تحلیل تطبیقی غلطیابی در زبانهای پارسی و انگلیسی: از بیقاعدگیهای نوشتاری تا پیچیدگی صرفی (ساختواژه)
تکنیکهای توضیح داده شده در بالا عمدتاً برای رسیدگی به یک دسته از خطاها طراحی شدهاند. با این حال، یک سیستم کامل غلطیابی باید با دو نوع اشتباه متفاوت مقابله کند، تقسیمبندیای که اساساً روشهای معماری مورد نیاز را به دو مسیر مجزا تقسیم میکند.
در پردازش زبان و بررسی املایی، دو نوع اصلی از خطاها وجود دارد که بهطور متفاوتی باید شناسایی و اصلاح شوند:
خطاهای غیرکلمهای (Non-Word Errors):
این اینها خطاهایی هستند که منجر به ایجاد رشتهای از حروف میشوند که واژهای معتبر در واژگان زبان نیست (برای مثال: "langauge"، "teh"، "acheive"). این نوع خطاها از طریق جستوجو در فرهنگ لغت قابل شناسایی هستند و هدف اصلی الگوریتمهای فاصله ویرایشی و الگوریتمهای آوایی به شمار میروند
خطاهای واقعی (Real-Word Errors):
این خطاها بهمراتب چالشبرانگیزتر هستند. زمانی رخ میدهند که یک خطای نوشتاری بهطور اتفاقی منجر به ایجاد یک واژه معتبر دیگر شود (برای مثال، نوشتن "from" به جای "form" یا "their" به جای "there"). از آنجا که واژه حاصل در فرهنگ لغت وجود دارد، روشهای بدون درنظرگرفتن متن کاملاً نسبت به آنها ناتوان هستند.
شناسایی و اصلاح خطاهای واقعی مستلزم آن است که نرمافزار زمینه واژه را در جمله تحلیل کند. این کار با استفاده از مدلهای زبانی زمینهای انجام میشود که احتمال وقوع یک دنباله واژگان را ارزیابی میکنند. سنتیترین رویکرد در این زمینه مدل n-تایی واژه است (مانند بایگرام (دوتایی) یا تریگرام (س تایی). این مدلها احتمال یک واژه را بر اساس n−1 واژه پیشین محاسبه میکنند.
برای نمونه، در جمله «I saw there house»، یک مدل تریگرام احتمال دنباله «saw there house» را بسیار پایینتر از «saw their house» ارزیابی میکند و در نتیجه، «there» را بهعنوان یک خطای احتمالی مشخص میسازد.
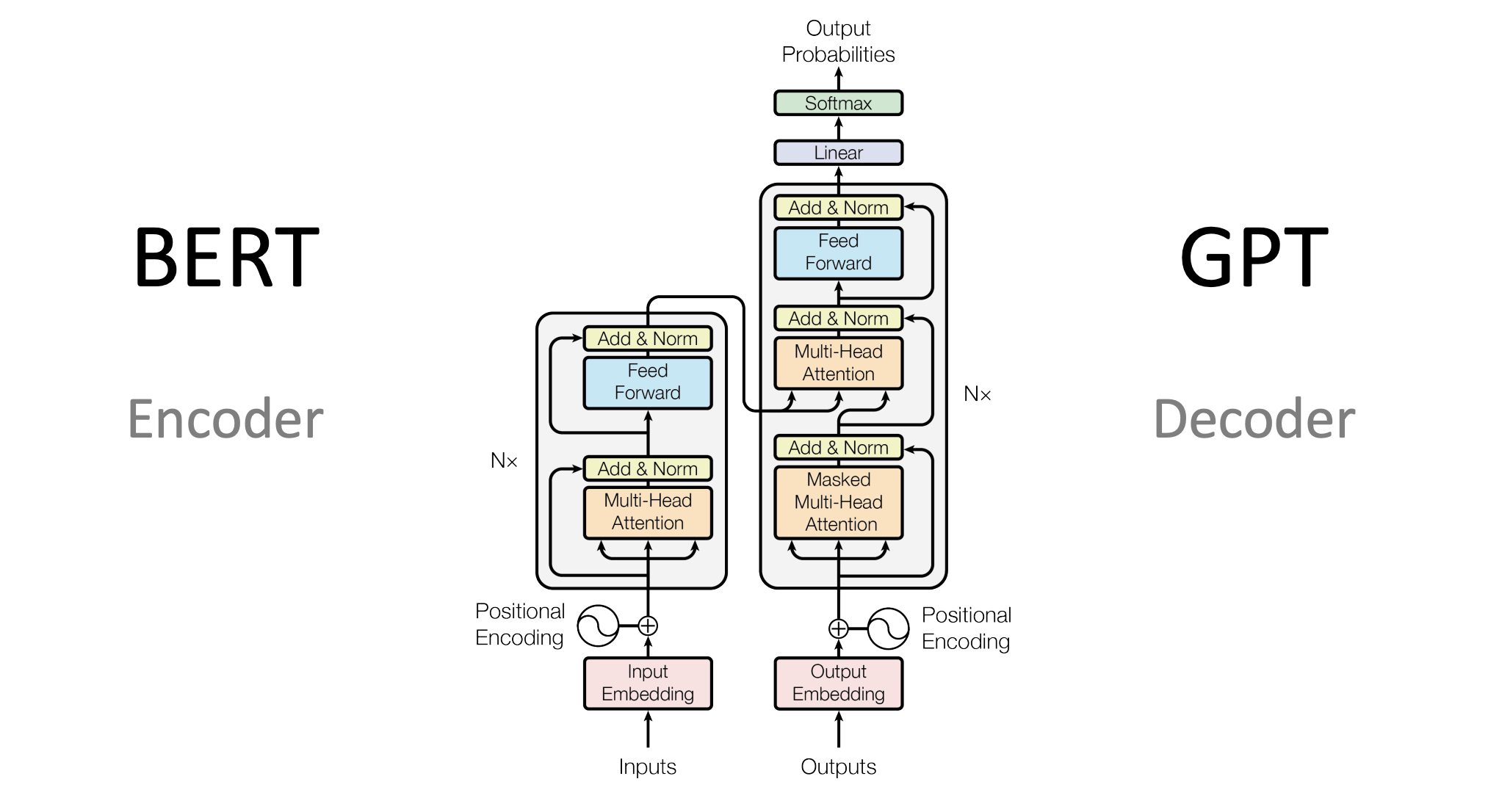
