به قلم محمد حسین قنبری، ورودی ۴۰۰ مهندسی کامپیوتر دانشگاه صنعتی اصفهان
بازنگریشده توسط ملیکا ملکی، ورودی ۴۰۰ کارشناسی مهندسی کامپیوتر صنعتی اصفهان
یه پیشنهاد کوچیک: اگر پیش زمینهای در این موضوعات ندارید، برای درک و فهم بیشتر میتونید قسمت قبلی متن رو از لینک زیر مطالعه کنید.
دیانای از دید یک برنامه نویس
در سیستمعامل یونیکس، وقتی یک برنامه جدید میخواهد اجرا شود، سیستم معمولاً از یک برنامهی دیگر کپی میگیرد. این کار با دستوری به نام ( )fork انجام میشود. در بدن انسان هم روشی مشابه وجود دارد!
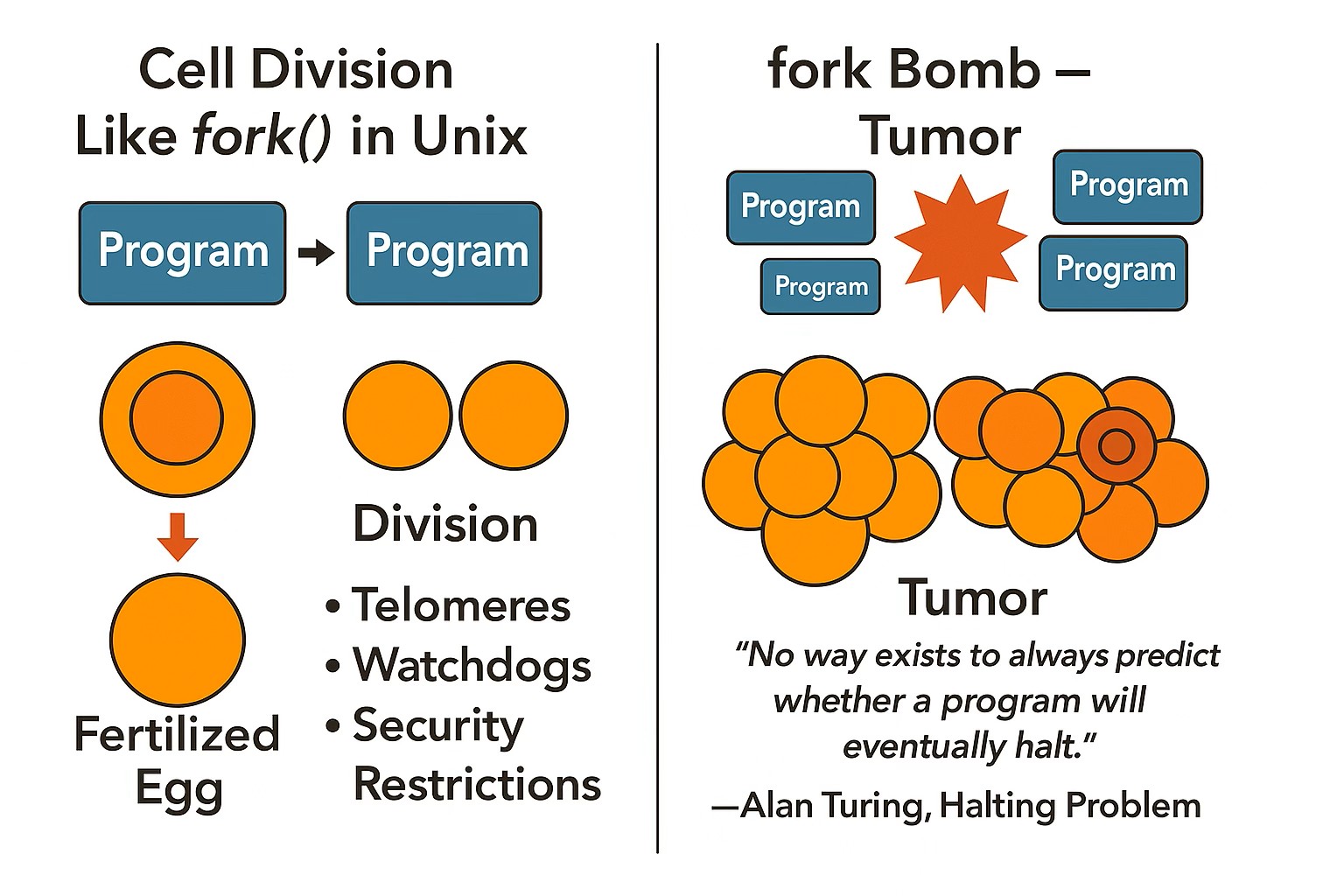
همهی سلولهای بدن ما در ابتدا از یک سلول ساده شروع شدهاند: تخمک بارور شده. این سلول اولیه بارها و بارها خودش را کپی کرده و در نتیجه سلولهای مختلف بدن بهوجود آمدهاند.
در یونیکس، وقتی ()fork انجام میشود، دو برنامه تقریباً شبیه هم هستند. در بدن هم وقتی یک سلول تقسیم میشود، دو سلول شبیه به هم ایجاد میشوند. اما بعد از این تقسیم، هر سلول ممکن است وظیفه و مسیر خاص خودش را پیدا کند (مثلاً یکی تبدیل به سلول مغز شود و دیگری به سلول پوست).
اما اگر این تقسیمها از کنترل خارج شوند و سلولها همینطور بیوقفه خودشان را کپی کنند، مثل این میشود که در سیستمعامل، یک برنامه مدام()fork کند و هزاران برنامهی بیهدف بسازد. این اتفاق در دنیای کامپیوتر به «بمب fork» معروف است و در بدن، ما به آن تومور یا سرطان میگوییم.
برای جلوگیری از این فاجعه، بدن چند سیستم کنترلی دارد:
تِلومیِرها (Telomeres): بخشهایی در انتهای DNA هستند که هر بار سلول تقسیم میشود، کمی کوتاهتر میشوند. وقتی خیلی کوتاه شدند، سلول دیگر اجازهی تقسیم ندارد.
واچداگها (Watchdogs): مانند نگهبانهایی هستند که وضعیت سلول را همیشه بررسی میکنند. اگر مشکلی ببینند، جلوی تقسیم بیشتر را میگیرند.
محدودیتهای امنیتی: بدن فقط در شرایط خاص اجازهی تقسیم سلول را میدهد. یعنی بهصورت پیشفرض، دسترسی به تقسیم سختگیرانه تنظیم شده است.
اما اگر این سیستمها به هر دلیلی خراب شوند یا آسیب ببینند، ممکن است سلولها از کنترل خارج شوند و تقسیم بیپایان انجام دهند — که نتیجهاش سرطان است. این ماجرا شبیه به یکی از مسائل معروف در کامپیوتر است به نام «مسئلهی توقف» (Halting Problem) که توسط آلن تورینگ مطرح شده. این مسئله میگوید:
«هیچ راهی وجود ندارد که بتوان همیشه پیشبینی کرد یک برنامه در نهایت متوقف میشود یا نه.»
به همین شکل، شاید هیچ راهحل کامل و تضمینی برای جلوگیری از سرطان وجود نداشته باشد؛ چون کنترل کامل روی توقف تقسیم سلولی هم غیرممکن است.

DNA ساختاری دارد شبیه یک نردبان پیچخورده (که به آن مارپیچ دوگانه یا Double Helix میگویند). هر پلهی این نردبان از دو قسمت (دو باز یا Base) ساخته شده. این بازها فقط بهصورت جفتهای خاصی کنار هم قرار میگیرند:
A همیشه با T جفت میشود.
