تا حالا شده فکر کنید همه چیز تحت کنترله، کدها دقیق نوشته شدن و هیچ چیز غیر منتظره ای نمی تونه اتفاق بیفته؟ بعد یهویی از جایی که اصلاً انتظارش رو نداشتید، همه چیز به هم بریزه؟ یک مشکل عجیب و غریب، یه مشکل پیش بینی نشده، یا حتی یک اتفاق غیرقابل تصور. این لحظه رو احتمالا اکثر ما تجربه کردیم و این دقیقا همون چیزیه که بهش میگیم "سورپرایززززز (غافلگیری)"
بیشتر مردم غافلگیری ها را دوست ندارند - به خصوص غافلگیری های منفی! شرکت ها معمولا از غافلگیری ها متنفرند. اکثر مدیران از غافلگیری بیزارند، چون این غافلگیری ها برنامه های دقیق آن ها را برهم می زند و ریسک های غیرمنتظره ای دارند. همچنین کارمندها نیز معمولا از غافلگیری ها متنفرند، چرا که اغلب به معنای کار اضافی و استرس زا است و گاهی حتی امنیت شغلی آن ها را به خطر می اندازد.
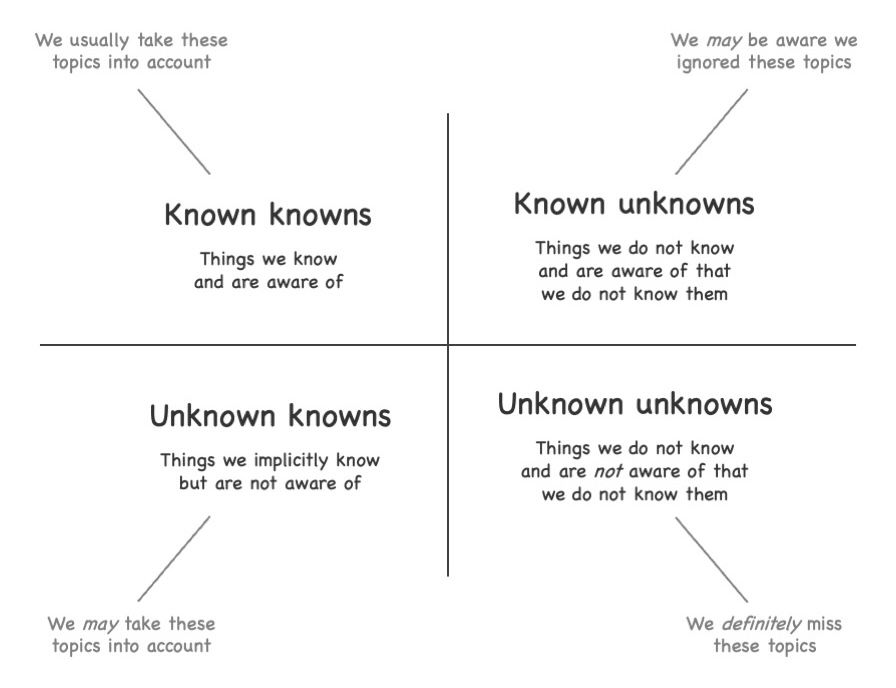
اما هرچقدر هم تلاش کنیم، غافلگیری ها اتفاق می افتند. البته افرادی هم هستند که فکر می کنند اگر به اندازه کافی برنامه ریزی کنیم، آن ها اتفاق نمی افتند. اینجاست که مدل known-unknown وارد می شه. مدلی که کمک می کنه متوجه بشیم چرا حتی بهترین برنامه ریزی ها هم نمی تونه ما رو از غافلگیری های اجتناب ناپذیر محافظت کنه و چطور می شه با این واقعیت کنار اومد.
معلوم های معلوم (Known knowns): چیزهایی که می دانیم و از وجودشان آگاهیم. این ها دانش صریح ما هستند. معمولا این موارد را در برنامه ریزی خود لحاظ می کنیم. هرچه برنامه ریزی دقیق تر باشد، لیست "معلوم های معلوم" ما کامل تر خواهد بود.
معلوم های نامعلوم (Unknown knowns): چیزهایی که به طور ضمنی می دانیم اما از وجودشان آگاه نیستیم. این ها دانش ضمنی ما هستند. اگر مشکلی پیش بیایید معمولا حس ششم ما را به سمت درست هدایت می کنند. ممکن است برخی از این موارد را در برنامه ریزی خود لحاظ کنیم، اما به دلیل سختی تبدیل دانش ضمنی به دانش صریح، احتمالا تعدادی از آن ها را از دست بدهیم.
نامعلوم های معلوم (Known unknowns): چیزهایی که نمی دانیم اما از ندانستنشان آگاهیم. اگر سخت کار کنیم، ممکن است برخی از موارد را شناسایی کرده و آن ها را به "معلوم های معلوم" تبدیل کنیم. شاید دیگران بتوانند به پر کردن بخشی از شکاف ها کمک کنند. با این حال، احتمال زیادی وجود دارد که برخی از آن ها را از دست بدهیم.
