
پرامپت یا دستور متنی، اساساً ورودی ای است که شما به یک مدل زبانی بزرگ (Large Language Model) میدهید تا پاسخی را بر اساس آن تولید کند. نکته جالب این است که برای نوشتن پرامپت، نیازی به تخصص فنی در زمینه هوش مصنوعی یا برنامهنویسی ندارید و هر کسی میتواند این کار را انجام دهد. با این حال، طراحی پرامپتی که بهترین نتیجه را به همراه داشته باشد، میتواند چالشبرانگیز باشد. کیفیت پاسخ مدل به عوامل متعددی بستگی دارد، از جمله:
مدل زبانی بزرگ مورد استفاده
دادههایی که مدل با آن آموزش دیده
تنظیمات فنی مدل (مثل پارامتر دما)
کلماتی که شما انتخاب میکنید
لحن و سبک نوشتار متن
نحوه ارائه اطلاعات در پرامپت
به همین خاطر، مهندسی پرامپت (یا فرایند بهبود پرامپتها) معمولاً نیازمند سعی و خطا و تکرار است. پرامپتهای نامناسب میتوانند باعث شوند مدل پاسخهای گنگ، اشتباه یا بیربط تولید کند. هرچند هنگام تعامل با چتباتهایی مانند جمینای در حال نوشتن پرامپت هستید (منظور هنگام استفاده از وبسایت جمینای)، اما این مقاله بیشتر بر تکنیکهای پیشرفتهتر پرامپتنویسی برای مدل جمینای از طریق پلتفرم Vertex AI و API تمرکز دارد، چرا که این روشها امکان کنترل دقیقتری روی تنظیمات مدل را فراهم میکنند. در ادامه، به بررسی روشهای مختلف پرامپتنویسی، نکات کاربردی برای حرفهای شدن در این زمینه و برخی مشکلاتی که ممکن است با آنها روبرو شوید، پرداخته خواهد شد.
مقاله های مرتبط:
- چت جی پی تی: فرصت ها، مخاطرات و کاربرد ها: بررسی فرصت ها، تهدید ها و کاربرد های هوش مصنوعی Chat GPT در ۱۰ حوزه اصلی تجارت، صنعت، آموزش و مقایسه مدل زبانی GPT-3.5 و GPT-4.
- هنر Prompt Engineering: مهارت بکارگیری چت جی پی تی: یک Prompt دستور یا جمله ای عملی است که برای برقراری ارتباط با مدلهای زبان هوش مصنوعی استفاده میشود تا پاسخی مرتبط، بهینه و دقیق دریافت شود.
- چت جی پی تی: معلم سیلیکونی من: در این مقاله، تجربیاتم را در استفاده از Chat GPT و نحوه تعامل با آن در جهت بهبود فرایند یادگیری و برنامه ریزی را مورد بحث قرار میدهم.
- چت جی پی تی: مقدمه ای بر مدل های زبانی بزرگ (LLMs): در این مقاله، به بررسی نحوه استفاده و ایجاد مدلهای زبان بزرگ می پردازیم.
- گوگل جمینای: ۵ قدم تا رستگاری دیجیتال: در این مقاله با الهام از آموزههای ارائه شده در Google Prompting Essentials Specialization by Coursera به مرور مبانی پرامپت نویسی می پردازم.
برای درک مهندسی پرامپت، ابتدا باید به یاد بیاوریم که مدلهای زبانی بزرگ اساساً ماشینهای پیشبینی هستند. یک مدل زبانی متن ورودی را دریافت کرده و بر اساس الگوهایی که در طول آموزش خود دیده است، پیشبینی میکند که کلمه (یا توکن) بعدی چه باید باشد. این فرآیند بارها تکرار میشود و هر توکن پیشبینیشده به انتهای متن اضافه میشود تا به پیشبینی توکن بعدی کمک کند.
وقتی شما یک پرامپت مینویسید، در واقع تلاش میکنید تا فرآیند پیشبینی مدل زبانی را به سمتی هدایت کنید که دنباله توکنهای مورد نظر پاسخهای دقیق و مرتبط با پرامپت شما را تولید کند. این شامل آزمایش و خطا برای یافتن بهترین عبارتبندی، بهینهسازی اندازه پرامپت و بررسی تاثیر سبک نگارش و ساختار آن بر روی وظیفه خاصی است که از مدل میخواهید انجام دهد.
تخمین سرانگشتی تعداد توکن ها: این روش دقت کمتری دارد اما برای یک تخمین سریع مفید است.
زبان انگلیسی: به طور متوسط، یک توکن تقریباً معادل 4 کاراکتر یا حدود 0.75 کلمه است (یعنی 100 توکن تقریباً 75 کلمه است).
زبان فارسی: این نسبت متفاوت است. به دلیل ساختار زبان فارسی و نحوه شکستن کلمات (گاهی پیشوندها، پسوندها یا حتی بخشهایی از یک کلمه به عنوان توکن جداگانه در نظر گرفته میشوند)، معمولاً تعداد توکنها به ازای هر کلمه یا هر کاراکتر بیشتر از زبان انگلیسی است. یک تخمین بسیار تقریبی میتواند این باشد که هر کلمه فارسی بین 1.5 تا 3 توکن یا بیشتر باشد، اما این عدد بسیار متغیر است.
پرامپتها میتوانند برای انجام طیف گستردهای از کارها مانند خلاصهکردن متون طولانی، استخراج دادههای کلیدی، پاسخگویی به سوالات، دستهبندی محتوا، ترجمه بین زبانها یا زبانهای برنامهنویسی، نوشتن کد، ایجاد مستندات فنی و حتی استدلال منطقی استفاده شوند.
فرآیند مهندسی پرامپت معمولاً با انتخاب مدل زبانی مناسب آغاز میشود (لازم است پرامپتهای خود را برای هر مدل زبانی بزرگ بهطور خاص تنظیم کنید). همچنین علاوه بر متن پرامپت، آزمایش کردن تنظیمات مختلف مدل (مانند پارامتر "دما" یا "top-k") نیز برای رسیدن به نتیجه مطلوب ضروری است.
اکثر مدل های زبانی بزرگ گزینههای مختلفی برای کنترل نحوه تولید خروجی ارائه میدهند. برای اینکه پرامپت شما به بهترین نتیجه برسد، لازم است این تنظیمات را متناسب با کاربرد خود بهینه کنید.
یکی از تنظیمات بسیار مهم، حداکثر طول خروجی است که مشخص میکند مدل اجازه دارد حداکثر چند توکن در پاسخ خود تولید کند.
توجه: باید در نظر داشت که تولید توکنهای بیشتر نیازمند محاسبات سنگینتر توسط مدل زبانی است. این به معنی مصرف انرژی بیشتر، احتمالاً زمان پاسخدهی طولانیتر و در نهایت، هزینه بالاتر است.
نکته قابل توجه این است که صرفاً کاهش دادن سقف طول خروجی، باعث نمیشود مدل بهطور خودکار خلاصهتر یا موجزتر بنویسد. بلکه فقط باعث میشود تولید متن پس از رسیدن به آن حد متوقف شود، حتی اگر جمله یا مفهوم ناقص بماند. بنابراین، اگر به پاسخهای کوتاه نیاز دارید، احتمالاً باید خودِ پرامپت را طوری طراحی کنید که مدل را به سمت ایجاز و اختصار هدایت کند.
محدود کردن طول خروجی به خصوص در استفاده از برخی تکنیکهای پیشرفته پرامپتنویسی اهمیت پیدا میکند، زیرا در این روشها ممکن است مدل پس از ارائه پاسخ اصلی، به تولید توکنهای غیرضروری ادامه دهد که با تعیین سقف مناسب میتوان از آن جلوگیری کرد.
به عنوان مثال در کامپیوتر های شخصی باید به محدودیت LM Studio و همچنین محدودیت خود مدل توجه کرد تا دچار گلوگاه (bottleneck) نشویم. مثلا در هنگام دانلود مدل جما (گوگل) در قسمت Model Information سایت Huggingface نسبت به محدودیت های مدل توضیحاتی ارايه شده است:

