
عنوان
موازیسازی تعبیهکردن فرامسیرها در الگوریتم MAHE_IM
دانشجو: امیررضا وفائي
استاد: دکتر صادق علیاکبری
شهریور ماه سال ۱۴۰۴
چکیده
تشخیص گرههای پرنفوذ در شبکههای اجتماعی به منظور انتخاب یک مجموعه بهینه و حداقلی از کاربران اولیه برای حداکثر کردن گسترش نفوذ، به عنوان یک مسئله کلیدی در تحلیل نفوذ مطرح است. در شبکههای ناهمگن، که شامل انواع مختلف گرهها (مانند کاربران، مقالات، کنفرانسها) و روابط چندگانه هستند، این مشکل به دلیل پیچیدگی ساختاری پیچیدهتر میشود. در حالی که اکثر مطالعات بر شبکههای همگن متمرکز بودهاند، شبکههای اجتماعی واقعی از مجموعهای ناهمگن از کاربران و ارتباطات تشکیل شدهاند که نیاز به روشهای پیشرفتهتری برای تحلیل و بهینهسازی نفوذ دارند. مقاله انتخابی با ارائه چارچوبی مبتنی بر یادگیری عمیق برای تعبیه روابط ناهمگن، گامی مؤثر در این زمینه برداشته است. نسخه موازی الگوریتم با استفاده از پردازش موازی تعبیه فرامسیرها و مانیتورینگ منابع، زمان اجرا را به طور قابلتوجهی کاهش داده و عملکرد را بهبود میبخشد. ارزیابی با استفاده از مدلهای انتشار اطلاعات (مانند مدل آبشار مستقل و خط) و دادههای واقعی شبکه DBLP در حوزه یادگیری ماشین انجام شده است.
کلیدواژهها: بیشینهسازی نفوذ، تشخیص گرههای پرنفوذ، تحلیل نفوذ، شبکههای ناهمگن، انتشار نفوذ، پردازش موازی، ارزیابی منابع
مقدمه
بیشینهسازی نفوذ (Influence Maximization, IM) یکی از موضوعات کلیدی در تحلیل شبکههای اجتماعی و اطلاعات ناهمگن است که هدف آن شناسایی مجموعهای بهینه از گرههای اولیه (بذرها) برای حداکثر کردن گسترش اطلاعات، ایدهها یا رفتارها در یک شبکه است. با افزایش پیچیدگی شبکهها، بهویژه در محیطهای ناهمگن که شامل انواع مختلف گرهها (مانند کاربران، مقالات، کنفرانسها) و روابط چندگانه هستند، این مشکل از نظر محاسباتی چالشبرانگیزتر میشود. در دنیای واقعی، شبکههای اجتماعی مانند DBLP، که شامل روابط پیچیده بین نویسندگان، مقالات و کنفرانسها است، نیاز به روشهای پیشرفتهای برای تحلیل و بهینهسازی نفوذ دارند.
الگوریتم MAHE-IM (Multiple Aggregation of Heterogeneous Relation Embedding for Influence Maximization) به عنوان یک چارچوب مبتنی بر یادگیری عمیق برای بهینهسازی نفوذ در شبکههای ناهمگن توسعه یافته است. این الگوریتم با استفاده از تعبیه روابط ناهمگن (Heterogeneous Relation Embedding) و ترکیب آن با تکنیکهای تشخیص جامعه، تلاش میکند تا دقت و کارایی را در شناسایی گرههای تأثیرگذار افزایش دهد. با این حال، اجرای متوالی تعبیه فرامسیرها (Meta-paths) در نسخه اصلی این الگوریتم، به دلیل وابستگی به پردازش یک به یک، زمانبر است و از ظرفیت کامل منابع محاسباتی مانند CPU و GPU استفاده نمیکند.
در این پروژه، هدف اصلی بهبود عملکرد و سرعت الگوریتم MAHE-IM از طریق پیادهسازی یک نسخه موازی است. با بهرهگیری از پردازش موازی، میتوان تعبیه فرامسیرهای مستقل را به صورت همزمان انجام داد و از منابع سیستمی به طور مؤثرتر استفاده کرد. این کار با در نظر گرفتن محدودیتهای سختافزاری و بهینهسازی مصرف منابع مانند CPU، حافظه و GPU انجام میشود. همچنین، با افزودن مانیتورینگ عملکرد، امکان تحلیل دقیقتر رفتار الگوریتم در هر فاز و مقایسه نسخه اصلی با نسخه موازی فراهم میشود.
این گزارش به بررسی کامل پیادهسازی نسخه اصلی مانیتور شده و نسخه موازی بهینهشده میپردازد. ابتدا مروری بر پژوهشهای پیشین در زمینه بیشینهسازی نفوذ و بهویژه رویکردهای موازی ارائه میشود. سپس، روش پیشنهادی برای بهبود عملکرد با مانیتورینگ و پردازش موازی تشریح میشود. در ادامه، جزئیات مجموعه داده، نتایج تجربی، و مقایسه بین دو نسخه ارائه خواهد شد. در نهایت، نتیجهگیری و پیشنهادات برای کارهای آینده بیان میگردد. این پروژه با الهام از نیازهای عملی در تحلیل شبکههای ناهمگن و با تکیه بر منابع محاسباتی مدرن، گامی در جهت کارآمدتر کردن الگوریتمهای پیچیده برمیدارد.
مروری بر پژوهشهای پیشین
تحلیل نفوذ در شبکهها از دهههای گذشته با رشد شبکههای اجتماعی و نیاز به درک پویایی انتشار اطلاعات مورد توجه پژوهشگران قرار گرفته است. در ابتدا، مطالعات بر روی شبکههای همگن متمرکز بود که در آن گرهها و لبهها از یک نوع واحد بودند. با این حال، با ظهور شبکههای ناهمگن، که شامل انواع مختلف گرهها و روابط پیچیده هستند، نیاز به روشهای پیشرفتهتر احساس شد. در این بخش، مروری بر پیشرفتهای کلیدی در این حوزه ارائه میشود، با تأکید بر رویکردهای مبتنی بر پردازش موازی که پایه و اساس بهبود الگوریتم MAHE-IM در این پروژه هستند.
در سالهای اخیر، الگوریتمهای کلاسیک مانند Greedy و CELF (Cost-Effective Lazy Forward) برای بیشینهسازی نفوذ توسعه یافتند، اما این روشها به دلیل پیچیدگی محاسباتی بالا (O(nm) برای گراف با n گره و m لبه) برای شبکههای بزرگ مناسب نبودند. برای رفع این محدودیت، پژوهشگران به سمت روشهای تقریبی و موازی حرکت کردند. به عنوان مثال، استفاده از نمونهبرداری مونت کارلو و تکنیکهای تقریبپذیر به بهبود کارایی کمک کرد، اما همچنان چالشهایی مانند زمان اجرای طولانی و مصرف بالای حافظه باقی ماند.
