منبع اصلی این پست، دوره آمار و احتمال مهندسی دکتر علی شریفی زارچی از آکادمی مکتبخونه میباشد. لطفاً برای حفظ حقوق منتشر کننده اصلی، ویدیوهارو از منبع اصلی دنبال کنید. همچنین، در انتهای هر جلسه، به ویدیو مربوط به آن جلسه ارجاع داده شده است.

سعی کردم هرچیزی که از ویدیوها فهمیدم رو به صورت متن در بیارم و در این پلتفورم با بقیه به اشتراک بذارم. کل ویدیوها 27 تاست که سعی میکنم هفتهای یک الی دو جلسه رو منتشر کنم. تا جایی که تونستم سعی کردم خوب و کامل بنویسم، اما اگر جایی ایرادی داشت، حتما تو کامنتها بهم بگید تا درستش کنم.
پیشنهاد میکنم قبل از خوندن ادامه مطلب، یک کاغذ و قلم جلو دستتون باشه تا بتونید روابط ارائه شده رو در جاهایی که لازم هست برای خودتون تو کاغذ بنویسید و محاسبات لازم رو خودتون هم انجام بدین تا بهتر متوجه بشید که در هر مرحله چه اتفاقی میفته.
سوالی ذهن آقای مارکف رو مشغول کرده بود با این مضمون:
"اگر میانگین طول عمر آدمها 60 سال باشه، چقدر احتمال داره که یک آدمی بیشتر از 300 سال عمر کنه؟"
در ادامه قراره این سوال رو با جزییات بیشتری بررسی کنیم و یه جوابی هم براش پیدا کنیم.
فرض کنید یک توزیع ناشناختهای داریم که هیچی ازش نمیدونیم. فقط میانگینش رو بهمون دادن و میدونیم که هر متغیر تصادفی که از این توزیع میاد قطعاً مثبته. عدد مثبتی هم مثل a وجود داره. میخوایم ببینیم که چقدر احتمال داره که P(X ⩾ a) باشه؟
حالا با توجه به سوالی که مطرح شد، داریم a=300 و E(X)=60 و دنبال محاسبه احتمال P(X ⩾ 300) هستیم. چون توزیع رو نمیدونیم، نمیتونیم این احتمال رو دقیق محاسبه کنیم، ولی میتونیم براش یک حد بالا به دست بیاریم. از قبل میدونیم که این حد بالا از 1 کمتره، ولی میخوایم حد بالاتر دقیقتری براش پیدا کنیم. حالا، چرا حد پایین براش پیدا نمیکنیم؟ از اونجایی که a از میانگین بزرگتره، ممکنه توزیعمون تو a صفر باشه، ما که نمیدونیم چه توزیعی داریم، برای همین نمیشه حد پایینی جز صفر رو در نظر گرفت.
از اونجایی که دنبال محاسبه احتمال P(X ⩾ a) هستیم، میتونیم بیایم به کمک رابطه E(X) بهش برسیم. چون X همواره مثبته برای همین بازه انتگرال رو میتونیم از 0 تا مثبت بینهایت در نظر بگیریم و چون دنبال P(X ⩾ a) هستیم میتونیم انتگرال رو بشکنیم به دو تا بازه:
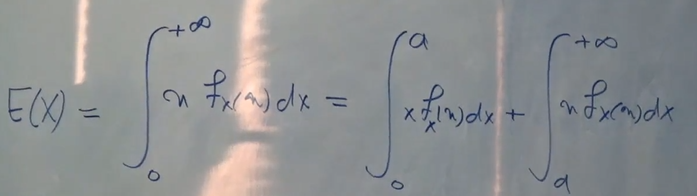
انتگرالی که بازه 0 تا a داره رو میدونیم که همواره مثبته. میتونیم حذفش کنیم و داشته باشیم:
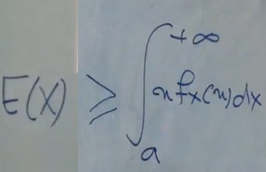
با توجه به بازه انتگرال x همیشه بزرگتر یا مساوی a هست برای همین میتونیم انتگرال رو به صورت زیر بنویسیم:
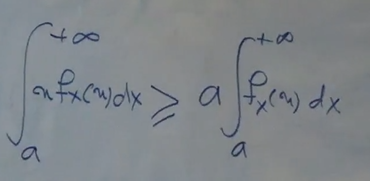
انتگرال بالا هم برابر هست با P(X ⩾ a) پس در نهایت داریم:
E(X) ⩾ a P(X ⩾ a) P(X ⩾ a) ⩽ E(X) / a
به نابرابری به دست اومده نابرابری مارکف گفته میشه.
