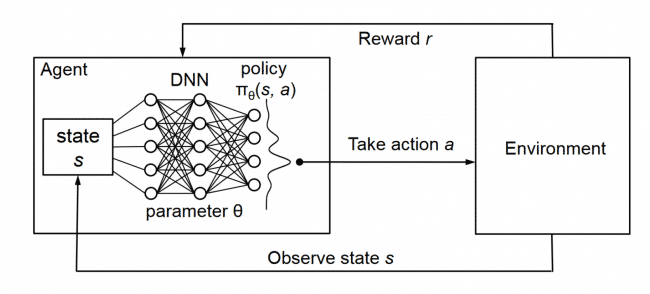
من دانشجوی ارشد هوش مصنوعی هستم و میخام مرحله به مرحله از پیاده سازی پروژه یکی از درس هام با عنوان یادگیری تقویتی رو به همراه کد و تمام جزییاتش براتون بنویسم. اینجا یک مدل ساده میسازیم که تنها ورودیش اطلاعات صفحه بازی یعنی داده های پیکسلی هستش و میتونه بر اساس اون مدلی رو یاد بگیره و بر اساس اون بازی کنه. این کار در واقع پیاده سازی یکی از مقالات گروه دیپ مایند هستش که اگه تو کار هوش مصنوعی باشین حتما میشناسینش. عنوان مقاله مربوطه هست: “Playing Atari with Deep Reinforcement Learning” که به فارسی میشه آتاری بازی با استفاده از یادگیری تقویتی عمیق :)
اصولا چیزی که در کلاس های یادگیری تقویتی مخصوصا در بحث های ابتداییش ارایه میشه مربوط به مدل هایی هستن که مثلا با value iteration یا policy iteration سعی میکنن یک تابع هزینه بسازن و عامل بتونه بار اساس اون در محیط رفتار کنه. این مدل ها در دنیای واقعی ارزشی ندارن حقیقت !!!
مدل هایی که میان یک تابع ارزش مشخص رو یاد میگیرن در واقع میتونن هدفشون اینه در هر حالتی که قرار میگیرین بهتون بگن چه ارزشی رو میگیرین ولی مشکل از جایی شروع میشه که محیط ما لزوما تعداد محدودی حالت نداشته باشه مثل یک بازی که میتونه بر اساس رفتار کاربر میلیون ها حالت مختلف داشته باشه. اینجاست که لازم میشه کلا نوع نگاهمون رو عوض کنیم و بیایم به جای بدست آوردن مقادیر دقیق بریم سراغ function approximation یا تابع تقریب و مفاهیمی مثل شیب خط مشی یا policy gradient.
الگوریتم و متدی که در این مقاله استفاده شده ویژگی هایی داره که قابل توجهه.
نکته اول اینه که این کار اولین مدل یادگیری عمیق هستش که تونسته در یادگیری control policy با استفاده از داده های سنسور با ابعاد بالا خوب عمل کنه. یعنی مثلا نیومدیم داده هارو دسته بندی شده و تگ دار بهش بدیم که مثلا فلان چیزی که در صفحه بازیه، چیه و چه اکشن هایی داره و ... و به بیان علمی ویژگی یا feature های دستی یا hand crafted بهش ندادیم. فقط ی صفحه بازی دادیم و بقیه چیزارو باید خودش یاد بگیره. دادن صفحه بازی هم به این معناس که مقادیر پیکسل به پیکسل رو به الگوریتم دادیم.
به صورت خیلی کلی مدل ما شامل یک CNN میشه که به همراه یک مدلی تو مایه های رویکردی که Q learning داره train شده و داده های پیکسلی رو میگیره و خروجی ی value function میده که پاداش های آینده رو تقریب بزنه.

این مدل رو هفت تا بازی Atari 2600 از محیط یادگیری Arcade امتحان شده و تونسته در 6تا از بازی ها از تمامی مدل های قبلی (به زمان چاپ مقاله توجه کنید) بهتر عمل کنه و در سه تا از بازی ها تونسته از شما (هوش انسانی) بهتر بازی کنه ! :)

یکی از ویژگی های مهم پیاده سازی این پروژه که قراره در موردش بحث کنیم اینه که از فریمورک های دیپ استفاده نکرده و به صورت تقریبا pure python پیاده شده با کتابخانه هایی مثل نامپای. تنها ایمپورت مهم این کد Gym هستش که از باز اگه یادگیری تقویتی باز! باشین باید حتما بشناسینش. این RL benchmarking toolkit که از پروژه های OpenAI هستش به شما کمک میکنه که درگیر پیاده سازی محیط و عامل و ... نشین و بتونین روی الگوریتم یادگیری که میخاین پیاده کنین تمرکز کنین.
