
مدلهای زبانی بزرگ (Large Language Models) که نمایندهی پیشرفت در حوزه پردازش زبان طبیعی (Natural language processing) هستند قادر به تولید متن شبیه به انسان و درک ساختارهای زبانی پیچیده میباشند. این مدلهای هوش مصنوعی پیشرفته، از جمله مدلهای GPT سری OpenAI و Gemini گوگل، نحوه تعامل انسان با فناوری را به طور کلی تغییر می دهند و از تولید محتوای خودکار تا استفاده از آن ها به عنوان دستیاران مجازی شخصی امکانات متعددی را فراهم میکنند. در این مقاله، به بررسی نحوه استفاده و ایجاد مدلهای زبان بزرگ خواهم پرداخت.
مقاله های مرتبط:
- چت جی پی تی: فرصت ها، مخاطرات و کاربرد ها: بررسی فرصت ها، تهدید ها و کاربرد های هوش مصنوعی Chat GPT در ۱۰ حوزه اصلی تجارت، صنعت، آموزش و مقایسه مدل زبانی GPT-3.5 و GPT-4.- هنر Prompt Engineering: مهارت بکارگیری چت جی پی تی: یک Prompt دستور یا جمله ای عملی است که برای برقراری ارتباط با مدلهای زبان هوش مصنوعی استفاده میشود تا پاسخی مرتبط، بهینه و دقیق دریافت شود.
- چت جی پی تی: معلم سیلیکونی من: در این مقاله، تجربیاتم را در استفاده از Chat GPT و نحوه تعامل با آن در جهت بهبود فرایند یادگیری و برنامه ریزی را مورد بحث قرار میدهم.
- گوگل جمینای: راهنمای جامع مهندسی پرامپت: در این مقاله، مبانی مهندسی پرامپت، تکنیکها و بهینهسازی تعامل با مدلهای زبانی گوگل را مرور میکنم.
- گوگل جمینای: ۵ قدم تا رستگاری دیجیتال: در این مقاله با الهام از آموزههای ارائه شده در Google Prompting Essentials Specialization by Coursera به مرور مبانی پرامپت نویسی می پردازم.

مدل زبان بزرگ یا Large Language Model به نوعی از مدل های هوش مصنوعی اشاره دارد که برای درک، تولید و دستکاری زبانی طراحی شده اند. این مدل ها با اندازه وسیع، پیچیدگی و توانایی در یادگیری الگوها و تولید متن منسجم مشخص می شوند. ویژگی های کلیدی مدل های زبان بزرگ عبارتند از:
هر مدل زبانی بزرگ (LLM) معمولاً بر روی مجموعه داده های عظیم شامل میلیاردها کلمه یا متن آموزش می بینند. اندازه مدل به تعداد پارامترهای آن اشاره دارد که می تواند از صدها میلیون تا ده ها میلیارد متغیر باشد.
هر مدل زبانی بزرگ (LLM) اغلب بر روی مجموعه های بزرگ متن با استفاده از تکنیک یادگیری بدون نظارت از قبل آموزش داده می شوند. در مرحله پیش-آموزش، مدل یاد می گیرد که کلمه بعدی را در یک دنباله (sequence) با توجه به بافت و وزن کلمات قبل پیش بینی کند.

پس از مرحله پیش-آموزش، مدل های زبانی بزرگ را میتوان با استفاده از روشهای یادگیری نظارت شده، روی وظایف یا حوزههای خاص تنظیم کرد. تنظیم-دقیق به مدل اجازه می دهد تا با وظایف زبانی خاص مانند ترجمه، خلاصه سازی یا تجزیه و تحلیل احساسات سازگار شود.
مدل های زبانی بزرگ توانایی تولید متنی شبیه انسان را بر اساس دستورهای ورودی ارائه شده توسط کاربران دارند. مولد بودن به مدل زبانی بزرگ در استفاده ی طیف وسیعی از کاربردهای خلاقانه از جمله تولید متن، داستان سرایی و... کمک می کند.
بیشتر مدل های زبانی بزرگ (LLM) از طریق یادگیری خود نظارتی، اغلب با استفاده از پیش بینی احتمال کلمه بعدی، آموزش می بینند. وظیفه اصلی شامل پیش بینی توزیع احتمال کلمه بعدی با توجه به کلمات قبلی است. زمینه بسیار مهم است. همانطور که در ابزارهایی مانند Chat GPT دیده میشود مدلها معمولا از مجموعههای عظیم متن (کتاب، اینترنت و...) یاد میگیرند، در نتیجه عملکرد چشمگیری دارند.
