امروزه بسیاری از نرمافزارها و سرویسهای آنلاین روی سیستمهای پیچیده و توزیعشده اجرا میشوند. در چنین سیستمهایی ممکن است مشکلاتی مانند قطعی سرور، اختلال شبکه، افزایش ناگهانی کاربران یا خرابی بخشی از سیستم رخ دهد. مهندسی آشوب (Chaos Engineering) روشی است که به کمک آن این نوع خرابیها بهصورت عمدی و کنترلشده شبیهسازی میشوند تا مشخص شود سیستم در شرایط بحرانی چگونه عمل میکند.
فرض کنید یک ماشین جدید ساختهاید. به جای اینکه منتظر بمانید تا در جاده و حین رانندگی تصادف کند، خودتان در پیست آزمایش با پتک به بدنه آن میکوبید یا ترمزها را دستکاری میکنید تا ببینید چقدر محکم است!
مهندسی آشوب دقیقاً همین است. یعنی ما عمداً و در یک محیط کنترلشده، خرابکاریهایی (مثل قطع کردن یک سرور، شبیهسازی قطع اینترنت و یا پر کردن حافظه CPU) را وارد سیستم نرمافزاری خودمان میکنیم تا ببینیم آیا سیستم میتواند گلیم خودش را از آب بیرون بکشد و به کارش ادامه دهد یا کلاً منفجر میشود! هدف ما خرابکاری نیست، بلکه پیشگیری پیشدستانه (Proactive) از فاجعه است.
به طور کلی، مهندسی آشوب به تیمهای نرمافزاری کمک میکند تا قبل از وقوع بحرانهای واقعی، نقاط ضعف سیستم را شناسایی کرده و قابلیت اطمینان و تابآوری نرمافزار را افزایش دهند.
Backend for Frontend یا به اختصار BFF یک الگوی معماری نرمافزار است که در آن برای هر نوع رابط کاربری یک بکاند اختصاصی در نظر گرفته میشود. ایده اصلی این است که نیازهای یک وبسایت، اپلیکیشن موبایل یا حتی یک دستگاه هوشمند با یکدیگر متفاوت هستند؛ بنابراین بهتر است هر کدام یک لایه بکاند مخصوص خود داشته باشند.
در معماریهای سنتی، همه فرانتاندها مستقیماً با یک بکاند مشترک ارتباط برقرار میکنند. این موضوع باعث میشود بکاند مجبور باشد نیازهای مختلف و گاهی متناقض چندین نوع کاربر را پوشش دهد. در الگوی BFF، بین فرنتاند و سرویسهای اصلی سیستم یک بکاند اختصاصی قرار میگیرد که فقط برای همان فرانتاند طراحی شده است.
BFF یعنی ما به جای اینکه یک بکاند غولآسا داشته باشیم که سعی کند همه را راضی نگه دارد، برای هر کلاینت یک لایه بکاند اختصاصی و کوچک میسازیم. این لایه مانند یک «مترجم» عمل میکند که دادههای خام را از میکروسرویسهای اصلی میگیرد، آنها را به شکلی که آن کلاینت خاص نیاز دارد فیلتر یا ترکیب میکند و تحویل میدهد.
با پیچیدهتر شدن سیستمهای امروزی و کم شدن زمان عرضه به بازار، مهندسان نیاز به ابزارهای کمکی دارند. در اینجا اصطلاح AI4SE (مخفف AI for Systems Engineering) متولد میشود. به زبان ساده، در AI4SE از ابزارها و تکنیکهای هوش مصنوعی (مثل یادگیری ماشین و پردازش دادهها) استفاده میشود تا فرآیند طراحی، ساخت، تست و نگهداری سیستمهای پیچیده نرمافزاری را بهبود، سرعت و بهینهسازی ببخشد.
در AI4SE از هوش مصنوعی برای انجام یا تسهیل کارهایی مانند تولید کد، یافتن خطاها، تولید تست، تحلیل نیازمندیها و پیشبینی مشکلات احتمالی استفاده میشود. به این ترتیب، بخشی از کارهایی که قبلاً بهصورت دستی انجام میشد، میتواند به کمک ابزارهای هوشمند سریعتر و دقیقتر انجام شود.
اگر در موضوع قبلی (AI4SE) از هوش مصنوعی به عنوان دستیار استفاده میکردیم، در SE4AI (مخفف Systems Engineering for AI) ورق کاملاً برمیگردد. در اینجا ما میخواهیم یک سیستم نرمافزاری بسازیم که خودش یک بخش هوش مصنوعی یا یادگیری ماشین در دلش دارد؛ مثلاً یک ماشین خودران، یک سیستم تشخیص پزشکی یا ابزار هوشمند بورس.
سیستمهای هوش مصنوعی معمولاً پیچیدهتر از نرمافزارهای سنتی هستند؛ زیرا علاوه بر کد، شامل دادهها، مدلهای یادگیری ماشین و فرآیندهای آموزش و بهروزرسانی نیز میشوند. به همین دلیل، برای اطمینان از کیفیت، امنیت، قابلیت اطمینان و عملکرد صحیح این سیستمها، باید از اصول مهندسی نرمافزار استفاده شود.
