دیتا ساینس یعنی استفاده از داده برای پیشبینی وقوع یک پدیده در شرایط مختلف. برای انجام این کار، ما یک مدل بر اساس داده های موجود ارائه میکنیم و از آن مدل استفاده میکنیم تا وقوع یک پدیده را در شرایط نزدیک به داده هایمان پیشبینی کنیم. مشخص است که برای اینکه مدل ما یک پیشبینی دقیق انجام دهد، باید به خوبی با داده های اولیه آموزش تطبیق داده شده باشد.
در حالت کلی، دو نوع تطبیق نیافتن برای مدل وجود دارد:
کمبرازش: کمبرازش یا Underfitting حالتی است که مدل آنقد پیچیده نیست که روی داده ها تطبیق بیابد. در این حالت عملکرد مدل روی داده های فعلی مناسب نیست و نمیتواند بین آنها ارتباطی برقرا کند. یک مثال از مدل کمبرازش میتوان مدلی را مثال زد که میخواهد نرخ مالیات را در کشوری که نرخ مالیات در حال افزایش است، پیشبینی کند. در این حالت، مدل فکر میکند که نرخ مالیات برای همه افراد در حال افزایش است و میزان درآمد مردم در آن تاثیری ندارد، در نتیجه میزان نرخ مالیات را برای همه افراد یکسان در نظر میگیرد.
بیشبرازش: بیشبرازش یا Overfitting حالتی است که مدل بیش از حد پیچیده است. این پیچیدگی به این معناست که مدل برای هر داده موجود دیتاست، تغییرات زیادی را اعمال میکند. عملکرد این مدل ها بر روی داده های موجود یعنی داده هایی که آنها را قبلا دیده و تطبیق داده شده، عالی است اما در پیشبینی های آینده عملکرد بدی دارد.
این دو مفهوم را میتوانید در شکل زیر ببینید. نقاط مشکی را داده های موجود در نظر بگیرید. نرخ مالیات نقطه ده هزار دلار، ده درصد، بیست هزار دلار بیست درصد و سی هزار دلار سی درصد است. چند نقطه رندوم هم وجود دارند که نشان دهنده این موضوع است که ممکن است میزان مالیات یک خانه، از این قاعده پیروی نکند و شرایط برای آنها فرق کند. خط آبی رنگ را که نشان دهنده مدل کمبرازش است در نظر بگیرید. این نوع مدل فکر میکند که نرخ مالیات یک روند خطی دارد. مدل بیش برازش با رنگ قرمز، یک مدل پیچیده است که فکر میکند باید دلیلی برای هر نرخ مالیات داشته باشد.
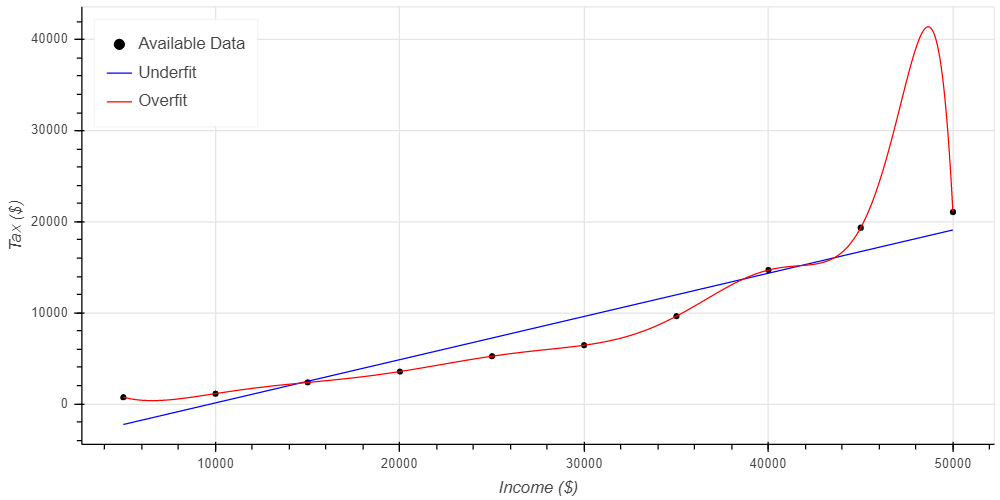
همانطورکه پیداست مدل کمبرازش عملکرد ضعیفی دارد و کلاً سه نقطه را میتواند درست حدس بزند. همچنین در فهمیدن اینکه نرخ مالیات با افزایش میزان درآمد رابطه مستقیم دارد، ضعیف عمل کرده است.