سری GPT (مدلهای ترانسفورماتورِ پیشآموزشی) که توسط OpenAI توسعه یافتهاند، از محبوبترین و پرکاربردترین LLMها محسوب میشوند. این مدلها (مثل GPT-4o و نسخههای جدیدتر) روی حجم بزرگی از دادههای متنی آموزش دیدهاند و درک و تولید زبان طبیعی، خلاصهسازی، ترجمه، برنامهنویسی و پاسخگویی مکالمهای را با کیفیت بالا انجام میدهند. در نسخههای جدید، پشتیبانی از چندوجهی (ترکیب متن با تصویر و گاهی صوت)، استفاده از ابزارها (مثل جستوجو/تحلیل فایل)، و کنترلپذیری بهترِ خروجی برای کاربردهای واقعی مانند پشتیبانی مشتری، تولید محتوا و دستیارهای کاری هم پررنگتر شده است.
Gemini خانوادهی مدلهای زبانیِ گوگل است که با تمرکز روی کاربردهای عمومی و سازمانی توسعه داده میشود. این مدلها معمولاً در یک اکوسیستم بزرگتر (ابزارهای ابری و سرویسهای گوگل) بهکار میروند و روی «چندوجهی بودن» و اتصال به ابزارها/جریانهای کاری تأکید دارند. Gemini در کارهایی مثل تحلیل اسناد، پاسخگویی دقیقتر در وظایف اداری، تولید متن و کدنویسی، و یکپارچگی با سرویسهای سازمانی گزینهی رایجی است.
Claude خانوادهی مدلهای شرکت Anthropic است که معمولاً به لحن طبیعی، نوشتار تمیز و رعایت بهتر دستورالعملها شناخته میشود. تمرکز این خانواده غالباً روی ایمنی، کاهش خروجیهای پرریسک، و کمک به کارهای متنیِ بلند (مثل جمعبندی گزارشها، بازنویسی حرفهای، تولید متنهای رسمی و تحلیل) است. برای تیمهایی که کیفیت نوشتار، سازگاری با سیاستها و تعامل قابل اتکا در مکالمه برایشان مهم است، Claude انتخاب پرتکراری محسوب میشود.
Grok مدلهای شرکت xAI است که بیشتر با رویکرد «دستیار گفتوگومحور» و پاسخهای سریع و سرراست معرفی میشود. در برخی ارائهها، تأکید این خانواده روی تعامل لحظهای و تجربهی مکالمهای متفاوت (گاهی با لحن غیررسمیتر) است. بهطور کلی، Grok برای پرسشوپاسخ، خلاصهسازی و کمکهای عمومی مناسب است و بسته به نسخه/محصولی که استفاده میکنید، امکانات جانبی مثل اتصال به ابزارها هم میتواند نقش مهمی داشته باشد.
DeepSeek نام خانوادهای از مدلهاست که در سالهای اخیر بهخصوص در جامعهی توسعهدهندگان و حوزهی کدنویسی/استدلال مورد توجه قرار گرفته است. این خانواده معمولاً با تمرکز بر کارایی و عملکرد قوی در وظایف فنی (مثل حل مسئله، تولید کد، و تحلیل مرحلهای) شناخته میشود و در برخی سناریوها گزینههای متنباز یا قابل استقرار (بسته به نسخه/مجوز) هم اهمیت پیدا میکنند. اگر مخاطب وبلاگ شما فنی است، اشاره به استفاده در «کدنویسی و تحلیل» برای معرفی DeepSeek مفید است.
Qwen خانوادهی مدلهای زبانیِ علیبابا است که بهویژه در کاربردهای چندزبانه و سناریوهای سازمانی/محصولی دیده میشود. این مدلها در وظایف رایج مانند تولید محتوا، چت، خلاصهسازی، استخراج اطلاعات از متن، و کدنویسی استفاده میشوند و بسته به نسخه، ممکن است گزینههای متنباز یا قابل استقرار برای تیمهایی که کنترل زیرساخت برایشان مهم است هم ارائه شود. برای معرفی Qwen، تأکید روی «چندزبانه بودن» و «کاربردهای سازمانی» معمولاً دقیق و مفید است.