تفاوت SE4AI با AI4SE در این است که در AI4SE، هوش مصنوعی به مهندسی نرمافزار کمک میکند؛ اما در SE4AI، مهندسی نرمافزار به ساخت و مدیریت سیستمهای هوش مصنوعی کمک میکند.
در دنیای مهندسی نرمافزار، ما سالهاست که از DevOps استفاده میکنیم تا فرآیند نوشتن کد و قرار دادن آن روی سرور را خودکار و سریع کنیم. اما وقتی پای یادگیری ماشین (Machine Learning) به میان میآید، قضیه خیلی پیچیدهتر میشود؛ چون ما اینجا فقط با «کد» سروکار نداریم، بلکه با «کد + دادهها + مدل ریاضی» طرف هستیم.
MLOps (مخفف Machine Learning Operations) مجموعهای از روشها و ابزارهاست که فرهنگ DevOps را وارد دنیای یادگیری ماشین میکند. هدف MLOps این است که چرخه حیات یک مدل هوش مصنوعی (از آمادهسازی دادهها و آموزش مدل گرفته تا تست، ارزیابی، مستقر کردن روی سرور و پایش آن) را کاملاً خودکار و استاندارد کند تا مدلها سریعتر و با خطای کمتر به دست کاربران برسند.
در پروژههای یادگیری ماشین، تنها ساخت مدل کافی نیست. دادهها باید جمعآوری و آماده شوند، مدل آموزش ببیند، آزمایش شود، در محیط واقعی مستقر گردد و عملکرد آن بهطور مداوم پایش شود. انجام دستی این مراحل زمانبر و پرخطا است. MLOps با استفاده از خودکارسازی، کنترل نسخه، CI/CD و پایش مداوم، این فرآیندها را سادهتر و قابل اعتمادتر میکند. از مهمترین مزایای MLOps میتوان به کاهش زمان استقرار مدل، افزایش همکاری بین تیمهای داده و توسعه، بهبود کیفیت مدلها و کاهش هزینههای نگهداری اشاره کرد.
Infrastructure as Code یا IaC روشی برای مدیریت و پیکربندی زیرساختهای فناوری اطلاعات از طریق کد است. در این رویکرد، به جای اینکه سرورها، شبکهها، پایگاههای داده و سایر منابع بهصورت دستی تنظیم شوند، تمام تنظیمات و مشخصات زیرساخت در قالب فایلهای کد تعریف میشوند.
IaC به زبان سادهتر میگوید که به جای کارهای دستی، بیایید کل ساختار زیرساخت (مثل سرورها، شبکهها، لود بالانسرها و دیتابیسها) را در قالب فایلهای متنی و کد بنویسیم. ابزارهای IaC این کدها را میخوانند و خودکار در چند دقیقه دقیقاً همان محیطی که خواستهایم را در کلود (مثل AWS یا سرورهای محلی) برای ما میسازند. با این کار، مدیریت زیرساخت دقیقاً مثل مدیریت کدهای یک نرمافزار میشود.
مهمترین مزیت IaC ایجاد یکپارچگی و تکرارپذیری است. وقتی زیرساخت از طریق کد تعریف شود، محیطهای توسعه، تست و عملیاتی دقیقاً مشابه یکدیگر خواهند بود و مشکل «تفاوت محیطها» به حداقل میرسد. همچنین استفاده از کنترل نسخه (Version Control) باعث میشود تغییرات زیرساخت قابل پیگیری و بازگشت باشند.
