سلام من امیر حسین واحد هستم و در این پست می خوام یه گروهی از هنرمندان خیلی باحالی رو بهتون معرفی کنم که فکر کنم کسی تا به حال در یوتیوب فارسی ازشون حرفی نزده. خوشحال میشم به خود کانال هم سر بزنید و نسخه ویدئو ای این پست رو مشاهده کنید.

https://www.youtube.com/watch?v=ou_JMGHtZWk
مثل همیشه داشتم یوتوب می دیدم و به کانال موزه هنر های معاصر MOMA برخوردم و در داخلش یه ویدئو ای بود با عنوان چگونه ماشین ها می توانند دنیا رو متصور بشن؟

https://www.youtube.com/watch?v=G2XdZIC3AM8&t=26s
در طی ویدئو، ما به نمایشگاهی دعوت میشم که آثار اون در نگاه اول یه سری قاب های هستن که تصاویر متحرکی عجیبی رو به ما نشون میدن. بعدا زمانی حیرت زده میشیم که می فهمیم این تصاویر حاصل رویاپردازی مدل های هوش مصنوعی ه. تصاویر خیره کننده است و حتی توی نمایشگاه یه کنسولی هست که میشه به صورت حضوری داده های اولیه مدل رو عوض کرد و در دل یه رویایی جدید فرو رفت.
اما برای اینکه بتونیم از نحوه تولید تصاویر یکم بیشتر سر در بیاریم، احتیاج داریم یکم در مورد مدل های که تصویر تولید می کنن بیشتر بدونیم. شبکه های عصبی ای که متولی تولید این تصاویر هستن، معمولا به صورت supervised این کار رو انجام میدن. اگر خیلی ساده بخوام این مورد رو برای خودم توضیح بدم که بهتر بفهمم (من به مقام شامخ شما بیننده عزیز در حوزه علم و دانش جسارت نمی کنم)، باید بگم که، میان در قالب یک فرآیند خیلی خیلی طولانی تصاویر مختلفی از یک سیب رو به عنوان مثال، به یک شبکه عصبی معرفی می کنن و بهش میگن، این سیب زرده، این سیب قرمزه و غیره. در نهایت تصویر یه سیب رو بهش میدن و در انتها ازش می پرسن این چیه ؟ اونم میگه سیب و خیلی خیلی هنر کنه میگه چه جور سیبه این نمونه. البته خود همین جواب دادن هم در قالب درصد می سنجن، یعنی اینکه با توجه به آموزش های که دیده چه قدر می تونه در نهایت پاسخ درستی به سوالات ارائه بده.
جالبی نمایشگاهی که داریم ازش حرف می زنیم اینه که هر اثر از دو بخش تشکیل شده، در بخش اول، یه شبکه عصبی از مدل supervised وجود داره که در این نمونه، از داده های تصاویر آثار MOMA تغذیه و مورد آموزش قرار گرفته که خروجی این کار یه فضای سه بعدی ه که میاد آثار رو بر اساس شباهت های که به هم دارن دسته بندی می کنه و شما می تونید با یک دسته پلی استیشن در این فضا سه بعدی شنا کنید و موقعیت خودتون در این فضا رو جا به جا کنید. در بخش دوم که در ورودی خودش، موقعیت شما در این فضای سه بعدی رو دریافت میکنه، میاد فاصله سنجی انجام میده و بین آثاری که در این مدل سه بعدی گنجانده شده اند، سعی می کنه یه نقطه اشتراک پیدا کننده در این فضای چند بعدی. این نقطه اشتراک میشه ورودی شبکه عصبی دوم که تلاش میکنه یه اثری در چارچوب این اشتراکات رو به صورت unsupervised تولید کننده. اما unsupervised چه جوری کار می کنه.
توی کتاب حیات نسخه سه، میاد یه مثال خیلی خیلی باحالی می زنه. میگه زندانی رو تصور کنید که ۱۰۰۰ سلول زندانی داره، روزی فرا میرسد که زندان بان از کاری که داره انجام میده خسته میشه و تصمیم میگه که یک رمان بنویسه. این کار در خفی انجام میشه ولی در انتها می خواد یه آزمایش انجام بده. این خبر رو که می خواد رمان بنویسه رو و با زندانی ها مطرح میکنه و به اون ها جمله اول رمان رو ارائه می کنه، به عنوان مثال میگه سوار بی سر امد اما … و حالا از زندانی ها می خواد که کلمه بعدی رو بهش پیشنهاد بدن، یعنی در هر روز، به ازای هر کلمه از رمان، هزار پیشنهاد دریافت می کنه. این کار رو تا پایان تعداد کلماتی که خودش نوشته ادامه میده و در نهایت دو رمان داره که فقط جمله اولشون با هم شباهت داره و مابقی کلمات شبیه هم نیستن اما این نکته وجود داره که چه قدر این دو رمان به هم شبیه اند؟! کاری که مدل های شبکه های عصبی مثل chatgpt انجام میدن همینه. اونا درکی از کلمات ندارن و فقط با یک بازی ریاضی احتمال وقوع کلمه بعدی رو می سنجن و سعی می کنن مورد انتظار ترین زنجیره کلمات رو بهتون ارائه بدن.
اما اگر بخوایم برگردیم به صحبت اصلی مون، حاصل تلاش هوش مصنوعی دوم که از مدل های تولید تصویر GAN استفاده می کنه شبیه Stable Diffusion، میشه خواب AI به همین دلیل اسم نمایشگاه unsupervised ه. لینک جزئیات بیشتر در مورد نمایشگاه اینجا هست.