در کارهایی مانند ترجمه زبان، تجزیه و تحلیل احساسات و طبقه بندی متن.
تولید متن برای برنامه هایی مانند چت بات ها، دستیاران مجازی و پلتفرم های تولید محتوا.
نویسندگان و هنرمندان از LLM برای کمک به تولید ایده ها، تهیه پیش نویس داستان ها و کشف ارتباط بین سبک های ادبی یا ایجاد یک سبک جدید استفاده می کنند.
LLM ها در محیط های تحقیقاتی برای تجزیه و تحلیل داده های متنی، ایجاد فرضیه ها به دانشمندان در حوزه های مختلف کمک می کنند.
به طور کلی، مدل های زبان بزرگ نشان دهنده پیشرفت قابل توجهی در هوش مصنوعی است که پیامدهای گسترده ای برای ارتباطات، خلاقیت و حل مسئله دارد.
مدلهای زبان بزرگ (LLM) به عنوان نوع خاصی از مدل زبان با ویژگیهای کمی و کیفی متمایز تعریف میشوند:
در هر مدل زبانی بزرگ پارامترهای مدل نسبت به مدل های زبان دیگر متفاوت است (معمولا بسیار بیشتر از نمونه های قبلی است (ده ها تا صدها میلیارد)).
ویژگیهای نوظهور مانند یادگیری Zero-shot (بعد تر Few-shot)، قابلیتهایی را در مدل زبانی بزرگ آشکار می کنند که در مدلهای کوچکتر دیده نمیشوند.

به توانایی تکمیل کار توسط مدل یادگیری ماشین که به صراحت برای آن آموزش ندیده است یادگیری zero-shot می گویند. مدل های زبانی بزرگ از طریق یادگیری خود-نظارتی (self-supervised learning) به این امر دست می یابند. یادگیری خود-نظارتی که پاردایم یادگیری با نظارت سنتی را تغییر داد، به مدل اجازه می دهد تا وظایف خود را بدون نیاز به یادگیری با مثال های واضح نشان داده شده توسط انسان پیش بینی و درک کند.
۱. ایجاد یک مدل زبانی بزرگ جدید (ایجاد پارامترهای جدید)
۲. مهندسی دستورات یا Prompt Engineering
۳. تنظیم-دقیق یا Fine-Tuning (تغییر پارامترهای مدل)
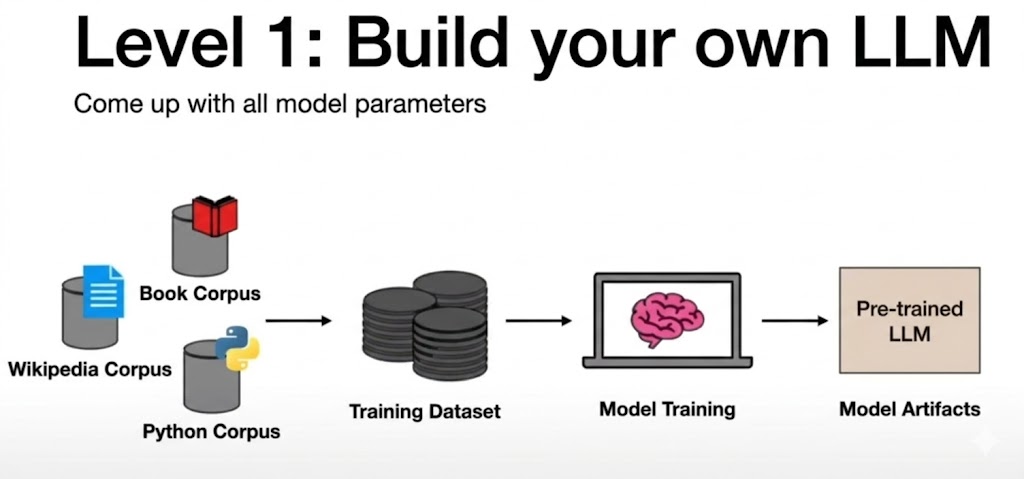
ایجاد یک LLM سفارشی با تعریف تمام پارامترهای مدل آغاز می شود. در ابتدا نیاز است مجموعه بزرگی از داده ها را به دست آورید، سپس مجموعه داده آموزشی را پردازش کنید، یادگیری خود نظارتی را برای آموزش مدل انجام دهید و از این مدل زبانی بزرگ از پیش آموزش دیده (pre-trained) به عنوان نقطه شروع استفاده کنید.
