
۱. تاریخچه نتفلیکس
نتفلیکس در سال ۲۰۰۷ خدمات استریم ویدیو را راهاندازی کرد که به کاربران اجازه می داد محتوا را بدون نیاز به دانلود مستقیماً مشاهده کنند. در ابتدا محتوای غیر اوریجینال در آن عرضه می شد ولی به تدریج شروع به تولید محتوای اختصاصی خود مثل سریال ها و فیلم ها کردند. تا سال ۲۰۱۰، نتفلیکس به ۲۰ میلیون مشترک در سراسر جهان دست یافت. در طی سالهای بعدی نیز به رشد خود ادامه داد و در حال حاضر بیش از 302 میلیون مشترک، بزرگترین سرویس استریم ویدیو در جهان محسوب می شود.
نتفلیکس به یکی از محبوبترین پلتفرمهای استریم فیلم و سریال در جهان تبدیل شده است و به طور مداوم در حال رشد و توسعه است. این شرکت که به غول استریمینگ شهرت دارد، به دلیل معماری ابری پیچیده خود که قابلیت اطمینان، مقیاسپذیری و عملکرد را برای کاربران در سراسر جهان تضمین میکند، شناخته شده است. نتفلیکس روی دو ابر AWS و Open Connect کار میکند. این دو سرویس ابری به عنوان ستون فقرات Netflix با هم کار می کنند و هر دو مسئولیت اساسی در ارائه ویدیو به کاربران دارند.
۲. اجزای اصلی معماری نتفلیکس

الف) کلاینت: دستگاهها و رابط کاربری که برای پخش ویدیوهای Netflix استفاده میشود. مانند تلویزیون، XBOX، لپتاپ یا تلفن همراه.
ب) زیرساخت اختصاصی Open Connect یا CDN نتفلیکس:
تعریف CDN: شبکه تحویل محتوا (content delivery network) سیستمی از سرورهای توزیع شده (شبکه) است که صفحات و سایر محتوای وب را بر اساس موقعیت جغرافیایی کاربر، مبدا صفحه وب و سرور تحویل محتوا، به کاربر تحویل میدهد.
Open Connect ویدیوی Netflix را در مکانهای مختلف در سراسر جهان ذخیره میکند. دقیقاً همان کاری که از یک CDN انتظار میرود.
وقتی پخش ویدیو را فشار میدهیم، محتوا از Open Connect به ریکوئست ارسالی پاسخ داده میشود و برای نمایش از آن استفاده میشود تا سرعت بالاتری برای دسترسی وجود داشته باشد.
سیستم شبکه تحویل محتوا (CDN)، شبکهای از سرورهای توزیع شده در نقاط مختلف جهان است. در واقع OC همان CDN اختصاصی و سفارشیسازی شده خود Netflix است که همه چیزهایی را که مستلزم پخش ویدئو است را مدیریت میکند. سرورهای Open Connect در سراسر جهان توزیع شدهاند.
سناریوی اجرایی مراحل OCها و درخواست کاربران به سایت Netflix از طریق CDNهای اختصاصی:
کاربر درخواستی برای یک ویدیو به وب سایت یا برنامه نتفلیکس ارسال میکند.
درخواست به CDN مسیریابی میشود.
سرویس CDN بررسی میکند که آیا نسخه ذخیره شده محلی از ویدیو در دسترس است یا خیر.
اگر نسخه محلی موجود باشد، CDN آن را به کاربر تحویل میدهد.
اگر نسخه محلی در دسترس نباشد، CDN درخواست را به یکی از سرورهای اصلی هدایت میکند.
سرور اصلی پس از مسیریابی، نسخهای از ویدیو را برای CDN ارسال میکند.
سرویس CDN، نسخه درخواستی را برای کاربر ارسال میکند، همچنین آن را در edge شبکه خود برای درخواستهای بعدی ذخیره میکند.
کاربر ویدیو را تماشا میکند و به همین شکل سایر درخواستها نیز مدیریت میشوند.
مزایای AWS و CDN:
مقیاسپذیری AWS و CDN: به نتفلیکس اجازه میدهند تا به راحتی با افزایش تقاضا برای خدمات خود سازگار شود.
عملکرد بهتر: CDN با کاهش زمان تاخیر و بهبود کیفیت پخش، تجربه بهتری برای کاربران ایجاد میکند.
کاهش هزینه: استفاده از خدمات ابری به نتفلیکس اجازه میدهد تا هزینههای زیرساخت را به صورت pay as you go پرداخت کند، که میتواند به صرفهجویی در هزینههای کلی منجر شود.
Reliability: استفاده از چندین منطقه AWS و CDN به نتفلیکس امکان میدهد تا در صورت خرابی در یک منطقه، به ارائه سرویس خود ادامه دهد.
OCAها در ISPها:
OCAها در ISPها نصب میشوند که باعث میشود آنها نزدیک کاربر باشند و در نهایت باعث کاهش تأخیر و بهبود کیفیت استریم میشود.
نتفلیکس پیشبینی میکند که کاربران احتمالاً ویدیوهایی را تماشا میکنند و آنها را در OCA در ساعات غیر اوج مصرف ذخیره میکنند، که استفاده از پهنای باند را کاهش میدهد و سرعت پخش را بهبود میبخشد.
نقش CDN در عملکرد:
کاهش تأخیر و بهبود زمان loading:
سرورهای توزیع شده جغرافیایی: CDN نتفلیکس سرورهایی دارد که به صورت استراتژیک در سراسر جهان قرار گرفتهاند و آنها را بدون توجه به مکان کاربران به آنها نزدیکتر میکند. این امر به طور قابل توجهی فاصله فیزیکی که دادهها باید طی کنند را کاهش میدهد و تأخیر را به حداقل میرساند و در نتیجه منجر به loading سریعتر برای ویدیوها و محتوای مرتبط میشود.
پخش با نرخ بیت تطبیقی (ABR) و بافرینگ:
ذخیرهسازی سرورهای لبه: محتوای پربازدید، از جمله نسخههای مختلف نرخ بیت جریانهای ویدیویی، در سرورهای لبه نزدیکتر به کاربران ذخیره میشود. این امکان دسترسی فوری به محتوا را بدون نیاز به دریافت آن از سرورهای اصلی میدهد و در نتیجه تأخیر را بیشتر کاهش میدهد و وقفههای بافرینگ را به حداقل میرساند.
کاهش تراکم شبکه:
همکاریهای Open Connect: نتفلیکس از طریق Open Connect با ارائهدهندگان خدمات اینترنتی (ISP) همکاری میکند و اتصالات اختصاصی را ایجاد میکند که اولویت را به ترافیک نتفلیکس میدهند. این امر از مسیرهای شلوغ اینترنت عمومی عبور میکند و مسیر مستقیمتر و کمبارتری برای انتقال داده ارائه میکند که منجر به پخش روانتر و بافرینگ کمتر میشود.
مقیاسپذیری و انعطافپذیری:
تعادل بار پویا: CDN به طور هوشمندانه ترافیک را در شبکه بزرگ سرورهای خود توزیع میکند و اطمینان مییابد که هیچ سروری بیش از حد تحت بار نباشد و گلوگاهها به حداقل برسند. این به نتفلیکس امکان میدهد جلسات (Session) پخش همزمان را بدون افت عملکرد مدیریت کند.
مقیاسگذاری خودکار بر اساس تقاضا: نتفلیکس از ابزارهایی برای مقیاسگذاری خودکار زیرساخت CDN خود بر اساس تقاضای لحظهای استفاده میکند. این امر ظرفیت کافی را در ساعات اوج تضمین میکند و از تأمین بیش از حد منابع در دورههای خلوتتر جلوگیری میکند و هزینه و عملکرد را بهینه میکند.
مزایای دیگر:
کاهش بار سرور: با ارائه محتوا مستقیماً از سرورهای لبه، CDN به طور قابل توجهی بار سرورهای اصلی نتفلیکس را کاهش میدهد و به آنها اجازه میدهد تا بر پردازش محتوا و مدیریت تحویل تمرکز کنند.
قابلیت اطمینان بهبود یافته: ماهیت توزیع شده CDN افزونگی و تحمل خطا را فراهم میکند. اگر یک سرور با مشکلی مواجه شود، سایر سرورها میتوانند ترافیک را مدیریت کنند و حتی در صورت قطع برق موضعی، توقف کار را به حداقل رسانده و پخش بدون وقفه را تضمین کنند.
پ) زیرساخت و توسعه بکاند: این بخش تمام کارهایی را که مربوط به پخش ویدئویی نباشد (مانند محتوای جدید، پردازش ویدئوها، توزیع ویدئوها روی سرورهای مختلف در نقاط مختلف جهان و مدیریت ترافیک شبکه) انجام میدهد. مؤلفه Backend شامل پایگاهدادهها، سرورها، monitoring، موتور recommendation، سرویسهای background و غیره میباشد. بیشتر این فرآیندها مانند login، recommendation، تاریخچهی کاربران، صورتحسابها، و پشتیبانی مشتری توسط سرویسهای وب آمازون (AWS) مدیریت میشوند. به عبارت دیگر، وقتی ما یک فیلم یا سریال را در نتفلیکس انتخاب میکنیم، ابتدا "بکاند" کارهای لازم برای آمادهسازی آن را انجام میدهد. سپس ویدئو بر روی شبکه CDN توزیع میشود و نزدیکترین سرور Open Connect آن را با بالاترین کیفیت و سرعت ممکن برای شما پخش میکند. AWS EC2، AWS S3، Cassandra، Hadoop و Kafka نمونههایی از سرویسهای Backend هستند.
نتفلیکس از طیف وسیعی از خدمات AWS برای پشتیبانی از عملیات خود استفاده میکند، از جمله:
سرویس Amazon EC2 برای میزبانی مایکروسرویسها و سایر برنامههای کاربردی.
سرویس Amazon S3 برای ذخیرهسازی محتوای ویدیویی.
سرویس Amazon DynamoDB برای ذخیرهسازی meta data و دادههای کاربر.
سرویس Amazon CloudFront برای توزیع محتوای استاتیک مانند تصاویر و کد جاوا اسکریپت.
سرویس ELB که به تنظیم بار کاربران روی نمونههای مختلف نرمافزاری و محتوای ویدئویی کمک میکند.
ت) رابط کاربری نتفلیکس: نتفلیکس بخش فرانتاند را به سه دلیل اصلی با ReactJS ساخته است:
سرعت راهاندازی: ReactJS به توسعهدهندگان اجازه میدهد اجزای مستقل بسازند که میتوان آنها را به راحتی تست و بهروزرسانی کرد. این امر به راهاندازی سریع ویژگیهای جدید و بهبود تجربه کاربری کمک میکند.
کارایی در زمان اجرا: ReactJS از یک DOM مجازی استفاده میکند که کارآیی رندر را بهبود میبخشد و منجر به تجربه روانتری برای کاربران میشود، به خصوص روی دستگاههای کمتوان.
ماژولار بودن: اجزای ReactJS کاملاً مستقل هستند که باعث میشود کد تمیزتر، سازمانیافتهتر و قابل نگهداریتر شود. این امر به همکاری تیمی مؤثر و توسعه سریع نرمافزار کمک میکند.
گلوگاه (سرویس عضویت): به عنوان یک سرویس پخش آنلاین مبتنی بر اشتراک مانند نتفلیکس، منبع اصلی درآمد آن، پلن عضویت است. بنابراین نتفلیکس باید بیش از 250 میلیون عضویت در سراسر جهان را مدیریت کند. پلتفرم عضویت در نتفلیکس نقش حیاتی در مدیریت کل چرخه عمر اشتراک کاربر دارد، مانند ثبت نام، تغییرات طرح، تمدید، مشکلات پرداخت، توقف یا لغو عضویت.

نکات کلیدی در مورد معماری سرویس عضویت:
پلتفرم عضویت، کاتالوگ طرح عضویت و قیمتگذاری را به صورت جهانی و با تغییرات در مناطق مختلف مدیریت میکند.
سرویس کاتالوگ قیمتگذاری طرح، مدیریت قوانین را بر اساس پیشنهادات خاص هر مکان انجام میدهد.
دو پایگاه داده CockroachDB برای ذخیره اطلاعات قیمتگذاری طرح و بازخرید استفاده میشوند.
سرویس قیمتگذاری اعضا از اقدامات اعضا، مانند تغییر طرحها یا اضافه کردن اعضای اضافی، پشتیبانی میکند.
یک میکروسرویس اختصاصی، تعاملات شرکا، از جمله فعالسازی بستهها، ثبتنامها و ادغام با پلتفرمهایی مانند اپ استور اپل را مدیریت میکند.
دادههای عضویت در پایگاههای داده Cassandra ذخیره میشوند که از سرویس اشتراک و سرویس ردیابی تاریخچه پشتیبانی میکنند.
دادههای تولید شده توسط پلتفرم برای استخراج insight در مورد ثبتنامها و پیشبینیهای درآمد، به مصرفکنندگان پاییندست ارسال میشود.
در مراحل اولیه پلتفرم عضویت نتفلیکس، تاریخچه و دادههای اعضا از طریق رویدادهای سطح برنامه ردیابی میشدند. برای دستیابی به راهکار ردیابی دادههای جزئیتر و پایدارتر، نتفلیکس روشی مبتنی بر الگوی تغییر دادهها (CDC) توسعه داد. CDC یک الگوی طراحی است که مستقیماً تغییرات ایجاد شده در یک پایگاه داده را ثبت میکند و آن تغییرات را برای پردازش یا تجزیه و تحلیل بیشتر به سیستمهای پاییندستی منتقل میکند. اتخاذ رویکردی شبیه به CDC تضمین میکند که تمام تغییرات ایجاد شده در منابع داده عضویت در یک سیستم ثبت وقایع append-only ثبت شوند، که توسط یک پایگاه داده Cassandra پشتیبانی میشود.