در قسمتی از متن به حداکثر تعداد توکنهایی که مدل جما ۲۷ بیلیون پارامتر میتواند به عنوان ورودی (Total input context) بگیرد، بدون در نظر گرفتن خروجی ۱۲۸ هزار توکن است و در مقابل خروجی (Total output context) آن محدود به ۸۱۹۲ توکن می باشد.
اما در اجرای شخصی مدل در روی کامپیوتر شخصی و برنامه LM Studio باید توجه داشت:
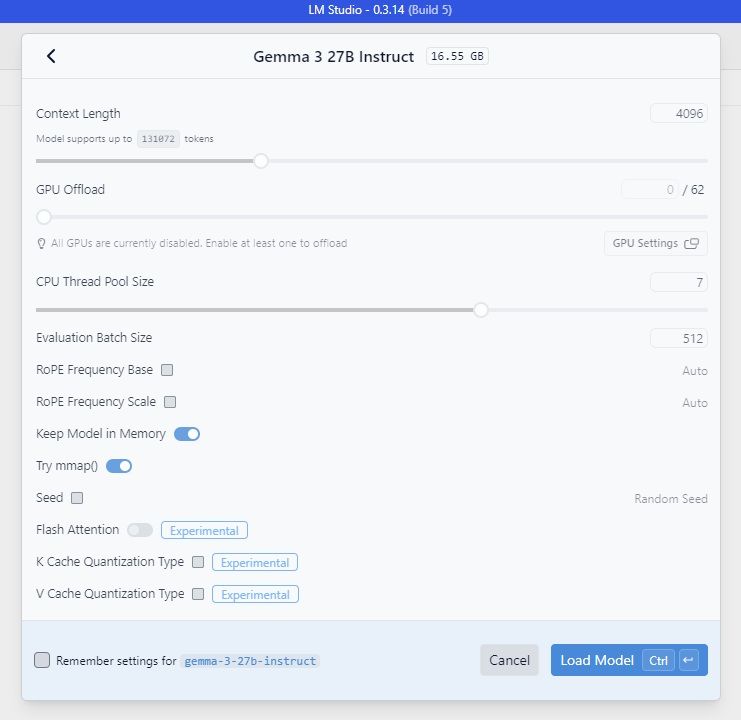
در بالای تصویر Model supports up to 131072 tokens نشان از مقدار پیش فرضی به میزان ۱۳۱۰۷۲ توکن است که نشان دهنده توانایی پردازش تا حداکثر ۱۳۱۰۷۲ توکن در هر بار پردازش دارد.
اما نوار Context Length حداکثر مقدار واقعیای توکن که مدل در این Load برای context مجاز میداند را نشان می دهد که ۴۰۹۶ توکن است. اگرچه این مقدار میتواند به صورت اسمی تا ۱۳۱۰۷۲ باشد اما به دلایل زیر خیلی پایینتر از حداکثر مقدار تعریف شده مدل انتخاب می شود:
صرفهجویی در رم و منابع سیستم
سرعت بیشتر در پردازش
عدم نیاز به کانتکستهای خیلی بلند برای اکثر وظایف روزمره
توجه داشته باشید که context length برابر است با مجموع تعداد توکنهای ورودی و تعداد توکنهایی که مدل قرار است تولید کند:
context length = number of input tokens + number of output tokens
وقتی جمینای پاسخی تولید میکند، مستقیماً یک کلمه (توکن) خاص را به عنوان کلمه بعدی "انتخاب" نمیکند. در عوض، برای تمام کلمات ممکن در دایره لغات خود، یک احتمال محاسبه میکند که آن کلمه، کلمه بعدی در جمله باشد. سپساز میان این احتمالات، کلمه نهایی برای افزودن به پاسخ، "نمونهگیری" میشود. یعنی بر اساس این احتمالها، یک انتخاب صورت میگیرد (کلمات با احتمال بالاتر شانس بیشتری برای انتخاب شدن دارند). برای اینکه بتوانید روی این فرآیند نمونهگیری و در نتیجه، خلاقیت یا دقت پاسخ Gemini تاثیر بگذارید، تنظیمات رایجی وجود دارد:
پارامتر دما (Temperature)
پارامتر Top-K
پارامتر Top-P
این سه پارامتر، نحوه پردازش احتمالات محاسبه شده و انتخاب نهایی توکن بعدی را کنترل میکنند. تنظیم دقیق خروجیهای هوش مصنوعی تولیدی با تغییر تنظیمات ابزار برای کاهش خطاهای احتمالی (hallucinations) و تولید خروجیهای مفیدتر امکان پذیر است.
نمونهبرداری را مانند برداشتن یک تکه کوچک از یک پازل بزرگتر تصور کنید. وقتی هوش مصنوعی متن تولید میکند، همهی کلمات یا جملات ممکن را همزمان بررسی نمیکند. در عوض، چند احتمال را بر اساس دادههایی که آموزش دیده نمونهبرداری میکند. پارامترهای نمونهبرداری مثل حفاظهایی هستند که این فرآیند را تحت تاثیر قرار میدهند و به شما اجازه میدهند اندازهی مجموعه گزینههایی را که ابزار هوش مصنوعی تولیدی هنگام ساخت خروجی انتخاب میکند، گسترش دهید یا محدود کنید. پارامتری که احتمال انتخاب گزینهها در این مجموعه را تعیین میکند، دما نام دارد. میتوانید آن را مثل این بدانید که به ابزار هوش مصنوعی خود دستور میدهید که پاسخها چقدر محدود و سرراست یا چقدر خلاقانه، باز یا غیرمنتظره باشند، یا چیزی بین این دو.
فرض کنید میخواهید تصمیم بگیرید چه چیزی بخورید. یک منوی گزینه دارید، اما نمیدانید کدام را انتخاب کنید، بنابراین یک تاس میاندازید. (کلمه "die" شکل مفرد کلمه"dice" است.) میتوانید به غذای مورد علاقهتان سه وجه از تاس را بدهید، اولویت بعدی دو وجه و سوم یک وجه — یا میتوانید به هر کدام دو وجه بدهید. دما تعیین میکند که چقدر احتمال دارد چیزی غیرمنتظره امتحان کنید.
پارامتر "دما" به عنوان یک تنظیم کلیدی در جمینای به شما امکان میدهد میزان تصادفی بودن خلاقیت در پاسخهای تولید شده را کنترل کنید. این پارامتر بر نحوه انتخاب کلمه (توکن) بعدی در فرآیند ساخت پاسخ تأثیر میگذارد:
دمای پایین (نزدیک به ۰): وقتی دما را پایین تنظیم میکنید، جمینای تمایل دارد پاسخهای قطعیتر، متمرکزتر و قابل پیشبینیتری ارائه دهد. این حالت برای مواقعی مناسب است که به دنبال یک پاسخ دقیق و مشخص هستید (مثلاً در خلاصهسازی یا پاسخ به سوالات واقعیتمحور یا ریاضی). دمای ۰ (صفر) (یا Greedy Decoding به معنای حالت حریصانه) تقریباً همیشه محتملترین کلمه بعدی را انتخاب میکند و کمترین میزان تصادفی بودن را دارد.
دمای بالا: (نزدیک به ۲) با افزایش دما، پاسخها متنوعتر، خلاقانهتر و گاهی غیرمنتظرهتر میشوند. این تنظیم برای کارهایی مثل طوفان فکری، نوشتن داستان یا تولید ایدههای جدید مفید است. هرچه دما بالاتر برود، احتمال انتخاب کلمات کمتر رایج نیز بیشتر افزایش مییابد و خروجی به سمت تصادفی شدن پیش میرود.
به طور خلاصه، میتوانید عملکرد "دما" در جمینای را شبیه به نحوه کارکرد پارامتر دما در تابع "سافتمکس" (SoftMax) در یادگیری ماشین در نظر بگیرید. دمای پایینتر، توزیع احتمال را تیز تر (تمرکز روی محتملترین گزینهها)، و دمای بالاتر آن را پهن تر میکند (شانس بیشتری به گزینههای کمتر محتمل میدهد).
تابع سافتمکس (SoftMax): یک تابع ریاضی است که یک لیست (وکتور) از اعداد حقیقی دلخواه را به عنوان ورودی میگیرد و آن را به یک لیست از احتمالات تبدیل میکند. تمام اعداد در لیست خروجی، مقادیری بین ۰ و ۱ خواهند بود و مجموع تمام اعداد در لیست خروجی دقیقاً برابر با ۱ میشود.
این تابع با استفاده از عملیات نمایی (به توان رساندن با پایه عدد e یا نپر)، مقادیر بزرگتر در ورودی را نسبت به مقادیر کوچکتر بسیار برجستهتر میکند و سپس نتایج را نرمالایز میکند تا مجموعشان ۱ شود.
کاربرد اصلی:
- طبقهبندی چند کلاسه (Multi-class Classification): مهمترین کاربرد سافتمکس در یادگیری ماشین و بهویژه در شبکههای عصبی است. وقتی یک مدل باید پیشبینی کند که ورودی به کدام یک از چند دسته ممکن تعلق دارد (مثلاً تشخیص اینکه تصویر مربوط به گربه، سگ، یا پرنده است)، لایه خروجی مدل معمولاً امتیازاتی برای هر دسته تولید میکند. تابع سافتمکس این امتیازات خام را به احتمالات تبدیل میکند (مثلاً: گربه ۷۰٪، سگ ۲۵٪، پرنده ۵٪) و دستهای که بالاترین احتمال را دارد، به عنوان پاسخ نهایی مدل انتخاب میشود.
- مکانیزم توجه (Attention Mechanism): در مدلهای پیشرفتهتر مانند ترنسفورمرها (که اساس مدلهایی مثل جمینای)، از سافتمکس برای محاسبه وزنهای توجه استفاده میشود تا مشخص شود مدل هنگام پردازش یک بخش از ورودی، باید به کدام بخشها بیشتر توجه کند.
پس به طور خلاصه، سافتمکس راهی برای تبدیل امتیازات به یک توزیع احتمال قابل تفسیر است که عمدتاً برای تصمیمگیری در مسائل طبقهبندی با بیش از دو گزینه کاربرد دارد.
تصور کنید که دارید برای دوستی تعریف میکنید که آن روز صبح چه کارهایی انجام دادهاید. جملهای که با «This morning, I went to the» شروع میشود، میتواند به شکلهای مختلفی ادامه پیدا کند، اما احتمال اینکه کلمات بعدی «grocery store» یا «parking lot» باشند بیشتر از «haunted house» یا «moon» است. با تغییر دما میتوانید میزان تصادفی بودن خروجی ابزار هوش مصنوعی را تنظیم کنید.
برای روشنتر شدن این مفهوم، دوباره به جمله مثال برگردیم: «This morning, I went to the». بر اساس تحلیل حجم زیادی از متنها، ابزار هوش مصنوعی احتمالات کلمات بعدی را به این شکل تعیین کرده است:
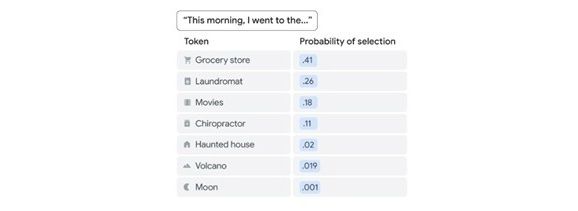
کلمه "grocery store" (خواربارفروشی) بالاترین احتمال (۰.۴۱) را دارد، به این معنی که ابزار آن را بهترین گزینه برای تکمیل جمله میداند. تنظیم دما بر نحوه نمونهبرداری ابزار از این لیست احتمالات تأثیر میگذارد.
دمای پایین (مثلاً ۰.۱) باعث میشود ابزار به شدت کلماتی را که بالاترین امتیاز احتمال را دارند، مانند "grocery store" در این سناریو، ترجیح دهد.
دمای بالا (مثلاً ۲.۰) تصادفی بودن و خلاقیت بیشتری را به پاسخ ابزار اضافه میکند و احتمال انتخاب کلمهای با احتمال کمتر، مانند "haunted house" (خانه جنزده) را بیشتر میکند.
در نهایت، تنظیم دمای یک ابزار هوش مصنوعی تعیین میکند که آیا ابزار به احتمال زیاد به موارد آشنا و مورد انتظار پایبند باشد یا ریسک کند و خروجی غیرمنتظرهتری ارائه دهد. میتوانید این تنظیمات را در API بیشتر مدلهای هوش مصنوعی مولد پیکربندی کنید، اما هنگامی که یک مکالمه چت جدید را باز میکنید، تنظیمات به حالت پیشفرض باز میگردند.
در حالی که امتیاز دما احتمال انتخاب یک پاسخ فردی توسط ابزار هوش مصنوعی مولد را تعیین میکند، سایر پارامترهای نمونهبرداری تعیین میکنند که ابزار هوش مصنوعی مولد از چند پاسخ میتواند انتخاب کند. دو ابزار دیگر در جمینای برای کنترل دقیقتر نحوه انتخاب توکن بعدی در پاسخها وجود دارد:
پارامتر Top-K
پارامتر Top-P
این دو تنظیم، روشهایی برای نمونهگیری (سمپلینگ) هستند که به شما کمک میکنند تا دایره کلماتی که جمینای میتواند به عنوان کلمه بعدی انتخاب کند را بر اساس احتمال آنها محدود کنید. هدف استفاده از این پارامتر ها نیز مانند دما، تنظیم میزان تنوع و خلاقیت در مقابل تمرکز و دقت خروجی جمینای است.
وقتی از Top-K استفاده میکنید، شما عدد K را تعیین میکنید (مثلاً K=10).
یعنی جمینای قبل از انتخاب کلمه بعدی، فقط K عدد از محتملترین کلمات را در نظر میگیرد و انتخاب نهاییاش را از میان همین گروه K تایی انجام میدهد و به شما امکان میدهد نتایج مورد نظر خود را با دقت بیشتری تنظیم کنید.
تنظیم مقدار top-k روی حداقل ۱ (یا تنظیم دما روی ۰) همیشه محتملترین نتیجه را تضمین میکند که به آن "رمزگشایی حریصانه" (greedy decoding) میگویند. این خروجی دیگر تصادفی نیست، بلکه قطعی است، به این معنی که هر بار از یک ورودی یکسان، نتیجه یکسانی تولید میشود.
مقدار top-k پایینتر دامنه گزینههای موجود برای خروجی را محدود میکند، که میتواند به کاهش توهمات (hallucinations) کمک کند. هنگامی که در حال انجام تحقیقات بازار هستید اما نتایج منطقی نیستند، زمان آن است که مقدار top-k را کاهش دهید.
مقدار top-k بالاتر میتواند نتایج شگفتانگیزی را تولید کند که برای تفکر خارج از چارچوب مفید است. اگر در حال آماده شدن برای راهاندازی یک سرویس جدید (یا تشکیل یک تیم مسابقه) هستید و به دنبال نامی هستید که واقعاً جذاب باشد، مقدار top-k بالاتر ممکن است منجر به یک پیشرفت شود.
- مقدار K بزرگتر: به جمینای اجازه میدهد از بین گزینههای بیشتری انتخاب کند و پاسخ متنوعتری بدهد.
- مقدار K کوچکتر: انتخابها را محدودتر کرده و پاسخ متمرکزتر و قابل پیشبینیتر میشود. حالت K=1 دقیقاً معادل انتخاب قطعیترین گزینه یا حالت حریصانه (greedy decoding) است.
در حالی که مقدار top-k تعداد توکنهایی را که هوش مصنوعی مولد از میان آنها انتخاب میکند، تعیین میکند، مقدار top-p آن مجموعه را با استفاده از احتمال ترکیبی کلی بیشتر اصلاح میکند. هر توکن دارای امتیاز احتمال بین ۰ و ۱ است (آستانه احتمال تجمعی P (عددی بین ۰ و ۱، مثلاً P=0.9)) که شانس انتخاب تصادفی آن توسط هوش مصنوعی مولد را در پاسخ خود اندازهگیری میکند.
جمینای تنها از توکنها (با شروع از محتملترین و به ترتیب نزولی) انتخاب میکنند تا زمانی که مجموع امتیازات احتمال آنها به مقدار top-p داده شده برسد، که روش دیگری برای گفتن به ابزار است که از آن چه میخواهید (کلمه بعدی فقط از میان کلماتی که در این لیست موقت قرار گرفتهاند، انتخاب (نمونهگیری) میشود).
نمونهبرداری را مانند جستجوی یک کتاب عاشقانه کمدی جدید برای خواندن در کتابخانه تصور کنید: ممکن است ۱۰ کتاب مختلف را از قفس بردارید (این همان امتیاز top-k شماست)، اما سپس انتخاب خود را بر اساس اینکه کدام کتابها به بهترین وجه با ترجیح شما مطابقت دارند، بیشتر اصلاح میکنید، و اینجا جایی است که top-p وارد میشود. در امتیاز top-p بسیار پایین 0.1، تضمین شده است که پرفروشترین کتاب محبوب را میخوانید، اما امتیاز top-p بالاتر مانند 0.8 ممکن است منجر به یک شگفتی دلپذیر از یک انتخاب کمتر شناخته شده شود.
در تنظیم پیشفرض ۱.۰، مقدار top-p هیچ تأثیری بر نمونهبرداری ندارد.
مقدار top-p پایینتر (کمتر از ۱.۰) کماحتمالترین پاسخها را از بررسی ابزار هوش مصنوعی مولد حذف میکند. هنگام درخواست از یک ابزار هوش مصنوعی مولد برای پردازش آمار و ارائه تجزیه و تحلیل برای پاسخ به یک سوال خاص، مقدار top-p پایینتر ممکن است بهترین کارایی را داشته باشد.
مقدار top-p بالاتر به ابزار هوش مصنوعی مولد اجازه میدهد تا آزادانهتر بین پاسخها انتخاب کند، که میتواند به کارهایی که نیاز به مقایسه بین نتایج مختلف دارند کمک کند. اگر در تصمیمگیری برای نوع رویداد تبلیغاتی که آگاهی از برند شما را افزایش میدهد، گیر کردهاید، تکرار ورودی خود با مقدار top-p بالاتر طیف وسیعتری از پیشنهادات را برای شما به ارمغان میآورد.
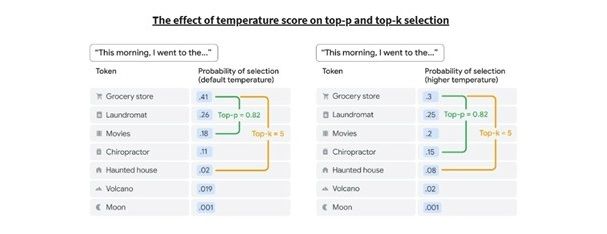
با هر سه پارامتر نمونهبرداری، امتیاز بالا میتواند جرقههایی از بینشهای شگفتانگیز را ایجاد کند اما این افزایش در تصادفی بودن همچنین میتواند منجر به توهمات (hallucinations) شود، بنابراین فراموش نکنید که خروجی را بررسی کنید.
در طوفان فکری خلاقانه، بهترین ایده لزوماً اولین ایدهای نیست که به ذهنتان میرسد، و پربارترین پیشنهادات هوش مصنوعی همیشه بالاترین احتمالات را نخواهند داشت. دستکاری امتیاز دما، مقدار top-k و مقدار top-p میتواند مسیرهای جدیدی را برای کاوش باز کند یا آن را به سمتی که نیاز دارید محدود سازد.
بهترین روش برای فهمیدن اینکه کدام ترکیب از Top-K، Top-P و دما برای کار شما با جمینای مناسبتر است، با مقادیر مختلفی آنها آزمایش کنید و ببینید کدامیک نتایجی را تولید میکند که به دنبالش هستید. گاهی استفاده همزمان از آنها (با اولویتبندی مشخص) نیز میتواند مفید باشد.
در مدل های جمینای توکنهایی که معیارهای Top-K و Top-P را برآورده میکنند، نامزدهایی برای توکن پیشبینی شده بعدی هستند، سپس دما برای نمونهگیری از توکنهایی که از معیارهای Top-K و Top-P عبور کردهاند اعمال میشود. اگر فقط Top-K یا Top-P در دسترس باشد، رفتار یکسان است اما فقط از یک تنظیم Top-K یا Top-P استفاده میشود. اگر دما در دسترس نباشد، از هر توکنی که معیارهای Top-K و یا Top-P را برآورده میکند، به صورت تصادفی انتخاب میشود تا یک توکن پیشبینی شده بعدی واحد تولید شود.
تنظیمات بیش از حد یک مقدار نمونه گیری، تنظیمات نمونهگیری دیگر را لغو یا بیاهمیت می کند:
تنظیم دما روی ۰: Top-K و Top-P بیاهمیت میشوند - توکن با بیشترین احتمال، توکن پیشبینی شده بعدی میشود. اگر دما را به شدت بالا تنظیم کنید (بالای ۱ - توزیع احتمال بسیار یکنواخت میشود)، دما بیاهمیت میشود و از هر توکنی که از معیارهای Top-K یا Top-P عبور کند، به صورت تصادفی نمونهگیری میشود تا یک توکن پیشبینی شده بعدی انتخاب شود.
تنظیم Top-K روی ۱: دما و Top-P بیاهمیت میشوند. فقط یک توکن از معیارهای Top-K عبور میکند، و آن توکن، توکن پیشبینی شده بعدی است. اگر Top-K را به شدت بالا تنظیم کنید، هر توکن با احتمال غیر صفر برای اینکه توکن بعدی باشد، معیارهای Top-K را برآورده میکند و هیچ کدام انتخاب نمیشوند.
تنظیم Top-P روی ۰ (یا یک مقدار بسیار کوچک): مدل نمونهگیری توکن را با بیشترین احتمال را در نظر میگیرد تا معیارهای Top-P را برآورده کند (دما و Top-K را بیاهمیت میکند). اگر Top-P را روی ۱ تنظیم کنید، هر توکن با احتمال غیر صفر برای اینکه توکن بعدی باشد، معیارهای Top-P را برآورده میکند، و هیچ کدام انتخاب نمیشوند.
به عنوان یک نقطه شروع کلی:
تنظیمات ذیل نتایج نسبتا منسجمی میدهد که میتواند خلاقانه (نه به طور افراطی) باشد.
Temperature=0.2
Top-P=0.95
Top-K=30
تنظیمات ذیل نتایج خلاقانه می دهد:
Temperature=0.9
Top-P=0.99
Top-K=40
تنظیمات ذیل نتایج کمتر خلاقانه می دهد:
Temperature=0.1
Top-P=0.9
Top-K=20
تنظیمات نامناسب دما، Top-P و Top-K ممکن است مدل را مجبور به تولید متنی بکند که با مقدار زیادی کلمات پرکننده و نامرتبط به پایان برسد. مثلا در دماهای پایین، مدل بیش از حد قطعی میشود و مسیر با بالاترین احتمال منجر به یک حلقه شود که پاسخ را به متن تولید شده قبلی بازگرداند (باگ حلقه تکرار). برعکس، همچنین در دماهای بالا، خروجی مدل بیش از حد تصادفی میشود و احتمال اینکه یک کلمه یا عبارت انتخاب شده به طور تصادفی شانس بازگشت به حالت قبلی و ایجاد باگ حلقه تکرار به دلیل تعدد گزینه های موجود را افزایش میدهد.