C همیشه با G جفت میشود.
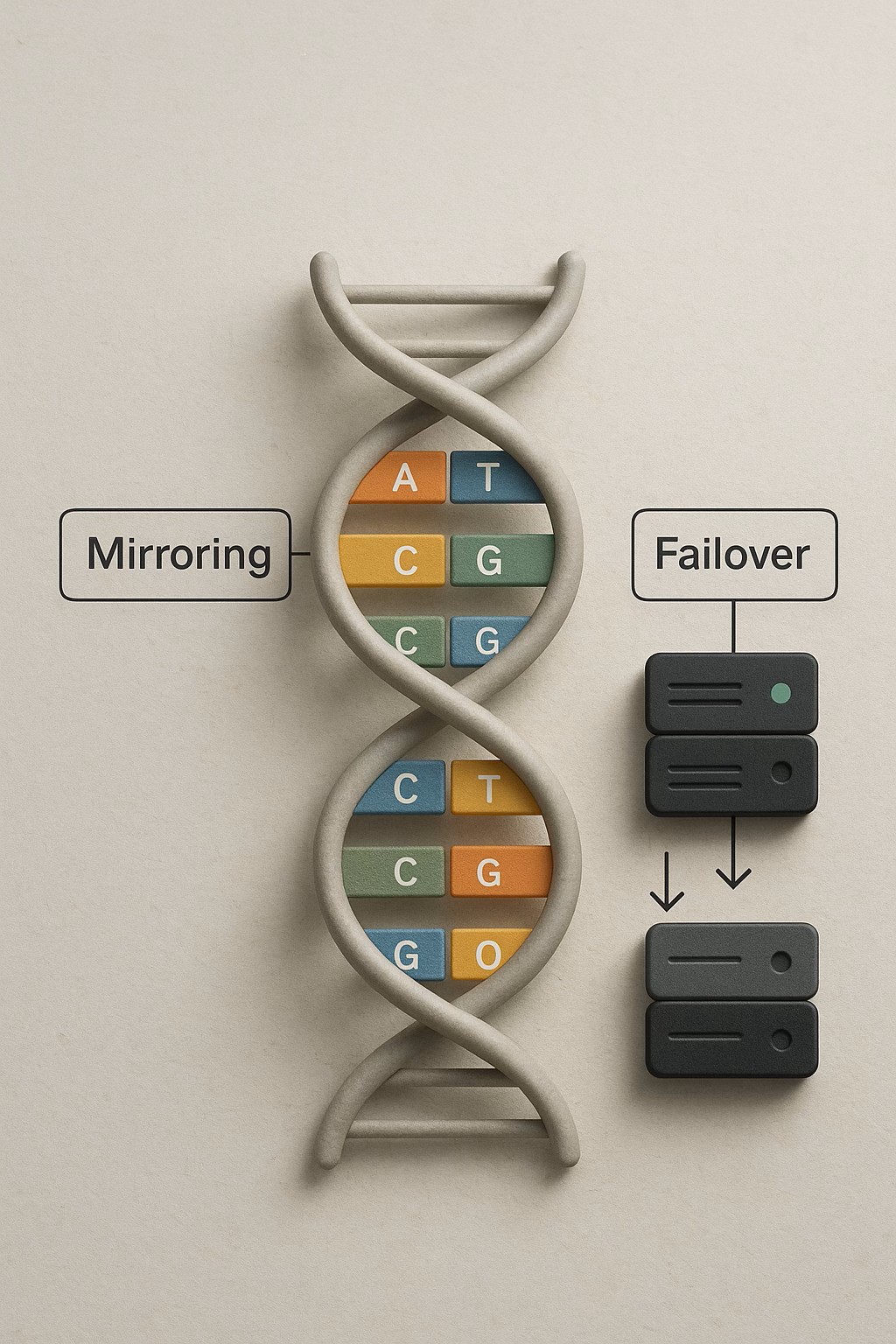
یعنی اگر یکی از این نیمهها آسیب ببیند یا گم شود، با استفاده از نیمهی دیگر میتوان دقیقاً نسخهی اصلی را بازسازی کرد.
این دقیقاً شبیه چیزی در دنیای کامپیوتر است به نام RAID-1. در این حالت، اطلاعات روی دو هارد دیسک بهصورت همزمان ذخیره میشوند. اگر یکی خراب شود، دومی هنوز سالم است و اطلاعات از بین نمیرود.
اما ماجرا از این هم جالبتر است! بدن ما از هر کروموزوم دو نسخه دارد — یکی از پدر و یکی از مادر. این یعنی بیشتر ژنها بهصورت دو نسخهای (redundant) در بدن وجود دارند. اگر یکی از نسخهها دچار آسیب یا جهش شود، نسخهی دوم هنوز هست و میتواند وظیفهاش را انجام دهد.
این هم مشابه یک مفهوم در شبکه و سرورها به نام Failover است. وقتی سرور اصلی از کار میافتد، سرور پشتیبانی خودکار وارد عمل میشود تا سیستم متوقف نشود.
اما یک استثنا هم وجود دارد!
در بدن مردان، کروموزوم Y فقط یک نسخه دارد (چون مردان XY هستند). بنابراین ژنهایی که روی کروموزوم Y قرار دارند، نسخهی پشتیبان ندارند.
به همین دلیل، اگر ژنهای موجود روی کروموزوم Y آسیب ببینند، ممکن است بدن نتواند جبران کند — و این بخشها حساستر و آسیبپذیرتر هستند.
در دنیای برنامهنویسی، وقتی چندین برنامه یا کتابخانهی نرمافزاری به هم وابسته باشند و یکی از آنها تغییر کند، ممکن است کل سیستم بههمبریزد. این وضعیت را برنامهنویسها بهدرستی "جهنم وابستگیها" (Dependency Hell) مینامند.
جالب است بدانید که در سلولهای بدن ما هم دقیقاً همین مشکل وجود دارد!
در بدن، پروتئینها مثل کارگرهای کارخانه عمل میکنند و برای انجام درست کارشان، باید با پروتئینهای دیگر هماهنگ باشند.
تحقیقات نشان دادهاند که پروتئینهایی که با تعداد زیادی پروتئین دیگر تعامل دارند، خیلی سخت و کُند تغییر میکنند یا حتی اصلاً تکامل نمییابند.
چرا این اتفاق میافتد؟
چون اگر فقط یکی از این پروتئینها تغییر کند یا جهش پیدا کند، باید همچنان با تمام پروتئینهایی که به آن وابستهاند سازگار باقی بماند.
اگر این هماهنگی از بین برود، سیستم دچار اختلال یا خرابی میشود — دقیقاً مثل وقتی که در یک نرمافزار بزرگ، نمیتوان بهراحتی یک API مهم را تغییر داد چون کلی کد دیگر به آن وابسته است.
پس...
در بدن هم، برخی پروتئینها شبیه APIهای مرکزی نرمافزار هستند:
تغییرشان دردسر دارد چون تعداد زیادی بخش به آنها وابستهاند.
این یعنی تکامل ژنتیکی هم، مثل برنامهنویسی، باید با دقت و هماهنگی بالا انجام شود — وگرنه به جای پیشرفت، با مشکل و اختلال روبهرو خواهیم شد!