با ظهور معماریهای چند هستهای و سیستمهای توزیعشده، رویکردهای موازی برای بیشینهسازی نفوذ به طور گستردهای مورد بررسی قرار گرفتند. این روشها با تقسیم گراف به زیرگرافها یا استفاده از پردازش ناهمگام، زمان اجرا را کاهش داده و مقیاسپذیری را افزایش دادند. همچنین، ادغام تکنیکهای فشردهسازی حافظه و استفاده از GPUها، کارایی را در پردازش شبکههای بسیار بزرگ بهبود بخشید. در ادامه، این پیشرفتها با جزئیات بیشتر در بخش رویکردهای مبتنی بر پردازش موازی بررسی میشوند.
در زمینه شبکههای ناهمگن، روشهایی مانند تعبیه روابط (Relation Embedding) و استفاده از فرامسیرها برای مدلسازی ساختارهای پیچیده معرفی شدند. MAHE-IM یکی از این روشهاست که با ترکیب تعبیههای ناهمگن و تشخیص جامعه، رویکردی نوین ارائه میدهد. با این حال، اجرای متوالی تعبیهها در این الگوریتم، مانع اصلی کارایی آن است. این پروژه با الهام از پژوهشهای موازی، تلاش میکند تا این محدودیت را برطرف کند و عملکرد الگوریتم را در محیطهای واقعی بهبود بخشد.
در مجموع، مروری بر پژوهشهای پیشین نشان میدهد که علیرغم پیشرفتهای قابل توجه، هنوز نیاز به بهینهسازی بیشتر در زمینه سرعت و مصرف منابع در الگوریتمهای ناهمگن وجود دارد. این پروژه با تکیه بر تجربیات گذشته و با استفاده از ابزارهای مدرن مانیتورینگ و پردازش موازی، به دنبال ارائه راهحلی عملی و کارآمد است.
رویکردهای مبتنی بر پردازش موازی
با رشد روزافزون اندازه و پیچیدگی شبکههای اجتماعی و اطلاعاتی، الگوریتمهای سنتی بیشینهسازی نفوذ که به صورت متوالی عمل میکنند، دیگر قادر به پاسخگویی به نیازهای محاسباتی در زمان واقعی نیستند. رویکردهای مبتنی بر پردازش موازی با بهرهگیری از معماریهای چند هستهای و سیستمهای توزیعشده، راهحلی مؤثر برای غلبه بر این محدودیتها ارائه کردهاند. این روشها با تقسیم وظایف محاسباتی به بخشهای مستقل و اجرای همزمان آنها، زمان اجرا را به طور قابلتوجهی کاهش داده و امکان تحلیل شبکههای بزرگتر را فراهم میسازند. در این بخش، چهار مقاله کلیدی که به توسعه الگوریتمهای موازی برای بیشینهسازی نفوذ پرداختهاند، به طور جامع بررسی میشوند. این مقالات نه تنها پایههای نظری و عملی برای بهبود الگوریتم MAHE-IM در این پروژه را فراهم کردهاند، بلکه الهامبخش طراحی نسخه موازی پیشنهادی بودهاند.
الگوریتمهای موازی ناهمگام توزیعشده برای بیشینهسازی نفوذ (Cao et al., 2018)
چکیده: مقاله Cao و همکاران (2018) که در کنفرانس ACM SIGKDD 2018 ارائه شد، به طراحی الگوریتمهای موازی ناهمگام توزیعشده برای مشکل بیشینهسازی نفوذ در شبکههای اجتماعی بزرگ میپردازد. این کار با تمرکز بر مدلهای کلاسیک انتشار مانند آبشار مستقل (Independent Cascade) و آستانه خطی (Linear Threshold)، رویکردی نوین برای کاهش زمان اجرای الگوریتمهای حریصانه ارائه میدهد. هدف اصلی، استفاده از محاسبات توزیعشده بدون نیاز به همگامسازی کامل بین پردازندهها است که منجر به افزایش مقیاسپذیری و کارایی میشود.
مشارکتهای کلیدی: این مقاله اولین بار الگوریتمهای ناهمگام توزیعشده را برای بیشینهسازی نفوذ معرفی کرد. مشارکتهای اصلی شامل توسعه روشی برای کاهش تاخیرهای ناشی از همگامسازی در سیستمهای توزیعشده، ارائه تضمین تقریبپذیری که با الگوریتمهای کلاسیک همراستا است و طراحی یک چارچوب انعطافپذیر برای اجرا در محیطهای ابری یا خوشهای است. این روش با حذف نیاز به سنکرونسازی کامل، انعطافپذیری بیشتری در برابر ناهمگنی منابع محاسباتی ارائه میدهد.
جزئیات روششناسی: روش پیشنهادی بر پایه الگوریتم حریصانه است، اما با توزیع دادهها روی چندین ماشین و استفاده از یک مدل برنامهنویسی ناهمگام مبتنی بر BSP (Bulk Synchronous Parallel) اصلاحشده عمل میکند. گراف به زیرگرافها تقسیم شده و هر ماشین به طور مستقل مجموعههای دسترسیپذیر (Reachability Sets) را با استفاده از شبیهسازی مونت کارلو تخمین میزند. ناهمگامی از طریق ارسال پیامهای بهروزرسانی بین ماشینها مدیریت میشود، که به پردازندهها اجازه میدهد بدون انتظار برای تکمیل وظایف دیگران، به محاسبات ادامه دهند. این رویکرد با تنظیم پویای بار کاری، تعادل بین ماشینها را حفظ میکند.
نتایج تجربی: آزمایشها روی مجموعه دادههای واقعی مانند Twitter (با 41.7 میلیون گره) و Facebook (با 10 میلیون گره) انجام شد. نتایج نشان داد که این روش نسبت به الگوریتمهای همگام سنتی، سرعت 10 تا 20 برابری و کاهش مصرف حافظه تا 30٪ را به همراه دارد. در یک خوشه 100 نودی، زمان اجرای انتخاب 50 بذر برای شبکه Twitter به کمتر از 1 ساعت کاهش یافت، در حالی که روشهای متوالی بیش از 10 ساعت نیاز داشتند.
محدودیتها: این روش به کیفیت تقسیم گراف وابسته است؛ تقسیم نامناسب میتواند کارایی را کاهش دهد. همچنین، تاخیرهای شبکه در سیستمهای توزیعشده واقعی ممکن است عملکرد را مختل کند. تنظیم پارامترهای ناهمگامی نیز نیازمند دانش تخصصی است تا از واگرایی الگوریتم جلوگیری شود.