چالش اول اینه که الگوریتم های عمیق داده زیادی احتیاج دارن ولی چیزی که در یادگیری تقویتی داریم ی سیگنال پاداش هستش که عموما اسپارس، نویزی و با تاخیر یا delayed هستش. تاخیر بین عمل و پاداش میتونه تا هزاران استپ زمانی باشه.
چالش دیگه اینه که در الگوریتم های عمیق عموما این فرض رو دارند که داده مستقل هستند ولی در RL وجود دنباله های حالت که highly correlated هستن اجتناب ناپذیره.
و اما از همه مهم تر اینکه در RL ، توزیع داده میتونه در زمانی که الگوریتم در حال یادگیری هست تغییر کنه که میتونه برای الگوریتم های عمیق که فرضشون ثابت بودن distribution هست مشکل ساز باشه.
پیشنهاد مقاله استفاده از CNN هستش که میتونه با یکی از variant های Q-learning یادگیری رو انجام بده و برای به روز رسانی وزن های شبکه عصبی هم از Stochastic Gradient descent استفاده کنه. و برای غلبه به چالش های non-stationary distribution و correlated data هم یک مکانیزمی رو پیشنهاد دادن به اسم experience relay که به صورت رندم داده های قبلی رو دوباره به شبکه میده و کمک میکنه به smooth شدن توزیع بر روی رفتار های گذشته.
این نکته هم درمورد پیاده سازی حایز اهمیته که ما سعی میکنیم که تا حد ممکن فرضیات بازی پونگ رو در پیاده سازی در نظر نگیریم چرا که به دنبال این هستیم که مدلی بسازیم که بتونه کلا بازی رو با ورودی پیکسل انجام بده و بازی پونگ در حقیقت اهمیتی برامون نداره . در واقع این مدل یک رویکردی به سمت AGI یا Artificial General Intelligence داره که هدفش اینه که مدلی بسازه که نه فقط در یک بازی و مسیله خوب عمل میکنه بلکه به صورت عمومی بلده بازی های مختلف رو یاد بگیره! (ترمیناتور نشه صلوات)

این شبکه در واقع نقش عامل ما رو بازی خواهد کرد. این شبکه قراره حالت یا state بازی رو بگیره و به ما بگه که بریم بالا یا پایین. رویکرد ما برای پیاده سازی این شبکه این خواهد بود که یک شبکه دو لایه میسازیم مثل تصویر زیر که تصویر رو میگیره به صورت خام (210*160*3) و احتمال حرکت بالا رو بهمون میده. لازم به ذکره که در اینجا باید از stochastic policy استفاده کنیم به این معنا که با یک احتمالی فلان عمل یا action رو انجام بدیم که دلیلش رو در قسمت یادگیری مدل بیشتر باز میکنیم.
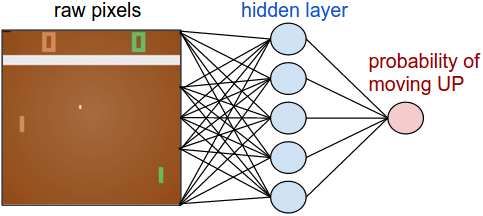
برای شفاف تر شدن شبکه خط مشی میتونین روش پیاده سازیش رو در کد زیر با numpy/python ببینین. در این کد وکتور X رو به عنوان داده ورودی پیکسلی در نظر بگیرین:
h = np.dot(W1, x) # compute hidden layer neuron activations h[h<0] = 0 # ReLU non linearity: threshold at zero logp = np.dot(W2, h) # compute log probability of going up p = 1.0 / (1.0 + np.exp(-logp)) # sigmoid function (gives probability of going up)`
در این کد W1 و W2 دو وکتور هستند که به صورت رندم ساخته ایم و در خط آخر هم از سیگموید غیرخطی استفاده کردیم که مقادیر خروجی احتمال رو تو بازه [0,1] قرار میده. کاری که در لایه پنهان یا hidden layer این شبکه انجام میدیم اینه که میتونیم سناریو های مختلف بازی رو شناسایی کنیم مثل اینکه آیا توپ بالاس و پد ما در وسط قرار گرفته. وزن های مربوط به وکتور W2 هم میتونن به ما بگن که در هر حالت بوجود اومده آیا پد رو ببریم بالا یا پایین. ولی خب با توجه به اینکه مقادیر این دو وکتور رو ابتدا رندم قرار دادیم پس زیاد خوب بازی نخواهد کرد و کاری که ما باید انجام بدیم اینه که این مقادیر وزن ها رو به شکلی تنظیم کنیم که عامل ما بتونه مثل ی حرفه ای بازی کنه!
نکته: برای اینکه شبکه ما بتونه تغییرات و تحرک رو در بازی تشخیص بده ایده آله که دو تا فریم از بازی رو به شبکه بدیم ولی برای ساده سازی ی مقداری پیش پردازش انجام میدیم تا بتونیم تفاوت بین فریم های بازی رو به شبکه بدیم که میتونه خیلی ساده با تفریق کردن دو تا فریم به دست بیاد.
اینجا خوبه که یکم در مورد سختی و رویکرد به نظر غیرممکنی که بازی کردن و حل این مسیله با RL میتونه داشته باشه بحث کنیم. در واقع اگه یک نگاه سطح بالا بخایم داشته باشیم به این شکله که 100800 تا عدد رو می گیریم و forward میدیم به شبکه خط مشی که خودش در حد میلیونی پارامتر داره در W1 و W2. حالا فرض کنیم که این شبکه بگه ما ما پد رو ببریم بالا. در این حالت ممکنه پاداشی که از بازی بگیریم صفر باشه در این مرحله و دوباره بهمون 100800 تا عدد مربوط به فریم بعدی رو بگیریم و این روند ممکنه تا 100 بار تکرار بشه تا بتونیم یک مقدار غیرصفر بگیریم. حالم گیرم که پاداش غیرصفر بگیریم،خیلی هم عالی ولی چطور می تونیم بفهمیم این پاداش برای کدوم رفتارمون بوده؟ آیا مربوط به کاری بوده که همین اخیرا انجام دادیم؟ یا کاری که 76 قدم قبل انجام دادیم؟ یا به خاطر دو تا از کار هایی که در قدم 10 و 90 داشتیم؟ و حالا کدوم یکی از اتصالات و مقادیر شبکه رو تغییر بدیم که در آینده بهتر عمل کنیم؟
این در واقع یکی از مشکلات مطرح در این حوزه به اسم Credit assignment problem هستش. در همین مثال بازی پونگ اگه بخایم در نظر بگیریم، ما میدونیم که زمانی پاداش +1 میگیریم که حریف نتونه توپ رو با پدش برگردونه و ازش رد بشه. دلیل اصلی این اتفاق اینه که ما توپ رو در جهتی فرستادیم که حریف نتونسته توپ رو برگردونه و این اتفاق برمیگرده شاید به چیزی حدود بیست فریم قبل از گرفتن پاداش و سایر حرکت هامون بعد از اون وارد کردن ضربه دیگه تاثیری در در پاداشی که گرفتیم نداشته. این نشون میده که با مسیله پیچیده ای طرف هستیم که به نظر غیرقابل حل به نظر میرسه!
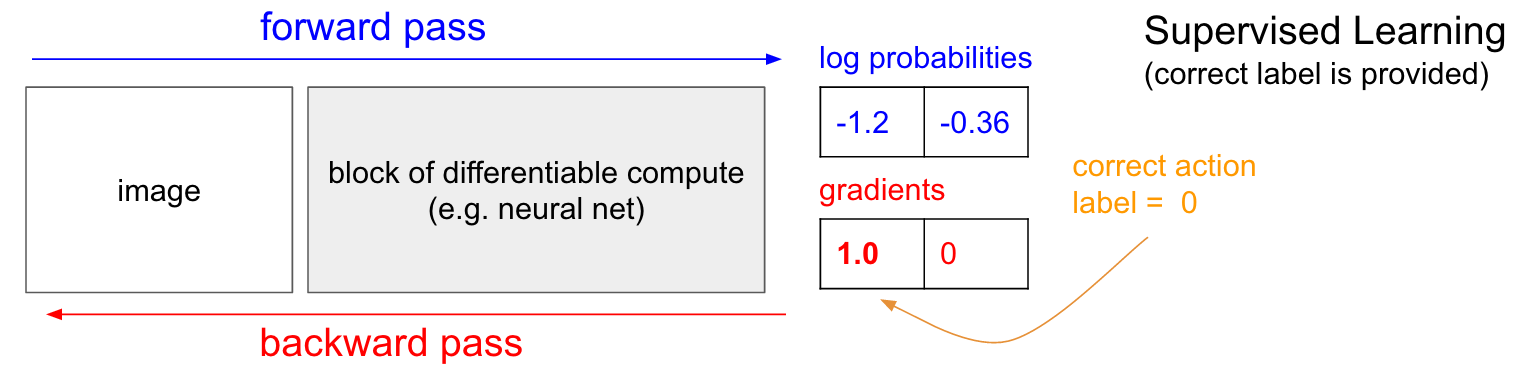