در یک گفتوگو کسی گفت: «خیلی جالب میشه اگه بشه ژنوم انسان رو هک کرد و کدی نوشت که خودش رو به بقیه ژنها کپی کنه و از بدن به عنوان واسطه استفاده کنه. درست مثل کرمهای کامپیوتری مانند Nimda!»
و بعد متوجه شد که:
ویروسهای زیستی دقیقا همین کار را از میلیونها سال پیش انجام میدهند!
ویروسها کد ژنتیکی خود را وارد DNA ما کرده، خودشان را کپی میکنند و با استفاده از بدن میزبان (یعنی بدن ما) به دیگر موجودات منتقل میشوند.
خیلی از این ویروسها آنقدر خوب این کار را انجام دادهاند که امروزه بخشی از ژنوم ما شدهاند و در DNA همهی ما جا خوش کردهاند.
برای انجام این کار، ویروسها باید خیلی ماهرانه عمل کنند تا توسط سیستم دفاعی بدن، که نقش «آنتیویروس» را بازی میکند، شناسایی نشوند. اگر شناسایی شوند، از ورودشان به DNA جلوگیری میشود.
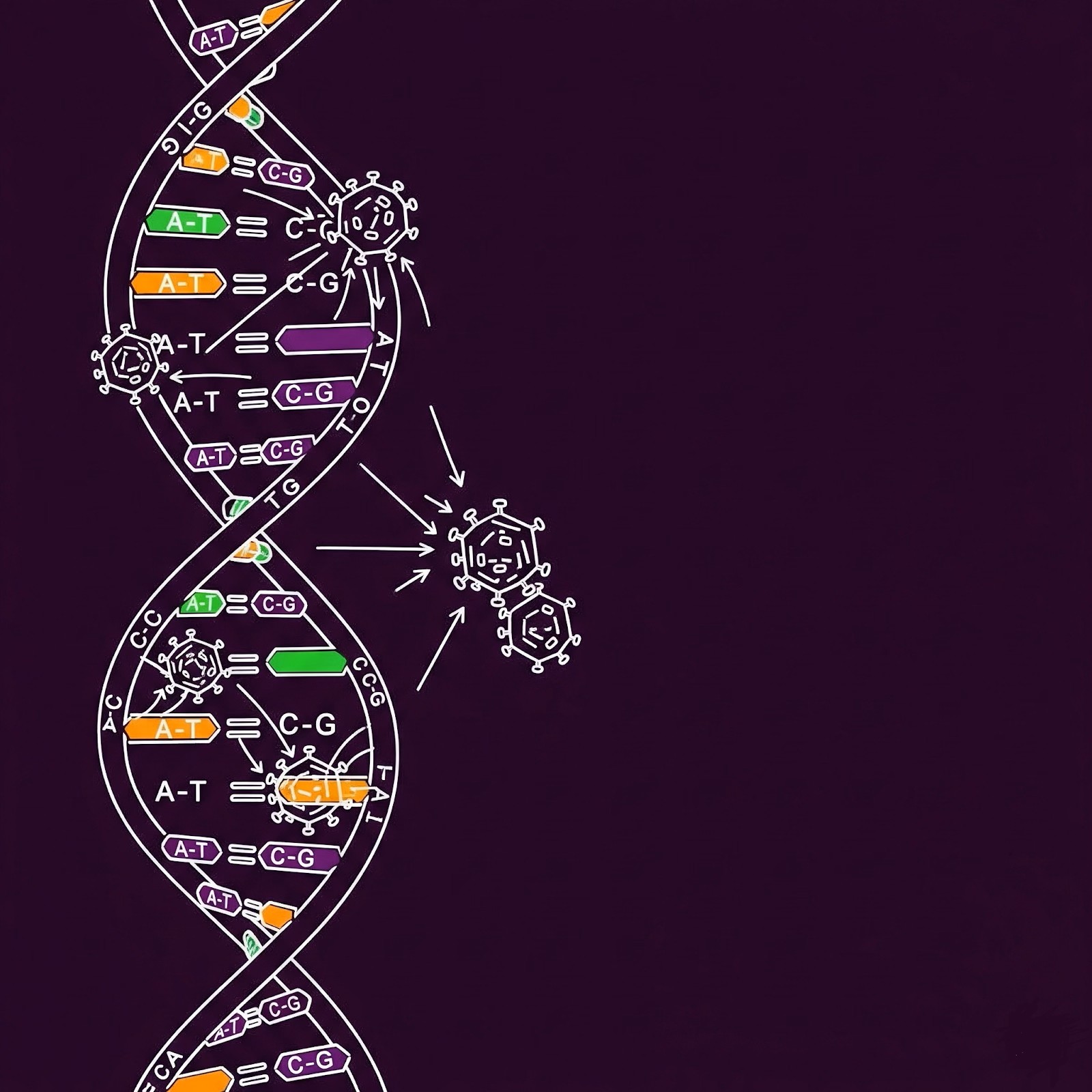
وقتی دانشمندان برای اولین بار شروع به کشف دنیای ژنتیک کردند، با انواع و اقسام مولکولهای شیمیایی روبهرو بودند که ارتباط بین آنها مشخص نبود. اما زمانی که مشخص شد اطلاعات ژنتیکی از DNA به RNA و سپس به پروتئین منتقل میشوند، این مسیر را یک کشف انقلابی دانستند و به آن نام معروف «دگما مرکزی» دادند.

اگر اهل کدنویسی باشی، این فرایند خیلی آشناست. فرض کن یک فایل مثل main.c داری:
اول کامپایل میشه و تبدیل میشه به فایل میانی main.o
بعد هم تبدیل میشه به یک فایل اجرایی مثل main.exe
در زیستشناسی هم همین اتفاق میافته:
اطلاعات از DNA استخراج میشوند، به شکل RNA دراومده و بعد برای ساختن پروتئینها بهکارمیروند.
طبق این قانون، اطلاعات فقط در همین مسیر حرکت میکنه و به عقب برنمیگرده.
اما مثل هر سیستم قدیمی... گاهی قانون شکسته میشه!
در دنیای واقعی، سیستمها همیشه استثنا دارند. مثلاً در برنامهنویسی، گاهی بعد از اجرای برنامه، یه پَچ (Patch) روی سورسکد میزنی!
در ژنتیک هم همینطوره:
گاهی RNA میتونه دوباره روی DNA تاثیر بذاره (مثلاً ویروس HIV این کارو میکنه).
یا حتی پروتئینهایی که ساخته شدند، ممکنه دوباره برگردند و تغییراتی در DNA ایجاد کنند.
ولی همچنان...
با همهی این استثناها، مسیر اصلی DNA→ RNA → Protein همچنان ستون فقرات زیستشناسی مولکولی محسوب میشه.
درست مثل اینکه بگیم «قانون اصلی هنوز پابرجاست، فقط بعضی وقتا یه میانبُر یا پَچ هم هست!»
تغییر دادن DNA خیلی راحتتر از تغییر دادن بدن انسان زنده است.
الان شرکتهایی وجود دارد که اگر یک فایل متنی پر از حروف DNA براشون بفرستیم، اون DNA را تولید میکنند!
ما حتی میتونیم DNA جدید رو وارد جنین حیوانات یا گیاهان در حال رشد کنیم.
اما کاری که خیلی سخته اینه که بخوایم بدن یک آدم زنده رو پَچ کنیم!
یعنی درست مثل وقتی که بخوایم یک برنامهی در حال اجرا را وسط کار تغییر بدیم. برنامهنویسها خوب میدونند این چقدر دردسر داره!
