سال 2026 با یک تغییر بنیادین در مهندسی نرمافزار آغاز میشود: در عصر هوشواره، توان تولید کد دیگر کمیابترین منبع نیست. تا چند سال پیش، بخش بزرگی از سختی کار مهندس نرمافزار در این بود که زبان ماشین را به اندازه کافی خوب بلد باشد، سینتکس را درست بنویسد، کتابخانهها را بشناسد، خطاهای عجیب زماناجرا را دیباگ کند و در نهایت سیستم را با دست خود بسازد. اما امروز عوامل هوشمند میتوانند بخشهای بزرگی از این کار مکانیکی را انجام دهند. آنها میتوانند فایل بسازند، کامپوننت تولید کنند، API endpoint بنویسند، تست اضافه کنند، مهاجرت بسازند و حتی یک برنامه کامل را با چند جمله توضیح اولیه بالا بیاورند.
اما همین قدرت، مسئلهی تازهای ایجاد میکند. اگر تولید کد بسیار سریع و ارزان شود، خطر تولید خطا هم بسیار سریع و ارزان میشود. ما وارد دورهای شدهایم که در آن هوشواره میتواند به جای یک تکمیلخودکار ساده، به یک موتور پیادهسازی با توان عملیاتی بالا تبدیل شود. این موتور میتواند هزاران خط کد تولید کند، اما اگر جهتدهی صحیح، محدودیت، نیت و تاییدیه نهایی نداشته باشد، خروجی آن الزاماً مهندسیشده نیست. ممکن است فقط مقدار زیادی کد تولید کند که ظاهراً کار میکند، اما در لایههای قواعد کسب و کار، امنیت، معماری، نگهداری و انطباق با نیازمندی دچار مشکل است.
اینجاست که ما میان دو جهان تمایز میگذاریم: جهان اول را وایبکدینگ و دنیای دوم را توسعهی مبتنی بر مشخصات (spec-driven development ) مینامیم. وایبکدینگ جذاب، سریع، خلاقانه و برای شروع ایدهها بسیار مؤثر است. اما برای ساخت سیستمهای واقعی، قابل نگهداری و حیاتی کافی نیست. توسعهی مبتنی بر مشخصات یا SDD پاسخی است به این پرسش: وقتی هوشواره قدرت زیادی برای تولید کد دارد، انسانها چگونه باید هدف و نیت دقیق خود را تعریف کنند، ابهام را کنترل کنند، معماری را حفظ کنند، و خروجی را قابل راستیآزمایی کنند؟
پیام اصلی این نوشته این است که گلوگاه مهندسی نرمافزار در حال جابهجایی است. قبلاً گلوگاه اصلی پیادهسازی و کد نویسی بود؛ یعنی اینکه چقدر سریع میتوانیم کد بزنیم، دیباگ کنیم و سیستم را بسازیم. اما با هوشواره، گلوگاه جدید بیان نیت است؛ یعنی اینکه چقدر دقیق، بیابهام، قابل تست و قابل اجرا میتوانیم بگوییم چه میخواهیم. آینده مهندسی نرمافزار فقط به کسانی تعلق ندارد که سریعتر کد میزنند، بلکه به کسانی تعلق دارد که دقیقتر فکر میکنند، بهتر مشخصات (specification) مینویسند و بهتر روالهای تاییدیه دادن را طراحی میکنند.
این روزها اصطلاح وایبکدینگ به عنوان یک سبک بداههمحور در استفاده از هوشواره معرفی میشود. در این سبک، توسعهدهنده به جای اینکه ابتدا ویژگیهای دقیق، طرح یا طراحی معماری بنویسد، مستقیماً با هوشواره وارد گفتگو میشود. توسعهدهنده یک هدف کلی میگوید، مثل “یک snake game بساز”، “یک داشبور بساز”، “login page اضافه کن” یا “بازنشانی کلمه عبور flow پیاده کن”. سپس هوشواره حجم زیادی کد تولید میکند. توسعهدهنده آن را اجرا میکند، اگر خروجی ظاهراً درست بود، به پرامپت بعدی میرود؛ اگر نبود، دوباره پرامپت میدهد: “رنگش را عوض کن”، “این bug را درست کن”، “یک دکمه دیگر اضافه کن”، “این بخش را responsive کن”.
نکته مهم این است که وایبکدینگ صرفاً به معنی استفاده از هوشواره هنگام کدنویسی نیست. داشتن Copilot یا ChatGPT کنار کد ادیتور لزوماً وایبکدینگ نیست. وایبکدینگ یک فرایند کاری خاص است که در آن پرامپت عملاً جای مشخصات را میگیرد. یعنی پرامپت، همان چیزی میشود که سیستم باید بر اساس آن ساخته شود، بدون اینکه نیت به شکل پایدار، قابل بازبینی و قابل ردیابی ثبت شده باشد.
این سبک به شدت جذاب است، چون با شیوه طبیعی اکتشاف انسان هماهنگ است. وقتی پروژهای تازه شروع میشود، انسان معمولاً دقیق نمیداند چه میخواهد. میداند که مثلاً یک داشبورد لازم دارد، اما نمیداند نمودار میلهای بهتر است یا نمودار دایرهای. میداند ویژگی باید برای کاربر مفید باشد، اما جزئیات تعامل، edge caseها و وضعیتهای خطا هنوز روشن نیستند. هوشواره در این مرحله بسیار مفید است، چون میتواند صفحه خالی را از بین ببرد و در چند ثانیه چیزی قابل مشاهده تولید کند.
در اینجا ارزش وایبکدینگ واقعی است. ما آن را صرفاً رد نمیکنیم. برای هکاتون، اثبات مفهوم ، نمونهسازی اولیه، دمو سریع، آزمایش ایدهی محصول یا ساخت اسکریپتهای ساده، وایبکدینگ میتواند عالی باشد. وقتی سطح پروژه کوچک است و کل سیستم را میتوان در ذهن نگه داشت، ذهن انسان خودش محافظ هوشواره است. اگر برنامه دو فایل و چند صد خط کد دارد، توسعهدهنده میتواند با نگاه کلی بفهمد چه اتفاقی افتاده است.
اما مشکل از جایی شروع میشود که پروژه از سطح نمونهسازی اولیه عبور میکند. مثل دنیای واقعی یک اتاق کوچک وسط یک باغ را شاید بتوان بداهه ساخت، اما یک برج 100 طبقه را نه. یک بازی ساده را میتوان با حسن درونی ساخت، اما سیستم پرداخت، مدیریت کاربران، حقوق و دستمزد، سیستم سلامت یا سیستم مالی را نمیتوان با همان منطق ساخت. در سیستم واقعی، هر تصمیم کوچک ممکن است پیامد امنیتی، مالی، حقوقی، عملیاتی یا معماری داشته باشد.

چهار محدودیت ساختاری برای وایبکدینگ قابل بررسی است. این محدودیتها فقط ایرادهای اجرایی کوچک نیستند، بلکه نشان میدهند چرا این سبک در مقیاس واقعی شکست میخورد. این چهار محدودیت عبارتاند از مشکل فرضیات، پوسیدگی زمینه (context decay)، عدم تطابق معماری و مسئله پاسخگویی.
1. مشکل فرضیات:
اولین و شاید خطرناکترین مشکل وایبکدینگ این است که پرامپتها هرگز جامع نیستند. وقتی میگوییم «پرداخت را پردازش کن»، هنوز دهها پرسش بیپاسخ باقی مانده است. اگر پرداخت نهایی نشد، چه میشود؟ آیا تلاش مجدد داریم؟ چند بار؟ با چه فاصلهای؟ آیا خطا لاگ میشود؟ آیا رخدادی برای تیم کشف تقلب تولید میشود؟ آیا کاربر پیام خاصی میبیند؟ آیا پرداخت خودکار است؟ اگر گیتوی دیر پاسخ دهد چه اتفاقی میافتد؟
در فرایند بداههمحور، هوشواره معمولاً نمیایستد تا همه این سؤالها را بپرسد. هوشواره برای مفید بودن طراحی شده است، پس جاهای خالی را پر میکند. اما آنها را نه بر اساس قواعد کسب و کاری شرکت شما، بلکه بر اساس احتمال آماری، الگوهای دیدهشده و زمینهی محدود خودش پر میکند. نتیجه ممکن است ظاهراً منطقی باشد، اما با واقعیت سازمان، معماری، سیاست امنیتی یا قانون کسبوکار شما ناسازگار باشد.
مثال تلاش مجدد برای پرداخت بسیار روشن است. فرض کنید دو سرویس مختلف با هوشواره و در زمانهای متفاوت ساخته شوند. در سرویس اول، هوشواره تصمیم میگیرد پرداخت ناموفق را سه بار پشت سر هم تکرار کند. در سرویس دوم، هوشواره تصمیم میگیرد هر یک ساعت یک بار مجددا تلاش کند. هر دو سرویس جداگانه در تست ساده کار میکنند. هیچ خطایی را فوری نمیبینیم. اما در سطح سیستم، رفتار پرداخت ناهماهنگ است. ممکن است مشتریان چند بار هزینه پرداخت کنند، یا تلاش مجدد خیلی دیر انجام شود، یا مانیتورینگ رفتار متناقض ببیند.
