
An index is an on-disk structure associated with a table or view that speeds retrieval of rows
from the table or view.
ایندکس یه ساختار داده(data structure) کمکی برای افزایش سرعت سرچ توی دیتابیسه. بدون ایندکس مجبوریم کل جدول رو اسکن کنیم (Full Table Scan) که برای جدولای بزرگ مثلا چند میلیون ردیف خیلی کند انجام میشه. در واقع مثل فهرست کتاب میمونه که میتونی بفهمی یه مطلب خاص توی کدوم صفحات هستش.
ایندکس باعث میشه سرعت خوندن از جدول بره بالا ولی overhead اش اینه که باعث کند شدن Insert/Update/Delete میشه چون باید ایندکس آپدیت بشه. اگه از ایندکس درست استفاده کنیم سرعت Where - Join - Order By - Group By افزایش پیدا می کنه.
استراتژی ایندکس برای افزایش سرعت یه چیزه! کوچیک کردن فضای جستجو یا search space. سریع ترین راه برای جستجو روی چند میلیون ردیف اینه که همه اون چند میلیون ردیف رو بررسی نکنیم صرفا فضای جستجو رو تا حد امکان کاهش بدیم.
مفهوم Heap و نحوه ذخیره جدول و ایندکس روی دیسک
یه ساختار داده است که دیتابیس با اون قالب روی دیسک مینویسه و نوشتنش هیچ ترتیب خاصی نداره. مشابه مفهوم heap - stack توی Memory که توی برنامه نویسی خصوصا C/C++ داریم، منتها اینجا ذخیره روی دیسکه و همچنین هیچ ربطی به heap توی ساختار داده و الگوریتم نداره.
شکل زیر یه شمای کلی از نحوه ذخیره جدولا روی دیسک و همچنین ایندکس ها میده:
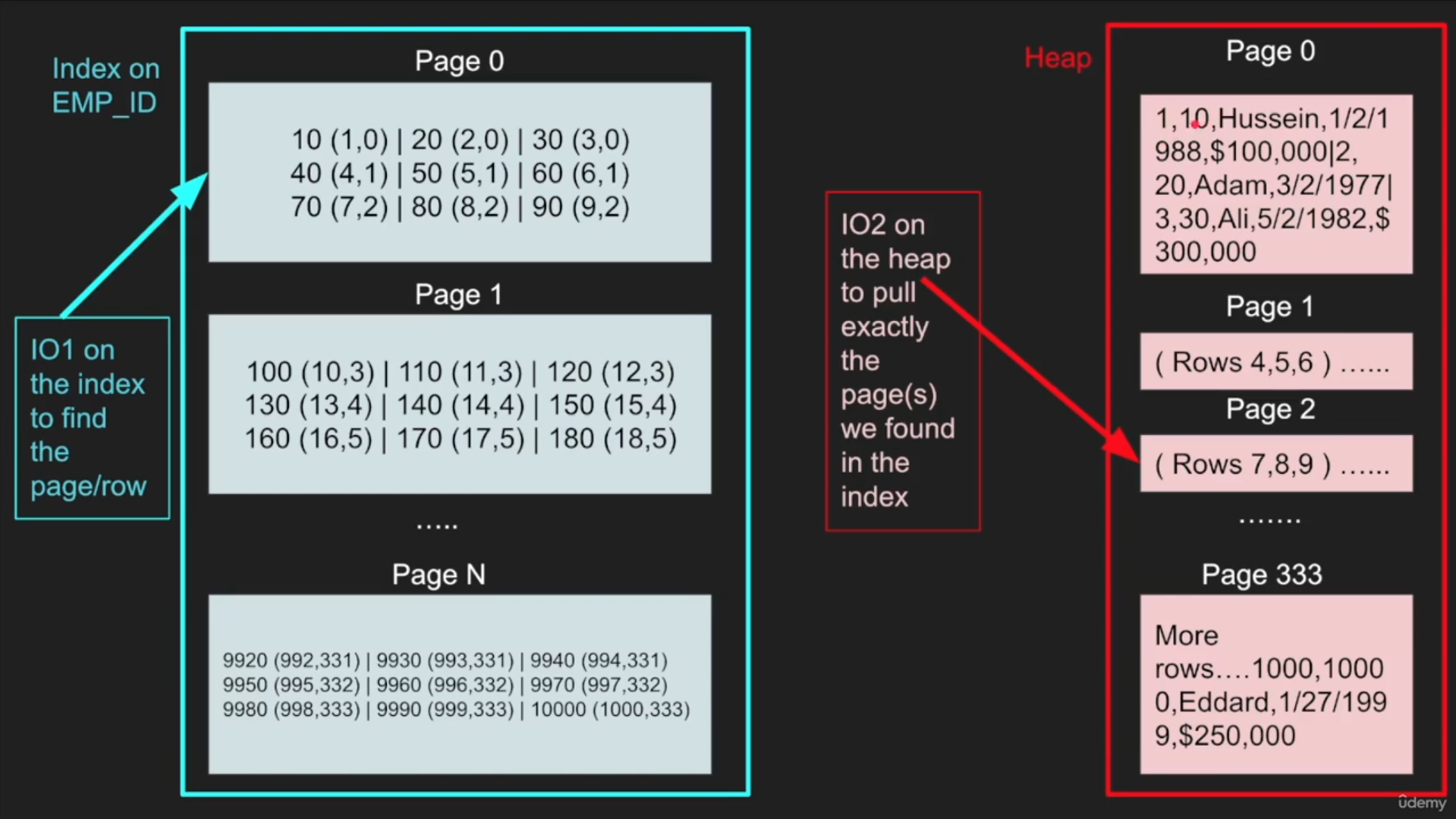
توضیح تصویر: اینجا مثلا هزارتا ردیف/row داریم و فرضا توی هر page (که میدونیم توی پستگرس یه فایل با سایز ثابت 8KB عه) 3 تا ردیف جا میشه (به صورت باینری نوشته میشه البته). دیتابیس به هر ردیف یه آیدی خودش اختصاص میده به اسم row_id/tuple_id. توی قسمت ایندکس میایم مقدار ستون به همراه row_id و page_number رو ذخیره میکنیم. خود ایندکس هم به شکل پیج پیج ذخیره میشه. اینجا خطی نشون دادیم ولی بسته به نوع ایندکس میتونه درخت یا چیزای دیگه باشه.
10 (1, 0) => value=10 is present on row_id=1 and page number=0