در مورد بیماری خیلی خطرناکی به نام SCID (نوعی نقص سیستم ایمنی) سالهاست میدونیم که فقط باید چند حرف از DNA این بیماران رو درست کنیم تا خوب شوند.
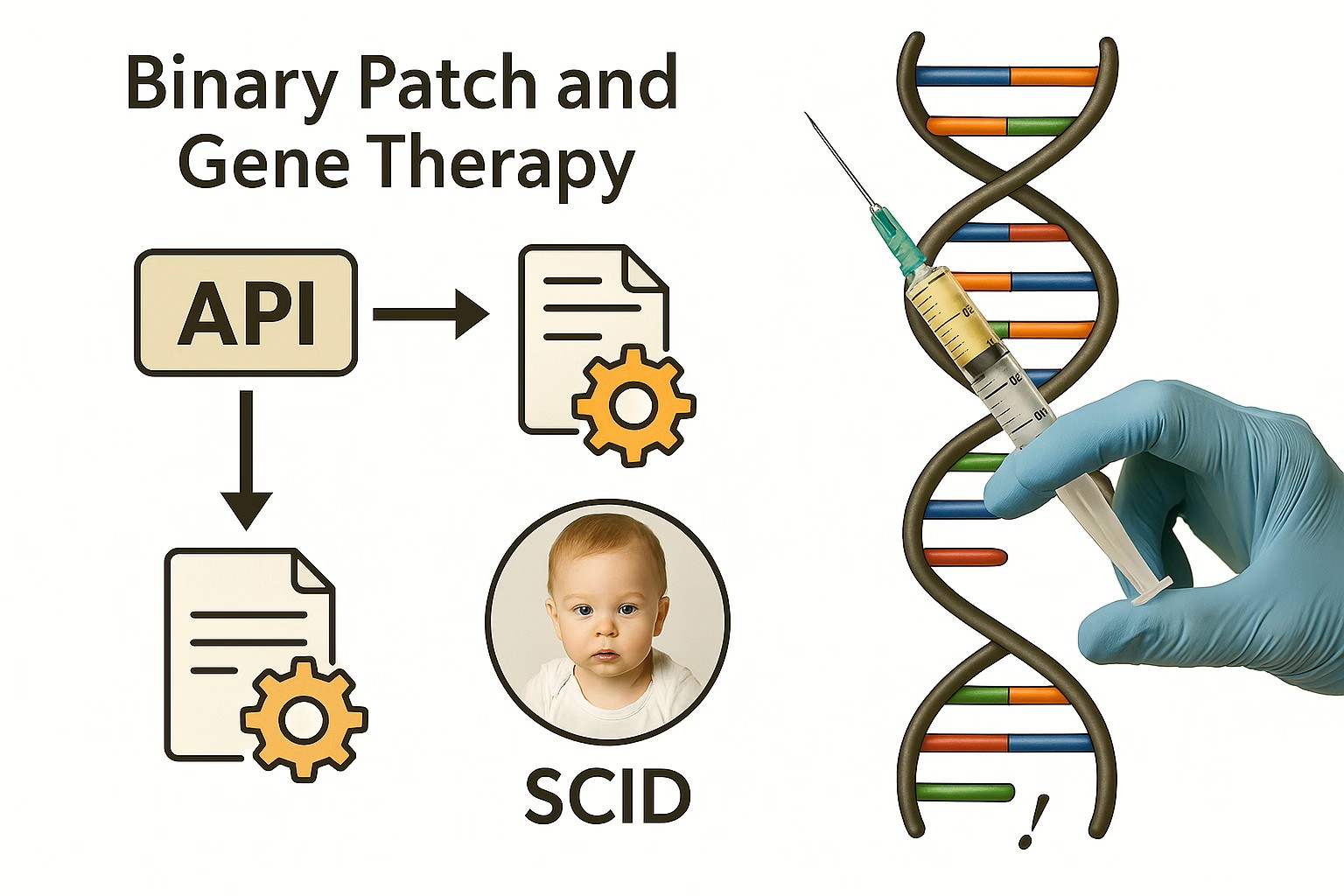
ولی انجام این کار در بدن زنده خیلی سخت بود. چون بدن ما مثل یک سیستم امنیتی قوی جلوی ورود کد خارجی رو میگیره — حتی از مایکروسافت هم محافظت بهتری داره!
با این حال، اخیراً یک ویروس خاص پیدا شده که میتونه از این سد امنیتی عبور کنه و ژن معیوب رو اصلاح کنه.
نتیجه؟ بیماران مبتلا به SCID بعد از این درمان، کاملاً سالم شدن!
همونطور که در کامپیوتر، دادهها ممکنه خراب شوند (مثلاً هنگام انتقال یا ذخیرهسازی)، در بدن ما هم DNA یا RNA ممکنه اشتباهاتی داشته باشند — مثلاً یه «حرف» از کد ژنتیکی عوض بشه.
اما بدن یک ترفند هوشمندانه داره که کمک میکنه حتی وقتی خطا اتفاق افتاد، نتیجهی نهایی سالم بمونه!
RNA فقط از ۴ حرف ساخته شده:
A, U, C, G
هر ۳ حرف کنار هم کدی میشوند که مشخص میکنه چه آمینواسیدی ساخته بشه.
مثلاً:
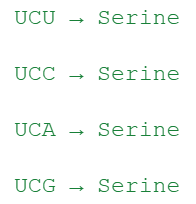
یعنی حتی اگر یکی از حروف اشتباهی عوض بشه (مثلاً UCU بشه UCC)، باز هم همون آمینو اسید ساخته میشه!
این یعنی سیستم ژنتیکی ما بهطور پیشفرض مقاوم در برابر خطاهای کوچک طراحی شده. درست مثل تکنولوژیای که توی کامپیوتر استفاده میشه به اسم:
Forward Error Correction یا FEC
یکی از معروفترین مثالهاش کدهای رید-سولومون (Reed–Solomon Codes) است که مثلاً توی CD و DVD هم استفاده میشوند. این کدها اجازه میدهند خطاهای جزئی اصلاح بشه، حتی بدون نیاز به ارسال دوبارهی اطلاعات.
در DNA هم اینطوره:
سیستم رمزگذاری RNA طوری طراحی شده که کدهای مشابه، نتیجهی مشابهی بدهند.
حتی اگر یک حرف اشتباه بشه، نتیجه میتونه همون بمونه که پایداری سیستم را نشان میدهد.
این باعث میشه خطاهای کوچک، آسیبی به پروتئین نهایی نزنند.
پیشنهاد مطالعه:
برای مطالعه بیشتر دربارهی این موضوع جالب، کتاب Metamagical Themas نوشته داگلاس هافستدر را پیشنهاد میکنیم. این کتاب پر از ایدههای عجیب، جالب و فلسفی دربارهی هوش، زبان، کد و ساختارهای تکرارشوندهست. اگر از ترکیب علوم و تفکر منطقی خوشتون میاد، حتماً برای مطالعه کتاب خوبیه.
بعضی کدها در برنامهنویسی آنقدر حیاتیاند که کسی جرأت دست زدن به آنها را ندارد؛ حتی اگر سازندهی آنها رفته باشد. فقط میدانیم که "کار میکند".
در ژنتیک هم چنین چیزی وجود دارد. برخی ژنها مثل ساعت مولکولی ثابت و بدون تغییر میمانند. برای نمونه، ژنهای هیستون H3و H4 بسیار حساس هستند و اگر تغییر کنند، موجود زنده نمیتواند به درستی کار کند.
این ژنها مسئول بستهبندی و سازماندهی کل DNA در سلول هستند. جالب اینکه در انسان، این ژنها اصلاً جهش نمیکنند (نرخ جهش = صفر). حتی با مرغ، چمن یا قارچ هم این ژنها تقریباً یکی هستند!

پس برای جلوگیری از جهش، دو روش اصلی وجود دارد:
۱)استفاده از کدهای تکراری (مثلاً چند کد مختلف که یک آمینواسید بسازند).
۲)کپیبرداری از ژنها در شرایط مناسب سلول (مثلاً در زمان خاصی از تقسیم سلولی).
به نظر میرسد ژنهای H3 و H4 با دقت زیاد نوشته شدهاند و حتی اگر تغییر کوچکی هم رخ دهد، تاثیری بر خروجی ندارند.
در کدهای دیجیتال، مشخص بودن مرز بین بایتها مهم است. مثلاً این دنباله:

نمایندهی اعداد ۱، ۲ و ۳ است. اما اگر جابهجا بخوانیم:

اعداد ۲، ۴ و ۶ را بهدست میآوریم! پس برای جلوگیری از این مشکل، در بسیاری از سیستمهای دیجیتال از بیتهای شروع و پایان استفاده میشود.
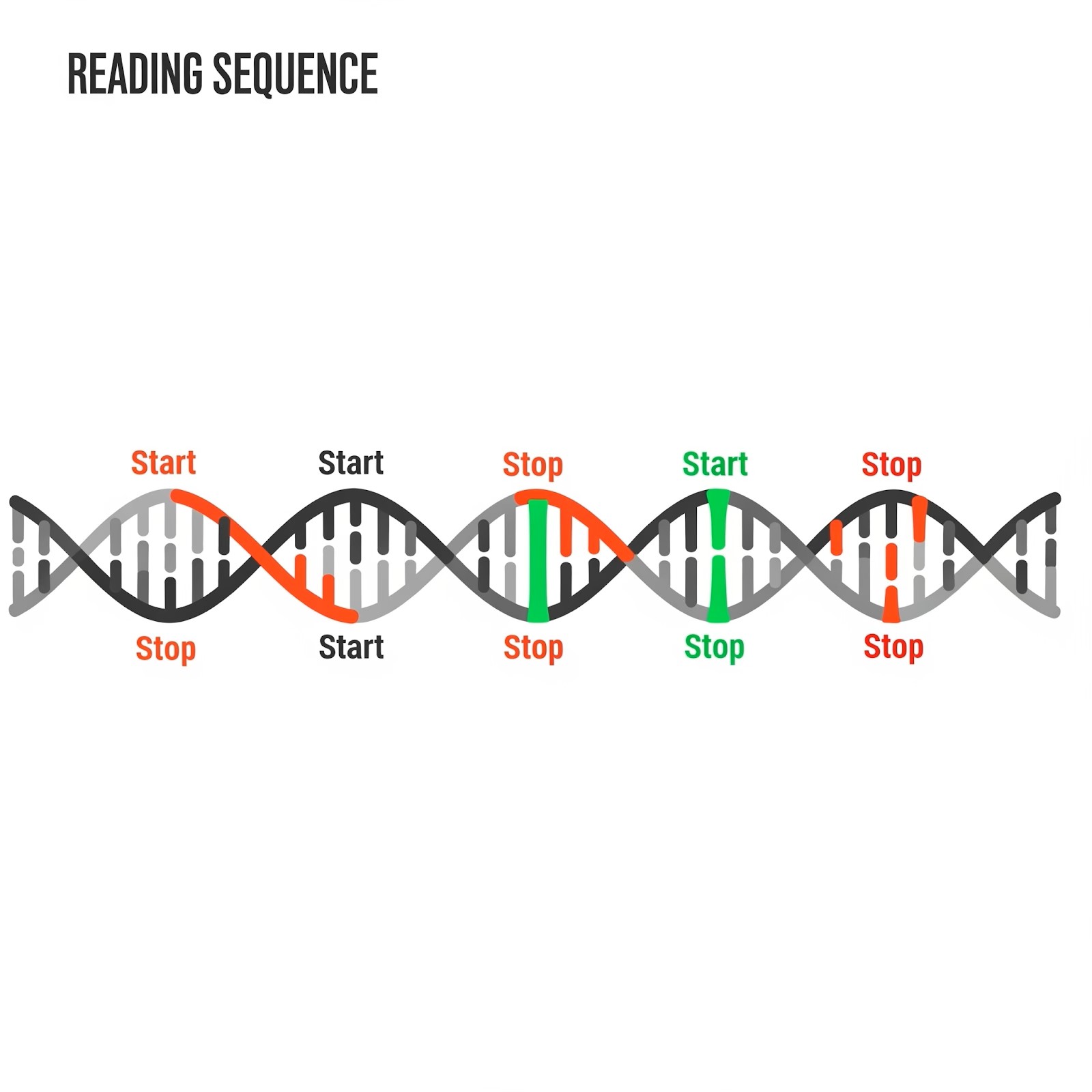
در DNA هم مکانهایی برای شروع خواندن تعریف شدهاند. این کمک میکند تا سلول بداند از کجا شروع کند. جالب اینکه برخی تکههای DNA از چند نقطهی شروع قابل خواندن هستند و هر بار خروجی متفاوت ولی مفیدی تولید میکنند! به این حالت میگویند "Open Reading Frame".
در مجموع، هر رشتهی DNA معمولاً ۶ روش مختلف برای خواندن دارد (۳ جهت رو به جلو و ۳ جهت رو به عقب).
DNA مثل یک زبان برنامهنویسی کامپیوتری نیست. واقعاً نیست. اما شباهتهای زیادی وجود دارد که میتوانیم از آنها بهره ببریم. میتوانیم هر سلول را مانند یک پردازنده (CPU) تصور کنیم که هستهی خود را اجرا میکند. هر سلول یک نسخه از کل هسته را دارد، اما تنها بخشهای مرتبط را فعال میکند. به عبارت دیگر، مانند این است که هر سلول بخشی از سیستمعامل خود را در اختیار دارد و بسته به نیاز، تنها ماژولها یا درایورهای خاصی را بارگذاری میکند.
وقتی یک سلول نیاز به انجام کاری دارد (مانند "فراخوانی یک تابع" در دنیای برنامهنویسی)، بخش مربوطه از ژنوم را آماده میکند و آن را به RNA تبدیل میکند. سپس RNA به یک دنباله از اسیدهای آمینه ترجمه میشود، که در کنار هم یک پروتئین میسازند و DNA برای آن کد نوشته است. حالا این قسمت واقعاً جالب است :-)
این پروتئین با یک آدرس تحویل علامتگذاری میشود. این آدرس یک نشانگر متشکل از چند اسید آمینه است که به باقیماندهی سلول میگوید این پروتئین باید به کجا برود. دستگاههای مختلفی وجود دارند که این دستورات را پردازش کرده و پروتئین را به مقصد مورد نظر میفرستند، جایی که ممکن است این پروتئین به قسمت خارجی سلول ارسال شود.
سپس دستورالعمل تحویل از پروتئین جدا میشود و مراحل پردازش بعدی ممکن است انجام شوند که میتواند منجر به فعال شدن پروتئین شود – و این خوب است، زیرا شما ممکن است نخواهید که یک پروتئین فعال را از مکانهایی عبور دهید که نباید در آنجا فعالیت کند.