یکی از بهینهسازیهای اصلی انجام شده توسط نتفلیکس، اولویتبندی حذف بار است. اولویتبندی حذف بار در لایه Zuul API Gateway پیادهسازی شده است. این سیستم به طور مؤثر انواع مختلف ترافیک شبکه را مدیریت میکند و تضمین میکند که درخواستهای پخش حیاتی نسبت به ترافیک تلهمتری کماهمیتتر در اولویت قرار گیرند.
سرویس PlayAPI: یک سرویس backend حیاتی در صفحه کنترل پخش ویدئو است که مسئول رسیدگی به پخش آغاز شده توسط دستگاه و درخواستهای مجوز لازم برای شروع پخش است. PlayAPI این درخواستها را بر اساس اهمیت آنها دستهبندی میکند:
درخواستهای آغاز شده توسط کاربر (حیاتی): این درخواستها زمانی انجام میشوند که کاربر دکمه پخش را میزند و مستقیماً بر توانایی کاربر برای شروع تماشای یک نمایش یا فیلم تأثیر میگذارند.
درخواستهای pre-fetch (غیرحیاتی): این درخواستها به صورت خوشبینانه زمانی انجام میشوند که کاربر بدون زدن دکمه پخش، محتوا را مرور میکند تا در صورت تصمیم کاربر برای تماشای یک عنوان خاص، تأخیر کاهش یابد.
این شرکت یک محدودکننده همزمانی را در PlayAPI پیادهسازی کرده است که درخواستهای آغاز شده توسط کاربر را نسبت به درخواستهای pre-fetch اولویتبندی میکند، بدون اینکه دو کنترلکننده درخواست را به صورت فیزیکی تقسیمبندی کند. مکانیزم اولویتبندی فقط زمانی فعال میشود که سرور به محدودیت همزمانی رسیده باشد و نیاز به رد درخواستها داشته باشد.
پردازش افزایشی برای دادههای جدید یا تغییر یافته در گردشهای کاری: مزیت کلیدی این روش این است که فقط دادههایی را که به تازگی به مجموعه دادهها اضافه یا بهروزرسانی شدهاند، به صورت افزایشی پردازش میکند، به جای اینکه کل مجموعه دادهها را دوباره پردازش کند. این روش هزینه منابع محاسباتی را کاهش میدهد، و زمان اجرا را نیز به میزان قابل توجهی کاهش میدهد. برای پشتیبانی از پردازش افزایشی، باید تغییرات افزایشی دادهها را ثبت و وضعیت آنها را پیگیری کند. باید از تغییر آگاه باشد و بتواند تغییرات را از جدول(های) منبع ثبت کند و سپس به ردیابی آن تغییرات ادامه دهد. اطلاعات تغییر ثبت شده باید شامل تمام دادههای مرتبط، از جمله ردیفهای تغییر نیافته در جدول منبع نیز باشد. پس از ثبت اطلاعات تغییر (داده یا محدوده)، یک گردش کاری باید دادهها را به روشی کمی پیچیدهتر در جدول هدف بنویسد. نتفلیکس از نوشتن فقط با اضافه کردن (مثلاً INSERT INTO) برای اضافه کردن دادههای جدید به مجموعه دادههای موجود استفاده میکند. پس از اتمام پردازش، دادههای اضافه شده به جدول ارسال میشوند.
مقاومت در برابر خرابیها: نتفلیکس برای مقاومسازی سرویسها در برابر هر نوع خرابی، هنگام فراخوانی سایر سرویسها، مدیریت خطاها، تلاشهای مجدد و زمانهای از دست رفته را انجام میدهد.
پروتکل ارتباط با پایگاه داده: پروتکل RTMP (Real-Time Messaging Protocol) برای ارتباط با پایگاه داده استفاده میشود. این پروتکل که توسط Macromedia (اکنون متعلق به Adobe) برای پخش صدا، تصویر و دادهها از طریق اینترنت توسعه یافته است، به دلیل قابلیت تأخیر کم، به طور گسترده برای پخش زنده استفاده میشود. RTMP با تجزیه دادهها به قطعات کوچکتر و انتقال آنها از طریق یک اتصال مداوم، تحویل روان و مداوم را تضمین میکند.
قابلیت مشاهده و نظارت: نتفلیکس تأکید زیادی بر قابلیت مشاهده و نظارت دارد تا عملکرد روان پلتفرم عضویت خود را تضمین کند.
ثبت وقایع گسترده، داشبوردها و مکانیسمهای ردیابی توزیعشده، امکان تشخیص و رفع سریع خطا را فراهم میکنند. در معماری میکروسرویس نتفلیکس، این ابزارها برای شناسایی و عیبیابی مشکلات ضروری هستند.
دادههای عملیاتی برای تقویت مدلهای یادگیری ماشینی که تشخیص ناهنجاری را افزایش میدهند و فرآیندهای حل خودکار مشکل را فعال میکنند، به کار گرفته میشوند. همه این کارها برای تلاش و حفظ یک تجربه پخش بدون وقفه برای کاربران انجام میشود.
نتفلیکس از ابزارهایی مانند کیبانا و الاستیکسرچ برای ایجاد داشبورد و تجزیه و تحلیل دادههای لاگ استفاده میکند. در صورت افزایش ناگهانی نرخ خطا، این داشبوردها به تیم اجازه میدهند تا به سرعت endpoint خاص ایجادکننده مشکل را شناسایی کرده و اقدامات اصلاحی را انجام دهند.
روند تولید و استقرار ویدئوها در نتفلیکس: در قدم اول ویدیوهایی با کیفیت بالا از شرکتهای فیلمسازی دریافت میشوند، اما پیش از آنکه بر صفحه نمایش ظاهر شوند، نیاز به چندین مرحله آمادهسازی دارند. قبل از اینکه محتواهای ویدیویی در دسترس کاربران قرار گیرد، نتفلیکس باید ویدیو را به فرمتی تبدیل کند که برای دستگاه هر شخص بهترین کارایی را داشته باشد. این فرآیند Transcoding نامیده میشود. Transcoding فرآیندی است که یک فایل ویدئویی را از یک فرمت به فرمت دیگر تبدیل میکند تا فیلمها در پلتفرمها و دستگاههای مختلف قابل مشاهده باشند.
مراحل ترنسکدینگ:
تجزیه و تحلیل ویدئوی اصلی: ابتدا، ویدئوی اصلی تجزیه و تحلیل میشود تا خطاهای احتمالی شناسایی و اصلاح شوند.
انتخاب فرمتها و رزولوشنها: بر اساس دستگاههای پشتیبانی شده، نتفلیکس فرمتها و رزولوشنهای مختلفی را برای ویدئو تعیین میکند. این انتخاب شامل فرمتهای استاندارد برای تلویزیونها، رایانههای شخصی، تبلتها و تلفنهای همراه است.
انکودینگ ویدئو: سپس، ویدئوی اصلی به فرمتها و رزولوشنهای مختلف انکود میشود. این فرآیند شامل فشردهسازی ویدئو برای اطمینان از کاهش حجم دادهها بدون از دست دادن کیفیت قابل توجه است.
ذخیرهسازی و توزیع: پس از انکودینگ، ورژنهای مختلف ویدئو در سرورهای نتفلیکس ذخیره میشوند. این سرورها بخشی از شبکه تحویل محتوای (CDN) نتفلیکس هستند، که توزیع موثر ویدئوها به کاربران در سراسر جهان را تضمین میکند.
پخش بهینه: هنگامی که کاربر درخواست پخش ویدئویی را میدهد، نتفلیکس به طور خودکار بهترین ورژن ویدئو را بر اساس پهنای باند و دستگاه کاربر انتخاب میکند. این اطمینان حاصل میکند که کاربران تجربه پخش بهینهای داشته باشند، حتی در شرایط پهنای باند محدود.
پشتیبانی از Adaptive Bitrate Streaming: همچنین هر ویدیو به بخشهای زیادی تقسیم میشود تا از جریان نرخ بیت تطبیقی (adaptive bitrate streaming) پشتیبانی کند. پخش با نرخ بیت تطبیقی امکان تغییر کیفیت ویدیو را با تغییر شرایط شبکه فراهم میکند. در صورتی که شرایط شبکه ضعیف باشد، وضوح استریم هم پایین تر می آید.
مدیریت حقوق دیجیتال (DRM): علاوه بر این، یک کد ویژه برای جلوگیری از دزدی به فایلها اضافه میشود. به آن مدیریت حقوق دیجیتال (DRM) میگویند. محتوای ویدیو را رمزگذاری میکند و از دسترسی غیرمجاز جلوگیری میکند.
بهینهسازی فایلها در نتفلیکس: نتفلیکس از بیش از ۲۲۰۰ دستگاه پشتیبانی میکند و هر کدام از آنها وضوح و فرمت متفاوتی را میطلبند. برای برآوردن این نیاز، فرآیند کدگذاری ویدئو وارد صحنه میشود. مهندسان ابتدا خطاهای موجود را یافته و سپس ویدیوی اصلی را به فرمتها و وضوحهای مختلفی تقسیم میکنند. سرعت اینترنت نیز در کیفیت تماشا نقش مهمی دارد. به همین دلیل، برای هر فیلم، نتفلیکس حدود ۱۱۰۰ تا ۱۲۰۰ نسخه با رزولوشنهای متفاوت (مانند 4k و 1080p) ایجاد میکند. نتفلیکس چندین کپی برای یک فیلم با وضوحهای مختلف ایجاد میکند. این کپیها نیاز به رمزگذاری و پیشپردازش زیادی دارند. نتفلیکس ویدیوی اصلی را به تکههای کوچکتر تقسیم میکند و با استفاده از پردازشهای موازی در AWS، این تکهها را به فرمتهای مختلف (مانند mp4، 3gp و غیره) در وضوحهای تصویر مختلف (مانند 4k، 1080p و غیره) تبدیل میکند. پس از رمزگذاری، فایلهای کپی ساخته شده، به تمام سرورهای مختلف که در مکانهای جغرافیایی متفاوت توزیع شدهاند منتقل میشوند.
پخش با نرخ بیت تطبیقی (ABR): نتفلیکس به صورت لحظهای وضعیت شبکه را تجزیه و تحلیل میکند و کیفیت (نرخ بیت) جریان ویدیو را بر اساس آن تنظیم میکند. این کار با اجتناب از وقفههای بافرینگ، حتی با اتصالات کندتر، پخش روان را تضمین میکند. نسخههای با نرخ بیت پایینتر از همان محتوا نیز در دسترس هستند که با فدا کردن مقداری از کیفیت ویدیو، عملکرد بهتری در پهنای باند محدود ارائه میدهند.
پیشنمایش و بافرینگ: نتفلیکس اقدامات کاربر را پیشبینی میکند و دادههای فیلمها یا نمایشهای آینده را در پسزمینه پیشنشان میدهد. این کار یک بافر ایجاد میکند که حتی در صورت نوسانات لحظهای شرایط شبکه، پخش بدون وقفه را تضمین میکند.
کدکهای HEVC و VP9: نتفلیکس از کدکهای ویدیویی پیشرفته مانند HEVC و VP9 استفاده میکند که در عین حفظ کیفیت تصویر عالی، فشردهسازی بالایی انجام می دهند. این میزان داده مورد نیاز برای ارسال ویدیو را کاهش میدهد و نیاز به پهنای باند و پتانسیل بافرینگ را به حداقل میرساند.
قالبهای کانتینر کارآمد: آنها از قالبهای کانتینر کارآمدی مانند MP4 استفاده میکنند که سربار را به حداقل میرساند و پخش روان را تضمین میکند.
فرآیند گام به گام نحوه اطمینان نتفلیکس از کیفیت پخش بهینه:
زمانی که کاربر اپلیکیشن نتفلیکس را بر روی دستگاه خود بارگذاری میکند، ابتدا نمونههای AWS وارد عمل میشوند و برخی وظایف مانند ورود به سیستم، توصیهها، جستجو، تاریخچه کاربر، صفحه اصلی، صورتحساب، پشتیبانی مشتری و غیره را انجام میدهند.
پس از آن، زمانی که کاربر دکمه پخش را بر روی یک ویدئو فشار میدهد، نتفلیکس سرعت شبکه یا ثبات اتصال را تجزیه و تحلیل میکند و سپس بهترین سرور Open Connect نزدیک به کاربر را پیدا میکند.
بسته به دستگاه و اندازه صفحه نمایش، فرمت ویدئوی مناسب به دستگاه کاربر پخش میشود.
هنگام تماشای ویدئو، ممکن است ویدئو به صورت کیفیت پایین ظاهر شود و پس از مدتی دوباره به HD بازگردد. این اتفاق به این دلیل میافتد که برنامه به طور مداوم بهترین سرور Open Connect را برای پخش چک میکند و در صورت نیاز بین فرمتها (برای بهترین تجربه تماشا) جابجا میشود. به این قابلیت نتفلیکس، پخش تطبیقی (Adaptive) ویدئو گفته میشود.
دادههای کاربر مانند جستجوها، تماشاها، مکان، دستگاه، نظرات و پسندها در AWS ذخیره میشوند، و نتفلیکس از این دادهها برای ساخت توصیههای فیلم برای کاربران با استفاده از مدل یادگیری ماشینی یا هادوپ استفاده میکند.
انتخاب زمان Transcoding: تصمیم اینکه transcoding در چه مرحلهای صورت بگیرد نیز یک انتخاب است:
عملیات transcode در لحظه و بعد از درخواست کاربر انجام شود.
عملیات بعد از هر اضافه شدن ویدیو صورت گیرد.
در صورتی که از تصمیم اول پیروی شود برای هر فیلم (حتی اگر برای فیلمی قبلا درخواستی آمده باشد) باید transcode انجام شود و این میتواند سربار زیادی برای سیستم داشته باشد. البته میتوان بعد از هر درخواست transcode محتواهای ویدیویی را برای دیگر کاربران ذخیره کرد. اما این مورد نیز edge caseهایی مثل فیلمهایی که طرفداران زیادی دارند و در لحظه به سامانه اضافه شدهاند داشته باشد. ممکن است در لحظات ابتدایی آنقدر درخواستها زیاد شود که منابع بسیاری از سیستم استفاده شود. در نهایت نتفلیکس تصمیم گرفته است با در نظر گرفتن مزایا و معایب بیان شده، transcode را بعد از اضافه شدن هر ویدیو انجام دهد.

Zero Configuration Service Mesh with On-Demand Cluster Discovery (مش سرویس با کشف خوشه بر اساس تقاضا)
تاریخچه مختصری از IPC در نتفلیکس: نتفلیکس از اولین شرکتهایی بود که در سال ۲۰۰۸ به فضای ابری AWS روی آورد و تا سال ۲۰۱۰ پخش آنلاین نتفلیکس به طور کامل روی AWS اجرا میشد. در آن زمان، ابزارهای محیط ابری تقریباً وجود نداشتند (CNCF تا سال ۲۰۱۵ شکل نگرفته بود). از آنجایی که هیچ راهحل موجودی در دسترس نبود، نتفلیکس نیاز داشت خودش آنها را بسازد. برای ارتباط بین فرآیندی (IPC) بین سرویسها، نتفلیکس به مجموعه ویژگیهای غنیای نیاز داشت که معمولاً یک متعادلکننده بار عادی ارائه میدهد. همچنین به راهحلی نیاز داشت که واقعیت کار در فضای ابری را پوشش دهد: محیطی بسیار پویا که گرهها در آن بالا و پایین میآیند و سرویسها باید به سرعت به تغییرات واکنش نشان دهند و در صورت خرابی، مسیر خود را تغییر دهند. برای بهبود در دسترس بودن، سیستمهایی طراحی شد که اجزا بتوانند به طور جداگانه از کار بیفتند و از نقاط خرابی واحد جلوگیری کنند. این اصول طراحی نتفلیکس را به سمت متعادلکننده بار سمت کلاینت سوق داد و قطعی برق شب کریسمس ۲۰۱۲ این تصمیم را بیشتر تثبیت کرد. در طول این سالهای اولیه در فضای ابری، نتفلیکس Eureka را برای کشف سرویس و Ribbon (که در داخل شرکت با نام NIWS شناخته میشود) را برای IPC ساخت. Eureka مشکل چگونگی کشف نمونهها توسط سرویسها برای ارتباط را حل کرد و Ribbon منطق سمت کلاینت را برای متعادلسازی بار و همچنین بسیاری از ویژگیهای تابآوری دیگر فراهم کرد. Eureka و Ribbon رابط کاربری ساده اما قدرتمندی ارائه دادند.
برای اینکه یک سرویس با سرویس دیگری ارتباط برقرار کند، باید دو چیز را بداند: نام سرویس مقصد و اینکه آیا ترافیک باید امن باشد یا خیر. مفاهیم انتزاعی که Eureka برای این منظور ارائه میدهد، IPهای مجازی (VIP) برای ارتباط ناامن و VIPهای امن (SVIP) برای ارتباط امن هستند. کلاینتهای IPC با هدف قرار دادن آن VIP یا SVIP نمونهسازی میشوند و کد کلاینت Eureka با دریافت آنها از سرور Eureka، ترجمه آن VIP را به مجموعهای از جفتهای IP و پورت مدیریت میکند. کلاینت همچنین میتواند به صورت اختیاری ویژگیهای IPC مانند تلاش مجدد یا قطع مدار را فعال کند، یا به مجموعهای از پیشفرضهای معقول پایبند بماند. در این معماری، ارتباط سرویس به سرویس دیگر از طریق نقطه شکست واحد متعادلکننده بار انجام نمیشود. نکته منفی این است که Eureka یک نقطه شکست واحد جدید به عنوان source of truth برای میزبانهایی است که برای VIPها ثبت شدهاند. با این حال، اگر Eureka از کار بیفتد، سرویسها میتوانند به ارتباط با یکدیگر ادامه دهند، اگرچه اطلاعات میزبان آنها با گذشت زمان و با بالا و پایین آمدن نمونههای VIP، قدیمی میشود. توانایی اجرا در یک حالت degraged اما در دسترس در طول قطعی برق، هنوز هم پیشرفت قابل توجهی نسبت به توقف کامل جریان ترافیک است.
چرا مش؟ معماری فوق در طول دهه گذشته به خوبی کار کرده است، اگرچه تغییر نیازهای تجاری و تکامل استانداردهای صنعت، پیچیدگیهای بیشتری را به اکوسیستم IPC نتفلیکس از چندین جهت اضافه کرده است.
اول اینکه، نتفلیکس تعداد کلاینتهای مختلف IPC را افزایش داده است. ترافیک IPC داخلی نتفلیکس اکنون ترکیبی از REST ساده، GraphQL و gRPC است.
دوم، نتفلیکس از یک محیط فقط جاوا به یک محیط Polyglot منتقل شده است: اکنون از node.js، پایتون و انواع OSS و نرمافزارهای آماده نیز پشتیبانی میکند.
سوم، نتفلیکس به افزودن قابلیتهای بیشتر به کلاینتهای IPC خود ادامه داده است: ویژگیهایی مانند محدود کردن همزمانی تطبیقی، شکستن مدار، پوشش ریسک و تزریق خطا به ابزارهای استانداردی تبدیل شدهاند که مهندسان برای قابل اعتمادتر کردن سیستم به آنها متوسل میشوند.
در مقایسه با یک دهه پیش، اکنون از ویژگیهای بیشتر، به زبانهای بیشتر و در کلاینتهای بیشتر پشتیبانی میشود. حفظ برابری ویژگیها بین همه این پیادهسازیها و اطمینان از اینکه همه آنها به یک شکل رفتار میکنند، چالش برانگیز است: آنچه نتفلیکس میخواهد یک پیادهسازی واحد و آزمایش شده از همه این قابلیتها است، تا بتواند تغییرات را ایجاد کرده و اشکالات را در یک مکان برطرف کند. اینجاست که سرویس مش وارد عمل میشود: میتوان ویژگیهای IPC را در یک پیادهسازی واحد متمرکز کرد و کلاینتهای هر زبان را تا حد امکان ساده نگه داشت: آنها فقط باید بدانند که چگونه با پروکسی محلی صحبت کنند. Envoy به عنوان پروکسی بسیار مناسب است. به نتفلیکس امکان میدهد تا به صورت پویا تعادل بار سمت کلاینت را طوری تنظیم کند که انگار یک متعادلکننده بار مرکزی است، اما همچنان از متعادلکننده بار به عنوان یک نقطه شکست واحد در مسیر درخواست سرویس به سرویس جلوگیری میکند.
سوال بعدی این بود: چگونه باید این انتقال را انجام دهیم؟ نتفلیکس در مورد تعدادی محدودیت برای مهاجرت تصمیم گرفت.
اول: نتفلیکس میخواست رابط کاربری موجود را حفظ کند.
دوم: نتفلیکس میخواست مهاجرت را خودکار کند و آن را تا حد امکان یکپارچه کند.
این دو محدودیت به این معنی بود که نتفلیکس باید از انتزاعهای Discovery در Envoy پشتیبانی میکرد، تا کلاینتهای IPC بتوانند به استفاده از آن در داخل سیستم ادامه دهند. خوشبختانه، Envoy برای این کار، انتزاعهای آمادهای داشت. VIPها میتوانستند به عنوان Envoy Clusters نمایش داده شوند و پروکسیها میتوانستند آنها را با استفاده از CDS از صفحه کنترل نتفلیکس دریافت کنند. میزبانهای موجود در آن خوشهها به عنوان Envoy Endpoints نمایش داده میشوند و میتوانند با استفاده از Endpoint Discovery Service دریافت شوند.
خیلی زود به مانعی برای مهاجرت یکپارچه برخورد شد: Envoy الزام میکند که کلاسترها به عنوان بخشی از پیکربندی پروکسی مشخص شوند. اگر سرویس A نیاز به ارتباط با کلاسترهای B و C داشته باشد، باید کلاسترهای B و C را به عنوان بخشی از پیکربندی پروکسی A تعریف کنید. این میتواند در مقیاس بزرگ چالش برانگیز باشد: هر سرویس مشخصی ممکن است با دهها کلاستر ارتباط برقرار کند و آن مجموعه کلاسترها برای هر برنامه متفاوت است. علاوه بر این، Netflix همیشه در حال تغییر است: نتفلیکس دائماً ابتکارات جدیدی اضافه میکند و معماری خود را تغییر میدهد. این یعنی کلاسترهایی که یک سرویس با آنها ارتباط برقرار میکند با گذشت زمان تغییر خواهند کرد.
با توجه به مقادیر اولیه Envoy که در دسترس بود، رویکردهای مختلفی برای پر کردن پیکربندی کلاستر ارزیابی شد:
از صاحبان سرویس خواسته شود کلاسترهایی را که سرویسشان باید با آنها صحبت کند، تعریف کنند. این گزینه ساده به نظر میرسد، اما در عمل، صاحبان سرویس همیشه نمیدانند یا نمیخواهند بدانند که با چه سرویسهایی صحبت میکنند. سرویسها اغلب کتابخانههای ارائه شده توسط تیمهای دیگر را که با چندین سرویس دیگر در پشت صحنه صحبت میکنند، وارد میکنند یا با سایر سرویسهای عملیاتی مانند تلهمتری و ثبت وقایع ارتباط برقرار میکنند. این یعنی صاحبان سرویس باید بدانند که این سرویسها و کتابخانههای کمکی چگونه در پشت صحنه پیادهسازی میشوند و هنگام تغییر، پیکربندی را تنظیم کنند.
ایجاد خودکار پیکربندی Envoy بر اساس نمودار فراخوانی یک سرویس. این روش برای سرویسهایی که از پیش موجود هستند ساده است، اما هنگام ایجاد یک سرویس جدید یا اضافه کردن یک خوشه بالادستی جدید برای برقراری ارتباط، چالش برانگیز است.
همه خوشهها را به هر برنامه ارسال کنید: این گزینه به دلیل سادگی جذاب بود، اما با محاسبات ساده به سرعت به نتفلیکس نشان داد که ارسال میلیونها Endpoint به هر پروکسی امکانپذیر نیست.
هر یک از این گزینهها به اندازه کافی معایب قابل توجهی داشتند که نتفلیکس گزینه دیگری را بررسی کرد:
چه میشد اگر میتوانستیم اطلاعات کلاستر را در زمان اجرا، به صورت درخواستی دریافت کنیم، به جای اینکه از قبل تعریف کنیم؟
در آن زمان، تلاش برای ایجاد شبکه سرویس هنوز در حال راهاندازی بود و تنها چند مهندس روی آن کار میکردند. نتفلیکس با Kinvolk مذاکره کرد تا ببیند آیا میتوانند با نتفلیکس و جامعه Envoy در پیادهسازی این ویژگی همکاری کنند. نتیجه این همکاری، کشف خوشه بر اساس درخواست (ODCDS) بود. با این ویژگی، پروکسیها اکنون میتوانند اطلاعات خوشه را در اولین تلاش برای اتصال به آن جستجو کنند، به جای اینکه همه خوشهها را در کانفیگ از پیش تعریف کنند.
با وجود تغییرات در صفحه کنترل و صفحه داده، flow به شرح زیر است:
درخواست کلاینت به Envoy میرسد.
خوشه هدف را بر اساس هدر Host یا authority استخراج کنید (هدر استفاده شده در اینجا قابل تنظیم است، اما این رویکرد نتفلیکس است).
اگر آن خوشه از قبل شناخته شده است، به مرحله ۷ بروید.
خوشه وجود ندارد، بنابراین درخواست در حال انجام را متوقف میکنیم.
یک درخواست به اندپوینت سرویس کشف خوشه (CDS) در صفحه کنترل ارسال کنید.
صفحه کنترل یک پاسخ CDS سفارشی بر اساس پیکربندی سرویس و اطلاعات ثبت Eureka تولید میکند.
Envoy خوشه (CDS) را دریافت میکند که باعث میشود اندپوینت از طریق سرویس کشف (EDS) استخراج شوند.
اندپوینت ها برای خوشه بر اساس اطلاعات وضعیت Eureka برای آن VIP یا SVIP بازگردانده میشوند.
درخواست کلاینت متوقف میشود.
Envoy درخواست را به صورت عادی مدیریت میکند: با استفاده از یک الگوریتم متعادلسازی بار، یک اندپوینت را انتخاب میکند و درخواست را صادر میکند.
این جریان در عرض چند میلیثانیه تکمیل میشود، اما فقط در اولین درخواست به کلاستر. پس از آن، Envoy طوری رفتار میکند که انگار کلاستر در کانفیگ تعریف شده است. نکته مهم این است که این سیستم به نتفلیکس اجازه میدهد تا بدون نیاز به پیکربندی، سرویسها را به طور یکپارچه به سرویس مش منتقل کند و یکی از محدودیتهای اصلی خود را رفع کند. نتفلیکس همچنان از Eureka به عنوان source of truth برای VIPها و وضعیت نمونهها استفاده میکند که به نتفلیکس امکان میدهد در حین مهاجرت، از یک محیط ناهمگن شامل برخی از برنامهها روی مش و برخی دیگر پشتیبانی نکند. یک مزیت دیگر نیز وجود دارد: میتوان با fetch کردن دادهها برای کلاسترهایی که واقعاً با آنها در ارتباط هستیم، میزان استفاده از حافظه Envoy را پایین نگه داشت.
البته یک نکته منفی در fetch کردن این دادهها بر اساس تقاضا وجود دارد. آن هم این است که این کار باعث افزایش تأخیر در اولین درخواست به یک خوشه میشود. نتفلیکس با مواردی مواجه شده است که سرویسها در اولین ریکوئست به دسترسی با تأخیر بسیار کم نیاز دارند و اضافه کردن چند میلیثانیه اضافی، سربار زیادی را اضافه میکند. برای این موارد استفاده، سرویسها باید خوشههایی را که با آنها ارتباط برقرار میکنند از قبل تعریف کنند. در مجموع، نتفلیکس معتقد است که کاهش پیچیدگی در سیستم، این نکته منفی را برای مجموعه کوچکی از سرویسها توجیه میکند.
مدیریت حجم ترافیک بالا در نتفلیکس
ELB (Elastic Load Balancer) توزیعکننده ترافیک: ELB دارای دو طرح متعادلکننده بار است. اولین ردیف برای تعادل بار پایه مبتنی بر DNS. تعادل بار در ابتدا در مناطق، سپس نمونهها. ردیف دوم سرویس ELB آرایهای از نمونههای متعادلکننده بار است که توازن بار چرخشی را نسبت به نمونههای خود که پشت آن در همان منطقه هستند انجام میدهد.
در نتفلیکس، ترافیک عظیمی جریان دارد. اینجاست که نقش ELB یا همان متعادلکننده بار الاستیک مشخص میشود. نتفلیکس از سرویس load balancer الاستیک آمازون (ELB) برای هدایت ترافیک به سرویسهای front-end استفاده میکند. ELB به طور خودکار ترافیک ورودی برنامه را در چندین هدف، در یک یا چند منطقه در دسترس توزیع میکند. بر سلامت نقاط هدف ثبت شده خود نظارت میکند و ترافیک را فقط به نقاط هدف سالم هدایت میکند و در واقع در Netflix مسئول مسیریابی ترافیک است.

