من این مطلب رو قبلا تو وبلاگ خودم نوشته بودم. اما چون فعلا چیز بهتری برای نوشتن نداشتم تصمیم گرفتم همین مطلب رو اینجا هم بذارم.
این روزها احتمالا اسم ریکامندر سیستم و یا سیستم توصیهگر رو بیشتر از قبل میشنویم. از اونجایی که الان بیشتر از یکساله که روی این سیستمها کار میکنم، به نظرم اومد بد نباشه در یک مطلب این سیستمها رو خلاصه توضیح بدم و کمی از انواع روشهایی که این سیستمها استفاده میکنند بگم.
در سالهای اخیر تعداد محصولات و کالاهایی که فروشندهها و سرویسدهندههای اینترنتی ارائه میکنند حسابی افزایش یافته. شرکتها محصولات بیشتری تولید میکنند تا نیازهای بیشتری از مشتریها رو برطرف کنند. این اتفاق از طرفی باعث میشه حق انتخاب کاربر بالا بره و از طرفی حق انتخاب رو برای کاربر خیلی سخت میکنه
ریکامندر سیستمها یا سیستمهای توصیهگر، تکنولوژیهای به سرعت رو به توسعهای هستند که به کاربرها و مشتریها کمک میکنند تا محصولاتی که براشون جالبه یا بهش نیاز دارند رو به راحتی پیدا کنند. این سیستمها در فروشگاههای اینترنتی کاربرد زیادی دارند، چون این فروشگاهها حق انتخاب زیادی به کاربر میدن و انتخاب رو براش سخت میکنند. در حقیقت این سیستمها هم برای کاربر و هم برای فروشنده ارزش افزوده دارند؛ به کاربر کمک میکنند تا محصول مورد نیازش رو پیدا کنه و به فروشنده کمک میکنند تا تبلیغات بهتری داشته باشد و به طور هدفمندتر محصولش رو به مشتریها توصیه کنه. معمولا یک سیستم توصیهگر محصولات را به وسیله تخمین امتیاز یا ساخت لیست مرتب شده از محصولات برای هر کاربر توصیه می کند.
رویکردهای مورد استفاده در سیستمهای توصیهگر به دو دسته کلی تقسیم میشوند:
۱. پالایش مشارکتی Collaborative Filtering
۲. محتوا محور Content Base
در زیر هر کدام از رویکردهای زیر را به اختصار توضیح میدم.
رویکرد پالایش مشارکتی، رویکردی مشهور و شناخته شده است و بسیاری از سیستمهای توصیهگر بر مبنای این روش کار میکنند. پالایش مشارکتی از قانون بسیار سادهای زندگی میکند: کاربرها تمایل دارند محصولاتی را بخرند که کاربرهای با سلیقه مشابه آنها خریدهاند. برای مثال در جدول زیر کاربر U1 احتمالا تمایل دارد تا محصول I2 را بخرد، زیرا کاربرهای U1 و U4 محصول I1 را میپسندند و کاربر U4 امتیاز بالایی به محصول I2 داده است.
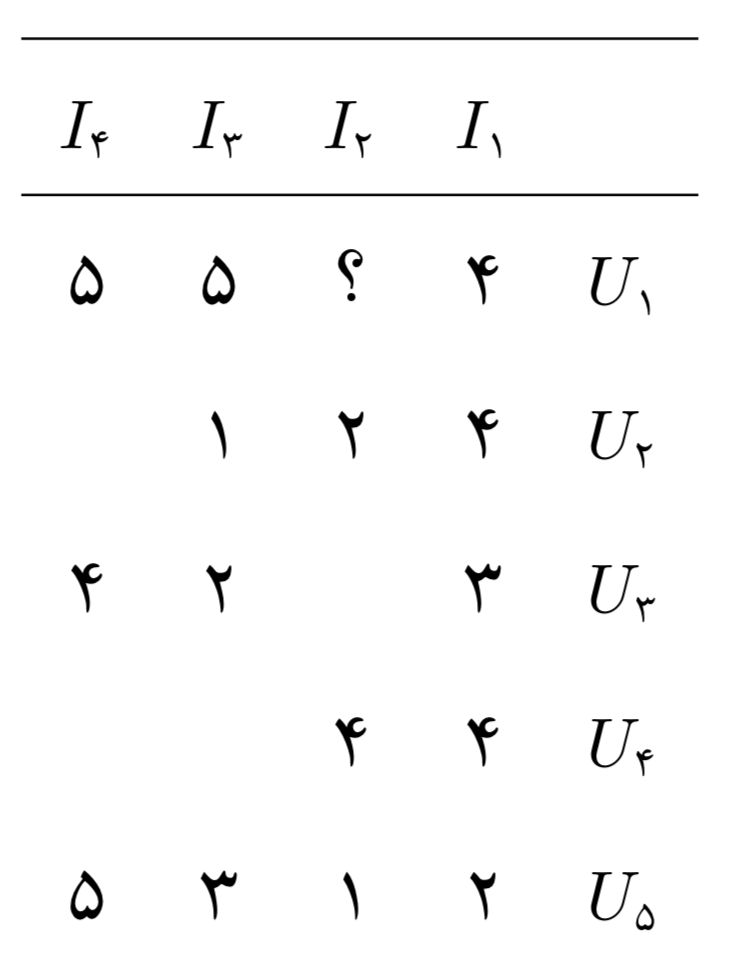
پالایش مشارکتی روشهای مختلفی دارد که دو روش اصلی آن یعنی روش همسایه محور و تجزیه ماتریسی را در ادامه توضیح میدم.