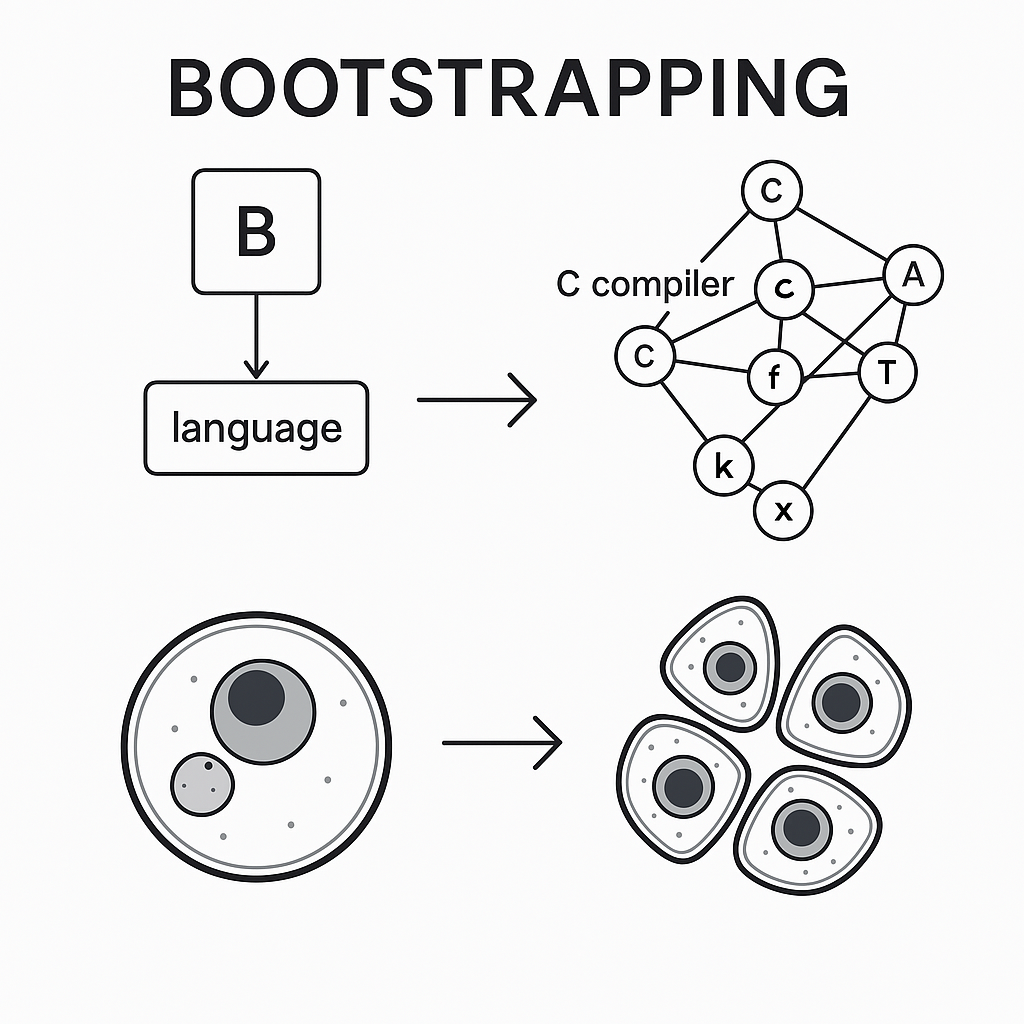
اگر تمام کامپایلرهای C موجود در کره زمین را از بین ببریم و فقط کد یکی از آنها را باقی بگذاریم، با مشکل بزرگی روبهرو خواهیم شد. بله، ما کد C برای یک کامپایلر C داریم، اما برای کامپایل کردن آن به یک کامپایلر C نیاز داریم!
در واقع، این مشکل با نوشتن اولین کامپایلر C در زبان C حل نشد (آها)، بلکه با استفاده از یک زبان موجود به نام B حل شد. برای جزئیات بیشتر میتوانید به «بوتاسترپینگ» مراجعه کنید.
همین قضیه برای ژنوم هم صدق میکند. برای ایجاد یک «دستگاه باینری» از یک موجود زنده، نسخه زنده آن موجود لازم است. ژنوم به یک زنجیره ابزار پیچیده نیاز دارد تا یک موجود زنده را تحویل دهد. خود کد بیاثر است. این زنجیره ابزار معمولاً به نام «والدین شما» شناخته میشود.
آپدیت: اخیراً این امکان فراهم شده است که با استفاده از مقدار کمی مادهی زنده، زندگی جدیدی ایجاد شود. شعار «هر سلول از یک سلول بهوجود میآید» در حال تغییر است. برای مثال، پروژه Mycoplasma laboratory یک نمونه از این پیشرفتها است.
به نظر میرسد که RNA، که به عنوان کد میانه بین DNA و پروتئین عمل میکند، ممکن است همان زبان «B» برای DNA بوده باشد. حالا این سوال پیش میآید که RNA از کجا آمده است؟ جالب است که اشیاء فرازمینی اغلب حاوی اسیدهای آمینه هستند!
بوتاسترپینگ (Bootstrapping) یک مفهوم مهم در علوم کامپیوتر و مهندسی نرمافزار است که به معنی شروع یک فرایند پیچیده از طریق یک مرحلهی سادهتر و پایهایتر است.
مثلاً فرض کنید میخواهیم یک کامپایلر (برنامهای که کدهای برنامهنویسی را به زبان قابل فهم کامپیوتر تبدیل میکند) بنویسیم. مشکل اینجاست که برای ساختن کامپایلر جدید، معمولاً باید از یک کامپایلر دیگر استفاده کنیم. پس چگونه اولین کامپایلر ساخته شده؟ اینجا بوتاسترپینگ وارد میشود.
بوتاسترپینگ یعنی: با استفاده از یک سیستم یا ابزار سادهتر (مثلاً یک زبان برنامهنویسی سادهتر یا برنامهای که قبلاً ساخته شده)، ابتدا نسخهی اولیهای از سیستم پیچیدهتر را میسازیم. سپس این نسخه اولیه خودش را بهبود میدهد و نسخههای بهتر و کاملتری تولید میکند.
نام «بوتاسترپ» (بوتاسترپ به معنی بند کفش یا تسمهی بوت است) از این ایده آمده که انگار میخواهی خودت را از زمین بلند کنی فقط با کشیدن بند کفشهایت! یعنی شروع یک کار بزرگ با استفاده از ابزارهای بسیار ابتدایی.
در دنیای زیستشناسی، بوتاسترپینگ شبیه همان کاری است که سلول مادر برای ایجاد سلول جدید انجام میدهد. یعنی ژنوم به تنهایی نمیتواند زندگی ایجاد کند، بلکه به ماشینآلات و ابزارهای سلول موجود نیاز دارد تا آن را فعال کند و موجود جدید ساخته شود.