40 (4, 1) => value=40 is present on row_id=4 and page number=1
در ادامه انواع ایندکس رو بررسی می کنیم بر اساس دسته بندی های مختلف.
داده های یه جدول به صورت پیش فرض بدون هیچ ترتیب خاصی در Heap روی دیسک ذخیره میشن.
1. Clustered Index
اگر از ایندکس کلاستر شده استفاده کنیم میتونیم دیتابیس رو مجبور کنیم که دیتاها رو بر اساس یه ستون خاص (معمولا primary key) به صورت مرتب شده ذخیره کنه انگار که داخل جدول خودش یه جور ایندکس عه.
این مدل ایندکس توی SQL Server و MySQL(InnoDB) وجود داره و primary key میشه clustered index و جدول مرتب شده نگهداری میشه. Postgres این مدل ایندکس رو نداره و همه ایندکس ها secondary هستن ینی داده های جدول بدون هیچ ترتیب خاصی روی Heap/Disk نوشته میشن و یه ساختار داده خارج جدول میاد کمکش. البته postgres دستور cluster داره که میاد جدول رو بر اساس یه ایندکس مرتب میکنه ولی دائمی نیست و با اضافه/کم شدن ردیفای جدید ترتیب خراب میشه.
2. Non-Clustered Index
ایندکس کلاستر نشده یه داده ساختاریه که جدای از جدول ساخته میشه و کاری به ترتیب ذخیره شدن دیتاها توی جدول نداره مثل BTree و Gin و ... .
ایندکس توی دیتابیس Postgres چندین نوع داره:
1. B+Tree
این مدل ایندکس برای عملگرهای مقایسه / comparison (< > = <= >=) و Range query و نگهداری مقادیر unique و Order by عالی عمل میکنه (مقادیر رو مرتب شده ذخیره میکنه). پستگرس وقتی بهش میگی ایندکس بساز به طور دیفالت این مدل ایندکس رو میسازه. البته خود پستگرس به این میگه BTree ولی توی پیاده سازی از B+Tree در واقع استفاده می کنه طبق سورس کد.
این مدل ایندکس به درد Cardinality پایین مثل enum و true/false نمیخوره.
2. Gin
مخفف Generalized Inverted Index یا ایندکس معکوس عمومیه. برای full text search و داده های Array , JSONB مناسبه. حالا چرا بهش میگن معکوس؟ در واقع معکوس نیستش مثل ایندکس عادی میاد مقادیر رو به ردیف ها مپ می کنه اینجوری:
a -> [row1, row2, ...]
b -> [row4, row6, ...]