این همان بی سر و صدا اشتباه بودن “quietly wrong” است. نرمافزار سقوط نمیکند. دمو را پاس میکند. اما از نظر قوانین واقعی غلط است. خطر چنین خطاهایی بیشتر از خطاهای آشکار است، چون دیر کشف میشوند و معمولاً در محیط عملیاتی، زیر فشار واقعی یا در رخدادها خود را نشان میدهند.
2. پوسیدگی زمینه:
مشکل دوم پوسیدگی زمینه است. امروز مدلهای زبانی پنجرههای زمینهی “پنجره زمینه” بزرگی دارند. برخی مدلها میتوانند صدها هزار یا حتی میلیونها توکن را در زمینه بگیرند. در نگاه اول ممکن است فکر کنیم مشکل زمینه حل شده است. اما تأکید میکنم که پنجرهی زمینهی نظری با توجه موثر یکی نیست.
وقتی پروژه بزرگ میشود، تصمیمات معماری، فایلها، تغییرات، وصلهها، پرامپتها و جزئیات زیادی روی هم انباشته میشوند. حتی اگر همه اینها در زمینه باشند، تضمینی نیست که مدل به اندازه کافی به تصمیمات بنیادین روز اول توجه کند. در روز سیام پروژه، هوشواره ممکن است خطای امروز را با توجه به زمینهی محلی حل کند، اما تصمیم معماری سه هفته قبل را عملاً نادیده بگیرد.
نتیجه، ترکیبی از تصمیمات محلی است. سیستم به مجموعهای از تصمیمات محلی تبدیل میشود که هر کدام در زمان خود منطقی بودهاند، اما در کل هماهنگ نیستند. هوشواره مسئلهای را که جلوی چشمش است بهینه میکند، نه کل سیستم را. این برای سیستمهای بلندمدت خطرناک است، چون انسجام معماری را از بین میبرد.
3. عدم تطابق معماری:
مشکل سوم عدم تطابق معماری است. هوشواره معمولاً تلاش میکند پرامپت فعلی را سریع حل کند. اگر بگوییم “جستجوی کاربر را اضافه کن”، ممکن است مستقیم در API handler از پایگاهداده پرسوجو کند، چون این سریعترین راه برای گرفتن خروجی درست است. اما اگر معماری پروژه میگوید تمام دسترسیها به پایگاه داده باید از طریق لایه داده انجام شود، این کار معماری را نقض میکند.
چنین نقضهایی در ابتدا کوچک به نظر میرسند. یک کوئری مستقیم در هندلر. یک کتابخانه جدید برای یک ویژگی کوچک. یک قاعدهی نامگذاری متفاوت. یک مدیریت خطای متفاوت. اما همین موارد در طول زمان بدهیهای فنی میسازند. معماری تمیز به آرامی تبدیل به اسپاگتی میشود. مشکل اینجاست که در وایبکدینگ، توسعهدهنده معمولاً کد را خط به خط نمیخواند؛ فقط اجرا میکند و میبیند تابع کار میکند. چون کار میکند، با بقیه کدها ترکیب میشود. اما معماری یک ترک دیگر برداشته است.
در مقیاس سازمانی، این مشکل بسیار جدی است. تیمها برای ثبات به قواعد معماری نیاز دارند. اگر هر ویژگی با الگوی متفاوتی ساخته شود، نگهداری سختتر، آموزش دادن کندتر، بازسازی پرریسکتر و تحلیل حادثه پیچیدهتر میشود.
4. مسئله پاسخگویی:
چهارمین مشکل مسئولیتپذیری و پاسخگویی است. در هر سیستم جدی، باید بتوانیم به پرسشهایی پاسخ دهیم: چرا سیستم این رفتار را دارد؟ چه کسی این تصمیم را تأیید کرده است؟ این نیازمندی از کجا آمده است؟ چرا timeout پنج ثانیه است نه سی ثانیه؟ چرا محدودیت بر اساس IP است نه کاربر؟ چرا پیام خطا عمومی است؟
در وایبکدینگ، پاسخ بسیاری از این پرسشها گم میشود. اگر کد در اثر چند پرامپت و چند وصله تولید شده باشد، سابقهای از نیت نداریم. حقیقت سیستم فقط «چیزی است که کد الان انجام میدهد». در حادثه یا کالبدشکافیهای بعدی، گفتن اینکه “چت بات این کار را کرد” پاسخ مهندسی قابل قبولی نیست.
پاسخگویی فقط مسئله مدیریتی نیست؛ مسئله معماری است. بدون ردیابی توانایی، نمیتوانیم بفهمیم رفتار سیستم از کدام نیازمندی آمده، کدام ریسک را پوشش میدهد و کدام محدودیت را حفظ میکند. این یعنی نگهداری تبدیل به مهندسی معکوس میشود.

فرض کنید ویژگی بازنشانی کلمه عبور را میخواهیم توسعه دهیم. در وایبکدینگ ممکن است توسعهدهنده به هوشواره بگوید: «یک جریان کاری برای بازنشانی کلمهعبور اضافه کن». هوشواره معمولاً یک صفحه ورود ایمیل میسازد، یک لینک بازنشانی ارسال میکند، و اجازه میدهد کاربر کلمهعبور جدید انتخاب کند. در دمو، همه چیز خوب به نظر میرسد. مدیر محصول خوشحال میشود، چون ویژگی کار میکند.
اما امنیت بازنشانی کلمهعبور در جزئیاتی است که معمولاً در پرامپت ساده گفته نمیشوند. آیا توکن یکبارمصرف است؟ آیا تاریخ انقضا دارد؟ چند دقیقه؟ آیا توکن رمزنگاری شده ذخیره میشود؟ آیا محدودیتی برای نرخ درخواست وجود دارد؟ آیا روالی برای تشخیص استفاده بد داریم؟ آیا لاگ کارها ثبت میشود؟ آیا لینک بازنشانی بعد از استفاده غیرفعال میشود؟ آیا کاربر میتواند چند توکن فعال همزمان داشته باشد؟ پیام خطا برای ایمیل ناموجود چیست؟
اگر پیام خطا بگوید “ایمیل یافت نشده”، مهاجم میتواند بفهمد کدام ایمیلها در سیستم ثبت شدهاند. این پیام خطا میتواند باعث account enumeration شود. شاید در دموی عادی مهم به نظر نرسد، اما در سیستم واقعی میتواند پایه حملات بعدی باشد. اگر زمان انقضای توکن تعریف نشده باشد، لینک بازنشانی ممکن است بیش از حد معتبر بماند. اگر محدودیت نرخ درخواست نداشته باشیم، مهاجم میتواند سیستم ایمیل را اسپم کند یا بینهایت ایمیل ارسال کند.
این مثال نشان میدهد که هوشواره معمولاً مسیر صحیح را خوب میسازد، اما سیستم واقعی فقط مسیر صحیح نیست. سیستم واقعی مسیر بحرانی، استفاده بد، محدودیت امنیتی، تطابق کامل با نیازمندی، لاگ، مشاهدهپذیری، قوانین عملیاتی سازی و ... دارد. اگر اینها در ویژگی نباشند، هوشواره ممکن است آنها را نادیده بگیرد یا با حدسهای نامطمئن پر کند.
در SDD، قبل از پیادهسازی، قوانین چنین ویژگیهایی باید ثبت شوند. مثلاً باید گفته شود توکن پس از پانزده دقیقه منقضی میشود، پاسخ برای ایمیلهای موجود و ناموجود عمومی و یکسان است، هر کاربر یا IP در بازه زمانی مشخص محدودیت درخواست دارد، همه درخواستها برای حسابرسی لاگ میشوند، و خطاهای داخلی به کاربر جزئیات نمیدهند. سپس وظایف از همین مشخصاتمشتق میشوند: شمای پایگاهداده تغییر کند، سرویس توکن ساخته شود، محدودیت تعداد درخواست اضافه شود، endpoint پیاده شود، تستهای امنیتی و حالتهای خاص نوشته شوند.
تفاوت SDD و وایبکدینگ در حجم مستندات نیست؛ در کاهش سکوت و ابهام است. هر چیزی که گفته نشده، برای هوشواره فضای حدس ایجاد میکند. SDD تلاش میکند سکوتهای خطرناک را به اظهارات صریح یا شفافسازیهای قابل پیگیری تبدیل کند.
توسعهی مبتنی بر مشخصات یا SDD به عنوان بازگشت به بروکراسی قدیمی نیست، بلکه یک لایه حاکمیتی برای عصر هوشواره است. در مدلهای قدیمی، مشخصات اغلب مستنداتی بود که برای روال اداری و باز کردن کارها از سر نوشته میشد و سپس کنار گذاشته میشد. اما در SDD، مشخصاتباید سیستم ثبت اصلی ویژگیها باشد. یعنی حقیقت رسمی رفتار سیستم در مشخصاتزندگی میکند، نه صرفاً در کد.