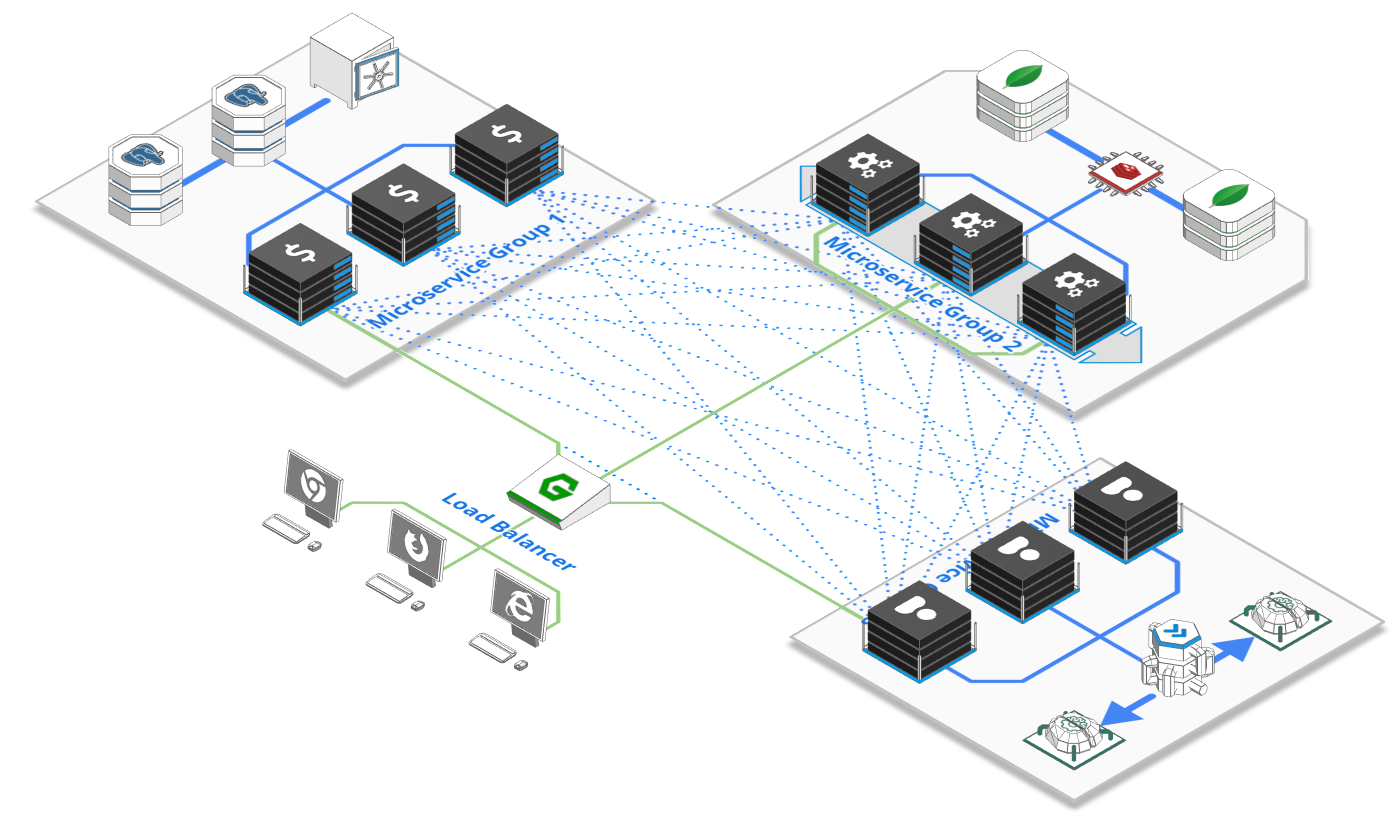
در معماری Microservices، دو فناوری مهم برای مدیریت ارتباطات وجود دارند: API Gateway و Service Mesh. این دو مفهوم گاهی شبیه به هم به نظر میرسند، اما وظایف متفاوتی دارند و معمولاً در کنار یکدیگر استفاده میشوند. وقتی یک معماری یکپارچه (Monolith) را میشکنیم و به کلی میکروسرویس کوچک تبدیل میشود، دو چالش بزرگ ارتباطی داریم:
۱. کلاینتهای بیرونی (مثل اپلیکیشن موبایل کاربر) چطور باید با این همه سرویس داخلی صحبت کنند؟
۲. این میکروسرویسهای داخلی چطور خودشان با یکدیگر امن و سریع ارتباط برقرار کنند؟
برای حل این دو چالش، دو تکنولوژی متفاوت اما مکمل داریم: API Gateway و Service Mesh.
API Gateway در ورودی سیستم قرار میگیرد و تمام درخواستهای کاربران یا سیستمهای خارجی را دریافت میکند. این لایه وظایفی مانند مسیریابی درخواستها، احراز هویت، محدودسازی تعداد درخواستها (Rate Limiting)، مدیریت نسخههای API و نظارت بر ترافیک را انجام میدهد. به بیان ساده، API Gateway دروازه ورود به سیستم است.