تا اینجا متوجه شدیم در تنظیمات مربوط به مدلهای زبانی، مفاهیمی مانند دما، گسترهی انتخاب واژگان (top-p) و تعداد گزینههای برتر (top-k) نقش مهمی در نحوه تولید پاسخ دارند. این تنظیمات به ما امکان میدهند تا میزان خلاقیت، تنوع، یا تمرکز پاسخها را کنترل کنیم. اما حتی با تنظیم دقیق این پارامترها، هنوز هم کیفیت خروجی تا حد زیادی به کیفیت پرامپت بستگی دارد.
مهندسی پرامپت به عنوان مهارتی کلیدی با بهرهگیری از ساختار آموزش مدلها و اصول کارکرد آنها، میتواند شما را به پاسخهای مرتبطتر و دقیقتری برساند. اکنون که درک بهتری از چیستی مهندسی پرامپت و ضرورت آن داریم، بیایید به برخی از مهمترین و کاربردیترین روشها و الگوهای پرامپتنویسی نگاهی بیندازیم.
۱. پرامپت زیرو-شات (Zero-shot)
۲. پرامپت تک-شات و چند-شات (One-shot & Few-shot)
۳. پرامپت سیستمی (System Prompting)
۴. پرامپت نقشدار (Role Prompting)
۵. پرامپت کانتکسچوال (Contextual Prompting)
۶. پرامپت استپبک (Step-back Prompting)
۷. زنجیره تفکر (Chain of Thought)
۸. خودسازگاری (Self-consistency)
۹. درخت تفکرات (Tree of Thoughts)
۱۰. پارادایم ReAct (Reason & Act)
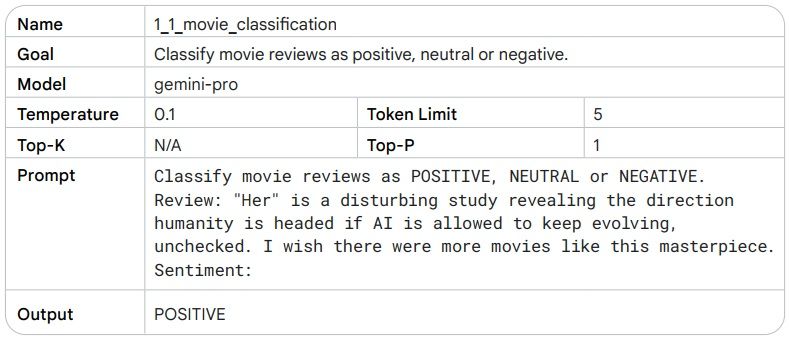
پرامپت زیرو-شات توصیفی از یک وظیفه و برخی متنها (یک سؤال، شروع یک داستان، یا دستورالعملها) را برای شروع کار به مدل زبانی ارائه میدهد. این ورودی میتواند هر چیزی باشد.
در مثال زیر دمای مدل باید روی عدد پایینی تنظیم شود، زیرا نیازی به خلاقیت نیست، و ما از مقادیر پیشفرض Top-K و Top-P مدل جمینای پرو استفاده کردیم. به خروجی تولید شده توجه کنید. کلمات "disturbing" و "masterpiece" باید پیشبینی را کمی پیچیدهتر کنند، زیرا هر دو کلمه در یک جمله استفاده شدهاند.
وقتی زیرو-شات کار نمیکند، میتوانید نمونهها یا مثالهایی را در پرامپت ارائه دهید، که منجر به پرامپت "تک-شات" و "چند-شات" میشود. این مثالها میتوانند به مدل کمک کنند تا الگوها را بهتر درک کند و پاسخهای دقیقتری تولید کند.
پرامپت تک-شات: یک مثال واحد ارائه میدهد.
پرامپت چند-شات: چندین مثال ارائه میدهد.
مثالها به ویژه زمانی مفید هستند که میخواهید مدل را به سمت یک ساختار یا الگوی خروجی خاص هدایت کنید.