ELB یک تعادل بار دو لایه را انجام میدهد که در آن بار ابتدا بر روی مناطق در دسترس و سپس نمونهها (سرورها) متعادل میشود. ELBها به گونهای تنظیم شدهاند که بار ابتدا در zoneها و سپس instanceها متعادل شود:
Tier اول: تصور کنید نتفلیکس به بخشهای متعددی تقسیم شده است. ELB ابتدا ترافیک ورودی را در میان این بخشها یا همان Zones به صورت چرخشی و منصفانه توزیع میکند. به این ترتیب، هیچ بخشی بیش از حد شلوغ نمیشود و کاربران در هر گوشهای از این قلمرو به سرعت به محتوا دسترسی پیدا میکنند. اولین لایه شامل load balancer با الگوریتم Round Robin پایه مبتنی بر DNS است. هنگامی که درخواست در اولین بار متعادلکننده فرود میآید، در یکی از مناطق (با استفاده از الگوریتم دور چرخشی) که ELB شما برای استفاده از آن پیکربندی شده است (z1 to z3)، متعادل میشود.
Tier دوم: سطح یا لایه دوم آرایهای از نمونههای متعادلکننده بار است و باز هم الگوریتم Round Robin را برای توزیع درخواست در بین نمونههایی که پشت آن در همان منطقه یکسان هستند، انجام میدهد. هر بخش (Zone) خود به تعدادی سرور تقسیم میشود که مستقیماً به درخواستهای کاربران پاسخ میدهند. ELB در این مرحله نیز وارد عمل میشود و درخواستهای ورودی را به صورت چرخشی میان این سرورها توزیع میکند. به این ترتیب، بار بیش از اندازه روی هیچ سروری توزیع نمیشود و کاربران تجربهای روان و بدون وقفه دارند.
سرویس اختصاصی ZUUL
فیلترهای ZUUL (API gateway) برای مدیریت پروتکلهای شبکه، سرورهای وب، مدیریت اتصال و کار پروکسی استفاده میشوند. این سرویس شامل سه فیلتر جداگانه، مانند فیلترهای ورودی برای احراز هویت، مسیریابی یا تنظیم درخواستها؛ فیلترهای اندپوینت برای درخواستهای مربوط به سرویسهای backend؛ و فیلتر خروجی برای متریک یا اضافه کردن/حذف هدرهای سفارشی است. کاربرد اصلی آن هدایت ترافیک به خوشههای مختلف است. زول یک سرویس Gateway است که مسیریابی پویا، مانیتورینگ، انعطافپذیری و امنیت را برای ترافیک سرویسهای نتفلیکس فراهم میکند. این سرویس امکان مسیریابی آسان بر اساس پارامترهای کوئری، URL و مسیر را میدهد.
برای درک بهتر نحوه کار زول، اجزای مختلف آن را بررسی میکنیم:

سرور Netty مسئولیت رسیدگی به پروتکل شبکه، وب سرور، مدیریت اتصال و کار پروکسی را بر عهده میگیرد. هنگامی که درخواست به سرور Netty برخورد میکند، درخواست را به فیلتر ورودی پروکسی میکند.
فیلتر ورودی مسئول احراز هویت و مسیریابی درخواست است و سپس درخواست را به فیلتر اندپوینت ارسال میکند.
فیلتر اندپوینت برای بازگرداندن یک پاسخ ایستا یا ارسال درخواست به سرویس Backend استفاده میشود.
هنگامی که پاسخ را از سرویس Backend دریافت کرد، درخواست را به فیلتر خروجی ارسال میکند.
یک فیلتر خروجی برای فشردهسازی محتوا، محاسبه معیارها یا افزودن/حذف هدرها استفاده میشود.
پس از آن، پاسخ به سرور Netty ارسال میشود و سپس توسط کلاینت دریافت میشود.
ویژگیهای ZUUL:
پشتیبانی از http2
TLS متقابل
retry logic
داشتن همزمانی یا concurrency
مزایای ZUUL:
مسیریابی پویا: ابتدا درخواست را تجزیه و تحلیل میکند و میتواند مسیر را بر اساس کلمات کلیدی، آدرس اینترنتی یا مسیر مشخص شده انتخاب کند. به این ترتیب، کاربران به سرعت به مقصد خود (فیلم مورد نظر) میرسند.
نظارت و پایداری: زول همواره بر عملکرد سیستم نظارت میکند. او سلامت سرورها را بررسی میکند و در صورت لزوم، ترافیک را به مسیرهای جایگزین هدایت میکند تا هیچگاه وقفهای در تماشای فیلمها رخ ندهد. به این ترتیب، پایداری و دسترسی مداوم برای کاربران تضمین میشود.
امنیت و حفاظت: زول امنیت محتوا را بر عهده دارد. او با فیلتر کردن درخواستهای غیرمجاز و مشکوک، از نفوذها و حملات سایبری جلوگیری میکند. به این ترتیب، اطلاعات کاربران و محتوای ارزشمند نتفلیکس در امنیت کامل قرار میگیرند.
انعطاف و کارایی: زول قابلیتهای ویژهای نیز در اختیار توسعهدهندگان قرار میدهد. آنها میتوانند با استفاده از زول، ترافیک ورودی را تقسیمبندی کنند و عملکرد سرورهای جدید را آزمایش نمایند. اگر تیمها نیاز به آزمایش تغییراتی داشته باشند که به چندین درخواست متوالی در ساخت جدیدشان نیاز دارند، تستهای canary را اجرا میکنند که بدون ایجاد اختلال در سیستم همان کاربران را برای مدت کوتاهی به ساخت جدیدشان هدایت میکند. میتوان سرویسهای جدید را تست کرد. وقتی سرویسی را ارتقا میدهید و میخواهید نحوه رفتار آن با درخواستهای API بلادرنگ بررسی کنید، در آن صورت، میتوانید سرویس خاص را روی یک سرور مستقر کنید و میتوانید بخشی از ترافیک را به سرویس جدید جهت بررسی به صورت real time هدایت کنید.
سرویس Hystrix
سپر دفاعی سیستمهای توزیعشده: Hystrix یک circuit breaker است. در یک سیستم پیچیده توزیع شده، ممکن است یک سرور به پاسخ سرور دیگری متکی باشد. وابستگیهای بین سرورها میتواند منجر به تأخیر شود و اگر یکی از سرورها در نقطهای از کار بیفتد، ممکن است کل سیستم از کار بیفتد. کتابخانه Hystrix با افزودن منطقlatency tolerance و fault tolerance، تعاملات بین سرویسهای توزیع شده را کنترل میکند. Hystrix این کار را با ایزوله کردن نقاط دسترسی بین سرویسها، سیستمهای remote و کتابخانههای third party انجام میدهد. مثلاً اگر میکروسرویسی که لیست فیلمهای مناسب را به کاربر ارائه میکند، fail شود، ترافیک به میکروسرویسی که ۱۰ فیلم برتر را برمیگرداند تغییر مسیر میدهد و در نتیجه failure کنترل میشود.
مزایای Hystrix:
Real-time monitoring
جلوگیری از cascading failure: دیگر لازم نیست اثر دومینویی بر سیستم حاکم باشد. هیستریکس به سرعت خرابیها را شناسایی و کنترل میکند و از گسترش آنها جلوگیری میکند.
کنترل تأخیرها: تأخیر و کندی از بین خواهد رفت. هیستریکس تأخیر ناشی از وابستگیهای خارجی را مهار میکند و تعاملات روان و responsive را تضمین میکند.
بازیابی سریع: در صورت خرابی، هیستریکس یک بازیابی سریع را سازماندهی میکند و به سیستم ما اجازه میدهد با اختلال کم به حالت عادی بازگردد.
ایجاد قابلیت downgrade سرویس: هنگامی که با چالشهای غیرقابل عبور مواجه میشویم، هیستریکس با فعال کردن مکانیزمهای پشتیبانگیری به شیوهای مناسب، حتی در مواجهه با مشکلات، تجربهی پیوسته ای را برای کاربر تضمین میکند.
هوشیاری بالا: هیستریکس به عنوان نگهبان هوشیار عمل میکند و نظارت تقریباً بیدرنگ، هشدارهای تشریحی و کنترل عملیاتی عمیق را ارائه میدهد، بنابراین میتوان از تهدیدهای بالقوه پیشگیری کرد.
کش کردن درخواستها به صورت concurrency aware: هیستریکس از ذخیرهسازی هوشمندانه درخواستها استفاده میکند و تعاملات گذشته را به خاطر میسپارد تا عملکرد را بهینه کند.
دستهبندی خودکار برای افزایش کارایی: هیستریکس درخواستهای مشابه را با هم گروه میکند و از قدرت batch processing برای سادهسازی عملیات و افزایش کارایی استفاده میکند.
پلتفرم Titus
Titus یک پلتفرم مدیریت container است که اجرای container مقیاسپذیر و قابل اعتماد و ادغام cloud-native با Amazon AWS را فراهم میکند. Titus توسط نتفلیکس ساخته شده است و برای تقویت استریم، recommendation و سیستمهای محتوا استفاده میشود. Titus هزاران نمونه AWS EC2 را مدیریت میکند و روزانه صدها هزار container را برای workloadهای دستهای و سرویس راهاندازی میکند. Titus میتواند تصاویر بستهبندی شده (images packaged) را به عنوان containerهای Docker اجرا کند و در عین حال امنیت و قابلیت اطمینان (reliability) بیشتری را در مورد اجرای container فراهم کند. میتوان Titus را به عنوان نسخه نتفلیکس Kubernetes در نظر گرفت.