طبق صورت مسئلهای که داشتیم اگر یک انسانی بخواد بیشتر از 300 سال عمر کنه احتمالش هیچوقت از 0.2 بیشتر نمیشه:
P(X ⩾ 300) ⩽ 60 / 300 P(X ⩾ 300) ⩽ 0.2
اگر در مسئله داده شده به جز اطلاعات در مورد میانگین در مورد واریانس هم بهمون اطلاعاتی میدادن، اون موقع محاسباتمون چطور میتونست پیش بره؟ آیا ممکن بود حد بالایی که به دست میاریم دقیقتر بشه؟
فرض کنید تو همون مسئله سن آدمها انحراف از معیار رو هم بهمون داده باشن و برابر با 10 باشه، با این حساب واریانس میشه 100.
یعنی همچنان هیچ اطلاعاتی در مورد توزیع نداریم و فقط میدونیم میانگین 60 عه و واریانس 100. الان اگر بخوایم حد بالا رو محاسبه کنیم به چه عددی میرسیم؟ نابرابری چبیشف قراره این رو بررسی کنه.
تو نابرابری مارکف به رابطه زیر رسیدیم:
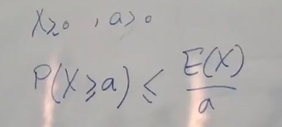
فرض کنید یه متغیر Y و یک متغیر b داریم که به صورت زیر تعریف میشن:
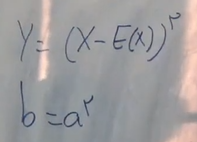
حالا طبق نابرابری مارکف برای Y و b داریم:
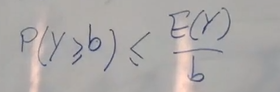
بعد از جایگذاری مقادیر، رابطه به صورت زیر در میاد:
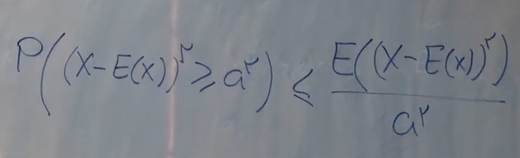
حالا، عبارت سمت چپ برابر هست با:
P(|X - E(X)| > a)
عبارت سمت راست هم که تعریف واریانس تقسیم بر a^2 عه، پس در نهایت داریم:
P(|X - E(X)| > a) ⩽ Var(X) / a^2
به این نابرابری، نابرابری چبیشف گفته میشه.
حالا برگردیم به مسئلهای که داشتیم و مقادیر رو جایگذاری کنیم:
P(|X - E(X)| > a) ⩽ Var(X) / a^2 P(|X - 60| > 240) ⩽ 100 / 240 * 240 P(|X - 60| > 240) ⩽ 0.0017
همونطور که واضحه، حد بالایی که با این نابرابری به دست میاد خیلی دقیقتره نسبت به نابرابری مارکف. جوابی که به دست اومده به این معنیه که احتمال اینکه یک نفر بیشتر از 300 سال عمر کنه، از 0.0017 کمتره.
