تولید خودکار دادههای آزمون برای سیستمهای شیءگرا، به دلیل پیچیدگی تعاملات میان اشیاء و الگوی ترکیب (Composition)، با چالشهای جدی روبرو است. روشهای سنتی مبتنی بر جستجو اغلب در مواجهه با وابستگیهای پنهان وضعیت اشیاء، در بهینگیهای محلی گرفتار شده و از دستیابی به پوشش کد بالا باز میمانند. هدف این پژوهش، ارائه روشی نوین مبتنی بر یادگیری عمیق برای کشف گرههای استراتژیک در گراف نرمافزار است که تغییر آنها بیشترین پتانسیل را برای باز کردن مسیرهای اجرایی جدید دارد. در این مطالعه، ابتدا کد منبع Apache Hadoop به یک گراف وابستگی شامل کلاسها، متدها و فیلدها تبدیل شد که منجر به ایجاد گرافی با بیش از ۲۴۰,۰۰۰ گره و ۷۰۰,۰۰۰ یال گردید. سپس، یک مدل Graph Autoencoder – GAE با استفاده از لایههای کانولوشن گراف (GCN) پیادهسازی شد تا ساختار و وابستگیهای پنهان سیستم را در یک Embedding Space یاد بگیرد. در نهایت، با تحلیل بردارها در Embedding Space، متغیرهایی که دارای بیشترین امتیاز علیت بودند، استخراج شدند. نتایج نشان داد که مدل پیشنهادی میتواند بدون نیاز به اجرای کد، متغیرهای کلیدی سیستم را شناسایی کند. ۱۰ متغیر برتر شناسایی شده شامل Loop Counters، System Status Flags و Configuration Identifiers بودند که نقاط گلوگاه برای کنترل جریان اجرا محسوب میشوند. این امر نشاندهنده توانایی مدل در درک ساختار معنایی برنامه است. این پژوهش نشان میدهد که شبکههای عصبی گرافی پتانسیل بالایی برای استخراج روابط علّی در نرمافزارهای مقیاس بزرگ دارند. لیست متغیرهای استخراج شده میتواند به عنوان یک نقشه راه به الگوریتمهای تولید آزمون مانند EvoSuite تزریق شود تا با تمرکز بر این موضوع، از دام بهینگی محلی خارج شده و پوشش آزمون را افزایش دهند.
نرمافزارها به جزء جداییناپذیر زندگی بشر تبدیل شدهاند و از سادهترین لوازم خانگی تا حیاتیترین زیرساختهای صنعتی را مدیریت میکنند. این گستردگی باعث شده است که ویژگیهای کیفی نرمافزار نظیر قابلیت اطمینان، نگهداریپذیری و امنیت، بیش از پیش اهمیت یابند. کیفیت نرمافزار در واقع ستون فقرات موفقیت و پایداری سیستمها محسوب میشود و نقص در آن نه تنها به نارضایتی کاربران میانجامد، بلکه هزینههای مالی و اعتباری سنگینی را به سازمانها تحمیل میکند. در این راستا، آزمون نرمافزار به عنوان روش اصلی صنعت برای ارزیابی و تضمین کیفیت شناخته میشود. با توجه به پیچیدگی روزافزون سیستمها، تولید خودکار مجموعههای آزمون (Test Suites) به یک ضرورت تبدیل شده است تا ضمن کاهش تلاشهای دستی، میزان پوشش آزمون را افزایش دهد. این حوزه همواره یکی از زمینههای فعال پژوهشی بوده و روشهای متنوعی مانند آزمون مبتنی بر جستجو (SBST)، تولید تصادفی هدایتشده با بازخورد و اجرای نمادین پویا برای آن توسعه یافته است.
آزمون مبتنی بر جستجو (SBST) و محدودیتهای روشهای آزمون مبتنی بر جستجو، و بهویژه ابزارهایی مانند EvoSuite، در سالهای اخیر توجه زیادی را به خود جلب کردهاند و توانستهاند در دستیابی به معیارهای پوشش کد (Code Coverage) عملکرد قابلقبولی از خود نشان دهند. اساس کار این روشها، تبدیل مسئله تولید داده آزمون به یک مسئله بهینهسازی است که در آن الگوریتمهای جستجو (مانند الگوریتم ژنتیک) سعی میکنند ورودیهایی را بیابند که بیشترین بخشهای کد را اجرا کنند.