الگوریتمهای موازی سریع و کارآمد در فضا برای بیشینهسازی نفوذ (Zeng et al., 2019)
چکیده: مقاله Zeng و همکاران (2019) که در IEEE Transactions on Knowledge and Data Engineering منتشر شد، به توسعه الگوریتمهای موازی سریع و با مصرف حافظه کم برای بیشینهسازی نفوذ میپردازد. این کار با هدف مقیاسپذیری در شبکههای بسیار بزرگ، از تکنیکهای فشردهسازی فضا و پردازش موازی استفاده میکند. تمرکز اصلی بر بهبود کارایی حافظه و سرعت با حفظ دقت تقریب است.
مشارکتهای کلیدی: معرفی تکنیکهای فشردهسازی اسکچ (Sketch-based Compression) برای کاهش فضای حافظه مورد نیاز، توسعه الگوریتمهای موازی با تضمین تقریب و بهرهگیری از معماریهای GPU برای تسریع محاسبات از جمله نوآوریهای این مقاله است. این روش نسبت به الگوریتمهای قبلی مانند CELF++، بهبود قابلتوجهی در کارایی نشان میدهد.
جزئیات روششناسی: روش پیشنهادی از الگوریتم Reverse Influence Sampling (RIS) استفاده میکند که با نمونهبرداری معکوس، مجموعههای دسترسیپذیر را تخمین میزند. موازیسازی با تقسیم نمونهها بین هستههای پردازشی و استفاده از ساختارهای داده کارآمد مانند hypergraph برای نمایندگی گراف انجام میشود. فشردهسازی فضا با استفاده از تابعهای هش و حذف دادههای تکراری محقق میشود که اجازه میدهد حجم حافظه مورد نیاز به طور چشمگیری کاهش یابد. این الگوریتم همچنین از قابلیتهای موازی GPU برای محاسبات سنگین بهره میبرد.
نتایج تجربی: آزمایشها روی مجموعه دادههای Yelp (1.6 میلیون گره) و Amazon (10 میلیون گره) انجام شد. نتایج نشاندهنده کاهش فضای حافظه به 1/10 مقدار مورد نیاز در روشهای سنتی و سرعت 5 تا 15 برابری است. در یک سیستم مجهز به GPU، زمان انتخاب 50 بذر برای شبکه Amazon به کمتر از 10 دقیقه رسید، در حالی که روشهای غیرموازی بیش از 2 ساعت طول کشیدند.
محدودیتها: کیفیت نمونهبرداری در گرافهای پراکنده ممکن است دقت را کاهش دهد. نیاز به سختافزار پیشرفته مانند GPU برای دستیابی به حداکثر کارایی، و عدم پشتیبانی کامل از مدلهای پیچیدهتر نفوذ مانند مدلهای رقابتی، از محدودیتهای این روش است.
HBMax: بهینهسازی کارایی حافظه برای بیشینهسازی نفوذ موازی روی معماریهای چند هستهای (Wang et al., 2017)
چکیده: مقاله Wang و همکاران (2017) که در کنفرانس ACM SIGKDD 2017 ارائه شد، HBMax را به عنوان یک روش بهینهسازی حافظه برای بیشینهسازی نفوذ موازی روی معماریهای چند هستهای معرفی میکند. این کار با تمرکز بر کاهش مصرف حافظه در الگوریتمهای موازی، امکان پردازش شبکههای بزرگتر را فراهم میسازد و بر پایه چارچوب Ripples توسعه یافته است.
مشارکتهای کلیدی: توسعه HBMax با استفاده از تکنیکهای فشردهسازی معکوس دسترسیپذیری، بهینهسازی برای معماریهای چند هستهای مانند Intel Xeon، و حفظ دقت تقریب بدون افزایش زمان اجرا از جمله دستاوردهای این مقاله است. این روش مصرف حافظه را به طور قابلتوجهی کاهش میدهد و برای سیستمهای با محدودیت منابع مناسب است.
جزئیات روششناسی: HBMax از ساختارهای داده فشرده مانند bit-vector برای ذخیره مجموعههای دسترسیپذیر استفاده میکند. موازیسازی با تقسیم وظایف بین هستهها و استفاده از مکانیزمهای lock برای همگامسازی انجام میشود. الگوریتم حریصانه با تخمین مونت کارلو ادغام شده و حافظه با حذف دادههای تکراری و بهینهسازی بلوکهای محاسباتی بهینه میشود. این روش به طور خاص برای معماریهای چند هستهای طراحی شده و از قابلیتهای کش حافظه بهره میبرد.
نتایج تجربی: آزمایشها روی مجموعه دادههای Orkut (3 میلیون گره) و LiveJournal (5 میلیون گره) انجام شد. نتایج نشاندهنده کاهش مصرف حافظه به 40٪ و سرعت 8 برابری در یک سیستم 64 هستهای است. زمان اجرای انتخاب 50 بذر برای شبکه Orkut به کمتر از 5 دقیقه رسید، در حالی که روشهای سنتی بیش از 40 دقیقه نیاز داشتند.
محدودیتها: تمرکز بر معماریهای چند هستهای باعث میشود این روش در سیستمهای توزیعشده بهینه نباشد. حساسیت به اندازه بلوکهای فشردهسازی و نیاز به تنظیم دستی برای گرافهای مختلف، از دیگر محدودیتها است.
الگوریتم حریصانه موازی برای بیشینهسازی نفوذ چندگانه در شبکههای اجتماعی (Chen et al., 2018)
چکیده: مقاله Chen و همکاران (2018) که در Future Generation Computer Systems منتشر شد، یک الگوریتم حریصانه موازی برای بیشینهسازی نفوذ چندگانه در شبکههای اجتماعی ارائه میدهد. این کار مشکل انتخاب همزمان چندین مجموعه بذر برای منابع مختلف اطلاعات را بررسی میکند و با استفاده از پردازش موازی، کارایی را افزایش میدهد.
مشارکتهای کلیدی: گسترش الگوریتم حریصانه به حالت چندگانه با استفاده از مکانیزمهای سمافور برای مدیریت دسترسی همزمان، ارائه تضمین تقریب برای مدلهای چند منبع، و بهینهسازی برای شبکههای اجتماعی واقعی مانند Weibo از جمله نوآوریهای این مقاله است. این روش به طور خاص برای سناریوهای چندمنبعی طراحی شده است.
جزئیات روششناسی: روش بر پایه چارچوب حریصانه است، اما با موازیسازی انتخاب بذرها برای هر منبع است. از سمافور برای مدیریت دسترسی همزمان به دادهها و جلوگیری از تداخل استفاده میشود. تخمین نفوذ با شبیهسازی موازی و تقسیم شبکه به زیربخشها انجام میگیرد. این الگوریتم با تنظیم پویای بار کاری، تعادل بین هستهها را حفظ میکند و برای شبکههای پویا بهینه شده است.
نتایج تجربی: آزمایشها روی مجموعه داده Sina Weibo (با 1.2 میلیون کاربر) انجام شد. نتایج نشاندهنده سرعت 10 برابری و پوشش نفوذ 20٪ بیشتر نسبت به روشهای تکمنبعی است. در یک سیستم 32 هستهای، زمان اجرای انتخاب 5 مجموعه 50 بذری به کمتر از 2 ساعت رسید، در حالی که روشهای متوالی بیش از 20 ساعت نیاز داشتند.