ایرادی که به این نابرابری وارده اینکه P(|X - E(X)| > a) داره دو طرفه تخمین زده میشه. مثالی که اول جلسه زدیم رو به یاد دارید؟ اگر به جای اینکه دنبال P(X ⩾ 300) میبودیم، دنبال احتمال P(X ⩾ 90) بودیم، جواب نامساوی چبیشف چی میشد؟
به کمک نابرابری چبیشف نمیتونستیم برای این سوال جوابی پیدا کنیم. چرا؟ چون تو این حالت نابرابری به صورت زیر در میاد:
P(|X - 60| > 30) = P(X > 90 or X < 30)
حالا ایراد جواب به دست اومده چیه؟ ایراد اینکه ما صرفاً دنبال پیدا کردن احتمال P(X ⩾ 90) هستیم، ولی الان احتمال P(X ⩾ 30) هم قاطیش شده. حالا تکلیف چیه؟ تو این مواقع چه کنیم؟ میایم از یک نابرابری دیگه استفاده میکنیم!
دنبال پیدا کردن احتمال P(X ⩾ a) هستیم. میایم به طرفین یه b اضافه میکنیم و به توان دو میرسونیم و داریم:
X ⩾ a ≡ X + b ⩾ a + b ≡ (X + b)^2 ⩾ (a + b)^2 P(X ⩾ a) ≡ P(X + b ⩾ a + b) ≡ P((X + b)^2 ⩾ (a + b)^2)
حالا از نابرابری مارکف استفاده میکنیم برای رابطهای که به دست آوردیم و داریم:
P((X + b)^2 ⩾ (a + b)^2) ⩽ E((X + b)^2) / ((a + b)^2) P(X ⩾ a) ⩽ E((X + b)^2) / ((a + b)^2)
قبل از ادامه مراحل بیایم اول رابطه زیر رو باز کنیم ببینیم برابر با چیه:
E((X + b)^2) = E(X^2 + b^2 + 2bX) = E(X^2) + b^2 + 2bE(X)
حالا اگر فرض کنیم میانگین X برابر با 0 باشه داریم:
E((X + b)^2) = E(X^2 + b^2 + 2bX) = E(X^2) + b^2 + 2bE(X) = Var(X) + b^2
در ادامه با توجه به اطلاعاتی که به دست آوردیم اگر نامساوی زیر رو باز کنیم خواهیم داشت:
P(X ⩾ a) ⩽ E((X + b)^2) / ((a + b)^2) ⩽ Var(X) + b^2 / (a + b)^2
حالا، اگر فرض کنیم مقدار b برابر باشه با Var(X) / a و این فرض رو به رابطه بالا تزریق کنیم داریم:
P(X ⩾ a) ⩽ Var(X) + b^2 / (a + b)^2 ⩽ (Var(X) + (Var(X)^2 / a^2)) / ((a + (Var(X) / a))^2)
در نهایت اگر روابط رو بنویسیم و ساده کنیم خواهیم داشت:
P(X ⩾ a) ⩽ Var(X) / (Var(X) + a^2)
پس چی شد؟ دو تا شرط داریم. اگر E(X) برابر با 0 باشه و a هم عددی مثبت باشه احتمال P(X ⩾ a) همواره از Var(X) / (Var(X) + a^2) کوچیکتر مساویه.
در ادامه میخوایم مثالی که اول جلسه زدیم رو با این نابرابری حل کنیم. فرض کرده بودیم که a=300 هست و میانگین 60 و واریانس 10. از اونجایی که تو این نابرابری میانگین باید برابر با 0 باشه پس یه متغیر جدید Y با میانگین صفر تعریف میکنیم و داریم:
Y = X - E(X) Y = X - 60
واریانس Y با واریانس X برابره و برابر 100 هست و اگر به جای X متغیر Y رو بذاریم خواهیم داشت:
P(X - E(X) ⩾ a - E(X)) ⩽ Var(X) / (Var(X) + (a - E(X))^2) P(X - 60 ⩾ 300 - 60) ⩽ 100 / (100 + 240 * 240) P(X ⩾ 300) ⩽ 0.0017
حالا یه سوال. یکم بالاتر تو این نابرابری فرض کردیم که مقدار b برابر هست با Var(X) / a. چرا اصلاً اینطور در نظر گرفتیم؟
در واقع میتونستیم به جای Var(X) / a هر عدد دیگهای در نظر بگیریم و به جواب میرسیدیم. ولی قضیه اینکه با در نظر گرفتن Var(X) / a میتونیم کوچیکترین حد بالا رو به دست بیاریم.
