از اونجایی که خیلی یادگیری رو دوست دارم تصمیم گرفتم یکم با LLMها بیشتر وَر برم، با وب سایت Hugging Face آشنا شدم، اگه بخوام در موردش خیلی کوتاه توضیح بدم انگار Hugging Face شبیه گیتهابه؛ با این تفاوت که مخصوص مدلهای هوش مصنوعیه، حالا این مدلها میتونه پرایویت باشن یا پابلیک، میتونی بین مدلهایی که مردم پابلیک گذاشتن بگردی و نحوه استفاده از api های هر مدل که دارن رو هم تو پیج هر کدوم ببینی. هر مدل زبانی هم دلت بخواد میتونی پیدا کنی از چت گرفته تا مدلهای تولید تصویر، صدا، ترجمه و ... . یه توکن هم میده که میتونی با اون توکن به مدلها دسترسی پیدا کنی، خیلی خوشحال و شادمان که به به عجب چیزی پیدا کردم ولی بعد یه ساعت کار باهاش دیدم به محدودیت رایگان خوردم و باید پلن پولی بگیرم و خیلی تو ذوقم خورد :). همین شد که رفتم دنبال یه راهحل لوکال.
یکم سرچ کردم دیدم که چیزی هست به اسم Ollama که میتونی روی سیستمت نصب کنی و کلی LLM روی سیستم لوکالت بیاری بالا، رفتم گشتم دیدم هم مستقیم روی سیستم عامل میتونیم نصب کنیم و هم با داکر. از اونجایی که دوست ندارم خیلی سیستمعاملم پر از نصب و کانفیگ بشه، تصمیم گرفتم تو یه محیط ایزوله با داکر کامپوز Ollama رو بالا بیارم، حالا پایینتر مرحله به مرحله میگم چطوری نصب کنین و اصلا چقد منابع لازم دارین.
منابع مورد نیاز:
برای نصب Ollama که عملا منابع خاصی نیاز نداریم(مثلا ۵۰۰ مگ براش کافیه)، بیشتر منابع واسه زمانی هست که بعد از اینکه نصبش کردیم باید باهاش LLM مورد نظرمون رو دانلود کنیم و ران کنیم، اونجاس که منابع خیلی مهم میشه و به RAM و CPU نیاز پیدا میکنیم (GPU ضروری نیست ولی اگه داشته باشی اجرای مدلها خیلی سریعتر میشه).
حالا من خودم لپتاپم ۳۲ گیگ رم داره و cpu یک اینتل i7 نسل ۱۳ هست ولی برای اجرا مدلهای سبک با یک رم ۸ گیگ و یه i5 نسل ۸ به بالا هم میشه کار و جمع کرد.
نصب Ollama:
اگه خواستید مستقیم روی سیستم نصب کنین فقط کافیه با این دستور پیش برید.
curl -fsSL https://ollama.com/install.sh | sh
(من چون با این دستور نصب نکردم واقعیتش نمیدونم در ادامه چی در انتظارتونه :) ولی فک نکنم کار سختی باشه).
خب بریم سراغ نصب با داکر:
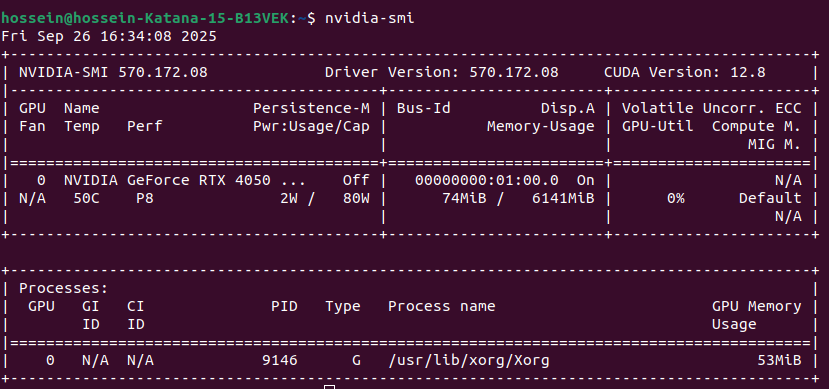
اگه GPU دارین دستورات زیر رو بزنید ببینید درایورش نصب هست یا نه
nvidia-smi
خروجیش یه چیزی مثل پایین میشه:
بعد اینکه مشخص شد GPU دارین و میخوایید ازش استفاده کنین باید یه سری ابزار هم نصب کنین که دستوراتش رو پایین میزارم. (البته با این پیشفرض میرم جلو که شما قبلا داکر رو روی سیستم دارین)
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg
curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt-get update
sudo apt-get install -y nvidia-container-toolkit
sudo nvidia-ctk runtime configure --runtime=docker
sudo systemctl restart docker
حالا بریم سراغ داکر کامپوز:
services: ollama: image: ollama/ollama:latest container_name: ollama ports: - "11434:11434" volumes: - ollama_data:/root/.ollama - ./modelfiles:/modelfiles environment: - OLLAMA_NUM_PARALLEL=4 - OLLAMA_MAX_LOADED_MODELS=3 - NVIDIA_VISIBLE_DEVICES=all - NVIDIA_DRIVER_CAPABILITIES=compute,utility deploy: resources: reservations: devices: - driver: nvidia capabilities: ["gpu"] count: all restart: unless-stopped networks: - traffic-network webui: image: ghcr.io/ollama-webui/ollama-webui:main container_name: ollama-webui ports: - "3000:8080" depends_on: - ollama networks: - traffic-network environment: - OLLAMA_API_BASE_URL=http://ollama:11434/api restart: unless-stopped volumes: ollama_data: networks: traffic-network:
حالا یه سوالی که با دیدن این داکر کامپوز براتون پیش میاد اینه که این ollama-webui دیگه از کجا پیداش شد :)
بخوام ساده توضیح بدم خود ollama انگاری قلب ماجراس و هر چیزی که پشت صحنه بهش نیاز داریم رو هندل میکنه و حالا میخوام که یه UI با حال هم داشته باشیم که خیلی درگیر ترمینال نشیم و اگه عکس اول این مقاله رو برگردی یه نگاهی بهش بندازی تهش میشه اون :).