استفاده از پرامپت بدون تغییر پارامترهای مدل (تمرکز بر برنامه نویسی). استفاده از پرامپت برای به حداکثر رساندن عملکرد مدل زبانی بزرگ نوعی هنر تجربی است.
- راه آسان: استفاده از پرامپت با استفاده از رابط کاربری (مانند وب سایت ChatGPT، Gemini و …)
- روشی کمتر آسان: تعامل با مدل زبانی بزرگ با استفاده از OpenAI API یا Hugging Face Transformers Library. مثال عملی زیر استفاده از LangChain و Python برای ساخت یک grader خودکار بر اساس Prompt Engineering ارائه می دهد.

در حالی که مدلهای پایه خود-نظارت (pre-trained) میتوانند با کمک Prompt Engineering عملکرد چشمگیری را در طیف گستردهای از وظایف از خود نشان دهند، اما همچنان پیشبینیکننده کلمات هستند و ممکن است پاسخ هایی ایجاد کنند که کاملاً مفید یا دقیق نیستند. از محدودیت های Prompt Engineering وابستگی کامل به مدل، کارایی در برابر هزینه و برتری بالقوه مدل های تخصصی کوچکتر در مقابل مدل های جامع هست.

تنظیم-دقیق یا Fine-Tuning به معنای گرفتن یک مدل از قبل آموزش دیده (pre-trained LLM) و آموزش حداقل یک پارامتر مدل داخلی برای یک کار خاص است. در زمینه LLM ها، آنچه که معمولاً انجام می شود تبدیل یک مدل پایه همه منظوره (مانند GPT-3) به یک مدل تخصصی برای یک مورد خاص (مانند ChatGPT) است. برای مثال، بیایید تکمیلهای Davinci (مدل GPT-3 پایه) و text-davinci-003 (یک مدل تنظیمشده دقیق) را با هم مقایسه کنیم.

بهبود پارمتر های مدل عملکرد مدل پایه را بهبود می بخشد. حتی یک مدل کوچکتر اما تنظیم دقیق شده بر روی مجموعهای از وظایف معمولا از مدلهای بزرگتر (احتمالا گرانتر) عملکرد بهتری دارد. این موضوع توسط Open AI با مدل نسل اول "Instruct GPT" به روشنی نشان داده شد. جایی که پاسخ های مدلInstruct GPT با ۱.۳ میلیارد پارامتر به رغم کوچکتر بودن ( تقریبا ۱۰۰ برابری) نسبت به مدل پایه GPT-3 با ۱۷۵ میلیارد پارامتر ترجیح داده شد.
اگرچه بیشتر مدل های زبانی بزرگ که امروزه با آنها در تعامل هستیم مثل GPT-4O مدل های self-supervised نیستند، باز هم مشکلاتی در نتیجه استفاده از مدل بهبود یافته برای یک مورد استفاده خاص وجود دارد. یکی از مهمترین مشکلات این است که مدل های زبانی بزرگ محدودیت اطلاعات دارند. بنابراین، ممکن است مدل در وظایفی که به طیف وسیع دانش پایه یا برعکس به اطلاعاتی خاص در حوزه مورد نظر نیاز دارد عملکرد ضعیفی داشته باشد. مدلهای بهبود یافته میتوانند این مشکل را با تنظیم-دقیق اطلاعات در طول فرآیند آموزش حل کنند. این همچنین نیاز به پر کردن موارد ورودی با زمینه اضافی را از بین میبرد و در نتیجه میتواند به کاهش هزینه آموزش مدل منتج شود.
یک مدل زبانی بزرگ از قبل آموزش دیده (pre-trained LLM) به دست آورده، پارامترهای مدل را با نمونه های خاص کار (آموزش تحت نظارت یا تقویتی) به روز و مدل تنظیم-دقیق شده را به کار می گیریم. مزیت کلیدی این رویکرد این است که مدلها میتوانند عملکرد بهتری داشته باشند در حالی که به نمونههای برچسبگذاری شده دستی (supervised learning Labeling) به مراتب کمتری متکی هستند.
برای بهینهسازی یک مدل، سه روش عمومی وجود دارد. این روشها به طور انحصاری نیستند و هر ترکیبی از این سه رویکرد میتواند برای بهینهسازی مدل استفاده شود.
