توی این پست میخوایم با استفاده از (Model Context Protocol) MCP و یک مدل زبانی آفلاین (Local LLM)، سرعت کارمون رو در زمینه Static Analysis تا حد قابل توجهی بالا ببریم.
پیشنیاز این پست اینه که با مقدمات Reverse Engineering و Static Malware Analysis آشنا باشید.

همونطور که میدونید، تحلیل باینری (به خصوص بخش Static Analysis)، در کل فرایندی زمانبره. قبل از AI، سعی میکردیم با استفاده از ابزارها و اسکریپتها این فرایند رو تا جای ممکن کوتاه و بخشهایی از کار رو Automate کنیم.
حالا با وجود AI، در کنار استفاده از ابزارها و اسکریپتهای قبلی، میتونیم سرعت کار رو تا حد زیادی بیشتر از قبل کنیم. البته در مقایسه با حوزههایی مثل Development، هنوز AI تو زمینه Reverse و تحلیل باینری خیلی اونقدری که انتظار میره پیشرفت نکرده! ولی با این وجود، بازم میتونه تا حد قابل توجهی کار رو سریعتر کنه. (توی Development که دیگه واقعا کم مونده با کارفرما تماس بگیره بگه «پروژه آمادست!» 😄)
بگذریم، بریم سر اصل موضوع...
اولین چیزی که نیاز داریم، خود Ghidra هست، اگه نصب ندارین، آخرین نسخه رو از GitHub دانلود کنید:
یادتون نره که JDK هم باید نصب باشه، Ghidra بهش نیاز داره.
برای استفاده از یک مدل زبانی آفلاین (Local LLM)، نیاز به یک Engine داریم که مدل رو اجرا کنه. در حال حاضر ابزارها و Engineهای مختلفی برای این منظور وجود داره، ولی ما کارمون را با Ollama میریم جلو.
چرا Ollama ؟ 🤔
رابط کاربری ساده، نصب و راهاندازی سریع، مدیریت همزمان چند مدل، پشتیبانی از API، مستندات کامل و...
البته استفاده از Ollama اجباری نیست، شما میتونین از ابزار و Engineهای دیگه هم استفاده کنید.
برای دانلود Ollama، نسخه متناسب با سیستمعامل خودتون رو از لینک زیر دانلود و نصب کنید:
نیازه که IP رو از ایران، به جای دیگهای تغییر بدین 😒
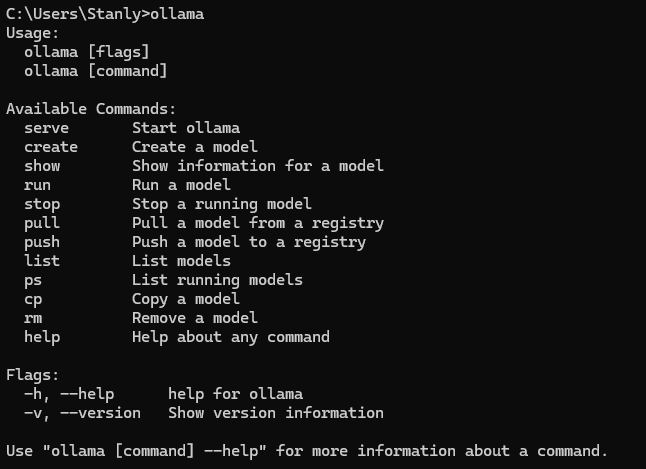
بعد از نصب، برای اطمینان از اینکه فرایند نصب به درستی انجام شده، ollama رو در Command Line اجرا کنید، خروجی باید به این صورت باشه:
حالا باید نسبت به نیاز و انتظاری که از مدل داریم، یک مدل مناسب رو دانلود کنیم.
پلتفرمهای زیادی برای دانلود مدلهای زبانی (LLM) وجود دارن، حتی خود وبسایت Ollama هم بخشی رو برای دانلود مدلها داره.
اما ما از Hugging Face استفاده میکنیم. چرا؟
توی Hugging Face تنوع مدلها بسیار بیشتره، از مدلهای عمومی گرفته تا مدلهایی برای کاربردهای خاص (مثل مدلهای تخصصی پزشکی، حقوقی و... )
اکثر مدلهایی که داره، قابلیت سفارشیسازی (customize) دارن و میشه نسبت به نیازمندی و منابعی که داریم بهینهشون کنیم.