فقط فرقش اینه که میاد و مقدار اون ستون رو میشکنه و توکنایز میکنه مثلا برای Full text search میاد کلمات جمله رو توکنایز میکنه و هر کلمه رو به ردیف ها مپ می کنه:
regular index:
"how are you?" => [row1, row2, ...]
inverted index:
"how" => [row1, row10]
"are" => [row2, row 20]
"you" => [row3, row4, row12]

حالا جنرالایز یا عمومی برای چیه؟ ینی فقط برای full text search نیست برای جیسون و آرایه و هر تایپی که براش مشخص کنی کار میکنه فقط باید بهش operator class / opclass لازم رو بدی تا بتونه خودش مقادیر ستون لازم رو توکنایز کنه.
این مدل ایندکس بدرد دیتاست های کوچولو و جدولایی که زیاد آپدیت میشن نمیخوره.
3. Hash
این یه هش مپ ساده است که میاد مقادیر رو میبره توی یه هش فانکشن و مقدار هش به ردیف مربوطش مپ میشه
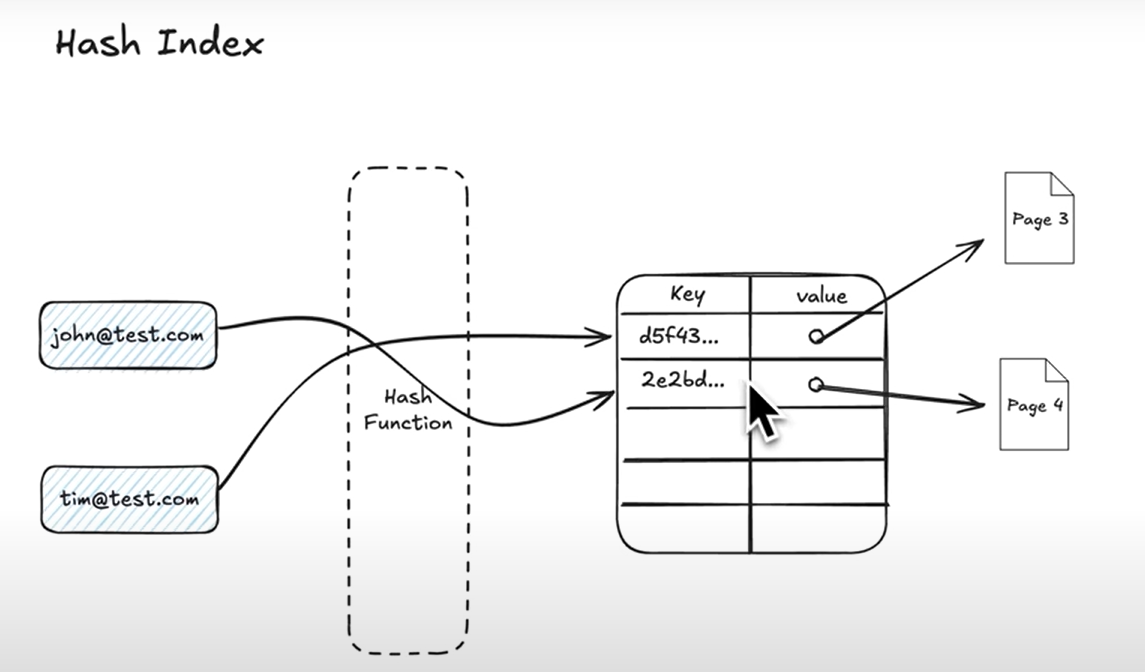
برای مقایسه برابری / equality بدرد میخوره ولی چون به صورت دیفالت همون ایندکس BTree کار اینم انجام میده تازه مرتب شده هم ذخیره میکنه خیلی از این استفاده نمیشه. بیشتر اوقات BTree بهترم عمل می کنه. هش ایندکس فقط برخی موارد که داده های اون ستون یکنواخت پراکنده شده باشن مثل uuid بهتر عمل می کنه.
4. Gist
مخفف Generalized Search Tree عه و برای داده هایی که ساختار خطی ندارن بدرد می خورده مثل داده های جغرافیایی. مثلا میخوایم روی محدوده یک کیلومتری یک نقطه جغرافیایی فیلتر کنیم. اینجا این از BTree بهتر عمل می کنه و بهینه تره. توی equality خوب عمل نمیکنه به اندازه BTree ولی برای محدوده عالیه.
5. SP-Gist
مخفف Space-Partitioned Gist عه و ورژن بهینه شده قبلیه منتها برای داده های sparse و پراکنده یا غیر یکنواخت.