بهتازگی، ظهور Deep Learning یا یادگیری عمیق مدلهای زمینهای بسیار قدرتمندتری را معرفی کرده است. معماریهای مبتنی بر ترنسفورمر یا مبدل مانند BERT (Bidirectional Encoder Representations from Transformers) (ارایه رمزگذار دوجهتی از ترنسفورمرها) قادرند کل زمینه جمله (واژههای قبل و بعد) را تحلیل کنند تا درک معنایی عمیقی به دست آورند. با ماسک کردن یک واژه و پیشبینی جایگزین محتملترین آن، این مدلها میتوانند خطاهای واقعی ظریف را با دقت بسیار بالاتری نسبت به مدلهای n-گرامی شناسایی کنند.
برای فهمیدن این موضوع لازم است توضیحاتی درباره Transformerها داده شود. واژه معروف GPT در کلماتی مانند ChatGPT هم سرواژه عبارت Generative Pre-trained Transformer است.
بطور بسیار خلاصه، ترنسفورمر نوعی مدل یادگیری عمیق است که برای پردازش زبان طبیعی (و حتی کارهای دیگر مثل تصویر) ساخته شده است. کاری که انجام میدهد این است که به جای نگاه کردن به کلمات بصورت تکتک و یکییکی، کل جمله را همزمان نگاه میکند و روابط بین تمام کلمات را درک میکند. این کار باعث میشود مدل بفهمد یک کلمه در جمله چه نقشی دارد و معنای کلی جمله چیست.
BERT یک مدل معروف بر پایه ترنسفورمر است. کاری که BERT انجام میدهد این است که جمله را از دو طرف نگاه میکند (یعنی هم کلمات قبل و هم کلمات بعد از یک واژه خاص) و سعی میکند بهترین واژه جایگزین را پیشبینی کند. این ویژگی باعث میشود BERT بتواند خطاهای ظریف واژهای را تشخیص دهد و معنای جمله را نسبت به مدلهای قدیمی مثل n-گرام بسیار بهتر بفهمد.
قبل از توضیح مفصلتر درباره معماری Transformer، شاید بهتر باشه نگاهی به دنیای پردازش زبانهای طبیعی قبل از پیدایش ترنسفورمر بیندازیم. قبل از مدل ترنسفورمر که دنیای پردازش زبان طبیعی رو متحول کرد، Recurrent Neural Networks یا شبکههای عصبی بازگشتی (RNN) و Long Short-Term Memory یا حافظه بلندمدت کوتاهمدت (LSTM) ابزارهای اصلی برای کار با دادههای ترتیبی مثل متن یا سریهای زمانی بودند.