پرامپت سیستمی کانتکس کلی و هدف اصلی را برای مدل زبانی مشخص میکند. این به شما اجازه میدهد تا به مدل بگویید چه نوع دستیاری باشد، چگونه پاسخ دهد، و چه محدودیتهایی داشته باشد (قرار است چکار کنی). مثلاً مدل باید یک متن رو ترجمه، یا یک نظر رو دستهبندی کند. این پرامپت تصویر بزرگی از وظیفه مدل را در اختیارش قرار می دهد.
در جدول زیر، یک پرامپت سیستمی (System Prompt) ارائه شده است که در آن اطلاعات بیشتری درباره نحوه بازگرداندن خروجی مشخص شده. پارامتر دما برای دستیابی به سطح خلاقیت بالاتر، افزایش داده شده و همچنین محدودیت توکن بالاتری را تعیین شده است.

به دلیل دستورالعمل واضحی که درباره نحوه ارائه خروجی، مدل (علیرغم تنظیمات دما و توکن بالا که معمولاً باعث تولید متن بیشتر یا خلاقانهتر میشوند) در خروجی خود متن اضافهای تولید نکرده و دقیقاً به فرمت درخواستی پایبند ماند.
پرامپت سیستمی با ساختارمند کردن و کاهش خطا پدیده توهمزایی یا تولید اطلاعات نادرست و بیاساس (Hallucinations) توسط مدل را محدود میسازد، زیرا مدل باید اطلاعات را دقیقاً در قالب کلیدها و مقادیر تعریفشده جای دهد.
همچنین پرامپت سیستمی میتواند برای کنترل ایمنی (Safety) و جلوگیری از تولید محتوای نامناسب یا سمی (Toxicity) بسیار مفید باشد. برای کنترل خروجی، کافی است یک خط دستورالعمل اضافی (مانند You should be respectful in your answer) به انتهای پرامپت بیفزایید.
با دادن یک شخصیت یا هویت خاص به مدل انتظار رفتار متمرکز مطابق با آن را داریم. مثلاً «تو یک معلم زبان انگلیسی هستی» یا «مثل یک دوست صمیمی با من حرف بزن». این کار باعث میشه جوابها با نقش و دانش و رفتاری تعریف شده، همخوانی داشته باشه.
میتوانید به مدل هوش مصنوعی نقش یک ویراستار کتاب، یک معلم مهدکودک، یا یک سخنران انگیزشی را بدهید. وقتی نقش مدل مشخص شد، میتوانید درخواستهایی به او بدهید که مختص همان نقش باشند. مثال زیر نمونهای از ایفای نقش یک کارمند آژانس مسافرتی توسط مدل هوش مصنوعی را نشان میدهد. اگر شما همین نقش را به «معلم جغرافیا» تغییر دهید، متوجه خواهید شد که پاسخ کاملاً متفاوتی دریافت میکنید.
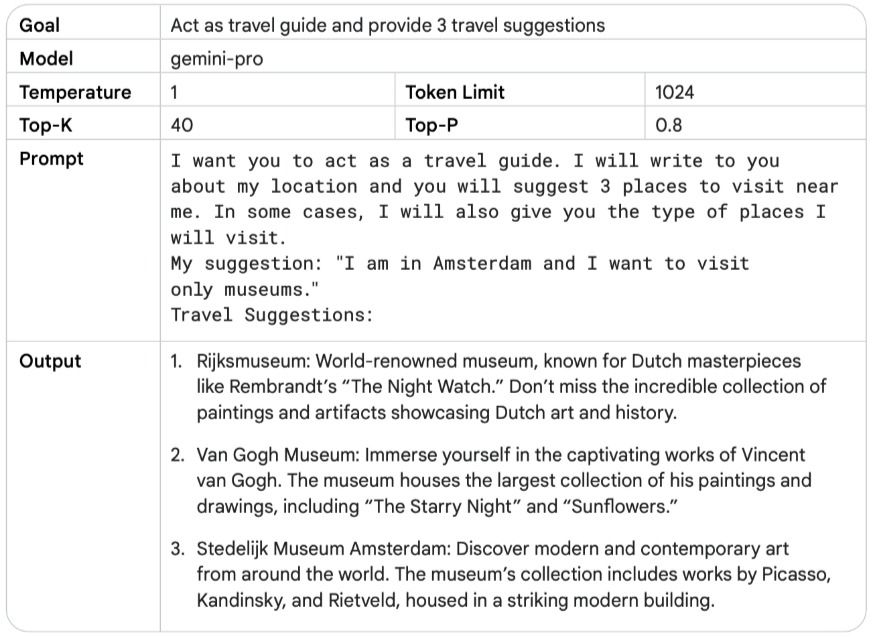
این دیدگاه نقشمحور با ارائه یک الگو (blueprint) مشخص میکند که شما چه لحن، سبک و تخصص متمرکزی را از مدل انتظار دارید. در نتیجه، این کار به بهبود کیفیت، مرتبط بودن (relevance) و اثربخشی (effectiveness) خروجی نهایی شما کمک میکند.
چند سبک نوشتاری موثر در ایجاد پرامپت:
- چالشی (Confrontational): کمی تند و مستقیم، برای به چالش کشیدن.
- توصیفی (Descriptive): با جزئیات زیاد و تصویرسازی.
- مستقیم (Direct): بدون حاشیه و سر اصل مطلب.
- رسمی (Formal): با ادبیات و ساختار رسمی.
- طنزآمیز (Humorous): شوخطبعانه و با چاشنی خنده.
- تأثیرگذار (Influential): برای اثرگذاری بر مخاطب.
- غیررسمی (Informal): دوستانه و خودمانی.
- الهامبخش (Inspirational): برای ایجاد انگیزه و امید.
- متقاعدکننده (Persuasive): برای قانع کردن مخاطب.
حالا بیایید پرامپت خودمان در جدول قبل را تغییر دهیم تا سبکی طنزآمیز و الهامبخش داشته باشد.

پرامپت کانتکسچوال شامل ارائه جزئیات خاص یا اطلاعات پسزمینهای اضافی که به موضوع یا مربوط به وظیفه فعلی می شود به مدل میدهد. مثلا در پاسخ به پرسش این اطلاعات به مدل کمک میکند تا بفهمد دقیقا چه چیزی خواسته شده و جواب بر اساس آن تنظیم شود.