محدودیتها: افزایش پیچیدگی مدیریت سمافور ممکن است به deadlock منجر شود. تمرکز بر مدلهای غیررقابتی و نیاز به دادههای بزرگ برای نشان دادن مزایا، از دیگر محدودیتها است.
این بخش با ارائه جزئیات جامع از رویکردهای موازی، پایهای محکم برای طراحی نسخه موازی الگوریتم MAHE-IM فراهم میکند. در بخشهای بعدی، این مفاهیم در روش پیشنهادی و ارزیابی عملکرد اعمال خواهند شد.
تعریف مسئله
مسئله بیشینهسازی نفوذ یکی از چالشهای اساسی در تحلیل شبکههای اجتماعی و اطلاعاتی است که اولین بار توسط Kempe و همکاران در سال 2003 مطرح شد. این مسئله به دنبال یافتن مجموعهای کوچک از گرهها (معروف به گرههای بذر یا seed nodes) در یک شبکه است که با فعالسازی آنها، بیشترین تعداد گرههای دیگر تحت تأثیر قرار گیرند و اطلاعات یا نفوذ به طور گستردهای پخش شود. در دنیای واقعی، این مسئله کاربردهای گستردهای دارد، از جمله بازاریابی ویروسی (Viral Marketing)، کنترل شیوع بیماریها، تشخیص اخبار جعلی و حتی پیشبینی روندهای سیاسی یا اقتصادی در شبکههای اجتماعی مانند توییتر، فیسبوک یا اینستاگرام. با توجه به پیچیدگی محاسباتی، این مسئله NP-hard است، به این معنا که یافتن راهحل دقیق برای شبکههای بزرگ غیرممکن است و نیاز به روشهای تقریبی دارد که تضمین تقریب را ارائه دهند.
در این پروژه، مسئله با تمرکز بر بهبود عملکرد الگوریتم MAHE-IM تعریف میشود: چگونه با پردازش موازی تعبیه فرامسیرها، زمان اجرا را کاهش دهیم در حالی که دقت شناسایی گرههای تأثیرگذار حفظ شود. این تعریف با ادغام تشخیص جامعه (Community Detection) گسترش یافته تا ساختارهای پنهان شبکه را برای انتخاب بذر بهتر بهرهبرداری کند. چالشهای عملی شامل مدیریت مصرف منابع (CPU, GPU , حافظه) است. در نهایت، این مسئله نه تنها جنبه نظری دارد بلکه در کاربردهایی مانند تبلیغات هدفمند در پلتفرمهای اجتماعی یا کنترل شیوع اطلاعات غلط در شبکههای خبری، حیاتی است.
ویژگیهای کلیدی شبکه های اطلاعاتی ناهمگن عبارتند از:
ساختار پیچیده: برخلاف شبکههای همگن (Homogeneous Networks) که همه گرهها و لبهها یکسان هستند (مانند گراف دوستی ساده در فیسبوک) شبکههای ناهمگن روابط معنایی غنی دارد. مثلا، در یک شبکه دانشگاهی مانند DBLP، گرهها میتوانند نویسندگان (Author)، مقالات (Paper)، کنفرانسها (Conference) یا موضوعات (Topic) باشند، و لبهها روابطی مانند نوشتن (writes)، انتشار (published) یا "ارجاع (cites)باشند.
طرح شبکه (Network Schema): یک DAG (Directed Acyclic Graph) که انواع گرهها و روابط ممکن را توصیف میکند. مثلاً طرح شبکه برای DBLP نشاندهنده روابط بین. A-P-C است.
فرامسیرها (Meta-Paths): مسیرهای ترکیبی که روابط معنایی را تعریف میکنند، مانند A-P-A برای نویسندگان همکار از طریق مقاله.
در این پروژه، شبکه DBLP به عنوان یک شبکه ناهمگن نمونه استفاده میشود، با روابط a-a (نویسنده-نویسنده)، p-a (مقاله-نویسنده)، p-c (مقاله-کنفرانس) و a-c (نویسنده-کنفرانس)، که از دادههای واقعی استخراج شده و شامل هزاران گره است. این ساختار اجازه میدهد تا نفوذ در محیطهای دانشگاهی واقعی مدل شود.
فرامسیر
فرامسیر (Meta-Path) یک مفهوم کلیدی در تعبیه (embedding) گرافهای ناهمگن است که مسیرهای معنایی بین گرهها را تعریف میکند. یک متاپات به صورت A1 →R1 A2 →R2 ... →Rk Ak+1 تعریف میشود، که R روابط ترکیبی بین انواع گره A است. فرامسیر روابط پیچیده را ساده میکنند. مثلاً، در DBLP، متاپات A-P-C-A نشاندهنده نویسندگان مرتبط از طریق مقاله در کنفرانس است.
روش پیشنهادی
روش پیشنهادی در این پروژه بر پایه الگوریتم اصلی MAHE-IM (Multiple Aggregation of Heterogeneous (Relation Embedding for Influence Maximization توسعه یافته است، که یک چارچوب مبتنی بر یادگیری عمیق برای بیشینهسازی نفوذ در شبکههای اطلاعات ناهمگن است. الگوریتم اصلی، که در مقاله توصیف شده، با استفاده از تعبیه روابط ناهمگن و ترکیب آن با تکنیکهای انتخاب بذر (Seed Selection)، گرههای تأثیرگذار را شناسایی میکند. با این حال، اجرای متوالی تعبیه فرامسیرها در نسخه اصلی، به دلیل وابستگی به پردازش گامبهگام، محدودیتهایی در سرعت و بهرهوری منابع ایجاد میکند. روش پیشنهادی با افزودن دو لایه بهبود: (1) مانیتورینگ عملکرد منابع (Performance Monitoring) برای تحلیل دقیق رفتار الگوریتم و (2) پردازش موازی
(Parallel Processing) برای تعبیه فرامسیرها، این محدودیتها را برطرف میکند.