شبکههای عصبی بازگشتی برای پردازش دادههایی طراحی شدهاند که ترتیب در آنها اهمیت دارد، مانند جملات در یک متن یا دادههای سری زمانی. این شبکهها نوعی حافظه داخلی دارند که اطلاعات را از یک مرحله به مرحله بعدی منتقل میکند.
نحوه کار: شبکه RNN دادهها را بهصورت گامبهگام پردازش میکند. در هر گام، ورودی جدید (مانند یک کلمه) با اطلاعات ذخیرهشده از گامهای قبلی ترکیب میشود تا خروجی تولید کند و حافظه بهروزرسانی شود. این فرآیند مانند دنبال کردن یک زنجیره اطلاعاتی است که در هر مرحله تکمیل میشود.
مزایا:
توانایی پردازش دادههایی با طولهای متفاوت.
مناسب برای کاربردهایی مانند تشخیص گفتار یا پیشبینی سریهای زمانی.
محدودیتها:
حافظه محدود: در درک ارتباط بین دادههایی که فاصله زیادی از هم دارند، عملکرد ضعیفی دارد.
پردازش کند: به دلیل پردازش ترتیبی، امکان انجام محاسبات همزمان وجود ندارد.
چالشهای یادگیری: گاهی یادگیری شبکه به دلیل مشکلات فنی دشوار میشود.
LSTM نسخه پیشرفتهتری از RNN است که برای رفع مشکلات آن، بهویژه ناتوانی در حفظ اطلاعات بلندمدت، توسعه یافته است. این شبکه میتواند اطلاعات مهم را برای مدت طولانیتری حفظ کند.
نحوه کار: LSTM دارای یک حافظه داخلی است که مانند یک دفترچه یادداشت عمل میکند. این حافظه توسط سه مکانیزم کنترلی مدیریت میشود:
مکانیزم فراموشی: مشخص میکند چه اطلاعاتی از حافظه حذف شود.
مکانیزم ورودی: تصمیم میگیرد چه اطلاعات جدیدی به حافظه اضافه شود.
مکانیزم خروجی: تعیین میکند کدام اطلاعات از حافظه برای تولید خروجی استفاده شود. این مکانیزمها به شبکه اجازه میدهند اطلاعات مهم را نگه دارد و موارد غیرضروری را کنار بگذارد.
مزایا:
یادگیری ارتباطات طولانی: توانایی درک ارتباط بین بخشهای دور در دادهها، مانند جملات طولانی در متن.
یادگیری پایدارتر: مشکلات یادگیری RNN را تا حد زیادی برطرف کرده است.
کاربرد گسترده: در زمینههایی مانند ترجمه متن، تحلیل احساسات و تشخیص گفتار استفاده شده است.
محدودیتها:
پیچیدگی بالا: به دلیل ساختار پیچیده، پردازش آن زمانبرتر است.
پردازش ترتیبی: مانند RNN، دادهها را بهصورت گامبهگام پردازش میکند که سرعت را کاهش میدهد.
نیاز به منابع بیشتر: برای دادههای ساده ممکن است بیش از حد پیچیده باشد.
البته نباید تصور کرد که با ظهور ترنسفورمر مدلهایی مانند RNN و LSTM منسوخ شدهاند، در کاربردهایی مثل دستهبندی ایمیل یا تشخیص اسپم هنوز کاربرد دارند. در پردازش صدا و گفتار و پیشبینی سریهای زمانی مانند قیمت سهام و تحلیل نوارهای مغز و قلب و روباتیک و تشخیص ناهنجاری مانند تقلب و کلاهبرداری در سیستمهای مالی و کاربردهایی که نیاز به منابع بسیار محدودتر از مدلهای ترنسفورمر دارند هنوز مورد استفاده هستند.
حالا به تعریف کاملتر از ترنسفورمر برمیگردیم
ترنسفورمر یک معماری شبکه عصبی است که در سال ۲۰۱۷ توسط گروهی از پژوهشگران در مقالهای با عنوان «توجه همه آن چیزی است که نیاز دارید» (Attention is All You Need) معرفی شد. این مدل برای پردازش دادههای ترتیبی، بهویژه در پردازش زبان طبیعی (مانند ترجمه، تولید متن و پاسخ به پرسشها) طراحی شده است. برخلاف مدلهای قبلی مانند RNN و LSTM که دادهها را بهصورت گامبهگام پردازش میکردند، ترنسفورمر با استفاده از مکانیزم «توجه» (Attention) میتواند تمام بخشهای داده را بهصورت همزمان بررسی کند. این ویژگی باعث شده که ترنسفورمرها سریعتر، قویتر و مناسبتر برای دادههای بزرگ باشند.