6. BRIN (Block Range Index)
بدرد جداول خیلی بزرگ با داده هایی میخوره که به طور طبیعی مرتب شده ان و داده ها با مکان فیزیکیشون correlation دارن مثل جدول لاگ ایونت ها. این ایندکس خیلی کم حجمه و حتی درخت هم نیست و فقط میاد محدوده بلاک ها رو مپ میکنه به بازه های مشخص مثلا بازه زمانی مشخص مثل تصویر:

برای مقایسه محدوده بدرد میخوره برای عملگر برابری/equality فایده نداره.
اگه دیتا رو بزنی حذف کنی بعد Vacuum بزنی اونوقت correlation طبیعی بین داده ها و مکان فیزیکی اونها روی دیسک به هم میریزه و کمتر بهینه میشه چون دیتابیس مجبوره بیشتر بگرده.
1. Single Column Index
فقط روی یه ستون اعمال میشه
CREATE INDEX idx_name ON grades(name);
2. Multi-Column/Composite Index
ترکیب چنتا ستون رو ایندکس می کنیم. مثلا:
CREATE INDEX idx_orders_customer_date ON orders(customer_id, order_date);
قانون Leftmost Prefix Rule
ترتیب تعریف ستون ها مهمه! ایندکس(منظورمون ایندکس BTree هست اینجا) اول بر اساس کلید اول مرتب میکنه بعد برای مقادیری که کلید اول یکسان دارن بر اساس کلید دوم مرتب میکنه بعد مقادیری که کلید اول و دوم یکسان دارن بر اساس کلید سوم مرتب میکنه.
ینی ایندکس مرکب فقط روی ((ستون اول)) یا ترکیب ((ستون اول + ستونهای بعدی به ترتیب)) میتونه مستقیم کمک کنه در بقیه موارد چیزی رو گردن نمیگیره!
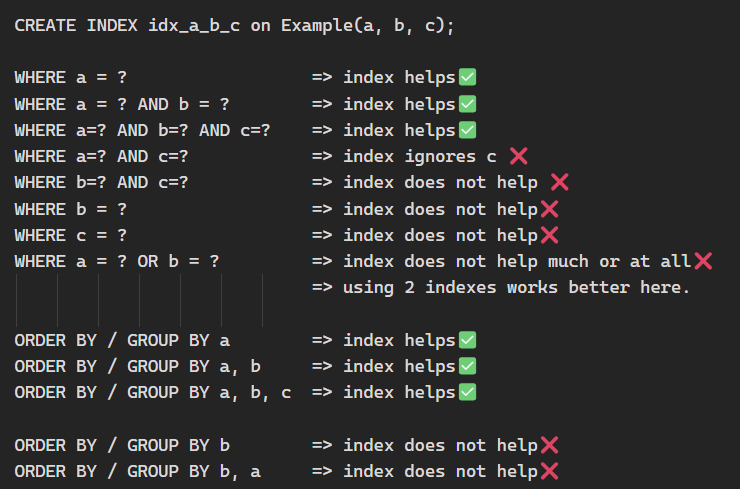
بر این اساس بهتره کلیدها رو جوری بچینیم که ستونهای با cardinality بالاتر اول قرار بگیرند و بعد ستون های با cardinality کمتر.
تفاوت Composite Index و Single Column Index
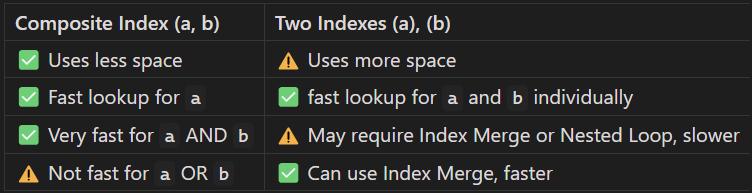
3. Partial Index
فضای ایندکس رو محدود میکنیم با شرط گذاشتن. به جای کل جدول فقط بخشی از جدول ایندکس میشه. مثلا:
CREATE INDEX idx_users_active_email
ON users(email)
WHERE is_active = true;
SELECT * FROM users WHERE is_active = true AND email = 'test@example.com';
تو این مثال ما همیشه داریم روی یوزرای فعال کوئری میگیرم پس بهتره روی ایندکس شرط بذاریم که با کل جدول ایندکس نسازیم صرفا جاهایی که شرط صدق میکنه. اینجوری فضای جستجو باز هم کوچیکتر میشه و ایندکس بهینه تر.
