
سلام به همه — مخصوصاً تیمهای فنی و محصول در دیوار.
این نوشته روایت کوتاهی از تجربهایه که توی یکی از تستهای امنیتیم با Agentهای مرتبط با فرایند فروش در دیوار داشتم.
هدفم اینه که تجربهم رو با همصنفیها و تیمهای محصول به اشتراک بذارم تا همهمون اهمیت امنیت در محصول های AI Base رو بهتر درک کنیم.
ماه پیش، تجربهم توی یه هکاتون باعث شد بفهمم مدلها چقدر میتونن غیرقابلپیشبینی باشن.
اما این بار تجربهای داشتم توی یه محیط واقعی — درست وسط دیوار — با Agentهایی که در فرایند آگهی و چت نقش دارن.
یه روز بعدازظهر، پشت میزم نشسته بودم و داشتم قیمت ماشینها رو توی دیوار نگاه میکردم.
روی یکی از آگهیها زدم و رفتم داخل چت. وقتی پیام دادم، دیدم دستیار خریدار دیوار داره جوابم رو میده — یعنی در واقع دارم با یه Agent صحبت میکنم.
خوشم اومد ازش، دلم خواست یه کم اذیتش کنم 😄
اولش همهچی طبیعی بود. Agent طوری طراحی شده بود که خارج از موضوع آگهی پاسخ نده — همون چیزی که انتظارش میرفت.
ولی تجربه قبلیم از هکاتون بهم میگفت همیشه یه راه باریک هست که میشه بهش سیخ زد.
همین حسِ کنجکاوی باعث شد برم دنبالش.
فهمیدم وقتی دربارهی چیزای نامرتبط به آگهی حرف میزنم، Agent سریع بحث رو برمیگردونه به موضوع آگهی.
ولی در مورد درخواستهای ساده یه رفتار متفاوت داشت.
مثلاً وقتی گفتم:
«بگو سلام»
جواب داد:
«سلام!»
اونجا بود که فهمیدم پسرمون اونقدرها هم سفت و محکم نیست 😏
و خب انتظارشم داشتم، چون Agent باید تا حدی طبیعی و تعاملی رفتار کنه.