هر موجود زنده، زندگی خود را از یک سلول واحد آغاز میکند. این سلول شامل دو نسخهی کامل از ژنوم است، یعنی مانند یک فایل فشرده (مثل tarfile) است که تمام محتویات آن از قبل استخراج شدهاند و آمادهی استفاده هستند. اما سوال اصلی اینجاست: بعد از این مرحله چه اتفاقی میافتد؟
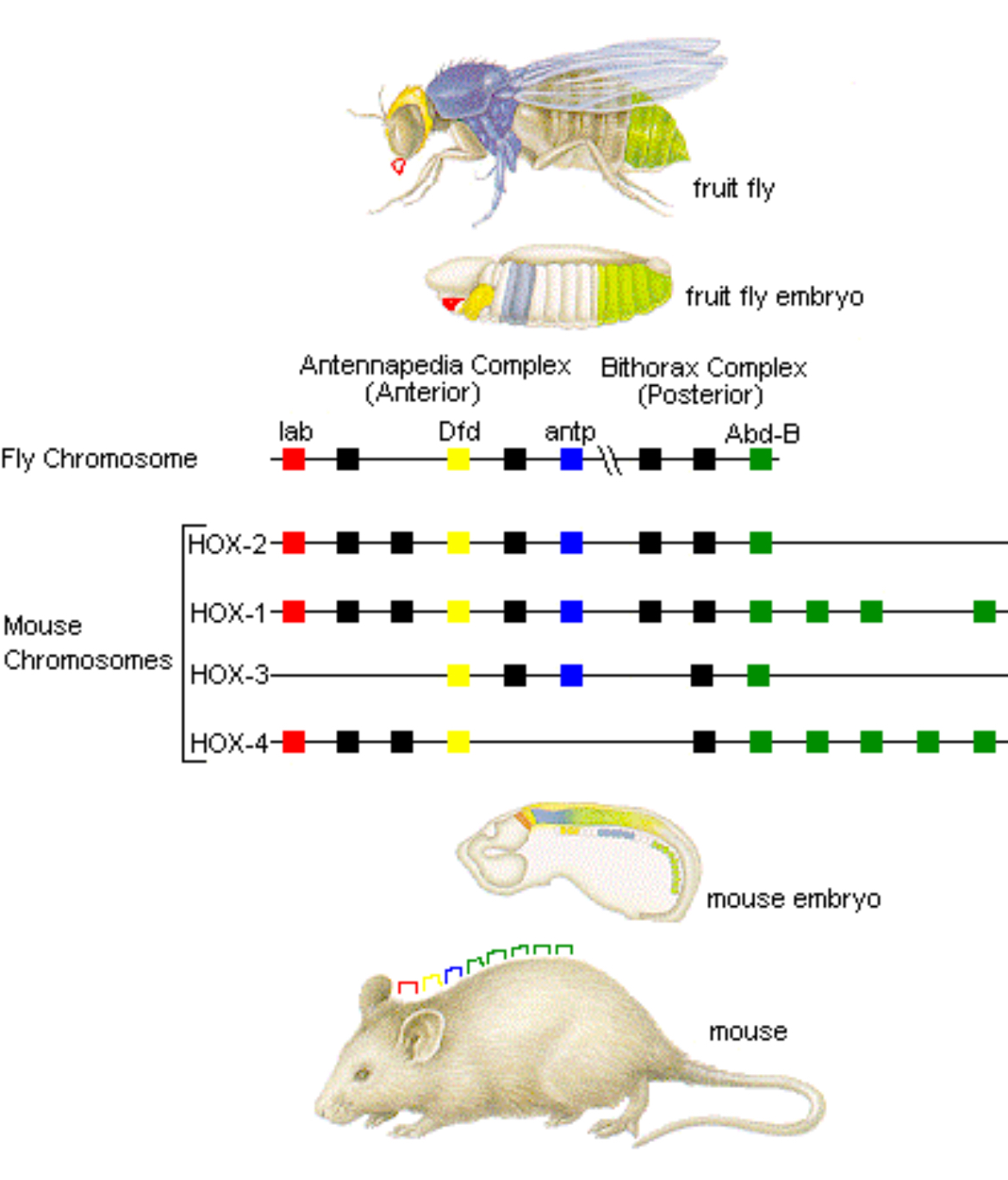
اینجاست که ژنهای ویژهای به نام ژنهای Homeobox (یا Hox) وارد عمل میشوند. این ژنها به سلولها کمک میکنند تا در حین تکثیر و رشد، تشخیص دهند که چه نقشی باید ایفا کنند. برای مثال، برخی سلولها باید به سلولهای مغز تبدیل شوند، برخی دیگر به سلولهای قلب یا استخوان.
ژنهای Hox به گونهای رفتار میکنند که انگار در حال اجرای یک فایل Makefile هستند، درست مانند دنیای برنامهنویسی که در آن یک فایل Makefile مشخص میکند کدام بخش از برنامه چه زمانی و به چه ترتیبی اجرا شود. ژنهای Hox به سلولها نمیگویند مستقیماً چه چیزی بسازند، بلکه آنها را راهنمایی میکنند که کدام ژنهای دیگر را فعال کنند.
در ابتدای فرآیند رشد، ژنهای Hox یک گرادیان شیمیایی ایجاد میکنند تا به سلولها کمک کنند موقعیت خود را در بدن در حال رشد تشخیص دهند. این گرادیان، به نوعی مثل یک GPS عمل میکند و مشخص میکند که سلول در «بالای» بدن قرار دارد یا «پایین». مثلاً ممکن است دستور داده شود:
«از ساخت سر شروع کن»
و سلولهایی که در ناحیهی بالایی بدن قرار دارند، مسیر تولید ساختارهای مربوط به سر را آغاز کنند. در مقابل، سلولهایی که پایینتر هستند، شروع به ساخت نوتوکورد(محور پشتی ابتدایی) یا ستون فقرات میکنند.
یکی از جالبترین کشفیات دربارهی ژنهای Hox، شباهت عملکرد آنها بین گونههای بسیار متفاوت است. برای مثال، اگر بخشی از ژن Hox موش را که مسئول ساختن پا است، در ژنوم مگس میوه(Drosophila) قرار دهید، آن ژن میتواند باعث رشد پا به جای شاخک پشه شود!
بهطور دقیقتر:
«وقتی ژن Hox-B6 موش در بدن مگس میوه قرار داده شود، میتواند جای ژن Antennapedia را بگیرد و باعث شود بهجای شاخک، پا رشد کند.»
این موضوع نشان میدهد که ژنهای Hox در گونههای مختلف مانند انسان و حشرهها، با اینکه صدها میلیون سال پیش از هم جدا شدهاند، هنوز میتوانند به صورت صحیح در بدن موجودات دیگر کار کنند.
البته باید توجه داشت که روند ساختن پا در موش و پشه کاملاً متفاوت است، اما چیزی که این آزمایش ثابت میکند این است که ژنهای Hox مانند یک Selector (انتخابگر) عمل میکنند: آنها مشخص میکنند کدام فرآیندها باید فعال شوند، اما مستقیماً دخالتی در ساخت ساختارها ندارند.
در دنیای زیستشناسی، همهی موجودات زنده دارای DNA هستند. این مادهی ژنتیکی مانند یک کتابخانهی عظیم از دستورالعملها عمل میکند و به سلولها میگوید چگونه کار کنند، چه بسازند و چگونه واکنش نشان دهند. در انسانها و دیگر موجودات پیچیدهتر، این DNA معمولاً به صورت چندین کروموزوم خطی ذخیره میشود، مثل کتابهایی که کنار هم در یک کتابخانه قرار گرفتهاند.
اما در باکتریها، ماجرا سادهتر است. باکتریها معمولاً فقط یک کروموزوم دایرهای دارند. این کروموزوم، اطلاعات ژنتیکی اصلی باکتری را در بر دارد و تمام کارهای اساسی و حیاتی سلول را مدیریت میکند.
