
چند روز پیش مسئلهای پیش آمد که باید دادههای سایت اداره کل حقوقی قوه قضاییه کرول شود. اما چون این سایت که با فریمورک ASP MVC پیادهسازی شده و برای جلوگیری از CRAWL از یک توکن در صفحه به صورت hidden استفاده میکند، امکان کرول مستقیم API آن وجود نداشت و باید حتما صفحه ابتدا باز شده و پس از بررسی آن مقدار هش، سپس درخواستهای API ارسال شود. این چالش فرصتی فراهم کرد که مدل جدید Claude 3.7 sonnet را به صورت thinking امتحان کنم.
ابتدا پروژه را در گیت ساختم و چند فایل خالی به عنوان ساختار اولیه ایجاد کردم. سپس برای ورودی و خروجی API با استفاده از مدل claude-3.7-sonnet-thinking در crusor مدلهای pydantic ساختم.
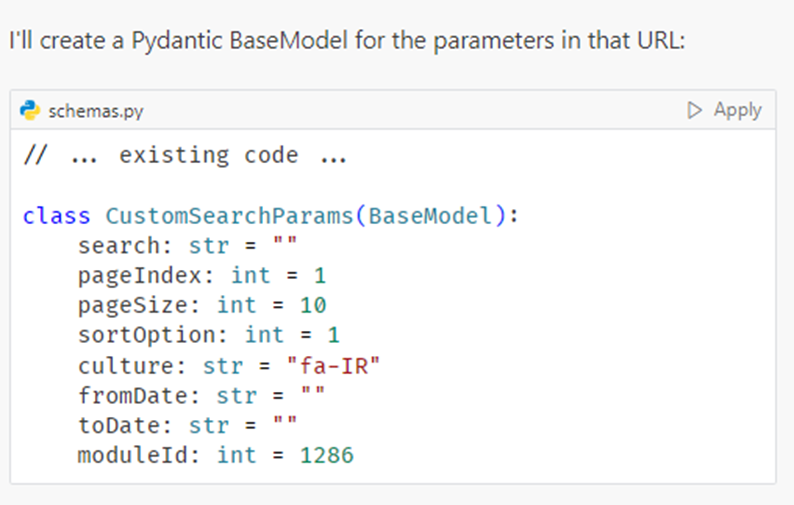
سپس فرایند کرول را با یک پرامپت به شرح زیر در تب CHAT Cursor نوشتم.
I want to crawl the search of this site with url : edarehoquqy.eadl.ir
After the page is showed up, the value hidden input with name “__RequestVerificationToken” in html is set (xpath: //input[@name="__RequestVerificationToken"]). After that, we fill “pageSize”, “sortOption”, “fromDate”,”toDate”,”pageIndex”. Then this api is called in this style: curl 'https://edarehoquqy.eadl.ir/API/Mvc/IdeaProject.IdeaSearch/CustomSearch/Search?search=&pageIndex=2&pageSize=10&sortOption=1&culture=fa-IR&fromDate=&toDate=&moduleId=1286' \
-H 'accept: */*' \
-H 'accept-language: en-US,en;q=0.9' \
-b 'dnn_IsMobile=False; .ASPXANONYMOUS=uB40DZf5_NHwQ6aolTxQMcopdf_gqFz-o7CbtkPDHB9KmjMhV0xZhgxz5tqpX7sMgw1Dfh4yNSLkdQZhNu5cnxDmuBBb_ryyXKqJrZdbyL2MORmw0; __RequestVerificationToken=gpTij-n68kJ0jQq4n84dyEEz1t9p8z6CGMm5wMLP8Mv-jE6jtE73ViUB_FHYp95Gxz19ew2' \
-H 'moduleid: 1286' \
-H 'priority: u=1, i' \
-H 'referer: https://edarehoquqy.eadl.ir/%D8%AC%D8%B3%D8%AA%D8%AC%D9%88%DB%8C-%D9%86%D8%B8%D8%B1%DB%8C%D8%A7%D8%AA-%D9%85%D8%B4%D9%88%D8%B1%D8%AA%DB%8C/%D8%AC%D8%B3%D8%AA%D8%AC%D9%88%DB%8C-%D9%86%D8%B8%D8%B1%DB%8C%D9%87' \
-H 'requestverificationtoken: SHp8WUNLYG4Rg-ySgF90wOEOR1Eqx7yTIwncLFgjHQji4N2Ugyv98O1I5Eukf8i43H4KNQ2' \
-H 'sec-ch-ua: "Not(A:Brand"v="99", "Google Chrome"v="133", "Chromium"v="133"' \
-H 'sec-ch-ua-mobile: ?0' \
-H 'sec-ch-ua-platform: "Windows"' \
-H 'sec-fetch-dest: empty' \
-H 'sec-fetch-mode: cors' \
-H 'sec-fetch-site: same-origin' \
-H 'tabid: 495' \
-H 'user-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/133.0.0.0 Safari/537.36' \
-H 'x-requested-with: XMLHttpRequest' Now implement the crawler class (name the file handler.py) to get input options and handle these operation and pagination based on result (more:true or false). Then write unit test.