روشهای همسایه محور ارتباط بین محصولات و یا کاربرها را محاسبه میکنند. این روش خودش میتونه دو حالت داشته باشه: در حالت محصول محور، امتیاز تخمینی یک کاربر به یک محصول، براساس امتیازهای همان کاربر به محصولات مشابه (همسایه) آن محصول تخمین زده میشه. در حالت کاربرمحور، در تخمین امتیاز یک کاربر به یک محصول، به کاربرهایی با علایق مشابه آن کاربر رجوع میشود و از امتیازهای داده شده توسط آنها به آن محصول برای تخمین امتیاز کاربر مورد نظر استفاده میشود.
روش همسایهمحور دو مرحله اصلی دارد: محاسبه شباهت و سپس تخمین. گفتم که در هر دو حالت کاربر محور و محصول محور، ما نیاز به محاسبه شباهت داریم؛ یا بین کاربرها و یا بین محصولات. این محاسبه شباهت به روشهای مختلفی میتونه انجام شه. روشهایی مثلهمبستگی پیرسون یا شباهت کسینوسی معروفترین این روشها هستند.
در روش پالایش مشارکتی همسایه محور، برای اینکه عمل توصیه انجام شود یا رتبهی کاربر u به محصولی تخمین زده شود، از شباهتهای به دست آمده برای ساخت مجموعهای از کاربرها که به کاربر u شبیه هستند استفاده میشود. سپس تخمین رتبه کاربر u را میتوان با استفاده از امتیازهای داده شده توسط این مجموعه از کاربرهای مشابه به دست آورد.
روش همسایه محور مزیتهای زیر را دارد:
از آنجایی که این روش به شدت به دادهی مشترک بین کاربرها وابسته است، زمانی که دادهها پراکنده هستند و داده مشترک زیادی بین کاربرها وجود ندارد، گاهی شباهتهای محاسبه شده و توصیه حاصل از این روشها قابل اعتماد نخواهد بود.
روشهای تجزیه ماتریسی روشهای دیگری از رویکرد پالایش مشارکتی هستند که در عمل بهترینند. من سعی میکنم به بهترین حالتی که میتونم این روش رو توضیح بدم.
ما معمولا در سیستمهای توصیهگر مجموعهای از کاربرها و مجموعهای از محصولات داریم. هر کدام از این کاربرها ممکن است به یک یا چند محصول امتیاز داده باشند. مثلا سایت IMDB رو فرض کنید. این سایت احتمالا میلیونها کاربر و هزاران فیلم داره و هر کدام از این کاربرها به چند فیلم امتیاز دادهاند. میتونیم این امتیازها رو با یک ماتریس نشون بدیم. به این ترتیب که هر سطر بیانگر یک کاربر و هر ستون بیانگر یک فیلم باشه. حالا سطر i و ستون j بیانگر امتیاز کاربر iام به فیلم jام است.
حالا برای لحظهای ماتریس بالا رو فراموش کنید. تصور کنید که من یک سایت شبیه به IMDB دارم و میخوام حدس بزنم هر کاربر ممکنه چه فیلمهایی رو دوست داشته باشه. یکی از اولین روشهایی که به ذهن میرسه چیه؟ من بیام برای هر فیلم چند ویژگی در نظر بگیرم. مثلا ژانر، سال تولید، کارگردان، بازیگرا، زبان فیلم، کشور ساخت فیلم و غیره. حالا بیام از هر کاربر هم بپرسم که نظرت در مورد این ویژگیها چیه؟ مثلا بپرسم علی تو چه ژانر فیلمی دوست داری؟ کارگردان محبوبت چیه؟ فیلمایی که میبینی معمولا به چه زبانیه و همینجوری نظرش رو در مورد همه این ویژگیها بفهمم. حالا خیلی ساده بیام بر مبنای اطلاعاتی که از علی و از همه فیلمها دارم، بگم علی احتمالا چه فیلمی رو دوست داره و اون رو بهش پیشنهاد بدم.