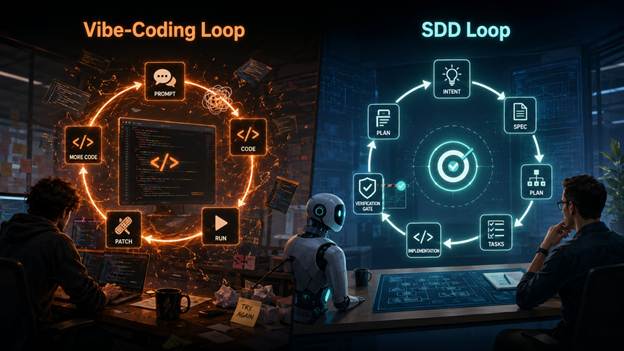
در وایبکدینگ، چرخه کاری معمولاً چنین است: پرامپت، کد، اجرا، اصلاح. انسان روی خروجی تکرار میکند. یعنی وقتی کد بد است، پرامپت جدید میدهد یا پچ میزند. اما در SDD، چرخه چنین است: نیت، spec، طرح، وظایف، پیادهسازی، تاییدیه. انسان روی نیت تمرکز میکند. یعنی ابتدا میپرسد دقیقاً چه میخواهیم، چه چیزی خارج از محدوده است، چه edge caseهایی وجود دارد، چه رفتارهای خطایی وجود دارد؟ چه قواعدی اصلا نباید نقض شوند.
این مدل به ظاهر چند مرحله بیشتر دارد، اما هدف آن کند کردن پروژه نیست. هدف این است که عدم قطعیت از انتهای فرایند به ابتدای فرایند منتقل شود. در وایبکدینگ، ابهام ابتدا پنهان میماند و بعد در محیط عملیاتی، بررسیهای امنیتی یا فرایندهای نگهداری آشکار میشود. در SDD، ابهام زود آشکار میشود و قبل از تولید کد در مقیاس بالا حل میشود.
در اینجا نقش انسان و هوشواره از هم جدا میشود. انسان معمار نیت است. او چرایی، چگونگی، محدودهها، قواعد و نکات مثبت و منفی را تعیین میکند. هوشواره موتور پیاده سازی است. او چگونگی را با سرعت بالا اجرا میکند. اگر این نقشها برعکس شوند، یعنی هوشواره مجبور شود نیت گمشده را حدس بزند و انسان فقط خروجی را اجرا کند، سیستم به سمت آشفتگی میرود.
مطلب را با این موضوع ادامه میدهیم که اگر هوشواره سینتکس، کتابخانهها و بخش مکانیکی کدنویسی را آسان کند، سختی کار کجا میرود؟ پاسخ ما این است که سختی حذف نمیشود، جابهجا میشود. برای دههها گلوگاه مهندسی نرمافزار پیادهسازی بود. ما محدود بودیم به سرعت تایپ، دیباگ، شناخت زبانها و مدیریت جزئیات فنی.
اما اکنون پیادهسازی ارزانتر شده است. هوشواره میتواند ساختار اولیه تولید کند، کامپوننت بسازد، endpoint بنویسد و تست ایجاد کند. بنابراین ارزش مهندسی به لایه بالاتری منتقل میشود: شفافیت ذهن. یعنی توانایی تعریف دقیق اینکه سیستم چه باید بکند و چه نباید بکند.
در این جهان جدید، زبان طبیعی به رابط مهمی برای ساخت نرمافزار تبدیل میشود. اما زبان طبیعی اگر بدون دیسیپلین استفاده شود خطرناک است. برخلاف پایتون یا جاوا یا سیشارپ، زبان طبیعی خطایسینتکس آشکار ندارد. جملهای مثل «سیستم سریع باشد» کاملاً از نظر گرامری صحیح است، اما از نظر مهندسی تقریباً بیمعنی است. کامپایلر سنتی در برابر سینتکس غلط خطا میدهد، اما هوشواره در برابر نیازمندی مبهم معمولاً خروجی تولید میکند. به همین دلیل، در زبانی طبیعی به جای خطای سینتکس با خطای منطفی و ابهام روبهرو هستیم.
برای توضیح این تغییر، تاریخچه انتزاع را مرور میکنیم. نسل اول زبانهای برنامهنویسی کدهای ماشین بودند؛ انسان مستقیماً با صفر و یکها یا دستورهای نزدیک به سختافزار سروکار داشت. نسل دوم اسمبلی بود؛ کمی انسانیتر، اما هنوز نزدیک به سختافزار و زیرساخت. نسل سوم زبانهایی مثل C++، جاوا و سیشارپ بودند که انسان را از سختافزار دورتر و به مفاهیم نزدیکتر کردند. نسل چهارم زبانهای ویژه در حوزههای خاص مثل SQL بودند که برای دامنه مشخصی انتزاع بالاتری فراهم کردند.
اکنون برخی از هوشواره و زبانهای طبیعی به عنوان شکل تازهای از نسل پنجم صحبت میکنند. البته هشدار میدهم که اصطلاح نسل پنجم بار تاریخی دارد. در دهه ۸۰، logic programming و پروژههای بزرگ مبتنی بر Prolog و Lisp machines هم رؤیای تعریف مسئله با قواعد منطقی و حل خودکار آن را داشتند. آن مسیر به عنوان پارادایم عمومی شکست خورد، چون شکننده بود و به قواعد بسیار دقیق نیاز داشت.
اما موج جدید متفاوت است. اینجا زبان طبیعی با هوشواره عامل ترکیب میشود. هوشواره میتواند نیت را به استک خاصی از تکنولوژی، فایل، کد و تست ترجمه کند. از این منظر، هوشواره شبیه یک کامپایلر انعطافپذیر است. کامپایلر سنتی سینتکس دقیق را به کد ماشین ترجمه میکند. هوشواره نیت ساختاریافته را به پیادهسازی ترجمه میکند. اما چون خروجی کارش احتمالی است، برای قابل اعتماد شدن به spec، محدودیتها، دروازهها و تایید نیاز دارد.

تا اینجا تا حدودی توضیح دادیم که SDD از نظر ایده کاملاً جدید نیست، اما اکنون به دلیل توان هوشواره و پنجرههای زمینهی بزرگتر عملیتر شده است. اگر هوشواره فقط چند خط آخر گفتگو را به یاد داشته باشد، نمیتواند یک سیستم پیچیده را بر اساس spec، اسکیما، قواعد معماری و محدودیتهای امنیتی بسازد. در آن حالت فقط میتواند توابع های کوچک بسازد.
اما با پنجره زمینههای بزرگ، هوشواره میتواند بخش قابل توجهی از زمینه پروژه را ببیند: معماری مستندات، ساختار پایگاه داده، داستانهای کاربر، قواعد امنیتی، API contract، کدهای موجود و تسکها. این تغییر «فیزیک پروژه» را عوض میکند. هوشواره دیگر الزاماً در خلأ تکه کد تولید نمیکند؛ میتواند کد را در واقعیت محصول قرار دهد.
البته زمینه بزرگ به تنهایی کافی نیست. اگر زمینه پر از سندهای قدیمی، تناقض، ابهام باشد، هوشواره از همان مواد خام غلط خروجی تولید میکند. بنابراین بزرگتر شدن پنجره زمینه فقط وقتی مفید است که ویژگیها زنده، دقیق و نسخهپذیر باشند. اگر به هوشواره سند دروغ بدهیم کد ایراددار تحویل میگیریم.
به همین دلیل SDD در عصر هوشواره دوباره دیسیپلینهای قدیمی مهندسی را زنده میکند. نه به شکل آبشاری کند و سنگین، بلکه به شکل چرخه سریع و قابل تکرار. میتوان صبح مشخصاتنوشت، طرح تولید کرد، وظایف را ساخت، پیادهسازی گرفت، شکست را دید، مشخصات را اصلاح کرد و دوباره تولید انجام داد. این چیزی است که ما از آن به عنوان دیسیپلین قدیمی با سرعت جدید یاد میکنیم: ایمنی برنامه ریزی بدون گیرکردن در باتلاق.
تا اینجا SDD را به عنوان ترکیبی عملگرایانه از چند دهه تجربه مهندسی نرمافزار معرفی کردیم. این روش از SDLC، PRD، TDD، BDD و MDD ایده میگیرد، اما آنها را برای عصر هوشواره بازسازی میکند.
چرخه حیات توسعه نرم افزار( SDLC): دیسیپلین و مراحل
اغلب Software Development Lifecycle به بروکراسی، روال آبشاری و فازهای طولانی متهم شده است. اما نیت اصلی آن کاملاً منطقی بود: نمیتوان بدون پایه، نقطه بازرسی، پاسخگویی و جداسازی دغدغهها سیستم جدی ساخت. باید بین چه و چگونه تمایز بگذاریم. باید قبل از پیادهسازی درباره نیازمندی، طراحی و اعتبارسنجی فکر کنیم.
مشکل مدلهای قدیمی این بود که مراحل سخت و کند بودند. گاهی ماهها برای سند و تفاهم صرف میشد و وقتی پیادهسازی شروع میشد، نیاز بازار تغییر کرده بود. SDD تلاش میکند دیسیپلین را نگه دارد، اما کندی را حذف کند. چون هوشواره پیادهسازی را سریعتر میکند، فاصله بین طراحی و کد میتواند از ماهها به دقیقهها یا ساعتها کاهش یابد.