نکته: بین پرامپت System، Contextual و Role Prompting ممکن است در شباهتها و تفاوتها همپوشانی زیادی وجود داشته باشه. مثلا یک دستور نقش دار (مثل یک مترجم باش)، میتواند همزمان سیستمی باشد (مثل این متن را از فارسی به انگلیسی ترجمه کن) ولی هر کدام هدف اصلی متفاوتی دارند.
در استپبک پرامپتینگ، بهجای اینکه مستقیماً از مدل بخواهیم یک سؤال را پاسخ دهد، ابتدا از آن میخواهیم دربارهی سؤالی که قرار است حل کند فکر کند یا سوالات میانی مطرح کند—نوعی «یک قدم به عقب برداشتن» برای داشتن دید بهتر. سپس از آن نتایج استفاده میکنیم تا پاسخ نهایی را بگیریم. در این روش، ابتدا به مدل یک سوال کلی مرتبط با وظیفه خاص داده میشود. سپس پاسخ این سوال کلی بهعنوان ورودی به درخواست بعدی برای انجام وظیفه خاص داده میشود. این گام به عقب به مدل اجازه میدهد تا دانش پسزمینه مرتبط و فرآیندهای استدلالی را فعال کند، ساختار مسئله را تحلیل کند، مفروضات را بررسی کند و جنبههای مختلف سؤال را قبل از اینکه بخواهد مسئله خاص را حل کند جدا کند.
مدلهای زبانی گاها در پاسخ مستقیم به مسائل چندمرحلهای دچار اشتباه میشوند. اما اگر از آنها بخواهیم ابتدا دربارهی مسئله استدلال کنند یا یک لایه تحلیلی بالاتر بروند، معمولاً نتیجه بهتری میگیریم. پرامپت استپبک مدل را تشویق میکند تا بهصورت انتقادی فکر کند و دانش خودش را به روشهای جدید و خلاقانه به کار ببرد. این روش باعث میشود درخواست نهایی که وظیفه را انجام میدهد، در مقایسه با زمانی که مدل مستقیماً با یک درخواست خاص روبهرو میشود از دانش بیشتری در پارامترهای مدل استفاده کند.
همچنین، این روش میتواند به کاهش سوگیریها در پاسخهای مدل کمک کند، چون بهجای تمرکز روی جزئیات خاص، روی اصول کلی متمرکز میشود.
مثالها برای درک بهتر برای فهم بهتر اینکه چطور پرامپت استپبک میتواند نتایج را بهبود بدهد، بیایم چند مثال رو بررسی کنیم. ابتدا یک درخواست سنتی از مدل را نگاه میکنیم:

توجه داشته باشید با تنظیم دما روی ۱ برای یک خط داستانی کلی، نوشتهها خلاقانه اما معمولاً تصادفی و کلی می شوند.
حالا آن را با یک پرامپت استپبک مقایسه میکنیم:

به نظر این موضوعات برای بازی ویدیویی اول شخص مناسب باشند. حالا به درخواست قبلی برگشته، ولی این بار پاسخ سوال استپبک رو بهعنوان زمینه (Context) اضافه می کنیم:

زنجیره تفکر تکنیکی است که توانایی استدلال مدلهای زبانی بزرگ را با تولید گامهای استدلالی میانی بهبود میدهد. این روش به مدل کمک میکند تا پاسخهای دقیقتری تولید کند. میتوان زنجیره تفکر را با پرامپت Few-Shot ترکیب کنید تا در وظایف پیچیدهتر که نیاز به استدلال قبل از پاسخ دارند، نتایج بهتری بگیرید.
مزایای زنجیره تفکر:
در این روش نیازی به تنظیم دقیق (Finetuning) مدل نیست و با مدلهای آماده به خوبی کار میکند.
این روش با شفافیت و تفسیرپذیری گامهای استدلال را دنبال و مشکل احتمالی براحتی پیدا می شود.
با این روش عملکرد درخواست وقتی از نسخههای مختلف مدلهای زبانی استفاده میکنید کمتر تغییر می کند. یعنی درخواستهایی که از زنجیره تفکر استفاده میکنند، نسبت به درخواستهای بدون استدلال، بین مدلهای مختلف پایداری بیشتری دارند.
معایب زنجیره تفکر:
پاسخ مدل شامل گامهای استدلالی زنجیره تفکر است، که به معنای تولید توکنهای خروجی بیشتر است. این امر باعث ایجاد هزینه و زمان بیشتر برای پاسخ های محتمل می شود.
کاربرد های عملی زنجیره تفکر:
- تولید کد (Code Generation): میتونید درخواست رو به چند گام تقسیم کنید و هر گام رو به خطوط خاصی از کد مرتبط کنید.
- ایجاد داده های مصنوعی (Synthetic Data): مثلاً وقتی یه نقطه شروع دارید، مثل «محصول اسمش XYZ هست، یه توضیح بنویس و مدل رو از فرضیاتی که بر اساس اسم محصول میکنی، هدایت کن.»
- توضیح گامهای حل مسئله: به طور کلی، هر کاری که با صحبت کردن و توضیح دادن حل شود، کاندیدای خوبی برای زنجیره تفکر است. اگر میتواند گامهای حل مسئله رو توضیح دهید، زنجیره تفکر را امتحان کنید!
برای توضیح مثال در جدول زیر، ابتدا یک درخواست بدون استفاده از زنجیره تفکر می نویسیم تا نقاط ضعف مدل زبانی را نشان دهیم:

با توجه به اشتباه بودن پاسخ مدل حالا از گامهای استدلالی میانی استفاده کنیم، تا خروجی بهتر شود:

جدول بالا نمونه ای از زنجیره تفکر بدون نمونه (Zero-Shot Chain of Thought) هست. به یاد داشته باشید که ترکیب زنجیره تفکر با تکنمونه (Single-Shot) یا چندنمونه (Few-Shot)، بسیار قدرتمند تر می شود (مثال زیر).