در کل مدلهایی که وبسایت Ollama ارائه میده، بیشتر مناسب کاربرایی هست که دنبال تجربه ساده و سریع استفاده از مدلهای آفلاین هستن، اما Hugging Face آزادی عمل و تنوع بیشتری داره و میتونیم نسبت به سختافزار و نیازمندی، مدل مناسبتری رو دانلود کنیم.
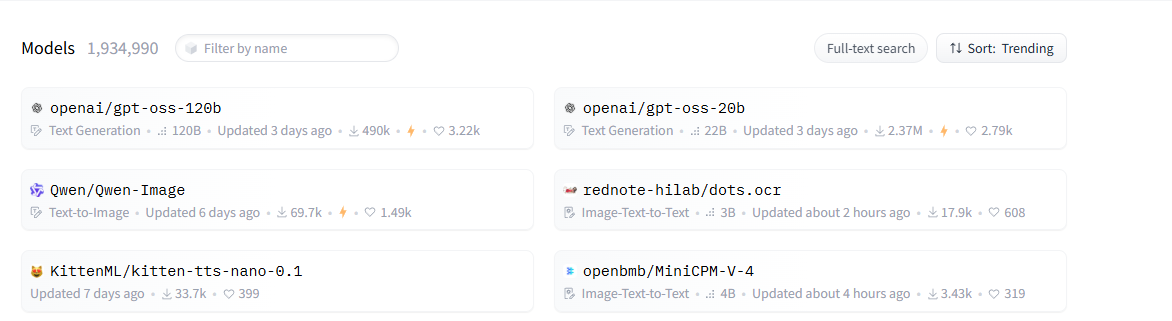
برای دانلود مدل از Hugging Face، اول وارد بخش Model ها بشین:
همونطور که مشخصه تو این بخش در حال حاضر 1,934,990 مدل وجود داره، ولی همونطور که صحبتش شد ما باید نسبت به کانفیگ سختافزاری و نیازمون، مدل مناسب رو دانلود کنیم:
مدلهای آفلاین عمومی قابل دسترس در زمینه تحلیل باینری و Malware Analysis فعلا تنوع زیادی ندارن و انتخاب بینشون خیلی سخت نیست، چون گزینههای اصلی محدود میشه به Qwenمحصول علیبابا و Code LLaMA
حالا ما برای ادامه کار، Qwen رو انتخاب میکنیم، چرا؟ 🤔
مدل Qwen در زمینه تحلیل باینری، عملکرد بهتری از خودش نشون داده.
از نظر مصرف منابع سختافزاری بهینهتر عمل میکنه.
بنابراین Qwen رو جستجو میکنیم و نتایج رو بر اساس Recently updated مرتب میکنیم:

تو این مرحله، انتخاب مدل در نهایت به منابع سختافزاری شما بستگی داره.
مدلهایی که تو اسمشون عبارتهای Instruct، Thinking یا Coder دارن، منابع سختافزاری خیلی بالایی نیاز دارن و معمولا باید روی سرور یا Workstationهای با کانفیگ بالا ازشون استفاده کرد.
مثلا مدل Qwen/Qwen3-Coder-480B-A35B-Instructحدود 480 میلیارد پارامتر داره و در حال حاضر کاملترین مدل از این لیست به حساب میاد، ولی خب طبق مستندات نیاز به 64 هسته CPU، بیشتر از 512GB رم و کارت گرافیک NVIDIA A100 80GB داره. 😕
پس میریم سراغ مدلهای خیلی خیلی پایینتر 😁
از این لیست، مدل Qwen/Qwen3-14Bبا یک سیستم خونگی کانفیگ خوب هم قابل استفادست، این مدل به 64GB رم و یک کارت گرافیک RTX 4090 نیاز داره تا بتونه عملکرد خوبی داشته باشه.
ما در نهایت کار رو با مدل Qwen/Qwen3-8Bادامه میدیم که 8 میلیارد پارامتر داره، این مدل رو میشه سر یه لپتاپ معمولی با 16GB رم و یک کارت گرافیک RTX 3090 هم به راحتی استفاده کرد. (بدون نیاز به GPU و فقط با داشتن یک CPU خوب هم میشه عملکرد خوبی ازش گرفت.)
سوالی که احتمالا پیش میاد اینه که:
ما از یک مدل 480 میلیارد پارامتری رسیدیم به یک مدل ۸ میلیاردی! این مدل با این حجم از پارامتر اصلا میتونه نیاز ما رو جواب بده؟
واقعیت اینه که طبیعتا هر چقدر کانفیگ سختافزاری بالاتری داشته باشیم، میتونیم از مدلهای قویتری استفاده کنیم و خروجی بهتر و دقیقتری بگیریم، اما از اونجایی که هدف این پست آشنایی با روش کاره، همین مدل 8 میلیارد پارامتری در حدی که با روش کار آشنا بشیم نیازمون رو برطرف میکنه.
ولی در نهایت، نیازه که شما بر اساس کانفیگ سختافزاریتون مدل قویتری را انتخاب کنید.
⚠️ فقط یک نکته مهم:
مدلی را انتخاب کنید که آخر اسمش gguf باشد. با وجود اینکه برای عملکرد بهتر مدلها، GPU قطعا با اختلاف بهتره، ولی این دسته از مدلها با بهینهسازیهای GGUF و Quantization تا حد زیادی برای اجرا با CPU (بدون نیاز به GPU) بهینه شدن، مثلا شما میتونین بدون GPU و فقط با داشتن یک CPU خوب (حداقل 8 هسته) و 16GB رم، مدلهای تا 14 میلیارد پارامتر رو هم خروجی خوبی بگیرین.
خب پس نسبت به سختافزاری که دارین، مدل مناسب رو انتخاب کنید و بعد وارد بخش Files and Versions اون مدل بشین: (در تصویر زیر با کادر قرمز مشخص شده)
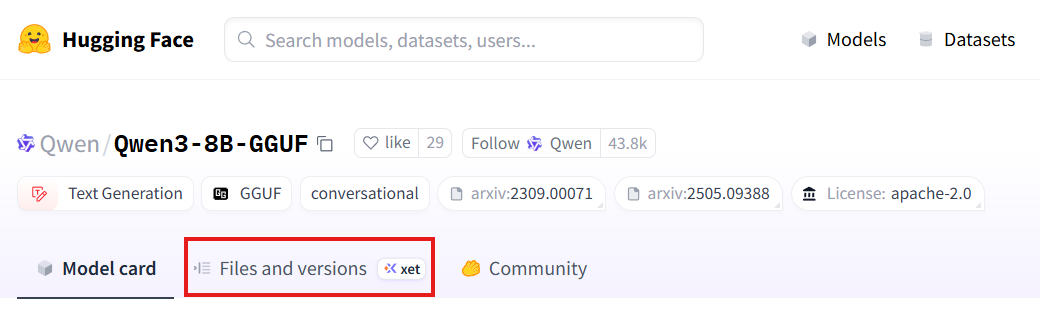
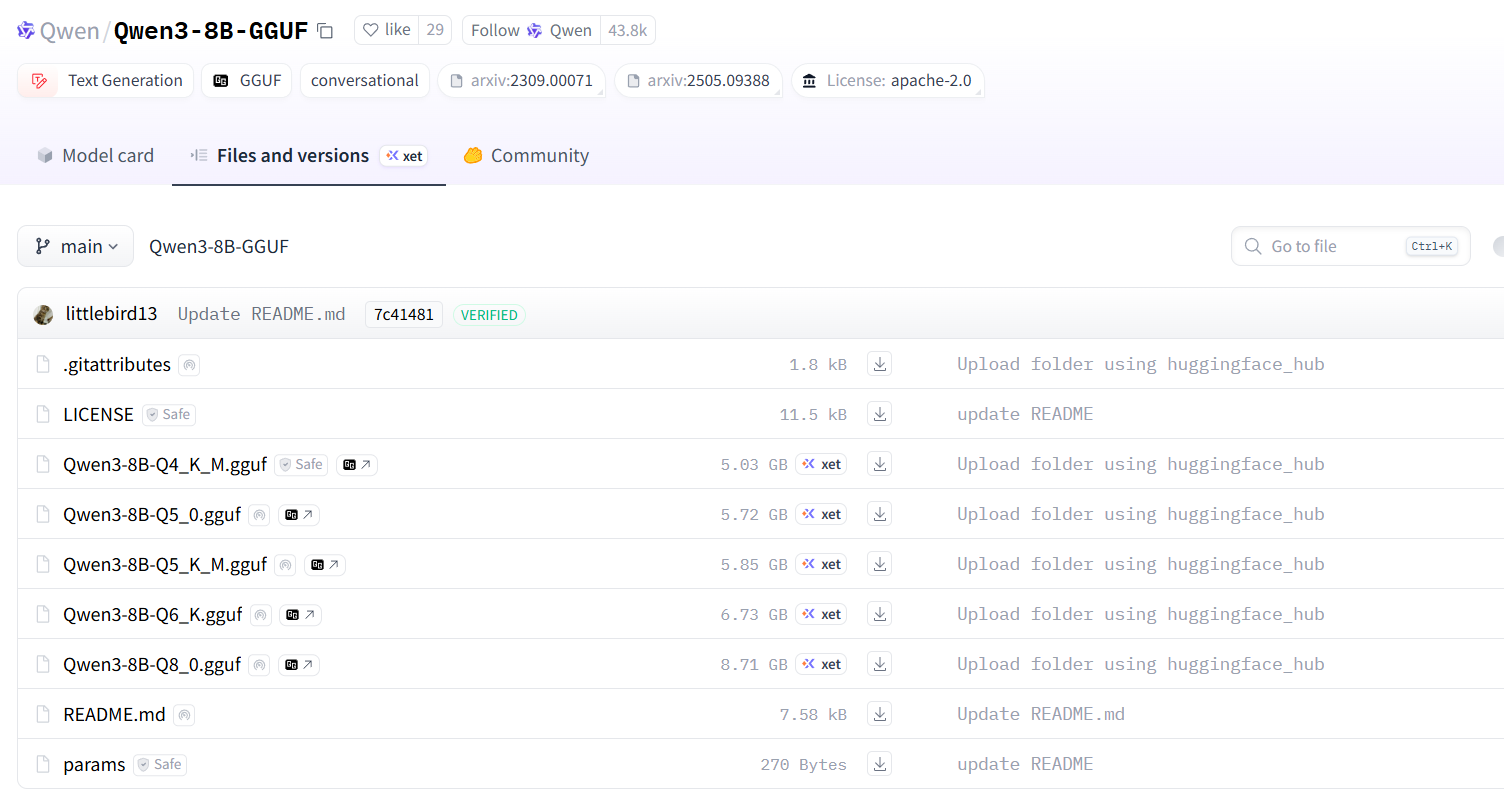
حالا اینجا Quantizationهای مختلفی ازش رو داریم که باید بر اساس مشخصههایی که توی اسمشون هست اونی که مناسبه رو دانلود کنیم (تصویر زیر):
Q4: (4 بیت) - کوچیکتر و سریعتر، ولی دقت کمتر
Q5: (5 بیت) - تعادل نسبتا مناسب
Q6: (6 بیت) - نزدیک به دقت کامل اما حجم بیشتر
Q8: (8 بیت) - معمولا کمتر کوانتیزه شده، همین باعث میشه حداکثر دقت و حجم بالاتر رو داشته باشه.
K و M هم به ترتیب به نوع Quantization و روش بهینه سازی اشاره دارن.
در واقع هر چقدر بیتها کمتر باشن (مثلا Q4) مدل حجم کمتری داره و سریعتر اجرا میشه، ولی ازون طرف از دقتش هم کم میشه. پس در نهایت ما مدل Qwen3-8B-Q4_K_M.gguf رو انتخاب میکنیم، چون فقط میخوایم با نحوه کار آشنا بشیم.
این مدل دقت کمتری نسبت به بقیهشون داره، ولی حجم کمتر، سرعت بیشتر و منابع سختافزاری کمتری رو نیاز داره.
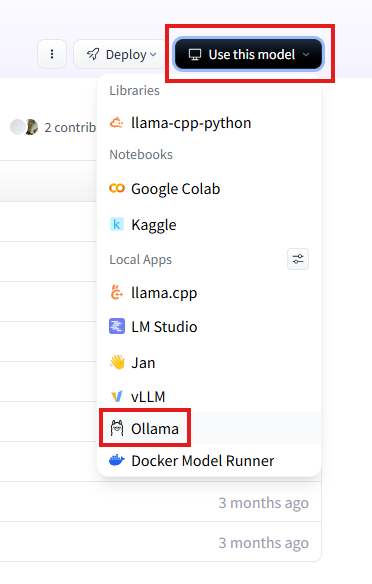
برای دانلود روی Use this model کلیک کنید و از بخشی که باز میشه Ollama رو انتخاب کنید، به این صورت:
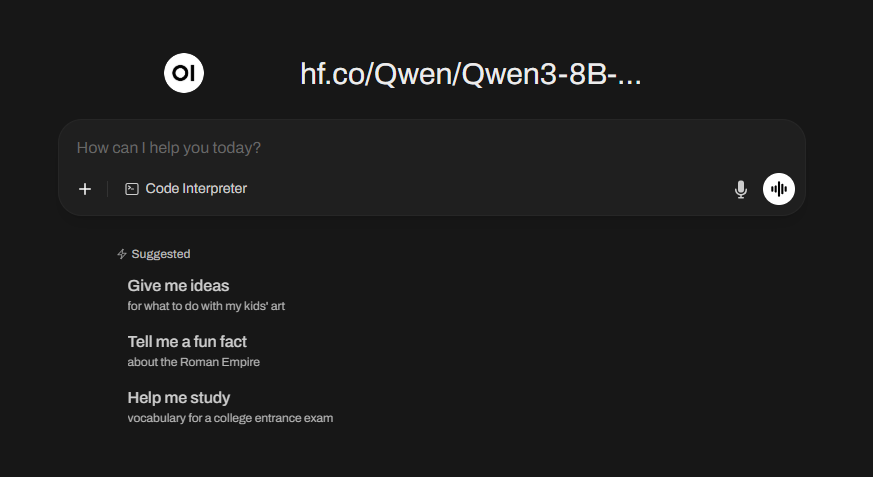
حالا از این قسمت، مدل دقیق مورد نظرمون رو انتخاب میکنیم تا بتونیم command مربوط به دانلودش رو copy کنیم:

البته جای run رو با pull عوض میکنیم که فقط دانلودش کنه، فعلا نمیخوایم اجراش کنه، پس:
ollama pull hf.co/Qwen/Qwen3-8B-GGUF:Q4_K_M
بعد از دانلود، برای اطمینان کامندollama list رو اجرا کنید، خروجی باید تموم مدلهای نصبشده را لیست کنه.
به این صورت:

حالا به یک UI نیاز داریم تا بتونیم با مدلی که دانلود کردیم ارتباط بگیریم، البته استفاده از UI اجباری نیست و میشه به صورت CLI هم با مدل کار کرد، ولی خب اینجوری کار کردن باهاش خیلی سادهتر و خروجی هم قشنگتر نشون داده میشه. ابزارهای رایگان زیادی توی این زمینه وجود دارن، که Open UI یکی از بهتریناشونه، چون هم سبکه و هم رابط کاربری سادهای داره.
این ابزار را میتونید از GitHub نصب و اجرا کنید:
https://github.com/open-webui/open-webui
نصب و اجرا کردنش خیلی سادهست، خودشم تو مستنداتش خیلی خوبو قشنگ توضیح داده، سر همین اینجا دیگه وارد جزئیات نصب و اجرا نمیشیم.
در نهایت، بعد از run کردنش، بر اساس Portی که مشخص کردین یک URL بهتون میده، مثلا:
http://localhost:3000
با باز کردن این آدرس، اگه همه چیز به درستی انجام شده باشه باید برسیم به این صفحه:
البته اولین باری که اجراش میکنید، ازتون میخواد که یک اکانت کاربری (Local) ایجاد کنید.
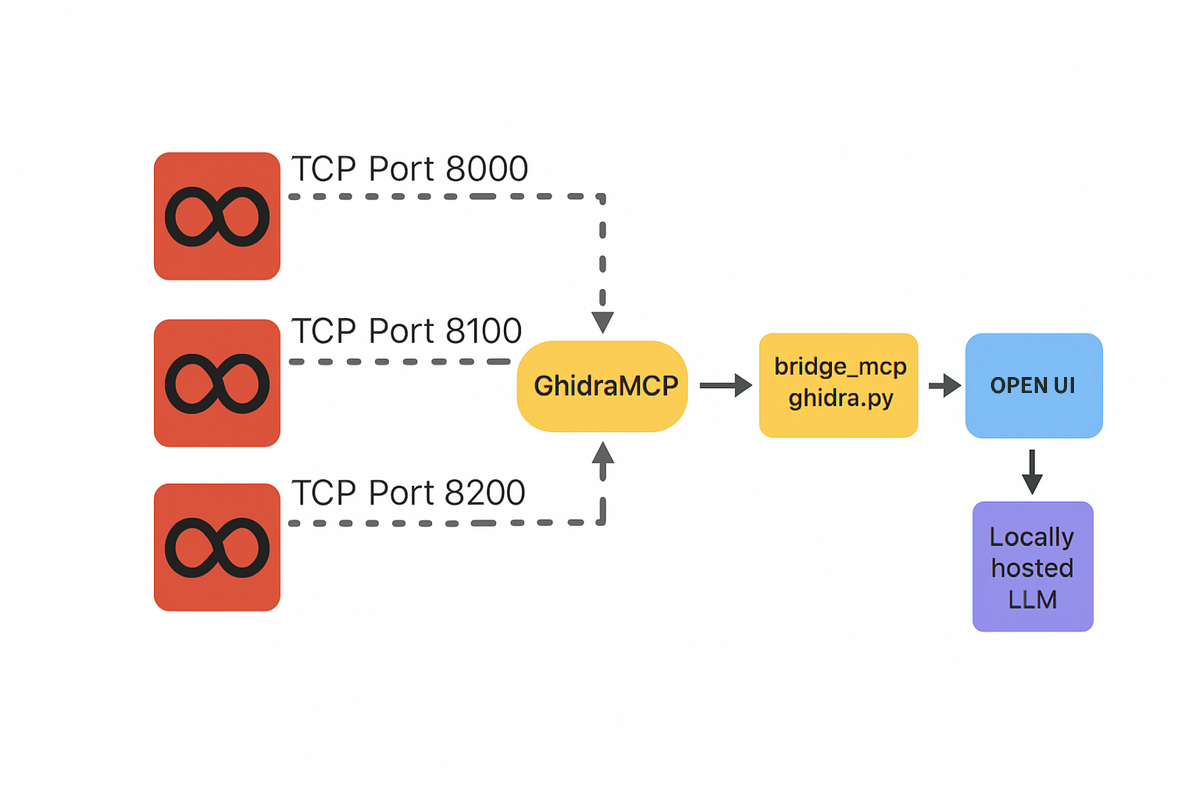
تا اینجای کار ما Ghidra، یک LLM آفلاین، یک Engine برای اجرای مدل و یک UI برای ارتباط با مدل رو نصب کردیم. حالا باید ارتباط بین Ghidra و این مدل را ایجاد کنیم. برای این کار، لازمه اکستنشن Ghidra MCP را دانلود و نصب کنیم.
ریپازیتوری اصلی این اکستنشن:
https://github.com/LaurieWired/GhidraMCP
اما ما از نسخه Fork شدش استفاده میکنیم:
https://github.com/starsong-consulting/GhydraMCP
نسخه Fork شده برای هر نمونه Ghidra که اجرا میکنیم، یک Port جدا اختصاص میده و اینجوری میشه برای هر Ghidra ای که باز داریم، بدون تداخل با مدل ارتباط داشته باشیم.
اگه معمولا بیشتر از یک Ghidra به صورت همزمان اجرا نمیکنید، نیازی نیست حتما نسخه Fork رو نصب کنید.
برای استفاده از این اکستنشن، از بخش release، فایلی که تو اسمش complete داره رو دانلود میکنیم:
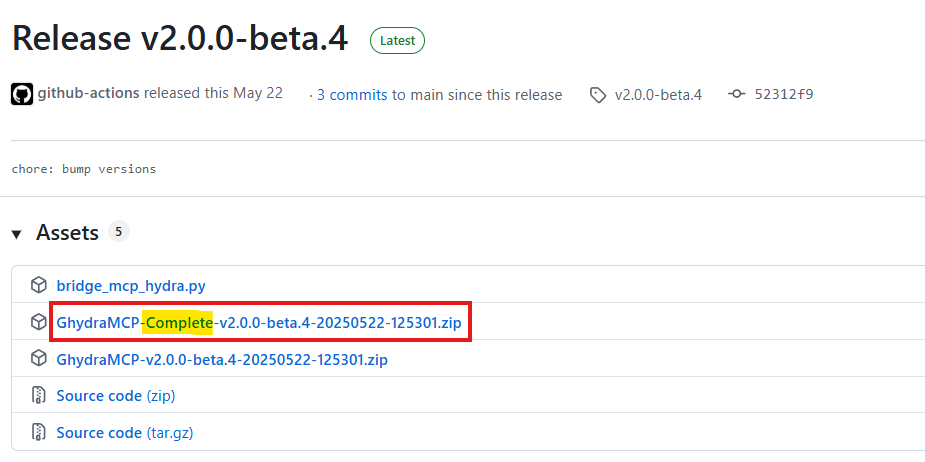
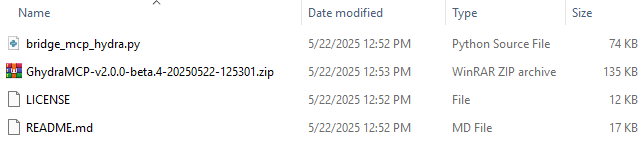
بعد از دانلود از حالت فشرده خارجش میکنیم و میرسیم به این 4 فایل:
حالا وارد Ghidra میشیم و از منوی File، گزینه Install Extensions رو انتخاب میکنیم:

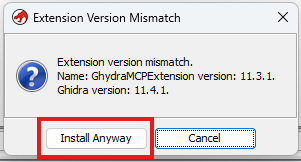
تو این مرحله از بخشی که باز میشه، آیکن + رو انتخاب کنین و از بین 4 فایل مرحله قبل، فایل zip رو بهش بدین، احتمالا یه پیام بیاد که نسخه Ghidra با نسخه Extension هماهنگ نیست، این موضوع مهم نیست و شما Install anyway رو بزنین.
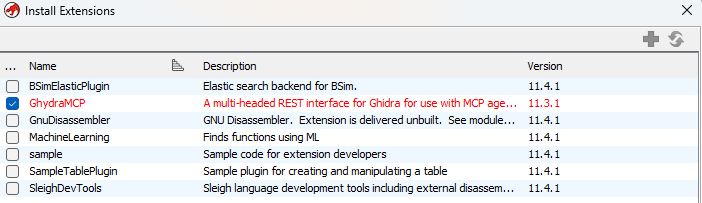
در نهایت Ghidra MCP باید به این صورت به لیست Extensionها اضافه شده باشه:
حالا یک بار Ghidra رو restart کنید و برای اطمینان از نصب صحیح Extension، از منوی File بخش Configure و بعد بخش Configure از زیر مجموعهی Developer رو انتخاب کنید:

اینجا باید GhydraMCPPlugin توی لیست باشه و تیکش هم خورده باشه (اگه تیکش نخورده بود، خودتون بزنین):

خب حالا نیاز داریم ارتباط بین Ghidra MCP با LLM رو ایجاد کنیم. این کار با استفاده از فایل bridge_mcp_ghidra.pyانجام میشه (یکی از همون 4 فایلی که مرحله قبل دانلود کردیم)، این فایل همونطور که از اسمش هم مشخصه مثل یک پُل عمل میکنه و ارتباط بین Ghidra MCP رو با LLM فراهم میکنه. حالا ما این وسط یه Open UI هم گذاشتیم، پس میشه به این صورت:
برای اجرا کردن bridge_mcp_hydra.pyمیتونیم خیلی ساده با python اجراش کنیم، ولی اینجوری باید تعداد خیلی زیادی dependency رو یکی یکی با pipدانلود کنیم، روش سادهتر و سریعتر اینه که بیایم از uv استفاده کنیم. همونطور که میدونید uv یک Package Manager پایتونه که با Rust نوشته شده، نسبت به pip سرعت بالاتری داره، مدیریت dependencyها رو خیلی سادهتر کرده و هر چی نیازه رو خودش دانلود میکنه.
این ابزار رو میتونید از Githubش دانلود کنید:
https://github.com/astral-sh/uv
بعد از نصب uv، حالا باید bridge_mcp_hydra.pyرو به این صورت اجرا کنیم:
uv run bridge_mcp_hydra.py

الان تا اینجای کار همه ارتباطها برقرار شد به جز ارتباط Open UI که هنوزم هیچ ارتباطی با Ghidra نداره. در واقع ما الان اومدیم با استفاده از bridge_mcp_hydra.py ارتباط بین Ghidra و مدل رو برقرار کردیم، حالا باید به نوعی Open UI هم وارد این زنجیره ارتباطی بشه.

برای اینکه بتونیم این ارتباط رو ایجاد کنیم، Open UI از ما یک آدرس OpenAPIمیخواد. در واقع اینجا bridge_mcp_hydra.py که نقش یک پُل بین Ghidra با بیرون رو بر عهده داره، باید یک OpenAPI بده بهمون.
سریعترین راه حل چیه؟ استفاده از mcpo :
https://github.com/open-webui/mcpo
mcpo این امکان رو فراهم میکنه که بشه هر ابزار MCP رو به عنوان یک HTTP Server که از OpenAPI پشتیبانی میکنه به صورت RESTful به بیرون Expose کرد.
برای نصب mcpo به این صورت عمل میکنیم:
pip3 install mcpo
و حالا به جای اینکه bridge_mcp_hydra.py رو مستقیم اجرا کنیم، این کارو از طریق mcpo انجام میدیم:
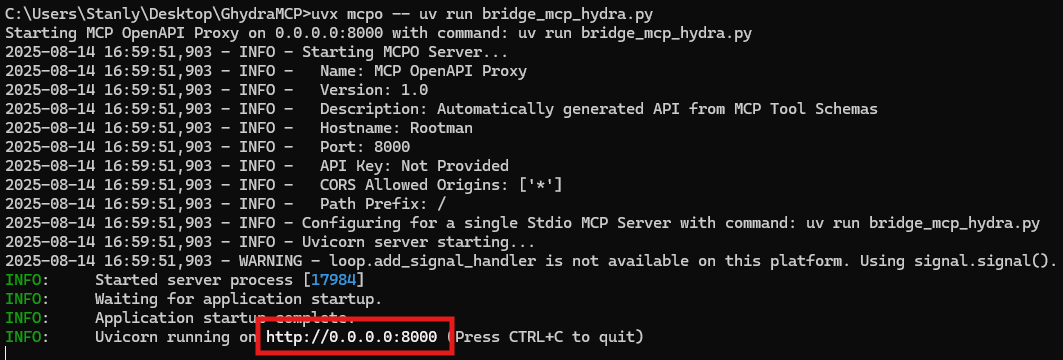
uvx mcpo --uv run bridge_mcp_hydra.py
اینجوری در کنار اینکه bridge_mcp_hydra.py اجرا شده، یک آدرس OpenAPI هم بهمون میده:
حالا فقط کافیه این آدرس رو به Open UI بدیم، از این مسیر:
Settings → Tools → Add Connection

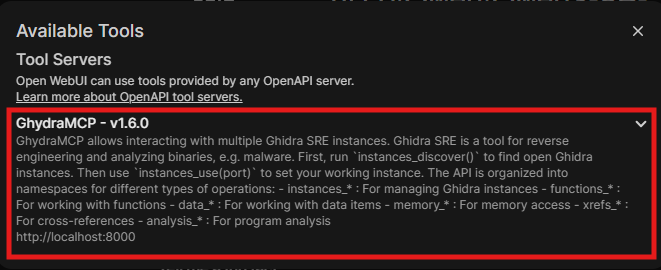
حالا اگه به صفحه اصلی Open UI برگردید، یک آیکن شبیه آچار اضافه شده که با کلیک روی اون، به لیست ابزارهای فعال Ghidra MCP هم اضافه شده:
الان همهچیز آمادست 😍
برای کار باهاش، کافیه فایل مورد نظر رو توی Ghidra باز کنید و بعد از طریق Open UI هر سوال یا درخواستی دارید بهصورت ChatBotی مطرح کنید تا مدل براتون انجام بده.
بعضی از کارهایی که میتونید ازش بخواید (بر اساس مستندات Ghidra MCP):
دیکامپایل خودکار توابع
گرفتن کد سطح بالا (C-style) از توابع باینری و دادنش به مدل برای تحلیل یا بازنویسی
دیساسمبلی دقیق توابع
دریافت دستورهای اسمبلی بهصورت کامل و ساختارمند برای بررسیهای سطح پایین
تحلیل جریان داده (Data Flow Analysis)
مدل میتونه از مسیر دادهها در کد مطلع بشه و بخشهای مشکوک یا مهم رو شناسایی کنه
تولید و نمایش گراف فراخوانی توابع (Call Graph)
ساختار ارتباط توابع رو به مدل بده تا رفتار کلی برنامه رو تحلیل کنه
کشف و مدیریت اینستنسهای Ghidra در حال اجرا
پیدا کردن Ghidraهای باز، اتصال و جابجایی سریع بین اونها برای کار روی چند پروژه همزمان
خواندن مستقیم حافظه برنامه
دسترسی به بایتهای خام برای بررسی دادهها یا ساختارهای خاص
دریافت لیست تمام رشتهها (Strings)
شناسایی پیامها، کلیدها یا متنهای مخفی در باینری
اضافه کردن یا تغییر کامنت در کد
مدل میتونه توضیحات تحلیلی یا یادداشتهای خودش رو مستقیما در Ghidra ذخیره کنه
البته همونطور که اول پست گفتم، هنوز AI در حوزه تحلیل باینری به اون نقطه ایدهآل نرسیده (حداقل در مدلهای عمومی)، اما همین الان هم میتونه سرعت کار رو تا حد زیادی بالا ببره. امیدوارم روز به روز چیزای بیشتری رو بتونیم به AI بسپاریم تا فرصت بشه وقتمون رو روی حوزههای بیشتر و جدیدتری بذاریم. 🤠

امیدوارم این پست براتون مفید بوده باشه.
اگه سوالی داشتید میتونیم لینکدین در ارتباط باشیم.
شاد و موفق باشید... ❤️