای BPMS پلتفرمهای نرمافزاری هستن که این فرآیندها را به صورت خودکار و یکپارچه، تو لایههای مختلف کسبوکار، مدیریت و هماهنگ میکنن.
یک BPMS معمولاً از سه لایه اصلی تشکیل شده:
1. موتور فرآیند/Process Engine
2. صفحهکار/Worklist
3. ابزارهای یکپارچهسازی/Integration Tools
این سیستمها معمولاً از استاندارد جهانی BPMN 2.0 استفاده میکنن تا فرآیندها رو به صورت گرافیکی رسم کنن و موتور پردازشگر/process engine مستقیماً همون مدلها رو تفسیر و مسیریابی میکنه.
تو معماریهای مدرن و میکروسرویسی امروزی، BPMSها به عنوان هماهنگکننده مرکزی و orchestrator به کار میرن. ابزارهای قدرتمندی مثل Camunda با بهرهگیری از الگوی Saga، میتونن تراکنشهای توزیعشده طولانیمدت رو مدیریت کنن و اگر خطایی تو طول مسیر رخ داد، با فراخوانی اقدامات جبرانی، پایداری دادهها رو تو کل سیستم حفظ کنن.

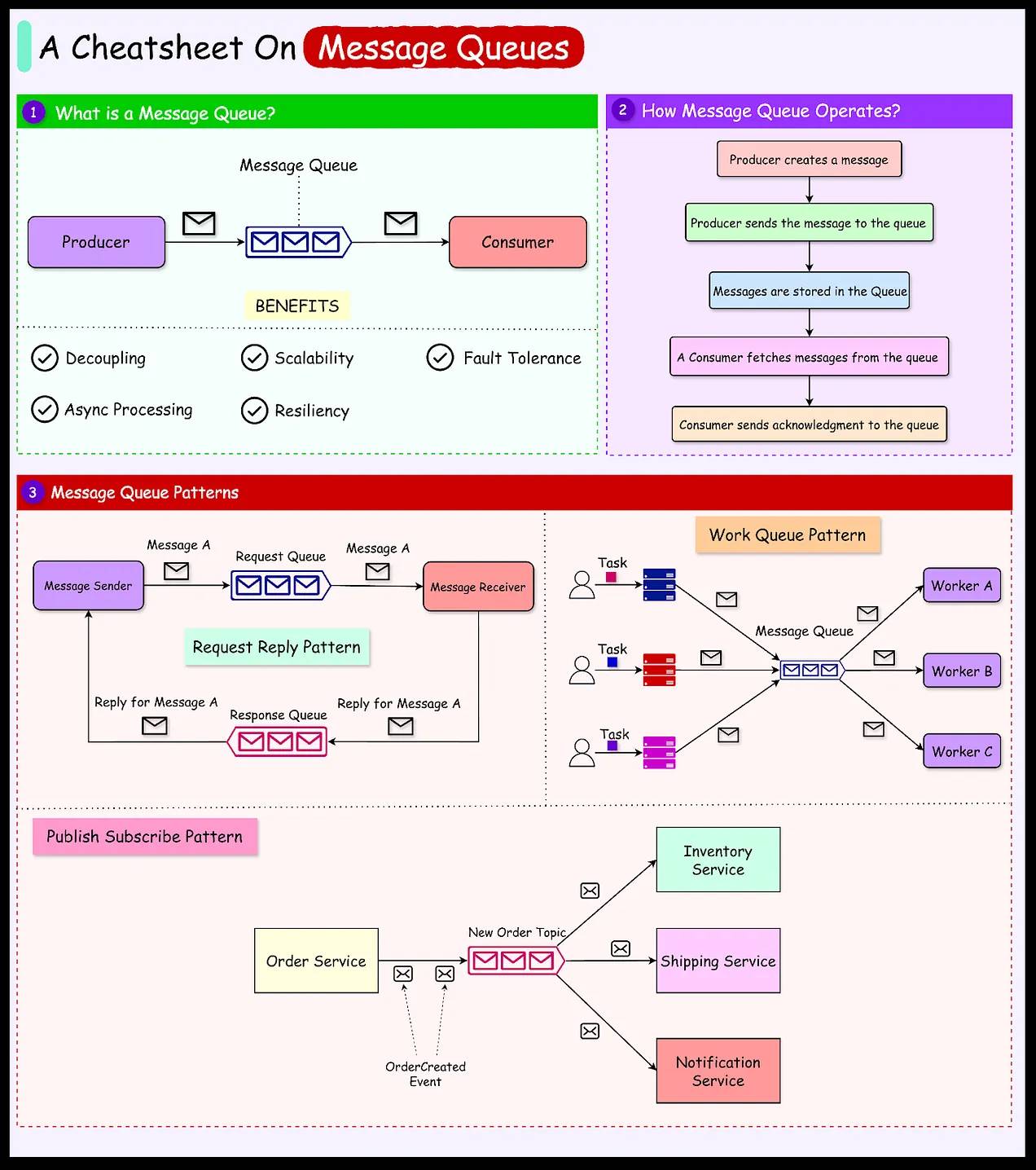
Message Queue
در معماریهای توزیعشده، اگر یک سرویس به طور مستقیم و همگام سرویس دیگه رو صدا بزنه و سرویس مقصد در دسترس نباشه یا کند باشه، کل سیستم دچار مشکل میشه. Message Queue به کمک یک واسط ناهمگام/asynchronous intermediary به جای ارتباط مستقیم، سرویس فرستنده پیام رو در یک صف قرار میده و بدون اینکه منتظر پاسخ باشه، به کارش ادامه میده؛ حالا، هر زمان که سرویس دریافتکننده آماده بود، پیام رو از صف برداشته و پردازش میکنه.
تو این فضا دو ابزار قدرتمند با الگوهای متفاوت داریم: RabbitMQ و Apache Kafka.
ابزار RabbitMQ یک کارگزار پیام کلاسیکه/push-based که پیام رو به دست مصرفکننده میرسونه و بلافاصله بعد از تایید دریافت، اون رو پاک میکنه؛ بنابراین برای ارتباطات بینسرویسی سنتی و مسیریابیهای دقیق عالیه.
ولی Kafka یک پلتفرم استریم توزیعشده است که پیامها رو مثل یک لاگ دائمی روی دیسک ذخیره میکنه/pull-based تا مصرفکنندهها با سرعت خودشون پیامها رو بخونن یا حتی بازپخش کنن. این ویژگی، kafka رو برای پردازش جریانهای دادهای خیلی حجیم و معماریهای رویدادمحور بیرقیب میکنه.
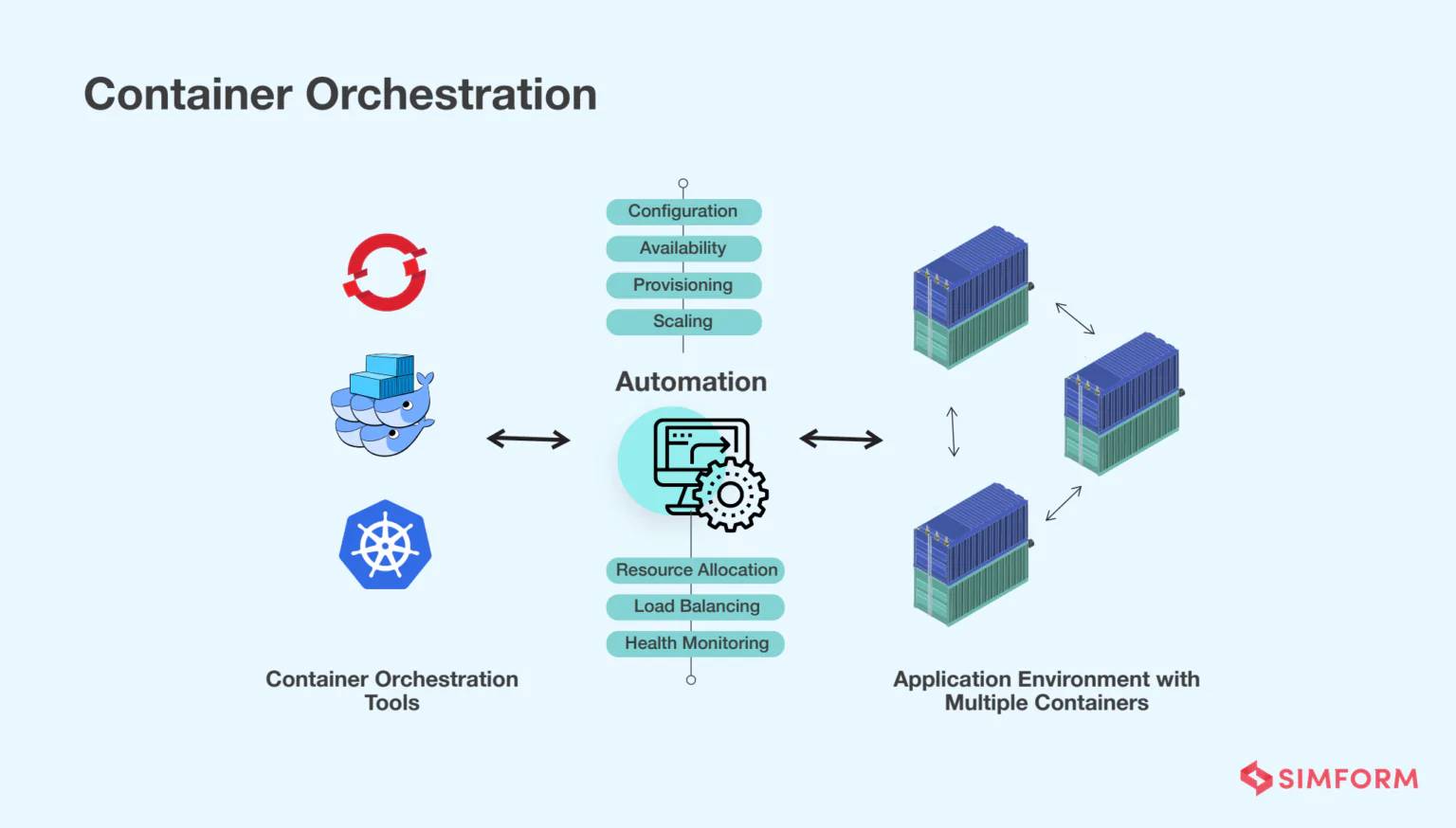
Containers and Container Orchestration