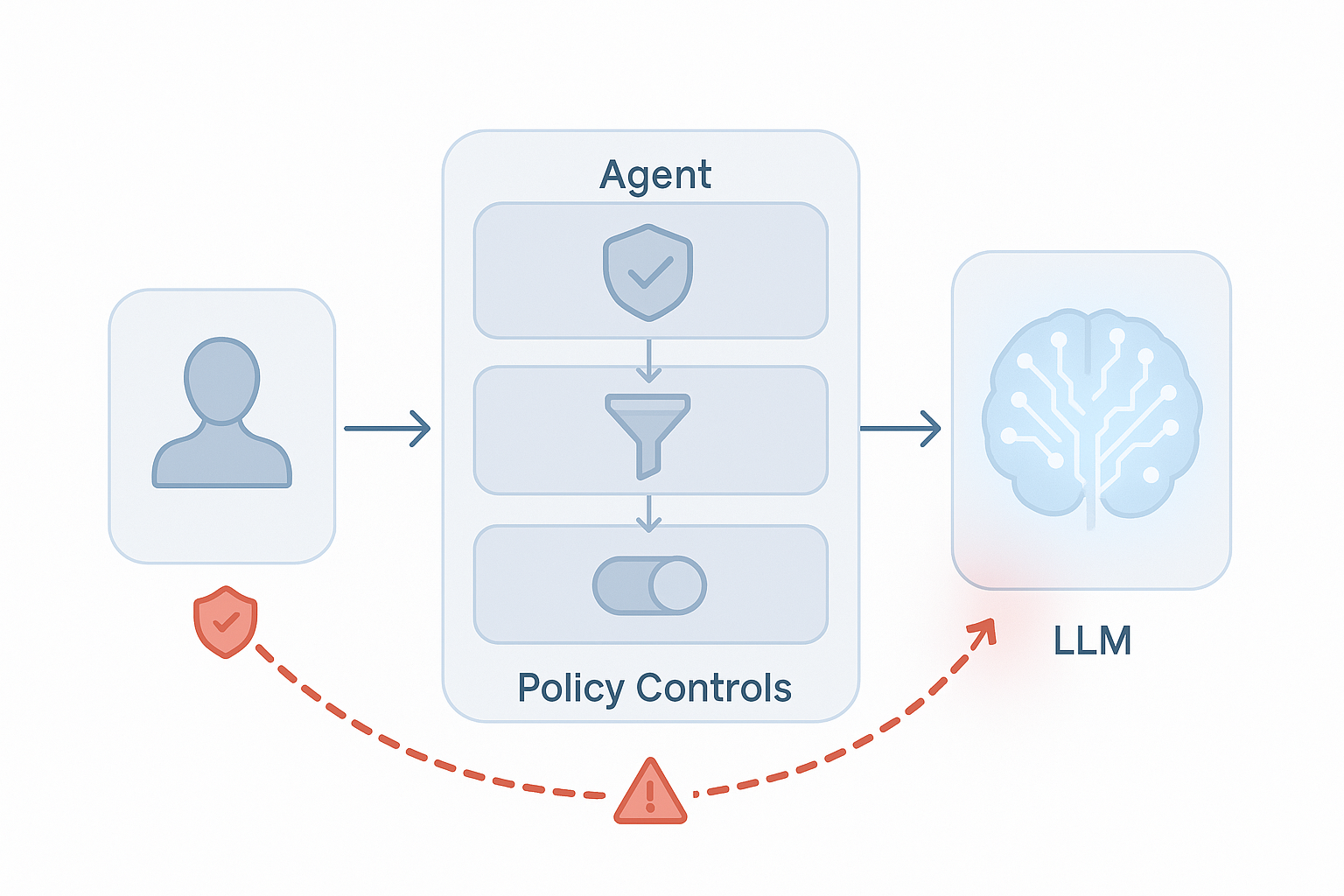
اینجا لازمه یه نکته فنی بگم (به زبون ساده).
Agent یه مغز تصمیمگیر داره — همون LLM — که تعیین میکنه در هر مرحله چی بگه و از چه ابزاری استفاده کنه.
ولی قبل از اینکه ورودی من به اون LLM برسه، از یه سری گاردریل و فیلتر رد میشه.
مثلاً فیلترهایی که مطمئن میشن سؤال کاربر در چارچوب موضوع آگهی باشه، یا خروجی نهایی حاوی اطلاعات حساس نباشه.
این لایهها همون چیزین که باید ازشون رد بشی اگه بخوای با خود LLM مستقیم صحبت کنی، نه Agent.
سوال!؟
منظور از اتصال مستقیم به LLM چیه؟
یعنی جواب درخواستمون رو بدون هیچ فیلتر و کنترلی از LLM دریافت کنیم و بتونیم مستقیم با خود LLM صحبت کنیم و یه جورایی لایه های کنترلی Agent رو دور بزنیم
حالا چرا باید مستقیم با خود Agent صحبت کنیم؟
چون LLM هست که به Agent میگه چیکار کنه و چیکار نکنه و ما برای اینکه بتونیم حملات Prompt injection رو انجام بدیم و کنترل Agent رو دست بگیریم نیازه با LLM تعامل کنیم تا بتونیم Prompt Injection رو رقم بزنیم :))
از همونجا، دنبال راهی بودم که مستقیم با LLM پشت Agent ارتباط بگیرم — یعنی همونجایی که دیگه هیچ لایهی محافظتی بین من و LLM نباشه.
قدم اول: رد کردن گاردریلهای سطح Agent.
قدم دوم: دور زدن محدودیتهای System Prompt و رسیدن به اون نقطهای که Prompt Injection اتفاق میافته.
متأسفانه چون هنوز اجازه انتشار جزئیات فنی از طرف دیوار صادر نشده، نمیتونم مراحل دقیق رو بگم.