استفاده از Chaos Monkey
Chaos Monkey اسکریپتی است که به طور مداوم در تمام محیطهای Netflix اجرا میشود و با خاموش کردن تصادفی نمونههای سرور باعث بینظمی و هرج و مرج (chaos) میشود. از این رو، در حین نوشتن کد، توسعهدهندگان نتفلیکس به طور مداوم در محیطی از سرویسهای غیرقابل اعتماد و قطعیهای غیرمنتظره فعالیت میکنند. در واقع Chaos Monkey نمونهها را به طور تصادفی متوقف (terminate) میکند تا اطمینان حاصل کند که توسعهدهندگان، سرویسها را به گونهای پیادهسازی میکنند که در برابر خرابیها انعطافپذیر باشد.
نتفلیکس یکی از اولین شرکتهایی بود که معماری میکروسرویسها را پذیرفت و از معماری monolithic به میکروسرویسها در بستر cloud مهاجرت کرد. در حقیقت، این شرکت مفاهیم میکروسرویسها را، قبل از این که حتی به طور آکادمیک معرفی شده باشند، اجرا کرد. بر این اساس میتوانیم نتفلیکس را به عنوان یک پیشگام در زمینه مهاجرت به میکروسرویسها مطرح کنیم.
در حدود ۲۰ سال قبل، نتفلیکس مانند کلوپی بود که با دادن حق اشتراک، فیلمها را در قالب DVD عرضه میکرد؛ اما در حال حاضر یکی از بزرگترین سیستمهای پخش زنده در بستر اینترنت است. همان طور که مشخص است، برای چنین نیازمندی متفاوت و وسیعی که در طول زمان برای این شرکت ایجاد شد، معماری گذشته دیگر پاسخگو نبود و لازم بود تصمیمات متفاوتی در خصوص ساختار معماری آن گرفته شود. در ابتدا، معماری نتفلیکس یکپارچه بود و شامل یک برنامه جاوا بود که به طور مستقیم با یک پایگاه داده اوراکل متصل شده بود. این ساختار، که در دهه ۹۰ و اوایل ۲۰۰۰ رایج بود، به زودی محدودیتهای خود را نشان داد. کد یکپارچه تشخیص و رفع مشکلات را به یک فرایند طولانی تبدیل کرد و طراحی single point of failure پایگاه داده منجر به اختلالات قابل توجهی در سرویس شد. عدم انعطافپذیری در اجرای تغییرات، به دلیل ارتباط تنگاتنگ بین برنامه و پایگاه داده، مشکلات را بیشتر کرد.
مهاجرت نتفلیکس به میکروسرویسها بیشتر از دو سال به طول انجامید. چالشهای زیادی در این بازه رخ داد، از جمله این که نتفلیکس میبایست هم زیرساختهای ابری خود را نگهداری میکرد تا از صحت عملکرد آن مطمئن شود، هم ساختار سنتی خود را حفظ میکرد، تا کاربران به مشکل نخورند؛ این مسئله هزینه زیادی را به این شرکت وارد کرد. به علاوه انتقال حجم زیادی از داده به سرورهای جدید، مشکلاتی از قبیل لود زیاد بار و کارآیی پایین را در بر داشت.
برای رفع این مشکلات، نتفلیکس به سمت معماری میکروسرویسها حرکت کرد و برنامه یکپارچه خود را به مجموعهای از سرویسهای کوچک و مستقل تقسیم کرد. هر میکروسرویس، مانند یک عضو در بدن انسان، عملکرد خاصی را در اکوسیستم گستردهتر سرویس نتفلیکس انجام میدهد. میکروسرویسها در نتفلیکس به عنوان سرویسهای کوچک و مستقل که از طریق مکانیزمهای سبک مانند API منابع HTTP ارتباط برقرار میکنند، تعریف شدهاند. این پارادایم طراحی باعث ترویج جداسازی دغدغهها، ماژولاریتی، مقیاسپذیری و تقسیمبندی بار کاری میشود. نتفلیکس حدود ۷۰۰ میکروسرویس دارد.
اجزای کلیدی معماری میکروسرویس نتفلیکس شامل:
لایه پروکسی و API gateway: مدیریت درخواستهای ورودی و مسیریابی آنها به سرویسهای مناسب.
لایههای قدیمی و مدرن: تسهیل انتقال هموار از سیستمهای قدیمی به سرویسهای جدید.
سرویسهای میانی و پلتفرم: ارائه قابلیتهای اساسی برای پشتیبانی از میکروسرویسهای مختلف. به عنوان مثال، سرویس ذخیرهسازی ویدیو از سرویسی که وظیفه رمزگذاری ویدیوها را بر عهده دارد یا سرویسی که مسئول تبدیل فرمت آنها است، جدا میشود.
قابلیت اطمینان (Reliability) در میکروسرویسها: چطور میتوان اطمینان داشت که چنین سیستمی همیشه قابل اعتماد و در دسترس است؟
نتفلیکس برای افزایش قابلیت اطمینان (reliability) میکروسرویسها:
از ابزارهایی مانند Hystrix، Titus و Chaos Monkey استفاده میکند.
میکروسرویسهای حیاتی و مهم را جدا میکند (Critical Microservices).
سرویسها به صورت stateless طراحی میشود.
سبک معماری نتفلیکس به صورت مجموعهای از سرویسها ساخته شده است. تمام APIهای مورد نیاز برای برنامهها و وباپها را تامین میکند. زمانی که درخواستی در endpoint دریافت میشود، این end point دیگر میکروسرویسها را برای دادههای مورد نیاز فرا میخواند و این میکروسرویسها نیز ممکن است دادهها را از میکروسرویسهای دیگری درخواست کنند. پس از آن، پاسخ کامل برای درخواست API به end point فرستاده میشود.
اکوسیستم میکروسرویسهای نتفلیکس بر اساس کارایی به دو دسته تقسیم شده است.
سرویسهای حیاتی: آنهایی هستند که کاربرها به صورت مکرر با آنها ارتباط دارند. این سرویسها از عمد به شکل مستقل از بقیه نگه داشته میشوند. این استقلال، تضمین میکند که سرویسهای پایه متاثر از failureها واقع نمیشود و کاربران میتوانند به استفاده از آنها ادامه دهند. میکروسرویسهای حیاتی شامل قابلیتهای اساسی مانند جستجوی ویدئو، پیمایش فیلم ها و پخش ویدئو هستند. چنین روشی منجر به دسترسیپذیری (availability) بالا میشود و در بدترین سناریو کاربران میتوانند کارهای ابتدایی را انجام دهند چرا که بخشهای حیاتی در دسترس هستند.
سرویسهای stateless: این سرویسها، مسئول serve کردن درخواستهای API به کاربران هستند و طوری طراحی شدهاند که با instanceهای دیگر، حتی در صورت بروز failure، بدون مشکل کار کنند. این سرویسها برای بالا نگه داشتن availability نیاز هستند.
نتفلیکس تعدادی از سرویسها را به عنوان سرویسهای حیاتی جدا میکند و وابستگی آنها به سایر سرویسها را به حداقل میرساند. طراحی سرویسها به گونهای است که اگر یکی از endpointها دچار خطا شد یا درخواست به موقع سرویسدهی نشد، بتوان به سرور دیگری سوئیچ کرد و کار را انجام داد. در واقع به جای تکیه بر یک سرور خاص و حفظ وضعیت (state) در آن سرور، میتوان درخواست را به سرور (service instance) دیگری هدایت کرد. اگر سروری از کار بیفتد با سرور دیگری جایگزین خواهد شد. یعنی یک سرور خاص نیست که برای ما اهمیت دارد، بلکه کارکردی که دارد باعث میشود به آن اهمیت دهیم. این رویکرد امکان میدهد که در صورت بروز خطا در یک سرور، به راحتی و بدون اختلال در تجربه کاربری، درخواستها را به سرور دیگری منتقل کنند.
همانطور که گفته شد، نتفلیکس برای قابل اعتماد کردن معماری میکروسرویس خود، چندین رویکرد و ابزار پیشرفته را به کار گرفته است. این اقدامات شامل موارد زیر است:
استفاده از Hystrix برای مدیریت شکستها: همانطور که دیدیم، Hystrix یک کتابخانه circuit breaker ایجاد شده توسط نتفلیکس است که به میکروسرویسها اجازه میدهد تا در مواجهه با خطاها، به صورت مقاوم عمل کنند. این ابزار به سرویسها کمک میکند تا در زمان خرابیها، ترافیک را به روشهای پیشفرض یا فالبک هدایت کنند.
مقیاسپذیری ابری و استفاده از AWS: با استفاده از زیرساخت ابری آمازون وب سرویسها (AWS)، نتفلیکس از مزایای مقیاسپذیری، انعطافپذیری و قابلیت اطمینان بالا بهرهمند میشود. این زیرساخت ابری به نتفلیکس امکان میدهد تا منابع خود را بر اساس نیاز فوری افزایش یا کاهش دهد.
مانیتورینگ و لاگگیری پیشرفته: نتفلیکس از ابزارهای مانیتورینگ و لاگگیری پیشرفته استفاده میکند تا بتواند عملکرد سیستم و میکروسرویسهای خود را به طور مداوم زیر نظر داشته باشد. این امکان به تیمهای مهندسی اجازه میدهد تا به سرعت مشکلات را شناسایی و رفع کنند.
Chaos Engineering: نتفلیکس پیشرو در استفاده از Chaos Engineering است، یک رویکرد آزمایشی که به طور عمدی شرایط خرابی را در محیط تولید ایجاد میکند تا اطمینان حاصل شود که سیستم قادر به تحمل خرابیها و بازیابی از آنها است.
با ترکیب این رویکردها و ابزارها، نتفلیکس توانسته است معماری میکروسرویس خود را به یکی از قابل اعتمادترین و مقیاسپذیرترین سیستمها در صنعت پخش زنده تبدیل کند.
کش کردن با EV Cache
در اکثر برنامهها، بخشی از دادهها هستند که مکررا استفاده میشود. برای پاسخ سریعتر، این دادهها را میتوان در بسیاری از endpointها کش کرد و میتوان آنها را به جای سرور اصلی از حافظه کش دریافت کرد. این باعث کاهش بار سرور اصلی میشود، اما مشکل این است که اگر گره پایین بیاید، RAM هم پایین میآید و این میتواند به عملکرد برنامه ضربه بزند. برای حل این مشکل Netflix لایه کش سفارشی خود را به نام کش EV ساخته است. EVCache یک راهحل ذخیرهسازی cache توزیع شده مبتنی بر Memcached و Spymemcached است که به خوبی با Netflix OSS و زیرساخت AWS EC2 یکپارچه شده است. EVCache در واقع یک پوشش (wrapper) در اطراف Memcached است. نتفلیکس خوشههای زیادی را در تعدادی از نمونههای AWS EC2 مستقر کرده است. به طور سنتی ذخیرهسازی cache روی RAM انجام میشود، اما ذخیره کردن حجم زیادی از دادهها در RAM هزینه زیادی دارد. از این رو نتفلیکس تصمیم گرفت تا برخی از دادههای cache را به SSD منتقل کند. EVcache برای ذخیرهسازی توزیعشده استفاده میشود. وقتی گره از کار میافتد، تمام حافظه پنهان همراه با آن از دست میرود و تا زمانی که تمام دادهها بازیابی نشوند، عملکرد کاهش مییابد. اما نتفلیکس با EVcache با چندین کپی از حافظه در گرهها، تقسیمبندی میشود. حافظه پنهان از نزدیکترین حافظه پنهان یا گره خوانده میشود. اگر گره در دسترس نباشد، از سایر گرههای موجود دریافت میشود.
انواع EV Cache:
سرویس EVCache ساده: این نوع EVCache شامل یک خوشه Memcached با چندین گره است که در یک منطقه (Zone) در دسترس هستند. این نوع EVCache برای برنامههایی که به پایداری بالا نیاز ندارند مناسب هستند.
سرویس استقرار Multi-Zone: این نوع EVCache شامل چندین خوشه Memcached در چندین منطقه (Zone) است. دادهها در تمام خوشهها به طور همزمان ذخیره میشوند و در صورت خرابی یک منطقه، دادهها در مناطق دیگر همچنان در دسترس خواهند بود. این نوع EVCache برای برنامههایی که به پایداری بالا نیاز دارند مناسب است. طبیعتاً هزینه Multi-Zone EVCache Deployment بیشتر از EVCache ساده است.
مراحل استفاده از EVCache:
برنامه EVCache یک درخواست برای خواندن یا نوشتن داده ارسال میکند.
سرویس EVCache درخواست را به خوشه Memcached مناسب هدایت میکند.
اگر درخواست برای خواندن باشد، گره Memcached دادهها را به EVCache برمیگرداند.
سرویس EVCache دادهها را به برنامه برمیگرداند.
اگر درخواست برای نوشتن باشد، EVCache، دادهها را به تمام خوشههای Memcached در تمام مناطق ارسال میکند.
گرههای Memcached دادهها را ذخیره میکنند.
هر cluster دارای تعداد زیادی گرهی Memcached است و آنها نیز cache clientهایی دارند. دادهها در سراسر cluster در یک منطقه (zone) به اشتراک گذاشته میشود و چندین نسخه کپی از cache در sharded node ذخیره میشود. در هر write برای client، تمام گرهها در همه clusterها بهروزرسانی میشوند، اما read از حافظه cache، فقط به نزدیکترین cluster و گرههای آن (نه همه clusterها و گرهها) ارسال میشود. در صورتی که یک گره در دسترس نباشد، از گره دیگری که در دسترس است میخواند. این رویکرد کارایی (performance)، دسترسپذیری (availability) و قابلیت اطمینان (reliability) را افزایش میدهد. منظور از performance در اینجا سرعت است. با ذخیرهسازی دادهها در حافظه کش، زمان پاسخگویی به درخواستها به طور قابل توجهی کاهش مییابد. و منظور از reliablity هم مقاومت سیستم در برابر خرابیها و ناپایداریهاست.
پایگاهدادهها
نتفلیکس، برای ذخیرهسازی دادههای متنوع خود، از دو پایگاه داده مجزا و قدرتمند بهره میگیرد: MySQL و Cassandra. هر یک از این پایگاهها، ویژگیهای منحصر به فردی دارند و برای مقاصد خاصی به کار گرفته میشوند.
سرویس MySQL: صورتحساب و اطلاعات کاربر از پایگاه داده mysql استفاده میکند. دلیل استفاده از پایگاه داده mysql ایمن نگه داشتن دادهها است.
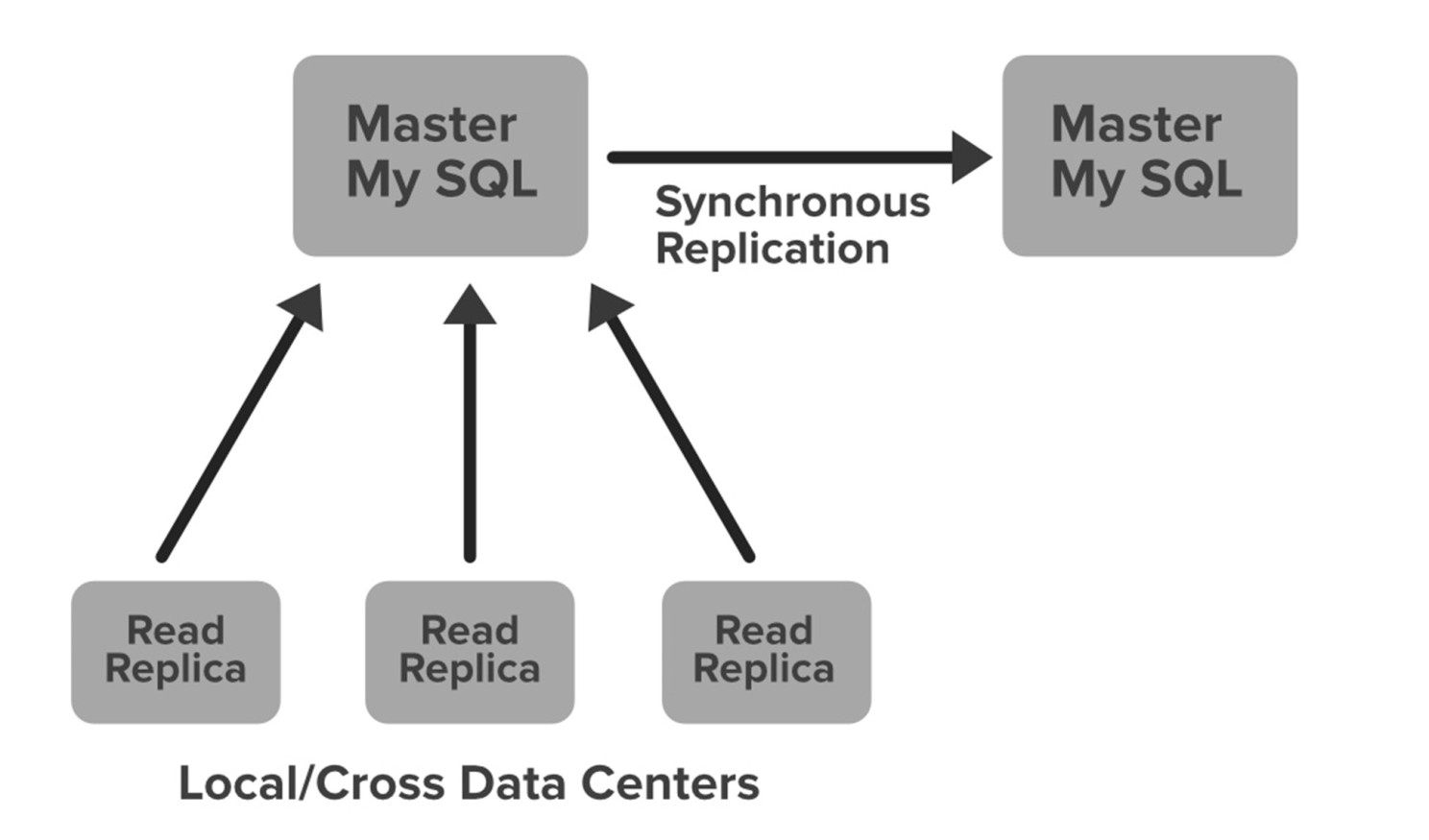
برای حفاظت از اطلاعات حیاتی مانند جزئیات صورتحسابها، پروفایل کاربران و تراکنشهای مالی، نتفلیکس به پایگاه دادهای با قابلیت انطباق ACID نیاز دارد. در این میان، MySQL با داشتن ساختاری مستحکم و امکان راهاندازی چندین سرور اصلی همزمان (Master-Master Setup)، گزینهای ایدهآل به شمار میرود. پایگاه داده MySQL نتفلیکس روی instanceهای Amazon EC2 با موتور InnoDB ذخیرهسازی مستقر شده است.
یکی از ویژگیهای بارز این کانفیگ، بهرهگیری از «پروتکل تکثیر همزمان» است. بدین معنی که هر گونه نوشتهای که روی سرور اصلی اولیه (master) انجام میشود، بهطور همزمان بر روی سرور اصلی دیگر نیز تکثیر میگردد. تأیید نهایی تنها زمانی صادر میشود که صحت نوشتن اطلاعات در هر دو سرور اصلی تأیید شده باشد. این امر، سطح بالایی از دسترسیپذیری دادهها را تضمین میکند.
نتفلیکس برای هر گره، یک Read Replica نیز راهاندازی کرده است. این کار، دسترسپذیری و مقیاسپذیری بالایی را به ارمغان میآورد. به این ترتیب، تمامی کوئری های خواندنی به سمت کپیهای خواندنی هدایت میشوند و تنها کوئری های نوشتنی به سمت سرورهای اصلی هدایت میشوند. در صورت بروز خطا در سرور اصلی اولیه MySQL، سرور اصلی ثانویه به سرعت نقش اصلی را بر عهده میگیرد و ورودی DNS متعلق به پایگاه داده به این سرور جدید تغییر مسیر داده میشود. بدین ترتیب، کوئری های نوشتنی نیز به سمت این سرور اصلی جدید هدایت خواهند شد.
سرویس Cassandra: Cassandra برای فایلهای مدیا و مشاهده رکورد تاریخ استفاده میشود. برخی از دادهها به صورت غیر فشرده ذخیره میشوند، در حالی که بقیه به صورت فشرده ذخیره میشوند.
سرویس Cassandra یک پایگاه داده NoSQL متنباز (open-source) است که توانایی مدیریت حجم عظیمی از دادهها را دارد و به خوبی از پسِ عملیات سنگین خواندن و نوشتن برمیآید. با افزایش روزافزون کاربران نتفلیکس، حجم دادههای مربوط به سابقه تماشای هر عضو نیز به طرز چشمگیری افزایش یافت. این حجم عظیم داده، مدیریت آنها را به چالشی جدی تبدیل کرده است. نتفلیکس از Cassandra برای مقیاس پذیری (scalability)، عدم وجود نقاط شکست واحد (single points of failure) و استقرارهای بین منطقهای (cross-regional deployment) استفاده میکند. نتفلیکس انواع دادهها را در نمونههای Cassandra DB خود ذخیره میکند. به عنوان مثال، تاریخچه مشاهده هر کاربر در Cassandra ذخیره میشود. در ابتدا تاریخچه مشاهده در یک سطر (row) ذخیره میشد، اما با افزایش کاربران نتفلیکس، حجم دادهها نیز افزایش یافت و منجر به هزینه عملیاتی بیشتر و کارایی کمتر اپلیکیشن شد.
نتفلیکس با در نظر گرفتن دو هدف اصلی، اقدام به مقیاسگذاری ذخیرهسازی دادههای سابقه تماشا نموده است:
کاهش اشغال فضای ذخیرهسازی (Storage Footprint کوچکتر).
ثبات performance خواندن/نوشتن با افزایش دادههای تماشای هر عضو (نسبت نوشتن به خواندن دادههای سابقه تماشا در Cassandra حدود ۹:۱ است).

ویژگیهای Cassandra در نتفلیکس:
مدل دادهای کاملاً Denormalized
بیش از ۵۰ خوشه Cassandra
بیش از ۵۰۰ گره
بیش از ۳۰ ترابایت بک آپ گیری روزانه
بزرگترین خوشه: ۷۲ گره
یک خوشه: بیش از ۲۵۰ هزار نوشتن در ثانیه
وقتی برای حل این مشکل، نتفلیکس اقدام به فشردهسازی ردیفهای قدیمی نمود، دادهها به دو بخش تقسیم شدند:
تاریخچه تماشای زنده (Live Viewing History - LiveVH): این بخش شامل تعداد محدودی از دادههای اخیر سابقه تماشا با آپدیت های مکرر است. این دادهها که به وفور برای وظایف ETL مورد استفاده قرار میگیرند، به صورت فشردهنشده ذخیره میشوند.
سابقه تماشای فشردهشده (Compressed Viewing History - CompressedVH): حجم عظیمی از سابقههای تماشای قدیمی در این بخش، دادهها در یک ستون واحد برای هر کلید ردیف (Row Key) و به صورت فشرده ذخیره میشوند تا فضای ذخیرهسازی اشغالشده به حداقل برسد.
پردازش دادهها در نتفلیکس
نتفلیکس از Kafka و Apache Chukwa برای جمعآوری و پردازش دادهها استفاده میکند. این دادهها شامل گزارش خطا، فعالیتهای رابط کاربری، رویدادهای عملکرد، فعالیتهای تماشای ویدئو و رویدادهای عیبیابی و تشخیص هستند. آنها روزانه چیزی حدود ۵۰۰ میلیارد رویداد داده، معادل ۱.۳ پتابایت و در ساعات اوج ۸ میلیون رویداد به ازای ۲۴ گیگابایت در ثانیه را پردازش میکنند.
این رویدادها شامل طیف گستردهای از اطلاعات هستند، از جمله:
گزارشهای خطا
فعالیتهای رابط کاربری
رویدادهای عملکرد
فعالیتهای تماشای ویدیو
رویدادهای (event) عیبیابی و تشخیص
به کارگیری Apache Chukwa
Apache Chukwa یک سیستم جمعآوری داده open-source برای نظارت بر سیستمهای توزیع شده بزرگ است. Apache Chukwa بر روی سیستم فایل توزیع شده Hadoop (همان HDFS) و چارچوب Mapreduce ساخته شده است و مقیاسپذیری و استحکام Hadoop را به ارث برده است. Apache Chukwa همچنین دارای مجموعهای منعطف و قدرتمند از ابزارها برای نمایش (displaying)، نظارت (monitoring) و تجزیه وتحلیل (analyzing) دادههای جمعآوری شده است. این ابزار، لاگها و رخدادها را از قسمتهای مختلف سیستم جمعآوری و آنالیز میکند. Apache Chukwa رویدادها را از بخشهای مختلف سیستم جمعآوری میکند و آنها را در فرمت Hadoop file sequence (S3) مینویسد و سپس تیم Big Data آن فایلهای S3 را در Hive در فرمت داده Parquet پردازش میکند. این فرآیند، پردازش دستهای نام دارد که عموماً به صورت ساعتی یا روزانه انجام میشود و کل مجموعه دادهها را مورد بررسی قرار میدهد.
نقش Apache Kafka
Apache Kafka یک پلتفرم استریم رویداد توزیع شده open-source است که توسط هزاران شرکت برای pipelineهای داده با کارایی بالا، تجزیهوتحلیل جریان دادهها، یکپارچهسازی دادهها و اپلیکیشنهای حیاتی استفاده میشود. در نتفلیکس Apache Kafka مسئول انتقال دادهها از kafka جلویی (fronting kafka) به موارد مختلفی از جمله S3، Elastic Search، و kafka ثانویه (Consumer kafka) است. مسیریابی این پیامها با استفاده از فریمورک Apache Samza انجام میشود. ترافیک ارسالی توسط Chukwa میتواند استریمهای کامل یا فیلتر شده باشد، بنابراین گاهی اوقات ممکن است لازم باشد فیلترهای بیشتری روی استریمهای Kafka اعمال شود. به همین دلیل router از یک Kafka به Kafka دیگر در نظر گرفته میشود.
حضور Apache Samza
Apache Samza یک فریمورک open-source محاسباتی غیرهمزمان برای پردازش استریم است. به عبارت دیگر Apache Samza یک موتور پردازش داده مقیاسپذیر است که پردازش و آنالیز دادهها را به صورت real-time ممکن میسازد. Apache Samza در ارتباط با Apache Kafka توسعه یافته است.

