
در دنیای پرسرعت و پر هرج و مرج بورس، که هر ثانیه معادل میلیونها تومان است، داشتن دیدی لحظهای و دقیق از بازار، دیگر یک لوکس نیست، بلکه یک ضرورت انکارناپذیر است! امروز میخوام شما رو به یک سفر هیجانانگیز در دنیای دادههای لحظهای بورس ببرم. از جایی که ثانیهها حکم طلا رو دارن و دادهها مثل یک رودخانه خروشان بیوقفه در جریانن. چالش ما؟ نه تنها زنده موندن در این سیل، بلکه ساختن یک قایق موتوری سریع و هوشمند برای رسوندن اطلاعات درست و بهموقع به دست معاملهگرها.
در بازار بورس، هر لحظه هزاران اتفاق میافته: قیمت یک سهم عوض میشه، بهترین سفارشهای خرید و فروش تغییر میکنن و ... . حالا تصور کنید ما نه تنها با دادههای یک سهم، بلکه با دادههای تمام اوراق مشتقه (Options) مرتبط با اون هم سروکار داریم.
هدف نهایی این بود که کاربر در پلتفرم معاملاتی خودش بتونه پارامترهای پیچیدهای مثل ارزش استراتژیهای آپشن (Covered Call) و پارامترهای یونانی اختیار معامله (Option Greeks) مثل دلتا، گاما و تتا رو به صورت لحظهای ببینه. این یعنی ما باید:
دادههای خام قیمت و سفارشات رو از یک منبع خارجی بگیریم.
فرمولهای مربوطه رو روی این دادهها در لحظه محاسبه کنیم.
نتایج رو فقط برای کاربرانی بفرستیم که به اون سهم یا بازه خاصی از دادهها علاقه دارن.
فرستادن کل دادهها برای همه مثل اینه که برای پیدا کردن یک نفر در استادیوم آزادی، کل استادیوم رو بلندگو بذاریم و اسمش رو فریاد بزنیم! 📣 ما به یک راهکار هوشمندانهتر نیاز داشتیم.
برای حل این چالش، ما یک خط لوله (Pipeline) پردازش داده طراحی کردیم که قلب تپندهاش چند تا از بهترین ابزارهای دنیای بیگ دیتا بود.
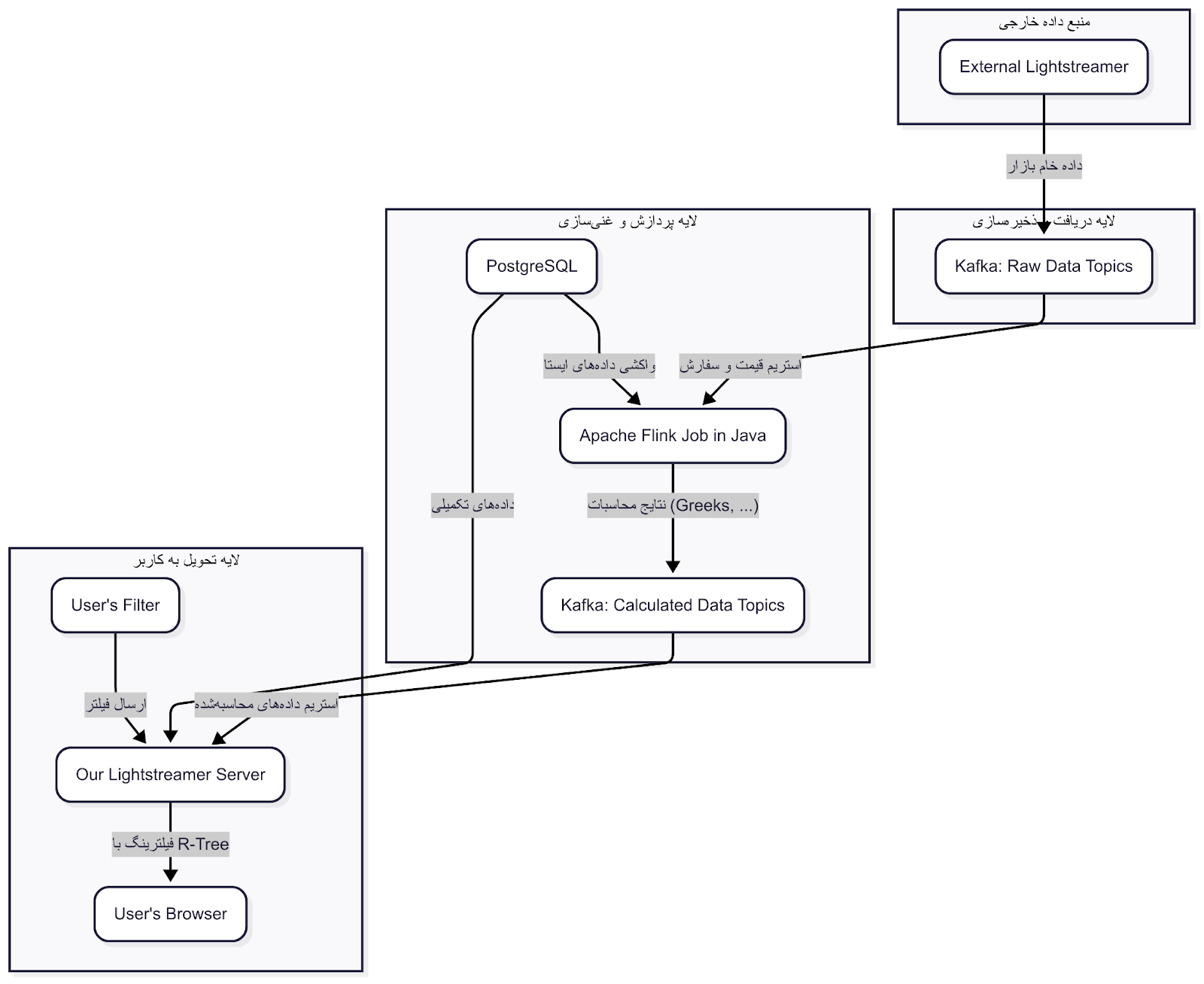
همه چیز از یک سرویسدهنده خارجی شروع میشد که دادههای خام بازار رو از طریق Lightstreamer به ما میرسوند. اولین قدم ما این بود که این جریان داده رو بگیریم و به یک جای امن و قابل اطمینان هدایت کنیم. اینجا بود که Apache Kafka وارد صحنه شد.
ما تمام پیامهای خام رو مستقیماً در تاپیکهای مختلف کافکا ذخیره میکردیم. کافکا مثل یک دفتر ثبت وقایع خیلی دقیق و وسواسی عمل میکرد که هیچ دادهای از قلم نمیافتاد و به ما اجازه میداد که سیستمهای مختلفی از این دادهها به صورت همزمان و بدون تداخل استفاده کنن. این کار باعث شد اجزای سیستم ما از هم جدا (Decoupled) بشن و هر کدوم کار خودشون رو بکنن.
حالا که دادههای خام رو در کافکا داشتیم، وقتش بود که روشون جادو کنیم! اینجا بود که Apache Flink، این قهرمان پردازش استریم، با قدرت وارد شد. ما تمام منطق محاسباتی خودمون رو با زبان جاوا در قالب Flink Jobها پیادهسازی کردیم.
جریان کار در فلینک به این صورت بود:
مصرف دادههای سریع و کند: جاب فلینک ما به دو منبع وصل بود. از یک طرف، دادههای پرتکرار و سریع (مثل قیمت لحظهای) رو از تاپیکهای کافکا میخوند. از طرف دیگه، برای غنیسازی دادهها (Data Enrichment)، اطلاعاتی که کمتر تغییر میکردن (مثل مشخصات یک سهم یا اوراق مشتقه) رو مستقیماً از دیتابیس PostgreSQL واکشی میکرد. این کار جلوی ارسال اطلاعات تکراری و سنگین در استریم رو میگرفت.