فرض کنید میخوایم میانگین قد ایرانیهارو محاسبه کنیم. چطوری به دست بیاریم این میانگین رو؟ بیایم قد 3 نفر رو اندازه بگیریم میانگین بگیریم، یا 10 نفر، یا 20 نفر؟
منطقیه که هر چقدر تعداد آدمها بیشتر باشه، جوابی که واسه میانگین به دست میاد جواب بهتریه. به عبارتی دیگه یعنی تخمین دقیقتریه از میانگین واقعی جمعیت.
حالا قانون اعداد بزرگ چیه؟ این قانون داره میگه که اگر بیای تعداد آدمهایی که داری قدشون رو محاسبه میکنی به بینهایت میل بدی، باعث میشه میانگینی که به دست میاری خیلی به میانگین واقعی قد آدمها نزدیک بشه، در نتیجه خطای حاصل (تفاوت بین میانگینی که به دست میاد با میانگین واقعی) به سمت صفر میل کنه. اگه بخوایم ریاضی توضیحات ارائه شده رو بنویسیم میشه رابطه زیر:
P(|((X1 + X2 + ... + Xn)/n) - µ| ⩾ error) → 0, if n → 0
چطور میشه این قانون رو اثبات کرد؟ به کمک نامساوی چبیشف. اثبات سادهای هم داره. اگر علاقهمند هستین که جزییات بیشتری در این خصوص بدونید، پیشنهاد میکنم که به دقیقه 56 از ویدیو این جلسه مراجعه کنید.
فرض کنید یک توزیع یکنواخت داریم با min=5 و max=10. میایم هر دفعه 10 تا سمپل رو از این توزیع بر میداریم و میانگین 10 تا سمپل رو حساب میکنیم. از اون طرف میانگین واقعی توزیع رو هم میدونیم که برابر هست با:
µ = (max+min) / 2
اگر بیایم 1000 بار این کار رو انجام بدیم و هر دفعه خطای بین میانگین واقعی و میانگین 10 تا نمونه رو محاسبه کنیم و در یک نمودار رسم کنیم خروجی به صورت زیر در میاد:
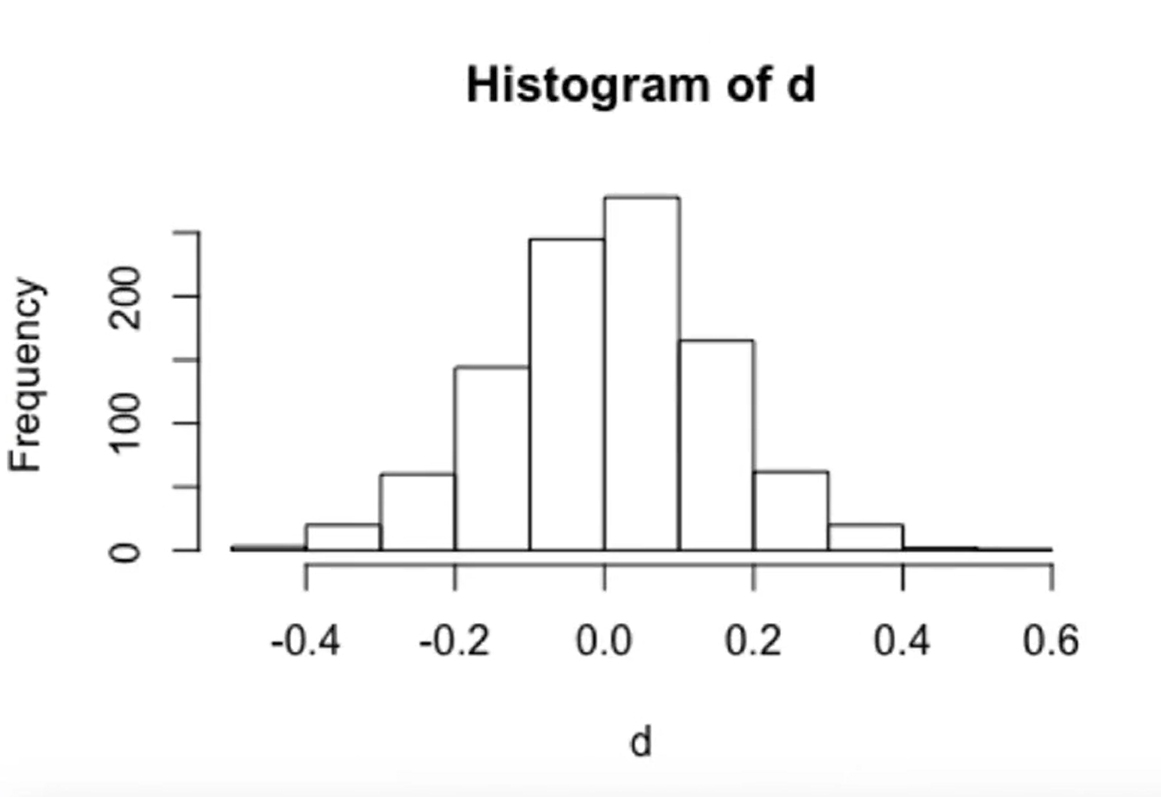
حالا اگر بیایم هر دفعه به جای 10 تا نمونه، 1000 تا نمونه برداریم و میانگین بگیریم و دوباره نمودار خطا رو رسم کنیم داریم:
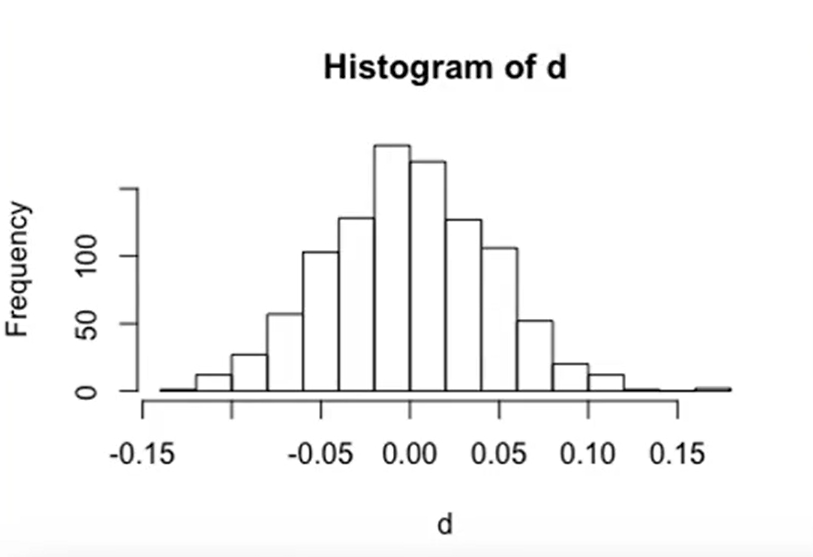
چه اتفاقی افتاد؟ تو نمودار اول بازه تغییرات خطا بین منفی 0.4 تا 0.6 بود. تو نمودار دوم بازه تغییرات خطا از منفی 0.15 هست تا 0.15. انگار که هرچقدر تعداد نمونههارو بیشتر میکنیم، خطای بین میانگین محاسبه شده با میانگین واقعی داره کم و کمتر میشه و اگر تعداد نمونهها به بینهایت برسه، این خطا برابر با 0 میشه.
با انواع نابرابری مثل نابرابری مارکف و نابرابری چبیشف آشنا شدیم. همچنین، قانون اعداد بزرگ رو بررسی کردیم و فهمیدیم که داره چیو نشون میده.
اگر جایی ایراد یا مشکلی بود، حتما بهم بگید تا تصحیحش کنم. همچنین، پیشنهاد میکنم که حتماً صفحه گیتهاب این دوره رو مورد بررسی قرار بدین. حتماً به دردتون میخوره.