Elastic Search در نتفلیکس
Elasticsearch یک موتور جستجو و آنالیز توزیع شده است که بر روی Apache Lucene ساخته شده است. در واقع Elasticsearch یک موتور جستجوی full-text توزیع شده با قابلیت multitenant است. نتفلیکس از Elasticsearch برای مصورسازی دادهها، پشتیبانی مشتری و برای تشخیص خطا در سیستم استفاده میکند. با Elasticsearch به راحتی میتوان وضعیت سیستم را monitor کرد، لاگهای خطا و خرابیها را عیبیابی کرد. به عنوان مثال، اگر کاربر قادر به پخش ویدئو نباشد، مسئول خدمات مشتری این مشکل را با استفاده از elasticsearch حل میکند. تیم پخش ویدئو، کاربر را جستجو میکند تا بداند چرا ویدیو در دستگاه کاربر پخش نمیشود. آنها از تمام اطلاعات و رویدادهایی که برای آن کاربر خاص اتفاق میافتد آگاه میشوند و متوجه میشوند که چه چیزی باعث خطا در استریم ویدیو شده است. همچنین برای پیگیری استفاده از منابع و شناسایی مشکلات ثبت نام (signup) یا ورود (login) از elasticsearch استفاده میشود. از Elastic Search برای جستجوی لیست فیلمها یا سریالها بر اساس عنوان یا هر برچسب مرتبط با آن استفاده میشود. یکی دیگر از کاربردهای Elastic Search ردیابی رویدادهای کاربر در صورت بروز خطا است.
جریان کار جست و جوی محتوا:
کلاینت عنوان ویدیو را جستجو میکند.
سرویس کشف محتوا (CDS) از جستجوی الاستیک درخواست میکند تا بررسی کند که آیا عنوان در پایگاه داده وجود دارد یا خیر.
اگر عنوان ویدیو در جستجوی الاستیک پیدا شود، CDS جزئیات را از پایگاه داده دریافت میکند.
جزئیات ویدیو به کلاینت بازگردانده میشود.
CDS از سرویس شباهت محتوا (CSS) درخواست میکند که لیستی از عناوین ویدیوی مشابه را به CDS برمیگرداند.
CDS جزئیات ویدیو را از پایگاه داده برای آن عناوین ویدیوی مشابه دریافت میکند.
CDS جزئیات ویدیوی مشابه را به کلاینت برمیگرداند.
اسپارک (Spark) و سیستم توصیه ویدئو
هنگامی که صفحه اول Netflix باز میشود، دیده می شود که هر ویدئو تصویر مربوط به خودش را دارد. به این تصاویر، تصاویر تیتر میگویند. Netflix حداکثر کلیک را برای ویدیوها از کاربران میخواهد و این کلیکها به تصاویر تیتر بستگی دارد. Netflix باید تصویر تیتر قانعکننده مناسبی را برای یک ویدیوی خاص انتخاب کند. برای انجام این کار، Netflix چندین اثر هنری را برای یک فیلم خاص ایجاد میکند و این تصاویر را به صورت تصادفی برای کاربران نمایش میدهد. برای یک فیلم، تصاویر میتوانند برای کاربران مختلف متفاوت باشند. نتفلیکس بر اساس اولویتها و سابقه تماشای شما پیشبینی میکند که چه نوع فیلمهایی را بیشتر دوست دارید یا چه بازیگرانی را در یک فیلم بیشتر دوست دارید. با توجه به سلیقه کاربران، تصاویر برای آنها نمایش داده میشود.
اگر کاربری بخواهد محتوا یا ویدیویی را در Netflix پیدا کند، سیستم توصیه Netflix به کاربران کمک میکند تا فیلمها یا ویدیوهای مورد علاقه خود را بیابند. برای ساخت این سیستم توصیه، Netflix باید علاقه کاربر را پیشبینی کند و انواع مختلفی از دادهها را از کاربران جمعآوری میکند، از جمله:
تعامل کاربر با سرویس (مشاهده سابقه و نحوه امتیازدهی کاربر به عناوین دیگر)
سایر اعضا با سلیقه و ترجیحات مشابه
اطلاعات فراداده از ویدیوهای قبلاً تماشا شده برای یک کاربر مانند عناوین، ژانر، دستهها، بازیگران، سال انتشار و غیره
دستگاه کاربر، در چه زمانی کاربر فعالتر است و برای چه مدت کاربر فعال است
نتفلیکس از دو الگوریتم مختلف برای ساخت یک recommendation system استفاده میکند:
فیلتر مشارکتی: ایده این فیلترینگ این است که اگر دو کاربر سابقه رتبهبندی مشابهی داشته باشند، در آینده نیز رفتار مشابهی خواهند داشت.
فیلتر مبتنی بر محتوا: ایده این است که آن ویدیوهایی را فیلتر کنید که مشابه ویدیویی است که کاربر قبلاً دوست داشته است. فیلترینگ مبتنی بر محتوا به شدت به اطلاعات محصولات مانند عنوان فیلم، سال انتشار، بازیگران، ژانر بستگی دارد. بنابراین برای پیادهسازی این فیلتر، دانستن اطلاعاتی که هر مورد را توصیف میکند مهم است.
موتور Apache Spark
Apache Spark یک موتور چند زبانه برای اجرای مهندسی داده، علم داده و یادگیری ماشین در ماشینها یا خوشههای single‑node است. نتفلیکس از Apache Spark و یادگیری ماشین برای پیشنهاد فیلم استفاده میکند.
دو عنصر کلیدی در سیستم توصیه نقش آفرینی میکنند:
یادگیری ماشین: نتفلیکس از الگوریتمهای هوشمند یادگیری ماشین استفاده میکند تا اطلاعات شما را تحلیل کند. این الگوریتمها با بررسی سوابق تماشای فیلمهایتان، امتیازدهیهای شما و حتی عادتهای تماشایی (زمان تماشا، مدت زمان تماشا و ...) ترجیحات و الگوهای رفتاری شما را درک میکنند.
اسپارک: حجم عظیم دادههای نتفلیکس، تحلیل آنها را با روشهای سنتی غیرممکن کرده است. اسپارک با موازیسازی محاسبات، تحلیل این حجم انبوه از اطلاعات را با سرعت و دقت بالایی انجام میدهد.
معماری زیرساخت ردیابی توزیع شده در Netflix:
۱. مشکل: مهندسان نتفلیکس برای بررسی ایرادات استریم دادهها مجبور به بررسی حجم عظیمی از دادهها و لاگها بودند. این فرآیند زمانبر، طاقتفرسا و مستعد خطا بود.
۲. راهحل: استفاده از ردیابی توزیع شده برای جمعآوری و تجزیه و تحلیل دادههای مربوط به تراکنشها در سراسر سیستم. انتخاب ابزار Open-Zipkin به عنوان یک ابزار منبع باز محبوب برای ردیابی توزیع شده.
۳. نتفلیکس برای رفع چالش بررسی خطاهای سیستم استریم، که مستلزم تحلیل دستی و زمانبر حجم عظیمی از لاگها بود، به سراغ پیادهسازی معماری ردیابی توزیع شده رفت. این کار با انتخاب ابزار Open-Zipkin آغاز شد تا بتوان مسیر هر درخواست را در سیستم دنبال کرد، مشکلات را سریعتر شناسایی نمود و عملکرد را با یافتن گلوگاهها بهبود داد. کتابخانههای tracer در سطح کد به منظور جمعآوری اطلاعات تراکنشها پیادهسازی شدند و دادههای جمعآوریشده به سیستم پردازش Real-Time ارسال شدند.
با توجه به چالشهایی مانند حجم زیاد داده و نیاز به پردازش Real-Time، نتفلیکس ابزار Mantis را توسعه داد که دادهها را با بافر کردن و پردازش همزمان تحلیل میکرد. همچنین با ارائه زبان MQL، امکان کاوش دقیقتری در دادهها فراهم شد. این سیستم با فشردهسازی و بهینهسازی مصرف منابع، تحلیل سریعتر و موثرتری را ممکن کرد و توانست دادهها را در زمان اجرا تحلیل کرده و کارایی سیستم را بالا ببرد.
در حوزه ذخیرهسازی، افزایش مداوم دادهها چالشهایی برای تیم ایجاد کرد. در ابتدا از Elasticsearch استفاده شد، اما بهمرور به دلیل محدودیت مقیاسپذیری، به Cassandra مهاجرت کردند. همچنین برای کاهش هزینه و افزایش کارایی، از تکنیکهایی مثل فشردهسازی با zstd، استفاده از حافظههای ابری EBS و ساختار Tiered Storage بهره گرفتند. این اقدامات منجر به بهینهسازی قابل توجه هزینهها و افزایش انعطافپذیری سیستم ذخیرهسازی شدند.
برای جمع بندی، اقدامات انجام گرفته برای ارتقای برخی از Quality Attribute ها را مرور می کنیم:
کارایی (Performance)
شبکه CDN: کاهش فاصله فیزیکی و تأخیر.
پخش با بیت نرخ تطبیقی: تضمین پخش روان حتی با اتصالات کندتر (با از دست دادن کیفیت ویدئو).
پیش نمایش و بافر: تضمین پخش بدون وقفه حتی با نوسانات لحظهای.
کدینگ و فشرده سازی (VP9, HEVC): در عین حفظ کیفیت تصویر عالی، به نسبتهای فشردهسازی بالایی دست مییابند. میزان داده برای ارسال ویدئو را کاهش میدهد.
بهینهسازی شبکه (Open Connect): نتفلیکس با ارائهدهندگان خدمات اینترنتی (ISP) همکاری میکند تا اتصالات اختصاصی را برای اولویت دادن به ترافیک نتفلیکس برقرار کند. این کار از تراکم در مسیرهای عمومی اینترنت میکاهد و سرعت تحویل را بهبود میبخشد.
تحلیل پیشبینیکننده: نتفلیکس از الگوریتمهای یادگیری ماشین برای پیشبینی تقاضای آینده و مقیاسگذاری زیرساخت خود قبل از ساعات اوج استفاده میکند و به حداقل رساندن گلوگاههای احتمالی و مشکلات بافرینگ کمک میکند.
Availability (دسترسپذیری)
زیرساخت و افزونگی (Redundancy):
مراکز داده با توزیع جهانی: نتفلیکس شبکه وسیعی از مراکز داده را در سراسر جهان راهاندازی کرده است که به صورت استراتژیک قرار گرفتهاند و تأثیر قطعی یا اختلالات منطقهای را به حداقل میرسانند.
استراتژی چند ابری: استفاده از چندین ارائه دهنده ابر مانند AWS، Google Cloud Platform و Microsoft Azure، افزونگی را افزایش میدهد و وابستگی به هر فروشنده را کاهش میدهد. این امر حتی در صورت وجود مشکل با یک ارائه دهنده، تداوم سرویس را تضمین میکند.
تکرار محتوا: محتوا در سراسر مراکز داده مختلف تکرار میشود تا حتی در صورت بروز مشکل در یک مکان، در دسترس بودن را تضمین کند. این تضمین میکند که کاربران میتوانند از سرورهای نزدیک به خود به نمایشها و فیلمهای مورد علاقه خود دسترسی داشته باشند و تأخیر و اختلالات احتمالی را به حداقل برسانند.
مقاومت و همیاری شبکه (Open Connect): همکاری با ارائه دهندگان خدمات اینترنتی (ISP) از طریق Open Connect، اتصالات اختصاصی با پهنای باند بالا ایجاد میکند که اولویت را به ترافیک نتفلیکس میدهند. این امر از مسیرهای شلوغ اینترنت عمومی عبور میکند و مسیر مستقیمتر و قابل اعتمادتری برای انتقال داده ارائه میدهد.
نظارت لحظهای: نتفلیکس به طور مداوم زیرساخت و عملکرد پلتفرم خود را برای هرگونه ناهنجاری یا مشکل احتمالی نظارت میکند. این به آنها اجازه میدهد تا قبل از تشدید شدن مشکلات و تأثیرگذاری بر کاربران، آنها را شناسایی و حل کنند.
مکانیسمهای بازیابی خودکار: بسیاری از سیستمها به مکانیسمهای بازیابی خودکار مجهز هستند که میتوانند بدون نیاز به دخالت دستی از مشکلات جزئی بهبود یابند و زمان خرابی را به حداقل برسانند.
امنیت (Security)
رمزنگاری: دادههای کاربران، از جمله رمزعبور، اطلاعات پرداختی و تاریخچه تماشا، در حالت سکون و حین انتقال با استفاده از الگوریتمهای رمزنگاری قدرتمند رمزگذاری میشوند. این کار حتی در صورت رهگیری انتقال دادهها، دسترسی یا رمزگشایی آنها را برای طرفهای غیرمجاز دشوار میکند.
کنترل دسترسی: کنترلهای دقیق دسترسی محدود میکنند که چه کسی میتواند به دادههای کاربری درون نتفلیکس دسترسی داشته باشد و رویههای احراز هویت قوی برای جلوگیری از دسترسی غیرمجاز وجود دارد.
شفافیت و انطباق: نتفلیکس به مقررات مربوط به حریم خصوصی داده مانند GDPR و CCPA پایبند است و به کاربران اطلاعات شفافی در مورد جمعآوری دادهها و شیوههای استفاده از آنها ارائه میدهد.
چالشهای کلیدی و راهحلهای ارائه شده در این معماری:
مدیریت وابستگیها: یکی از چالشهای اصلی، مدیریت وابستگیها بین سرویسها برای جلوگیری از خرابیهای متوالی بود. نتفلیکس برای مدیریت تایماوتها، تلاشهای مجدد (retry) و اجرای مکانیزمهای جایگزین، از Hystrix استفاده کرد.
پایداری و قضیه CAP: با تمرکز بر تعادل میان سازگاری و دسترسی، نتفلیکس سازگاری نهایی را انتخاب کرد و از فناوریهایی مانند Cassandra برای مدیریت دادههای توزیع شده استفاده کرد.
قابلیت اطمینان زیرساخت: یک حادثه در شب کریسمس ۲۰۱۲، زمانی که یک خرابی در سیستم کنترل AWS منجر به اختلالات گسترده شد، نیاز به یک زیرساخت مطمئن را برجسته کرد. این حادثه نتفلیکس را به توسعه یک استراتژی چند منطقهای برای افزایش استقامت سوق داد.
سرویسهای stateless در مقابل سرویسهای دارای حالت: نتفلیکس بین سرویسهای بدون حالت، که مقدار زیادی از دادهها را ذخیره نمیکنند و به سرعت از دست دادن گره بهبود مییابند، و سرویسهای دارای حالت مانند پایگاههای داده و حافظههای نهان، که در آنها از دست دادن گره اهمیت بیشتری دارد، تمایز قائل شد.
استراتژیهای کشینگ: نتفلیکس استراتژی کشینگ خود را از کشهای تکگرهای به رویکردی مطمئنتر با استفاده از EVCache، یک فناوری مبتنی بر MemcacheD، تکامل داد و قابلیت اطمینان را تضمین کرد.
اسپاتیفای یکی از محبوبترین سرویسهای استریم موسیقی در دنیاست، که این محبوبیت بیدلیل نیست. پشت پرده، این پلتفرم از یک فناوری پیشرفته استفاده میکند تا خدماتش را به میلیونها کاربر در سراسر جهان ارائه دهد. از معماری مبتنی بر میکروسرویسها گرفته تا بهرهگیری از containerization و ابزارهای پیشرفته مانیتورینگ.
۱. تاریخچه تحول معماری اسپاتیفای
داستان موفقیت اسپاتیفای از سال ۲۰۰۶ آغاز شد، زمانی که «دنیل اک» و «مارتین لورنتزون» با هم آشنا شدند و رویای ساخت یک سرویس قانونی و مقرونبهصرفه برای مقابله با دزدی موسیقی را شکل دادند. اسپاتیفای در سال ۲۰۰۸ کارش را در سوئد آغاز کرد و بعد به کشورهای اروپایی دیگر گسترش یافت.
یکی از عوامل مهمی که باعث شد اسپاتیفای در ابتدای کار به سرعت محبوب شود، مدل تجاری نوآورانهی آن بود: ارائهی سرویس freemium که به کاربران امکان میداد بهصورت رایگان از بخشی از موسیقیها استفاده کنند و در صورت تمایل با پرداخت هزینه، به نسخهی premium بدون تبلیغ و با امکانات بیشتر دسترسی داشته باشند. تمرکز بر تجربهی کاربری نیز نقش مهمی در موفقیت اسپاتیفای ایفا کرد؛ از طراحی ساده و کاربرپسند رابط کاربری گرفته تا پلیلیستهای شخصیسازیشده و پیشنهادات هوشمندانه. همچنین، اسپاتیفای سرمایهگذاری گستردهای روی همکاری با شرکتهای موسیقی و هنرمندان انجام داد تا بتواند آرشیوی غنی و در حال رشد را در اختیار کاربران قرار دهد. قابلیتهایی مثل اشتراکگذاری و ساخت پلیلیستهای مشترک با دوستان و دنبالکنندهها، به گسترش طبیعی سرویس کمک زیادی کرد.
با رشد اسپاتیفای، این شرکت وارد بازارهای جدید از جمله آمریکا (در سال ۲۰۱۱) شد و به توسعهی پلتفرمش ادامه داد؛ قابلیتهایی مانند پادکستها و محتوای انحصاری را اضافه کرد تا کاربران بیشتری را جذب و حفظ کند.
۲. نیازمندیهای سیستم
برای طراحی یک اپلیکیشن استریم موسیقی مانند اسپاتیفای، ابتدا باید نیازمندیها را شناخت.
۲.۱. نیازمندیهای عملکردی (Functional Requirements)
جستجو: کاربران بتوانند آهنگها، هنرمندان، آلبومها و پلیلیستها را جستجو کنند.
استریم موسیقی: کاربران بتوانند آهنگها را به صورت زنده پخش کنند.
پلیلیستها: کاربران بتوانند پلیلیست بسازند، به اشتراک بگذارند یا آنها را ویرایش کنند.
پیشنهاد موسیقی: بر اساس تاریخچهی شنیداری و سلیقهی کاربران، آهنگهایی به آنها پیشنهاد داده شود.
مدل تبلیغاتی: کاربران نسخهی رایگان، پس از چند آهنگ، تبلیغات صوتی خواهند شنید.
۲.۲. نیازمندیهای غیرعملکردی (Non-Functional Requirements)
Latency (تأخیر): تأخیر پایین برای پخش فوری موسیقی بعد از انتخاب کاربر، دریافت سریع نتایج جستجو، و تعامل روان با رابط کاربری حیاتی است. پخش زندهی آهنگها باید با تأخیر بسیار کم انجام شود.
Scalability (مقیاسپذیری): مقیاسپذیری تضمین میکند که با افزایش تعداد کاربران، سیستم بتواند بار اضافی را بدون افت عملکرد مدیریت کند. سیستم باید بتواند صدها میلیون کاربر جهانی و میلیونها استریم همزمان را پشتیبانی کند.
Availability (دسترسپذیری): کاربران باید بدون وقفه به امکاناتی مثل استریم موسیقی، جستجو و سایر قابلیتها دسترسی داشته باشند. سیستم همیشه باید در دسترس باشد و قطعی نداشته باشد.
Robustness (پایداری و مقاومت): شامل توانایی مقابله با ورودیهای نامعتبر، مشکلات شبکه، خرابی سرور و رفتارهای غیرمنتظره از سمت کلاینت است.
پوشش جهانی: پشتیبانی از کاربران در مناطق مختلف جغرافیایی با کمک CDN برای تحویل سریعتر فایلهای صوتی.
CAP Theorem: با توجه به ماهیت سرویس استریم موسیقی مانند Spotify که دسترسی آنی به آهنگها و metadata برای تجربه کاربری اهمیت دارد، باید روی Availability (دسترسپذیری) و Partition Tolerance (تحمل پارتیشن) تمرکز کرد. Partition Tolerance اطمینان حاصل میکند که در صورت بروز اختلالات شبکهای، سیستم همچنان فعال باقی بماند و کاربران بتوانند به آهنگها دسترسی داشته باشند. Availability تضمین میکند که حتی در صورت خرابی سرور، کاربران بتوانند آهنگها را جستجو و پخش کنند.
۲.۳. نیازمندیهای ظرفیت (Capacity Requirements)
فرضیات ترافیکی:
کاربران فعال کل: ۵۰۰ میلیون
کاربران فعال روزانه: ۱۰۰ میلیون
متوسط تعداد استریم روزانه هر کاربر: ۱۰
حجم متوسط هر آهنگ: ۵ مگابایت
طول متوسط آهنگ: ۴ دقیقه
کاتالوگ آهنگها: ۱۰۰ میلیون آهنگ
تخمین پهنای باند شبکه:
استریم روزانه: ۱۰۰ میلیون کاربر × ۱۰ استریم/کاربر = ۱ میلیارد استریم
انتقال داده روزانه: ۱ میلیارد استریم × ۵ مگابایت/استریم = ۵ پتابایت
انتقال داده در هر ثانیه: ۵ پتابایت / ۸۶۴۰۰ ثانیه ≈ ۵۸ گیگابایت در ثانیه
تخمین فضای ذخیرهسازی:
موسیقیها: ۱۰۰ میلیون آهنگ × ۵ مگابایت/آهنگ = ۵۰۰ ترابایت
متادیتای آهنگها: ۱۰۰ میلیون آهنگ × ۲ کیلوبایت/آهنگ = ۲۰۰ گیگابایت
متادیتای کاربران: ۵۰۰ میلیون کاربر × ۱۰ کیلوبایت/کاربر = ۵ ترابایت
۳. معماری کلان
اسپاتیفای از معماری microservices استفاده میکند تا سیستمش قابلیت مقیاسپذیری و نگهداری بالا داشته باشد. این معماری پلتفرم را به سرویسهای کوچک و مستقلی تقسیم میکند که هرکدام مسئول انجام عملکرد خاصی هستند، مانند مدیریت کاربران، ساخت پلیلیست، استریم محتوا یا موتورهای پیشنهاددهنده.

مزایای معماری Microservices:
Scalability: هر سرویس میتواند بهصورت مستقل و بر اساس میزان تقاضا مقیاسپذیر شود.
Fault Isolation: در صورت خرابی یک سرویس، سایر سرویسها تحت تأثیر قرار نمیگیرند.
Independent Deployment: توسعهدهندگان میتوانند هر سرویس را بهصورت جداگانه بهروزرسانی کنند، بدون اینکه بر کل سیستم تأثیر بگذارد.
اجزای اصلی در معماری سطح بالای اسپاتیفای عبارتند از:
SpotifyWebServer: بهعنوان لایهی BFF (Backend for Frontend) عمل میکند که وظایفی مانند احراز هویت، rate limiting، و اعتبارسنجیها را انجام میدهد.
SongSearchService: سرویس جستجوی آهنگ که نتایج مرتبط با کوئری کاربر را برمیگرداند.
Elasticsearch: برای افزایش سرعت جستجو بر اساس نام آهنگ، خواننده، متن ترانه یا سایر metadataها استفاده میشود. این سرویس ایندکسی از محتوای قابل جستجو ایجاد میکند تا retrieval سریع ممکن شود.
SongMetadataService: سرویسی که APIهایی برای دریافت داده از MetadataDB ارائه میدهد.
MetadataDB: سیستم مرجع برای metadata آهنگها.
SongStreamingService: برای استریم فایل صوتی آهنگ به کاربر استفاده میشود.
ObjectStore: سیستم مرجع برای نگهداری فایلهای صوتی.
CDN: شبکه تحویل محتوا که آهنگها را cache میکند تا latency کاهش یابد.
۴. فناوریهای کلیدی و Tech Stack
۴.۱. فناوریهای بکاند
Java: زبان برنامهنویسی اصلی اسپاتیفای است و برای ساخت RESTful APIها و مدیریت وابستگیها از Spring Framework استفاده میشود.
Scala: برخی از سرویسهای اصلی با Scala نوشته شدهاند.
Node.js: برخی سرویسهای بکاند نیز با Node.js توسعه داده شدهاند.
Apache Kafka: برای پردازش دادهها و رویدادها به صورت real-time استفاده میشود.
Apache Cassandra: دیتابیس NoSQL که برای ذخیرهی اطلاعاتی مانند پلیلیستها و آرشیو موسیقی کاربران به کار میرود.
Redis: برای cache کردن دادههایی مثل اطلاعات مربوط به آهنگها، آلبومها و هنرمندان.
Docker: برای containerization و اجرای میکروسرویسها در قالب کانتینرهای سبک.
۴.۲. فناوریهای فرانتاند
React: برای ساخت رابط کاربری وباپ.
Redux: برای مدیریت state در اپلیکیشن.
Sass: برای تولید CSS با قابلیتهای بیشتر.
Webpack: برای bundle کردن فایلهای جاوااسکریپت و دیگر منابع.
۴.۳. زیرساخت (Infrastructure)
Amazon Web Services (AWS): برای ارائه منابع محاسباتی و ذخیرهسازی.
Kubernetes: برای orchestration کانتینرها و مدیریت میکروسرویسها.
Terraform: برای پیادهسازی infrastructure بهصورت کد.
Prometheus: برای مانیتورینگ سلامت سیستمها.
Grafana: برای ساخت داشبوردهای تحلیلی و بصریسازی دادهها.
۵. مدل سیستمی اسپاتیفای
برای اینکه بتوانند دربارهی نرمافزار خود صحبت کنند و به تفاهم برسند، اسپاتیفای یک زبان مشترک و مجموعهای از تعریفها به اسم «مدل سیستمی اسپاتیفای» ایجاد کرده است. این مدل، مجموعهای از موجودیتها و انتزاعات پایهای را معرفی میکند که به تجزیه و تحلیل اطلاعاتی دربارهی سلامت نرمافزار، مالکیت و وابستگیهای آن کمک میکند. این درک مشترک از نرمافزار و منابع، کلید موفقیت در مقیاس کاری اسپاتیفای است.
۵.۱. موجودیتهای اصلی مدل سیستمی:
API ها: مرزهای بین کامپوننتها را تعریف میکنند، یعنی مشخص میکنند هر بخش چطور با بقیه ارتباط دارد.
Component ها: بخشهای مستقل نرمافزاری هستند، مثل یک سرویس بکاند، یک وبسایت، یک پایپلاین دیتا یا حتی یک کتابخانه.
Resource ها: زیرساختهایی هستند که یک کامپوننت برای اجرا به آنها نیاز دارد، مثل دیتابیس، ماشین مجازی یا فضای ذخیرهسازی.

۵.۲. انتزاعهای جدید برای مدیریت پیچیدگی:
System ها: مجموعهای از موجودیتهایی که با هم کار میکنند تا یک عملکرد مشخص ارائه دهند.
Domain ها: سیستمها و موجودیتهایی که به یک حوزهی کسبوکار مربوط میشوند.
با تبدیل این مدل به متادیتا، اسپاتیفای توانسته است یک کاتالوگ نرمافزاری ایجاد کند که مالکیت، وابستگی، چرخهعمر و سایر اطلاعات را دنبال و ثبت میکند.

۶. استفاده از مدل C4 برای دیاگرامهای اسپاتیفای
مدل C4 یک روش سبک، ساده و موثر برای بصریسازی معماری نرمافزار است. این مدل مجموعهای از انتزاعات مشخص، نشانهگذاری استاندارد و بهترین روشها برای کشیدن دیاگرام را ارائه میدهد. این مدل تعادل خوبی بین روشهای پراکنده و استانداردهای خشک ایجاد میکند.

اسپاتیفای از نشانهگذاریها و اصول C4 استفاده کرده، اما بخش های انتزاعی آن را با مدل سیستمی خود جایگزین کرده است. نتیجه، مجموعهای جدید از دیاگرامهای پایه برای مستندسازی معماری و طراحی سیستم است:
System Landscape Diagram: نشان میدهد یک مجموعه سیستم مرتبط چطور با هم در ارتباطند و چه وابستگیهایی به بیرون دارند. مثلاً همهی سیستمهایی که توسط یک تیم اداره میشوند.
System Context Diagram: نشان میدهد یک سیستم چطور در بافت کلی کسبوکار، کاربران و سایر سیستمها قرار گرفته است.
System Components Diagram: نشان میدهد اجزای داخلی یک سیستم چیست. (در مدل C4 به آن Container Diagram هم میگویند).

۶.۱. نمونهای از جزئیات معماری با مدل C4 (Backstage)
کانتینر: سیستم Backstage از سه جزء اصلی تشکیل شده است:
یک برنامه وب Backstage که مسئول نمایش مهمترین اطلاعات به کاربر است.
یک سرویس Backstage Backend که مسئول راهاندازی سایر افزونههای Backstage مانند Software Catalog است.
یک پایگاه داده که مسئول ذخیره هرگونه دادهای است که باید به کاربر ارائه شود. این پایگاه داده معمولاً دادههای خاص افزونه را ذخیره میکند، به این معنی که بسته به نحوه تصمیمگیری شما برای نوشتن برنامه Backstage، میتوانید نمونههای پایگاه داده زیادی داشته باشید.
کامپوننت: برنامه وب Backstage از افزونهها تشکیل شده است. برخی از نمونههای افزونهها میتوانند یک افزونه CI/CD (مانند Circle CI، Travis CI) یا کاتالوگ نرمافزار باشند (ویژگیهای اصلی نیز افزونه هستند). این افزونهها معمولاً فراخوانیهای API را به سرویسهای دیگر ارسال میکنند تا اطلاعات را به کاربر ارائه دهند. اگر افزونه نیاز به دسترسی به API دارد، Backstage سه گزینه ارائه میدهد:
دسترسی مستقیم به API.
پیکربندی Backstage برای پروکسی کردن به یک API موجود.
ایجاد یک افزونه backend اگر API در کنار افزونه frontend پیادهسازی شود.

اتوماسیون دیاگرامهای معماری در Backstage:
داشتن یک کاتالوگ کامل از نرمافزار، متادیتاها و کامپوننتها، امکان تولید خودکار دیاگرامهای معماری و مرور تعاملی آنها را فراهم کرده است. این دیاگرامها همیشه با واقعیت بهروز هستند، زیرا از روی متادیتای زنده تولید میشوند. Backstage با سیستم افزونهپذیری خود، امکان اضافه کردن تب "Architecture" به صفحهی هر سیستم را فراهم کرده که دیاگرام Spotify Component آن سیستم را نشان میدهد.
۷. شبکه تحویل محتوا (CDN) برای استریم
اسپاتیفای از Content Delivery Networks برای تحویل موسیقی و محتوای صوتی با تأخیر پایین استفاده میکند. CDN فایلهای صوتی را روی سرورهای مرزی (edge servers) که بهطور جهانی توزیع شدهاند، cache میکند تا از نزدیکترین مکان به کاربر، محتوا را تحویل دهد.
نقش CDN در اسپاتیفای:
کاهش Latency: محتوا از سرورهای جغرافیایی نزدیکتر ارائه میشود و باعث کاهش زمان بارگذاری و بافر میگردد.
توزیع بار: با انتقال ترافیک به edge servers، فشار روی زیرساخت اصلی اسپاتیفای کاهش مییابد.
بهینهسازی هزینه: CDN هزینه بالایی دارد، بنابراین راهاندازی CDN اختصاصی ممکن است مقرونبهصرفهتر باشد. برخی آهنگها فقط در نواحی خاصی محبوباند؛ بنابراین، نگهداری آنها فقط در CDNهای منطقهای مناسبتر است. فقط آهنگهای با تقاضای بالا در CDN ذخیره شوند و بقیه در سرورهای با ظرفیت بالا و هزینه کمتر.
۸. زیرساخت داده و Apache Kafka
اسپاتیفای حجم بسیار زیادی از دادههایی را که کاربران در زمان واقعی (real-time) تولید میکنند، پردازش میکند. برای مدیریت این دادهها، از Apache Kafka استفاده میشود؛ یک پلتفرم توزیعشده برای event-streaming که حجم زیادی از داده را بین سرویسها ingest، process و انتقال میدهد.
خطوط پردازش داده:
Apache Kafka: مدیریت eventهای real-time مثل پخش آهنگ، رد کردن آهنگ (skip) و لایک کردن.
Apache Samza و Storm: پردازش دادههای real-time برای بهروزرسانی آنی سیستمهای پیشنهاددهنده و ویژگیهای شخصیسازیشده.
۹. سیستمهای ذخیرهسازی
اسپاتیفای از چندین راهحل ذخیرهسازی برای کاربردهای مختلف، از دادههای کاربران گرفته تا محتوای صوتی، استفاده میکند. در ابتدا از PostgreSQL استفاده میکرد اما به دلیل مشکلات مقیاسپذیری به ترکیبی از دیتابیسها مهاجرت کرد.
Cassandra: یک پایگاهداده NoSQL برای ذخیره دادههای گسترده و توزیعشده مانند پروفایل کاربران، دادههای پلیلیست و فعالیتهای کاربر. Cassandra در دسترسپذیری بالا و تحمل خرابی بسیار مناسب است.
Amazon S3: برای ذخیره فایلهای صوتی حجیم، کاور آلبوم و دیگر محتوای استاتیک. مقیاسپذیری و هزینه مناسب S3 برای کتابخانه گسترده موسیقی اسپاتیفای حیاتی است. آهنگها را میتوان Tiering کرد، به این شکل که آهنگهای کمتر محبوب به کلاس ذخیرهسازی S3 Standard-Infrequent Access منتقل شوند تا هزینهها بهینه شوند.
MySQL: برای تراکنشهای آنلاین با ساختار رابطهای.
Redis: برای کشینگ توزیعشده، و همچنین برای کش اطلاعات مربوط به آهنگها، آلبومها و هنرمندان.
HBase: ممکن است در سناریوهایی با throughput بالا مانند آنالیزها و متریکهای real-time استفاده شود.
HDFS (Hadoop Distributed File System): برای ذخیره آفلاین دادههای حجیم.
AWS, Google Cloud, Azure: به عنوان ذخیرهسازی ابری.
Hive: برای تحلیل دادههای کلان در سطح سازمانی.
۱۰. سیستم Personalization
سیستم پیشنهاددهنده اسپاتیفای یکی از قابلیتهای کلیدی آن است که پلیلیستهایی مثل Discover Weekly و Daily Mix را براساس ترجیحات کاربر شخصیسازی میکند.
مدلهای Machine Learning: برای ارائه پیشنهادهای دقیق، رفتار کاربر، metadata موسیقی و سابقه گوشدادن تحلیل میشوند.
Collaborative Filtering: استفاده از الگوریتمهای collaborative filtering برای پیشنهاد محتوا براساس سلیقه کاربران مشابه.
Natural Language Processing (NLP): برای پردازش و دستهبندی محتوای پادکستها و metadata، و بهبود پیشنهادهای مربوط به محتوای گفتاری.
۱۱. APIها برای ارتباط بین سرویسها
ارتباط بین microservices در اسپاتیفای از طریق RESTful APIs یا gRPC انجام میشود. این APIها پایه ارتباط بین سرویسهایی مانند سرویس پلیلیست، سرویس کاربران و سرویس محتوا هستند.
API Gateway: اسپاتیفای از API Gateway برای مدیریت ارتباط بین frontend و backend استفاده میکند. این قابلیت امکان مسیریابی بهینه درخواستها، load balancing و ویژگیهای امنیتی مانند rate limiting را فراهم میکند.
۱۲. لایه Cache
اسپاتیفای بهطور گستردهای از caching برای پاسخدهی سریعتر و کاهش بار روی دیتابیسها استفاده میکند.
Redis یا Memcached: برای ذخیرهسازی دادههایی که زیاد استفاده میشوند مانند پلیلیستهای کاربر، آهنگهای اخیراً پخششده و جزئیات پروفایل.
Edge Caching: علاوه بر caching توسط CDN برای فایلهای صوتی، ممکن است caching لایهای برای metadata مانند عنوان آهنگ و نام خواننده استفاده شود.
۱۳. پایش (Monitoring) و ثبت لاگ
با توجه به پیچیدگی سیستم، اسپاتیفای از ابزارهای monitoring و logging برای بررسی عملکرد سیستم، شناسایی مشکلات و اطمینان از اجرای روان استفاده میکند.
Grafana و Prometheus: برای مانیتورینگ لحظهای متریکهای سیستم؛ Prometheus برای جمعآوری متریک و Grafana برای visualization و هشداردهی استفاده میشود.
ELK Stack: برای لاگگیری متمرکز و رفع اشکال، ممکن است از ELK (Elasticsearch، Logstash، Kibana) استفاده شود تا مهندسان بتوانند لاگهای سرویسهای مختلف را تحلیل کنند.
۱۴. امنیت و کنترل دسترسی
اسپاتیفای اقدامات امنیتی گستردهای برای محافظت از دادههای کاربران و پلتفرم خود پیاده کرده است.
OAuth2 و JWT: برای احراز هویت (Authentication) و Authorization کاربران. این مکانیسمها دسترسی امن به منابعی مانند پلیلیستها و کتابخانه موسیقی را فراهم میکنند.
رمزنگاری (Encryption): دادهها، بهویژه اطلاعات شخصی و اعتبارنامهها، هم در حالت انتقال (با TLS) و هم در حالت ذخیرهشده رمزنگاری میشوند.
۱۵. DevOps و استقرار پیوسته (Continuous Deployment)
اسپاتیفای از رویکردهای DevOps برای استقرار سریع و روان ویژگیهای جدید و بهروزرسانیها استفاده میکند. از CI/CD pipelines برای توسعه سریع، تست و استقرار بهره میبرد.
Docker و Kubernetes: برای بستهبندی microservices از Docker استفاده میکند و با Kubernetes آنها را orchestration میکند تا مدیریت مقیاسپذیر و بهینه صورت گیرد.
۱۶. طراحی عمیق
۱۶.۱. پایگاه داده metadata (Metadata Datastore)
رویکرد اول: استفاده از پایگاه داده Relational: ساختار schema از پیش تعریفشدهای وجود دارد که بهندرت بهروزرسانی میشود. میتوان دادهها را نرمالسازی کرد و اطلاعات خواننده، تهیهکننده و سایر موارد را در جدولهای جداگانه ذخیره کرد تا redundancy دادهها کاهش یابد. از آنجایی که فقط ۱ گیگابایت داده نیاز است، همهی دادهها میتوانند در یک سرور پایگاهداده قرار گیرند.
رویکرد دوم: استفاده از پایگاه داده NoSQL: نیاز به تکرار دادهها وجود دارد، مثلاً اطلاعات مشترک مربوط به خوانندهها یا سایر جزئیات برای چندین آهنگ باید مجدداً ذخیره شوند.
Song
id: String
name: String
audioURL: String
۱۶.۲. Object Store و نحوه کارکرد استریم آهنگ
Amazon S3: میتوان از Amazon S3 برای ذخیره آهنگها استفاده کرد.
رویکرد اول: HTTP Range Requests: برای استریم صوتی یا ویدیویی، میتوان فایل را بهصورت کامل در Blob Storage ذخیره کرد و با استفاده از HTTP Range Request بخشهایی از آن را درخواست کرد. در صورتیکه سرعت اینترنت کاربر پایین باشد، این کار میتواند منجر به buffering شود، مخصوصاً وقتی که دادههای با bitrate بالا درخواست شود.
رویکرد دوم: Adaptive Bitrate با HTTP Range Requests: نسخههای مختلفی از فایل صوتی با bitrateهای متفاوت (مثلاً 320kbps، 128kbps و...) در Object Store ذخیره میشوند. اپلیکیشن کلاینت ابتدا نسخهای با bitrate پیشفرض (مثلاً 320kbps) را دریافت میکند تا فقط بخش اولیه فایل دانلود و پخش شود، و زمان بارگذاری اولیه کاهش یابد. همزمان اپلیکیشن پهنای باند اینترنت کاربر را پایش میکند و در صورت ناکافی بودن، به نسخهای با bitrate پایینتر سوئیچ میکند. این روش نیاز به کنترل بیشتر از سمت کلاینت و هماهنگی دقیق دارد.
رویکرد سوم: HLS یا DASH برای Adaptive Bitrate Streaming: در پروتکلهای استاندارد مانند HLS (HTTP Live Streaming) و DASH (Dynamic Adaptive Streaming over HTTP)، محتوا به قطعات کوتاه (chunks) با bitrateهای مختلف تقسیم میشود. پلیر رسانه یک manifest file را میخواند و بر اساس وضعیت شبکه، مناسبترین قطعه را انتخاب میکند.
نکته: میتوان رویکرد هیبریدی داشت: فایل manifest و قطعات (chunks) آهنگهای محبوب در CDN ذخیره شوند و آهنگهای کمتر محبوب در S3. هنگامیکه کلاینت درخواستی برای پخش آهنگ ارسال میکند، backend تصمیم میگیرد که URL فایل manifest را از CDN برگرداند یا از S3 (بر اساس فاکتورهایی مثل محبوبیت).
۱۶.۳. Failover در Elasticsearch
Elasticsearch سیستم مرجع (System of Record) برای metadata آهنگها نیست. اگر این سرویس دچار خرابی شود، میتوان cache آن را مجدداً با استفاده از دادههای موجود در MetadataDB بازسازی کرد. همچنین، هر بروزرسانی در MetadataDB، بهصورت event به Elasticsearch cluster ارسال شده و ایندکس آن بهروز میشود.
۱۶.۴. بهینهسازیها
شناسایی و حذف گلوگاهها (Bottlenecks): مثلا اگر یک خواننده مشهور آهنگ جدیدی منتشر کند، اکثر درخواستها برای آن آهنگ خاص خواهند بود. در این حالت، سرورهای وب که این درخواستها را پردازش میکنند فشار زیادی را به S3 وارد میکنند و این گلوگاه ایجاد میکند. راهحل: ذخیره آهنگهای محبوب در CDN (مثل Amazon CloudFront) باعث کاهش تأخیر و بهبود تجربه کاربری میشود.
عملکرد (Performance):
Load Balancer: استفاده از شاخص مناسب برای توزیع ترافیک باعث بهبود عملکرد میشود. پیشنهاد میشود توزیع بر اساس پهنای باند شبکه انجام شود، نه CPU.
کش کاربر: کاربر میتواند آهنگهای پرپخش خود را در کش ذخیره کند و بار سرور را کاهش دهد.
کش سرور: سرور نیز میتواند تعداد محدودی از آهنگهای پرپخش را در کش حافظه نگه دارد تا از بار روی دیتابیس و CDN کم شود.
رمزگذاری و فشردهسازی صوتی: میتوان سیستمهایی برای فشردهسازی فایل صوتی ایجاد کرد تا فضا بهینهتر استفاده شود.
گسترش پایگاهداده:
مدل Leader-Follower: از آنجایی که تعداد عملیات خواندن بسیار بیشتر از نوشتن است (تعداد زیاد کاربران که آهنگ پخش میکنند، اما تعداد کم هنرمندان که آهنگ آپلود میکنند)، میتوان از مدل Leader → Follower استفاده کرد:
یک پایگاهداده اصلی (Leader) برای نوشتن و خواندن.
چندین پایگاهداده ثانویه (Follower/Slave) فقط برای خواندن.
این کار باعث میشود metadata آهنگها و کاربران بهصورت سریع و بهینه خوانده شوند.
در نهایت می توان گفت معماری سیستم Spotify یک معماری پیچیده و مبتنی بر microservices است که برای پاسخگویی به نیازهای کاربران گسترده و مدیریت دادههای عظیم طراحی شده است. با استفاده از فناوریهایی مانند CDN، Apache Kafka، سیستمهای پیشنهاددهنده مبتنی بر machine learning، و ابزارهای ذخیرهسازی cloud، Spotify موفق به ارائه تجربهای پایدار، مقیاسپذیر و شخصیسازیشده برای کاربران خود شده است. بهرهگیری از caching، پردازش real-time و زیرساخت امن، Spotify را قادر ساخته تا تجربه استریم صوتی بیوقفهای را در سطح جهانی ارائه دهد.