سند PRD: از حقیقت مشورتی به حقیقت الزام آور
سند نیازمندی محصول قرار بود نیت محصول را ثبت کند، اما در بسیاری از تیمها تبدیل به سندی مشورتی شد. یعنی در ابتدا نوشته میشد، همه آن را امضا میکردند، سپس فرایند مهندسی شروع میشد و کمکم کد واقعیت را تعیین میکرد. اگر کد با PRD فرق داشت، معمولاً میگفتند PRD قدیمی است.
ما این مسئله را مسئلهی حقیقتِ مشورتی مینامد. سند فقط مشورت است، نه حقیقت. در SDD این رابطه باید برعکس شود. مشخصات باید اجباری باشند. یعنی اگر کد با مشخصات ناسازگار شد، یا کد باید اصلاح شود یا مشخصات باید آگاهانه و با بازبینی تغییر کند. هیچ تغییر خاموشی نباید پذیرفته شود.
فرایندهای TDD و BDD: نیت قابل اجرا
توسعه مبتنی بر آزمون یک ایده مهم را وارد مهندسی کرد: قبل از کد، نیت قابل اجرا بنویس. تست ابتدا با خطا متوقف میشود و سپس کد نوشته میشود تا آن را پاس کند. توسعه مبتنی بر رفتار این ایده را به زبان نزدیکتر به کسب و کار آورد، با الگوهایی مثل Given، When، Then.
فرایندهایSDD این ایده را گسترش میدهند. فقط رفتار نهایی نباید قابل تست باشد؛ معماری، الگوی ادغام، مرز تجزیه، مدیریت خطا و ویژگیهای معماری و محدودیتها هم باید کنترل شوند. اگر فقط به هوشواره بگوییم تستها را پاس کند، ممکن است راههای بدی انتخاب کند. شاید تابع را طوری بنویسد که یک مقدار ثابت برای پاس کردن تست باز گرداند، شاید خطای امنیتی بسازد، شاید کدی بنویسد که تست کوچک را پاس کند اما معماری را خراب کند.
بنابراین SDD به چیزی فراتر از تست نیاز دارد: مشخصات، طرح معماری، وظایف، دروازههای تایید و پیاده سازی. تست مهم است، اما کافی نیست. باید محافظان هوشوارهای برای معماری و قواعد هم وجود داشته باشد.
فرایند MDD: رؤیای تولید پیادهسازی از مدل
روال Model-Driven Development رؤیایی قدیمی داشت: منطق را در مدل تعریف کنیم و کد از روی آن تولید شود. ابزارهای UML و کد جنریتورها تلاش کردند این کار را انجام دهند. اما سربار زیاد، زبانهای مدلسازی سنگین، تولیدکنندههای شکننده و مشکل رفت و برگشت در فرایند مهندسی باعث شد این رویکرد در مقیاس عمومی موفق نشود.
رفت و برگشت در فرایند مهندسی یعنی مدل از کد تولید میشود یا کد از مدل، اما وقتی توسعهدهنده کد را دستی تغییر میدهد، مدل ناهمگام میشود. اگر مدل دوباره تولید شود، ممکن است تغییر دستی از بین برود. اگر کد تغییر کند و مدل تغییر نکند، دیاگرام تبدیل به دروغ میشود.
فرایند SDD از MDD ایده طراحی قبل از کد و پیادهسازی مشتق شده را میگیرد، اما تولیدکننده شکننده خود را با عوامل هوشمند جایگزین میکند. هوشواره میتواند متن نیازمندی، اسکیما، قطعه کد قدیمی، دیاگرام یا حتی توضیح طبیعی را با هم ببیند و از آن پیادهسازی بسازد. این انعطاف همان کامپایلر انعطلافپذیر است.

با تجربهای آشنا برای بسیاری از مهندسان شروع میکنیم: وارد تیمی جدید میشوید، سند زیبا و منظم است، دیاگرامها قانعکنندهاند، توضیح “سیستم پرداخت” کامل به نظر میرسد. اما وقتی کد را باز میکنید، میفهمید مستندسازی مربوط به سه سال پیش است. کد تغییر کرده، سند بهروز نشده و دیگر نقشه قابل اعتماد ندارید. این وضعیت مستندات بیات است.
سند بیات فقط قدیمی نیست، غیر قابل اعتماد است. وقتی تیم بفهمد سند قابل اعتماد نیست، دیگر آن را نمیخواند. از آن پس تنها حقیقت، کد است. اما کد معمولاً نیت را خوب توضیح نمیدهد. کد میگوید چه اتفاقی میافتد، اما الزاماً نمیگوید چرا، طبق کدام نیازمندی، با چه trade-off و برای پوشش کدام ریسک.
در جهان متمرکز بر کد ، مخزن کد منبع حقیقت است. مانترا این است: کد به ما دروغ نمیگوید. ولی ما این نگاه را به چالش میکشیم. اگر کد فقط طرح یا ترجمهای از حقیقتی بالاتر باشد چه؟ اگر کد چیزی باشد که باید از مشخصات مشتق شود، نه چیزی که مشخصات را تابع خود کند؟
وارونگی قدرت یعنی مشخصات از مستندات کمکی به سیستم ثبت حقایق ارتقا پیدا کند. در مدل قدیمی، مشخصات توضیح میدهد کد چه میکند. اگر تضادی وجود داشت، مشخصات بازنده است. در مدل SDD، کد باید مشخصات را پیادهسازی کند. اگر تضادی وجود داشت، کد بازنده است، مگر اینکه مشخصات با تصمیم آگاهانه تغییر کند.
این تغییر ذهنی برای توسعهدهندهها سخت است. سالها به ما گفته شده کد حقیقت نهایی است. مشتری کد را میبیند، نه سند را. محصول در محیط عملیاتی رفتار واقعی را اجرا میکند، نه نیازمندی سند را. بنابراین متمرکز بر کد بودن تاریخی قابل فهم است. اما در عصر هوشواره ، اگر کد با سرعت بالا و از پرامپتهای مبهم تولید شود، کد دیگر الزاماً دارایی اصلی نیست. دارایی اصلی نیت کنترلشده و قابل بازسازی است.
یکی از ایدههای مهم این متن این است که در SDD، کد میتواند مصنوع مشتقشده باشد. برای فهم این ایده، میتوان به کامپایلر فکر کرد. وقتی C++ مینویسیم، اسمبلی تولیدشده مهم است، اما معمولاً آن را نمیخوانیم. اسمبلی یک مصنوع مشتقشده از سورس کد سطح بالاتر است. ما روی C++ کار میکنیم، چون انتزاع بالاتری دارد و نیت انسان را بهتر بیان میکند.
در وارونگی قدرت، پایتون یا سیشارپ هم ممکن است نسبت به مشخصات نقش مشابهی پیدا کنند. مشخصات از سورس کد بالاتر است و کد، خروجی ترجمهشده آن است. البته کد هنوز لازم است؛ ماشین باید چیزی را اجرا کند. اما ارزش اصلی مهندسی به سمت بالا یعنی نیت حرکت میکند: روشن کردن حالتهای خاص، تعریف محدودیتها، نوشتن شروط پذیرش، تعیین مرزهای معماری و حفظ قابلیت ردیابی.
این ایده برای ایگو مهندسان ممکن است سخت باشد. ما سالها ارزش خود را در نوشتن کد خوب دیدهایم. اما وقتی هوشواره بخش زیادی از سینتکس و ساختار را تولید میکند، ارزش انسان در تعریف دقیق مسئله و کنترل کیفیت ترجمه است. در این مدل، مهندس بیشتر ویراستار نیت و معمار رفتار است تا صرفاً نویسندهی سینتکس.
اگر محافظان هوشوارهها درست باشند، این نگاه کیفیت را پایین نمیآورد. نگرانی طبیعی این است که اگر کد یکبارمصرف باشد، اسپاگتی کد در مقیاس بالا تولید شود. بدون دروازههایی برای تایید و مشخصات دقیق، بله، همین اتفاق میافتد. اما با ویژگی، طرح، وظیفههای کوچک، تست و بازبینی، کیفیت میتواند بالا برود، چون پیادهسازیها از منبع حقیقت یکسان و کنترل شده تولید میشوند.
در روش قدیمی، هر توسعهدهنده ممکن است ویژگی را با سبک و الگوی متفاوتی پیاده کند. اما اگر ویژگی، طرح و قوانین دقیق باشند، هوشواره میتواند پیادهسازیهای سازگارتر تولید کند. شرط این است که مشخصات صریح باشد، وظایف کوچک و قابل تایید باشند، و دروازهها جلوی خطا را بگیرند.

بخش دهم: نگهداری به عنوان نیت در حال تکامل
وارونگی قدرت تعریف نگهداری را هم تغییر میدهد. در مدل متمرکز بر کد ، نگهداری اغلب یعنی پچ کردن کد. گزارش باگ میآید، توسعهدهنده فایل مربوطه را پیدا میکند، یک شرط به کد اضافه میکند، مقدار timeout را تغییر میدهد یا اعتبارسنجی را در جایی وارد میکند. شاید باگ حل شود، اما نیت معمولاً در همان خط از کد دفن میشود.