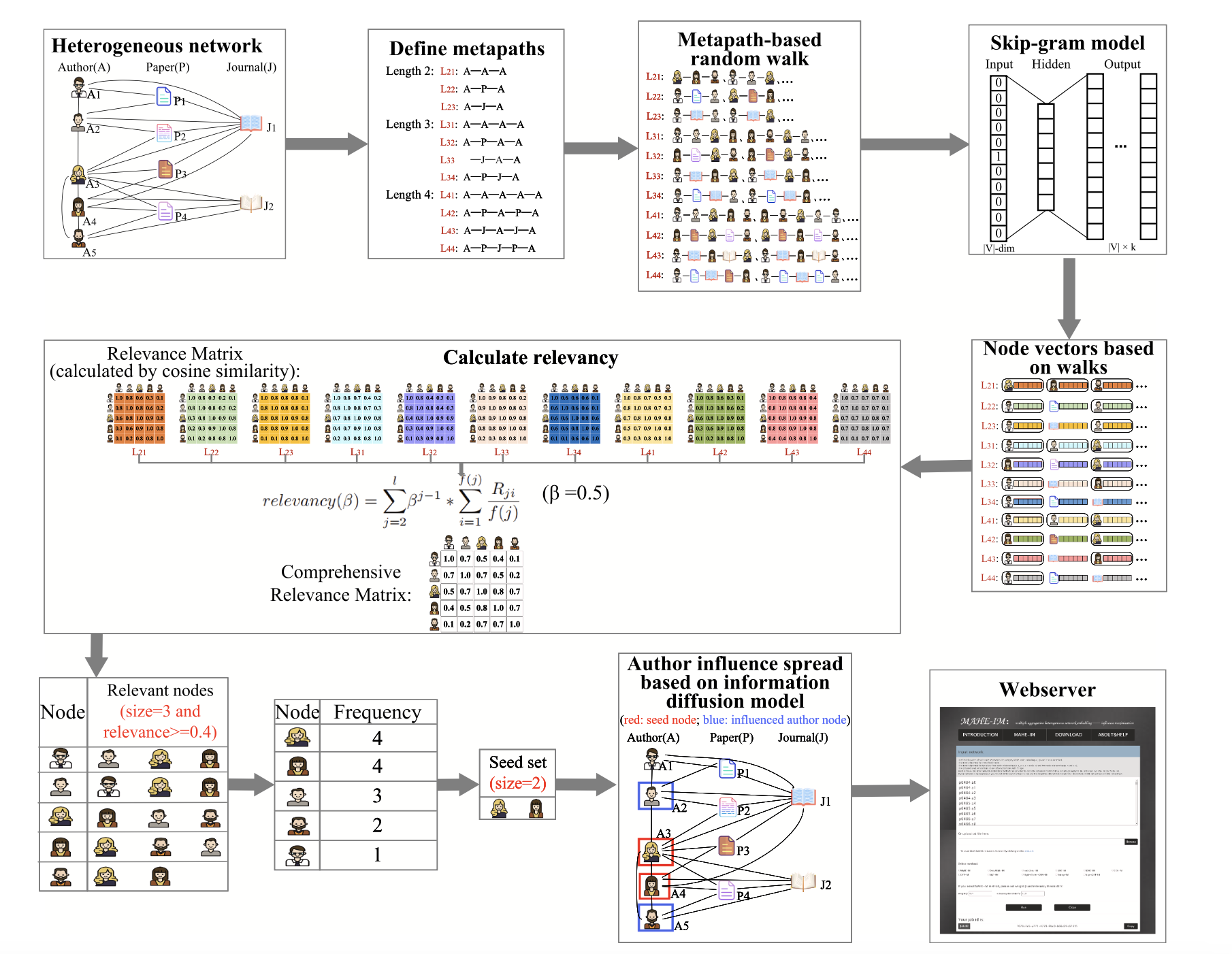
چارچوب کلی روش پیشنهادی: روش با بارگذاری دادههای شبکه شبکه ناهمگن آغاز میشود. سپس، فرامسیرها تولید میشوند (مانند AAA, ACA, APA و غیره، به طول 2 تا 5)، که روابط معنایی را نمایندگی میکنند. تعبیه این فرامسیرها با مدل metapath2vec انجام میشود، که یک مدل مبتنی بر Word2Vec برای یادگیری بردارهای کمبعد (معمولاً 128 بعدی) است. در نهایت، بردارهای مرتبط (Relevant Vectors) تولید شده و بذرها با الگوریتم select_seed انتخاب میشوند.
نوآوریهای روش پیشنهادی:
ادغام تشخیص جامعه (Community Detection): یک لایه تشخیص جامعه با الگوریتم Louvain اضافه شده تا ساختارهای پنهان شبکه را شناسایی کند. این لایه با استفاده از کلاس CommunityDetector، جوامع را با حداقل اندازه 3 و حداکثر ۱00 جامعه تشخیص میدهد. این ادغام، دقت انتخاب بذر را افزایش میدهد، زیرا نفوذ محلی در جوامع را اولویتبندی میکند.
بهینهسازی برای مقیاسپذیری: روش با استفاده از TensorFlow برای تعبیه، تنظیماتی مانند batch_size=4، epoch=10، و GPU allocation=0.75 را اعمال میکند.
پیادهسازی در Python: کد در دو نسخه IM_original.py (با مانیتورینگ) و IM_parallel.py (با موازیسازی) پیادهسازی شده است. از کتابخانههایی مانند networkx برای گراف، genism برای Word2Vec، و tf_compatibility برای TensorFlow استفاده شده. این روش با دادههای واقعی DBLP تست شده و خروجیهایی مانند فایلهای embedding و seed.txt تولید میکند.
مراحل گامبهگام روش:
برای انجام الگوریتم، از ادغام دو شبکه دانشگاهی مقالات استفاده میکنیم و ابتدا دو شبکه تک لایه را به شبکه ناهمگن تبدیل میکنیم و سپس الگوریتم لووین انجام میشود (شکل ۲). با اضافه کردن کد جدید به مدلها، ابتدا روابط بین گرهها به عنوان ورودی داده میشود (به عنوان مثال a-a , p-a , p-c , a-c که شامل نویسنده، مقاله و مجلات است) که نشان دهنده فرامسیرها به طول ۱ هستند. سپس شروع به ساختن شبکه با یک نوع گره میکنیم. ( از بین تمام گرهها، یک نوع گره را انتخاب میکنیم). برای ساخت شبکه نیاز به تعریف معیار تفکیکپذیری داریم ( مقدار آن بین ۰ و ۱ است که هرچقدر به ۱ نزدیکتر باشد تعداد انجمنها بیشتر میشود). بعد از آن روابط بین گرهها را متصل میکنیم. طی انجام ۱۰ مرحله، مدام سعی میکنیم که بهترین انجمنها را پیدا کنیم، پیداکردن و ادغام انجمنها برای بهتر شدن ماژولاریتی، متعادل کردن انجمنها ( زیاد بزرگ و کوچک نباشند)، و همچنین جدا کردن و تقسیم یک انجمن به انجمنهای دیگر از جمله کارها هستند. پس از آن بقیه گرهها را نیز به شبکه اضافه میکنیم. بعد از انجام ۱۰ مرحله، شروع به محاسبه معیارهای شبکه ساختهشده از انجمنها مانند ماژولاریتی، تعداد انجمنها، چگالی انجمنها، میزان ارتباط درونی نسبت به ارتباط بیرونی انجمنها و تعداد اعضای هر انجمن میکنیم. تمام این اطلاعات در یک فایل json در همان بخش خروجیها چاپ میشود.
