
رپلیکیشن به کپی کردن پیوسته داده ها از یک دیتابیس (Primary/Master) به یک یا چند دیتابیس دیگه (Secondary/Slave/Replica) میگیم.
پیش از ادامه یه نکته ای بگم، رپلیکیشن شاید مبحث ساده و بدیهی به نظر بیاد اما وقتی بخوایم درست تعریفش کنیم و شرح بدیم اصطلاحات پراکنده زیادی هست توش که اکثرا هم معنا هستن و این به شدت گیج کننده است! دلیلش هم اینه که بعد از به کار بردن هر مدل رپلیکیشن، تازه تئوریزه اش کردن و هم اینکه هر اکوسیستم و شرکتی از اصطلاحات خاص خودش استفاده کرده.
تبدیل replica به primary رو میگیم promote کردن
دیتابیس replica ایی که نمیشه بهش کانکت شد و کوئری زد (read) تا زمانیکه promote بشه به primary میگن warm standby و به replica ایی که میشه کانکت شد و کوئری های read رو جواب میده میگن hot standby.
نکته: رپلیکیشن میتونه بهمون کمک کنه که read و write رو از هم تفکیک کنیم و بتونیم read رو اسکیل کنیم که این توی سیستم های read-heavy ایده خوبیه. ایده تفکیک مسئولیت خوندن و نوشتن ایده اصلی پترن CQRS هستش بنابراین رپلیکیشن ابزاریه که میتونیم برای پیاده سازی CQRS ازش استفاده کنیم.
High Availability
Fault Tolerance
Disaster Recovery
اگه دیتابیس primary از کار افتاد replica میتونه به عنوان جایگزین عمل کنه (Failover). اگه اتوماتیکش کنیم میشه Automatic failover.
بار خوندن / read رو بین چنتا سرور تقسیم می کنیم. رپلیکاها خوندن رو هندل می کنن و پرایمری هم میتونه نوشتن و هم خوندن رو هندل کنه. فشار روی پرایمری رو میتونیم کم کنیم اینطوری(فقط خوندن رو بدیم دستش) و latency رو کاهش بدیم.
رپلیکاها نزدیک محل جغرافیایی کاربران هر منطقه مستقر میشن و باعث کاهش latency میشه
علاوه بر اینکه خود رپلیکا میتونه به عنوان بکاپ استفاده بشه میتونه کمک کنه از دیتا بکاپ بگیریم بدون اینکه رو primary فشار بیاریم.
اگه بخوایم دیتابیس رو به یه دیتابیس دیگه یا ورژن جدیدتر منتقل کنیم میتونیم از رپلیکیشن استفاده کنیم
برای اینکه به سرور primary فشار نیاریم میتونیم رپلیکا بیاریم بالا و بدیم دست تیم توسعه
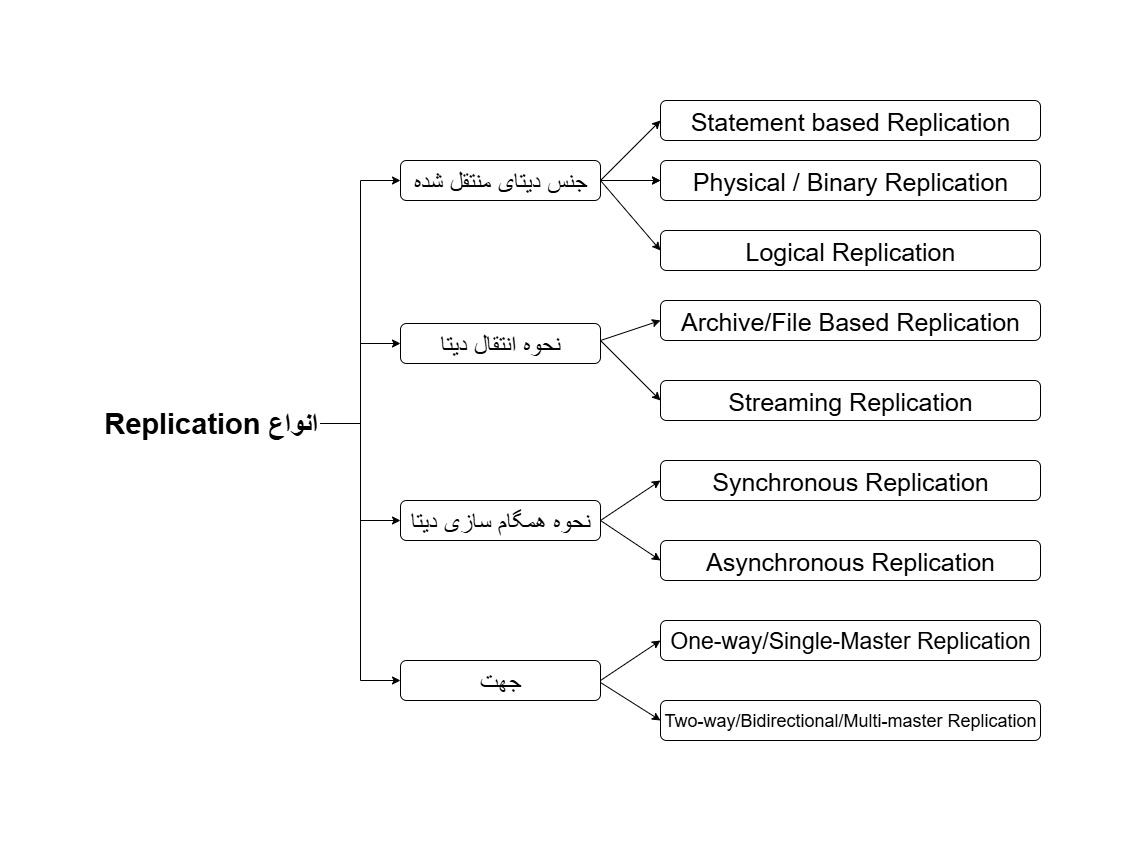
ینی عینا statement SQL به رپلیکا منتقل بشه. postgres از این پشتیبانی نمیکنه به صورت native.