انجام محاسبات: اینجاست که اصل ماجرا اتفاق میافتاد. فلینک با ترکیب دادههای سریع و کند، فرمولهای سنگین مالی مثل یونانیها (Greeks) رو در لحظه محاسبه میکرد. فلینک برای این کار ساخته شده و به لطف مدیریت حالت (Stateful Processing) قدرتمندش، میتونست محاسبات رو بر اساس رویدادها انجام بده.
تولید خروجی: بعد از اینکه محاسبات انجام میشد، فلینک نتایج تمیز و آماده رو دوباره به یک تاپیک جدید در کافکا میریخت. حالا ما یک استریم از دادههای محاسبهشده و آماده مصرف داشتیم.
در سمت دیگه، کاربر در فرانتاند یک فیلتر برای خودش انتخاب میکرد. مثلاً: "اختیار معاملههایی رو به من نشون بده که دلتای اونها بین ۰.۴ تا ۰.۶ و قیمت سهم پایه بالای ۲۰۰۰ تومنه". این فیلتر به سرور Lightstreamer ما ارسال میشد. اینجا ما از یک تکنیک خیلی جذاب برای فیلترینگ استفاده کردیم: R-Tree.
اگر با R-Tree آشنا نیستید، به زبان ساده یک ساختار داده درختیه که برای جستجوی دادههای چندبعدی (مثل جستجو در یک نقشه) فوقالعاده کارآمده. ما فیلترهای هر کاربر رو در یک R-Tree ذخیره میکردیم. وقتی یک رویداد محاسبهشده جدید از فلینک (که در کافکا بود) به دست ما میرسید، به جای اینکه اون رو برای تکتک کاربران چک کنیم، از R-Tree میپرسیدیم: "هی R-Tree، این داده به درد کدوم یکی از این فیلترها میخوره؟"
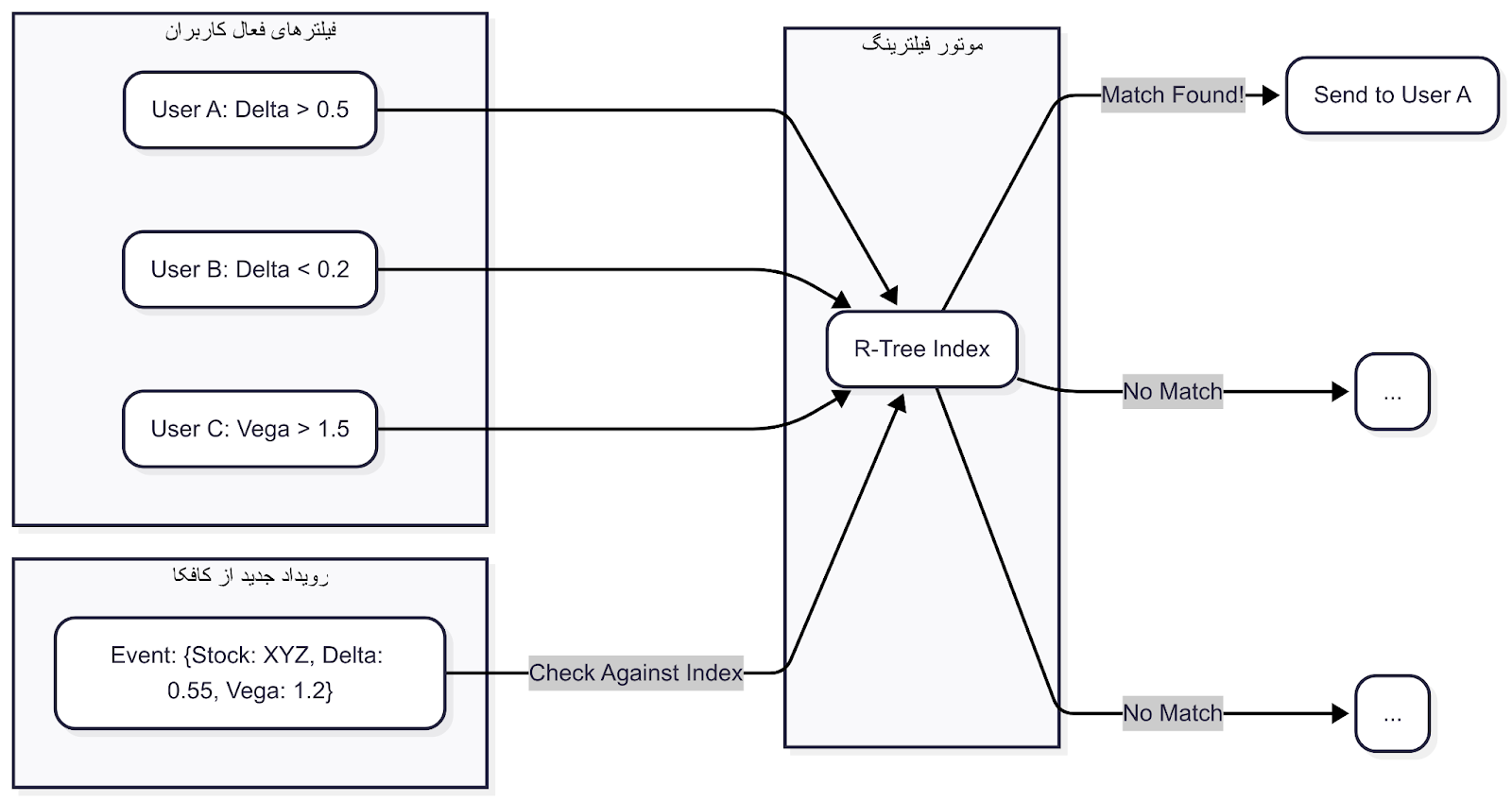