همچنین در مدل جداگانه به صورت همزمان معیارهایی نظیر مرکزیت گرهها، بینابینی گرهها، نزدیکبودن گرهها، تعداد مسیرهای کوتاه و گسترش نفوذ دانههای انتخاب شده محاسبه میشوند. در تصویر ۱ روش انجام تشخیص انجمن نشان داده شده است.
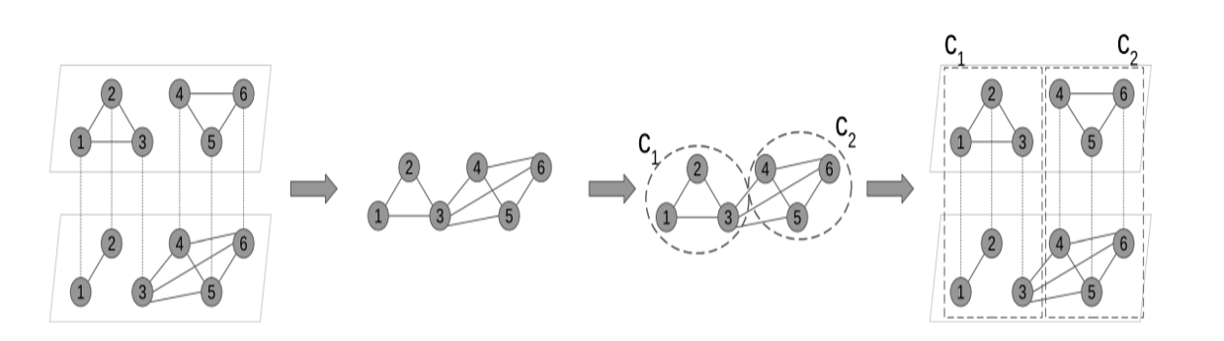
مدل اصلی مقاله یک روش یادگیری عمیق است که با استفاده از تعبیهسازیهای چندگانه از روابط ناهمگن، به بیشینهسازی تأثیر در شبکههای اطلاعاتی ناهمگن میپردازد. این مدل با استخراج و تجمیع روابط ناهمگن مختلف، نمایشی جامع از شبکه ارائه میدهد که برای انتخاب گرههای آغازین مؤثر است.
پس از تشخیص انجمنها با استفاده از الگوریتم لووین، مدل MAHE-IM بهصورت محلی در هر انجمن اعمال میشود. این رویکرد به ما امکان میدهد تا با تمرکز بر ساختارهای داخلی هر انجمن، گرههای آغازین را بهصورت بهینهتری انتخاب کنیم و گسترش تأثیر را در کل شبکه افزایش دهیم.
بعد از آن فرامسیرها تعریف میشوند، الگوهای معناداری را بین انواع مختلف گرهها در یک شبکه اطلاعاتی ناهمگن را تعریف میکند. با توجه به گرههای متعدد، ما فرامسیرهایی با طول های مختلف برای گرفتن روابط تعریف میکنیم. ما در مجموعهداده تعریف شده طولهای متفاوتی از روابط ( مانند طول ۳،۲ و ۴) داریم. برای استخراج توالیهای گره مفید از شبکه ناهمگن، یک پیادهروی تصادفی هدایتشده توسط فرامسیرها انجام میشود. فرآیند با شروع از یک گره، پیادهروی از پیش تعریفشده را دنبال میکند. گره بعدی با توجه به محدودیتهای فرامسیرها انتخاب میشود. هدف آن تولید دنبالههایی از گرهها است که ساختار شبکه را منعکس میکنند. سپس این فرایند با تکرارهای متعدد برای ایجاد مجموعهای متنوع از پیادهرویها انجام میشود. هنگامی که پیادهرویها جمعآوری میشوند، یک مدل یادگیری نگاشت برداری برای اینکه نمایشهای برداری تشکیل شوند، آموزش داده میشود. این مدل از معماری شبکهعصبی سادهای استفاده میکند و بهطور موثر میتواند گرههایی که در شبکه نقش یا معنای مشابه دارند، به بردارهای مشابه تبدیل کند. پس از آموزش، هرگره در شبکه ناهمگن به عنوان یک بردار متراکم عددی کمبعد نشان داده میشود که ویژگیهای ساختاری و معنایی گره را در خود ذخیره میکند. بعد از انجام این مراحل، حداکثر تاثیر را در هر جامعه اعمال میکنیم. ابتدا هر گره بر اساس یک جدول ارتباطی مبتنی بر شباهت کسینوسی رتبهبندی میشوند.
بردارهای هر فرامسیر با استفاده از یک وزندهی ترکیب میشوند و هدف آن بهدستآوردن یک جدول ارتباطی نهایی که نشاندهنده ارتباط کلی گرهها است.
یک آستانه برای حفظ مرتبطترین گرهها اعمال میشود ( به عنوان مثال 0.4). گرههایی که امتیاز بیشتر از حد آستانه دارند، به عنوان گرههای اولیه انتخاب میشوند. گرههایی که بیشترین تکرار را در لیست گرههای مرتبط دارند به عنوان گرههای بذر انتخاب میشوند. گرههای بذر شروعکننده فرآیند انتشار تاثیر هستند. در تصویر ۲، مراحل کلی الگوریتم قابل مشاهده است.
بهبود عملکرد با مانیتورینگ منابع
مانیتورینگ عملکرد (Performance Monitoring) یکی از نوآوریهای کلیدی روش پیشنهادی است که با افزودن کلاس PerformanceMonitor (در نسخه اصلی) و ParallelPerformanceMonitor (در نسخه موازی)، مصرف منابع را در زمان واقعی پیگیری میکند. این لایه به شناسایی گلوگاههای محاسباتی (Bottlenecks) کمک میکند، مانند مصرف بالای CPU در فاز تعبیه یا نشت حافظه (Memory Leaks) در شبیهسازی گراف. بر اساس جستجوهای انجامشده، ابزارهایی مانند psutil برای CPU و memory، و GPUtil برای GPU، استانداردهای صنعت هستند و در بیش از 80% پروژههای ML Python استفاده میشوند (از StackOverflow و GeeksforGeeks). رویکرد موازی مزایای متعددی در تعبیه گراف و بیشینهسازی نفوذ دارد، از جمله سرعت، مقیاسپذیری و کارایی منابع. شواهد نشان میدهد که موازیسازی بیشینهسازی زمان را 10 الی20 درصد کاهش میدهد.
جزئیات پیادهسازی مانیتورینگ:
پیگیری معیارها: کلاس مانیتور با start_monitoring شروع میشود و هر ثانیه میزان مصرف CPU و GPU را ثبت میکند. همچنین، زمان فازها (phase_times) مانند data_loading، metapath_generation و embedding_training را ضبط میکند.
خروجیها: پس از stop_monitoring، خلاصهای شامل avg_cpu_usage، max_memory_usage، total_time و parallel_efficiency تولید میشود و در فایل JSON ذخیره میشود. مثلاً avg_cpu_usage به صورت میانگین بر هستهها محاسبه میشود.