قبل از اینکه وارد رویکرد اصلی حل مسیله که استفاده از گرادیان خط مشی یا policy gradient هست بشیم خوبه کمی در مورد یادگیری نظارتی بحث کنیم و یکم با یادگیری تقویتی مقایسش کنیم چرا که معتقدم بسیار به هم شباهت دارن. خوبه که ی نیم نگاهی هم به دیاگرام زیر داشته باشین که احتمالا کمک کننده باشه. در یادگیری نظارتی به سیستم یک عکس میدیم و ازش ی سری احتمالات میگیریم که مثلا در اینجا میتونه مربوط به دو تا کلاس بالا وپایین باشه برای تعیین وضعیت پد. حالا چیزی که در دیاگرام زیر آوردم مقدار لگاریتم احتمالات هستش که شده (0.36- , 1.2-) و به جای مقادیر 70 و 30 که خروجی های احتمال رخداد بالا و پایین بودن این مقادیر رو میخایم بهینه کنیم (و دلیل این لاگ گرفتن اینه که هم از نظر ریاضیاتی کار رو راحت میکنه برای ما به خاطر ویژگی هایی که لگاریتم داره و دوما اینکه تاثیری در خروجی هم نمیزاره چرا که لگاریتم ی تابع مونوتونیکه یعنی با لاگ گرفتن از یک تابع مقادیرش به یک میزان اسکیل میشن و تابع به هم نمیریزه ). حالا اتفاقی که در یادگیری نظارتی میوفته اینه که ما به label یا برچسب ها دسترسی داریم. داشتن برچسب ها به این معناس که مثلا ما میدونیم در این مرحله کار درست اینه که پد رو ببریم بالا (برچسب صفر). در پیاده سازی کاری که میکنیم اینه که گرادیان 1.0 رو به مقدار لاگ احتمال بالا اضافه میکنیم و back propagation رو انجام میدیم تا وکتور gradient یا شیب w logp ( y = UP ∣ x )∇ رو محاسبه کنیم. خروجی این شیب به ما می گوید که پارامتر هایمان را تعداد میلیونی دارند رو چگونه باید به روز رسانی کنیم تا شبکه کمی دفعه بعد بتونه با احتمال بیشتری (more likely) بالا رو پیش بینی کنه. به عنوان مثال یکی از پارامتر های شبکه اگر مقدار گرادیانت منفی 1.2 داشته باشه به این معناست که اگر مقدار پارامتر را به اندازه بسیار کوچک مثبتی افزایش بدیم در حد 0.0001 ، در نتیجه مقدار لاگ احتمال به میزان 2.1 * 0.0001 کاهش خواهد یافت چرا که علامت منفی داره. حالا اگر براین اساس پارامتر ها را به روز رسانی کنیم ، به هدفمون رسیدیم و شبکه کمی بهتر آموزش دیده، به این معنا که اگه یک تصویر شبیه عکسی که بهش نشون دادیم رو بهش نشون بدیم با احتمال بیشتری خروجی بالا رو خواهد داد :)
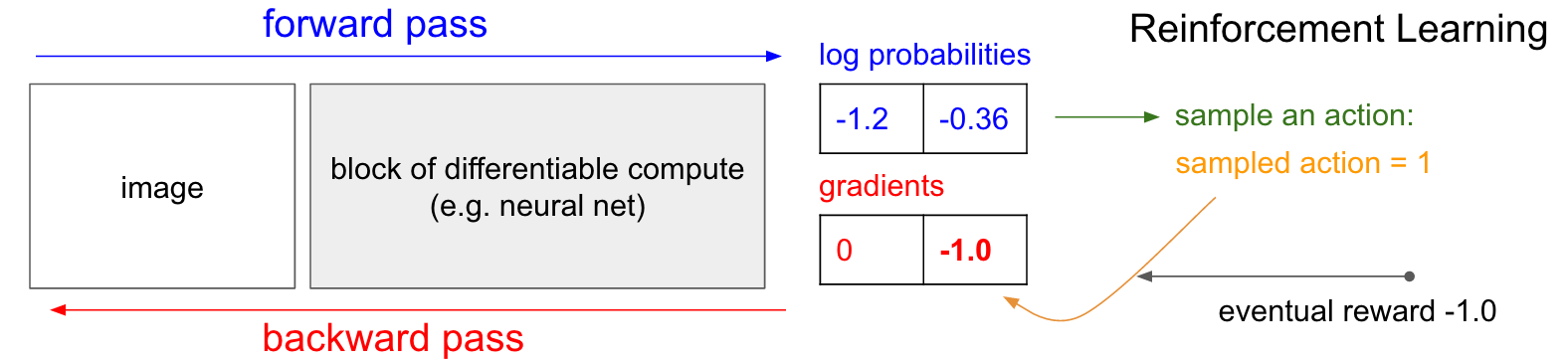
