
تو این پست میخواییم یه نگاه ساده ولی کاربردی به دو مکانیزم locking داشته باشیم. اول از همه به این سؤال جواب بدیم که locking چیه و چرا باید ازش استفاده کنیم؟
اکثر کسایی که رشته دانشگاهیشون کامپیوتر بوده حتماً تو دانشگاه با مباحث locking یه آشنایی کلی پیدا کردن که بیشتر تو درس سیستمعامل بهش پرداخته میشد، اما خیلی جاهای دیگه هم کاربرد داره. به طور کلی وقتی چند process یه resource رو با هم به اشتراک میزارن، سر اینکه تو یک لحظه خاص کدومشون میتونن به اون resource دسترسی داشته باشن دعواشون میشه. Locking یه پروتکلی هست که با تعریف یک سری قوانین جلوی این دعوا رو میگیره .
قبل از اینکه بریم تو دل قضیه، بیایید چندتا مفهوم رو باهم مرور کنیم:
مباحثی که تو ادامهی این نوشته میاد بیشتر تمرکزش روی دیتابیسهای Mysql و PostgreSQL هست، ولی برای اکثر دیتابیسهای مبتنی بر زبان SQL صادق هست.
تو هر کدوم از قوانینی که بالا بهشون اشاره کردیم حرف از تراکنش(transaction) هست، حالا چی هست این تراکنش؟ تو اکثر دیتابیسهایی که SQL Compatible هستن، شما وقتی میخوایین مجموعهای از کارها رو باهم انجام بدین و نمیخوایین قوانین ACID رو زیر پا بگذارین از transaction استفاده میکنین. نحوهی استفادش هم به این صورته:
یعنی هر تراکنشی اول شروع میشه و یک سری کارها توش انجام میشه و بعدش تثبیت میشه. حالا با یه مثال ساده ببینیم که استفاده از تراکنش برای رعایت قوانین ACID کافی هست یا نه!
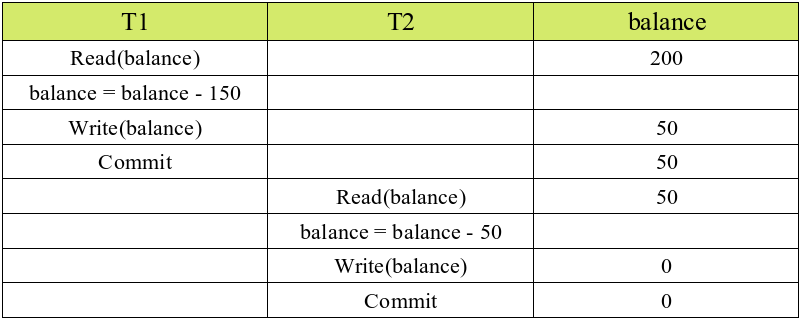
سیستم بانکی رو در نظر بگیرید که میشه توش موجودی یه حساب رو افزایش داد و یا از اون حساب برداشت کرد. حالا تصور کنید که شما یک حساب بانکی دارید که مبلغ ۲۰۰ هزار تومان موجودی دارد. شما یک خرید اینترنتی دارید و مراحل Checkout یک محصول رو داخل یک سایت انجام دادهاید و حالا رسیدهاید به مرحلهی پرداخت، قیمت این محصول ۱۵۰ هزار تومان هست. همزمان با این کار شما، خانومتون هم با کارت بانکیتون در حال خرید هست. شما مشخصات کارت بانکیتون رو تو درگاه پرداخت وارد میکنین و دکمهی پرداخت رو میزنین، تو همون لحظه خانومتون هم یه خرید به مبلغ 50 هزار تومان انجام میده و از کارت شما برای پرداخت استفاده میکنه. حالا دو درخواست کاهش اعتبار به سیستم بانکی رسیده، مراحلی که تو دیتابیس اتفاق میافتن به این شکله:

هر کدوم از درخواستهای کاهش اعتبار مراحل زیر رو انجام میدن:
به نظر میرسه که ما کارمونو درست انجام دادیم، چون از transaction استفاده کردیم و اگه موقع خوندن یا نوشتن به مشکل بخوریم کل تراکنش رو rollback میکنیم و Atomicity عملیات حفظ میشه. از طرف دیگه، قوانین Durability و Isolation هم توسط خود دیتابیس انجام میشه، چرا که بعد از نوشتن مبلغ نهایی در تراکنش اول، تراکنش دوم ازش تأثیر نپذیرفت و بعد از commit تغییرات ما تثبیت شد. ولی به نظر میرسه که Consistency دادهها حفظ نشده، چون اگه تراکنشها درست اجرا میشدن، موجودی نهایی حساب میبایست صفر میشد.