۱. یادگیری خودنظارتی / Self-supervised Learning
۲. یادگیری تحت نظارت / Supervised Learning
۳. یادگیری تقویتی / Reinforcement Learning
یادگیری خودنظارتی شامل آموزش مدل بر اساس ساختار ذاتی داده های آموزشی است. در زمینه LLM، آنچه که معمولاً به نظر می رسد به دنباله ای از کلمات (یا نشانه ها، به طور دقیق تر)، پیش بینی کلمه بعدی (توکن) داده می شود.
میتوان از مدلهای زبانی بزرگ از پیش آموزش دیده برای تنظیم دقیق مدل استفاده کرد. یک مورد استفاده بالقوه ایجاد مدلی است که می تواند با توجه به مجموعه ای از متون نمونه، سبک نوشتاری یک فرد را تقلید کند.
راه بعدی و شاید محبوبترین راه fine-tuning مدل یادگیری تحت نظارت است. یادگیری تحت نظارت شامل آموزش یک مدل در جفت ورودی-خروجی برای یک کار خاص است. به عنوان مثال می توان از instruction tuning با هدف بهبود عملکرد مدل در پاسخ به prompt کاربر نام برد.
مرحله کلیدی در یادگیری تحت نظارت، تنظیم مجموعه داده آموزشی است. یک راه ساده برای انجام این کار، ایجاد جفت پرسش و پاسخ و ادغام آنها در یک الگو است.
مثال: زوج پرسش و پاسخ:
سوال: سی و پنجمین رئیس جمهور ایالات متحده چه کسی بود؟
جواب: جان اف کندی.
"""Please answer the following question. Q: {Question} A: {Answer}"""
استفاده از prompt template مهم است زیرا مدل های پایه مانند GPT-3 اساسا "تکمیل کننده اسناد" هستند. به این معنی که با توجه به متنی، مدل متن بیشتری تولید می کند که از نظر آماری در آن زمینه با احتمال بیشتری معنا پیدا می کند. در واقع اینجا به نوعی فریب مدل زبانی برای حل مشکل از طریق Prompt Engineering اتفاق می افتد چرا که متن حاوی پاسخ موجود است.
مراحل یادگیری تحت نظارت (سطح بالا)
روش زیر یک روش سطح بالا برای تنظیم دقیق مدل تحت نظارت است. (هر یک از این مراحل میتواند مقالهای برای خود باشد)
۱. وظیفه ای دقیق را انتخاب کنید (مانند خلاصهنویسی، پاسخ به سؤال، طبقهبندی متن)
۲. مجموعه داده های آموزشی را آماده (یعنی جفت ورودی-خروجی (100 تا 10 هزار) ایجاد کنید) و داده ها را پیش پردازش کنید.
۳. یک مدل پایه را انتخاب کنید (با مدل های مختلف آزمایش کنید و یکی را انتخاب کنید که بهترین عملکرد را در کار مورد نظر دارد).
۴. از طریق یادگیری تحت نظارت fine-tuning را انجام می دهیم.
۵. ارزیابی عملکرد مدل
در نهایت، می توان از یادگیری تقویتی (به اختصار RL) برای fine-tuning مدل ها استفاده کرد. RL از یک مدل پاداش برای هدایت آموزش مدل پایه استفاده می کند. این میتواند اشکال مختلفی داشته باشد، اما ایده اصلی آموزش مدل پاداش برای امتیاز دادن به پاسخ های مدل زبانی است به طوری که ترجیحات human label را منعکس کند. سپس مدل پاداش را می توان با یک الگوریتم یادگیری تقویتی (مثلاً بهینه سازی خط مشی پروگزیمال (PPO)) ترکیب کرد تا مدل از پیش آموزش دیده را تنظیم کند.
نمونه ای از نحوه استفاده از یادگیری تقویتی توسط مدل Instruct GPT توسط OpenAI برای مدل نشان داده شده است که از طریق ۳ مرحله کلیدی توسعه یافته است.
مرحله ۱. در ابتدا جفتهای سوال-پاسخ (prompt-response pairs) با کیفیت بالا ایجاد کنید و یک مدل از پیش آموزشدیده را با استفاده از یادگیری تحت نظارت fine-tune کنید. (تقریبا ۱۳۰۰۰ پرامپت آموزشی)
توجه: می توانید (به طور متناوب) با مدل از پیش آموزش دیده به مرحله ۳ بروید.