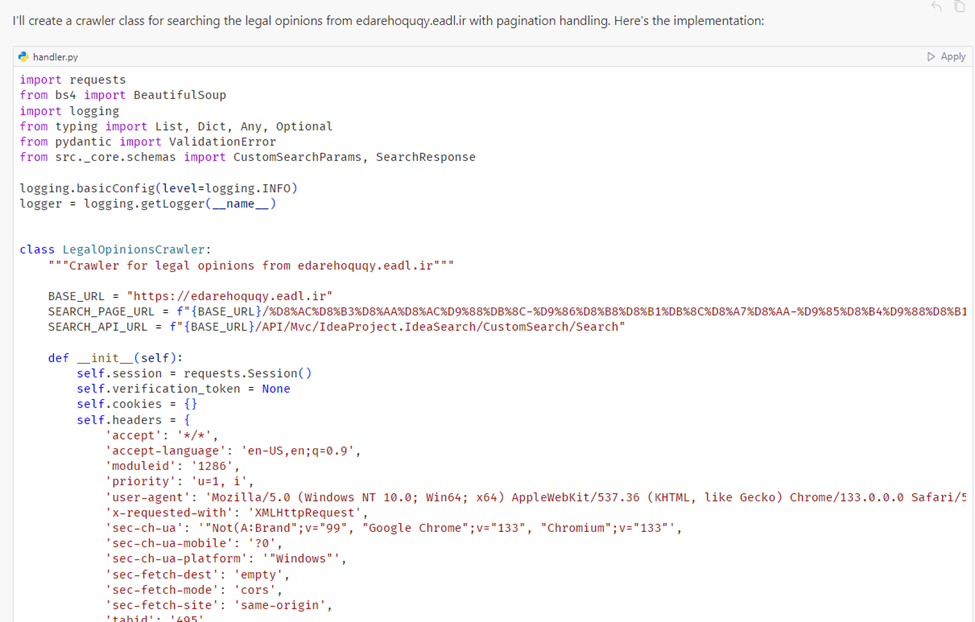
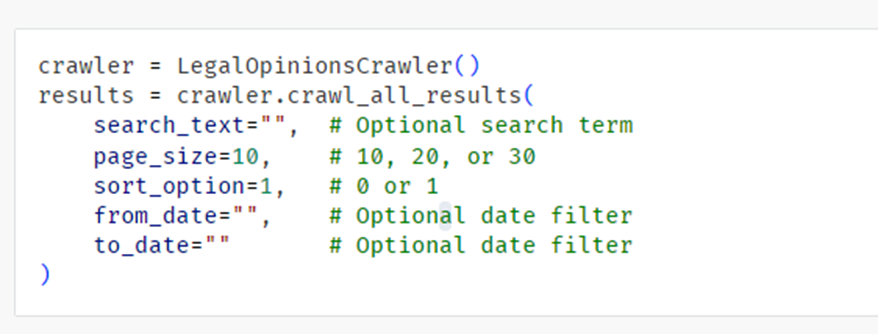
البته من به همین بسنده نکردم و در پرامپت بعدی گفتم با HTTPX ریفکتورشده بنویسه. تنها کاری که بعد از هر جواب، انجام دادم صرفا زدن Apply بود. خیلی شیک و مجلسی !
صرف نظر از تستی که نوشته بود، برای تست خودم یک فایل ساختم و کدی که پیشنهاد داده بود را کپی و اجرا کردم. در کمال ناباوری به درستی اجرا میشد. فقط یک چیزی کم داشت. با توجه به اینکه ممکنه در حین کرول خطا بدهد، نیاز است هر صفحه که کرول شد محتوای آن ذخیره شود. با پرامپت زیر بهش توضیح دادم و پس از خروجی، apply زدم!
change handler to also save each page result as json (utf8 and indent 4) to OUTPUT_PATH that defined in project_settings.
نکته جالب این بود که با یک فرمت خوانا نامگذاری فایلها را براساس ورودیهای کاربر نوشته بود که ممکن بود این نیاز را بعدا برایش پرامپت کنم.
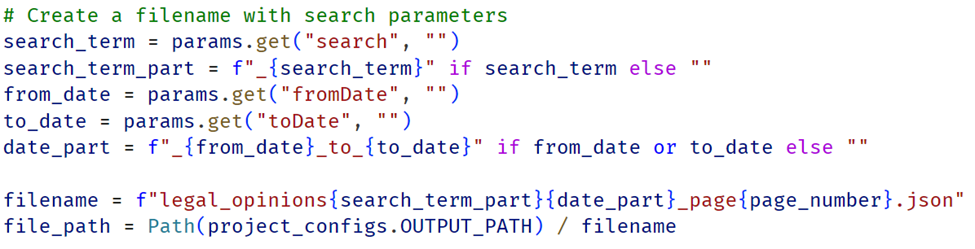
هنوز یک مسئلهای باقی مانده بود. اینکه اگر دوباره بخواهیم کرولر را اجرا کنیم بتواند از جایی که خطا خورده است ادامه دهد(آخرین فایل ذخیره شده) و از ابتدا شروع نکند. با یک پرامپت این مورد هم اضافه شد.
refactor handler to skip the pages that already saved in output_path and continue to next pages.
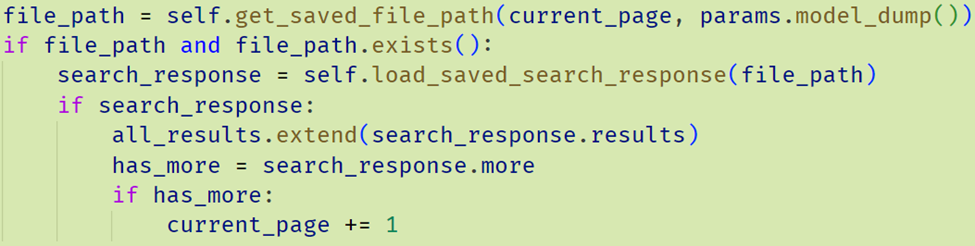
نمونه از کد اضافه شده:
پروژه نهایی در این لینک گیتهاب موجود است:
پ ن 1: فکر کنم نیازی به گفتن نباشه که README رو هم با claude-3.7-sonnet-thinking نوشتم :دی
پ ن 2: در این تست صرفا از تب CHAT استفاده کردم و هنوز حالت Composer و Agent را تست نکردم.