فناوری کانتینرسازی (مثل ابزار Docker) به وجود اومد تا کدهای یک برنامه رو با تمام کتابخونهها و وابستگیهاش تو یک واحد مجزا و ایزوله بستهبندی کنه. کانتینرها برخلاف ماشینهای مجازی (VM)، هسته سیستمعامل میزبان رو به اشتراک میذارن و به همین دلیل بسیار سبکترن و تو کسری از ثانیه اجرا میشن. ولی زمانی که سیستم بزرگ میشه و با دهها یا صدها کانتینر مواجه میشیم، مدیریت دستی اونها عملاً غیرممکنه. اینجاست که پلتفرمهای orchestration مثل Kubernetes وارد عمل میشن. کوبر وظیفه داره که containerها رو auto-scale کرده و بار ترافیکی رو توزیع کنه و اگر یک کانتینر از کار افتاد، بلافاصله اون رو جایگزین کنه (Self-Healing).
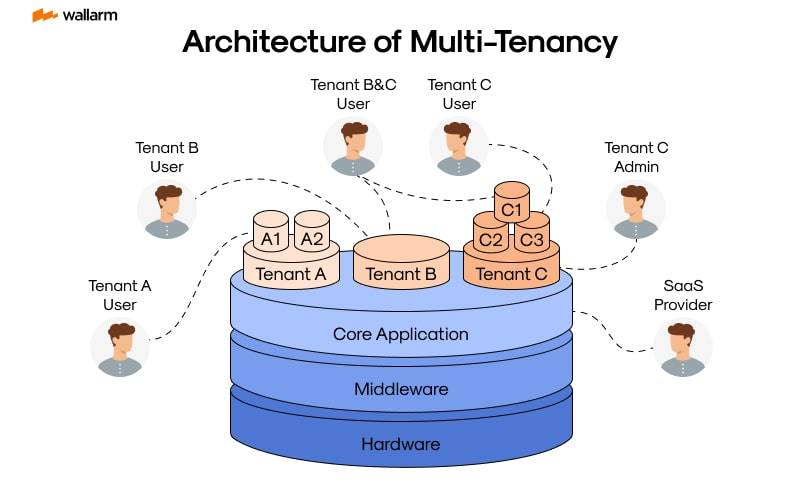
Multi-Tenancy Architecture
این معماری، مبنای سرویسهای ابری و SaaS هست؛ به این شکل که با راهاندازی فقط یک نسخه واحد از نرمافزار، به دهها یا صدها شرکت و سازمان مختلف (مستأجر/tenant) سرویس داده میشه، در حالی که دادههای هر سازمان کاملاً از بقیه جدا و ایزوله است.