مرحله ۲. از مدل fine-tune شده برای تولید پاسخ ها استفاده کنید و برچسبگذاران انسانی (human labelers) پاسخها را بر اساس ترجیحات خود رتبهبندی کنند. از این تنظیمات برای آموزش مدل پاداش استفاده کنید. (تقریبا ۳۳۰۰۰ درخواست آموزشی)
مرحله ۳. از مدل پاداش و یک الگوریتم یادگیری تقویتی (به عنوان مثال Proximal Policy Optimization (PPO)) برای تنظیم دقیق مدل استفاده کنید. (تقریبا ۳۱۰۰۰ پرامپت آموزشی)
استراتژی فوق منجر به ایجاد پاسخ های قابل توجه و هزینه عملکرد کمتر مدل زبانی بزرگ می شود و به طور کلی نسبت به مدل پایه ارجحیت بیشتری دارد. این کاهش عملکرد به عنوان مالیات همسویی نیز شناخته می شود.
در fine-tuning یک مدل با تعداد پارامترهای بین ۱۰۰ میلیون تا ۱۰۰ میلیارد باید به هزینه های محاسباتی فکر کرد. برای این منظور، یک سوال مهم این است که کدام پارامترها را (دوباره) آموزش می دهیم؟ با وجود کوهی از پارامترها، ما انتخاب های بی شماری برای تمرین داریم. در اینجا، من روی سه گزینه عمومی که پارامتر از بین آنها انتخاب می شود تمرکز می کنم.
آموزش مجدد همه پارامترها اولین گزینه آموزش تمام پارامترهای مدل داخلی است. در حالی که این گزینه ساده است (از لحاظ مفهومی)، اما از نظر محاسباتی گران ترین است. علاوه بر این، یک مشکل شناخته شده با تنظیم کامل پارامتر، پدیده فراموشی است. اینجاست که مدل اطلاعات مفیدی را که در آموزش اولیه خود یادگرفته فراموش میکند. یکی از راههایی که میتوانیم جنبه های منفی گزینه ۱ را کاهش دهیم، مسدود کردن بخش بزرگی از پارامترهای مدل است که ما را به گزینه ۲ میرساند.
یادگیری انتقالی (Transfer Learning (TL)) به حفظ ویژگیهای مفیدی که مدل از آموزشهای گذشته در هنگام اعمال مدل در یک کار جدید آموخته است ایجاد می شود. Transfer Learning به طور کلی شامل انداختن "سر" یک شبکه عصبی (NN) و جایگزینی آن با یک شبکه جدید (به عنوان مثال افزودن لایه های جدید با وزن های تصادفی) است.
نکته: سر در شبکه عصبی شامل لایه های نهایی آن است که نمایش های داخلی مدل را به مقادیر خروجی ترجمه می کند.
در حالی که دست نخورده ماندن اکثر پارامترها هزینه محاسباتی هنگفت آموزش یک LLM را کاهش می دهد، TL ممکن است لزوماً مشکل فراموشی را حل نکند. برای مدیریت بهتر هر دوی این مسائل، میتوانیم به مجموعهای از رویکردها روی آوریم.
شامل تقویت یک مدل پایه با تعداد نسبتاً کمی از پارامتر های قابل آموزش است. نتیجه کلیدی این متد fine-tuning عملکرد قابل مقایسه با fine-tuning کامل را در کسری ناچیز از هزینه محاسباتی و ذخیره سازی نشان می دهد. PEFT خانواده ای از تکنیک ها را در بر می گیرد که یکی از آنها روش محبوب Low-Rank Adaptation یا به اختصار LoRA است. ایده اصلی پشت LoRA انتخاب زیرمجموعه ای از لایه ها در یک مدل موجود و تغییر وزن آنها بر اساس معادله زیر است.

در حالی که fine-tuning مدل موجود به منابع محاسباتی و تخصص فنی نیازمند هست، مدلهای fine-tune شده (کوچکتر) میتوانند از مدلهای پایه از پیش آموزشدیده (بزرگتر) برای یک مورد خاص بهتر عمل کنند، حتی زمانی که بکارگیری استراتژی های prompt engineering هوشمندانه. علاوه بر این، با تمام منابع open-source LLM موجود، fine-tune یک مدل برای یک کاربرد سفارشی را آسانتر می کند.