مشکل کجاست؟ چیزی که اینجا رعایت نشده اصل Serializability هست. دیتابیسهایی مثل Mysql , PostgreSQL تو عملیات نوشتن به صورت خودکار قفل گذاری انجام میدن و عملیات رو به صورت ترتیبی انجام میدن، یعنی یک حالت صف مانند درست میشه و تغییرات یکی پس از دیگری اعمال میشه. اما تو عملیات خواندن هیچ قفل گذاری انجام نمیشه، مشکلی که ما اینجا داریم همینه، چون دو تا تراکنش همزمان یک مقدار رو از دیتابیس خوندن و بر اساس مقداری که خوندن کارهایی رو انجام دادن و بعد تثبیت شدن. تو یه حالت ایدهآل تراکنشها باید به شکل زیر اجرا میشدن:
پس اگه تراکنشها به صورت سری اجرا بشن مشکلی پیش نمیاد. اما چطور باید به دیتابیس این رو بفهمونیم؟! دو تا روش برای انجام این کار وجود داره که هر کدوم تو موقعیت خاصی کاربرد دارن.
تو این روش خیلی بد بینانه به قضیه نگاه میکنیم و اینجوری در نظر میگیریم که در هر لحظه که دادهای خونده میشه، با احتمال خیلی زیاد، یک تراکنش دیگه داره رو این داده کاری رو انجام میده. روش کار هم به این صورت هست که شما موقع خوندن اطلاعات به دیتابیس میگین که یه قفل روی این داده بزار و تا من نگفتم به کسی اجازهی خوندن و نوشتن رو این داده رو نده. البته ما دو نوع قفل داریم، یکیش انحصاری هست که اجازهی هیچ کاری رو به تراکنشهای دیگه روی یک داده مشترک نمیده و مدل دومش هم قفل اشتراکی هست که اجازه خواندن میده ولی نوشتن رو محدود میکنه.
تو مثال بالا، ما به یه قفل انحصاری نیاز داریم، برای این کار تو Mysql و PostgreSQL یه مدل query وجود داره که به این صورت هست:
نکتهی مهمی که وجود داره این هست که دیتابیس تا زمانی که تراکنش تثبیت نشه قفل رو آزاد نمیکنه، پس حتماً باید از تراکنش استفاده کنیم و کارای commit کردنش رو هم به درستی انجام بدیم. پس برای مثالی که بررسی کردیم، شبه کدش این شکل هست:
این روش برای مواقعی که تعداد نوشتن روی یک قلم دادهای زیاد باشد و احتمال بروز inconsistency زیاد باشد کاربرد دارد. مشکل اصلی این روش کند کردن روند خواندن همچنین احتمال بروز deadlock هست. در مورد deadlock تو پستهای بعدی بیشتر توضیح میدم.
این روش خیلی خوشبینانه به مسأله نگاه میکنه و تصور میکنه که وقتی قلم دادهای خونده میشه، تراکنش دیگهای رو این داده تغییراتی ایجاد نمیکنه. روش کارش به این صورته که توی هر تیبل، به ازای هر رکورد، یه فیلد مشخص کنندهی version اون رکورد رو هم داریم. معمولاً این فیلد همان updated_at معروفی هست که تو اکثر framework ها هم به صورت پیشفرض وجود داره. تو هر عملیات نوشتن، این فیلد رو یه نسخه میبریم بالاتر، مثلاً اگه یه فیلد عددی ساده گذاشتیم، یه واحد بهش اضافه میکنیم. مراحلی که باید انجام بدیم به این صورته:
پس برای مثالی که قبلاً زده بودیم، این شبه کد رو داریم:
البته این یه پیادهسازی ساده میتونه باشه و باید مثلاً max_retry داشته باشیم که اگه بیشتر از یه مقداری این کار رو تکرار کردیم و موفق نشدیم به شرایط ایدهآل برسیم، خطا برگردونیم و بگیم مثلاً دوباره تلاش کنید.
مشکلی که این روش داره این هست که اگه تعداد write زیاد باشه ممکنه یک سری از تراکنشها به خاطر مشکلی تحت عنوان starvation یا همون قحطی زدگی به خطا بخورن. به همین خاطر این روش برای شرایطی مناسبه که تعداد عملیات write کم هست ولی تعداد read خیلی زیاد هست. سرعت عملیات read تو این روش خیلی بالاست و اگه تو شرایط درستی ازش استفاده بشه میتونه تأثیر زیادی تو performance نهایی اپلیکیشنتون داشته باشه.
منابع: