به قلم محمد حسین قنبری، ورودی ۴۰۰ مهندسی کامپیوتر دانشگاه صنعتی اصفهان
بازنگریشده توسط پارسا شیرکوند، ورودی ۴۰۲ کارشناسی مهندسی کامپیوتر صنعتی اصفهان

درباره نویسنده
بِرت هوبرت یک کارآفرین، توسعهدهنده نرمافزار و پژوهشگر هلندی است که به دلیل فعالیتهایش در زیرساختهای اینترنت و امنیت سایبری شناخته میشود. او در یکی از سخنرانیهایش میگوید که ابتدا سالها در زمینه امنیت سایبری کار کرده است. وی در سال ۱۹۹۹ یک شرکت دیاناس به نام Power" DNS را تاسیس کرد که در آن دوران خیلی مورد استقبال قرار نگرفت.
مدتی بعد متوجه شد که یک نرم افزار خیلی گران -یعنی همان Power DNS را - برای مردم عادی طراحی کرده است که ممکن بود توانایی خرید آن را نداشته باشند.
وی در سال ۲۰۱۱ به دلایلی حوزه رایانش امن (Security) را ترک کرد. به گفته خودش، یکی از دلایلش این بود که از فعالیت در این زمینه خسته شده بوده و بعد از این اتفاق به مدت ۱۸ ماه در دانشگاه صنعتی دلفت (TU Delft) به تحقیق درباره دیانای میپردازد که از نظر خودش دوران بسیار جالبی بوده و منجر به انتشارات مقالاتی به دست او در نشریههای علمی شده است.
در این مقاله، نگاهی متفاوت و جذاب به دیانای خواهیم داشت؛ نه از دیدگاه یک زیستشناس مولکولی؛ بلکه از دید یک برنامهنویس کامپیوتر. اگرچه نویسنده اصلی این دیدگاه در ابتدا متخصص ژنتیک نبوده، اما طی سالها مطالعه و علاقهمندی، توانسته مفاهیم ژنتیکی را با زبان دنیای کامپیوتر تطبیق دهد و به شیوهای قابل درک برای برنامهنویسان بیان کند.

اغلب ما، کدهای برنامهنویسی را به زبانهایی مثل C یا Python میشناسیم که برای اجرا شدن نیاز به ترجمه توسط کامپایلر یا مفسر دارند. DNA نیز شباهتهایی با این فرایند دارد، با این تفاوت که DNA نه مانند زبان C خام و واضح است و نه کاملاً قابل بازگشت به «کد منبع». بلکه شبیه به کدی «بایتکامپایل شده» (Byte-Compiled) برای یک ماشین مجازی به نام «هسته سلول» است.
در واقع، آنچه ما از DNA میبینیم، تمام چیزیست که داریم. هیچ "کد منبع" قابل مشاهدهتری وجود ندارد که بتوان به آن بازگشت. سلولها به شکلی پیچیده ولی مؤثر، این اطلاعات ژنتیکی را تفسیر و اجرا میکنند.

مثل کد بایتکامپایل شده است
وقتی میگوییم DNA مثل کد Byte-Compiled است، یعنی DNA نه به اندازهی کد منبع ساده و قابلفهم است و نه به اندازهی کد باینری سخت و غیرقابلخواندن. بلکه چیزی مابین این دو است. برای مثال، در زبان برنامهنویسی Python، وقتی که کدی را اجرا میکنید یک فایل میانی به نام .pyc ساخته میشود که نیمه قابلخواندن است و برای ماشین مجازی پایتون قابل اجراست. DNA هم مثل این فایل میانی است؛ نه خیلی واضح، نه خیلی مبهم، اما قابل استفاده برای ماشین اجرا کنندهاش.
در دنیای کامپیوتر، ماشین مجازی یعنی محیطی که کد اجرا میشود، بدون اینکه مستقیم با سختافزار در تماس باشد. مثلاً جاوا دارای یک ماشین مجازی به نام JVM است که کد را اجرا میکند.
در بدن ما، ماشین مجازیای که DNA را اجرا میکند، سلول است؛ یا دقیقتر که بگوییم «هسته سلول» (Nucleus) جاییست که این کد خوانده و اجرا میشود. سلولها DNA را میخوانند، آن را تفسیر میکنند و با کمک آن پروتئینها و اجزای مختلف بدن را میسازند.
دیانای: زبان دیجیتال، اما نه دودویی (باینری)

یکی از نکات جالب در مورد DNA این است که برخلاف زبانهای کامپیوتری که مبتنی بر سیستم باینری (صفر و یک) هستند، DNA دارای چهار «حرف» یا باز (Base) است:
A (آدنین)، T (تیمین)، C (سیتوزین) و G (گوانین)
در زبان کامپیوتر، یک بایت متشکل از 8 بیت است که با دو حالت ممکن (0 یا 1) میتواند تا 256 مقدار متفاوت را نمایش دهد. اما در DNA، هر «کدون» (Codon) از سه باز تشکیل شده که هر کدام از میان چهار حرف ممکن انتخاب میشوند. بنابراین، تعداد ترکیبهای ممکن برابر است با:
هر کدون معادل یک آمینو اسید مشخص است. برای مثال، کدون GCC بیانگر آمینو اسید آلانین است. مجموعهای از این آمینواسیدها زنجیرهای به نام پلیپپتید یا پروتئین را تشکیل میدهند که واحدهای اساسی ساختار و عملکرد موجودات زنده هستند.
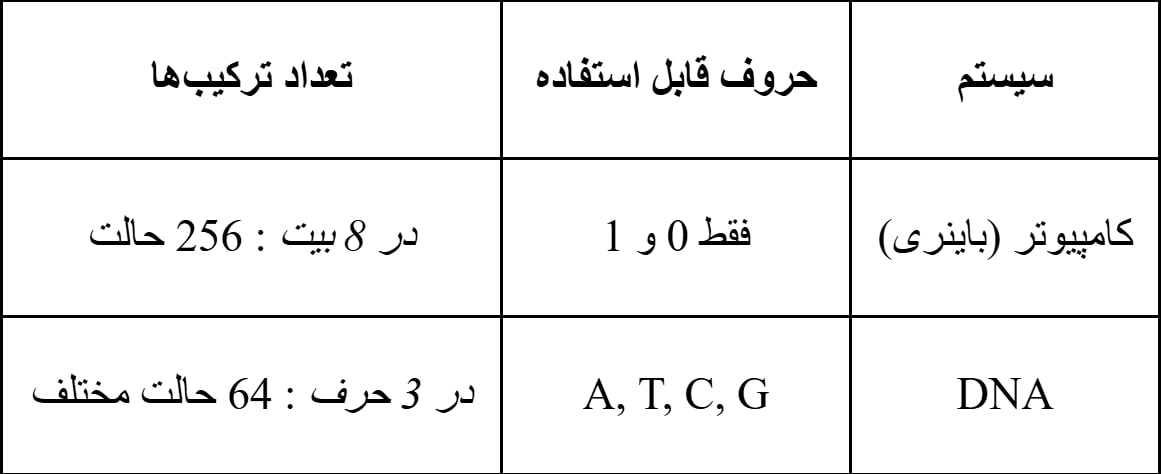
مفهوم کد مستقل از موقعیت در برنامهنویسی:
در دنیای کامپیوتر و برنامهنویسی، وقتی یک برنامه نوشته میشود، معمولاً آن برنامه در حافظه کامپیوتر (RAM) اجرا میشود. برنامهها معمولاً به آدرسهای خاصی در حافظه اشاره میکنند. اما گاهی اوقات لازم است یک برنامه بتواند در هر جای حافظه که سیستم صلاح میبیند اجرا شود، بدون اینکه خراب شود یا آدرسهایش اشتباه شوند.
اینجور برنامهها را «کدهای مستقل از موقعیت» مینامند. یعنی کدهایی که به جای استفاده از آدرسهای ثابت، طوری نوشته شدهاند که هر جا در حافظه قرار بگیرند، باز هم درست کار میکنند.
این کار مخصوصاً برای چیزهایی مثل «کتابخانههای پویا» (مثلا فایلهای .dll در ویندوز یا .so در لینوکس) خیلی مهم است. چون این فایلها ممکن است چند بار در جاهای مختلف حافظه بارگذاری شوند و اگر آدرسهای ثابتی درونشان باشد، دچار مشکل میشوند. پس این کتابخانهها طوری نوشته میشوند که بتوانند در هر موقعیتی اجرا شوند؛ بدون نیاز به تغییرات دستی.
در داخل سلولهای زنده، اطلاعات ژنتیکی ما روی مولکولی به نام DNA ذخیره شده است. DNA معمولاً ثابت است و هر بخش از آن وظیفه خاصی دارد؛ مثل دستور ساختن یک پروتئین یا تنظیم فعالیت ژنهای دیگر.
اما یک کشف عجیب در سالهای گذشته (دهه ۱۹۴۰) توسط «دکتر باربارا مککلینتاک» انجام شد. او فهمید که بخشهایی از DNA وجود دارند که میتوانند محل خود را در ژنوم تغییر دهند. یعنی مثلاً یک بخش از کروموزوم 1 به کروموزوم 5 یا یک جای دیگر از همان کروموزوم میپرد.
این بخشهای خاص را به اسمهای مختلف میشناسیم:
این تکههای DNA مثل کدی هستند که جای خاصی ندارند، میتوانند از یک نقطه به نقطه دیگر بروند و کماکان وظیفه خود را انجام دهند. درست مثل کدهای مستقل از موقعیت در برنامهنویسی.
امروزه دانشمندان دریافتهاند که تقریباً نیمی از کل DNA انسان از همین عناصر پرشپذیر تشکیل شده است! یعنی اینها فقط یک چیز خاص یا نادر نیستند، بلکه بخش خیلی بزرگی از ژنوم ما هستند.
در بدن ما میلیونها میلیون سلول وجود دارد: سلولهای مغز، قلب، پوست، کبد، ماهیچه و...
جالب اینجاست که تقریباً همهی این سلولها DNA یکسانی دارند! یعنی همهشان یک نسخه کامل از ژنوم انسان (که شامل حدود ۲۰ تا ۳۰ هزار ژن است) را با خود حمل میکنند.
اما سوال مهم این است که چرا سلول مغز فقط ژنهای مربوط به مغز را فعال میکند و مثلاً ژنهای کبد را استفاده نمیکند؟ یا سلول کبد چرا ژنهای چشم یا پوست را نمیخواند؟
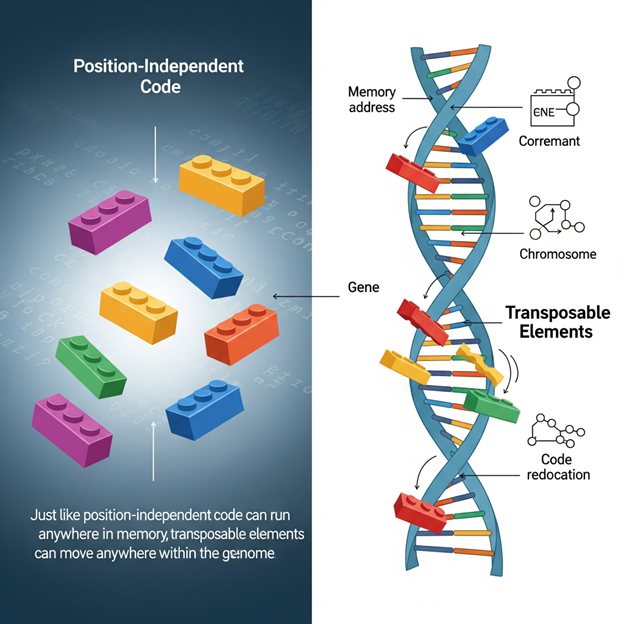
اینجاست که برنامهنویسی شرطی در ژنها وارد ماجرا میشود!
در برنامهنویسی، گاهی کدی داریم که فقط باید در شرایط خاصی اجرا شود. مثلاً:
#if USER == "admin" show_admin_panel(); #endif
این یعنی: فقط اگر کاربر مدیر بود، بخش مربوط به پنل مدیر اجرا شود. در غیر این صورت، نادیده گرفته میشود.
در DNA هم وضعیتی شبیه این داریم! در سلولهای بدن، با اینکه همهی ژنها وجود دارند، ولی فقط بعضی از آنها تحت شرایط خاصی فعال میشوند. مثلاً:
به همین دلیل، سلولهای بنیادی موضوع پژوهشهای داغ علمی هستند؛ زیرا آنها هنوز هیچ بخشی از ژنوم خود را حذف نکردهاند و قابلیت تبدیل به هر نوع سلولی را دارند. البته این به آن معنا نیست که تمام ژنها در این سلولها فعال هستند. بلکه سلولهای بنیادی در آغاز همانند ماشینهای حالت (State Machines) هستند که با گذشت زمان و تقسیم شدن (Fork)، به تدریج تخصصیتر میشوند. این فرایند را میتوان همچون انتخاب مسیرهایی در یک درخت تصمیمگیری در نظر گرفت.
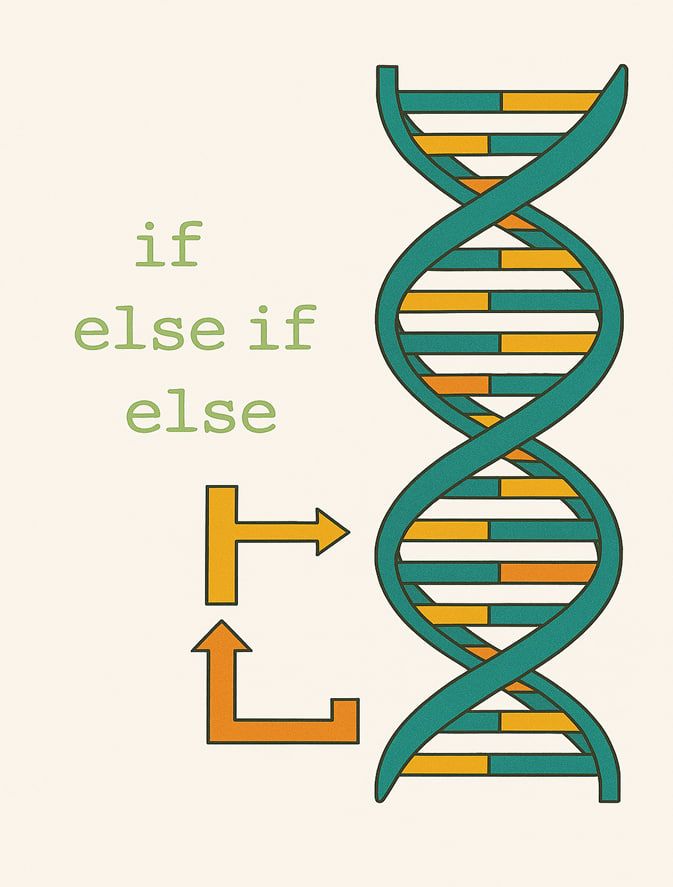
در بدن ما انواع مختلفی از سلولها وجود دارند: سلول پوست، سلول قلب، سلول مغز، سلول خون و ...
هر کدام از این سلولها وظیفه خاصی دارند و فقط همان کار را میتوانند انجام دهند.
اما در ابتدای زندگی، وقتی یک نطفه (زیگوت) تازه تشکیل میشود، تمام سلولهای آن یکساناند و هنوز تصمیم نگرفتهاند که قرار است چه نوع سلولی بشوند. به این سلولهای اولیه میگوییم سلولهای بنیادی.
سلولهای بنیادی مثل «کاغذ سفید» هستند.
یعنی هنوز نقش خاصی نگرفتهاند و میتوانند در آینده به هر نقشی دربیایند:
ممکن است به سلول پوست، سلول عصبی، سلول عضله، سلول کبد و ... تبدیل شوند.
نکته مهم:
این سلولها هیچ ژنی را از DNA خود حذف نکردهاند.
یعنی همه دستورالعملها برای تبدیل شدن به هر نوع سلول را دارند.
اما...
این به این معنا نیست که همهی ژنهایشان فعال است.
در واقع، آنها فقط ژنهایی را فعال میکنند که در آن مرحله از رشد لازم است. بقیه ژنها «خاموش» هستند، ولی حذف نشدهاند.
در علوم کامپیوتر، ما «ماشین حالت» داریم. این ماشینها بسته به ورودیهایی که میگیرند، به حالتهای مختلفی میروند.
سلولهای بنیادی هم تقریباً همینطور هستند؛ آنها در آغاز کاملاً آزاد و منعطفاند ولی با گذشت زمان، با دریافت «سیگنالهایی» از محیط یا داخل بدن، تصمیم میگیرند به چه سلولی تبدیل شوند. این انتخابها مرحلهبهمرحله هستند. یعنی یک سلول بنیادی اول تصمیم میگیرد که مثلاً سلول عصبی بشود، بعد تصمیم میگیرد که از چه نوع سلول عصبی باشد، و همینطور جلو میرود.
میتوان این فرایند را مثل درختی با شاخههای زیاد در نظر گرفت:
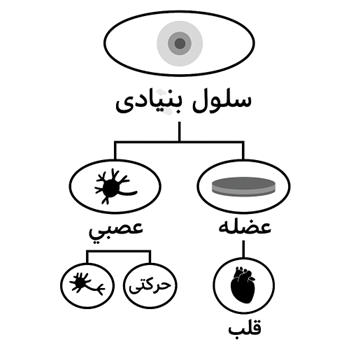
در ابتدا، سلول در نوک درخت (بالا) است و همه گزینهها را دارد.
ولی وقتی وارد یک شاخه شود، دیگر نمیتواند به شاخههای دیگر برگردد. یعنی وقتی مثلاً تبدیل به سلول عضله شد، دیگر نمیتواند سلول عصبی شود.
هر سلول میتواند - یا میتوان آن را وادار کرد - که تصمیمهایی دربارهی آیندهی خود بگیرد؛ تصمیمهایی که به تخصصیتر شدن آن منجر میشوند. این انتخابها از طریق فاکتورهای رونویسی (transcription factors) و تغییر در ساختار فضایی ذخیرهسازی DNA (اثرهای فضایی یا Steric Effects) به نسلهای بعدی همان سلول منتقل میشوند.
فاکتورهای رونویسی (Transcription Factors)
تغییرات فضایی (Steric Effects)
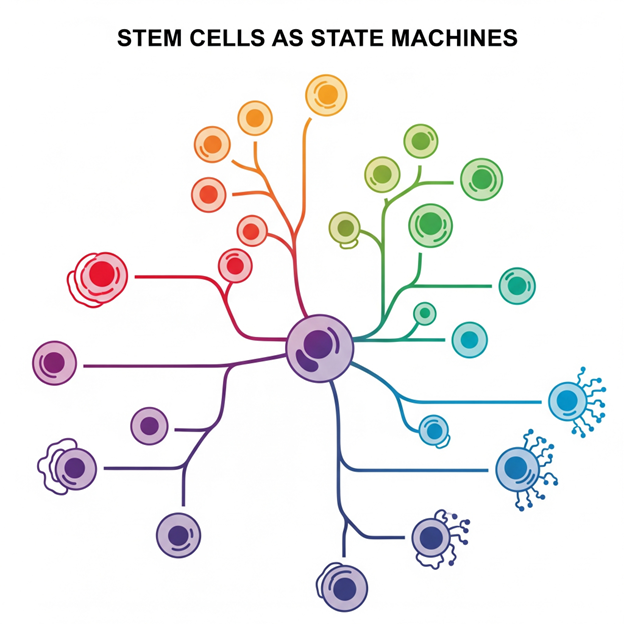
برای مثال، یک سلول کبدی اگرچه تمام ژنهای لازم برای تبدیل به سلول پوست را دارد، ولی در عمل نمیتواند چنین کاری انجام دهد. با این حال، پژوهشهایی وجود دارد که نشان میدهند میتوان برخی سلولها را دوباره به وضعیت بنیادیتر برگرداند، یا به اصطلاح «بهسمت بالا» در سلسلهمراتب سلولی پرورش داد. این سلولها را «سلولهای پرتوان» (Pluripotent) مینامند.
در دنیای ژنتیک، همیشه تصور میشود که برای تغییر در ویژگیهای بدن، حتماً باید تغییراتی در DNA اتفاق بیفتد. اما واقعیت این است که گاهی میتوان بدون هیچ تغییری در کد ژنتیکی، نحوه عملکرد ژنها را کنترل کرد. این پدیده را اپیژنتیک (Epigenetics) مینامند؛ یعنی تنظیمی فراتر از ژنها، چیزی شبیه به برنامهریزی نرمافزاری بر روی سختافزار ثابت.
برای فهم بهتر این موضوع، بیایید نگاهی به دنیای فناوری بیندازیم. وقتی سیستمعامل لینوکس اجرا میشود، ابتدا بررسی میکند که دستگاه چه ویژگیهایی دارد. اگر تنها یک پردازنده (CPU) داشته باشد، بخشهایی از کدی که مخصوص سیستمهای چندپردازندهای است، بهطور کامل از حافظه کنار گذاشته میشوند. این کار حتی پیش از آنکه شرطهایی مثل if(numcpus) > 1 بررسی شوند، انجام میشود. در واقع، سیستمعامل در لحظه اجرا تصمیم میگیرد که کدام بخش از برنامه فعال بماند و کدام بخش کنار گذاشته شود؛ بدون آنکه به فایل اصلی برنامه دست بزند. این رفتار را میتوان نوعی وصلهزنی زنده یا تنظیم پویای کد در زمان اجرا دانست.
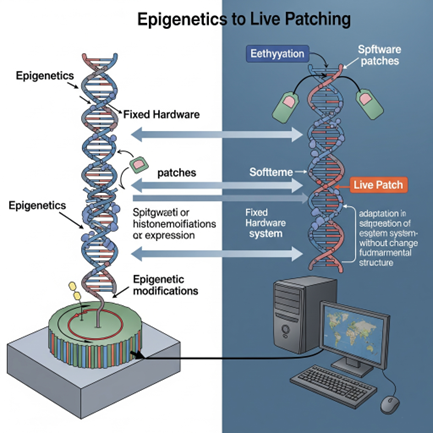
در بدن انسان هم فرآیندی مشابه رخ میدهد. بهویژه در دوران جنینی، ژنها تحت تاثیر عواملی قرار میگیرند که تعیین میکنند کدامیک فعال باشند و کدام غیرفعال بمانند. برای نمونه، هنگام رشد جُفت (یعنی همان بخشی که جنین را به بدن مادر وصل میکند) باید بین نیاز جنین به رشد و نیاز مادر به سلامت تعادل ایجاد شود. از دید ژنهای پدری، هرچه جنین بزرگتر و قویتر باشد، بهتر است. اما از دید بدن مادر، رشد زیاد جنین ممکن است خطرناک باشد و بارداری را تهدید کند. بنابراین، بدن مادر با استفاده از تنظیمات اپیژنتیکی تصمیم میگیرد برخی ژنهای پدری را خاموش یا کمفعال کند تا تعادل حفظ شود.
به این تنظیمات خاص، نقشگذاری ژنی یا ایمپرینتینگ (Imprinting) گفته میشود. این فرآیند تنها در بدن مادر انجام میشود، چون فقط مادر از وضعیت سلامت خودش آگاه است. ژنهای پدری، بدون اطلاع از شرایط فیزیکی بدن مادر، نمیتوانند در این تصمیمگیری دخالت کنند.
در مجموع، اپیژنتیک نشان میدهد که تنها داشتن ژن کافی نیست؛ مهم آن است که ژنها چگونه و در چه زمانی مورد استفاده قرار بگیرند. درست مانند برنامهای که بر اساس شرایط، بخشهایی از خود را فعال یا غیرفعال میکند، بدن نیز با استفاده از این تنظیمات هوشمندانه، مسیر رشد و سلامت خود را هدایت میکند — بیآنکه حتی یک حرف از کد ژنتیکیاش را تغییر دهد.
شواهد جدید نشان میدهند که وضعیت متابولیکی والدین حتی میتواند بر سلامت نوهها نیز اثر بگذارد. بهعنوان مثال، اگر نسل والدین در محیطی فقیر از نظر غذایی زندگی کرده باشند، ممکن است بدن نوهها برای بقای بهتر، متابولیسم متفاوتی را انتخاب کند.
مکانیسمهای اصلی اپیژنتیک شامل «متیلاسیون» (افزودن گروههای متیل به DNA برای خاموش یا روشن کردن ژنها) و همچنین «تغییر ساختار هیستونها» هستند که میتوانند DNA را به شکل فشرده در آورد و مانع از فعال شدن آن شوند.
برخی از این تغییرات اپیژنتیکی به نسلهای بعدی منتقل میشوند، در حالیکه برخی دیگر تنها بر فرد تأثیر میگذارند. این حوزه از علم هنوز در حال رشد و توسعه است، و احتمال میرود که درک ما از پویایی DNA و نقش آن در تنظیمات لحظهای زندگی، بهمراتب پیچیدهتر از چیزی باشد که پیشتر تصور میشد.
تا اینجای کار دیدیم که بخشهای زیادی از DNA مثل کامنتها در کدنویسی هستند. یعنی قسمتهایی که مستقیماً نقشی در ساخت پروتئین ندارند. اما یک سوال مهم اینجاست: آیا این بخشهای بهظاهر بیاستفاده فقط برای نادیده گرفتن هستند؟ یا شاید نقشی پنهانی دارند؟
یکی از نظریههای جالب برای توضیح این موضوع به چیزی به نام «تمایل به تا شدن» (Folding Propensity) مربوط میشود.
ما میدانیم که رشته DNA خیلی بلند است اما فضای داخل هسته سلول بسیار کوچک است. بنابراین DNA باید بهشکل خاصی پیچیده و تا شود تا بتواند به طرز مناسب قرار بگیرد. اما همه بخشهای DNA به یک اندازه برای این تا شدن مناسب نیستند. گاهی لازم است قطعات اضافهای بین بخشهای اصلی قرار بگیرند تا تا شدن بهتر انجام شود. اینجاست که اینترونها (intron) یا همان «کامنتهای ژنتیکی» وارد ماجرا میشوند.
برای اینکه بهتر درک کنیم، بیایید مثالی از دنیای تکنولوژی بزنیم: هارد دیسک کامپیوتر!
روی هارد، دادهها بهصورت تغییر در میدان مغناطیسی ذخیره میشوند. اما اگر اطلاعاتی مثل "000000" پشت سر هم باشند، چون تغییری اتفاق نمیافتد، سیستم نمیفهمد که دقیقاً چند صفر پشتسر هم آمده.
برای حل این مشکل، بین صفرها کدهای اضافه ولی بیمعنا قرار میدهند تا خواندن اطلاعات آسانتر و دقیقتر شود. این روش را «محدود سازی طول اجرا» (Run Length Limiting یا RLL) مینامند.
در DNA هم ممکن است اینترونها مثل همین دادههای اضافی عمل کنند، یعنی بهعنوان فاصلهگذار، به راحتتر تا شدن و ذخیره شدن DNA کمک کنند.
در زیستشناسی هنوز بحث داغی در جریان است که این اینترونها دقیقاً از چه زمانی وارد DNA شدند و چهکاری میکنند.
دو نظریه اصلی وجود دارد:
در این بحثها اصطلاحات سنگینی مثل «پتانسیل لوپ ساقهای» یا «تمایل به تا شدن» زیاد استفاده میشود. اما برای ما کافی است تا بدانیم که این بحث هنوز به نتیجه نرسیده و دانشمندان همچنان دربارهاش اختلافنظر دارند.
آپدیت ۲۰۱۳: آیا DNA اضافی واقعاً بیفایده است؟
بعد از سالها بحث، هنوز نتیجه قطعی به دست نیامده. اما بیشتر دانشمندان اکنون قبول دارند که اصطلاح «DNA بیاستفاده» یا «Junk DNA» درست نیست، چون بخش زیادی از این DNAها احتمالاً وظایف مهمی دارند.
ولی اینکه دقیقاً چه وظایفی دارند و چطور کار میکنند، هنوز معلوم نیست.
اگر تمایل دارید که اطلاعات بیشتری کسب کنید، مقالهای با عنوان "Fighting About Encode And Junk" در این زمینه وجود دارد.
آپدیت ۲۰۲۱: داستان همچنان ادامه دارد!
از آغاز این بحثها حدود ۱۸ سال گذشته و هنوز هم پایانی برای آن در کار نیست. بسیاری از پژوهشگران اکنون معتقدند که DNA هایی که قبلاً بیفایده تصور میشدند، حاوی اطلاعات و عملکردهای مهمی هستند.
ولی کشف دقیق این عملکردها هنوز ادامه دارد، و تقریباً هر روز اطلاعات تازهای دربارهی آنها بهدست میآید. این یعنی DNA بسیار هوشمندتر و پیچیدهتر از آن است که قبلاً فکر میکردیم.
لینک توضیحات مربوطه:
قسمت اول:
https://youtu.be/EcGM_cNzQmE?si=R-qmXRBDUoM8W998
قسمت دوم:
https://youtu.be/rCdhsN--Mdo?si=zyVzFITEsLJNYnRi
راستی!
این بخش اول از این مقاله جذاب بود.
منتظر قسمت دوم باشید!
https://zil.ink/faramatn