4. Covering Index / Include Index
یه سری ستون دیگه که جزو کلید ایندکس نیستن رو توی ایندکس لحاظ می کنیم تا دیگه دیتابیس نره توی heap دنبالشون بگرده مستقیم از خود ایندکس برشون داره بیاره. مثلا:
SELECT age, email
FROM users
WHERE name = 'Ali';
CREATE INDEX idx_user_name ON users(name) INCLUDE (age, email);
توی مثال بالا کوئری مثلا ما همیشه روی اسم کوئری میگیریم ولی همیشه هم فیلد ایمیل و سن رو میخوایم، به جای اینکه بعد از گرفتن مقادیر name با Index scan / Bitmap Index scan بریم توی Heap دنبالشون بگردیم میتونیم با Index Only Scan (که سریعتره) بدون اینکه به Heap بریم سریع دیتا رو fetch کنیم!
به ستون هایی که جزو کلید ایندکس هستن ینی روی اونها کوئری گرفته میشه میگیم key column و به اونهایی که جزو کلید ایندکس نیستن میگیم non-key column.
5. Unique Index
تضمین میکنه مقدار تکراری توی ایندکس نداشته باشیم / همه مقادیر یونیک باشن. مثلا:
CREATE UNIQUE INDEX idx_email ON users(email);
6. Function/Expression Index
ایندکسی که روی نتیجه یه عبارت ساخته میشه نه ستون خام. مثلا اینجا که بیشتر سرچ ها روی اسم با حروف کوچیک ملت انجام میشه این ایندکس رو ساختیم.
CREATE INDEX idx_lower_name ON customers(LOWER(first_name));
بلوم فیلتر / Bloom Filter
بلوم فیلتر یه data structure عه که میتونه به این سوال پاسخ بده:
"آیا این مقدار عضو این مجموعه هست یا خیر؟"
بلوم فیلتر به این سوال میتونه یه "نه" قاطع و یا یه "بله" احتمالی بده. ینی اگه بگه نه واقعا اون مقدار عضو اون مجموعه نیست ولی اگه بگه بله احتمالا هست ولی ممکنه هم نباشه ینی false positive داره (false negative نداره اصلا).
ترید آف ما اینجاست که حافظه بیشتری save می کنیم (کمتر مصرف می کنیم) و در عوض دقت پایینتری میگیریم.
- خب این به چه درد میخوره؟
برای بهینه سازی کوئری ها میتونه استفاده بشه و تعداد مراجعه به دیتابیس/دیسک/مرجع اصلی رو کاهش بده از طرفی حجم خیلی کمی حافظه مصرف می کنه. توی شبکه توی دیتابیس Cassandra (برای کاهش IO) توی ردیس و کلی جای دیگه کاربرد داره و جلوی کوئری های اضافی رو میگیره.
پستگرس یه نوع ایندکس فرعی هم به اسم Bloom داره که برای بررسی عضویت توی جدولایی که بزرگ هستن و میخوایم روی چنتا فیلد با هم فیلتر AND بزنیم کاربرد داره.
CREATE EXTENSION IF NOT EXISTS bloom;
CREATE INDEX idx_users_bloom ON users USING bloom (gender, status, age);
- چجوری کار میکنه؟
یه آرایه بیتی درست میکنیم و با مقدار اولیه صفر همه مقادیر رو پر می کنیم، بعد یه Hash Function تعریف می کنیم و هر مقداری که میخوایم به دیتابیسمون اضافه کنیم یه بار هم میبریم توی هش فانکشن. هش فانکشن یه عدد میده توی رنج اون آرایه، اون اندیس رو با مقدار 1 مقداردهی می کنیم. هر دفعه سوال شد آیا این مقدار توی این مجموعه هست اونو میبریم توی هش فانکشن اگه بیت مربوطه 0 بود ینی قطعا این مقدار توی مجموعه وجود نداره و اگه 1 بود ینی احتمالا وجود داره و باید بریم بگردیم پیداش کنیم. همین!