مدلهای زبانی بزرگ (LLMs) نمایانگر پیشرفتی قابل توجه در حوزه هوش مصنوعی و پردازش زبان طبیعی هستند. این مدلها که برای درک، تولید و دستکاری زبان طراحی شدهاند، با ویژگیهای کلیدی مانند اندازه وسیع (شامل میلیاردها پارامتر)، پیچیدگی بالا، و توانایی در یادگیری الگوها و تولید متن منسجم مشخص میشوند. مدلهایی مانند سری GPT از OpenAI و سری Gemini از گوگل نشاندهنده قابلیتهای چشمگیر این فناوری در تولید محتوای شبیه به انسان و درک ساختارهای زبانی پیچیده هستند.
آموزش این مدلها معمولاً شامل پیشآموزش بر روی مجموعههای عظیم داده متنی با استفاده از یادگیری بدون نظارت است که در آن مدل یاد میگیرد کلمه بعدی را در یک دنباله پیشبینی کند. این مدلها نحوه تعامل انسان با فناوری را به طور کلی تغییر میدهند و امکانات متعددی از تولید محتوای خودکار تا استفاده به عنوان دستیاران مجازی را فراهم میآورند.
تمایز LLMها نسبت به مدلهای زبانی قبلی هم در تفاوتهای کمی (پارامترهای بسیار بیشتر) و هم در تفاوتهای کیفی نهفته است. ویژگیهای نوظهور مانند یادگیری Zero-shot (توانایی انجام کار بدون آموزش صریح برای آن) که از طریق یادگیری خودنظارتی به دست میآید، قابلیتهایی را در LLMها آشکار میکند که در مدلهای کوچکتر دیده نمیشوند.
استفاده و بهبود این مدلها در سه سطح اصلی انجام میشود: مهندسی دستورات (Prompt Engineering) بدون تغییر پارامترها، تنظیم دقیق (Fine-Tuning) مدلهای از قبل آموزشدیده برای وظایف خاص، و ایجاد یک مدل زبانی بزرگ جدید. تنظیم دقیق میتواند عملکرد مدل پایه را بهبود بخشد و حتی مدلهای کوچکتر اما تنظیم شده دقیق را قادر سازد تا از مدلهای بزرگتر عملکرد بهتری داشته باشند، ضمن اینکه به حل مشکل محدودیت اطلاعات مدلها در حوزههای تخصصی کمک میکند و با استفاده از روشهایی مانند یادگیری تحت نظارت یا یادگیری تقویتی انجام میشود.
تکنیکهایی مانند PEFT نیز به کاهش هزینههای محاسباتی تنظیم دقیق کمک میکنند. در نهایت، LLMها کاربردهای گستردهای در زمینههایی مانند درک زبان طبیعی، تولید محتوا، نویسندگی خلاق، و تحقیق و توسعه یافتهاند، که نشاندهنده پتانسیل عظیم آنها برای ارتباطات، خلاقیت و حل مسئله است.
مدل زبانی بزرگ چیست؟
مدل زبانی بزرگ (Large Language Model) نوعی هوش مصنوعی است که برای درک، تولید و دستکاری زبان طراحی شده است. این مدلها با حجم وسیعی از دادهها آموزش میبینند و قادر به پیشبینی کلمه بعدی در یک دنباله متنی هستند.
کاربردهای مدلهای زبانی بزرگ چیست؟
مدلهای زبانی بزرگ در ترجمه زبان، تولید محتوا، نویسندگی خلاق و تجزیه و تحلیل دادههای متنی استفاده میشوند. آنها میتوانند به عنوان دستیاران مجازی و ابزارهای خودکارسازی محتوا مورد استفاده قرار گیرند.
تفاوت مدلهای زبانی بزرگ با مدلهای زبانی قبلی چیست؟
مدلهای زبانی بزرگ پارامترهای بیشتری دارند و قابلیتهای نوظهوری مانند یادگیری بدون نیاز به دادههای آموزشی (zero-shot learning) را نشان میدهند. این مدلها میتوانند وظایف پیچیدهتری را بدون نیاز به آموزش صریح انجام دهند.
مراحل بهبود مدلهای زبانی بزرگ چگونه است؟
بهبود مدل (Fine-tuning) شامل تنظیم دقیق مدل از قبل آموزشدیده برای یک وظیفه خاص است. این فرآیند با استفاده از یادگیری تحت نظارت یا تقویتی انجام میشود و مدلهای تخصصیتری برای کاربردهای خاص ایجاد میکند.