ترنسفورمر از دو بخش اصلی تشکیل شده است: انکودر یا رمزگذار (Encoder) و دیکودر d (Decoder). هر کدام از این بخشها شامل چندین لایه است که با همکاری هم دادهها را پردازش میکنند.
انکودر:
وظیفه انکودر دریافت ورودی (مثلاً یک جمله به زبان انگلیسی) و تبدیل آن به یک نمایش فشرده و معنادار است.
هر لایه انکودر شامل دو بخش اصلی است:
مکانیزم توجه خودکار (Self-Attention): این مکانیزم به مدل کمک میکند تا بفهمد کدام بخشهای ورودی به هم مرتبط هستند. مثلاً در جمله «گربه روی میز خوابید»، مکانیزم توجه میفهمد که «گربه» و «خوابید» ارتباط قویتری دارند تا «گربه» و «روی».
شبکه پیشبر (Feed-Forward Network): پس از توجه، اطلاعات پردازششده به یک شبکه عصبی ساده فرستاده میشود تا معانی پیچیدهتر استخراج شود.
چندین لایه انکودر (معمولاً ۶ لایه یا بیشتر) پشت سر هم قرار میگیرند تا اطلاعات ورودی را بهخوبی تحلیل کنند.
دیکودر:
دیکودر خروجی (مثلاً ترجمه جمله به فارسی) را تولید میکند.
مانند انکودر، دیکودر هم شامل لایههایی با مکانیزم توجه و شبکه پیشبر است، اما یک تفاوت مهم دارد:
دیکودر علاوه بر توجه به خروجیهای خودش، به خروجیهای انکودر هم نگاه میکند تا ورودی و خروجی را هماهنگ کند. مثلاً برای ترجمه، دیکودر مطمئن میشود که معنای جمله ورودی حفظ شود.
دیکودر هم معمولاً از چندین لایه تشکیل شده است.
مکانیزم توجه (Attention):
قلب ترنسفورمر مکانیزم توجه است. این مکانیزم به مدل اجازه میدهد تا روی بخشهای مهم داده تمرکز کند و ارتباطات بین آنها را بفهمد.
مثلاً در ترجمه، اگر کلمهای در جمله ورودی به کلمه خاصی در جمله خروجی مرتبط باشد، مکانیزم توجه این ارتباط را تقویت میکند.
توجه خودکار (Self-Attention) به مدل کمک میکند تا حتی بدون ترتیب خاصی، تمام بخشهای یک جمله را همزمان بررسی کند.
رمزگذاری موقعیت (Positional Encoding):
چون ترنسفورمر دادهها را بهصورت همزمان پردازش میکند و ترتیب گامبهگام ندارد، نیاز به روشی برای درک ترتیب کلمات (مثلاً کدام کلمه اول یا دوم است) دارد.
رمزگذاری موقعیت اطلاعات مربوط به ترتیب کلمات را به مدل اضافه میکند تا متوجه شود «گربه روی میز» با «میز روی گربه» فرق دارد.
پردازش موازی: برخلاف RNN و LSTM که دادهها را یکییکی پردازش میکردند، ترنسفورمر همه دادهها را همزمان بررسی میکند. این باعث میشود سرعت آموزش و پردازش خیلی بالاتر برود.
درک ارتباطات طولانی: مکانیزم توجه به مدل اجازه میدهد تا ارتباط بین کلمات یا بخشهایی که فاصله زیادی از هم دارند را بهخوبی درک کند.
مقیاسپذیری: ترنسفورمرها با دادههای بزرگ و سختافزارهای پیشرفته (مثل GPU) بسیار خوب کار میکنند و میتوانند مدلهای عظیمی مثل BERT یا GPT را پشتیبانی کنند.
انعطافپذیری: در انواع وظایف مثل ترجمه، خلاصهسازی متن، پاسخ به سؤالات و حتی تولید تصویر (در مدلهای جدیدتر) کاربرد دارند.