مثال محدودیت نرخ درخواست در بازنشانی کلمه عبور را در نظر بگیرید. گزارش باگ میگوید کاربران میتوانند بارها درخواست ارسال کنند و ایمیل اسپم شود. در مدل قدیمی، توسعهدهنده ممکن است مستقیم به “resetcontroller” برود و یک چک زمانی اضافه کند. مثلاً اگر درخواست قبلی کمتر از پنج ثانیه قبل بوده، درخواست جدید را رد کند. اما چرا پنج ثانیه؟ آیا بر اساس IP است یا کاربر؟ آیا در سیستم توزیع شده کار میکند؟ آیا باید Redis باشد یا پایگاه داده؟ این تصمیمها در کد پنهان میشوند.
در SDD، هنگام باگ، ابتدا سراغ کد نمیرویم. اول مشخصات را بروز میکنیم. قوانین را تعریف میکنیم: محدودیت نرخ درخواست چگونه است، پنجره زمانی چیست، محدودیت چیست، رفتار پاسخ چیست، حالات خاص چیست. سپس طرح را بروز میکنیم: این منطق کجا زندگی میکند، API دروازهway یا لایه سرویس برنامه یا ابزاری مبتنی بر تکنولوژی خاص است مثلا مبتنی بر ردیس؟ بعد وظایف ساخته میشوند: محدودیتساز پیادهسازی میشود، تست برای حالات خاص اضافه شود، قابلیت مشاهده اضافه شود. در نهایت کد نوشته یا بازتولید میشود.
این روش، کار مقدماتی بیشتری دارد، اما نیت را حفظ میکند. مهندس بعدی مجبور نیست اعداد جادویی را مهندسی معکوس کند. میبیند محدویت تعداد درخواست به عنوان یک قاعده کسب و کاری/ امنیتی در مشخصات آمده، معماری آن در طرح تصمیمگیری شده و تستهای آن وجود دارند.
بنابراین نگهداری در SDD یعنی نیت در حال تکامل. وقتی رفتار تغییر میکند، منبع حقیقت تغییر میکند و سپس پیادهسازی با آن همراستا میشود. دیباگ هم روال بالا دستی دارد. به جای اینکه فقط توابع را دیباگ کنیم، میپرسیم آیا نیازمندی مبهم بود؟ آیا طرح، محدودیتها را جا انداخته بود؟ آیا وظیفه غلط تعریف شده بود؟ آیا تست، رفتار درست را پوشش نمیداد؟ در این نگاه، ما دلیل را اصلاح میکنیم، نه فقط نشانه را.
بخش یازدهم: آیندهنگری و جدا کردن چه از چگونه
یکی از پیامدهای مهم SDD، جدایی کامل بین چه و چگونه است. قوانین کسب و کارها معمولاً نسبت به تکنولوژی پایدارترند. قانون اینکه بازنشانی کلمه عبور باید محدودیت نرخ درخواستداشته باشد، ممکن است سالها معتبر بماند، چه backend با Node.js نوشته شده باشد، چه با جاوا، سیشارپ یا پایتون. اما اگر این قانون فقط در کد فعلی دفن شده باشد، مهاجرت آینده تبدیل به مهندسی معکوس عظیم میشود.
بسیاری از بازنویسیها شکست میخورند، چون تیم دقیقاً نمیداند سیستم قدیمی چکاری میکند. کد رفتارهایی دارد که سالها به مرور اضافه شدهاند؛ سندها قدیمی شدهاند؛ تستها ناقصاند؛ قوانین کسب و کارها در پچها پنهان شدهاند. اگر مشخصات واقعی و الزامآوری وجود داشته باشد، مهاجرت به تکنولوژی جدید بیشتر تمرین برنامهریزی میشود تا باستانشناسی. تیم میداند چه رفتارهایی باید بازسازی شوند و کدام محدودیتها باید حفظ شوند.
این موضوع در امنیت و انطباق هم مهم است. در روشهای رایج، امنیت گاهی به چک لیست انتهای پروژه تبدیل میشود. اما در SDD، امنیت و انطباق باید اولویت اولمحدودیتها در مشخصات باشند. مثلاً رمزنگاری، لاگ، سیاست حفظ مشتری، حریم خصوصی ، محدودیت نرخ درخواست و شکست رفتار از اول در نیت میآیند، نه بعداً به عنوان پچ.
از دید معماری سازمانی، SDD میتواند دانش سیستم را از کد فعلی جدا کند. کد ممکن است تغییر کند، فریمورک ممکن است عوض شود، اما نیت و محدودیتها اگر درست ثبت شوند، دارایی بلندمدت سازمان خواهند بود.

در این قسمت مشخصات را به عنوان “زبان خاص” معرفی میکنیم؛ یعنی زبان مشترک بین انسانها و ماشینها. در تاریخ، “زبان خاص” زبان واسطی بود که گروههای مختلف برای تجارت و ارتباط از آن استفاده میکردند. در SDD، مشخصات باید زبان مشترک مدیر محصول ، توسعهدهنده، معمار، تستر، امنیت و عوامل هوشمند باشد.
این زبان مشترک صرفاً نثر آزاد نیست. باید زبان طبیعی ساختاریافته به همراه قرارداد، الگو، تگ و الگو باشد. اگر مشخصات برای انسان قابل فهم نباشد، محصول و کسب و کار نمیتوانند آن را تأیید کنند. اگر برای ماشین به اندازه کافی ساختاریافته نباشد، عامل نمیتواند از آن طرح، وظیفه، تست یا کد تولید کند.
چرا هوشواره این نیاز را جدیتر میکند؟ چون انسانها توانایی استنتاج زمینه دارند. اگر به یک توسعهدهنده ارشد بگوییم صفحه ورود بساز، او از تجربه میداند که در فرایند فراموشی کلمه عبور، مدیریت خطا، امنیت کلمه عبور و دسترسیپذیری مهماند. اما هوشواره ممکن است این زمینه را به طور قابل اعتماد استنتاج نکند. شاید حدس بزند، شاید هم نزنند. اگر تیم انسانی خودش روی معنی مشخصات توافق نداشته باشد، عامل هیچ شانسی ندارد.
بنابراین مشخصات باید جاهای خالی را کاهش دهد. اگر چیزی مشخص نیست، نباید ساکت بماند. باید به عنوان شفافسازی ثبت شود. اگر رفتار مهم است، باید شروط پذیرش داشته باشد. اگر شکست ممکن است، باید شکست رفتار تعریف شود. اگر داده رد و بدل میشود، باید قرارداد داده مشخص باشد. اگر محدودیتهای امنیتی وجود دارد، باید در مشخصات بیاید.
سند ایستا یک ضد الگو برای SDD است. ویکی، PDF، یادداشت یا سندی که در شروع نوشته شده و دیگر بروز نشده، برای هوشواره خطرناک است. اگر کد تغییر کند و سند تغییر نکند، سند تبدیل به دروغ میشود. اگر این دروغ را به هوشواره بدهیم، کد مشکل دار تولید میکند.
راهحل SDD، ویژگیهای زنده است. ویژگیها باید در مخزن کد زندگی کنند. باید نسخهپذیرباشند. باید کنار منبع کد قرار بگیرند یا حداقل در همان چرخه حیات باشند. باید برای آنها بیات شدگی، بازبینی، تاریخچه و مالکیت وجود داشته باشد. همانطور که تغییر کد بدون بازبینی خطرناک است، تغییر نیت هم باید بازبینی شود.
یک قانون عملی مهم، اصلاح ویژگی در ابتدا است. اگر رفتار سیستم قرار است تغییر کند، مشخصات باید قبل از کد یا حداقل در همان پول ریکوئست تغییر کند. تغییر باید نشان دهد نیت چگونه تغییر کرده است. این قانون باعث میشود تیم قبل از کدنویسی مجبور شود فکر خود را روشن کند.
این روش جلوی سند بیات را میگیرد، چون دیگر سند چیزی نیست که بعداً شاید بروزرسانی شود. خود سند بخشی از تغییرات است. اگر ویژگی تغییر کرد و مشخصاتت غییر نکرد، PR ناقص است. اگر مشخصات تغییر کرد و تست یا کد همراستا نشد،عملی که در دروازه رخ میدهد باید با خطا متوقف شود.

یکی از اصطلاحات مهم این نوشته نیت قابل اجرا است. منظور این نیست که فایل ویژگیها مثل پایتون اسکریپت اجرا میشود. منظور این است که مشخصات آنقدر دقیق است که بتوان از آن مصنوعات پاییندستی را به شکل قابل اعتماد تولید کرد: طرح، وظایف، تستها و پیادهسازی پرامپت.
یک مشخصات قابل اجرا یا قابل کامپایل باید چند عنصر داشته باشد. اول مرزهای دامنه؛ یعنی چه چیزی داخل محدوده است و چه چیزی صریحا خارج از محدوده است. معمولاً تیمها فقط داخل محدوده را مینویسند و خارج از محدوده را رها میکنند، اما برای هوشواره خارج از محدوده بسیار مهم است، چون جلوی اضافهکاری و توهم پیادهسازی را میگیرد.
دوم بازیگران و سفرهای کاربر باید مشخص باشند. چه کسی چه کاری انجام میدهد؟ کاربر، مدیر سیستم، سیستم، سیستمی بیرونی یا کارپس زمینه؟ سوم شروط پذیرش و شکست رفتار باید تعریف شوند. فقط نگوییم «کار کند»، بلکه بگوییم در موفقیت، شکست، timeout، ورودی غیر قابل قبول و عدم ارسال ورودی چه باید شود. چهارم قراردادهای داده، ورودیها و خروجیها باید مشخص شوند. چه فیلدهایی لازماند؟ چه فرمتی دارند؟ منطقه زمانی چیست؟ null مجاز است؟ پاسخ خطا چه شکلی است؟ پنجم ویژگیهای معماری محدودیتها باید بیایند: امنیت، حریم خصوصی، بهرهوری، قابلیت مشاهده، انطباق و دسترسیپذیری.
اگر یکی از اینها جا بیفتد، عامل معمولاً نمیایستد. LLM تکمیل با الگو انجام میدهد. یعنی فاصله را با چیزی که از نظر آماری قابل قبول است پر میکند. اما قابل قبول برای اینترنت یا داده آموزشی الزاماً درست برای معماری شما نیست.
تله تکمیل الگو یکی از خطرناکترین مفاهیم برای ما است. مدل زبانی برای تکمیل الگو آموزش دیده است. وقتی جمله یا درخواست ناقص باشد، ادامه قابل قبول میسازد. این توانایی در تولید متن و کد بسیار مفید است، اما در مهندسی خطر ایجاد میکند.
اگر نیازمندی بگوید “نرخ درخواست را محدود کن”. عامل ممکن است خودش تصمیم بگیرد محدودیت نرخ درخواست بر اساس IP باشد، یا کاربر، یا endpoint. ممکن است پنجره را یک دقیقه، پنج دقیقه یا یک ساعت بگیرد. ممکن است پاسخ را 429 بگذارد یا پیام خاص بسازد. شاید اینها معقول باشند، اما تصمیم رسمی نیستند.
در مهندسی، گپها باید قابل مشاهده شوند. اگر چیزی معلوم نیست، باید با تگهایی مثل نیازمندبررسی، ضد الگو مشخص شود. این کار عدم قطعیت را از ذهن پنهان یا حدس مدل به بکلاگ آشکار سؤالها تبدیل میکند. ابهام دیگر چیزی نیست که عامل زیر فرش پنهان کند؛ چیزی است که جریان کار باید روی آن توقف کند.
این تغییر رفتار سخت است، چون توسعهدهندهها به سرعت عادت دارند. وقتی هوشواره میتواند در چند ثانیه کد بسازد، توقف کردن برای سؤال پرسیدن کند به نظر میرسد. اما توضیح دادیم که این کند شدن برای افزایش سرعت است. اگر در مشخصات دروازهها پنج دقیقه برای شفافسازی وقت بگذاریم، شاید ده ساعت دیباگ و حادثخ را حذف کنیم.

کلمه EARS در اینجا مخفف Easy Approach to requirements syntax است. هدف آن این است که نیازمندیها به جای نثر مبهم، در قالبهای ساده و تکرارپذیر نوشته شوند. EARS زبان طبیعی را حذف نمیکند؛ آن را ساختاریافته میکند. جملات کمی خشکتر میشوند، اما ابهام کاهش مییابد.
مثلاً نیازمندی مبهم میگوید: «صفحه باید سریع باشد». اما سریع یعنی چه؟ در چه شرایطی؟ برای چه کاربری؟ با چه شبکهای؟ نیازمندی بهتر میتواند بگوید: “وقتی که کاربر صفحه سفارشات را باز میکند، سیستم باید زیر 2 ثانیه صفحه را نمایش دهد تا 10 هزار کاربر .” این جمله هنوز زبان طبیعی است، اما قابل ارزیابیتر است.
قالب رایج EARS چنین است: when event, the system shall response. چندین قالب دیگر با چنین ساختارهایی که مشاهده میکنید وجود دارد که رفتار سیستم را شفاف تر توضیح میدهد.
ارزش EARS فقط در سینتکس نیست. ارزش واقعی آن این است که نویسنده را مجبور میکند درباره شرایط و رفتار فکر کند. اگر نمیتوانیم جمله EARS بنویسیم، شاید نیازمندی خودمان را هنوز نفهمیدهایم. این برای SDD حیاتی است، چون هوشواره فقط به اندازه شفافیت مشخصات خوب عمل میکند.
شفافسازی دروازه مرحلهای است که قبل از طرح و پیادهسازی باید ابهامها را آشکار کند. در این مرحله عامل یا انسان باید سؤالهای باز را لیست کند. مثلاً برای محدودیت نرخ درخواست، سؤال میتواند این باشد: محدودیت نرخ درخواست براساس IP است، یا کاربر یا ترکیبی؟ برای خروجی گرفتن با فرمت CSV، سؤال میتواند این باشد: خروجی فقط صفحه جاری است یا همه نتایج فیلتر شده؟ منطقه زمانی ستون تاریخ چیست؟ محدودیت ردیفها چقدر است؟
قانون مهم این است که عامل نباید پیشفرضی را پیشنهاد کند مگر اجازه داشته باشد. اگر نیازمندی ناقص است، باید توقف کند. این با رفتار معمول هوشواره که میخواهد کمککننده باشد متفاوت است. ما باید مفید بودن را در چارچوب قواعد محدود کنیم. گاهی بهترین رفتار عامل این نیست که کد بسازد، بلکه این است که بگوید اطلاعات کافی نیست.
شفافسازی دروازه باعث میشود تخلفها نامرئی به سؤال مرئی تبدیل شود. اگر این دروازه نباشد، عامل تصمیم میگیرد و توسعهدهنده شاید متوجه نشود. اگر دروازه باشد، تیم میبیند که برای ادامه باید تصمیم بگیرد. این تصمیم بعداً در مشخصات ثبت میشود و قابلیت ردیابی ایجاد میکند.
از نظر فرهنگی، شفافسازی دروازه نیازمند صبر و بلوغ است. تیم باید بداند سرعت واقعی از حذف فکر کردن به دست نمیآید. سرعت واقعی زمانی به دست میآید که ابهامهای پرهزینه زود حل شوند و پیادهسازی با حدث ساخته نشود.
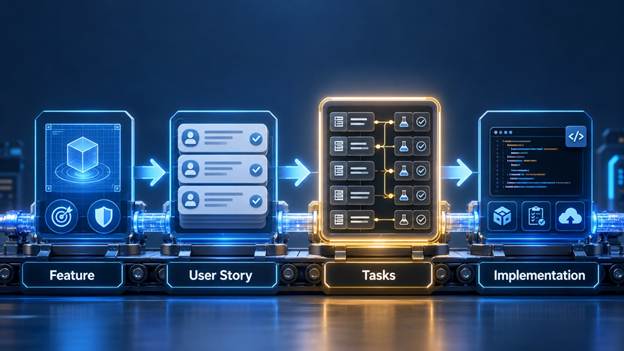
ما یک مسیر چندلایه برای SDD معرفی میکنیم. این مسیر را میتوان به شکل ویژگی، داستانهای کاربر، وظایف و پیادهسازی دید. در نسخه کاملتر، بین مشخصات و پیادهسازی، طرح و تایید دروازهها هم قرار میگیرند.
لایه اول ویژگی است. ویژگی چرا و خروجی را توضیح میدهد. چرا این ویژگی را میخواهیم؟ مرزهای آن چیست؟ چه چیزی خارج از محدوده است؟ چه ارزشی برای کاربر یا کسب و کار ایجاد میکند؟ بدون این لایه، هوشواره ممکن است فقط UI یا کد بسازد، بدون فهم هدف واقعی.
لایه دوم داستانهای کاربر و شروط پذیرش است. این لایه چه را روشن میکند. چه بازیگرهایی با سیستم تعامل دارند؟ چه رفتارهایی انتظار میرود؟ موفقیت چگونه تعریف میشود؟ شکست چگونه باید رفتار کند؟
لایه سوم وظایف است. این همان لایهای است که وایبکدینگ معمولاً از آن عبور میکند. در SDD، کار به واحدهای کوچک و قابل تایید تبدیل میشود: مهاجرتی برای پایگاه داده بساز، endpoint اضافه کن، متدی در سرویس پیاده کن، اعتبارسنجی اضافه کن، تست بنویس، وضعیت یو آی را بروزرسانی کن. این وظیفهها به هوشواره نمیگویند فقط “ویژگی را بساز”، بلکه مسیر کنترلشده پیادهسازی را مشخص میکنند.
لایه چهارم پیادهسازی است. در اینجا کدنویسی به کاری مکانیکیتر تبدیل میشود. هوشواره وظیفههای کوچک را انجام میدهد. انسان بازبینی میکند که تفاوت با وظیفه و مشخصات همخوان است یا نه. پیادهسازی دیگر جایی برای کشف بیقید نیست؛ جایی برای اجرای نیت روشن است.
فرایندSDD فقط نوشتن مشخصات نیست. مشخصات بدون دروازه میتواند دوباره به سند فراموششده تبدیل شود. ما بر بازبینی دروازهها تأکید داریم. بین ویژگی، طرح، وظایف و پیادهسازی باید بازبینی انسانی یا خودکار وجود داشته باشد.
مشخصات دروازه میپرسد: آیا شروط پذیرش صریح هستند؟ آیا شکست رفتار مشخص است؟ آیا قرارداد دادهها تعریف شده؟ آیا ابهام باقی مانده؟ اگر پاسخ منفی است، نباید طرح یا پیادهسازی شروع شود.
طرح دروازه میپرسد: آیا روش فنی با قوانین پروژه سازگار است؟ آیا ریسکهای امنیتی دیده شدهاند؟ آیا مسیر بازگشت وجود دارد؟ آیا معماری موجود حفظ میشود؟ آیا لایهها، وابستگیها و الگویهای ادغام درستاند؟
وظایف دروازه میپرسد: آیا وظیفهها کوچک و مستقلا قابل صحت سنجی هستند؟ یا عامل فقط یک وظیفه بزرگ با عنوان “سیستم را بساز” ساخته است؟ وظیفه خوب باید محدوده کوچک، خروجی روشن و تست/تایید مشخص داشته باشد.
پیادهسازی دروازه میپرسد: آیا تفاوت واقعاً وظیفهها را پیاده کرده؟ آیا کد از طرح منحرف نشده؟ آیا تستها رفتارهای مشخصات را اثبات میکنند؟ آیا محدودیتهای معماری نقض نشدهاند؟ این دروازه کیفیت را در انتهای مسیر کنترل میکند، اما به مشخصات و طرح بالادستی متصل است.
این دروازهها اصطکاک بیهدف نیستند؛ کنترل کیفیت در خط تولید هوشواره هستند. اگر دروازهها حذف شوند، هوشواره فقط کارخانه تولید خطای سریعتری میشود.

در سیستمهای قدیمی و به ارث رسیده، بزرگترین مشکل هوشواره این است که کد جدید، غریبه به نظر میرسد. شاید کتابخانهی استفاده کند که پروژه ندارد، قرارداد نامگذاری دیگری انتخاب کند، مدیریت خطای متفاوتی بسازد یا لایه سرویس را دور بزند. برای جلوگیری از این موضوع، قانون اساسی را معرفی میکنیم.
قانون اساسی فایلی مثل “agent.md” یا فایلهای مشابه است که در ریشه مخزن کد قرار میگیرد و قواعد غیرقابل مذاکرده پروژه را تعریف میکند. این فایل میگوید استک چیست، ساختار فولدرها چیست، لاگ چگونه است، مدیریت خطا چگونه است، دسترسی به پایگاه داده از کدام لایه انجام میشود، تست استراتژی چیست و چه چیزهایی ممنوعاند.
قانون اساسی برای عامل نقش قوانین قابلخواندن توسط ماشین را دارد. همانطور که یک کشور قانون اساسی دارد، ریپازیتوری هم باید قانونهایی داشته باشد که عامل نتواند به راحتی از آنها عبور کند. اگر قانون این است که پایگاه داده فقط از ریپازیتوریهای لایه دیتا اکسس قابل دسترسی است، قانون اساسی باید آن را صریح بگوید. اگر قانون این است که کتابخانه جدید بدون اجازه و تایید اضافه نشود، باید نوشته شود.
یکی از بخشهای مهم قانون اساسی، محدودیتهامنفی است. برای هوشواره فقط گفتن اینکه چه کار کند کافی نیست. باید بگوییم چه کار نکند. مثل:” لایه سرویس هرگز نباید دور زده شود” یا “هرگز روش جدید برای دسترسی به پایگاه داده استفاده نکن”. این قوانین جلوی پیادهسازیهایی که با معماری سازگاری ندارند را میگیرد.
قانون اساسی کمک میکند کد تولیدشده توسط ماشین شبیه کدی باشد که تیم مینوشت. این موضوع برای قابلیت توسعه و نگهداری سیستم حیاتی است. تیم نباید حس کند هوشواره هر بار تکهای غیرهمگون به سیستم وصل میکند.

بسیاری از ابزارهای هوشواره برای کدنویسی در دموهای جدید عالی به نظر میرسند، چون از صفر برنامهای کوچک میسازند. اما بیشتر تیمهای واقعی در پروژههای قدیمی کار میکنند: کدبیس قدیمی، محدودیتهای تاریخی، کتابخانههای تثبیتشده، تصمیمات معماری قبلی، تستهای ناقص، مهاجرتهای نیمهتمام و نیازمندیهای ضمنی بخشی از شرایط این پروژهها است.
در کد قدیمی، هوشواره اگر فقط پرامپت بگیرد، احتمالاً کدی تولید میکند که در خلأ خوب است اما در سیستم شما عجیب است. شاید از ORM دیگری استفاده کند. شاید الگو مدیریت خطای پروژه را نداند. شاید از سرویس موجود استفاده نکند و منطق را تکرار کند. شاید برای یک ویژگی کوچک وابستگی جدید اضافه کند.
فرایندSDD برای پروژههای قدیمی اهمیت بیشتری دارد، چون مشخصات و قانون اساسی میتوانند زمینه پروژه را صریح کنند. به عامل میگوییم: اینجا چگونه کار میکنیم، چه چیزی به ارث رسیده است، چه چیزی ممنوع است، کدام الگو باید حفظ شود، کدام لایه مالک کدام وظیفه است.
در چنین محیطی، SDD به مدرنسازی هم کمک میکند. به جای اینکه هوشواره آزادانه کد به ارث رسیده را دستکاری کند، ابتدا نیت ثبت میشود، سناریوهای پذیرش مشخص میشوند، طرح مهاجرت نوشته میشود و سپس پیادهسازی با دروازهها جلو میرود. این روش ریسک تغییرات را کاهش میدهد.
پیش از پایان خوب است به نقش MCP نیز در این فرایند بپردازیم. وقتی عامل برای تصمیمگیری به اطلاعات بیرون از کد نیاز دارد، مثل لاگ، ساختار پایگاه داده، متریکهای زنده یا ایشو ترکر، اتصال مستقیم و بدون قاعده میتواند خطرناک باشد. اگر عامل بدون نظارت به ابزارهای محیط عملیاتی یا داده حساس وصل شود، امنیت به کابوس شبانه تبدیل میشود.
در این شرایط MCP به عنوان کانال استاندارد و قابل بررسی برای اتصال عامل به ابزارها مطرح میشود. ایده این است که عامل بتواند واقعیات سیستم را ببیند، اما از مسیر کنترلشده. مثلاً اسیکمای پایگاهداده را بخواند، لاگهای محدود را ببیند، یا ابزار تست را اجرا کند، بدون اینکه دسترسی نامحدود و غیرقابل ارزیابی داشته باشد.
در SDD، زمینه فقط متن مشخصات نیست. زمینه میتواند واقعات عملیاتی سیستم هم باشد. اما این واقعیتها باید کنترلشده باشند. همانطور که مشخصات نسخهپذیراست و پیادهسازی دروازه دارد، دسترسی عامل به ابزارهای بیرونی هم باید قواعد، مجوزهها و عاملهای حسابرسی مبتنی بر هوشواره داشته باشد.
در این نوشته MCP به عنوان اصل عمیق پیادهسازی باز نمیشود، اما جهتگیری آن روشن است: عامل هوشمند نباید فقط چت بات باشد؛ باید در جریان کار مهندسی با کانالهای استاندارد، قابل کنترل و قابل ارزیابی کار کند.
در پایان این نوشته، به property-based خواهیم پرداخت. تستهای معمولی example-based هستند. یعنی چند مثال مشخص را بررسی میکنند: اگر ورودی برابر 2 باشد، خروجی باید 4 باشد. این روش مفید است، اما همیشه محدود به مثالهایی است که ما به ذهنمان رسیدهاند.
تستهایProperty-based به جای مثال، قواعد ثابت تعریف میکند. قواعد ثابت چیزی است که باید همیشه درست باشد، صرف نظر از اینکه ورودی چیست. مثلاً موجودی حساب هرگز نباید منفی شود. یا decrypt(encrypt(x)) باید x را برگرداند. یا بعد از ثبت در لیست مرتب، لیست همچنان مرتب بماند.
اگر ویژگیها بتوانند قواعت ثابت را خوب بیان کنند، هوشواره میتواند تستهای زیادی تولید کند و سیستم را با ورودیهای متنوع بررسی کند: رشته خالی، عدد بسیار بزرگ، کاراکترهای غیرمعمول، منطقه زمانیهای مختلف، emoji، null، آرایههای بزرگ، شرایط مسابقه و حالتهای مرزی. این حرکت از «آیا در دمو کار میکند؟» به سمت «آیا میتوانیم تلاش کنیم ثابت کنیم شکست نمیخورد؟» است.
ما این شرایط را حرکت از آرزو به قطعیت مینامیم. البته در نرمافزار قطعیت مطلق دشوار است، اما جهتگیری مهم است. به جای چند چک سطحی، قواعد ثابت مهم کسب و کار و امنیت را تعریف میکنیم و ابزارها تلاش میکنند آنها را بشکنند.
تستهای Property-based برای SDD طبیعی است، چون هر دو بر بیان دقیق نیت تکیه دارند. اگر نمیتوانیم قواعد ثابت را بنویسیم، شاید رفتار واقعی سیستم را هنوز دقیق نفهمیدهایم.

حال بیایید یک آزمایش ساده انجام دهیم. یک ویژگی کوچک بردارید، مثل خروجی گرفتن به CSV. ابتدا آن را با وایبکدینگ انجام دهید. فقط پرامپت بدهید، اجرا کنید، پچ کنید و ببینید چه میشود. سپس فرضیاتی را که هوشواره در نظر گرفته یادداشت کنید. آیا جدا کننده را خودش انتخاب کرد؟ آیا کاراکترهای خاص را حذف کرده؟ آیا مقادیر خالی را مدیریت کرد؟ آیا منطقه زمانی را مشخص کرد؟ آیا خروجی همه نتایج است یا فقط صفحه جاری؟
بعد همان ویژگی را با SDD انجام دهید. ابتدا تعریف ویژگی را بنویسید. سپس چند داستان کاربر و شروط پذیرش اضافه کنید. بعد وظیفهها را کوچک کنید. سپس هوشواره را وظیفه به وظیفه جلو ببرید. خروجی احتمالاً کمتر هیجانانگیز و بیشتر به طور کسل کنندهای صحیح خواهد بود. و در مهندسی نرمافزار، کسل کننده صحیح بودن اغلب بهتر از به طور هیجان انگیز شکست خورده، است.
این تمرین نشان میدهد SDD الزاماً در شروع به فریمورک سنگین نیاز ندارد. حتی یک فایل مشخصات ساده هم میتواند تفاوت ایجاد کند. مهم این است که قبل از کد، سکوتها را کم کنیم و فرضیات را آشکار کنیم.
مثلاً برای خروجی CSV، مشخصات باید بگوید کدام فیلدها در خروجی باشند، کدام فیلدها ممنوعاند، فیلترها اعمال میشوند یا نه، صفحهبندی چه اثری دارد، جداکننده چیست، حذف کاراکترهای خاص چگونه است، نام فایل چگونه ساخته میشود، مقادیر خالی چه خروجی دارد، خطا چگونه نمایش داده میشود و حداکثر تعداد رکوردها چیست.
این تمرین برای تیمها بسیار مفید است، چون تفاوت دو رویکرد را به صورت عملی نشان میدهد. تا وقتی فقط درباره SDD حرف میزنیم، ممکن است شبیه مستندسازی قدیمی اضافه به نظر برسد. اما وقتی دو خروجی وایب و SDD را کنار هم میگذاریم، تفاوت کیفیت، قابلیت ردیابی و ثبات واضحتر میشود.
فرایندSDD تعریف انجامشده را تغییر میدهد. در مدل قدیمی، انجام شده اغلب یعنی کد ترکیب شد، دمو کار کرد و شاید بعداً ویکی بروزرسانی شود. اما همه میدانند “بعداً ویکی بروزرسانی میشود” معمولاً یعنی هیچوقت بروز نمیشود.
در SDD، انجام شده یعنی بروزرسانی و تایید شده، تستها با مشخصات هماهنگاند، کد آن را پیادهسازی میکند، و قابلیت ردیابی از رفتار به نیازمندی وجود دارد. اگر ویژگی پیاده شده اما مشخصات تغییر نکرده، انجام شده نیست. اگر مشخصات تغییر کرده اما تست رفتار را پوشش نمیدهد، انجام شده نیست. اگر کد کار میکند اما طرح را نقض کرده، انجام شده نیست.
این تعریف ممکن است سختگیرانه به نظر برسد، اما در سیستمهای مبتنی بر عوامل هوشمند ضروری است. چون هوشواره میتواند حجم زیادی کد بسازد، ما به تعریف انجام شده قویتری نیاز داریم. اگر معیار انجام شده فقط "کد اجرا شد" باشد، محصول اشتباه بیسر و صدا وارد محیط عملیاتی میشود.
تعریف انجام شده در SDD باید بین محصول، مهندسی، QA و امنیت مشترک باشد. مشخصات "زبان خاص" است و انجام شده یعنی همه مصنوعات با آن همراستا هستند.
در این نوشته فقط یک فرایند فنی معرفی نکردیم؛ یک تغییر فرهنگی هم پیشنهاد دادیم. در دهه قبل که فرهنگ " سریع حرکت کن و چیزهایی را بشکن" وجود داشت، بسیاری از تیمها فکر کردن پیشزمینه را کندی میدانستند. مستندات بار اداری محسوب میشد. سرعت با شروع سریع کدنویسی تعریف میشد.
اما هوشواره این معادله را عوض میکند. وقتی کد تولید کردن ارزان است، دیگر شروع سریع نویسی مزیت اصلی نیست. اگر بدون وضوح شروع کنیم، فقط ابهام را سریعتر تبدیل به کد میکنیم. در این جهان، ارتباطات دیگر مهارت نرم حاشیهای نیست؛ توانایی فنی و اصلی در مهندسی است.
به این پرسش فکر کنید: اگر آخرین پیام Slack شما منبع کد برنامه بود، کامپایل میشد یا سرور را خراب میکرد؟ این سؤال نشان میدهد که در عصر هوشواره ، توان بیان دقیق فکر اهمیت فنی پیدا میکند. اگر نمیتوانیم واضح توضیح دهیم، نمیتوانیم قابل اعتماد بسازیم.
این برای مهندسین ارشد و معماران بسیار مهم است. نقش آنها فقط بازبینی کردن کد نیست؛ نقش آنها طراحی زبان نیت، قانونها، محدودیتهاو دروازهها است. آنها باید محیطی بسازند که هوشواره بتواند سریع حرکت کند، اما در مسیر درست.
در این نوشته یک مسیر مفهومی کامل معرفی شد. ابتدا نشان داد وایبکدینگ چرا جذاب است و چرا برای ساخت نمونه اولیه ارزش دارد. سپس توضیح داده شد چرا همین روش در سیستمهای واقعی با مشکل فرضیات، پوسیدگی زمینه، عدم تطابق معماری و مسئله پاسخگویی شکست میخورد.
بعد نشان داده شد که گلوگاه مهندسی نرمافزار از پیادهسازی به نیت منتقل شده است. هوشواره سینتکس و ساختار را آسانتر کرده، اما نیاز به شفافیت، دقت و تایید را بیشتر کرده است. زبان طبیعی به انتزاع جدیدی تبدیل میشود، اما فقط اگر ساختاریافته، صریح باشد.
سپس وارونگی قدرت مطرح میشود: مشخصات باید بالاتر از کد قرار گیرد. کد دیگر نباید تنها منبع حقیقت باشد. مشخصات باید سیستم ثبت باشد و کد مصنوعی مشتقشده از آن. اگر کد و مشخصات اختلاف دارند، پیشفرض این است که کد باید با نیت همراستا شود یا مشخصات آگاهانه تغییر کند.
در نهایت اصول عملی معرفی میشوند: ویژگیهای زنده در مخزن کد، ابتدا بروزرسانی ویژگی، ویژگیهای قابل کامپایل ، شفافسازی دروازهها، EARS، تفکیک وظیفه ، بازبینی دروازهها، قانون اساسی، محدودیتهای منفی، MCP و property-basedتست. همه اینها برای یک هدفاند: تبدیل هوشواره از یک کارخانه تولید خطای سریع به یک موتور پیادهسازی قابل کنترل.
پیام آخر این که آینده کدنویسی فقط درباره تایپ سریعتر نیست. آینده درباره شفاف فکر کردن است. هوشواره میتواند کد تولید کند، اما انسان باید نیت را معماری کند. هرچه هوشواره سریعتر شود، اهمیت مشخصات بیشتر میشود. بدون مشخصات، سرعت هوشواره فقط آشفتگی را تقویت میکند. با مشخصات، همان سرعت میتواند تبدیل به اهرمی برای مهندسی شود.

پ.ن 1: توی این نوشته از کلمه هوشواره به جای هوش مصنوعی استفاده کردم. این کلمه رو اولین بار توی یک پست اینستاگرامی از @sadrafr شندیم. برعکس کلمههای مزخرفی که بعضی سازمانها با هزینههای میلیاردی میخان جایگزین کنن، به نظرم آوا و معناشناسی خوبی داشت. برای همین به سهم خودم سعی در ترویج این کلمه دارم. نمیدونم لینک به اینستاگرام بدم دچار مشکلات ف.ی.ل.ت.ر.ی.ن.گ میشم یا نه. برای همین لینک ندادم. ولی اکانت همینه به نظرم مطالبش ارزش بالایی برای دیدن دارن.
پ.ن 2: یک سال از آخرین نوشته من گذشت. یکسال خیلی سختی برای همه ما بوده. عزیزان زیادی رو بی گناه از دست دادیم. مدتها حس و حال نوشتن و کاری انجام دادن به این شکل نبود. شاید هنوز هم نیست و با جای خالیشون هیچ وقت مثل قبل نشه.