خب حالا میخایم بررسی کنیم که در دنیای یادگیری تقویتی که برچسب رو نداریم باید چه کنیم؟ اینجا میخایم رویکردی به اسم policy gradient یا شیب خط مشی رو برسی کنیم که باز دیاگرام زیر در درک این مسیله کمک کنندست حتما ی نگاهی بهش بکنین. شبکه خط مشی ما برای بالا احتمال 30 درصد که لاگش میشه منفی 1.2 رو داد و برای پایین احتمال 70 درصد که لاگش میشه منفی 0.36 . حالا از این توزیع احتمال مقداری را نمونه برداری میکنیم که دراینجا فرض کنید پایین میشه نتیجه نمونه برداری و این تصمیم رو در بازی اعمال میکنیم. نکته ای که اینجا باید بهش توجه کنیم اینه که ما دراینجا میتونیم مقدار شیب 1.0 رو در شبکه اعمال کنیم مثل کاری که در یادگیری نظارتی کردیم و شبکه رو به شکلی تغییر بدیم که دفعه بعد هم با دیدن تصویری مشابه با کمی احتمال بیشتر همین تصمیم رو بهمون توصیه کنه ولی مشکل اینه که ما نمی دونیم آیا این تصمیم درسته یا نه! یعنی هنوز نمی دونیم، چرا که هنوز مشخص نیست نتیجه بازی چیه. ولی دقیقا نکته مهم همینجاست که مشکلی هم نداره که ندونیم، چرا که می تونیم صبر کنیم تا زمانی که بازی به نتیجه برسه و با توجه به اون پارامتر ها رو به روز رسانی کنیم. مثلا در اینجا نتیجه بازی شکست بوده که پاداش منفی یک گرفتیم. پس اگر مقدار منفی یک را به لاگ احتمال اضافه کنیم و در شبکه back propagate کنیم خواهیم دید که مقدار شیبی خواهیم داشت که با گرفتن تصویری مشابه با احتمال کمتری نسبت به قبل پایین رو به ما پیشنهاد خواهد داد چرا که همونطور که دیدیم نیجه بازی شد شکست و این چیزی نیست که ما میخواهیم.
به همین سادگی! ی خط مشی تصادفی یا stochastic policy داریم که تصمیمات یا action هایی رو نمونه برداری میکنه و تصمیماتی رو که به نتایج خوب منتهی میشن رو تشویق میکنه و تصمیماتی که به شکست میرسه رو تنبیه! جالبی قضیه اینه که لزوما نباید مقادیر منفی یا مثبت یک رو به عنوان پاداش بدیم بلکه میتونیم مثلا زمانی که اتفاق خاصی افتاده که خیلی وفق مرادمونه مثلا پاداش مثبت 10 بدیم و همچنان داستان به خوبی کار میکنه و این است زیبایی شبکه های عصبی که فکر میکنی نتیجه چیز شر محضه ولی خوشبختانه در جهانی که ما زندگی میکنیم اینجوری نیست و چه بسا به خوبی با ما رقابت میکنه :)
به علت طولانی شدن تصمیم گرفتم چند قسمتی کنم، قول میدم که آب نبندم بهش :)
http://karpathy.github.io/2016/05/31/rl/ Andrej Karpathy blog is main source <3
Mnih, V., Kavukcuoglu, K., Silver, D., Graves, A., Antonoglou, I., Wierstra, D. and Riedmiller, M., 2013. Playing atari with deep reinforcement learning. arXiv preprint arXiv:1312.5602.