نیاز به منابع زیاد: ترنسفورمرها برای آموزش به سختافزارهای قوی و دادههای زیاد نیاز دارند، که برای پروژههای کوچک یا دستگاههای کمقدرت مناسب نیست.
پیچیدگی محاسباتی: مکانیزم توجه برای دادههای خیلی طولانی (مثل متنهای چندصفحهای) میتواند بسیار سنگین و پرهزینه باشد.
عدم درک ترتیب ذاتی: چون ترتیب دادهها را با رمزگذاری موقعیت میفهمد، ممکن است در برخی موارد خاص به اندازه RNN و LSTM برای دادههای ترتیبی خاص (مثل سریهای زمانی) مناسب نباشد.
نیاز به دادههای زیاد: برای عملکرد خوب، ترنسفورمرها به حجم زیادی داده برای آموزش نیاز دارند.
ترنسفورمرها به دلیل قدرت و انعطافپذیریشان در بسیاری از زمینهها استفاده میشوند:
ترجمه ماشینی: مثل گوگل ترنسلیت که جملات را بین زبانها ترجمه میکند.
تولید متن: مدلهایی مثل GPT برای نوشتن متن، داستان یا حتی شعر.
پاسخ به پرسشها: سیستمهایی مانند گروک که به پرسشهای کاربران پاسخ میدهند.
خلاصهسازی متن: تبدیل متنهای طولانی به خلاصههای کوتاه و مفید.
تشخیص گفتار و تولید صوت: تبدیل گفتار به متن یا برعکس.
کاربردهای غیرزبانی: مثل پردازش تصاویر در مدلهایی مانند Vision Transformer یا تولید محتوا در DALL·E.
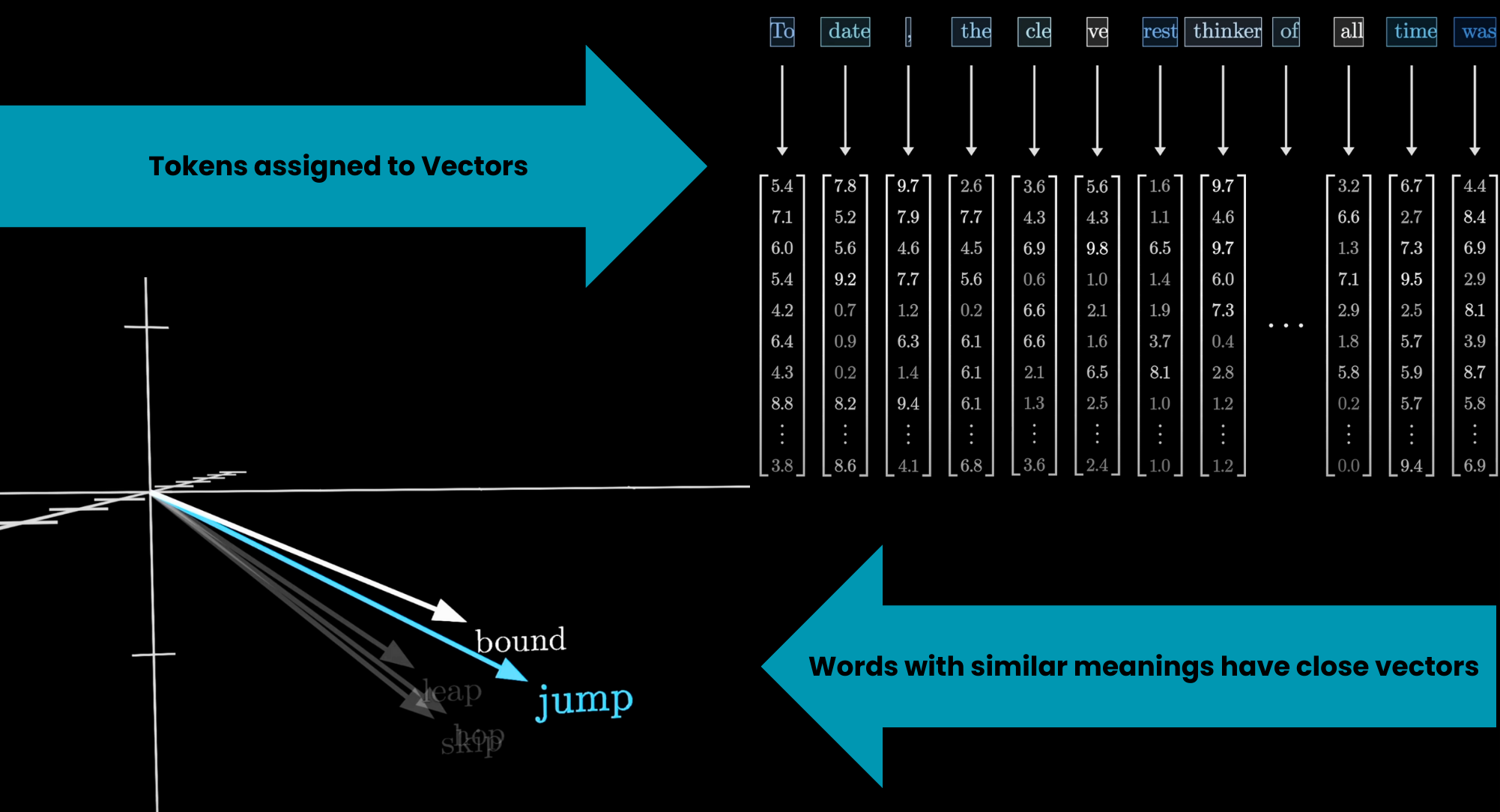
مکانیزم توجه یک روش کلیدی در مدلهای یادگیری عمیق، بهویژه ترنسفورمرها، است که به مدل کمک میکند تا روی بخشهای مهم داده تمرکز کند و ارتباطات بین آنها را بهتر درک کند. به جای پردازش همه دادهها بهطور یکسان، این مکانیزم مانند یک فیلتر عمل میکند و اهمیت هر بخش را نسبت به بخشهای دیگر محاسبه میکند.
ورودیها: دادهها (مثل کلمات یک جمله) به بردارهای عددی تبدیل میشوند.
محاسبه اهمیت: برای هر بخش، مدل بررسی میکند که چقدر به بخشهای دیگر مرتبط است (مثل اینکه در جمله «گربه روی درخت پرید»، کلمه «گربه» بیشتر به «پرید» مرتبط است تا «روی»).