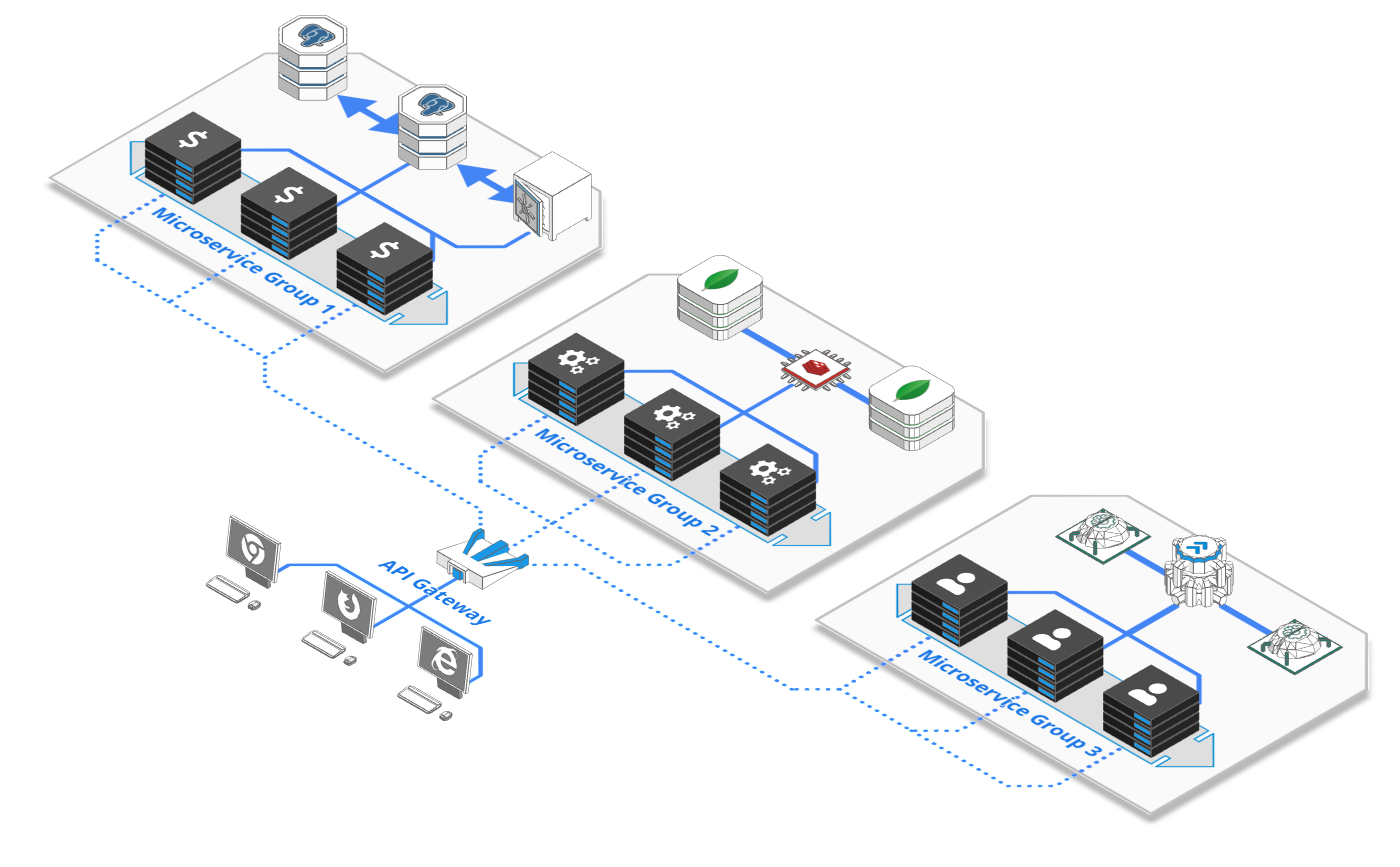
در مقابل، Service Mesh برای مدیریت ارتباط بین سرویسهای داخلی یک معماری میکروسرویسی استفاده میشود. این فناوری ارتباط سرویسها با یکدیگر را کنترل میکند و قابلیتهایی مانند کشف سرویسها، توازن بار (Load Balancing)، رمزنگاری ارتباطات، مانیتورینگ و مدیریت خطاها را فراهم میکند.
CQRS (مخفف Command Query Responsibility Segregation) یا تفکیک مسئولیت فرمان و پرسوجو یک الگوی معماری نرمافزار است که عملیات خواندن اطلاعات (Query) را از عملیات نوشتن و تغییر اطلاعات (Command) جدا میکند. در این الگو، به جای استفاده از یک مدل مشترک برای خواندن و نوشتن دادهها، برای هر کدام مدل یا حتی پایگاه داده جداگانه در نظر گرفته میشود.
در معماریهای سنتی (CRUD)، یک مدل واحد هم برای خواندن و هم برای تغییر دادهها استفاده میشود. اما در سیستمهای پیچیده، نیازهای بخش خواندن و نوشتن معمولاً متفاوت هستند. برای مثال، در یک فروشگاه اینترنتی، ممکن است ثبت سفارش (نوشتن) نیاز به پردازش تراکنش سنگین داشته باشد، اما کاربران همزمان هزاران بار لیست محصولات (خواندن) را لود کنند. استفاده از یک مدل برای هر دو کار، کارایی سیستم را پایین میآورد.
مزیت اصلی CQRS افزایش کارایی، مقیاسپذیری و انعطافپذیری سیستم است. با این حال، پیادهسازی آن پیچیدگی بیشتری نسبت به معماریهای معمولی دارد و معمولاً برای سیستمهای بزرگ و پیچیده توصیه میشود.
EDA (مخفف Event-Driven Architecture) یا معماری رویدادمحور یک الگوی معماری نرمافزار است که در آن اجزای سیستم از طریق رویدادها (Events) با یکدیگر ارتباط برقرار میکنند. رویداد به هر اتفاق مهمی در سیستم گفته میشود؛ مانند ثبت سفارش، پرداخت موفق، ورود کاربر یا تغییر وضعیت یک محصول.
