سلام رفقا
امید که دلتون شاد باشه
وسط این اوضاع آشفته و نابسامان که خیلی ها عزیزان شون رو تو جنگ از دست دادن و آسیب های جسمی و روحی دیدن، برای من نوشتن تو ویرگول نوعی مسکن و آرام بخش محسوب میشه، شاید بتونم با سرگرم کردن خودم پیرامون مبحث مورد علاقه کاریم یعنی دیتا، یه اثر مثبت هرچند کوچیک به اندازه سر سوزن بزارم، امید که روزای خوب بیاد برای کشورمون و با شادی و نشاط کنار کسایی که دوسشون داریم روزمون رو شب کنیم و شبمون رو روز
به امید اون روز ...
من محمدم، یه علاقه مند به ترکیب مهندسی داده و هوش مصنوعی :-)
تو این نوشتار میخوام Log-Structured Merge Tree رو بهتون معرفی کنم که در دیتابیس محشر کلیک هاوس، ایدهی ایندکس خلوت و ساختار MergeTree از مدلهای log-structured مثل LSM Tree الهام گرفته شده تا نوشتنهای حجیم سریع و پردازش تحلیلی بهینه بشه.
صحبت از کلیک هاوس شد، من اینجا یه رپوزیتوری آموزش محور ازش درست کردم تو گیت هاب و دارم توسعه اش میدم، اگر دوست داشتید می تونید یه نگاهی بهش بندازید :-)

اما دیگه بریم سراغ اصل کارمون:
اگه با دیتابیسهای مدرن مثل Cassandra، RocksDB یا LevelDB کار کرده باشید، احتمالاً اسم LSM Tree یا Log-Structured Merge Tree به گوشتون خورده. این ساختار داده یکی از مهمترین ایدهها در طراحی دیتابیسهای امروزی هستش، مخصوصاً وقتی حجم نوشتن روی دیتابیس مون خیلی زیاد باشه.
در واقع، LSM Tree یه روش هوشمندانه برای ذخیرهسازی دادههامون هستش که تلاش میکنه هزینهی نوشتن روی دیسک رو تا حد ممکن کاهش بده و در عوض، همهچیز رو به شکل دستهای و بهینه انجام بده.
خب این از مقدمه، حالا بریم سراغ تعریف مبحث مون:
Log-Structured Merge Tree یک ساختار دادهی ترکیبیه که برای مدیریت کلید-مقدارها (Key-Value) طراحی شده و هدف اصلیش، بهینهسازی عملیات نوشتن روی دیتابیس در حجم بالا است.
ایدهی اصلی ساده ست:
به جای اینکه هر داده همون لحظه روی دیسک بشینه (که بسیار کند و پرهزینه ست)، دادهها اول تو حافظه جمع میشن و بعد بهصورت دستهای روی دیسک منتقل میشن
اگه با فریم ورک اسپارک آشنایی داشته باشید احتمال یاد بچ پراسسینگ افتادین که البته اونجا میکروبچ هم داشتیم
LSM Tree معمولاً از دو بخش اصلی تشکیل میشه:
دادهها ابتدا وارد RAM میشن