با این حال، تحقیقات جدید نشان میدهد که صرفِ دستیابی به پوشش بالای کد، لزوما به معنای کشف مؤثر خطاها نیست. برای مثال، مطالعات روی مجموعه داده Defects4J نشان داده است که ابزارهای پیشرویی مانند EvoSuite، حتی با رسیدن به پوشش ۱۰۰ درصدی شاخه، تنها قادر به کشف حدود ۲۳ درصد از نقصهای واقعی بودهاند. علت اصلی این ضعف، اتکای این ابزارها به ورودیهای تصادفی یا مقادیر ثابتی است که با واقعیتهای معنایی برنامه و مشخصات پروژه همخوانی ندارند. علاوه بر این، این ابزارها در تولید دنبالهای از فراخوانیهای پیچیده که برای ساخت اشیاء در وضعیتهای خاص لازم هستند، دچار مشکل میشوند و نمیتوانند سناریوهای عمیق را پوشش دهند. این ناتوانی در مدیریت ساختارهای پیچیده، نیاز به استراتژیهای هوشمندتر برای تولید ورودیهای باکیفیت را برجسته میکند.
رویکردهای نوین در تولید داده آزمون برای غلبه بر محدودیتهای روشهای سنتی، محققان رویکردهای مختلفی را پیشنهاد کردهاند:
روشهای مبتنی بر محدودیت: یکی از این روشها، تغییر فضای جستجو از فضای مقادیر ورودی به فضای محدودیتها است. در این رویکرد، به جای جستجوی کورکورانه مقادیر، الگوریتم ژنتیک بر روی پارامترهای محدودیتساز (Path Constraints) تمرکز میکند. سیستم ابتدا محدودیتهای لازم برای رسیدن به شاخههای هدف را یاد میگیرد و سپس با حل آنها، داده آزمون دقیق تولید میکند.
آزمون در زبانهای پویا: در حالی که ابزارهایی مانند EvoSuite برای زبانهای با نوعدهی ایستا (مانند جاوا) توسعه یافتهاند، زبانهای پویا مانند پایتون چالشهای متفاوتی دارند. فقدان اطلاعات Type در زمان کامپایل باعث میشود فضای جستجو بسیار بزرگ شود. ابزار PYNGUIN به عنوان راهکاری برای این زبانها توسعه یافته تا با پیادهسازی الگوریتمهای جستجو، بر این چالش غلبه کند.
آزمون جهش(Mutation Testing): این روش به عنوان مکانیزمی قدرتمند برای ارزیابی کیفیت آزمونها مطرح است اما هزینه محاسباتی بالایی دارد. چالش اصلی در اینجا، تولید دادههایی است که بتوانند جهشیافتههای سرسخت (Stubborn Mutants) را از بین ببرند. رویکردهای جدیدی مانند چارچوب TDGMSE با معرفی شاخصهای ترکیبی (قابلیت دسترسی و آلودهسازی) و استفاده از تکامل مجموعه، سعی در حل این مشکل دارند. همچنین روش TAMMEA با استفاده از مدلهای زنجیره مارکوف برای کاهش شاخه و الگوریتم تخمین توزیع (EDA)، تلاش میکند با داده آزمون کمتر، جهشیافتههای بیشتری را بکشد. استفاده از شبکههای عصبی کانولوشنی (CNN) برای تخمین برازندگی در الگوریتمهای ژنتیک چندجمعیتی نیز از دیگر نوآوریهای این حوزه است.
چالشهای اختصاصی در آزمون سیستمهای شیءگرا به دلیل ماهیت ساختاری خود، پیچیدگیهای منحصربهفردی را به فرآیند آزمون تحمیل میکنند. در این سیستمها، واحد آزمون از «زیربرنامه» به «کلاس» تغییر میکند و درستی عملکرد تنها به ورودی وابسته نیست، بلکه به وضعیت داخلی (Internal State) شیء نیز بستگی دارد.
State Problem و کپسولهسازی: به دلیل اصل کپسولهسازی، دسترسی مستقیم به وضعیت اشیاء محدود است و تنها از طریق دنبالهای از فراخوانی متدها میتوان وضعیت را تغییر داد. این مسئله، تولید تست برای سناریوهایی که نیاز به وضعیت خاصی دارند را برای الگوریتمهای جستجو دشوار میکند.
