
این پروژه در اصل تکلیف یکی از دوستانم بود و من برای کمک به او سراغش رفتم.
در ابتدا تقریباً همه چیز برایم مبهم بود و درک روشنی از نحوه کار مدل نداشتم.
ابتدا کد را به AI دادم تا توضیح بدهد. توضیحاتی دریافت کردم، اما خیلی زود متوجه شدم که با خواندن توضیح آماده، فهم عمیق اتفاق نمیافتد.
به همین دلیل از AI خواستم کد را سادهتر کند، چون تا آن زمان من زبان C++ را در حد مقدماتی و در حد یک ترم دانشگاه بلد بودم.
از آنجایی که تبدیل الگوریتم نوشتاری به کد را بسیار دوست دارم، تصمیم گرفتم این بار هم همین کار را انجام دهم. بنابراین از AI خواستم الگوریتم نوشتاری (pseudocode) را استخراج کند و خودم آن را به C++ تبدیل کنم.
و اینجا بود که کار اصلی شروع شد.
اولین چیزی که باید میفهمیدم این بود که این کد دقیقاً چه کاری انجام میدهد و منطق آن چیست.
با کمی تحقیق به این نتیجه رسیدم که میتوان مفهوم آن را با یک مثال ساده توضیح داد:
فرض کنید:
در یک کیسه 5 سیب داریم و جرم آن 527 گرم است.
در کیسهای دیگر 8 سیب داریم و جرم آن 798 گرم است.
در کیسهای دیگر 3 سیب داریم و جرم آن را اندازه میگیریم.
با چند بار اندازهگیری متوجه میشویم جرم هر سیب تقریباً حدود 100 گرم است.
اگر از ما بپرسند جرم 6 سیب چقدر است، میتوانیم با تقریب خوبی پیشبینی کنیم.
این دقیقاً همان کاری است که مدل Linear Regression انجام میدهد:
آزمایش میکند، تکرار میکند و یاد میگیرد.
پایه این مدل فرمول زیر است:
y = a x + b
در پروژه من:
height = a ⋅ weight + b
اولین مرحله عملی، تعریف دادههای آموزشی بود.
برای این مدل از قد و وزن افراد استفاده کردم:
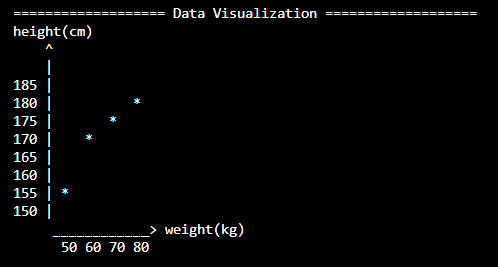
weight (kg): 50 ، 60 ، 70 ، 80
height (cm): 155 ، 168 ، 175 ، 181
در مدل اولیه از آرایههای C-style استفاده شده بود، اما چون آنها قدیمی هستند، تصمیم گرفتم از آرایههای مدرنتر C++ استفاده کنم.

در نسخه اولیه، دادهها به صورت خطی چاپ میشدند؛ هر فرد در یک خط با مشخصاتش.
این مدل نمایش برای من جذاب نبود.
تصمیم گرفتم دادهها را به صورت نمودار نقطهای در ترمینال نمایش دهم.
برای رسیدن به نمودار مناسب، چهار نسخه مختلف نوشتم تا در نهایت به مدلی رسیدم که:
دادهها را به صورت نقطهای نشان میداد
فاصله واقعی دادهها را حفظ میکرد
محور height و weight مشخص بود
این بخش از پروژه کاملاً طراحی و پیادهسازی شخصی خودم بود.
فرآیند آموزش مدل با استفاده از یک for loop انجام شد.
این حلقه شامل مراحل زیر بود:
جمعآوری تغییرات (Gradient Calculation)
محاسبه میانگین تغییرات
بهروزرسانی پارامترهای مدل (Update a and b)
گزارش میانگین خطا (Average Error Report)
متغیرهای اصلی مدل:
learning_rate
epochs
در ابتدا:
learning_rate = 0.001
epochs = 50,000
تمام متغیرهای محاسباتی از نوع float بودند.

پس از آموزش، بخش پیشبینی و محاسبه خطا نوشته شد.
در نسخه اولیه، نتایج به صورت خطی نمایش داده میشدند.
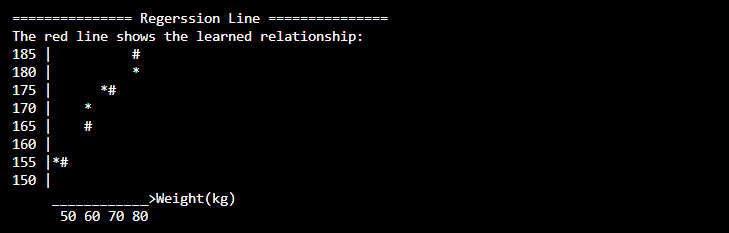
اما مشابه مرحله قبل، تصمیم گرفتم این بخش را نیز نموداری کنم.
در این مرحله:
دادههای واقعی با علامت *
خط رگرسیون با علامت #
نمایش داده شدند.
پیادهسازی این بخش دشوارتر از نمودار اولیه بود و با چندین بار تکرار و اصلاح به نتیجه رسیدم.
پس از اجرای اولیه، مشکلات فنی شروع شدند.
به دلیل اینکه متغیرها از نوع float بودند، در طول آموزش مدل مقدارها به overflow رسیدند و خروجیها به صورت NaN نمایش داده شدند.
راهحل:
تغییر نوع تمامی متغیرهای محاسباتی از float به double.

پس از این تغییر، به دلیل دقت و ظرفیت بیشتر double، محاسبات به درستی انجام شدند.
پس از اجرای موفق، مقدار خطای مدل حدود 12 cm بود که برای من قابل قبول نبود.
از آنجا که از double استفاده میکردم، امکان تنظیم دقیقتر پارامترها وجود داشت.
تغییرات انجامشده:
افزایش epochs از 50,000 به 240,000
کاهش learning_rate به 0.00045
نتیجه:
کاهش خطا از حدود 12 cm به حدود 1.08 cm


این کاهش خطا برای من یک پیشرفت جدی محسوب میشد.
در پایان، مدل توانست رابطهای خطی بین weight و height یاد بگیرد و با دقت مناسبی پیشبینی انجام دهد.
این پروژه برای من چند نکته مهم داشت:
فهم عملی Gradient Descent
درک تاثیر learning_rate
درک تاثیر epochs
اهمیت نوع داده (float vs double) در محاسبات عددی
اهمیت Visualization در فهم بهتر الگوریتم
این بار کافی بود فقط شروع کنم.
نتیجه، پیادهسازی یکی از سادهترین اما مهمترین مدلهای Machine Learning به صورت کامل در C++ بود، بدون استفاده از کتابخانههای آماده.
برای مشاهده کد کامل میتوانید به صفحه Github مراجعه کنید.