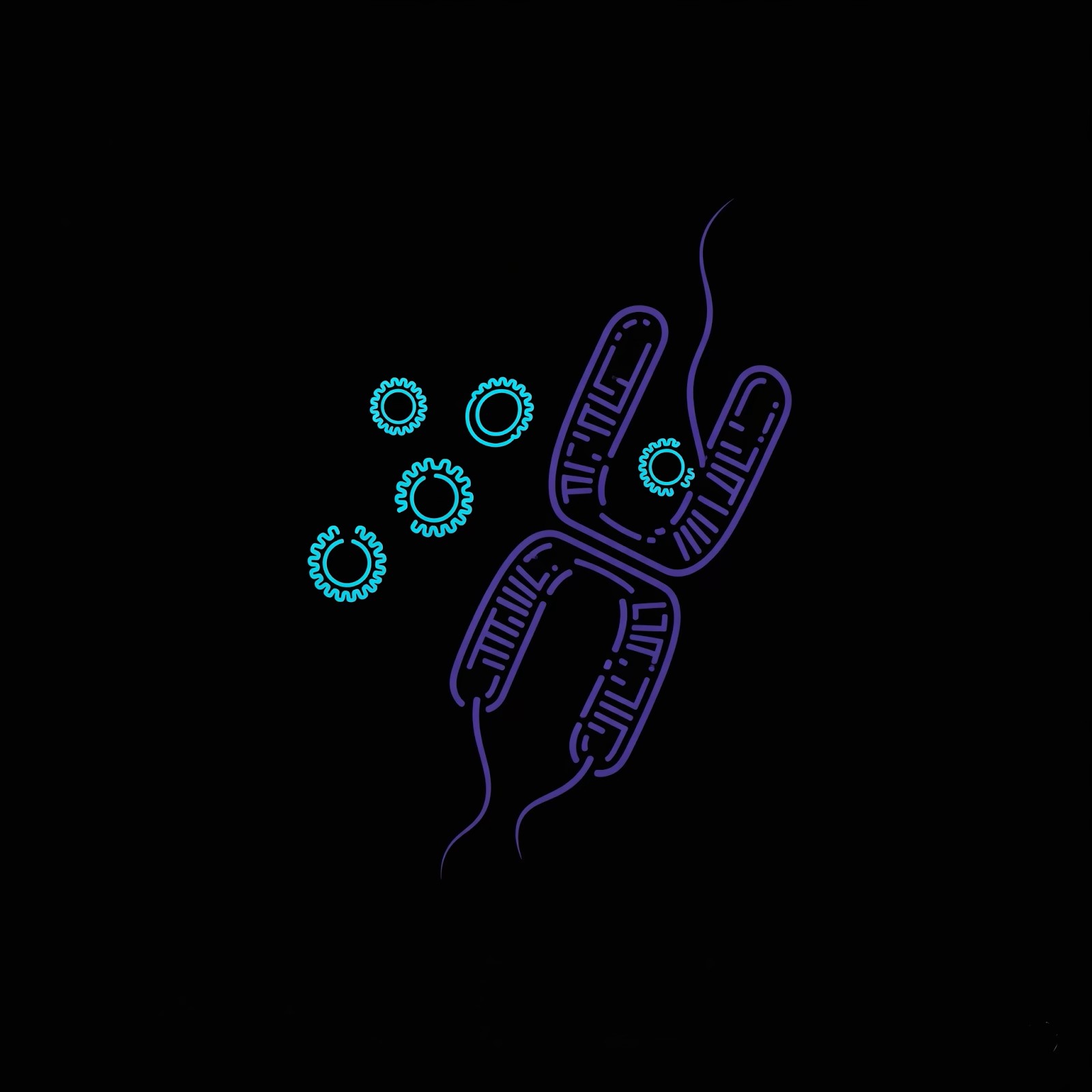
در کنار این ژنوم اصلی، بسیاری از باکتریها دارای بخش اضافهای از DNA هستند که به آنها پلاسمید (Plasmid) گفته میشود. پلاسمیدها حلقههای کوچکی از DNA هستند که به طور مستقل از کروموزوم اصلی عمل میکنند. این قطعات DNA اضافی مثل کتابهای جیبی تخصصیاند که باکتریها در کنار کتابخانهی اصلی خود نگهداری میکنند. آنها حاوی اطلاعات خاصی هستند که معمولاً برای بقا در شرایط سخت یا رقابت با دیگر موجودات استفاده میشوند.
یکی از مهمترین ویژگیهای پلاسمیدها، قابلیت جابهجایی آنهاست. پلاسمیدها میتوانند از یک باکتری به باکتری دیگر منتقل شوند، حتی اگر از گونههای متفاوت باشند. این انتقال باعث میشود ویژگیهایی مانند مقاومت به آنتیبیوتیکها خیلی سریع بین باکتریها گسترش پیدا کند. به همین دلیل، پلاسمیدها نقش بسیار مهمی در گسترش مقاومت دارویی در سطح جهانی دارند، و این مسئله یکی از نگرانیهای اصلی در پزشکی امروز است.
برای درک بهتر عملکرد پلاسمیدها، میتوان آنها را با مفاهیمی در دنیای برنامهنویسی و سیستمعاملها مقایسه کرد. در سیستمعامل لینوکس، قابلیتی به نام LD_PRELOAD وجود دارد. این ابزار میتواند بدون اینکه برنامهی اصلی متوجه شود، برخی از توابع آن را تغییر دهد یا به شکل دلخواه رفتار برنامه را عوض کند. این تغییر به صورت داوطلبانه توسط برنامهها اتفاق نمیافتد، بلکه گاهی اوقات به شکل اجباری اعمال میشود تا عملکرد سیستم تغییر یابد. پلاسمیدها نیز دقیقاً چنین نقشی در سلول دارند: آنها بخشی از DNA اصلی نیستند، اما وقتی وارد باکتری میشوند، بدون معطلی شروع به فعالیت میکنند و میتوانند ساختار و رفتار باکتری را تغییر دهند. این کار ممکن است به نفع باکتری باشد، مثلاً باکتری را در برابر آنتیبیوتیک مقاوم کند یا کمک کند آنزیم خاصی تولید کند.
از نظر عملکردی، پلاسمیدها به صورت مستقل از DNA اصلی تکثیر میشوند. به این معنا که اگر یک باکتری بخواهد تقسیم شود و از خودش یک نسخهی جدید بسازد، پلاسمیدها هم به شکل جداگانه و خودکار کپی میشوند و به سلولهای جدید منتقل میشوند. این توانایی به کمک بخشی از DNA پلاسمید انجام میشود که به آن "Origin of Replication" یا «مبدأ تکثیر» گفته میشود. این قسمت، مثل یک نقطهی شروع برای نسخهبرداری عمل میکند و وقتی باکتری آمادهی تقسیم میشود، این بخش فعال شده و پلاسمیدها شروع به تکثیر میکنند.
در مجموع، پلاسمیدها را میتوان مانند افزونههایی در نظر گرفت که بر روی یک برنامهی اصلی نصب میشوند. آنها به صورت مستقل کار میکنند، ویژگیهایی به سیستم اضافه میکنند، قابل انتقال هستند، و در زمان مناسب کپی میشوند تا در نسل بعدی هم باقی بمانند. این ساختار هوشمندانه و انعطافپذیر، یکی از رازهای موفقیت باکتریها در بقا و تکامل سریع آنهاست.
لینک توضیحات مربوطه:
قسمت اول:
https://youtu.be/EcGM_cNzQmE?si=R-qmXRBDUoM8W998
قسمت دوم:
https://youtu.be/rCdhsN--Mdo?si=zyVzFITEsLJNYnRi
نشریه فرامتنو جاهای مختلف مخصوصا تلگرام دنبال کنید:)
کلی اتفاق میفته اونجا.