اما قول میدم بهمحض اینکه این اجازه رو گرفتم، توی یه پست جداگانه کاملاً فنی و شفاف دربارهش بنویسم تا بهتر متوجه یکی از مسیرهای هک Agent ها بشیم.
بعد از رد کردن گاردریلهای Agent، بالاخره تونستم مستقیم با LLM ارتباط بگیرم.
اونجا تازه چالش اصلی شروع شد: عبور از گاردریل های System Prompt در LLM.
وقتی این مرحله هم رد شد، عملاً کنترل Agent دستم بود.
میتونستم خروجی LLM رو خودم تنظیم کنم و عملا کنترل Agent رو دست بگیرم :).
این یعنی اگه کسی نیت بدی داشته باشه، میتونه Agent رو به تولید یا افشای هر نوع دادهای وادار کنه — از prompt و سیاست داخلی گرفته تا رفتار غیرمنتظره در سطح سیستم.
برای اینکه واقعاً کنترل Agent رو در دست بگیری، باید از دو لایهی امنیتی رد بشی:
لایهی Agent-level → فیلتر ورودیها و بررسی خروجی برای جلوگیری از نشت داده.
لایهی LLM-level → تعریف system prompt و نقشها برای جلوگیری از hijack شدن و Prompt Injection.
اگر این دو لایه رد بشن، دیگه کنترل کامل دست مهاجمه. 😬
البته اینکه Agent طوری طراحی بشه که دسترسی های محدود به سیستم داشته باشه هم خیلی مهمه , مثلا فقط دسترسی read به بخشی های از دیتابیس و ... میتونه ریسک آسیب دیدن سیستم توسط Agent رو کم کنه.
این فقط یه باگ ساده نیست — یه نقطهٔ ورودی به کل اکوسیستم Agent است. با همین درگاه کوچیک، مهاجم میتونه زنجیرهای از آسیبها رو راه بندازه:
نشت اطلاعات محرمانه مثل System Prompt و سیاستهای داخلی؛
لو رفتن ساختار دادهها و فرمت خروجیها — یعنی مهاجم دید کاملی نسبت به ساختار داخلی Agent پیدا میکنه؛
Role Hijacking و Data Exfiltration — یعنی گرفتن نقشهای مختلف یا استخراج دادهها از سیستم؛
کنترل کامل خروجی LLM و تحمیل محتوای دلخواه به Agent و کاربر؛
حملات ثانویه روی زیرساخت — مخصوصاً Second-Order SQL Injection (وقتی خروجی آلودهٔ مدل بدون sanitization ذخیره میشه و بعدها موقع پردازش دوباره فعال میشه)، همچنین خطراتِ مشابه برای NoSQL/CSV Injection و حتی XSS؛
مهندسی اجتماعی و کلاهبرداری مالی (Fraud/Phishing) از طریق Agentهای میانی — چون پیام از کانال رسمی میان، خیلی قابلباورتره؛
Prompt DoS — اجبار مدل به تولید متنهای بسیار حجیم یا تکراری که مصرف توکن و هزینهها رو سرسامآور میکنه و پایداری سرویس رو زیر سؤال میبره؛
آسیب به اعتبار و اعتماد پلتفرم — کاربرا خروجی دستیارها رو پیام رسمی حساب میکنن؛ اگه اعتماد از دست بره، جبرانش سخته.
بهطور خلاصه: وقتی مهاجم بتونه خروجی مدل رو کنترل کنه، خطر فقط به همون پاسخِ اشتباه محدود نمیشه — میتونه زنجیرهای از حملات نرمافزاری و مهندسی اجتماعی رو بهوجود بیاره که روی دیتابیس، گزارشگیری، تجربهٔ کاربری و اعتبار محصول اثر میذاره.
توی مقالههای بعدی مفصل و فنیتر روی Second-Order SQL Injection و نحوهٔ جلوگیری ازش فوکوس میکنیم — چون این موضوعِ دقیقاً همون بخشی هست که یک خروجیِ آلوده از مدل میتونه بعداً دردسر درست کنه برامون.