وزندهی: بخشهای مهمتر وزن بیشتری میگیرند و در خروجی تأثیرگذارتر هستند.
توجه خودکار (Self-Attention): مدل به ارتباطات داخل یک مجموعه داده (مثل کلمات یک جمله) توجه میکند.
توجه چندسر (Multi-Head Attention): نسخه پیشرفتهای که توجه را در چندین جهت همزمان محاسبه میکند تا جنبههای مختلف روابط را پوشش دهد.
مکانیزم توجه چندسر نسخه پیشرفتهای از مکانیزم توجه خودکار (Self-Attention) است که در ترنسفورمرها استفاده میشود. این روش به مدل اجازه میدهد تا به جنبههای مختلف ارتباطات بین دادهها بهطور همزمان نگاه کند و درک عمیقتری از آنها به دست آورد.
در توجه خودکار، مدل بررسی میکند که هر بخش از داده (مثل یک کلمه در جمله) چقدر به بخشهای دیگر مرتبط است. مثلاً در جمله «گربه روی درخت پرید»، مدل میفهمد که «گربه» بیشتر به «پرید» مرتبط است.
در توجه چندسر، این فرآیند چندین بار (بهصورت موازی) تکرار میشود، اما هر بار با زاویه دید متفاوتی. انگار مدل به جای یک نگاه کلی، از چند زاویه به دادهها نگاه میکند.
مثلاً یک «سر» (Head) ممکن است روی ارتباط معنایی بین کلمات تمرکز کند (مثل «گربه» و «پرید»).
سر دیگر ممکن است روی ساختار دستوری تمرکز کند (مثل ارتباط بین «روی» و «درخت»).
هر سر یک مجموعه وزن تولید میکند که نشان میدهد کدام بخشها مهمترند. سپس این وزنها ترکیب میشوند تا مدل تصویر کاملتری از دادهها داشته باشد.
درک چندجانبه: با بررسی دادهها از زوایای مختلف، مدل روابط پیچیدهتر را بهتر درک میکند.
انعطافپذیری: به مدل کمک میکند تا در وظایف مختلف (مثل ترجمه یا خلاصهسازی) بهتر عمل کند.
مثلاً در ترجمه جمله «I love to read» به «من عاشق خواندنم»، یک سر ممکن است روی معنای «love» و «عاشق» تمرکز کند، در حالی که سر دیگر ترتیب کلمات را بررسی میکند.
در بخش بعد موضوع غلطیابی با توجه به ویژگیهای خاص زبان انگلیسی بیشتر بررسی میشود.