چند نکته:
برای مسائل پیچیده، از زنجیره تفکر استفاده کنید تا مدل را به استدلال قدم به قدم هدایت کنید.
باید پاسخ را بعد از توضیحات و استدلالها بنویسید. چون وقتی استدلالها را مینویسید، اطلاعاتی که مدل برای حدس زدن پاسخ نهایی استفاده میکند تغییر میکند.
وقتی از زنجیره تفکر و روش خود-سازگاری (Self-consistency) استفاده میکنید، باید بتوانید پاسخ نهایی را از متن درخواست جدا کنید، طوری که از استدلالها مستقل باشد.
برای روش زنجیره تفکر، دما را روی ۰ بگذارید. روش زنجیره تفکر بر اساس انتخاب ساده و مستقیم کار می کند، یعنی مدل زبانی کلمه بعدی را بر اساس بیشترین احتمال پیشبینی میکند. معمولاً وقتی از استدلال برای پیدا کردن پاسخ استفاده میکنید، فقط یک پاسخ درست وجود دارد. به همین دلیل، دما همیشه باید ۰ باشد.
در تکنیک خودسازگاری از مدل خواسته میشود چندین مسیر استدلال برای یک مسئله در نظر گرفته شود، سپس پاسخی با بیشترین سازگاری را انتخاب کند.
با وجود موفقیت های چشمگیر مدل های زبانی در وظایف مختلف پردازش زبان طبیعی توانایی آنها در استدلال اغلب بهعنوان یک محدودیت شناخته میشود که فقط با بزرگتر کردن اندازه مدل حل نمیشود. خودسازگاری (Self-Consistency) روشی پیشرفته است که نمونهبرداری (Sampling) و رأیگیری اکثریت (Majority Voting) را ترکیب میکند تا مسیرهای استدلالی متنوعی تولید می کند تا پاسخی که بیشترین سازگاری (بیشتر مورد توافق یا بیشترین تکرار) با پرامپت را دارد انتخاب کند. این روش دقت و انسجام پاسخهای تولیدشده توسط مدلهای زبانی رو بهبود میدهد.
خودسازگاری در ازای هزینه بالایی که دارد یک جور احتمال شبهتصادفی (Pseudo-Probability) برای درست بودن یک پاسخ ارائه میدهد.
احتمال شبهتصادفی (Pseudo-Probability): به یک کمیت یا عدد که شبیه احتمال رفتار میکند (مثلاً بین ۰ و ۱ است و نمایانگر میزان اطمینان یا وزن یک پیشبینی یا انتخاب است)، اما الزامات سختگیرانه احتمال ریاضی کلاسیک (مثل مجموع احتمالا به ۱ یا تبعیت از قانونهای کامل احتمال) را لزوماً رعایت نمیکند.
- مثل احتمال عمل میکند و درک میشود،
- ولی دقیقاً یک احتمال استاندارد به معنی ریاضی نیست.
مثال: فرض کنید یک مدل یادگیری ماشین تصویر گربه و سگ را تشخیص میدهد. مدل به یک تصویر نگاه میکند و خروجی زیر را میدهد:
- گربه: ۰٫۷
- سگ: ۰٫۴
خب، این اعداد شبیه احتمال هستند (بین ۰ و ۱ هستند و نشان میدهند مدل چقدر مطمئن است)، ولی اگر دقت کنید جمعشان بیشتر از ۱ شده!
0.7+0.4=1.1
که طبق قانون احتمال کلاسیک، نباید نمی شود. پس این اعداد شبهاحتمال هستند.
توجه: این وزنها شبهاحتمال هستند میتوانند نرمالسازی شوند (مجموعشان برابر ۱ شود)، اما قبل از نرمالسازی، ممکن است جمعشان ۱ نباشد.
1. تولید مسیرهای استدلالی متنوع: همون درخواست (Prompt) چندین بار به مدل داده میشه. تنظیم دمای بالا (High Temperature) باعث میشه مدل مسیرهای استدلالی و دیدگاههای متفاوتی برای مسئله تولید کنه.
2. استخراج پاسخ از هر خروجی: از هر پاسخ تولیدشده، جواب نهایی جدا میشه.
3. انتخاب شایعترین پاسخ: پاسخی که بیشترین تکرار رو داره، بهعنوان جواب نهایی انتخاب میش
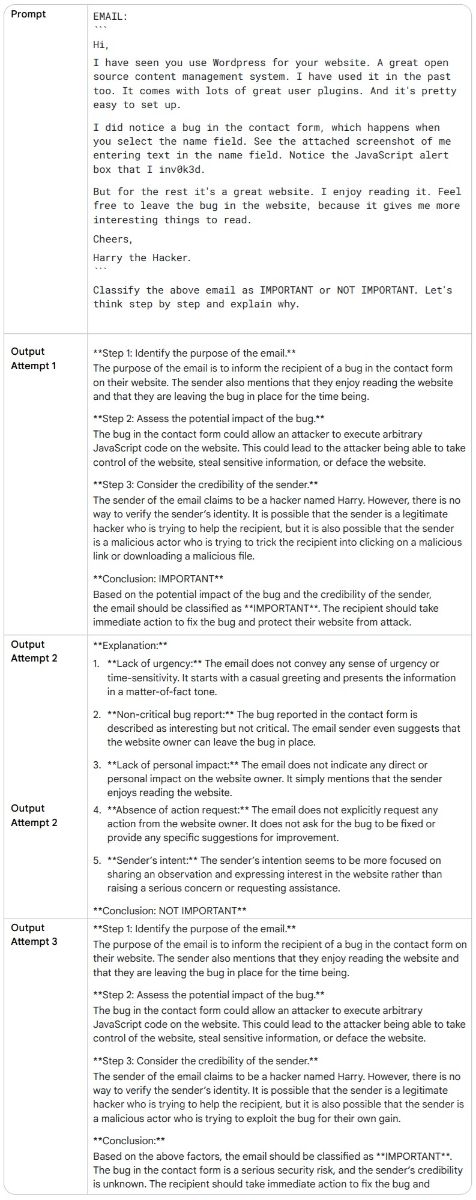
مثال: سیستم طبقهبندی ایمیل: در این مثال یک سیستم طبقهبندی ایمیل می ببینیم که ایمیلها به دو دسته مهم (IMPORTANT) یا غیرمهم (NOT IMPORTANT) تقسیم میشوند. یک درخواست زنجیره تفکر بدون نمونه (Zero-Shot CoT) چندین بار به مدل فرستاده میشود تا ببینیم آیا پاسخها بعد از هر بار ارسال فرق میکنند یا خیر. به لحن دوستانه، انتخاب کلمات و کنایه (Sarcasm) که در ایمیل استفاده شده توجه کنید. همه اینها ممکنه مدل زبانی رو گمراه کنند!
درخت تفکرات (ToT) یک توسعه از زنجیره تفکر است که به مدل اجازه میدهد چندین مسیر استدلال را کاوش و مسیرهای غیرامیدوارکننده را هرس کند. این روش، مفهوم روش زنجیره تفکر را تعمیم میدهد (Generalizes)، زیرا به مدل اجازه میدهد به جای اینکه فقط یک زنجیره افکار خطی و واحد را دنبال کند مسیر های استدلالی مختلف و متعددی را به طور همزمان کاوش کند.
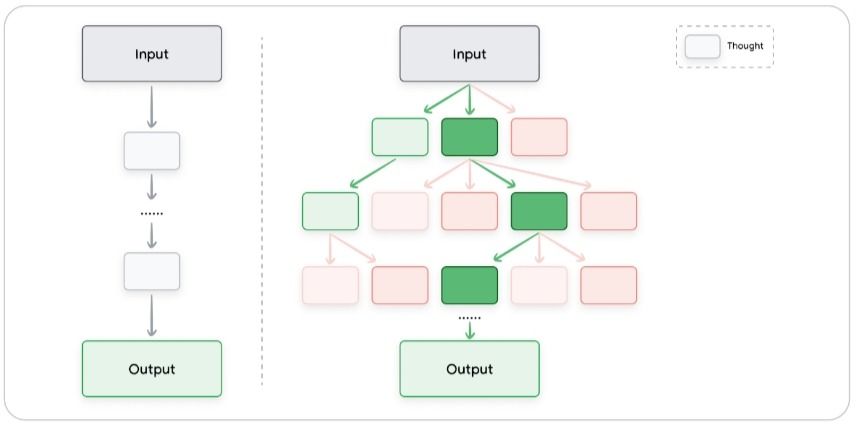
این رویکرد باعث میشود درخت تفکر به ویژه برای وظایف پیچیدهای که نیازمند کاوش (Exploration) هستند، بسیار مناسب باشد. سازوکار آن مبتنی بر نگهداری یک «درخت از افکار» است، که در آن هر «فکر» (Thought) نشاندهنده یک دنباله زبانی منسجم است که به عنوان یک گام میانی در مسیر حل یک مسئله عمل میکند. سپس مدل میتواند با انشعاب گرفتن (Branching out) از گرههای (Nodes) مختلف در این درخت، مسیرهای استدلالی مختلف را کاوش کند.
پرامپت ReAct (Reason & Act) یک پارادایم جدید در مدلهای زبانی بزرگ (LLMs) هست که به آنها کمک میکند وظایف پیچیده را با استفاده از استدلال به زبان طبیعی (natural language) و ترکیب آن با ابزارهای خارجی (مثل جستجو، code interpreter و غیره) حل کنند. این روش به مدل اجازه میدهد کارهایی مثل تعامل با APIها برای دریافت اطلاعات انجام دهد، که گامی اولیه به سمت مدلسازی ایجنت (Agent Modeling) محسوب میشود.
در ReAct از نحوه عملکرد انسانها در دنیای واقعی تقلید میشود؛ ما هم بهصورت کلامی استدلال میکنیم و برای بهدست آوردن اطلاعات، اقداماتی انجام میدهیم. ReAct در مقایسه با دیگر روشهای Prompt Engineering در حوزههای مختلف عملکرد خوبی دارد.
نحوه کار ReAct، با ترکیب استدلال و عمل در یک حلقه فکر-عمل (thought-action) کار میکند:
ابتدا مدل درباره مسئله استدلال میکند و یک طرح عملی تولید میکند. سپس اقدامات موجود در طرح را اجرا میکند و نتایج را مشاهده میکند. مدل از این مشاهدات برای بهروزرسانی استدلالش استفاده میکند و یک طرح عملی جدید میسازد. این فرآیند ادامه پیدا میکند تا مدل به راهحل مسئله برسد.
آزمایش ReAct در عمل
برای دیدن این روش در عمل، باید کدی بنویسید. در قطعه کد شماره 1، در اینجا از فریمورک LangChain در زبان پایتون به همراه VertexAI (از بسته google-cloud-aiplatform) و بسته google-search-results استفاده شده.
برای اجرای این نمونه، باید یک کلید SerpAPI رایگان از آدرس https://serpapi.com/manage-api-key بسازید و متغیر محیطی SERPAPI_API_KEY را تنظیم کنید
مثال واکنش:پرامپت ReAct (Reason & Act) یک پارادایم جدید در مدلهای زبانی بزرگ هست که به آنها کمک میکند وظایف پیچیده را با استفاده از ترکیب استدلال به زبان طبیعی (natural language) با ابزارهای خارجی (مثل جستجو، code interpreter و غیره) حل کنند. این روش به مدل اجازه میدهد کارهایی مثل تعامل با API ها برای دریافت اطلاعات انجام دهد، که گامی اولیه به سمت مدلسازی با ایجنت (Agent Modeling) محسوب میشود.
درواقع ReAct از نحوه عملکرد انسانها در دنیای واقعی تقلید میکند؛ ما هم بهصورت کلامی استدلال میکنیم و برای بهدست آوردن اطلاعات، اقداماتی انجام میدهیم. ReAct در مقایسه با دیگر روشهای Prompt Engineering در حوزههای مختلف عملکرد بهتری دارد. نحوه کار ReAct، با ترکیب استدلال و عمل در یک حلقه فکر-عمل (thought-action) کار میکند:
ابتدا مدل درباره مسئله استدلال میکند و یک طرح عملی تولید میکند. سپس اقدامات موجود در طرح را اجرا و نتایج را مشاهده میکند. مدل از این مشاهدات برای بهروزرسانی استدلالش استفاده میکند و یک طرح عملی جدید میسازد. این چرخه ادامه پیدا میکند تا مدل به راهحل مسئله برسد.
مثال: برای دیدن این روش در عمل، باید کدی بنویسید. در اینجا از فریمورک LangChain در زبان پایتون به همراه VertexAI (از بسته google-cloud-aiplatform) و بسته google-search-results استفاده شده. برای اجرای این نمونه، باید یک کلید SerpAPI رایگان بسازید و متغیر محیطی SERPAPI_API_KEY را تنظیم کنید. حالا یک کد پایتون مینویسیم که وظیفهای برای مدل زبانی بزرگ تعریف کنه: اعضای گروه متالیکا چند بچه دارند؟
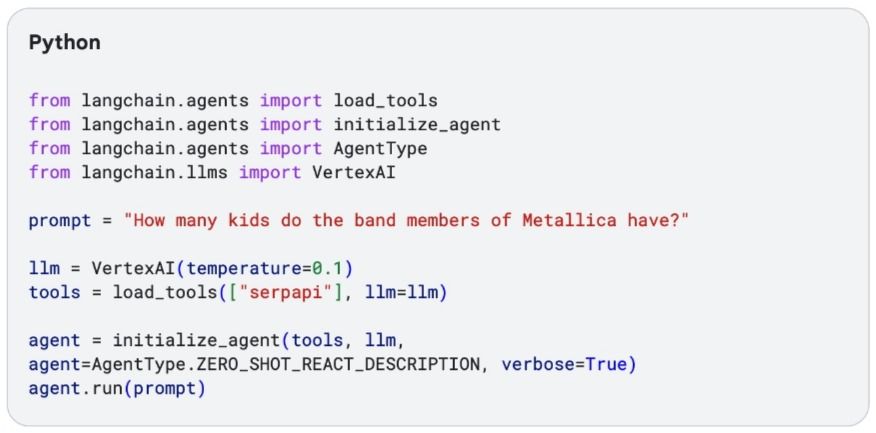
قطعه کد پایین نتیجه را نشان میدهد. توجه کنید که ReAct یه زنجیره از پنج جستجو انجام میده. درواقع، مدل زبانی نتایج جستجوی گوگل رو بررسی میکنه تا اسامی اعضای گروه رو پیدا کنه. بعد، نتایج را بهعنوان مشاهدات فهرست کرده و استدلالش را برای جستجوی بعدی ادامه میدهد. در این کد، مدل متوجه میشه که گروه متالیکا چهار عضو دارد. بعد، برای هر عضو گروه جستجو میکند تا تعداد بچهها را پیدا و در انتها همه را جمع میزند. در نهایت، کد تعداد کل بچهها را بهعنوان پاسخ نهایی برمیگرداند.