۱. تاریخچه تحول معماری
اوبر، با هدف اتصال سریع و آسان مسافران به حملونقل، به یکی از بزرگترین پلتفرمهای اشتراک سفر در جهان تبدیل شده است. در پشت این فرآیند به ظاهر ساده (رزرو تاکسی در ۱ تا ۲ دقیقه)، معماری عظیمی وجود دارد که هر مرحله از وارد کردن موقعیت مکانی تا نهایی شدن رزرو را پشتیبانی میکند. اوبر به عنوان یک سیستم حمل و نقل آنی، فراتر از هدف اولیه خود رشد کرده و اکنون بخشهای مختلفی از جمله تحویل غذا (Uber Eats) و حمل بار (Uber Freight) را نیز پشتیبانی میکند. این سیستم از لحظهای که کاربر ثبتنام میکند تا پایان سفر، حجم عظیمی از داده تولید میکند که شامل اطلاعات مسافر، موقعیت مکانی، پرداخت، دستهبندیها، رانندهها و هزینه سفر است. اوبر این دادهها را به صورت یکپارچه جمعآوری، ذخیره و تحلیل میکند.
اوبر در سال ۲۰۰۹ با معماری مونولیتیک (Monolithic) راهاندازی شد. این سیستم شامل یک Backend و یک Frontend واحد، و یک پایگاه داده مرکزی (با استفاده از Python و SQLAlchemy) بود. این معماری در ابتدا و با تعداد کم سفرها و شهرهای فعال، کافی بود. اما با گسترش سریع اوبر به شهرهای مختلف و افزایش پیچیدگی نیازهای تجاری، محدودیتهای معماری مونولیتیک مشخص شد.
از سال ۲۰۱۴، اوبر به معماری سرویسگرا (Service-Oriented Architecture - SOA) و در واقع همان میکروسرویس مهاجرت کرد. در این معماری، هر سرویس کوچک و مستقل است، یک وظیفهی خاص تجاری را انجام میدهد و میتواند از استک فناوری مناسب خود استفاده کند. ارتباط بین سرویسها از طریق API انجام میشود. مزیت اصلی این معماری، امکان استقرار مستقل هر سرویس است که سیستم را مقیاسپذیر و انعطافپذیر میسازد. این معماری اکنون نهتنها سرویس حملونقل، بلکه بخشهای دیگر مانند تحویل غذا و حمل بار را نیز پشتیبانی میکند.
با این حال، با رشد شدید سرویسها، سیستم میکروسرویسها نیز پیچیدهتر شد. ارتباطات بین سرویسها دشوارتر گردید و توسعهدهندگان با چالشهایی مانند مدیریت وابستگیها، هماهنگی بالا و افت بهرهوری مواجه شدند. اوبر برای حل این مشکلات، الگوی DOMA (Domain-Oriented System Architecture) را اتخاذ کرد. در DOMA، سیستم به مجموعههایی بهنام دامنه (Domain) تقسیم میشود که هر دامنه شامل سرویسهای مرتبط با یک حوزه خاص تجاری است. دامنهها در مجموعههای بزرگتری بهنام لایهها (Layers) گروهبندی میشوند که وابستگیها را کنترل میکنند. این طراحی، به شکل یک ساختار لایهای از میکروسرویسهاست. DOMA باعث شد ساختار میکروسرویسها از پیچیدگی خارج شده و به ماژولهایی کوچکتر، منعطفتر، و قابل استفاده مجدد تقسیم شوند. مزایای DOMA شامل تجربه بهتر توسعهدهنده، کاهش پیچیدگی سیستم، مهاجرت آسانتر در آینده و امکان نوآوری سریع است.

۲. نیازمندیهای سیستم
برای طراحی یک اپلیکیشن رزرو تاکسی مانند اوبر، ابتدا باید نیازمندیها را شناخت.
۲.۱. نیازمندیهای عملکردی (Functional Requirements)
نمایش تاکسیهای اطراف کاربر: کاربران باید بتوانند لیست تمام خودروهای موجود همراه با کمترین قیمت و زمان تقریبی رسیدن (ETA) را ببینند.
امکان رزرو تاکسی: کاربران باید بتوانند مسیر خود را انتخاب و خودرو رزرو کنند.
رهگیری موقعیت مکانی: کاربران باید بتوانند مکان راننده را روی نقشه مشاهده کنند. همچنین موقعیت لحظهای سفر باید بهروزرسانی شده و ارتباط میان راننده و مسافر ساده شود.
لغو سفر: کاربران باید در هر لحظه قادر به لغو سفر خود باشند.
ایجاد حساب کاربری و ورود کاربر: ثبتنام و احراز هویت امن باید برای کاربران ساده و سریع باشد.
تطبیق بلادرنگ راننده و مسافر: کاربران باید بتوانند در لحظه به رانندگان اطراف متصل شوند، بر اساس موقعیت، نوع خودرو و در دسترس بودن راننده.
پرداخت امن: تراکنشهای مالی باید از طریق درگاههای پرداخت امن و روشهای رمزنگاری قوی انجام شوند.
شخصیسازی مبتنی بر هوش مصنوعی: اوبر با استفاده از الگوریتمهای هوش مصنوعی، تجربه کاربران را شخصیسازی میکند (مانند پیشنهاد مبدا/مقصدهای پرتکرار با توجه به دادههای گذشته و شرایط لحظهای).
۲.۲. نیازمندیهای غیرعملکردی (Non-Functional Requirements)
پوشش جهانی: سیستم باید بتواند در مناطق مختلف جغرافیایی خدمات ارائه دهد.
تأخیر پایین (Low Latency): سیستم باید در شرایط اوج ترافیک، تأخیر را به حداقل رسانده و پخش فوری موسیقی بعد از انتخاب کاربر، دریافت سریع نتایج جستجو، و تعامل روان با رابط کاربری حیاتی است.
دسترسیپذیری بالا (High Availability): کاربران باید بدون وقفه به امکاناتی مثل استریم موسیقی، جستجو و سایر قابلیتها دسترسی داشته باشند. راهکارهای Failover برای تضمین ارائه خدمات بدون قطعی پیادهسازی شود.
پایداری بالا و سازگاری دادهها (High Reliability & Consistency): سیستم باید توانایی مقابله با ورودیهای نامعتبر، مشکلات شبکه، خرابی سرور و رفتارهای غیرمنتظره از سمت کلاینت را داشته باشد. اصل CAP (Consistency, Availability, Partition Tolerance) میگوید یک سیستم توزیعشده نمیتواند همزمان هم بسیار در دسترس و هم کاملاً سازگار باشد — اما در واقع، همه اجزای سیستم نیاز نیست که همزمان این دو ویژگی را داشته باشند — برخی اجزا باید سازگار باشند (مثل اطلاعات پرداخت)، و برخی دیگر باید در دسترس باشند (مثل موقعیت راننده).
مقیاسپذیری (Scalability): سیستم باید بتواند صدها میلیون کاربر جهانی و میلیونها استریم همزمان را پشتیبانی کند. زیرساخت باید توانایی پذیرش افزایش ترافیک را بدون کاهش کیفیت عملکرد داشته باشد.
امنیت (Security): پیادهسازی پروتکلهای احراز هویت، رمزنگاری و محافظت از اطلاعات کاربران الزامی است.
تطابق با مقررات (Compliance): سیستم باید مطابق با مقررات حفاظت از داده (مثل GDPR) عمل کرده و حفظ حریم خصوصی کاربران را تضمین کند.
۲.۳. اهداف بازنویسی برنامه اوبر
افزایش دسترسیپذیری تجربه اصلی کاربر (core rider experience).
فراهم کردن امکان آزمایشهای گسترده روی مسیرهای مشخص.
۲.۴. برآورد ظرفیت (Capacity Estimation)
با فرض ۵ میلیون کاربر فعال و ۲۰۰,۰۰۰ راننده و متوسط روزانه ۱ میلیون سفر:
درخواستها در ثانیه: اگر هر کاربر به طور متوسط ۵ عمل در اپلیکیشن انجام دهد، مجموعاً روزانه ۵ میلیون درخواست پردازش میشود که معادل تقریباً ۵۸ درخواست در ثانیه است.
نیاز به فضای ذخیرهسازی: اگر هر پیام حدود ۵۰۰ بایت حجم داشته باشد، روزانه به حدود ۲.۳۲ گیگابایت فضا نیاز داریم.
۳. معماری کلان (High-Level Design)
معماری اوبر از میکروسرویسهای متعددی تشکیل شده است که هر کدام وظیفه خاصی را بر عهده دارند. این سرویسها از طریق لود بالانسر (Load Balancer - LB) و Web Application Firewall (WAF) به یکدیگر و به کلاینتها (اپهای کاربر و راننده) متصل میشوند. تصویر کلی معماری اوبر نشاندهنده تعامل بین سرویسهای اصلی مانند Customer Services، Driver Services، Payment Services، Notification Services و DataBases است. سیستمهای تحلیل و مقابله با گلوگاهها (Analytics و Bottleneck Conditions) نیز از اجزای مهم این معماری هستند.

۴. اجزای کلیدی سیستم و نحوه تعامل آنها
۴.۱. Map Service و Segmentها:
اوبر برای تعیین موقعیت مکانی و یافتن رانندههای اطراف، از مفهومی به نام Segment استفاده میکند. یک Segment یک ناحیه مستطیلی روی نقشه است. کل یک شهر را میتوان به چندین Segment تقسیم کرد و موقعیت تاکسیها و کاربران در این Segmentها مشخص میشود.
از آنجا که تاکسیها دائماً در حرکت هستند، اطلاعات موقعیت مکانی آنها به صورت لحظهای دریافت و توسط Map Service مدیریت میشود. Map Service وظیفه نگاشت و مدیریت Segmentها برای کاربران و رانندهها را بر عهده دارد و همچنین ETA و مسیر رسیدن را محاسبه میکند.
در مناطق پرتراکم، Map Service Segmentها را به بخشهای کوچکتر تقسیم میکند و در مقابل، Segmentهای کمتراکم را با هم ادغام میکند تا مدیریت بهینهتر باشد.
اوبر برای تقسیم نقشهها به سلولهای کوچک، از کتابخانه Google S2 استفاده میکند. این سلولها (مثلاً به اندازه ۳ کیلومتر) شناسه منحصربهفرد دارند و به راحتی در سیستم توزیع شده مدیریت میشوند.
اوبر در گذشته از Mapbox استفاده میکرد اما بعدها به Google Maps API مهاجرت کرد.

۴.۲. تعامل کاربران و رانندگان (User/Driver App, Services, WebSocket):
اپلیکیشن کاربر (User App) و User Service: کاربران از طریق User App با سیستم در ارتباط هستند. این اپ به User Service متصل میشود که مخزن اطلاعات مربوط به کاربران است و از طریق APIها امکان دریافت و بهروزرسانی اطلاعات را فراهم میکند. این سرویس روی یک پایگاه داده MySQL-based User DB قرار دارد و اطلاعات را در Redis نیز cache میکند.
اپلیکیشن راننده (Driver App) و Driver Service: رانندهها از طریق Driver App به سیستم وصل میشوند. Driver App به Driver Service متصل است که معادل User Service برای رانندگان است. این سرویس نیز روی پایگاه داده MySQL-based Driver DB قرار دارد و اطلاعات را در Redis cache میکند.
WebSocket Servers و Location Service: Driver App برای ارسال موقعیت لحظهای راننده، از طریق مجموعهای از WebSocket Servers با Location Service در ارتباط است. این سرویس، موقعیت راننده را دریافت کرده و هر چند ثانیه یکبار موقعیت را به Map Service میفرستد تا Segment راننده را مشخص کرده و نگاشت رانندهها به Segmentها را در Redis بهروزرسانی کند. Location Service همچنین اطلاعات موقعیت را در Cassandra ذخیره میکند و مسیر حرکت راننده را برای صورتحساب یا بررسی های آتی نگهداری میکند.
WebSocket Manager و WebSocket Handler: WebSocket Handlerها یک اتصال دائمی با رانندهها برقرار میکنند تا پینگهای موقعیت مکانی را دریافت کنند یا اعلانهای مربوط به سفرها را ارسال نمایند. این Handlerها به یک WebSocket Manager متصلاند که با استفاده از Redis پایش میکند کدام راننده به کدام Handler متصل است. Redis علاوه بر نگهداری اطلاعات اتصال رانندهها، یک نگاشت معکوس هم نگه میدارد تا مشخص شود هر راننده به کدام host متصل است.
۴.۳. Trip Service:
Trip Service مخزن تمام اطلاعات مرتبط با سفرهاست. این سرویس روی یک پایگاه داده MySQL Trips DB و یک Cassandra قرار دارد.
MySQL اطلاعات مربوط به سفرهایی که در شُرف شروع یا در حال انجام هستند را نگه میدارد.
زمانی که سفر به پایان میرسد، اطلاعات به Cassandra منتقل میشود. دلیل استفاده از دو نوع دیتابیس این است که اگر فقط از MySQL استفاده شود، حجم دادهها بسیار زیاد میشود. اطلاعات سفر فعال که نیاز به بهروزرسانی دارد در MySQL نگهداری میشود، اما پس از اتمام سفر، توسط یک Trip Archiver (یک Job زمانبندیشده) به Cassandra منتقل میشود. Trip Service همچنین APIهای مربوط به سفر را ارائه میدهد.
۴.۴. Cab Request Service و Cab Finder Service:
زمانی که کاربر میخواهد یک تاکسی رزرو کند، این فرآیند توسط Cab Request Service آغاز میشود. این سرویس برای رزرو تاکسی و دریافت اطلاعات مربوط به تاکسی رزروشده، با Cab Finder Service در ارتباط است. Cab Request Service درخواست سفر را با موقعیت مبدا و مقصد از اپلیکیشن مشتری دریافت میکند.
Cab Finder مختصات موقعیت مبدا کاربر را از Map Service دریافت میکند تا Segment آن نقطه و Segmentهای اطراف را بررسی کرده و رانندههایی که به مشتری نزدیکتر هستند را پیدا کند.
Cab Finder همچنین مفهوم "mode" را پیادهسازی میکند (مثلاً کاربر Premium یا کاربر معمولی). اطلاعات موردنیاز برای تشخیص راننده مناسب، از طریق ماژولی به نام Driver Priority Engine تأمین میشود که رانندهها را بر اساس نیاز آن mode رتبهبندی میکند.
پس از انتخاب مناسبترین راننده، Cab Finder به WebSocket Manager پیام میدهد تا راننده از طریق WebSocket Handler مربوطه از سفر مطلع شود. همزمان، کاربر نیز از طریق Cab Request Service مطلع میشود.
پس از اختصاص راننده، Cab Finder با Trip Service ارتباط میگیرد تا سفری جدید ثبت شود.
۴.۵. سیستم تطبیق راننده و مسافر (Dispatch System - DISCO):
اوبر برای تطبیق تقاضا (مسافران) و عرضه (رانندگان) از سیستمی به نام DISCO استفاده میکند که مصرف سوخت را کاهش، زمان انتظار را کمینه و ETA کلی را به حداقل میرساند.

سرویس عرضه (Supply Service): هر خودرو موقعیت مکانی خود را هر ۴ ثانیه به سرور ارسال میکند. اطلاعات از طریق Load Balancer و Web Application Firewall به سرور منتقل میشود. Kafka REST API به عنوان مرکز داده عمل میکند و دادهها را به حافظه، دیتابیس و DISCO منتقل میکند.
سرویس تقاضا (Demand Service): درخواست کاربر از طریق WebSocket ارسال میشود. مکان کاربر با GPS شناسایی شده و نیازهای او (مثلاً نوع خودرو) ثبت میشود.
الگوریتم تطبیق: شناسه سلول (Cell ID) به عنوان کلید Shard استفاده میشود. Consistent Hashing برای تقسیم مسئولیت بین سرورها انجام میشود. نزدیکترین رانندهها با در نظر گرفتن سیستم جادهای (نه صرفاً موقعیت جغرافیایی) از طریق ETA محاسبه و رتبهبندی میشوند. سیستم به سادگی با افزودن سرورهای جدید در شهرهای تازه توسعه مییابد.
۴.۶. ساخت نقشه و محاسبه ETA:
همانطور که گفته شد اوبر در گذشته از Mapbox استفاده میکرد اما بعدها به Google Maps API مهاجرت کرد.
Trace Coverage: تطابق مسیرهای GPS گذشته با جادهها برای شناسایی مسیرهای ناقص یا اشتباه.
Preferred Access Points: تعیین دقیقترین نقاط سوار شدن در مکانهای خاص (مثل فرودگاه) با استفاده از الگوریتمهای یادگیری ماشین.
محاسبه ETA: برای اوبر حیاتی است زیرا روی درآمد و تجربه کاربر تأثیر مستقیم دارد. از داده GPS رانندگان برای پیشبینی ترافیک استفاده میکند. شبکه جادهای به صورت گراف (تقاطعها نودها و مسیرها یالها) مدلسازی میشود. از الگوریتم Dijkstra یا OSRM برای محاسبه سریعترین مسیر استفاده میشود.
۴.۷. خدمات (Services):
Customer Service: اطلاعات و احراز هویت کاربران.
Driver Service: اطلاعات و احراز هویت رانندگان.
Payment Service: مدیریت پرداختها.
Notification Service: ارسال اعلانها.
۴.۸. سیستم Analytics و Machine Learning (Kafka, Spark, Hadoop, Michelangelo):
Kafka: به صورت مداوم در حال دریافت Eventهایی مانند موقعیت مکانی، رزرو شدن یا نشدن تاکسی، بهروزرسانیهای سفر و... است. Cab Finder نیز یک event در Kafka قرار میدهد تا ثبت کند که آیا رانندهای برای سفر پیدا شده یا نه، و از این اطلاعات برای تحلیلها استفاده میشود.
Payment Service (در Analytics): یک Payment Service بر روی Kafka قرار دارد که به Event تکمیل سفر گوش میدهد. به محض تکمیل سفر، بر اساس مسافت، زمان و غیره، مبلغ پرداختی محاسبه شده و در یک Payment MySQL DB ذخیره میشود. در صورتی که روش پرداخت نیاز به درگاه داشته باشد، این سرویس به یک Payment Gateway متصل میشود.
Spark Streaming Cluster و Hadoop Cluster: اسپارک Streaming Cluster Eventهای پایه (مثل "راننده پیدا نشد" ) را بررسی میکند و همه Eventها را در یک Hadoop Cluster ذخیره میکند تا تحلیلهای پیشرفتهتری انجام شود.
از این دادهها برای پروفایلینگ کاربر و راننده، رتبهبندی رانندهها و اجرای Fraud Engine (موتور کشف تقلب) استفاده میشود. همچنین برای بهدست آوردن اطلاعات ترافیکی و بهبود Map Service نیز کاربرد دارند.
اوبر ابزار اختصاصی خود با نام LIDAR (Ledger of Interactive Data Analysis) را توسعه داده است که ترکیبی از Jupyter Notebook با Apache Spark و پلتفرم داده داخلی اوبر است.
پلتفرم یادگیری ماشین Michelangelo: در سال ۲۰۱۵، اوبر پلتفرم یادگیری ماشین خود با نام Michelangelo را معرفی کرد. این پلتفرم جامع برای ML و AI، تمام مراحل چرخه ML را پوشش میدهد: مدیریت داده، آموزش مدل، ارزیابی، پیشبینی، استقرار مدل و مانیتور پیشبینیها. در سال ۲۰۲۵، Michelangelo وظایف پیشرفتهتری مانند مدلسازیهای Generative AI را نیز پشتیبانی میکند، از جمله پیشبینی تقاضا، قیمتگذاری پویا و تحلیل رفتاری کاربران و رانندگان.
لاگبرداری در Backend و پردازش آفلاین داده: سیستمهای Backend اوبر، تعاملات کاربر را ثبت و تحلیل میکنند. این دادهها سپس در فرآیندهای آفلاین پردازش شده و تبدیل به مدلهایی قابل استفاده برای تصمیمسازی و تحلیل رفتار کاربران میشوند.
تحلیل داده: از تحلیل اثر تخفیفها تا پیشبینی بازگشت سفرهای فرودگاهی، تحلیل داده در اوبر امکان پیشبینی تقاضا، تشخیص روندها و شخصیسازی خدمات را فراهم کرده است.
۴.۹. مقابله با خرابی مراکز داده:
در صورت خرابی مرکز داده اصلی، اوبر از گوشی راننده به عنوان منبع داده پشتیبان استفاده میکند. سیستم از طریق ارسال یک State Digest رمزنگاریشده به اپ راننده، اطلاعات سفر را حفظ میکند. مرکز پشتیبان از اپ راننده Digest را دریافت کرده و با آن بهروز میشود.
۵. قابلیت اطمینان (Reliability)
از دیدگاه مهندسی، اوبر تلاش میکند که تجربه اصلی سفر در اوبر با دسترسیپذیری ۹۹.۹۹% همراه باشد. این یعنی فقط یک ساعت خاموشی در کل سال، یا یک دقیقه در هفته. برای رسیدن به این هدف، معماری جدید یک چارچوب "core" و "optional" برای کد تعریف کرد.
کدهای Core: شامل تمام بخشهای حیاتی مانند ثبتنام، آغاز سفر، پایان سفر یا لغو آن هستند و باید همیشه اجرا شوند. این کدها تحت بازبینی شدید قرار میگیرند.
کدهای Optional: میتوانند بدون لطمه به عملکرد اصلی، غیرفعال شوند و بازبینی سبکتری دارند. این تفکیک باعث میشود ویژگیهای جدید تست شوند و در صورت مشکل، به سرعت غیرفعال شوند بدون اینکه تجربه سفر مختل شود.
۶. Riblets؛ معماری جدید اپ مسافر اوبر
معماری موبایلی اولیه اوبر بر پایه MVC (Model-View-Controller) بود. با رشد اپ و بزرگتر شدن تیم، MVC پاسخگو نبود. مشکلات اصلی شامل Controllerهای حجیم (که مسئول همهچیز بودند) و فرآیند آپدیت شکننده به دلیل استفاده از if-elseهای تو در تو برای آزمایش قابلیتهای جدید بود. الگوی VIPER به عنوان یک مسیر میانی، سطح انتزاع بیشتری ارائه میداد. اما VIPER نیز مشکلاتی داشت: ساختار iOS-محور آن برای Android کارایی کمتری داشت و تفکیک کامل بین منطق تجاری و نمایشی در آن سخت بود. اوبر برای حل این مشکلات، الگوی اختصاصی خود به نام Riblets را ابداع کرد.