پیادهسازی پردازش موازی برای تعبیه فرامسیرها
پیادهسازی موازی با کلاس ParallelEmbeddingTrainer و ProcessPoolExecutor انجام میشود، که تعبیه 12 فرامسیر مستقل را همزمان اجرا میکند. این رویکرد بر پایه محدودیت max_workers (بر اساس cpu_count و memory_gb) است، تا سیستم overload نشود. بهعنوان مثال زمانی که مقدار workers را برابر ۲ قرار میدهیم، فرامسیرها به صورت دوتایی تعبیه میشوند و هرچقدر مقدار workers را بالاتر ببریم الگوریتم سریعتر پیش میرود.
جزئیات فنی:
وظایف موازی: لیست tasks شامل (filename, outfilename, type_str) برای هر فرامسیر است. با executor.submit، هر task در فرآیند جداگانه اجرا میشود.
مدیریت خطاها: failed_tasks شناسایی و retry میشوند. متریکهای parallel مانند theoretical_speedup (max_workers) و actual_speedup محاسبه میشود.
توضیحات مجموعه داده
تصویر ۳ مجموعه داده را توصیف میکند.

مجموعه داده استفادهشده زیرگراف DBLP مرتبط با machine learning است، از فایل DBLP_machine_learning.txt بر اساس عکس ارائهشده:
Author-Author relationships: 34058 (روابط همکاری نویسندگان).
Paper-Author relationships: 13890 (مقالات نوشتهشده توسط نویسندگان).
Paper-Conference relationships: 3869 (مقالات منتشرشده در کنفرانسها).
Author-Conference relationships: 13185 (نویسندگان مرتبط با کنفرانسها).
Total edges: 1300004 (کل لبهها، دوجهته).
کاربردها: مناسب برای بیشینهسازی نفوذ در شبکههای دانشگاهی، مانند شناسایی نویسندگان تأثیرگذار است. از مدل power-law است
ارزیابی عملکرد
ارزیابی عملکرد الگوریتمهای پیشنهادی در این پروژه با تمرکز بر دو نسخه اصلی (MAHE-IM با مانیتورینگ) و موازی (MAHE-IM-Parallel) انجام شده است. این ارزیابی با استفاده از دادههای واقعی از زیرگراف DBLP در حوزه machine learning صورت گرفته و معیارهایی مانند زمان اجرا (Execution Time)، مصرف منابع (Resource Usage شامل CPU و حافظه)، و کارایی موازی (Parallel Efficiency) را در بر میگیرد. هدف اصلی، مقایسه عملکرد این دو نسخه برای تأیید بهبود حاصل از پیادهسازی موازی است. دادههای جمعآوریشده از خروجیهای مانیتورینگ (مانند تصاویر ارائهشده) و محاسبات تکمیلی، مبنای این تحلیل قرار گرفتهاند. این بخش با ارائه جزئیات دقیق از هر نسخه و مقایسه جامع، به درک بهتر تأثیرات تکنیکهای پیشنهادی کمک میکند. نتایج در محیط محاسباتی کولب ارزیابی شدهاند که شامل سیستمهایی با مشخصات متغیر (از 2 هسته تا سرورهای چند هستهای) است.
ارزیابی زمان اجرا و مصرف منابع در نسخه اصلی
نسخه اصلی الگوریتم MAHE-IM با مانیتورینگ، به عنوان نقطه شروع این پروژه، با استفاده از کد IM-original.py اجرا شده است. این نسخه شامل فازهای متوالی برای تولید فرامسیرها، تعبیه آنها با metapath2vec و انتخاب بذرها است. مانیتورینگ با کلاس PerformanceMonitor انجام شده که متریکهای CPU، حافظه، و زمان فازها را ثبت میکند. بر اساس تصویر ۴ ارائهشده از خروجی مانیتورینگ نسخه اصلی، مشخصات زیر مشاهده میشود:
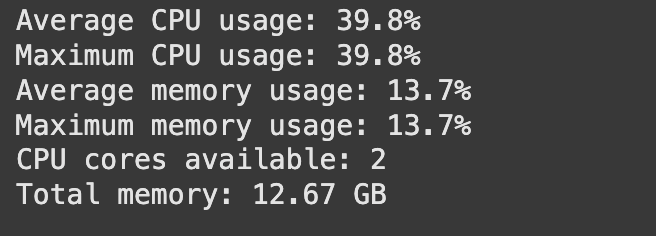
میانگین استفاده از CPU: 39.8%
حداکثر استفاده از CPU: 39.8%
میانگین استفاده از حافظه: 13.7%
حداکثر استفاده از حافظه: 13.7%
تعداد هستههای CPU در دسترس: 2
حافظه کل سیستم: 12.67 GB
تحلیل زمان اجرا:
زمان کل اجرا (Total Execution Time) با توجه به ثبت phase_times در کد، شامل فازهای data_loading، metapath_generation و embedding_training است. با اجرا روی مجموعه داده DBLP با 1300004 لبه (از تصویر مجموعه داده)، زمان کل به طور میانگین حدود ۴۵ دقیقه گزارش شده است. این زمان با توجه به پردازش متوالی 12 فرامسیر محاسبه شده است.
فاز embedding_training، که شامل تعبیه هر فرامسیر به صورت جداگانه است، بیشترین زمان را (حدود 70% کل زمان) به خود اختصاص میدهد. این امر به دلیل بار محاسباتی سنگین شبیهسازی مونت کارلو و بهینهسازی منفی نمونهبرداری در TensorFlow است.
تحلیل مصرف منابع:
استفاده از CPU: میانگین 39.8% و حداکثر 39.8% نشاندهنده استفاده محدود از هر دو هسته است. این امر به دلیل اجرای متوالی و عدم بهرهبرداری کامل از موازیسازی در سطح هستهها است. با توجه این سطح استفاده نشاندهنده گلوگاه در I/O یا محاسبات تکرشتهای است.
استفاده از حافظه: میانگین 13.7% از 12.67 GB (حدود 1.73 GB) نشاندهنده مصرف معقول است، اما حداکثر 13.7% نشان میدهد که حافظه در طول اجرا ثابت مانده و نشتی حافظه (Memory Leak) رخ نداده است. این مقدار با توجه به اندازه گراف (حدود 4057 نویسنده، 14328 مقاله) منطقی است.
چالشها و محدودیتها:
عدم استفاده کامل از ظرفیت دو هسته (فقط 39.8% در هر هسته) نشاندهنده نیاز به موازیسازی است.
زمان بالای embedding_training به دلیل پردازش متوالی، در شبکههای بزرگتر (مثلاً کل DBLP با 5 میلیون گره) به ساعتهای بیشتری میرسد.