در معماریهای سنتی، سیستمها به صورت همگام (Synchronous) با هم صحبت میکنند؛ یعنی سیستم A به سیستم B زنگ میزند و منتظر میماند تا جواب را بگیرد. اگر سیستم B قطع باشد، کار سیستم A هم لنگ میماند.
اما معماری رویداد-محور (EDA) میگوید: سیستمها باید به صورت ناهمگام (Asynchronous) و بر پایه رویدادها با هم ارتباط داشته باشند. رویداد یعنی «یک اتفاق مهم که در سیستم رخ داده و تمام شده است»؛ مثلاً: «کاربر دکمه خرید را زد»، «دمای سنسور به ۱۸۰ درجه رسید» یا «پرداخت موفقیتآمیز بود».
در این معماری، فرستنده (Producer) رویداد کاری ندارد که چه کسی قرار است این پیام را بگیرد؛ او فقط رویداد را داخل یک تالار گفتگو ارسال میکند. گیرندگان رویداد (Consumers) که گوشبهزنگ نشستهاند، هر زمان که آمادگی داشتند این پیام را برمیدارند و کار خودشان را انجام میدهند. فرستنده و گیرنده اصلاً همدیگر را نمیشناسند.
Serverless Architecture یک سبک معماری است که در آن توسعهدهندگان بدون مدیریت مستقیم سرورها، برنامههای خود را توسعه و اجرا میکنند. در این مدل، تأمین، نگهداری، مقیاسپذیری و مدیریت زیرساخت بر عهده ارائهدهنده خدمات ابری است و توسعهدهندگان تنها روی منطق و کدنویسی برنامه تمرکز میکنند.
بزرگترین اشتباه در کلمه Serverless این است که فکر کنیم «هیچ سروری در کار نیست!». در واقع، سرورها وجود دارند، اما دلیل این نامگذاری این است که شما به عنوان یک توسعهدهنده یا معمار نرمافزار، هیچ نیازی به دیدن، مدیریت، آپدیت یا خرید سرورها ندارید. در معماری سنتی، شما باید یک سرور مجازی اجاره میکردید، سیستمعاملش را آپدیت میکردید و نگران میشدید که اگر ترافیک بالا رفت سرور کرش نکند. اما در معماری بدون سرور، کل این دردسرها به عهده شرکت ارائهدهنده خدمات ابری (مثل آمازون، گوگل یا مایکروسافت) است. شما فقط کد خود را مینویسید و آپلود میکنید؛ سیستم ابری خودش به ازای هر درخواستی که سمت برنامه میآید، موقتاً یک سرور روشن میکند، کد شما را اجرا میکند، جواب کاربر را میدهد و بعد سرور را خاموش میکند!
مزایای اصلی Serverless شامل کاهش پیچیدگی مدیریت زیرساخت، افزایش سرعت توسعه، مقیاسپذیری خودکار و کاهش هزینههای عملیاتی است. با این حال، چالشهایی مانند وابستگی به ارائهدهنده سرویس، محدودیت منابع و تأخیر اولیه اجرای سرویسها (Cold Start) نیز وجود دارد.
API-First یک رویکرد توسعه نرمافزار است که در آن طراحی و تعریف APIها پیش از پیادهسازی سایر بخشهای سیستم انجام میشود. در این رویکرد، APIها بهعنوان اجزای اصلی و پایهای سیستم در نظر گرفته میشوند و سایر بخشها مانند وبسایت، اپلیکیشن موبایل یا سرویسهای دیگر بر اساس آنها توسعه مییابند.
در روشهای سنتی، وقتی میخواستیم یک نرمافزار بسازیم، اول دیتابیس و کدهای بکاند را مینوشتیم، ظاهر برنامه را طراحی میکردیم و در آخر به سراغ APIها میرفتیم.
اما رویکرد API-First دقیقاً برعکس است . این رویکرد میگوید: قبل از اینکه حتی یک خط کد برای برنامه بنویسید، اول باید روی طراحی، مستندسازی و ساختار مشخص API توافق کنید. در این مدل، API به عنوان یک «شهروند درجه یک» و پایه و اساس کل پروژه در نظر گرفته میشود. ما ابتدا یک «قرارداد» (Contract) با ابزارهایی مثل OpenAPI/Swagger میسازیم که میگوید سیستم قرار است چه ورودی و خروجیهایی داشته باشد، سپس همه تیمها کارشان را بر اساس این قرارداد شروع میکنند.
مزایای اصلی این رویکرد شامل توسعه سریعتر، قابلیت استفاده مجدد از سرویسها، یکپارچگی بهتر بین سیستمها، بهبود تجربه توسعهدهندگان و پشتیبانی مناسب از معماریهای مدرن مانند میکروسرویسها است. به همین دلیل API-First به یکی از رویکردهای رایج در توسعه سامانههای مدرن تبدیل شده است.
Domain-Driven Design یا DDD یک رویکرد طراحی نرمافزار است که تمرکز اصلی آن بر درک عمیق حوزه کسبوکار (Domain) و مدلسازی نرمافزار بر اساس مفاهیم و قوانین آن حوزه است. در این رویکرد، توسعهدهندگان و متخصصان کسبوکار با استفاده از یک زبان مشترک (Ubiquitous Language) همکاری میکنند تا نرمافزار بیشترین تطابق را با نیازهای واقعی سازمان داشته باشد.
بسیاری از پروژههای نرمافزاری به این دلیل شکست میخورند که برنامهنویسان بهترین تکنولوژیها را استفاده کردهاند، اما دقیقاً نفهمیدهاند که بیزینس یا همان دامنه کارفرما چطور کار میکند! به عنوان مثال شما نمیتوانید یک سیستم بانکی عالی بسازید، مگر اینکه اول محاسبات پیچیده بانکی و قوانین آن را عمیقاً درک کنید.
DDD میگوید که قلب فرآیند توسعه باید مدلسازی دقیق فرآیندها، قوانین و نیازمندیهای بیزینس باشد، نه مسائل فنی و دیتابیس. در این روش، برنامهنویسان و متخصصان بیزینس کنار هم مینشینند و یک زبان مشترک خلق میکنند. یعنی کلماتی که در کد استفاده میشود (مثل نام متغیرها و کلاسها) باید دقیقاً همان کلماتی باشد که کارفرما در دنیای واقعی استفاده میکند.
معماری ششضلعی یا Hexagonal Architecture یک روش طراحی نرمافزار است که هدفش جدا کردن منطق اصلی برنامه (Business Logic) از جزئیات فنی مثل دیتابیس، رابط کاربری و سرویسهای بیرونی است. در این مدل، هستهی برنامه در مرکز قرار دارد و همه چیز از طریق «پورتها» و «آداپتورها» به آن وصل میشود.
در معماریهای سنتی (۳ لایه)، لایه بیزینس مستقیماً به لایه دیتابیس وصل است. این یعنی اگر بخواهید دیتابیس را عوض کنید یا پکیج جدیدی نص کنید، احتمالاً کدهای اصلی بیزینس شما دستخوش تغییر و باگ میشوند.
اما معماری ششضلعی میگوید: هسته اصلی برنامه باید مثل یک جزیره کاملاً مستقل در مرکز قرار بگیرد و هیچ ابزار خارجی (مثل دیتابیس، پنل وب، تلگرام بوت، یا APIهای دیگر) نباید به درون آن نفوذ کنند. هسته برنامه فقط تعدادی پورت (که در کد همان Interfaceها یا قراردادها هستند) معرفی میکند. ابزارهای بیرونی، آداپتور مخصوص خود را مینویسند تا به این پورتها وصل شوند؛ درست مثل لپتاپ شما که یک پورت USB (مستقل از تکنولوژی) دارد و شما میتوانید هم موس، هم کیبورد و هم هارد اکسترنال را با آداپتورهایشان به آن وصل کنید، بدون اینکه ساختار داخلی لپتاپ تغییر کند.
Event Sourcing یک سبک معماری است که به جای اینکه فقط «وضعیت فعلی» سیستم را ذخیره کنیم، تمام تغییراتی که روی سیستم اتفاق میافتد را به شکل «رویداد» ذخیره میکند. یعنی به جای اینکه فقط بدانیم الان وضعیت چیست، دقیقاً میدانیم چه اتفاقهایی افتاده که ما را به این وضعیت رسانده است.
در دیتابیسهای سنتی (CRUD)، ما همیشه آخرین وضعیت یک داده را ذخیره میکنیم. مثلاً اگر موجودی حساب شما ۱۰۰ هزار تومان باشد و ۵۰ هزار تومان واریز کنید، عدد ۱۰۰ به ۱۵۰ تبدیل میشود. اگر کسی بپرسد «این ۱۵۰ هزار تومان چطور به دست آمده؟»، دیتابیس سنتی چیزی برای گفتن ندارد، مگر اینکه یک سیستم لاگگیری جداگانه ساخته باشید.
الگوی Event Sourcing میگوید: ما اصلاً وضعیت فعلی را ذخیره نمیکنیم؛ بلکه تمام اتفاقات و رویدادهایی که منجر به این وضعیت شدهاند را به صورت یک زنجیره متوالی ذخیره میکنیم. در این معماری، دیتابیس ما یک بانک اطلاعاتی فقطافزودنی (Append-only) به نام Event Store است. برای به دست آوردن موجودی فعلی حساب، سیستم از نقطه صفر شروع میکند و تمام رویدادهای واریز و برداشت را از ابتدا تا انتها روی حساب بازیانی (Replay) میکند تا به عدد نهایی برسد. سیستم کنترل نسخه (مثل Git) یا دفتر کل حسابداری بهترین مثالهای ملموس برای این الگو هستند؛ گیت کدهای نهایی را ذخیره نمیکند، بلکه تغییرات را نگه میدارد.
