بیاید رک باشیم:
من چرا باید Saga رو یاد بگیرم؟!
مگه همون Transaction دیتابیس کافی نیست؟
یه زمانی بود…
یه سرویس داشتی، یه دیتابیس، و یه BEGIN/COMMIT همهچی رو جمع میکرد.
ولی الان که رفتیم سمت Microservices، هر سرویس دیتابیس خودش رو داره، هر کدوم latency و failure خودش رو داره، و “همه باهم commit شن” دیگه اونقدرها ساده نیست.
پس مسئله اصلی چیه؟
وقتی یک کار business چند مرحلهست و هر مرحله توی یک سرویس جدا انجام میشه، چطور مطمئن میشی سیستم تو وضعیت داغون گیر نمیکنه؟
اینجاست که Saga میاد وسط.
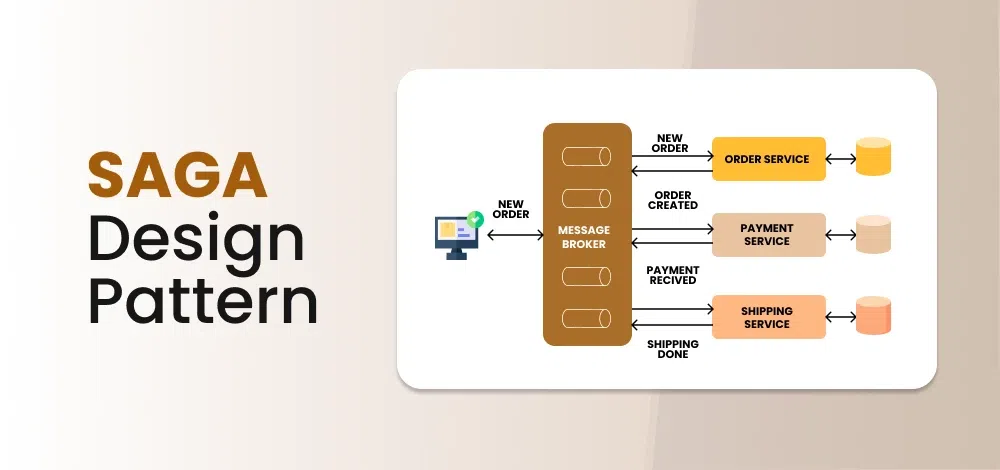
Saga یه الگوی طراحی برای مدیریت یک فرایند چندمرحلهایه که هر مرحلهاش یک Local Transaction توی یک سرویسه.
هر step “تو سرویس خودش” commit میشه.
اگر وسط کار fail شدی، به جای rollback واقعی، از Compensation استفاده میکنی.
یعنی چی؟
یعنی برگشتن به عقب با “عملیات جبرانی”.
مثلاً:
Inventory رزرو کردی؟
جبرانش میشه Release کردن رزرو.
Payment charge کردی؟
جبرانش میشه Refund کردن (یا void کردن بسته به حالتها).
Shipment ساختی؟
جبرانش میشه Cancel کردن shipment.
این دقیقاً همون چیزیه که تو production باعث میشه سیستم “قابل کنترل” بمونه، نه اینکه failها تبدیل به دیتای کثیف و وضعیتهای نصفه نیمه بشن.
Saga بهت میگه:
به جای اینکه دنبال strong consistency بین سرویسها باشی (که یا نمیشه یا خیلی گرونه)، برو سمت eventual consistency ولی با قواعد و کنترل.
نتیجه عملیش:
کمتر شدن orderهای گیر کرده
کمتر شدن “پشتیبانی دستی”
کمتر شدن شرایطی که باید SQL بزنی ببینی چی شد
و مهمتر از همه: رفتار قابل پیشبینی در زمان failure
این قسمت رو خیلیها نمیگن، ولی حداقل باید بدونی:
Saga جادو نیست.
Consistency رو “تغییر شکل” میده، حذفش نمیکنه.
Compensation همیشه “کامل” نیست.
مثال: وقتی پول واقعاً از حساب رفت، برگشتش ممکنه چند ساعت طول بکشه. این یعنی طراحی حالتهای میانی خیلی مهمه.
برای بعضی دامنهها، strong consistency واقعاً لازم میشه.
اونجا ممکنه اصلاً معماری سرویسهات یا boundaryها نیاز به بازنگری داشته باشه.
اینجا دقیقاً جاییه که داستان واقعی شروع میشه.
هر سرویس با eventها تصمیم میگیره قدم بعدی چیه.