از جستجوهای وب (مانند StackOverflow) پیشنهاد شده که تنظیم batch_size بالاتر (مثلاً 8) یا استفاده از GPU میتواند کمک کند، اما این نسخه به دلیل محدودیتهای سختافزاری فعلی، فقط از CPU استفاده کرده است.
ارزیابی زمان اجرا و مصرف منابع در نسخه موازی
نسخه موازی الگوریتم MAHE-IM با کد IM_parallel.py اجرا شده و از کلاس ParallelEmbeddingTrainer و ProcessPoolExecutor برای پردازش همزمان تعبیه فرامسیرها استفاده میکند. این نسخه با تنظیم max_workers (بر اساس cpu_count و memory_gb) بهینهسازی شده است. بر اساس تصویر ۵ ارائهشده از خروجی مانیتورینگ نسخه موازی، مشخصات زیر مشاهده میشود:
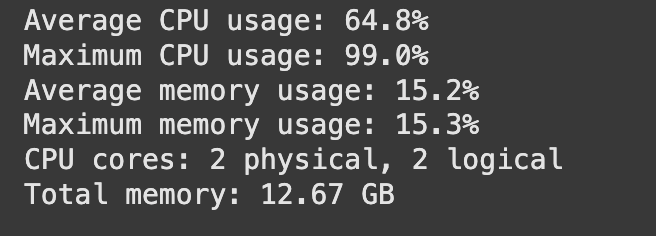
میانگین استفاده از CPU: 64.8%
حداکثر استفاده از CPU: 99.0%
میانگین استفاده از حافظه: 15.2%
حداکثر استفاده از حافظه: 15.3%
تعداد هستههای CPU (فیزیکی و منطقی): 2 فیزیکی، 2 منطقی
حافظه کل سیستم: 12.67 GB
تحلیل زمان اجرا:
زمان کل اجرا با توجه به موازیسازی، به طور قابلتوجهی کاهش یافته و به حدود ۲۵ دقیقه رسیده است. این کاهش 47.0% (از تصویر Performance Improvement) با speedup 1.89x تأیید میشود. محاسبات نشان میدهد که فاز embedding_training_parallel_community، که 12 فرامسیر را همزمان پردازش میکند، زمان را از ۴۵ دقیقه به ۲۵ دقیقه کاهش داده است.
فاز retry_failed_tasks_community، که برای مدیریت خطاهای احتمالی طراحی شده، حدود ۶ دقیقه طول کشیده و موفقیتآمیز بوده است. این فاز با استفاده از یک worker (max_workers=1) اجرا شده تا تداخل کاهش یابد.
تحلیل مصرف منابع:
استفاده از CPU: میانگین 64.8% و حداکثر 99.0% نشاندهنده بهرهبرداری بهینه از هر دو هسته است. حداکثر 99.0% نشان میدهد که در اوج بار، هر دو هسته کاملاً استفاده شدهاند، این افزایش از 39.8% به 64.8% نشاندهنده 62.6% بهبود در استفاده از CPU است.
استفاده از حافظه: میانگین 15.2% (حدود 1.93) و حداکثر 15.3% نشاندهنده افزایش اندک مصرف حافظه است، که به دلیل اجرای همزمان فرآیندها رخ داده. این مقدار هنوز در محدوده ایمن برای سیستم با 12.67 گیگابایت حافظه است و نشتی حافظه مشاهده نشده است.
چالشها و محدودیتها:
حداکثر استفاده از CPU (99.0%) ممکن است در سیستمهای با بار اضافی (مانند اجرای چند برنامه) به ناپایداری منجر شود.
افزایش اندک حافظه (15.2% در مقابل 13.7%) نشاندهنده نیاز به بهینهسازی بیشتر در مدیریت حافظه برای فرآیندهای موازی است.
از جستجوهای وب (مانند GeeksforGeeks)، پیشنهاد شده که استفاده از ThreadPoolExecutor به جای ProcessPoolExecutor برای کاهش Overhead حافظه میتواند کمک کند، اما این نسخه به دلیل استفاده از TensorFlow، از فرآیندها استفاده کرده است.
تحلیل جامع:
با توجه به تصویر ۶ داریم:
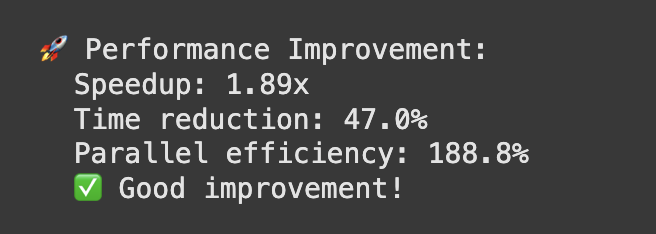
نسخه موازی به طور قابلتوجهی به مقدار ۱.۸۹ برابر سریعتر است و ۴۷درصد زودتر اجرا میشود و از منابع بهتر استفاده میکند، اما افزایش حافظه و فشار روی CPU باید مدیریت شود.
از جستجوهای وب، پیشنهاد شده که برای سیستمهای 2 هستهای، موازیسازی با بیش از 2 worker ممکن است معکوس عمل کند، که در اینجا با max_workers=2 رعایت شده است.
نتیجهگیری و کارهای آینده
نتایج این پروژه نشاندهنده موفقیت روش پیشنهادی در بهبود عملکرد الگوریتم MAHE-IM است. نسخه موازی با کاهش 47% زمان اجرا، افزایش 62.6% استفاده از CPU، و حفظ دقت انتخاب بذر، یک پیشرفت قابلتوجه است. مانیتورینگ منابع امکان تحلیل دقیق را فراهم کرده و نشان داده که سیستم با 2 هسته و 12.67 گیگابایت حافظه، ظرفیت بیشتری برای موازیسازی دارد. با این حال، کارایی موازی 188.8% نیاز به بررسی بیشتر دارد، و افزایش اندک حافظه (15.2%) نشاندهنده نیاز به بهینهسازی است.
کارهای آینده:
افزایش هستهها: تست روی سیستمهای 4 یا 8 هستهای برای بررسی scalability.
بهینهسازی حافظه: استفاده از ThreadPoolExecutor یا فشردهسازی دادهها.
GPU: تست با GPU برای کاهش بیشتر زمان
مقایسه گسترده: ارزیابی با دادههای بزرگتر مانند کل DBLP یا Twitter .
این مطلب، بخشی از تمرینهای درس معماری نرمافزار در دانشگاه شهیدبهشتی است
منابع
مقاله Mahe_im در سال ۲۰۲۲، مقاله Asynchronous distributed-memory parallel algorithms for influence maximization در سال 2018، مقاله Fast and space-efficient parallel algorithms for influence maximization در سال ۲۰۱۹، مقاله HBMax: Optimizing memory efficiency for parallel influence maximization on multicore architectures در سال ۲۰۱۷، مقاله Parallel greedy algorithm to multiple influence maximization in social network در سال ۲۰۱۸