مزیت مهم این روش این است که علاوه بر وضعیت فعلی، تاریخچه کامل هم داریم. بنابراین میتوانیم بفهمیم چه زمانی چه اتفاقی افتاده، یا حتی وضعیت سیستم را در یک زمان خاص بازسازی کنیم. البته در عوض، طراحی و پیادهسازی آن پیچیدهتر و سنگینتر از روشهای سنتی است.
پلتفرمهای Low-code و No-code ابزارهایی هستند که ساخت نرمافزار را خیلی سادهتر و سریعتر میکنند، طوری که لازم نیست مثل روشهای سنتی همهچیز را خطبهخط کدنویسی کنیم.
این پلتفرمها به کمک واسطهای کاربری گرافیکی، ابزارهای کشیدن و رها کردن (Drag-and-Drop) و مدلسازی بصری به کاربران اجازه میدهند بدون درگیر شدن با پیچیدگیهای کدنویسی، برنامه بسازند:
No-Code: مخصوص افرادی است که اصلاً دانش برنامهنویسی ندارند. آنها به کمک ابزارهای کاملاً بصری، کارهای خود را جلو میبرند.
Low-Code: به کمی دانش پایه برنامهنویسی نیاز دارد و به توسعهدهندگان حرفهای کمک میکند تا کارهای تکراری (مثل ساخت فرمها یا اتصال به دیتابیس) را با سرعت بالا (تا ۹۰٪ سریعتر) انجام دهند و فقط بخشهای بسیار خاص را کدنویسی کنند.
البته این ابزارها بیشتر برای اپلیکیشنهای ساده تا متوسط مناسباند (مثل داشبوردها، فرمها یا اتوماسیونهای ساده). برای سیستمهای خیلی پیچیده هنوز به توسعه سنتی (Pro-code) نیاز داریم. به همین دلیل معمولاً این دو روش در کنار هم استفاده میشوند: Low-code برای سرعت، و Pro-code برای انعطاف و قدرت بیشتر.
BPMS (مخفف Business Process Management Systems) یک نوع پلتفرم نرمافزاری است که کمک میکند فرآیندهای کاری یک سازمان را طراحی، اجرا، پایش و بهینهسازی کنیم. یعنی به جای اینکه کارها بهصورت پراکنده و دستی انجام شوند، همه چیز به شکل یک جریان مشخص و قابل کنترل مدیریت میشود.
در واقع BPM خودش «روش فکر کردن به فرآیندها» است، اما BPMS ابزار اجرایی آن است. این سیستمها به سازمان کمک میکنند بفهمند کارها دقیقاً چطور انجام میشوند، کجاها گلوگاه وجود دارد و چطور میتوان آنها را بهتر کرد.
BPMS معمولاً شامل طراحی فرآیند (Process Design)، اجرای گردشکار (Workflow Automation)، مانیتورینگ و تحلیل عملکرد است. بعضی نسخههای پیشرفته حتی اجازه میدهند فرآیندها قبل از اجرا شبیهسازی شوند تا مشکلات احتمالی دیده شود. مثلاً در یک شرکت، درخواست مرخصی، تأیید مدیر، ثبت در سیستم منابع انسانی و آرشیو شدن همه میتواند به صورت یک فرآیند در BPMS تعریف شود و سیستم خودش این مسیر را مدیریت کند.
مزیت مهم BPMS این است که باعث شفافیت، کاهش کارهای تکراری، افزایش سرعت و کنترل بهتر روی فرآیندهای سازمانی میشود. در عین حال، چون همه چیز را ساختارمند میکند، سازمان راحتتر میتواند رشد کند و فرآیندها را توسعه دهد یا تغییر دهد.
Message Queue، یکی از ابزارهای مهم در معماری نرمافزارهای مدرن است که برای ارتباط غیرهمزمان بین بخشهای مختلف سیستم استفاده میشود. ایده اصلی این است که به جای اینکه یک سرویس مستقیم منتظر پاسخ سرویس دیگر بماند، پیامها را در یک صف قرار میدهد تا بعداً توسط سرویسهای دیگر پردازش شوند.
در این مدل، سه بخش اصلی داریم: فرستنده پیام (Producer) که کار یا درخواست را تولید میکند، صف پیام (Broker) که پیامها را نگهداری و مدیریت میکند، و دریافتکننده (Consumer) که پیامها را برداشته و پردازش میکند. ابزارهایی مثل Apache Kafka و RabbitMQ از معروفترین نمونهها هستند.
به طور خلاصه، Message Queue مثل یک «ایستگاه پست دیجیتال» است که پیامها را نگه میدارد تا هر سرویس در زمان مناسب آنها را بردارد و پردازش کند، بدون اینکه همه چیز به هم وابسته باشد.