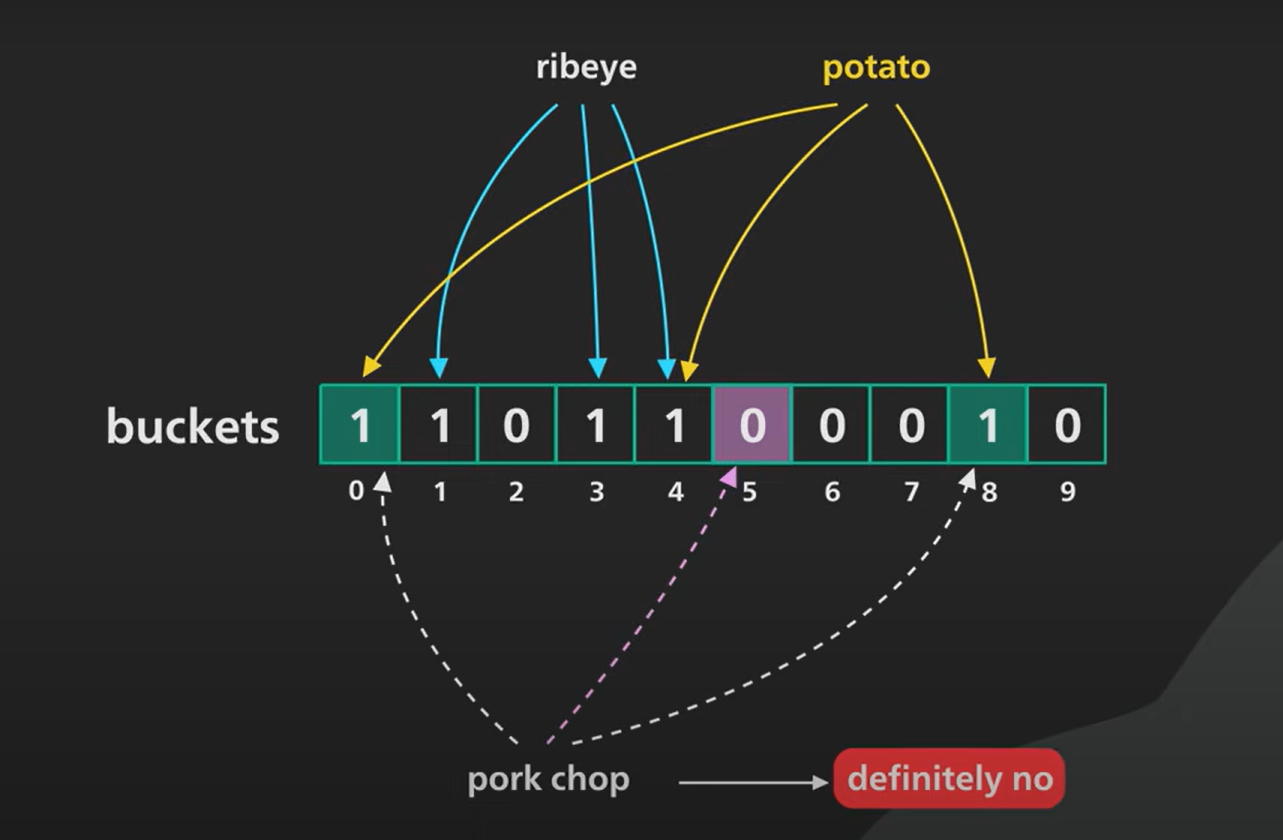
توی مثال شکل مشخصه قشنگ. البته این به واقعیت نزدیکتره چون بلوم فیلتر برای کاهش false positive میاد از سه تا hash function استفاده می کنه و مقدارا رو با هم and می کنه.
- اگه همه بیت ها پر بشن چی میشه؟
در این صورت دقتش خیلی میاد پایین(همه رو میگه yes و باید بری دیتابیس رو بگردی!) و باید تعداد بیت ها رو افزایش داد و دوباره یه جدیدشو ساخت مثلا.
- اگه یه داده حذف بشه چه کنیم؟
نمیتونیم بیت ها رو دست بزنیم چون نمیدونیم فقط مال اون دیتای حذف شده است یا مشترکه با بقیه دیتاهای موجود. توی Bloom filter سنتی این امکان وجود نداره ولی توی بلوم فیلترهای جدیدتر مثل Counting Bloom filter یا Cuckoo filter این امکان هستش. اونجا به جای استفاده از یه بیت میایم از یه integer استفاده می کنیم و هر بار یه دونه count+1 می کنیم. اینجوری میشه دیتا حذف هم کرد ولی هزینه ای دادیم این بوده که حافظه بیشتری مصرف می کنیم.
خب تا اینجا با انواع ایندکس آشنا شدیم حالا دست به آچار بشیم!
برای آنالیز کوئری های Postgres و اینکه بفهمیم چه مراحلی رو طی می کنه تا دیتا رو بگیره آیا از ایندکس داره استفاده می کنه یا نه از explain و explain analyze استفاده می کنیم. explain فقط برنامه ریزی دیتابیس رو نشون میده ولی explain analyze هم برنامه ریزی و تخمین رو نشون میده و هم کوئری رو ران می کنه و مقادیر آماری واقعی رو نشون میده.