وراثت و چندریختی: ویژگیهایی مانند وراثت و اتصال پویا (Dynamic Binding) باعث میشوند معیارهای پوشش سنتی ناکارآمد باشند. ممکن است یک کلاس والد پوشش داده شود، اما این پوشش توسط شیءای از کلاس فرزند صورت گرفته باشد و رفتار خودِ کلاس والد هرگز آزموده نشود. همچنین، بسیاری از خطاها ناشی از تعامل نادرست بین متدهای کلاس فرزند و وضعیتهای به ارث رسیده از والد هستند که معیارهای سنتی آنها را نادیده میگیرند.
پیچیدگی ترکیب (Composition): یکی از چالشبرانگیزترین الگوها، رابطه ترکیب است. در اینجا، یک کلاس نگهدارنده شامل چندین شیء مؤلفه است. صحت عملکرد سیستم به تعاملات شبکه ای و پیچیده میان این اجزا بستگی دارد. الگوریتمهای جستجوی فعلی اغلب در درک معنایی این روابط و تولید دنباله فراخوانیهای صحیح برای مقداردهی به اشیاء داخلی ناتوان هستند و در بهینگیهای محلی گرفتار میشوند.
کاربرد هوش مصنوعی و یادگیری عمیق در آزمون نرمافزار در سالهای اخیر، استفاده از یادگیری ماشین (ML) و یادگیری عمیق(DL) برای هوشمندسازی تولید داده آزمون رواج یافته است.
مدلهای زبانی بزرگ (LLMs): مدلهایی مانند GPT-3.5 به دلیل توانایی در درک متن، برای استخراج ورودیهای معنادار از (Bug Reports) استفاده میشوند. رویکردهای ترکیبی که از LLM برای پالایش ورودیهای استخراجشده توسط Regex استفاده میکنند، توانستهاند نرخ کشف نقص ابزارهایی مانند EvoSuite را بهبود بخشند. همچنین تکنیکهای مهندسی پرامپت مانند Tree-of-Thoughts به این مدلها کمک میکند تا با استدلال ساختاریافته، ورودیهای دقیقتری تولید کنند.
شبکههای مولد تخاصمی (GANs): تحقیقاتی بر روی استفاده از GANها برای یادگیری رفتار نرمافزار و تولید داده آزمون متمرکز شدهاند. برای مثال، مدل WGAN-GP برای بهبود پوشش شاخه در برنامههای بزرگ بدون نیاز به تحلیلهای پیچیده ایستا پیشنهاد شده است.
بهینهسازی چند وظیفهای و چند هدفه: برخی روشها از یادگیری مشارکتی چند وظیفهای (Multi-task learning) استفاده میکنند تا دانش کسبشده از آزمون یک تابع را به توابع مشابه منتقل کنند و مشکل انفجار مسیر را کاهش دهند. همچنین در بهینهسازی چند هدفه، ترکیب اهداف پوشش کد با اهداف مبتنی بر نقص (مانند تعداد استثناءها) نتایج بهتری نسبت به تمرکز صرف بر پوشش کد داشته است.
با وجود تمام پیشرفتهای ذکر شده، یک شکاف اساسی در ادبیات موضوع وجود دارد و آن عدم درک و مدلسازی روابط علّی در ساختارهای پیچیده شیءگرا است. اکثر روشهای موجود (چه سنتی و چه مبتنی بر هوش مصنوعی) بر بهینهسازی پارامترها یا استخراج ورودی تمرکز دارند و توجهی به کشف روابط علت و معلولی عمیق در الگوهایی نظیر ترکیب ندارند. همانطور که بیان شد، این پیچیدگیهای تعاملی مانع اصلی دستیابی به پوشش کامل هستند.
برای پر کردن این خلاء، میتوان از پیشرفتهای حوزههای دیگر نظیر زیستشناسی الهام گرفت. در زیستشناسی محاسباتی، مدلهای یادگیری عمیق مانند D2CL توانستهاند در سیستمهای بسیار پیچیده با ابعاد بالا (مانند تعاملات ژنی در سلول)، روابط علی را کشف کنند. این مدلها بر اساس فرضیه متا-ژنراتور عمل میکنند که میگوید روابط علی، امضاهای ساختاری و آماری مشخصی در دادهها بر جای میگذارند. مدل D2CL با استفاده از معماری دو شاخه (شامل شبکه عصبی کانولوشنی برای تحلیل توزیع داده و شبکه عصبی گرافی برای تحلیل ساختار)، این امضاها را یاد میگیرد و میتواند روابط ناشناخته را پیشبینی کند.