مثلاً:
OrderCreated → InventoryReserveRequested
InventoryReserved → PaymentChargeRequested
PaymentCharged → ShipmentCreateRequested
مزیتها:
ساده و سبک برای flowهای کوتاه
coupling کمتر به orchestrator مرکزی
عیبها:
وقتی flow بزرگ میشه، سیستم تبدیل میشه به “یه عالمه event که هیچکس نمیدونه کل داستان چیه”
دیباگ و مشاهده end-to-end سختتر میشه
تغییر flow تو آینده دردناکتره
یک orchestrator (یک سرویس یا workflow engine) مسئول state و ترتیب stepهاست.
مزیتها:
کنترل و observability بهتر
تغییر flow سادهتر
retry/timeout/timerها متمرکزتر
عیبها:
نیاز به طراحی درست orchestrator
اگر بد نوشته بشه، گلوگاه میشه
جمعبندی خودمونی:
اگه flow واقعاً business critical و چندمرحلهایه، Orchestration معمولاً production-friendly تره.
فرض کن داریم:
Order Service
Inventory Service
Payment Service
Shipping Service
Flow:
Order ایجاد میشه (و میره به حالت PENDING)
Inventory رزرو میشه
Payment شارژ میشه
Shipping ساخته میشه
Order میره به حالت CONFIRMED
حالا اگر Payment fail شد چی؟
Inventory رو release کن
Order رو ببر CANCELLED یا FAILED_PAYMENT
اگر Shipping fail شد چی؟
Refund payment (یا mark as refund pending)
Release inventory
Order رو ببر FAILED_SHIPPING
نکته:
اینجا دقیقاً همونجاست که “state” اهمیت پیدا میکنه.
تو باید به وضوح stateهای میانی رو تعریف کنی، وگرنه هر failure یه حالت جدید و ناشناخته میسازه.
اینها اون چیزیه که از “Saga روی کاغذ” جدا میکنه از “Saga که پول درمیاره”.
چون پیام duplicate میاد. retry میخوری. consumer دوباره اجرا میشه.
اگر idempotent نباشی، دو بار پول میکشی، دو بار shipment میسازی، یا دو بار رزرو میکنی.
بدونش end-to-end tracing نداری.
و بدون tracing یعنی production فقط حدس و گمان.
saga_id
Retry کورکورانه یعنی فشار بیشتر روی سرویس down شده.
Backoff و circuit-breaker و سقف retry خیلی مهمه.
سناریوی معروف:
دیتابیس commit شد ولی event منتشر نشد.
این یعنی system state تغییر کرد ولی بقیه سرویسها نفهمیدن.
Outbox این مشکل رو با “ذخیره event کنار تراکنش” حل میکنه.
حتی اگر Kafka داری، حتی اگر دقیقاً once رو دوست داری… واقعیت اینه که همیشه “at least once” رو باید فرض کنی.
Refund کردن پول همیشه ممکنه async باشه.
Release inventory شاید سریع باشه.
Shipping cancel شاید محدودیت داشته باشه.
پس compensation تو باید state-aware باشه.
حداقل stateها رو واضح کن:
PENDING
INVENTORY_RESERVED
PAYMENT_CHARGED
SHIPPING_CREATED
CONFIRMED
FAILED_*
COMPENSATING
این باعث میشه وقتی fail شدی، دقیق بدونی کجا بودی.
Saga بدون observability یعنی تو production کور هستی.
log با saga_id
metrics برای success/failure هر step
trace برای طول کشیدن stepها
اینها مستقیم روی SLA و هزینه تیم اثر میذارن.
Saga خوبه وقتی:
فرایند چندمرحلهای business داری
failureها “طبیعی” هستن و باید مدیریت بشن
میخوای سیستم resilient باشه نه fragile
Saga گزینه بدیه وقتی:
کل فرایند باید strong consistency آنی داشته باشه (مثل بعضی سناریوهای مالی/حساس)
compensation معنی نداره یا غیرممکنه
boundary سرویسها اشتباهه (گاهی باید سرویسها رو merge کنی یا domain رو درست ببری)
حالا این همه حرف… پیادهسازیش چیه؟
اینجا ابزارهایی مثل Temporal ارزش واقعی میدن:
چون orchestration رو تبدیل میکنن به Workflowهای durable با:
retry داخلی
timeout/timer داخلی
state management مطمئن
و اجرای قابل اعتماد حتی اگر worker ریستارت بشه
یعنی خیلی از دردهای “خودمون orchestrator بنویسیم” رو ازت میگیره.
Saga قرار نیست سیستم رو ساده کنه.
قرار نیست failure رو حذف کنه.
Saga کمک میکنه failure “قابل مدیریت” بشه.
و این دقیقاً همون چیزیه که تو production ارزش میده.