در عمل همچین کاری غیر دقیق، سخت و بسیار هزینه بره. پس چیکار کنیم؟
خب، حالا دوباره بریم سراغ ماتریس امتیازها که تو دو تا پاراگراف قبل تعریفش کردیم. من با این ماتریس یه کار جالب میکنم؛ ویژگیهایی که نمیدونم چی هستند رو ازشون استخراج میکنم و نظر هر کاربر رو بدون اینکه ازش سوالی بپرسم در مورد این ویژگیها میفهمم! برای مثال میگم که خب، من حدس میزنم محصولات من ۱۰۰ ویژگی داشته باشند. اسم این ویژگیها رو میذارم latent factor یا عاملهای نهان (نهان هستند برای اینکه نمیدونیم چی هستند!) حالا باید هر محصول رو تبدیل کنم به یک بردار ۱۰۰بعدی که هر بعد نشانگر مقداری است که آن محصول آن ویژگی را شامل میشود. به همین ترتیب کاربرها را هم به بردارهای صد بعدی تعریف میکنیم که هر بعد نشانگر این است که این کاربر چقدر به ویژگی متناظر با این بعد علاقه دارد. حالا اگر بیایم این دو بردار رو ضرب داخلی کنیم؛ یعنی المان های نظیر رو با هم ضرب کنیم و حاصل رو جمع کنیم، در واقع امتیاز اون کاربر به اون محصول را تخمین زدیم! هیجان انگیز نیست؟
برای رسیدن به بردارهای ویژگی، باید ماتریس امتیاز رو به دو ماتریس رتبه پایین تجزیه کنیم. برای این کار از روشی مشابه SVD استفاده میکنیم. برای اونهایی که ریاضی و یادگیری ماشین رو دوست دارند کمی وارد جزئیات میشم:
ما دو تا بردار داریم، به اسم های p و q که به ترتیب متعلق به کاربر و محصول هستند. میخوایم این دو بردار رو طوری بسازیم که ضرب داخلیشون تا حد ممکن شبیه به امتیازی بشه که کاربر صاحب بردار p یعنی u به محصول صاحب بردار q یعنی i داده. برای اینکار کافیه معادله زیر رو کمینه کنیم:
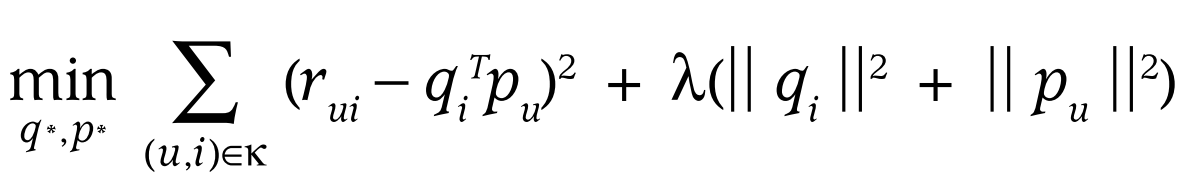
در این معادله r امتیاز کاربر u به i است و لاندا پارامتر رگولاریزیشن است. با کمینه کردن این معادله حاصلضرب pq تا حد ممکن به r نزدیک میشود و این چیزی است که به دنبال آن هستیم. بعد از اینکه این معادله رو به الگوریتمهایی مثل Gradient Descent کمینه کردیم، برای هر کاربر و محصول به یک بردار میرسیم. حالا برای تخمین امتیاز یک کاربر به یک محصول، تنها کافیه که بردارهای متتاظر با اونها رو در هم ضرب داخلی کنیم. البته معمولا معادله به این سادگی نیست و پارامترهای بایاس و یا دادههای غیر مستقیم هم وارد آن میشوند. من برای اینکه این نوشته از فرم پست وبلاگی خارج نشه خیلی وارد جزییات بیشتر ریاضی نمیشم. اگر خواستید در مورد این روش بیشتر و دقیقتر بخونید میتونید به مقالات این حوزه مثل این یک نگاهی بندازید.
برای اینکه این مطلب طولانیتر از این نشه وارد سیستمهای توصیهگر محتوا محور نمیشم. اگر از این نوشته استقبال شد و علاقهمند بودید، میتونید تو کامنتها بگید تا در این زمینه بیشتر و دقیقتر بنویسم.