کانتینرها یکی از مهمترین فناوریهای دنیای نرمافزار مدرن هستند که کمک میکنند برنامهها همراه با تمام وابستگیهایشان (مثل کتابخانهها و تنظیمات سیستم) در یک بستهی مستقل اجرا شوند. این کار باعث میشود برنامه در هر سیستمی دقیقاً به یک شکل اجرا شود، بدون اینکه مشکل «روی سیستم من کار میکند ولی روی سیستم تو نه» پیش بیاید. Docker یکی از معروفترین ابزارها برای ساخت و اجرای کانتینرها است. Docker به توسعهدهنده اجازه میدهد یک برنامه را داخل یک «ایمیج» بستهبندی کند و آن را روی هر سیستم اجرا کند.
اما وقتی تعداد کانتینرها زیاد میشود (مثلاً صدها یا هزاران سرویس)، مدیریت آنها سخت میشود. اینجاست که ابزارهایی مثل Kubernetes وارد میشوند. Kubernetes وظیفه دارد کانتینرها را در مقیاس بزرگ مدیریت کند، آنها را بین سرورها پخش کند، در صورت خرابی دوباره اجرا کند و به صورت خودکار مقیاس (scale) سیستم را تنظیم کند.
به زبان ساده:
Docker = ساخت و اجرای کانتینرها
Kubernetes = مدیریت و کنترل تعداد زیاد کانتینرها در یک سیستم بزرگ
برای مثال، Docker مثل این است که یک «جعبه غذای آماده» درست کنیم، اما Kubernetes مثل سیستم مدیریت رستورانی است که هزاران سفارش را بین آشپزها تقسیم میکند، اگر یکی از آشپزها خراب شد جایگزین میآورد و در ساعات شلوغی تعداد آشپزها را زیاد میکند.
در عمل، این دو معمولاً با هم استفاده میشوند: Docker برای ساخت و اجرای برنامه، و Kubernetes برای مدیریت آن در سطح بزرگ و حرفهای.
معماری Multi-Tenancy یا چندمستاجری به حالتی از طراحی نرمافزار گفته میشود که در آن یک نسخه (instance) از یک اپلیکیشن، بهطور همزمان به چندین مشتری یا گروه کاربری (tenant) سرویس میدهد. هر tenant میتواند یک فرد، یک شرکت یا یک سازمان باشد، اما نکته مهم این است که دادهها و تنظیمات هر کدام از هم جدا و ایزوله نگه داشته میشوند. فرض کنید یک مجتمع مسکونی بزرگ دارید. در این مجتمع، تمام ساکنین (مستاجرین) از یک زیرساخت مشترک (مثل اسکلت ساختمان، لولهکشی اصلی آب، آسانسور و ورودی مجتمع) استفاده میکنند، اما هر کدام واحد، کلید و حریم خصوصی کاملاً مستقل خود را دارند.
در این معماری، همه کاربران از یک زیرساخت و یک اپلیکیشن مشترک استفاده میکنند، اما سیستم طوری طراحی شده که دادههای هر tenant برای دیگران قابل مشاهده نیست. این موضوع هم باعث صرفهجویی در هزینهها میشود و هم مدیریت سیستم را سادهتر میکند.
اگر بخواهیم ساده بگوییم:
در حالت Single-Tenant هر مشتری یک نسخه جدا از نرمافزار دارد
در حالت Multi-Tenant همه مشتریها روی یک نسخه مشترک هستند، اما از هم جدا نگه داشته میشوند
مزیت مهم این مدل، کاهش هزینه، بهروزرسانی سادهتر و مقیاسپذیری بهتر است. چون وقتی یک آپدیت داده میشود، برای همه مشتریها همزمان اعمال میشود.
Data Migration یا مهاجرت داده به فرآیند انتقال دادهها از یک سیستم به سیستم دیگر گفته میشود. این انتقال میتواند بین دیتابیسها، نرمافزارها، سرورها، محیطهای ابری یا حتی فرمتهای مختلف فایل انجام شود. هدف اصلی این کار این است که دادهها به یک محیط جدید منتقل شوند بدون اینکه دقت، کامل بودن یا سازگاری آنها از بین برود. وقتی یک سازمان تصمیم میگیرد سیستمهای قدیمی خود را بهروز کند، دیتابیس سنتی خود (مثلا SQL Server) را به ابر منتقل کند (مثلا روی Cloud)، یا دو شرکت با هم ادغام میشوند، نیاز به جابجایی دادهها دارند.
در یک پروژه مهاجرت داده معمولاً سه مرحله اصلی داریم:
اول انتخاب و آمادهسازی دادهها (بررسی اینکه چه دادهای داریم و چه کیفیتی دارد)، دوم انتقال دادهها (جابجایی از سیستم قدیمی به جدید)، و سوم اعتبارسنجی (اطمینان از اینکه دادهها درست و کامل منتقل شدهاند).
چالش اصلی در Data Migration این است که دادهها معمولاً بسیار بزرگ، حساس و وابسته به سیستمهای مختلف هستند. اگر کوچکترین خطا در انتقال رخ دهد، ممکن است اطلاعات از بین برود یا سیستم جدید درست کار نکند.