نامعلوم های نامعلوم (Unknown unknowns): چیزهایی که نمی دانیم و از ندانستنشان هم آگاه نیستیم. فرقی ندارد چقدر تلاش کنیم، باز هم آن ها را از دست می دهیم.
اگر واقعا سخت تلاش کنیم و خوش شانس باشیم، شاید بتوانیم تمام اتفاقات و موقعیت های نامطلوبی که در سه بخش اول پنهان هستند را شناسایی کنیم. اما معمولا این کار را نمی کنیم. معمولا حتی با سخت ترین تلاش ها، برخی از این موارد را از دست می دهیم. برای مثال سعی کنید تمام اقلام موجود در آشپزخانه تان را از حفظ فهرست کنید. احتمالا چند مورد را فراموش خواهید کرد، معلوم های نامعلوم یا نامعلوم های معلوم.
1- پذیرش واقعیت و تغییر ذهنیت
تو اولین قدم باید بپذیریم که غافلگیری ها اجتناب ناپذیر هستند. یعنی اینکه قبول کنیم هیچ سیستمی بدون نقص نیست و همیشه شرایطی وجود داره که ممکنه پیش بینی نشده باشه. برای مثال وقتی Netflix شروع به استفاده از Chaos Monkey کرد، هدفش این بود که با ایحاد مشکلات عمدی در سرورها، تیم ها رو برای غافلگیری های احتمالی آماده کنه. خب این کار به تیم ها کمک کرد که به جای ترسیدن از خطاها، یک واکنش سریع و موثر داشته باشند.
اطلاعات بیشتر درمورد Chaos Monkey: lnkd . in / diHuQ5T5
2- آماده سازی برای ناشناخته ها
با اینکه نمی تونیم همه ناشناخته ها رو شناسایی کنیم، ولی میتونیم سیستم هایی رو طراحی کنیم که آماده مواجهه با این اتفاقات باشن.
Game Day Exercises: مشابه شبیه سازی مشکلات در دنیای واقعی، تیم ها می تونن سناریوهایی مثل قطع کانکشن به دیتابیس یا مشکل در سیستم های وابسته رو شبی سازی کنن تا آمادگی بیشتری پیدا کنن.
فرهنگ Blameless: وقتی یک باگ پیش بینی نشده باعث مشکل در سیستم میشه، تمرکز باید روی حل مسئله باشه نه پیدا کردن مقصر. این فرهنگ باعث میشه افراد بدون ترس مشکلات احتمالی رو مطرح کنن.
اطلاعات بیشتر درمورد فرهنگ Blameless: lnkd .in /dyDRR92X
3- استفاده از داده ها و ابزارها
برای کاهش اثر غافلگیری ها، می تونیم از ابزارهایی مثل Datadog برای مانیتور کردن و Post-Mortem برای بررسی دلایل اصلی و مستند سازی مشکل بعد از هر غافلگیری برای کاهش احتمال تکرارش استفاده کنیم.
4- طراحی انعطاف پذیر و ماژولار
باید سیستم ها رو طوری طراحی کنیم که هنگام وقوع مشکلات، کل سیستم با مشکل مواجه نشه. مثلا با استفاده از Resilience Pattern هایی مثل Circuit Breaker از افزایش خطاها جلوگیری کنیم. یا با طراحی ماژولار، در صورت بروز مشکل در یک قسمت از انتقال اون به بخش های دیگه جلوگیری کنیم.
اطلاعات بیشتر درمورد Circuit Breaker Pattern: lnkd .in /d2wAtuAW
5- تست و یادگیری مداوم
تست های مستمر و یادگیری از گذشته، بهترین ابزارهای ما برای کاهش تاثیرات هستن.
Chaos Engineering: ابزارهایی مثل Gremlin یا Chaos Monkey میتونن سناریوهای اختلال رو شبی سازی کنن و سیستم رو در برابر شرایط پیش بینی نشده مقاوم تر کنن.
بهبود مداوم: مستندسازی مشکلات و به روزرسانی فرآیندها به ما کمک میکنه که برای چالش های آینده آماده تر باشیم.
برای مثال تیم Dev ممکنه بعد از بروز یه مشکل، تست های جدیدی رو اضافه کنه که اون سناریو رو پوشش بده
در پایان، باید بدانیم که در دنیای نرم افزار، غافلگیری ها همیشه بخشی از واقعیت هستن. اما با پذیرش این واقعیت، آمادهسازی مناسب، استفاده از ابزارها و طراحی سیستم های مقاوم، می تونیم اثر این غافلگیری ها رو به حداقل برسونیم. مهم تر از همه، باید از هر غافلگیری به عنوان فرصتی برای یادگیری و رشد استفاده کنیم، چون تنها راه پیشرفت در دنیای ناشناخته ها، پذیرش و مدیریت اون هاست.
در نهایت، غافلگیری ها را نمیتوان حذف کرد، اما میتوان از آنها برای ساختن سیستم هایی مقاوم تر و تیم هایی قوی تر استفاده کرد.