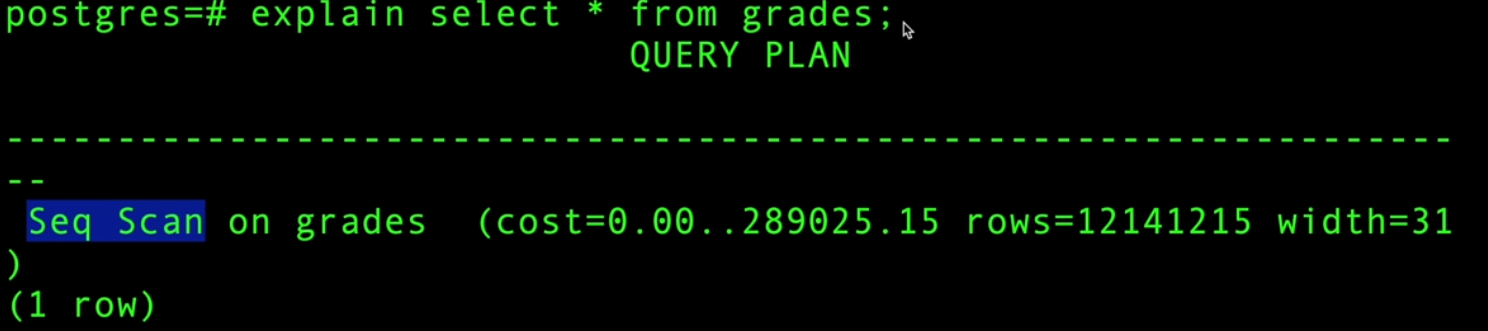
این میگه که عملیات Seq Scan انجام شده زمان تخمینی fetch کردن اولین tuple مساوی 0 عه و زمان تخمینی fetch کردن آخرین tuple مساوی 289 و خورده ای ثانیه است. تعداد تقریبی ردیف ها 12 میلیون و خورده ایه و طول هر tuple مساوی 31 بایته که میشه مجموع سایز field های اون جدول مثلا 4 بایت integer به اضافه 8 بایت double و ... .
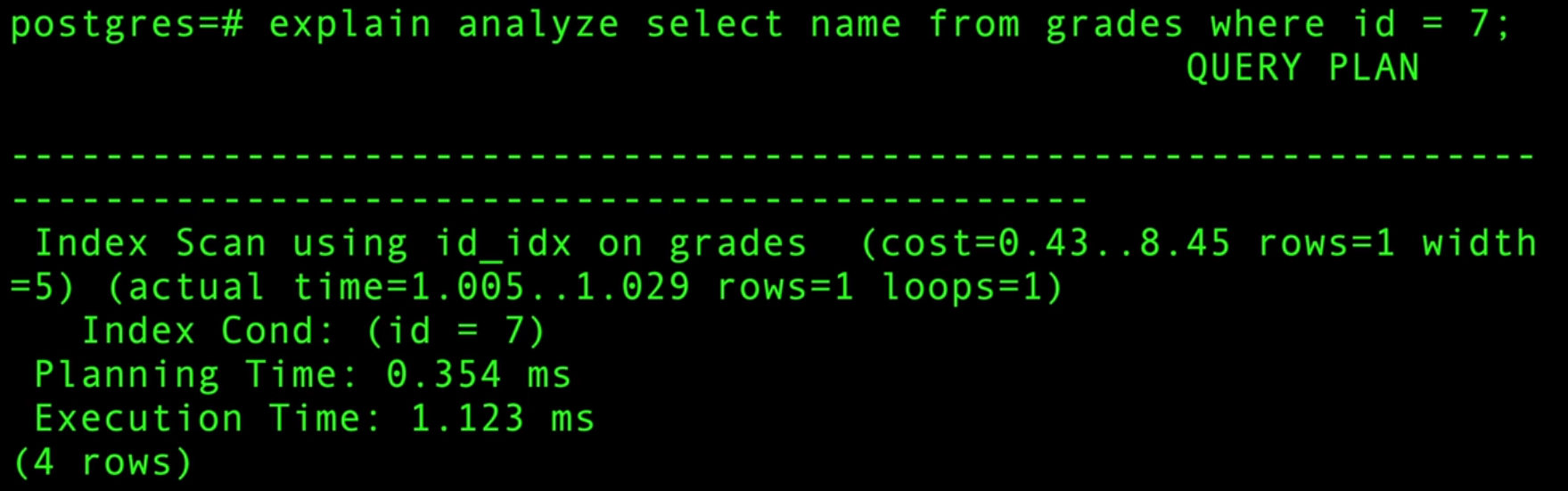
این هم میگه چقدر زمان برد برنامه ریزی کنم چقدر زمان اجرا طول کشید. البته خیلی از این میتونه بیشتر پیچیده بشه و باید حتما خودت با این ابزار کار کنی تا دستت بیاد!