R-Tree در کسری از ثانیه کاربر یا کاربران علاقهمند رو پیدا میکرد و ما داده رو فقط برای اونها ارسال میکردیم. این کار بار پردازشی سرور رو به شدت کاهش داد و باعث شد پهنای باند بیهوده مصرف نشه. استفاده از R-Tree مثل این بود که به جای گشتن کل کتابخانه برای پیدا کردن یک کتاب، مستقیم به قفسه و ردیف مربوطه برید. یک برد بزرگ برای ما! 🚀
این معماری به ما اجازه داد یک سیستم بسیار سریع، مقیاسپذیر و قابل اتکا بسازیم. بیایید نگاهی به نکات کلیدی بندازیم:
جادوی جداسازی با Kafka: کافکا به ما این امکان رو داد که تهیهکننده داده، پردازشگر و مصرفکننده نهایی کاملاً از هم مستقل باشن.
قدرت پردازش استریم با Flink: فلینک ثابت کرد که برای محاسبات پیچیده و Stateful روی دادههای زیاد، بهترین انتخابه.
فیلترینگ هوشمند، کلید عملکرد: استفاده از R-Tree در سمت سرور (Edge) یک تصمیم حیاتی برای جلوگیری از ارسال دادههای اضافی به کلاینت و کاهش هزینهها بود.
رویکرد ترکیبی (Hybrid): ترکیب یک ابزار استریمینگ مثل کافکا با یک دیتابیس سنتی مثل PostgreSQL برای غنیسازی دادهها، یک استراتژی کارآمد و بهینه است.
ساختن چنین سیستمی در دنیای پر استرس بازارهای مالی، یک تجربه فوقالعاده بود که به ما یاد داد چطور با ابزارهای درست میشه پیچیدهترین چالشهای دادهای رو هم حل کرد. امیدوارم این سفر کوتاه برای شما هم مفید بوده باشه. اگر سوالی دارید یا تجربه مشابهی داشتید، حتماً در کامنتها به اشتراک بذارید. خوشحال میشم با هم گپ بزنیم! 😉