https://refikanadol.com/works/unsupervised/
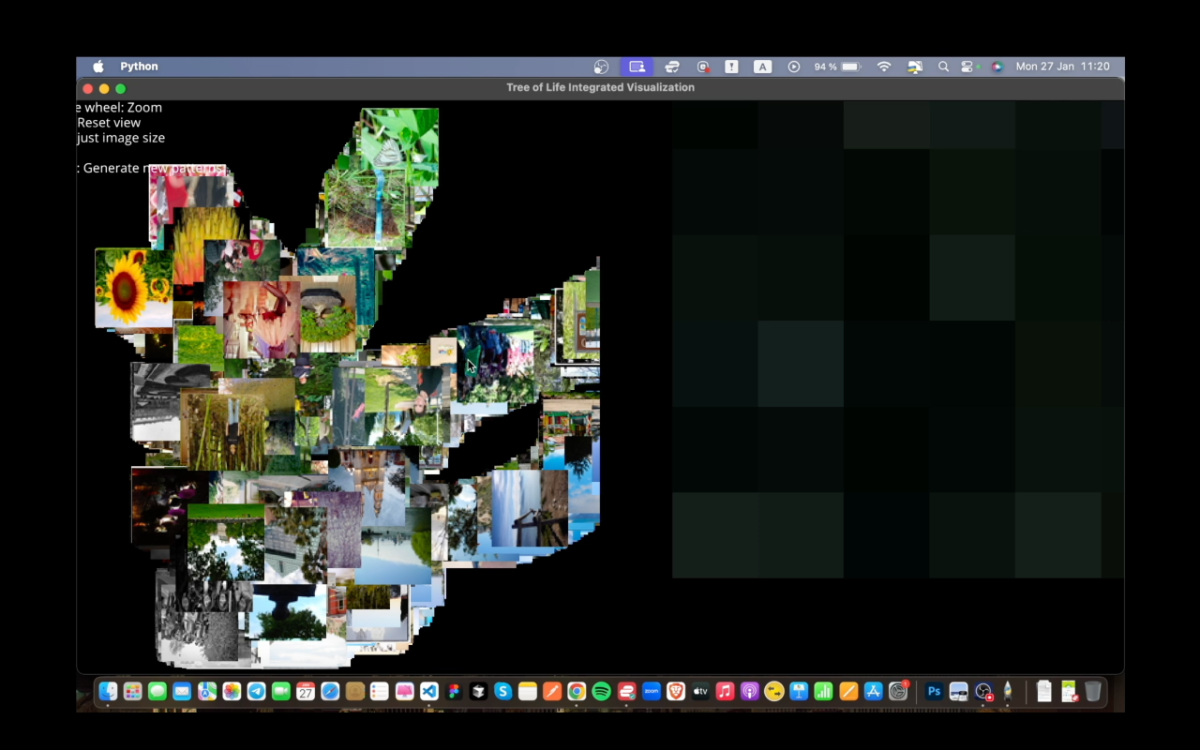
اما من خودم دوست داشتم که یک نمونه ساده از این کار رو توی لپ تاب خودم انجام بدم و اومدم برای مدل اول از تصاویر طبیعت بهره بردم و اومدم یه فضای سه بعدی از تصاویری که کتابخانه Open images در اختیارم قرار داده بود، ساختم. می تونید توی لینک در مورد این موضوع بیشتر بخونید.
https://storage.googleapis.com/openimages/web/index.html
حدود ۲۰۰۰ عکس رو اومدم دریافت کردم، پالایش کردم و دسته بندی کردم و این فضا سه بعدی رو تولید کردم که می توانید برای اطلاعات بیشتر به Github که براتون میذارم سر بزنید. در ادامه یه شبکه عصبی GAN رو با داده ها تصاویر طبیعت که دریافت کرده بودم، اموزش دادم و ازش خواستم که فصل مشترک نقطه ای که من در فضای سه بعدی توش قرار گرفتم که فضای مابین عکس های که وجود داره رو برامون تولید کنه و خبر خوب اینکه این مدل واقعا تولید عکس کرد. خیلی خیلی کار جذابی ه.
برای اینکه قدری بیشتر توضیح بدم، اومدم با کمک claude چند تا نقشه درست کردم که در نقشه اول داریم به ساختار کلی نرم افزار نگاه می کنم که می توانید توی لینک زیر این موضوع رو خودتون با دقت بیشتری دنبال کنین

در نقشه دوم داریم نحوه اجرایی سیستم رو با هم مشاهده می کنیم

به نظرم هر زمان وقت داشتید این موضوع رو امتحان کنید و خوش بگذرونید.
امیدوارم به زودی زود ببینمتون مخلصم ارادت.
لینک github پروژه رو هم در آدرس زیر در دسترس شما قرار داره
https://github.com/eddivahed/tree-of-life-visualization
مخلصم ارادت