مدل بیشبرازش عملکرد عالی ای دارد. همه نقاط را توانسته تطبیق دهد و شکل داده ها را هم درست درآورده است. اما این روند تا جایی صادق است که به چهل هزار دلار میرسد. در بازه 40 تا 44 هزار دلار هیچ افزایشی در نرخ مالیات را پیشبینی نکرده است. اما مشکل اصلی در بازه 45 تا 50 هزار دلار اتفاق میافتد. پیشبینی مدل این است که وقتی درآمد از 45 به 49 هزار دلار افزایش مییابد، نرخ مالیات هم با افزایش 22 هزار دلاری همراه میشود. این در حالی است که هیچ داده ای موجود نیست تا این حدس را اثبات کند! این مدل افزایش هایی را حدس میزند که در واقع اصلا واقعی نیستند.
برای فهمیدن اینکه مدل شما کمبرازش است یا بیشبرازش، میتوان توضیحات بالا را مدنظر قرار داد. در پایین خلاصه ای از آن را میتوانید بخوانید.
مدل های کمبرازش را میتوان شناسایی کرد چون:
مدل های بیشبرازش را میتوان شناسایی کرد چون:
یک مدل خوببرازش یا Well Fit Model باید داده های موجود را به خوبی تطبیق دهد و شکل داده ها را هم به خوبی نشان دهد. در شکل زیر میتواند عملکرد چنین مدلی را روی همان داده های شکل قبلی ببینید.
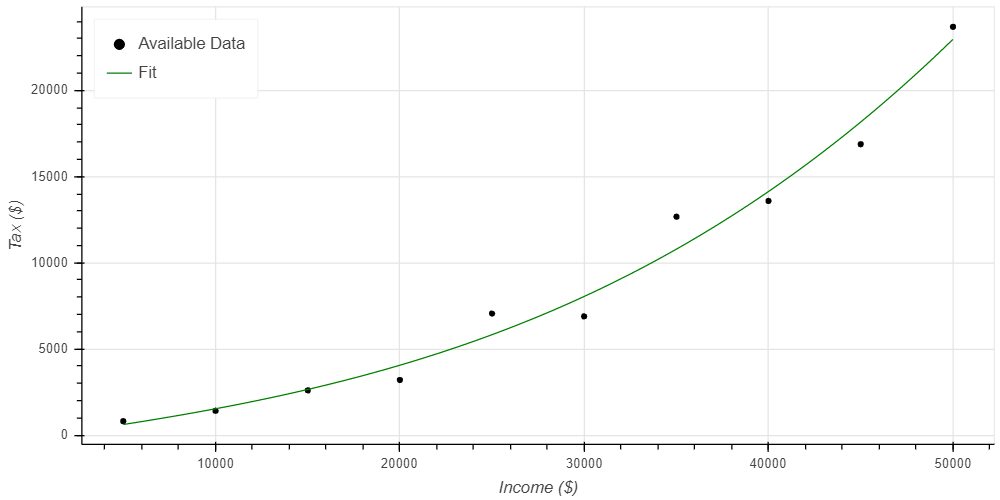
همانطور که میبینید این مدل در پیشبینی همه داده ها عملکرد خوبی ندارد اما با توجه به وجود داده های رندوم و پرت در دیتاست، چنین چیزی انتظار میرود. نکته دیگر این است که شکلی که مدل نشان میدهد به خوبی با داده ها مطابقت دارد. این شکل مانند خط آبی، نه خیلی ساده است، نه مثل منحنی قرمز خیلی پیچیده است. از این مدل میتوان انتظار داشت که پیشبینی های خوبی را انجام دهد.
ارائه مدل و اعتبارسنجی آن یکی از مفهوم های اصلی و مهم در دیتا ساینس است. برای انجام هر نوع کار دیتا ساینس، باید مطمئن باشیم مدل ما روی داده های موجود به خوبی تطبیق داده شده است و همچنین پیشبینی خوبی را در داده هایی که تا به حال ندیده انجام میدهد.