عیب: روی شبکه میتونه فشار بیاره + دیتابیس رپلیکا هم دقیقا همون محاسبات و بهینه سازی های پرایمری رو مجبوره تکرار کنه خودش!
دیتابیس بایت به بایت رپلیکیت میشه به صورت باینری مثلا فلان بلاک از فلان جای دیسک رفت روی این بلاک.
عیب: اگه ورژن دیتابیس رپلیکا جدیدتر باشه نمیتونه بفهمه اون باینری توش چیه + مجبوریم کل دیتابیس رو رپلیکیت کنیم نمیتونیم یه جدول خاص رو فقط رپلیکیت کنیم
تغییرات منطقی row by row (رکورد به رکورد) منتقل میشن مثلا این رکورد به جدول فلان اضافه شد.
مزیت: امکان رپلیکت به ورژن جدید دیتابیس + امکان رپلیکیت یه جدول خاص به جای کل دیتابیس
فایل های WAL بعد از اینکه پر شدن آرشیو میشن و به سرور رپلیکا منتقل میشن و اونجا replay میشن
عیب: امکان ایجاد lag و اختلاف زیاد بین پرایمری و رپلیکا
فایل های WAL به رپلیکا استریم میشن به صورت real-time. (به جای اینکه وایسیم فایل پر بشه بعد کلش منتقل بشه)
دیتابیس پرایمری منتظر ack تک تک رپلیکاها میمونه و بعد پیام تایید commit رو به کلاینت برمیگردونه.
مزیت: اینجوری Strong consistency خواهیم داشت (ر.ک. CAP Theorem) و همه رپلیکاها با پرایمری سینک هستن
عیب: اگه شبکه کند باشه یا تعداد رپلیکاها بالا باشه این زمان انتظار latency رو بالا میبره
دیتابیس پرایمری منتظر ack دادن رپلیکاها نمیمونه و سریع پیام تایید commit رو میده به کلاینت. توی background هم یه سری تسک ران میشن که اون دیتا رو به صورت asycn روی رپلیکاها بنویسه.
یه حالت دیگه هم داره که میتونیم منتظر یه تعدادی از رپلیکاها باشیم مثلا دوتای اول ack دادن ما commit کنیم. میشه شبه-سنکرون (Semi-Asynchronous)
پستگرس به صورت پیش فرض asynchronous replication انجام میده!
مزیت: تاخیر/latency کم میشه
عیب: Strong consistency رو از دست میدیم و به Eventual Consistency راضی میشیم.
حالت دیفالت رپلیکیشن که در اون دیتا به صورت یک طرفه از پرایمری به رپلیکا منتقل میشه و برعکسش اتفاق نمی افته. توی این حالت پرایمری میتونه هم read و هم write انجام بده ولی رپلیکا فقط read انجام میده و تازه read-only هم میشه (نمیتونی تغییرش بدی چه دیتا چه اسکیما).
مزیت: پیاده سازی راحتی داره و باعث میشه بتونیم read رو scale بکنیم
عیب: اگه write-heavy باشیم ممکنه یه سرور کفاف نده
در این حالت بیشتر از یه primary/master خواهیم داشت و هر سرور هم primary و هم replica میشه ینی همه سرورا میتونن هم بنویسن و هم بخونن!
پستگرس به صورت native ازش پشتیبانی نمی کنه!
مزیت: تونستیم read/write رو اسکیل کنیم
عیب: پیاده سازیش به شدت پیچیده است چون در صورت نوشتن دیتای متفاوت توی دوتا سرور (ایجاد conflict) باید بیایم و conflict resolution انجام بدیم که کار بسیار سختی هست و به دردسرش نمی ارزه معمولا