این پژوهش با فرض اینکه سیستمهای نرمافزاری شیءگرا نیز از پیچیدگی ساختاری مشابهی پیروی میکنند، پیشنهاد میدهد که میتوان از منطق مشابهی (تحلیل همزمان گراف نرمافزار و توزیع دادههای اجرا) برای کشف متغیرهای تاثیرگذار بر پوشش آزمون استفاده کرد. این رویکرد میتواند با شناسایی گلوگاههای علّی در گراف ترکیب اشیاء، فرآیند جستجوی داده آزمون را هوشمندانه هدایت کرده و از گرفتاری در بهینگیهای محلی جلوگیری کند.
پژوهش حاضر با الهام از مدلهای کشف روابط علّی در زیستشناسی نظیر مدل D2CL که برای تحلیل ژنها استفاده میشود، یک رویکرد نوین را پیشنهاد میدهد. فرضیه اصلی ما این است که همانطور که در شبکههای زیستی، برخی ژنها نقش تنظیمکننده اصلی (Master Regulator) را دارند، در گراف نرمافزار نیز متغیرها و فیلدهایی وجود دارند که نقش گلوگاههای اطلاعاتی را بازی میکنند. شناسایی و تغییر این متغیرها، موثرترین راه برای تغییر وضعیت شیء و در نتیجه افزایش پوشش آزمون است.
مراحل پیادهسازی این ایده بر روی چارچوب عظیم Apache Hadoop تشریح میشود. ما با استخراج یک گراف وابستگی غولپیکر و آموزش یک مدل Graph Autoencoder - GAE، موفق به استخراج سیگنالهای علَی از دل میلیونها خط کد شدیم.
گام نخست، تبدیل کد منبع ایستا به یک ساختار قابل فهم برای ماشین بود. ما نیاز به گرافی داشتیم که نه تنها کلاسها، بلکه ریزترین جزئیات اجرایی را نیز مدل کند. برای این منظور، چارچوب Apache Hadoop به عنوان مورد مطالعاتی انتخاب شد. دلیل این انتخاب، استفاده گسترده از الگوهای شیءگرا، حجم عظیم کد (بیش از ۱.۵ میلیون خط) و پیچیدگی تعاملات توزیعشده بود.
با استفاده از Parserها، ما یک گراف Call and Data Usage Graph استخراج کردیم که شامل سه نوع گره بود:
کلاسها (Classes): به عنوان ظروف اصلی منطق برنامه.
متدها (Methods): به عنوان واحدهای اجرایی.
فیلدها/متغیرها (Fields): به عنوان حافظههای وضعیت سیستم.
یالهای گراف نیز نشاندهنده روابط معنایی بودند:
رابطه HAS_METHOD و HAS_FIELD ساختار کلاس
رابطه CALLS جریان کنترل.
رابطه ACCESSES جریان داده.
خروجی این مرحله، گرافی عظیم با مشخصات زیر بود:
تعداد گرهها: ۲۴۴,۷۸۹ گره
تعداد یالها: ۷۳۹,۸۶۰ یال
برای اینکه شبکه عصبی بتواند گراف را پردازش کند، هر گره نیاز به یک بردار ویژگی (Feature Vector) داشت. در ابتدا، از روش One-Hot Encoding برای نوع گره (کلاس، متد، فیلد) استفاده شد. اما در آزمایشهای اولیه با Symmetry Problem مواجه شدیم.
از آنجا که هزاران متغیر در سیستم وجود داشتند که از نظر نوع یکسان بودند، مدل GNN قادر به تمایز قائل شدن بین آنها نبود و به همه امتیاز یکسانی میداد. برای شکستن این تقارن و دادن هویت منحصربهفرد به هر گره، ما استراتژی تزریق نویز تصادفی Random Noise Injection را پیادهسازی کردیم و بردار ویژگی نهایی برای هر گره به صورت زیر تعریف شد:
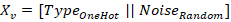
که در آن Type یک بردار ۳ بعدی و Noise یک بردار ۱۶ بعدی از اعداد تصادفی نرمال بود. این کار باعث شد ورودی شبکه ۱۹ بعدی شود و مدل بتواند هر گره را به صورت مجزا ردیابی کند.
مدل اصلی استفاده شده، یک خودرمزنگار گرافی (GAE) است که از دو بخش تشکیل شده است:
رمزنگار(Encoder): یک شبکه عصبی کانولوشنی گراف (GCN) دو لایه که اطلاعات ساختاری و ویژگیهای گرهها را دریافت کرده و آنها را به یک Latent Space با ابعاد کمتر فشرده میکند.