انواع اسکن
جدول در دیتابیس postgres
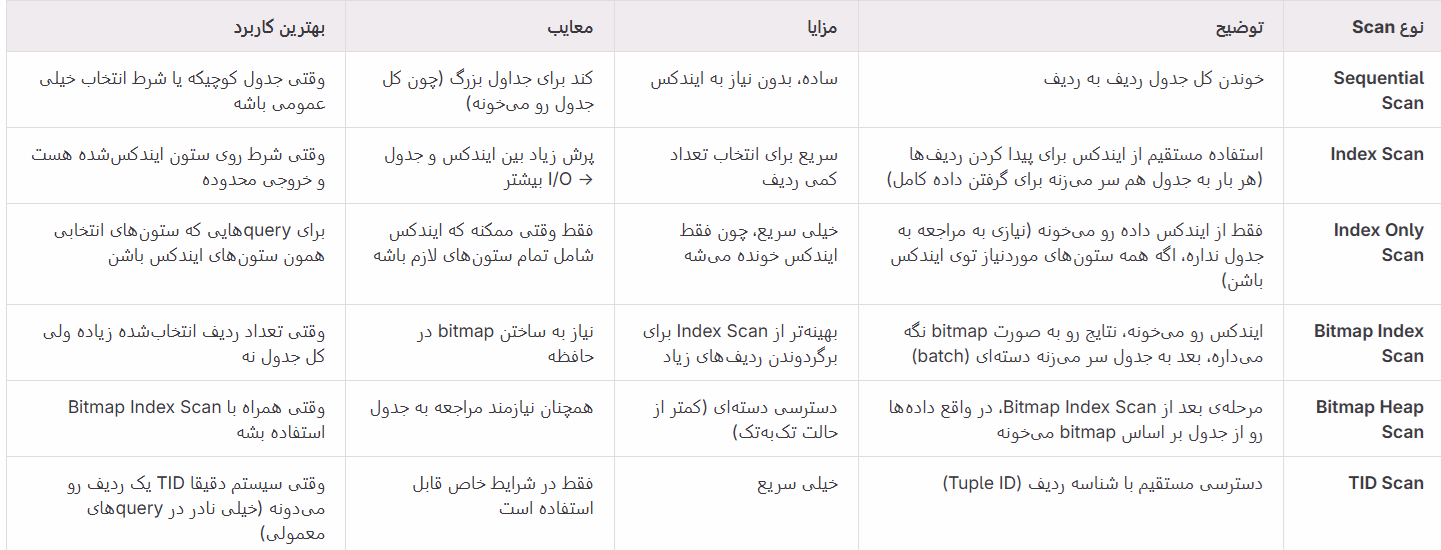
حالا بریم سراغ یه سری سوالات که ممکنه براتون پیش بیاد!
1. کی ایندکس به درد نمیخوره؟
وقتی که جدول کوچیکه یا Cardinality ستون کمه(Gender, status, true/false)
2. تفاوت covering index و Multi-column index/composite index چیه؟
توی ایندکس مرکب/چندستونی همه ستون های ایندکس key column هستن ینی ایندکس بر اساس اونها ساخته و مرتب میشه ولی توی ایندکس پوششی ایندکس فقط روی key column ها ساخته و مرتب میشه ولی مقدار non-key column ها رو هم توی ایندکس ذخیره می کنه که دیگه به Heap مراجعه نکنه و با Index only scan کارو در بیاره و پرفورمنس رو ببره بالا. ایندکس مرکب برای زمانیه که روی همه ستونهای ایندکس داره کوئری گرفته میشه ولی کاورینگ ایندکس برای زمانیه که فقط میخوایم روی key column کوئری بگیریم ولی یه سری فیلد اضافه هم همیشه همراهش لازم داریم.
البته جایی که از covering index ساپورت نمیشه (مثلا جنگو به صورت پیش فرض ساپورت نمیکنه مگه که لایبرری اضافه کنی یا دستی مایگریشن بنویسی) میشه از composite index استفاده کرد به جاش ایندکس سنگین تری ساخته میشه به نسبت و خب قاعدتا پروفورمنس پایین تری داریم (چون ایندکس به ترتیب روی همه کلیدها مرتب میشه) و حجم بیشتری اشغال می کنه.
منابع:
https://www.youtube.com/watch?v=_HG2eB27j00&t=2s&ab_channel=JaneExplainsIT
https://www.youtube.com/watch?v=2l-nCkPQVuQ&ab_channel=PostgresOpen
https://medium.com/threadsafe/unleashing-the-power-of-composite-indexes-in-postgresql-909ac95fc476
https://www.youtube.com/watch?v=V3pzxngeLqw&ab_channel=ByteByteGo