حالا با توجه به دانشی که در قسمت تکنیکهای مهندسی پرامپت به دست اوردیم، بهترین شیوهها و نکات کاربردی برای مهندسی پرامپت موثر را بررسی میکنیم:
مهمترین روش ارايه مثال هست (تک-شات و چند-شات) با پرامپت هست. ارائه مثالهای واضح به مدل کمک کند تا الگوها را بهتر درک کند و پاسخهای دقیقتری تولید کند. مثال بسیار بهینه هست چون شبیه یک ابزار آموزشی برای مدل عمل میکند.
مثال:
Translate the following English phrases to French:English: Hello, how are you?French: Bonjour, comment allez-vous?English: I would like to order a coffee, please.French: Je voudrais commander un café, s'il vous plaît.English: Where is the nearest train station?French:
نکته: برای وظایف پیچیده، از پرامپت چند-شات با مثالهای متنوع استفاده کنید.
پرامپتهای ساده و مستقیم اغلب بهترین نتایج را تولید میکنند. از زبان پیچیده یا دستورالعملهای مبهم خودداری کنید. اگر پرامپت برای خود شما هم گنگ بود، برای مدل هم نامفهوم است. در نوشتن پرامپ از افعال شبیه زیر میتوانید استفاده کنید:
Act, Analyze, Categorize, Classify, Contrast, Compare, Create, Describe, Define, Evaluate, Extract, Find, Generate, Identify, List, Measure, Organize, Parse, Pick, Predict, Provide, Rank, Recommend, Return, Retrieve, Rewrite, Select, Show, Sort, Summarize, Translate, Write.
مثال:
BEFORE: I am visiting New York right now, and I'd like to hear more about great locations. I am with two 3 year old kids. Where should we go during our vacation?
AFTER REWRITE: Act as a travel guide for tourists. Describe great places to visit in New York Manhattan with a 3 year old.
خروجی مورد نظرتان را به وضوح مشخص کنید. یک دستور مختصر ممکن است نتواند مدل را به اندازه کافی راهنمایی کند و خیلی کلی باشد.
به جای گفتن اینکه مدل چه کاری نکند، به آن بگویید چه کاری انجام دهد. در پرامپت (Prompting) برای هدایت خروجی یک مدل زبانی بزرگ (LLM)، از دستورات و محدودیتها استفاده میکنیم. این دو ابزار به ما کمک میکنند تا پاسخ مدل را به شکلی که میخواهیم شکل دهیم. در ادامه، این مفاهیم را به زبان ساده و قابل فهم توضیح میدهم:
دستورات، راهنماییهای مشخص و واضحی هستند که به مدل میگویند پاسخش چه شکل، سبک یا محتوایی باید داشته باشد. به عبارت دیگر، دستورات به مدل میگویند که چه کاری انجام دهد یا چه چیزی تولید کند.
مثال: «پاسخ را به صورت یک پاراگراف کوتاه بنویس.»
این نوع راهنمایی به مدل کمک میکند تا دقیقاً بفهمد چه انتظاری از آن داریم و کارش را در مسیر درست پیش ببرد.
محدودیتها، قوانینی هستند که مشخص میکنند مدل چه کاری نباید انجام دهد یا از چه چیزی باید دوری کند. اینها مثل خطوط قرمزی هستند که پاسخ مدل باید درون آنها بماند.
مثال: «از کلمات پیچیده و فنی استفاده نکن.»
محدودیتها کمک میکنند تا خروجی مدل در چارچوب مشخص و قابل قبولی بماند.
تحقیقات جدید نشان میدهد که استفاده از دستورات مثبت معمولاً بهتر از تکیه زیاد بر محدودیتها جواب میدهد. این موضوع شبیه به رفتار خود ما آدمهاست؛ ما هم راهنماییهای مثبت را بیشتر از لیست بلندبالای «این کار را نکن» دوست داریم.
دلیل بهتر بودن دستورات:
- دستورات بهطور مستقیم به مدل میگویند که چه نتیجهای میخواهیم
- امکان خلاقیت بیشتر در چارچوب مشخص
- جلوگیری از سردرگمی مدل
مشکلات محدودیتها:
- امکان ایجاد سردرگمی در مدل
- کاهش خلاقیت
- احتمال ایجاد تناقض بین محدودیتها
با اینکه دستورات مثبت بهتر هستند، محدودیتها هم در جاهایی به کار میآیند:
- جلوگیری از تولید محتوای مضر یا اشتباه.
- نیاز به قالب/سبک خاص (مثلاً محدودیت تعداد کلمات)
هر وقت میشود، از دستورات مثبت استفاده کنید. به جای اینکه به مدل بگویید چه کاری نکند، بگویید چه کاری بکند. این کار سردرگمی را کم میکند و باعث میشود پاسخ دقیقتر و بهتر باشد.
مثال: به جای «مبهم نباش»، بگویید «جزئیات واضح و مشخص بده.»
این تغییر ساده باعث میشود مدل بهتر بفهمد و نتیجه بهتری بدهد.
۱. اول با دستورات شروع کنید.
۲. فقط در صورت نیاز از محدودیتها استفاده کنید.
۳. ترکیبهای مختلف را آزمایش کنید.
۴. نتایج را مستندسازی کنید.
DO: Generate a 1 paragraph blog post about the top 5 video game consoles. Only discuss the console, the company who made it, the year, and total sales.
DO NOT: Generate a 1 paragraph blog post about the top 5 video game consoles. Do not list video game names.
برای کنترل طول پاسخ، محدودیتهای خاصی را مشخص کنید.
"Explain quantum physics in a tweet length message."
برای استفاده دوباره از پرامپتها و پویاتر کردن آنها، در پرامپتتان از متغییر هایی استفاده کنید که میتوانند برای ورودیهای مختلف تغییر کنند. برای مثال، همانطور که در جدول زیر نشان داده شده، پرامپتی که اطلاعاتی درباره یک شهر میدهد. به جای نوشتن ثابت نام شهر در پرامپت، از یک متغیر استفاده کنید. متغیرها میتوانند با جلوگیری از تکرار، در زمان و تلاش شما صرفهجویی کنند. اگر نیاز دارید همان اطلاعات را در چند پرامپت استفاده کنید، میتوانید آنها را در یک متغیر ذخیره کرده و سپس در هر پرامپت به آن متغیر اشاره کنید. این کار وقتی پرامپتها را در برنامههای خودتان ادغام میکنید، بسیار منطقی است.

فرمتهای مختلف پرامپت را آزمایش کنید تا ببینید کدام یک بهترین نتایج را تولید میکند. مدلهای هوش مصنوعی مختلف، تنظیماتشان، نوع درخواست (پرامپت)، کلماتی که انتخاب میکنید، و سبک نوشتنتان، همگی روی جوابی که میگیرید تأثیر میگذارند و میتوانند نتایج متفاوتی ایجاد کنند.
بنابراین، مهم است که با ویژگیهای مختلف درخواستتان آزمایش کنید؛ مانند: سبک نوشتن (رسمی، دوستانه، ساده و...) انتخاب کلمات (استفاده از مترادفها یا عبارات مختلف) نوع درخواست (مثلاً اینکه درخواستتان سوالی باشد، یک جمله خبری باشد، یا یک دستورالعمل)
مثال: فرض کنید میخواهید مدل متنی درباره کنسول بازی انقلابی "سگا دریمکست" بنویسد. میتوانید درخواستتان را به شکلهای مختلفی بنویسید، و هر کدام جواب متفاوتی خواهد داد:
سوالی
What was the Sega Dreamcast and why was it such a revolutionary console?سگا دریمکست چه بود و چرا یک کنسول انقلابی محسوب میشد؟
خبری
The Sega Dreamcast was a sixth-generation video game console released by Sega in 1999. It...سگا دریمکست یک کنسول بازی نسل ششم بود که توسط سگا در سال ۱۹۹۹ منتشر شد. این کنسول...
دستوری
Write a single paragraph that describes the Sega Dreamcast console and explains why it was so revolutionary.یک پاراگراف بنویس که کنسول سگا دریمکست را توصیف کند و توضیح دهد چرا اینقدر انقلابی بود.
وقتی از چند مثال آموزشی استفاده میکنید، کلاسها (دستهها) را با هم ترکیب کنید. معمولاً ترتیب مثالهای آموزشی (few-shot examples) که به مدل میدهید، نباید تأثیر زیادی داشته باشد. اما، وقتی کار شما دستهبندی است (مثلاً تشخیص ایمیل اسپم از غیر اسپم، یا دستهبندی نظرات مشتریان به مثبت و منفی)، خیلی مهم است که کلاسهای مختلف پاسخ را در مثالهایتان مخلوط کنید.
یعنی اگر مثالهایی برای کلاس "مثبت" و کلاس "منفی" دارید، آنها را یکی در میان یا با ترتیبهای مختلف بیاورید، نه اینکه همهی مثالهای "مثبت" را پشت سر هم و بعد همهی مثالهای "منفی" را بیاورید.
چرا این کار مهم است؟ چون اگر این کار را نکنید، ممکن است مدل به جای یاد گرفتن ویژگیهای اصلی هر کلاس، فقط ترتیب آمدن مثالها را یاد بگیرد. با ترکیب کردن کلاسها، مطمئن میشوید که مدل یاد میگیرد چه چیزی واقعاً یک متن را "مثبت" یا "منفی" میکند، نه اینکه صرفاً ترتیب مثالها را حفظ کند. این کار باعث میشود مدل در مواجهه با دادههای جدید که قبلاً ندیده، عملکرد بهتر و قابل اعتمادتری داشته باشد.
یک راهنمایی:
معمولاً خوب است که با حدود ۶ مثال آموزشی شروع کنید و از همانجا دقت مدل را بسنجید و ببینید آیا نیاز به تغییر یا مثالهای بیشتر دارید یا نه.

پرامپتهای خود و نتایج آنها را مستند کنید تا بتوانید آنچه کار میکند و آنچه کار نمیکند را پیگیری کنید.