Z = GCN(X, A)
در اینجا Z ماتریس Embedding نهایی است که حاوی امضای ساختاری هر گره میباشد.
رمزگشا (Decoder): این بخش تلاش میکند تا ماتریس مجاورت گراف (A) را از روی فضای نهان (Z) بازسازی کند. هدف این است که مدل یاد بگیرد کدام گرهها باید به هم متصل باشند.
Loss Function مدل، میزان خطای بازسازی گراف را میسنجد. کاهش این خطا به این معناست که مدل توانسته است منطق ارتباطی موجود در نرمافزار Hadoop را یاد بگیرد.
پیادهسازی با استفاده از کتابخانه PyTorch Geometric انجام شد. آموزش مدل بر روی گراف ۲۴۴ هزار گرهای Hadoop طی ۲۰۰ epoch صورت گرفت.
خطا از مقدار اولیه حدود ۱.۷۰ شروع شد و به سرعت کاهش یافت تا در نهایت در مقدار ۱.۰۲ تثبیت شد. این همگرایی نشان میدهد که مدل توانسته است الگوهای تکرار شونده در کد مانند الگوهای Getter/Setter، الگوهای Factory، و زنجیرههای فراخوانی را درک کند و آنها را در فضای برداری (Z) فشرده نماید.
پس از آموزش، ما ماتریس Z را استخراج کردیم. طبق تئوری مدلهای علّی، گرههایی که دارای مرکزیت و نفوذ بیشتری در شبکه هستند، در فضای نهان دارای بردار بزرگتری خواهند بود. ده متغیر برتری که مدل به عنوان تاثیرگذارترین نقاط سیستم شناسایی کرد عبارتند از:
1. org.apache.hadoop.metrics2.impl.PurgableSource.nextKey
2. org.apache.hadoop.mapred.TestJobClientGetJob.runningJob
3. org.apache.hadoop.hdfs.tools.offlineImageViewer.TestOfflineImageViewer.FILE_NODE_ID_1
4. org.apache.hadoop.mapred.TestJobClientGetJob.getJobRetriesCounter
5. org.apache.hadoop.hdfs.tools.offlineImageViewer.TestOfflineImageViewer.LOG
6. org.apache.hadoop.mapred.TestJobClientGetJob.lastGetJobRetriesCounter
7. org.apache.hadoop.hdfs.tools.offlineImageViewer.TestOfflineImageViewer.FILE_NODE_ID_2
8. org.apache.hadoop.hdfs.tools.offlineImageViewer.TestOfflineImageViewer.TEST_RENEWER
9. org.apache.hadoop.yarn.server.globalpolicygenerator.webapp.GPGPoliciesBlock.gpg
10. org.apache.hadoop.mapred.TestJobClientGetJob.TEST_ROOT_DIR
حضور متغیرهایی مانند runningJob و getJobRetriesCounter و lastGetJobRetriesCounter در صدر لیست، بسیار معنادار است. در برنامهنویسی همروند و توزیعشده مانند Hadoop MapReduce، Retries و Running flags دقیقا همان نقاطی هستند که جریان کد را تعیین میکنند. یک ابزار تست تصادفی ممکن است هزاران بار متغیرهای رشتهای بیاهمیت (مثل نام کاربر) را تغییر دهد و هیچ اتفاقی نیفتد. اما تغییر RetryCounter از 0 به 1، بلافاصله کد را وارد بلوکهای catch و مکانیزمهای Error Recovery میکند. مدل GNN ما بدون اینکه بداند Retry چیست، تنها از روی ساختار گراف فهمیده است که این متغیر به شاخههای حیاتی کد متصل است.
متغیرهایی مثل FILE_NODE_ID و TEST_ROOT_DIR و gpg نیز شناسایی شدند. اینها پارامترهای پیکربندی هستند. تغییر FILE_NODE_ID در ماژول HDFS (سیستم فایل توزیع شده) باعث میشود الگوریتمهای پردازش تصویر روی دادههای متفاوتی کار کنند. این متغیرها اغلب در ابتدای زنجیره اجرا قرار دارند و تغییر آنها Butterfly Effect در کل سیستم دارد. شناسایی خودکار این پارامترها تاییدی بر فرضیه متا-ژنراتور است؛ یعنی روابط علّی در سیستمهای نرمافزاری، امضای ساختاری مشخصی دارند که مدل آن را آموخته است.