معمولاً ساختار مرتب مثل Skip List یا Tree دارن
بسیار سریع برای نوشتن و جستجو
دادهها به صورت مرتب و دستهای ذخیره میشن
به فایلهای مرتب (Sorted Runs) تقسیم میشن
وقتی حافظه پر بشه، دادهها یکجا به دیسک منتقل و با دادههای قبلی ادغام (Merge) میشن
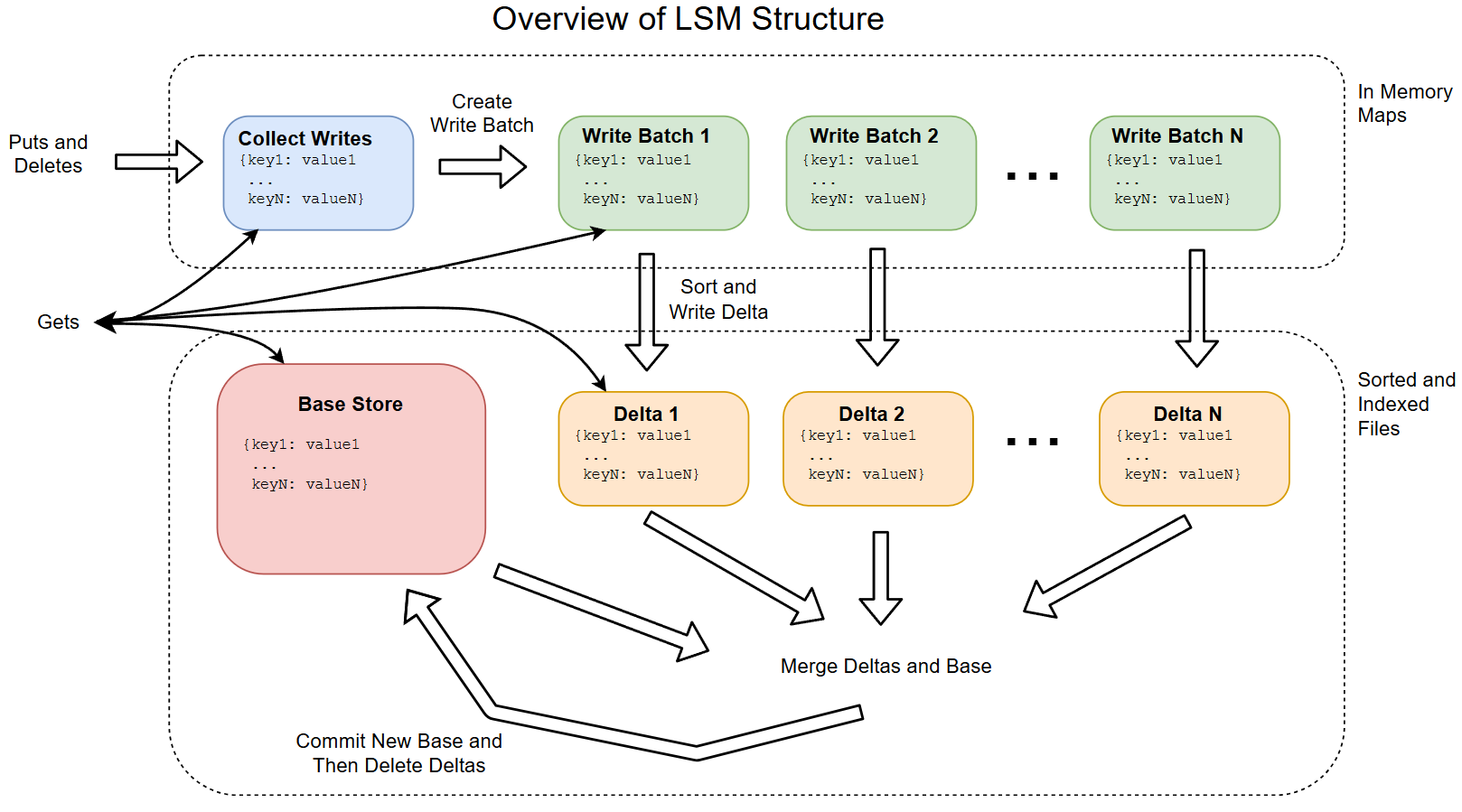
راز سرعت LSM Tree تو یه چیزه:
نوشتن ترتیبی (Sequential Write) به جای نوشتن تصادفی (Random Write)
دیسکها (خصوصاً HDDها) تو نوشتنهای تصادفی خیلی کُندن، اما تو نوشتن ترتیبی بسیار سریعترن. LSM Tree میاد و دقیقاً از همین موضوع استفاده میکنه.
وقتی دیتای جدید وارد میشه (خوش اومدی داداش، صفا آوردی، دیروز دوست، امروز آشنا :-)
اول تو حافظه ذخیره میشه
یک لاگ (Write-Ahead Log) برای جلوگیری از از دست رفتن داده ثبت میشه
وقتی حافظه پر شد، دادهها به دیسک flush میشن
در نهایت با دادههای قبلی merge میشن
نکته مهم:
حذفها هم واقعی نیستن، بلکه با یک علامت (tombstone) ثبت میشن
اما برای پیدا کردن یک کلید:
اول حافظه بررسی میشه
اگر نبود، لایههای دیسک یکییکی چک میشن
معمولاً از Bloom Filter برای سریع رد کردن فایلهای نامرتبط استفاده میشه
نتیجه:
اگه کلید موجود باشه: خیلی سریع پیدا میشه
اگه وجود نداشته باشه: ممکنه چند لایه بررسی شه
برای گرفتن بازهای از دادهها:
همه لایهها باید بررسی شن
نتایج با هم merge شن
دادههای تکراری حذف و آخرین نسخه نگه داشته میشه
این نوع عملیات معمولاً از point lookup کندتره، مخصوصاً اگر دیتامون اسپارس باشه
سرعت مشحر در write
مناسب برای دیتای حجیم و real-time
استفاده بهینه از دیسک
مناسب برای سیستمهای لاگ و تحلیلی
read ممکن است کندتر بشه
نیاز به mergeهای دورهای (compaction)
مصرف CPU و I/O در زمان مِرجِ دادهها
LSM Tree پایهی بسیاری از دیتابیسهای مدرنه، مثل:
ClickHouse
Cassandra
LevelDB
RocksDB
HBase
هر جایی که نوشتن زیاد و مداوم داریم، این ساختار عالی عمل میکنه.
LSM Tree یه سولوشن هوشمندانه برای یکی از بزرگترین مشکلات دیتابیسهاست،
اونم اینکه: چطور سریع بنویسیم بدون اینکه دیسک را نابود کنیم؟
با تبدیل نوشتنهای پراکنده به نوشتنهای بَچ، این ساختار تونسته تعادل خوبی بین سرعت، مقیاسپذیری و کارایی ایجاد کنه.
مرسی مقاله رو خوندین
سوالی بود من در خدمتم رفقا :-)