مهندسی پرامپت یک مهارت ضروری برای استفاده موثر از مدلهای زبانی بزرگ است. در این آموزش، مفاهیم اساسی مهندسی پرامپت، تنظیمات خروجی مدل، تکنیکهای مختلف پرامپت، کاربردها و بهترین شیوهها را پوشش دادم. به یاد داشته باشید که مهندسی پرامپت یک فرآیند تکراری است. آزمایش با پرامپتهای مختلف، تنظیمات مدل و تکنیکها برای دستیابی به بهترین نتایج ضروری است. با تمرین و تجربه، شما میتوانید پرامپتهایی ایجاد کنید که پاسخهای دقیق، مرتبط و مفید از مدل دریافت کنند. به یاد داشته باشید:
- واضح و دقیق باشید: دستورالعملهای واضح و دقیق ارائه دهید.
- از مثالها استفاده کنید: برای وظایف پیچیده، مثالهایی ارائه دهید تا مدل الگو را درک کند.
- فرمت خروجی را مشخص کنید: ساختار و فرمت خروجی مورد نظر خود را مشخص کنید.
- از تکنیکهای پیشرفته استفاده کنید: برای مسائل پیچیده، از تکنیکهایی مانند زنجیره تفکر یا درخت تفکرات استفاده کنید.
- تنظیمات مدل را بهینه کنید: با دما، Top-K و Top-P برای دستیابی به تعادل مناسب بین خلاقیت و دقت آزمایش کنید.
- آزمایش و تکرار کنید: پرامپتهای خود را مستند کنید، نتایج را ارزیابی کنید و بر اساس بازخورد بهبود دهید.
با تمرین و آزمایش مداوم، مهارتهای مهندسی پرامپت شما به طور قابل توجهی بهبود خواهد یافت. همچنین با پیشرفت فناوری مدل های زبانی بزرگ، مهندسی پرامپت نیز تکامل خواهد یافت. به روز ماندن با تکنیکهای جدید و بهترین شیوهها به شما کمک میکند تا از این ابزارهای قدرتمند به طور موثر استفاده کنید.
مهندسی پرامپت چیست و چرا اهمیت دارد؟ مهندسی پرامپت در واقع هنر و علم طراحی ورودیهایی (پرامپتها) برای مدلهای زبانی بزرگ (مانند گوگل جمینای) است که منجر به تولید پاسخهای دقیقتر، مرتبطتر و مطلوبتر میشود. این کار به این دلیل اهمیت دارد که کیفیت خروجی مدل به شدت به کیفیت ورودی آن وابسته است. یک پرامپت خوب میتواند مدل را به سمت تولید پاسخهای مفید و خلاقانه هدایت کند، در حالی که یک پرامپت ضعیف میتواند منجر به پاسخهای مبهم، اشتباه یا نامربوط شود. هدف اصلی مهندسی پرامپت، کنترل و هدایت فرآیند پیشبینی مدل زبانی برای تولید دنبالهای از توکنها است که به بهترین نحو به وظیفه مورد نظر پاسخ دهد.
چگونه تنظیمات نمونهگیری مانند دما، Top-K و Top-P بر خروجی مدل تاثیر میگذارند؟ مدلهای زبانی هنگام تولید پاسخ، برای هر کلمه احتمالی، احتمالی را محاسبه میکنند و سپس بر اساس این احتمالها، کلمه بعدی را "نمونهگیری" میکنند. پارامترهای نمونهگیری به شما امکان میدهند بر این فرآیند تأثیر بگذارید:
پارامتر دما (Temperature): میزان تصادفی بودن و خلاقیت در پاسخها را کنترل میکند. دمای پایین (نزدیک به ۰) منجر به پاسخهای قطعیتر و قابل پیشبینیتر میشود (مناسب برای خلاصهسازی، پاسخ به سؤالات واقعیتمحور). دمای بالا (نزدیک به ۲) پاسخها را متنوعتر، خلاقانهتر و گاهی غیرمنتظره میکند (مناسب برای طوفان فکری، داستاننویسی).
پارامتر Top-K: تعداد محتملترین کلماتی که مدل برای انتخاب کلمه بعدی در نظر میگیرد را محدود میکند. مقدار پایینتر Top-K دامنه گزینهها را محدود کرده و پاسخ را متمرکزتر میکند، در حالی که مقدار بالاتر دامنه را گسترش داده و به تنوع پاسخ کمک میکند.
پارامتر Top-P: کلمات با احتمال پایین را از مجموعه انتخاب حذف میکند. این پارامتر بر اساس مجموع احتمال کلمات عمل میکند. مقدار پایینتر Top-P پاسخهای کماحتمالتر را حذف میکند، در حالی که مقدار بالاتر به مدل اجازه میدهد آزادانهتر بین پاسخها انتخاب کند.
تنظیم دقیق این پارامترها میتواند به کاهش خطاهای احتمالی (مانند توهمات) و تولید خروجیهای مفیدتر کمک کند.
پرامپتهای System، Role و Contextual چه تفاوتها و شباهتهایی دارند؟ این سه نوع پرامپت روشهایی برای ارائه زمینه و دستورالعمل به مدل هستند، اما هدف اصلی آنها متفاوت است:
پرامپت سیستمی (System Prompting): زمینه کلی و هدف اصلی مدل را مشخص میکند. به مدل میگوید چه نوع دستیاری باشد، چگونه پاسخ دهد و چه محدودیتهایی داشته باشد. این پرامپت تصویر بزرگی از وظیفه مدل را ارائه میدهد و میتواند به کنترل ایمنی و کاهش توهمات کمک کند.
پرامپت نقشدار (Role Prompting): یک شخصیت یا هویت خاص به مدل میدهد تا انتظار رفتار متمرکز مطابق با آن نقش را داشته باشیم (مانند ایفای نقش معلم، کارمند آژانس مسافرتی). این پرامپت لحن، سبک و تخصص مورد انتظار از مدل را مشخص میکند.
پرامپت کانتکسچوال (Contextual Prompting): جزئیات خاص یا اطلاعات پسزمینهای اضافی مربوط به موضوع یا وظیفه فعلی را به مدل ارائه میدهد. این اطلاعات به مدل کمک میکند تا بفهمد دقیقاً چه چیزی خواسته شده و پاسخ را بر اساس آن تنظیم کند.
ممکن است در برخی موارد همپوشانیهایی بین این روشها وجود داشته باشد، اما هر کدام تمرکز اصلی متفاوتی برای هدایت مدل دارند.
پرامپتهای Zero-shot، One-shot و Few-shot چگونه به مدل در انجام وظایف کمک میکنند؟ این تکنیکها با ارائه یا عدم ارائه مثال به مدل، توانایی آن را در انجام وظایف تحت تأثیر قرار میدهند:
پرامپت Zero-shot: فقط توصیفی از وظیفه و متن ورودی (سؤال، دستورالعمل و غیره) را به مدل میدهد، بدون ارائه هیچ مثالی. مدل باید صرفاً بر اساس دانش آموزشدیدهاش پاسخ دهد.
پرامپت One-shot: علاوه بر توصیف وظیفه، یک مثال واحد از ورودی و خروجی مورد نظر را به مدل ارائه میدهد.
پرامپت Few-shot: چندین مثال از ورودی و خروجی مورد نظر را به مدل ارائه میدهد.
ارائه مثال (One-shot و Few-shot) به مدل کمک میکند تا الگوهای مورد نظر را بهتر درک کند و پاسخهای دقیقتری تولید کند، به خصوص زمانی که میخواهید مدل را به سمت یک ساختار یا الگوی خروجی خاص هدایت کنید.
تکنیکهای پیشرفتهتر مانند Chain of Thought و Step-back Prompting چگونه استدلال مدل را بهبود میبخشند؟ این تکنیکها با تشویق مدل به فرآیندهای فکری میانی، توانایی استدلال آن را افزایش میدهند:
زنجیره تفکر (Chain of Thought): مدل را وادار میکند تا گامهای استدلالی میانی را قبل از ارائه پاسخ نهایی تولید کند. این روش به مدل کمک میکند در مسائل پیچیدهای که نیاز به استدلال مرحله به مرحله دارند، دقت بیشتری داشته باشد. با نشان دادن نحوه رسیدن به پاسخ در چند مثال (Few-shot Chain of Thought)، میتوانید مدل را به پیروی از این الگو تشویق کنید.
پرامپت استپبک (Step-back Prompting): به جای پاسخ مستقیم به یک سؤال، ابتدا از مدل میخواهد یک گام به عقب برداشته و درباره سؤال اصلی فکر کند یا سؤالات میانی مرتبطی مطرح کند. سپس از این نتایج برای ارائه پاسخ نهایی استفاده میشود. این روش به مدل اجازه میدهد دانش پسزمینه مرتبط را فعال کند و ساختار مسئله را تحلیل کند قبل از حل آن.
این تکنیکها به ویژه برای مسائل پیچیده و چندمرحلهای مفید هستند و میتوانند منجر به پاسخهای دقیقتر و منطقیتر شوند.
تکنیکهای خودسازگاری (Self-consistency) و درخت تفکرات (Tree of Thoughts) چه نوآوریهایی در فرآیند تولید پاسخ ایجاد میکنند؟ این تکنیکها روشهای پیچیدهتری برای کاوش و ارزیابی مسیرهای استدلالی هستند:
خودسازگاری (Self-consistency): مدل را وادار میکند چندین مسیر استدلال مختلف برای یک مسئله تولید کند (معمولاً با تنظیم دمای بالا برای نمونهگیری متنوع). سپس پاسخی که بیشترین سازگاری یا تکرار را در بین این مسیرها دارد، به عنوان پاسخ نهایی انتخاب میشود. این روش دقت و انسجام پاسخهای تولیدشده را بهبود میبخشد.
درخت تفکرات (Tree of Thoughts): تعمیمی از زنجیره تفکر است که به مدل اجازه میدهد چندین مسیر استدلالی را به صورت همزمان کاوش کند و مسیرهای کمامیدوارکننده را کنار بگذارد (هرس کند). در این روش، مدل یک "درخت از افکار" ایجاد میکند که در آن هر گره یک گام میانی در مسیر حل مسئله است و مدل میتواند از گرههای مختلف انشعاب گرفته و مسیرهای متفاوتی را کاوش کند. این روش برای وظایف پیچیدهای که نیازمند کاوش گسترده هستند، مناسب است.
این تکنیکها با افزایش تنوع و عمق فرآیند استدلال داخلی مدل، پتانسیل آن را برای حل مسائل دشوارتر افزایش میدهند.
پارادایم ReAct (Reason & Act) چه کاربرد و مزیتی دارد؟ پرامپت ReAct (Reason & Act) یک پارادایم جدید است که توانایی استدلال زبان طبیعی مدل را با استفاده از ابزارهای خارجی ترکیب میکند. در این روش، مدل در یک حلقه "فکر-عمل" کار میکند: ابتدا درباره مسئله استدلال کرده و یک طرح عملی (شامل استفاده از ابزارهایی مانند جستجو یا کد) تولید میکند، سپس اقدامات موجود در طرح را اجرا کرده و نتایج را مشاهده میکند. مدل از این مشاهدات برای بهروزرسانی استدلال و طرح خود استفاده میکند تا به راهحل برسد.
مزیت اصلی ReAct این است که به مدل اجازه میدهد با دنیای خارج تعامل داشته باشد، اطلاعات بهروز را دریافت کند و وظایف پیچیدهای را که صرفاً با استدلال داخلی قابل حل نیستند، انجام دهد. این یک گام اولیه به سمت مدلسازی "ایجنت" است که میتواند به صورت مستقل عمل کرده و با محیط خود تعامل داشته باشد.
بهترین شیوهها و نکات کاربردی برای نوشتن پرامپتهای مؤثر کدامند؟ برای دستیابی به بهترین نتایج در مهندسی پرامپت، رعایت نکات زیر توصیه میشود:
ارائه مثال: استفاده از پرامپتهای تکشات و بهخصوص چندشات با مثالهای واضح و مرتبط، یکی از مؤثرترین روشها برای هدایت مدل و بهبود دقت پاسخها است.
طراحی ساده و واضح: پرامپتها باید ساده، مستقیم و بدون ابهام باشند. از زبان پیچیده و دستورالعملهای مبهم پرهیز کنید. استفاده از افعال دستوری مشخص (مانند Analyse, Summarize, Translate) مفید است.
مشخص کردن خروجی: فرمت، ساختار و هرگونه ویژگی خاص مورد انتظار در خروجی را به وضوح مشخص کنید.
استفاده از دستورالعملها به جای محدودیتها: به جای گفتن آنچه مدل نباید انجام دهد، به آن بگویید چه کاری باید انجام دهد. دستورالعملهای مثبت معمولاً مؤثرتر از محدودیتها هستند، اگرچه محدودیتها برای کنترل ایمنی یا قالبهای خاص ضروری هستند.
کنترل طول توکن: با تنظیم حداکثر طول خروجی یا گنجاندن درخواستهای ایجاز در پرامپت، طول پاسخ مدل را کنترل کنید.
استفاده از متغیرها: برای پرامپتهای قابل استفاده مجدد و پویا، از متغیرها برای ورودیهای مختلف استفاده کنید.
آزمایش با فرمتها و سبکهای مختلف: با سبکهای نوشتاری مختلف (رسمی، غیررسمی، توصیفی و غیره)، کلمات و ساختارهای جمله متفاوت در پرامپت خود آزمایش کنید تا ببینید کدامیک بهترین نتایج را برای وظیفه مورد نظر تولید میکند.
مستندسازی: پرامپتها و نتایج آنها را مستند کنید تا بتوانید آنچه مؤثر بوده و آنچه مؤثر نبوده است را پیگیری کرده و فرآیند بهبود را ادامه دهید.
مهندسی پرامپت یک فرآیند تکراری است که نیازمند آزمایش، ارزیابی و بهبود مداوم است.