ویژگیهای Riblets:
منطق به قطعات کوچک و تستپذیر تقسیم میشود.
هر Riblet تنها یک وظیفه دارد (اصل Single Responsibility).
ساختار اپ یک درخت از Ribletهاست.
تفاوت اصلی Riblets با VIPER در این است که در Riblets، رُوتینگ بر پایه منطق تجاری است، نه منطق نمایشی.
معماری جدید اوبر سازگار با هر دو پلتفرم iOS و Android طراحی شد تا توسعهدهندگان بتوانند بر بستر مشترک همکاری کنند.
اجزای Riblet و مسئولیتها:
Builder: ساختن Riblet و تعریف وابستگیها.
Component: فراهم کردن سرویسها و data streamهای مورد نیاز Interactor.
Router: متصل و جدا کردن Ribletهای فرزند؛ فعال/غیرفعالسازی Interactor.
Interactor: اجرای منطق تجاری مانند درخواست سفر یا واکشی داده. مالک وضعیت (state) و منطق تجاری مربوط به محدودهی خودش است. درخواستهایی به سرویسها میفرستد تا داده دریافت کند.
Presenter: ترجمه داده بین Interactor و View.
View (Controller): نمایش UI، تعامل با کاربر، دریافت ورودی و نمایش داده.
جریان داده درون یک Riblet:
دادهها فقط در یک جهت حرکت میکنند: Service → Model Stream → Interactor. مدلها Immutable (تغییرناپذیر) هستند. یعنی Interactor باید برای اعمال تغییرات، فقط از طریق لایه سرویس اقدام کند.
از Backend به View: داده وضعیت سفر از سرویس دریافت میشود، روی مدل استریم قرار میگیرد، Interactor آن را دریافت کرده و به Presenter ارسال میکند، سپس Presenter آن را برای View قالببندی میکند.
از View به Backend: کاربر روی دکمهای کلیک میکند. View این رویداد را به Presenter میدهد، Presenter متد مربوطه را روی Interactor فراخوانی میکند، و در نهایت Interactor یک درخواست به سرویس ارسال میکند.

ارتباط بین Ribletها:
هنگامی که یک Interactor تصمیم تجاری میگیرد، ممکن است نیاز داشته باشد دادهای را به Riblet دیگر ارسال کند یا رویدادی را اطلاع دهد. برای این کار، Interactor تصمیمگیرنده یک interface را فراخوانی میکند که توسط Interactor Riblet مقصد پیادهسازی شده است.
به سمت بالا (parent): از listener استفاده میشود (تقریباً همیشه توسط والد پیادهسازی میشود).
به سمت پایین (child): از delegate استفاده میشود (توسط فرزند پیادهسازی میشود و معمولاً برای ارتباط مستقیم و همزمان است). راهحل بهتر برای ارتباط به سمت پایین، استفاده از observable stream است. والد میتواند یک stream را به فرزند بدهد تا اطلاعات را دریافت کند. این روش توصیهشده برای ارسال داده از والد به فرزند است.
دستاوردها با Riblets:
افزایش دسترسیپذیری تجربه اصلی: Ribletها وظایف تفکیکشده و مشخصی دارند، بنابراین تست آنها آسانتر است. هر Riblet به صورت مستقل تست میشود که اطمینان بیشتری در بهروزرسانی و پایداری برنامه فراهم میکند. جداسازی Ribletهای حیاتی از کد اختیاری، امکان بازبینی سختگیرانهتری را برای بخشهای حیاتی فراهم کرد. همچنین، قابلیت rollback سراسری به وضعیت پایدار برای جریان اصلی فراهم شد. همه کدهای optional تحت feature flag هستند و در صورت مشکل، به راحتی میتوان آنها را غیرفعال کرد و تنها به core flow برگشت.
بستر مناسب برای توسعه آینده: Ribletها امکان جداسازی روشن منطق تجاری و نمایشی را فراهم کردند. معماری جدید platform-agnostic است که به توسعهدهندگان iOS و Android کمک میکند از اشتباهات یکدیگر درس بگیرند و راحتتر همکاری کنند. تست و پیادهسازی قابلیتهای جدید سادهتر شده است، زیرا میتوان آنها را به صورت plugin در قالب Ribletهای اختیاری اضافه کرد. این ساختار باعث میشود توسعه برنامه در سالهای آینده نیز ساده بماند.
۷. مدیریت و ذخیرهسازی دادهها
اوبر از مجموعه متنوعی از پایگاههای داده برای مدیریت حجم عظیم دادههای خود استفاده میکند. در ابتدا از PostgreSQL استفاده میکرد اما به دلیل مشکلات مقیاسپذیری به ترکیبی از دیتابیسها مهاجرت کرد.
MySQL: برای تراکنشهای آنلاین با ساختار رابطهای. همچنین برای User DB، Driver DB و Trips DB (برای سفرهای فعال) استفاده میشود.
Cassandra: برای اپلیکیشنهای RealTime (NoSQL توزیعشده). برای ذخیره اطلاعات موقعیت راننده و همچنین برای آرشیو سفرهای کاملشده.
Redis: برای کشینگ توزیعشده و همچنین برای کش اطلاعات User Service، Driver Service، و پایش اتصال رانندهها به WebSocket Handlerها.
HDFS (Hadoop Distributed File System): برای ذخیره آفلاین دادههای حجیم.
AWS, Google Cloud, Azure: به عنوان ذخیرهسازی ابری.
Hive: برای تحلیل دادههای کلان در سطح سازمانی.
آمادهسازی زیرساخت (Infrastructure Provisioning): اوبر از Terraform برای مدیریت Infrastructure as Code (IaC) استفاده میکند که فرآیند استقرار را تسریع و خطای انسانی را کاهش میدهد.
ساخت تصاویر کانتینری (Container Images): اوبر از ابزار اختصاصی uBuild (معرفیشده در سال ۲۰۱۵) برای ساخت تصاویر کانتینری امن، سازگار و بهینهشده استفاده میکند.
بهینهسازی عملکرد پایگاه داده با CacheFront:
Docstore، پایگاه داده توزیعشده اوبر، توان پردازش دهها میلیون درخواست در ثانیه را دارد. برای بهبود تأخیر (Latency) و کاهش هزینه، CacheFront طراحی شد که مکانیزم کش را در لایه کوئری پایگاه داده Docstore ادغام میکند.
CacheFront از تکنیکهایی مانند Timeout تطبیقی، Negative Caching، Cache Warming و ابزار Redis به عنوان کش توزیعشده استفاده میکند.
به لطف CacheFront، نرخ Cache Hit در اوبر به ۹۹.۹٪ رسیده و بیش از ۴۰ میلیون درخواست در ثانیه بدون فشار بر موتور ذخیرهسازی پردازش میشود.
۸. امنیت دادهها
حفظ امنیت داده کاربران، یکی از اولویتهای اصلی اوبر است. رویکرد امنیتی اوبر بر پایهی رمزنگاری دقیق (Fine-Grained Encryption) بنا شده و شامل کنترل دسترسی دقیق، سیاستهای نگهداری داده و رمزنگاری در حالت سکون (At Rest) است. اوبر همچنین از سیستمهای شناسایی تهدید مبتنی بر هوش مصنوعی برای کشف و خنثیسازی تهدیدات احتمالی بهصورت بلادرنگ استفاده میکند.
کنترل دسترسی دقیق (Fine-Grained Access Control): اوبر از رویکرد ستونمحور برای کنترل دسترسی استفاده میکند و دسترسی را تا سطح هر ستون تعیین میکند. از ویژگیهای Apache Parquet برای اعمال محدودیتهای دسترسی بر اساس برچسبهای تعریفشده استفاده میکند.
رمزنگاری در حالت سکون (Encryption at Rest): برای جلوگیری از دسترسی غیرمجاز، اوبر از رمزنگاری سطح ستون با استفاده از الگوریتمهایی مثل AES-GCM و AES-CTR بهره میبرد.
سیاستهای نگهداری داده (Data Retention Policies): اوبر از سیاستهای نگهداری پویا و انعطافپذیر استفاده میکند که امکان حذف انتخابی دادهها بر اساس دستهبندیها یا برچسبها را فراهم میکند.
توصیههای امنیتی برای کاربران: اوبر پیشنهاد میکند کاربران رمز عبور خود را به صورت دورهای تغییر دهند، اطلاعات تماس خود را بهروز نگه دارند، از بهاشتراکگذاری اطلاعات ورود پرهیز کنند و از رمزهای متفاوت برای حسابها استفاده نمایند.
۹. بهرهبرداری از داده کاربران برای تصمیمسازی هوشمند
داده کاربران موتور محرکه صنعت حملونقل اشتراکی است. این دادهها برای بهینهسازی نرخ تبدیل، شخصیسازی تجربه کاربر، تحلیل رفتار کاربران و طراحی راهکارهای ارتباطی هدفمند مورد استفاده قرار میگیرند.

استانداردسازی لاگها (Logs): فرآیند ثبت لاگها در اپلیکیشن موبایل، طبق استانداردهای سختگیرانهای انجام میشود تا ثبات بین پلتفرمها، رعایت حریم خصوصی و بهینهسازی مصرف شبکه تضمین شود.
۱۰. معماری کانال گفتوگو در اوبر (Chat Channel Architecture)
کانال چت اوبر، نمونهای از تعهد به کارایی عملیاتی و تجربه کاربری ممتاز است. در سال ۲۰۲۵، اوبر از چتباتهای مبتنی بر هوش مصنوعی برای پاسخگویی به سوالات متداول و کاهش زمان پاسخگویی استفاده میکند.

مراحل تحول:
پایهگذاری: راهاندازی چت با WebSocket برای پیامرسانی بلادرنگ.
تطبیقپذیری: بهرهگیری از Apache Kafka برای مقیاسپذیری.
بهینهسازی: استفاده از GraphQL Subscriptions و طراحی بدون وضعیت (Stateless) برای افزایش پایداری.
آیندهنگری: معماریهای هیبریدی و پایگاهدادههای Real-Time مانند Apache Cassandra برای پاسخدهی سریع و شخصیسازی.
۱۱. ساخت اجرایی (Runnable Artifact) و فعالسازی قابلیتها
برای توصیف کامل یک پیکربندی API در سیستم اوبر، فایلهای YAML و Thrift تمام اجزا را شامل میشوند. Self-served Gateway مسئول آن است که این پیکربندیها را کنار هم قرار دهد تا یک محیط اجرایی برای Gateway ایجاد کند.
۱۱.۱. دو نوع Gateway:
نوعی که پیکربندیها را به صورت داینامیک دریافت کرده و APIها را بر اساس آنها سرویس میدهد (مشابه ابزارهایی مانند Kong، Tyk یا reverse proxy هایی مثل Envoy و Nginx).
نوعی که با استفاده از code generation، یک artifact قابل اجرا (build) ایجاد میکند.
در اوبر، رویکرد دوم یعنی تولید کد (Code Generation) انتخاب شده است تا یک artifact اجرایی تولید شود.
۱۱.۲. مراحل Code Generation:
تولید اشیای schema: تمام فایلهای schema توسط پردازندههایی اجرا میشوند تا کد native در زبان Go برای thriftrw و protoc تولید شود. این کار برای serialization/deserialization و ایجاد رابطهای کلاینت مورد نیاز است.
تولید serialization اختصاصی: قراردادهای API با اپهای موبایل نیاز به serialization اختصاصی برای نوعهای خاصی مانند i64، enum و پروتکلهای مختلف دارند.
گراف وابستگیها (DAG): کدهای endpoint، کلاینتهای backend و middlewareها بهصورت static تولید میشوند. کلاینتها مستقلاند و میتوان بلافاصله تولیدشان کرد. Middleware ممکن است به صفر یا چند client وابسته باشد. Endpoint ها ممکن است به صفر یا چند middleware و حداکثر یک client وابسته باشند. این گراف جهتدار بدون حلقه (DAG) در زمان build حل میشود.
اتصال بین پروتکلها: چون کلاینتها مستقل از endpointها تولید میشوند، یک endpoint میتواند HTTP باشد ولی backend آن gRPC. این نگاشت در مرحلهی build انجام میشود.
تولید API: در این مرحله، گراف به ترتیب طی میشود تا تمام endpointها تولید شوند. برای هر endpoint قالب بارگذاری میشود، نگاشت بین درخواست endpoint و درخواست client (و بالعکس) تولید میشود، وابستگیها تزریق میشوند، و شیء IDL با تغییرات درخواست-پاسخ، hydrate میشود.
کل فرآیند Code Generation در یک کتابخانهی متنباز اوبر به نام Zanzibar کپسوله شده است.
۱۱.۳. چالشها و درسهای آموخته شده در توسعه Gateway:
زبان برنامهنویسی: نسل قبلی Gateway با Node.js ساخته شده بود که برای لایههای I/O سنگین مناسب بود. اما در اوبر، به دلیل هماهنگی با تیمهای داخلی، زبان Go انتخاب شد. اگرچه عملکرد بسیار خوبی داشت، ولی نبود Generics باعث شد حجم کد تولیدشده بالا برود، تا جایی که به محدودیت linker در Go برخورد کردند و مجبور شدند symbol table و اطلاعات debug را غیرفعال کنند. برخی قوانین نامگذاری در Go با Thrift ناسازگار بود که خطاهای عجیبی ایجاد میکرد.
فرمت serialization: مدیر پروتکل در Gateway از چندین پروتکل پشتیبانی میکند. این موضوع باعث ایجاد ناسازگاریهایی میان JSON و Thrift در نگاشت Union، Set، List و Map شد. برای حل این مشکل، استانداردهای داخلی خاصی توسعه داده شد.
پیکربندی پویا (Config Store): پیشتر، همه پیکربندیها در Git نگهداری میشد، حتی پیکربندیهای پویا مثل rate limit. این روش نیاز به Code Generation و Deploy داشت. اکنون بخشهای پویا در یک Config Store ذخیره میشوند تا بهروزرسانی سریعتر باشد.
UI Gateway و درک Payload: توسعه API تکی در UI آسان است، اما در حالت batch یا زمانی که Thriftها تو در تو باشند، دشوار میشود. جداسازی build system از UI نیز نمایش خطاها را سخت میکند، پس حفظ قرارداد بین این دو حیاتی است. در برخی کاربردها نیاز به deserialize کردن payload وجود دارد که پیچیدگی سیستم build و بار اجرایی را افزایش میدهد. اگر پروتکل frontend و backend یکسان باشند، بهتر است فقط به header و verbها دسترسی داشته باشیم.
۱۲. بهبود تجربه و ارتباط راننده و مسافر
نمایش مقصد سفر به راننده پیش از قبول کردن سفر.
اجرای طرحهای تشویقی جدید برای پاداش به رانندگانی که تلاش بیشتری میکنند.
تعامل فعال با رانندگان برای کاهش لغو سفرهای پذیرفتهشده و ایجاد مشوقهایی برای حفظ کیفیت خدمات.
تلاش برای پاسخگویی سریع به وقایع غیرمنتظره، بهمنظور تضمین کیفیت بالا در تمام لحظات سفر.
۱۳. تستهای داخلی پیشنهادشده توسط تیم اوبر
اوبر برای اطمینان از عملکرد صحیح سیستم، تستهای زیر را انجام میدهد:
تست Functional (رزرو، لغو، پرداخت).
تست بار و عملکرد (ترافیک بالا، Kafka، موقعیت GPS).
تست یکپارچگی سرویسها (Supply, Demand, Dispatch و Kafka).
تست تحمل خطا و بازیابی (خرابی مرکز داده، بازیابی Digest).
تست مکانیابی و الگوریتمهای Dispatch (با S2 و OSRM).
تست امنیتی (رمزنگاری، احراز هویت، API).
تست تحلیل داده (Kafka، Hadoop، ElasticSearch).
۱۴. مدل سطح بالای دیتا

معماری سیستم اوبر نمونهای از مهندسی نوآورانه است که یکی از بزرگترین سیستمهای حملونقل اشتراکی جهان را پشتیبانی میکند. این سیستم از یک معماری مونولیتیک اولیه به میکروسرویسها و سپس به معماری دامنهمحور (DOMA) تحول یافته است تا مقیاسپذیری، پایداری و انعطافپذیری لازم را برای سرویسدهی به میلیونها کاربر فراهم کند. اوبر با بهرهگیری از تکنولوژی هایی مانند Node.js, React.js, GraphQL, Mapbox, Hadoop, Apache Spark, CacheFront, Docstore, Cassandra, Redis و پلتفرم هوش مصنوعی Michelangelo، توانسته تجربهای یکپارچه، پایدار، مقیاسپذیر و کاربرپسند در همهی پلتفرمها ایجاد کند. معماری دامنهمحور (DOMA) و یکپارچگی تحلیلی با دادههای کلان، نهتنها کیفیت خدمات اوبر را تضمین کرده، بلکه به الگویی برای سایر شرکتهای فناورانه تبدیل شده است.

این مطلب، بخشی از تمرین های درس معماری نرمافزار در دانشگاه شهیدبهشتی است.
https://netflixtechblog.com/introducing-impressions-at-netflix-e2b67c88c9fb
https://dev.to/gbengelebs/netflix-system-design-backend-architecture-10i3
https://medium.com/@narengowda/netflix-system-design-dbec30fede8d
https://netflixtechblog.com/ready-for-changes-with-hexagonal-architecture-b315ec967749
https://blog.bytebytego.com/p/a-brief-history-of-scaling-netflix
https://dev.to/gbengelebs/netflix-system-design-how-netflix-onboards-new-content-2dlb
https://netflixtechblog.com/title-launch-observability-at-netflix-scale-8efe69ebd653
https://www.devlane.com/blog/spotify-a-deep-dive-into-their-tech-stack
https://engineering.atspotify.com/2022/07/software-visualization-challenge-accepted
https://www.designgurus.io/answers/detail/discuss-spotify-system-architecture
https://backstage.spotify.com/learn/backstage-for-all/architecture-and-technology
https://ujjwalbhardwaj.me/post/system-design-design-spotify-music-streaming-platform/
https://medium.com/@ishwarya1011.hidkimath/system-design-music-streaming-services-64df330b5624
https://www.codekarle.com/system-design/Uber-system-design.html
https://www.uber.com/en-GB/blog/architecture-api-gateway/
https://www.uber.com/en-FR/blog/new-rider-app-architecture/
https://intellisoft.io/the-foundation-of-uber-the-tech-stack-and-software-architecture/
https://www.clickittech.com/software-development/system-design-uber/
https://www.geeksforgeeks.org/system-design/system-design-of-uber-app-uber-system-architecture/