حالا وقتشه که اجراش کنیم:
docker compose up -d
بعد اینکه image دانلود شد حالا تو مرورگر بزن فقط اگه پورت ۳۰۰۰ قبلا استفاده شده پورتش رو تو داکر کامپوز عوض کن.
خب حالا باید اون تصویر اول بالای مقاله رو ببینید. تا اینجا تونستیم Ollama رو بیاریم بالا و اصل ماجرا از اینجا شروع میشه. یعنی دانلود LLMها. از این لینک میتونیم لیست همه LLMهایی که Ollama داره رو ببینیم.
قبل اینکه بخواییم بریم مدلها رو دانلود کنیم برای اینکه مطمئن بشید GPU شما داخل کانتینر Ollama اوکی هست این دستور رو بزنین:
docker exec -it ollama nvidia-smi
خروجیش باید مثل اون تصویر خروجیای که بالاتر از ترمینال گذاشتم باشه.
دانلود LLMها:
برای شروع کار بریم با llama2 استارت بزنیم، اگه بازش کنید لینک رو یه همچین چیزی رو میبینید:
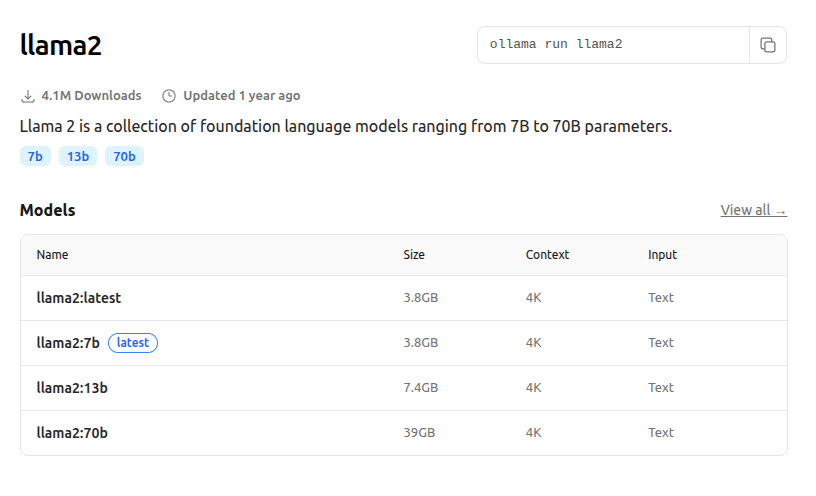
راجب اون عددهایی که جلو مدل نوشتن، مثلا واسه 7b یعنی این مدلی که حجمش هم ۳.۸ گیگ هست، حدود ۷ میلیارد پارامتر داره و منظور از پارامتر هم یعنی چیزی که مدل یاد میگیره، حالا بخوام ساده بگم هر چی تعداد پارامترها بیشتر باشه قطعا قدرت مدل هم بالاتر میره و دقیقتر میشه و اون ور هم حجمش بیشتر میشه و رم بیشتری لازم داره.
من مطابق با منابع لپتاپم llama2:7b پول میکنم، برای گرفتن مدل هم کافیه به کانتینر exec کنید و دستور پول رو بزنید اینجوری:
docker exec -it ollama ollama pull llama2:7b
بعدش باید وایسی تا کامل دانلود بشه، اینجا باید یکم صبور باشین، اگه سرعتت هم خوبه که ناز شصتت :)
فقط یه چیزی که من تو دانلود این مدلها بهش برمیخوردم و نمیدونم چه مرگشونه اولش با سرعت ۸ مگ دانلود میکنه و همه چی خوبه به اخرش که میرسه و مثلا ۲۰۰ مگ میمونه سرعتش میرفت روی کلیو و اعصابم رو به هم میریخت :)) امیدوارم واسه تو اینجوری نشه.
بعد اینکه دانلود شد حالا باید ران کنی:
docker exec -it ollama ollama run llama2:7b
بعدش برو تو لینک webui که همون لوکال هاست هست روی سلکت باکس select a model بزن و LLMای که پول کردی تو لیست میاد: (با سیستم نتونستم اسکرین شات بگیرم لیستش رو تا دکمه پرینت اسکرین میزدم میرفت :) با موبایل گرفتم).

تبریک میگم تموم شد و حالا شما میتونید ازش به صورت لوکال و آفلاین استفاده کنین و حتی میتونین از طریق apiای که میده هم باهاش کد نویسی کنین.
به امید اینکه بازخورد خوبی بگیره و مقاله دیگهای که از الان تو ذهنم هست رو بنویسم :)
پ ن: عزیزان اگه جایی از مقاله مشکلی داره لطفا باهام در میون بزارین تا اصلاح کنم.