برای این جداسازی سه رویکرد وجود داره: داشتن دیتابیس مجزا برای هر مشتری (گران اما بسیار امن)، استفاده از Schema جداگانه در یک دیتابیس مشترک، و یا قرار دادن همه دادهها تو یک جدول و تفکیک کردنشون با یک فیلد شناسایی مثل tenant_id (کمهزینهترین اما نیازمند مدیریت دقیق).
این معماری هزینههای عملیاتی رو به شدت کاهش میده و بهروزرسانی سیستم رو خیلی یکپارچه و راحت میکنه، اما اصلیترین چالش اون جلوگیری از نشت اطلاعات بین tenantهاست.
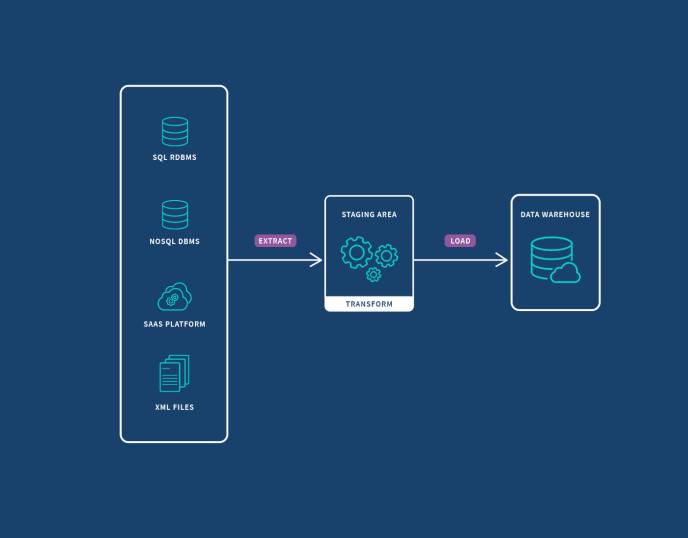
Data Migration
مهاجرت داده یکی از پرریسکترین کارهای مهندسی نرمافزاره و زمانی انجام میشه که بخوایم دیتابیس قدیمی رو تغییر بدیم یا دادهها رو برای شکستن یک معماری یکپارچه به میکروسرویسها تفکیک کنیم.
از اونجا که داده قلب تپنده سیستمه، هر خطایی تو این مسیر میتونه فاجعهبار باشه.
برای این کار معمولاً از سه استراتژی استفاده میشه: رویکرد Big Bang (خاموش کردن سیستم قدیمی و انتقال یکباره دادهها که باعث دانتایم میشه)، رویکرد تدریجی/Trickle (کار کردن موازی سیستم قدیم و جدید مثل الگوی Strangler Fig)، و جذابترین مدل یعنی Zero-Downtime که تو اون بدون توقف سیستم، دادهها به صورت بلادرنگ همگام میشن.
موفقیت تو این فرآیند که مبتنی بر ابزارهای ETL (Extract, Transform, Load) هست، نیازمند پایش مداوم و نوشتن برنامههای دقیق برای بازگشتپذیری و rollback کردن در زمان خطاست.
سخن پایانی
سعی کردم تو این پست، یک نمای کلی و سریع از 20 مفهوم و ترند مهمی که دنیای امروز مهندسی نرمافزار رو شکل میدن، ارائه بدم. همونطور که دیدید، از زیرساخت و کانتینرها گرفته تا الگوهای پیچیدهتری مثل CQRS و Event Sourcing، همه اینها مثل قطعات یک پازل بزرگ هستن که به ما کمک میکنن سیستمهای پایدارتر، مقیاسپذیرتر و تمیزتری بسازیم.
خوندن این مفاهیم پشت سر هم ممکنه کمی سنگین باشه، اما فراموش نکنید که این مقاله فقط یک roadmap بود تا چشمانداز کلی رو ببینیم و در پستهای آینده قراره تمام این الگوها رو زیر ذرهبین ببریم، چالشهای پیادهسازیشون رو تو دنیای واقعی بررسی کنیم و ببینیم چطور میشه ازشون تو معماری پروژههای خودمون استفاده کرد.
مرسی که تا اینجا همراه من بودید.
تا پستهای بعدی، خدانگهدارتون!