برای ارزیابی کارایی روش پیشنهادی، نتیجه از دو منظر کیفی و کمی مورد بررسی قرار گرفت. در روشهای سنتی نظیر Fuzzing، انتخاب متغیرها برای Mutation اغلب تصادفی است. اگر از بین ۵۰,۰۰۰ متغیر Hadoop به صورت تصادفی انتخاب کنیم، احتمال بالایی وجود دارد که متغیرهایی نظیر DEBUG_STRING یا tempVar انتخاب شوند که تغییر آنها هیچ تاثیری بر منطق برنامه ندارد. متغیرهای انتخاب شده ما همگی دارای بار معنایی بالا هستند. این انتخابها، فضای جستجو را برای ابزار آزمون به شدت کاهش میدهد.
زیرگراف مربوط به متغیر PurgableSource.nextKey بررسی شد. این متغیر در مرکز یک ستاره قرار دارد که به متدهای متعددی در سیستم Metrics متصل است. این تایید میکند که بردار Z که مدل یاد گرفته است، همبستگی مستقیمی با Graph Centrality و پیچیدگی اتصالات دارد. مدل به درستی یاد گرفته است که گرههایی که پل ارتباطی بین ماژولهای مختلف هستند، کاندیداهای بهتری برای روابط علّی میباشند.
این پژوهش با هدف حل مشکل تولید داده آزمون در سیستمهای پیچیده شیءگرا، یک رویکرد نوین مبتنی بر تلفیق تحلیل ایستا و یادگیری عمیق را ارائه کرد. ما نشان دادیم که:
میتوان کد منبع عظیم و پیچیده را به یک گراف یکپارچه تبدیل کرد که تمام جزئیات تعاملات (وراثت، ترکیب، جریان داده) را حفظ کند.
مدلهای GNN بهویژه Autoencoderها قادرند ساختار پنهان و روابط علّی موجود در نرمافزار را بدون نیاز به اجرای کد یاد بگیرند.
متغیرهای استخراج شده برای تست به خوبی انتخاب شدند.
[1] M. Ghoreshi و H. Haghighi، "Object Coverage Criteria for Supporting Object-oriented Testing،" Research Square، 2022.
[2] P. Amman و j. Offutt، Introduction to software testing، United States of America: Cambridge University Press، 2008.
[3] W. C، Ouédraogo، L. Plein، K. Kaboré، A. Habib، J. Klein، D. Lo، T. F و Bissyandé، " Enriching automatic test case generation by extracting relevant test inputs from bug reports،" 2025.
[4] A. Fontes، G. Gay و R. Feldt، "Exploring the Interaction of Code Coverage and Non- Coverage Objectives in Search- Based Test Generation،" 2025.
[5] F. Tamagnan، A. Vernotte، F. Bouquet و B. Legeard، "Generation of Regression Tests From Logs With Clustering Guided by Usage Patterns،" 2023.
[6] S. Lukasczyk، FlorianKroiß و GordonFraser، "An empirical study of automated unit test generation for Python،" 2023.
[7] L. Taoa، X. Dang، J. Hu، D. Gong، G. Hao، X. Yao و B. Huang، "Optimizing test data generation using SI_CNNpro-enhanced MGA for mutation testing،" 2024.
[8] C. Weia، X. Yaoa، D. Gongb، H. Liuc و X. Dangd، "Set evolution basedtest datageneration for killing stubborn mutants،" 2024.
[9] C. Wei، X. Yao، D. Gong و H. Liu، "Test Data Generation for Mutation Testing Based on Markov Chain Usage Model and Estimation of Distribution Algorithm،" 2024.
[10] M. Ghoreshi و H. Haghighi، "An incremental method for extracting tests from object-oriented specification،" 2016.
[11] X. GUO، H. OKAMURA و T. DOHI، "Automated Software Test Data Generation With Generative Adversarial Networks،" 2022.
[12] AfonsoFontes و GregoryGay، "The integration of machine learning into automated test generation: A systematic mapping study،" 2022.
[13] J. Cao، H. Huang، F. Liu، Q. Zhang و Z. Hao، " Multi-task collaborative method based on manifold optimization for automated test case generation based on path coverage،" 2024.
[14] K. Lagemann، C. Lagemann، B. Taschler و S. Mukherjee، "Deep Learning of causal Structures in high dimensions under data limitations،" nature machine intelligence، 2023.
[15] L. B. a. M. Miraz، "TestFul: Automatic Unit-Test Generation for Java Classes،" 2010.