دنبال راهنمایی برای رسیدن به شغل رویاییتان و بهبود مهارتهای یادگیری عمیق خود هستید؟ دیگر لازم نیست دنبال چیزی بگردید. این مقاله پاسخ ۲۰ سوال رایج مصاحبه برای موقعیتهای یادگیری عمیق را ارائه میدهد و به شما کمک میکند تا با کمی تمرین در مصاحبهها عالی عمل کنید.
سوالات عمومی یادگیری عمیق معمولاً مربوط به درک این حوزه، وجه تمایز آن از سایر حوزههای هوش مصنوعی، ارتباط مسائل دنیای واقعی با راهحلهای یادگیری عمیق و درک چالشها و محدودیتهای آنها است.
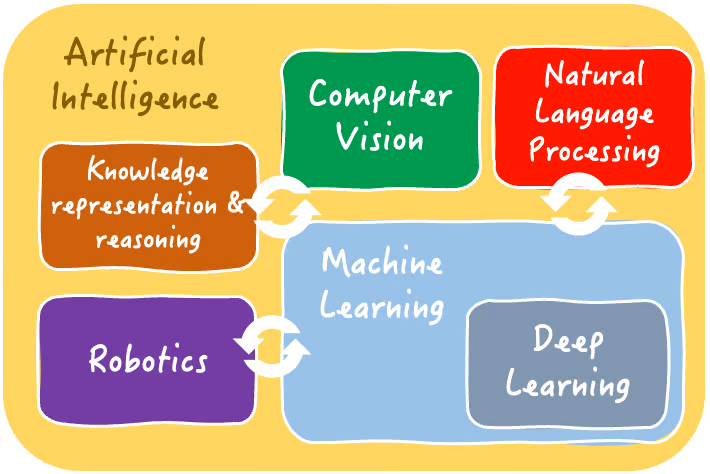
یادگیری عمیق زیرمجموعهای از یادگیری ماشین و هوش مصنوعی به طور کلی است. این شامل آموزش مدلهای بزرگ مبتنی بر شبکههای عصبی مصنوعی بر روی دادهها است.
مدلها یاد میگیرند که وظایف پیشبینی و استنتاج چالشبرانگیز (مانند طبقهبندی، رگرسیون، تشخیص اشیاء در تصاویر و غیره) را با کشف خودکار الگوها و ویژگیهای پیچیده در دادهها حل کنند. این کار با تقلید از ساختارهای داخلی پیچیده در مغز انسان انجام میشود.
دوره آموزشی «درک هوش مصنوعی» ما، حوزهها و وظایف قابل حل هوش مصنوعی، از جمله یادگیری عمیق، را به طور جامع رمزگشایی میکند.
راهحلهای یادگیری عمیق یا Deep Learning در مسائلی که دادهها پیچیدگی بالایی دارند، مثلاً در دادههای بدون ساختار یا با ابعاد بالا یا high-dimensional، برجسته هستند.
همچنین این روش انتخاب ارجح برای مسائلی با حجم انبوه دادهها یا نیازمند ثبت الگوهای ظریف است: اغلب اوقات، آنها میتوانند در استخراج و درک ویژگیهای معنادار دادهها که رویکردهای یادگیری ماشین ممکن است نتوانند آنها را پیدا کنند، موفق شوند.
در اینجا چند نمونه از مسائلی که با راهحلهای یادگیری عمیق قابل حل هستند، آورده شده است:
طبقهبندی تصاویر گونههای جانوری یا گیاهی
پیشبینی بلندمدت قیمتهای بازار سهام
تشخیص چهره در تصاویر
وظایف پردازش زبان طبیعی مانند تشخیص صدا، ترجمه زبان و موارد دیگر
با این حال، توجه داشته باشید که برای بسیاری از وظایف و مجموعه دادههای سادهتر، مدلهای یادگیری ماشین سبک مانند درختهای تصمیمگیری و رگرسیونها ممکن است بیش از حد کافی باشند، و این امر آنها را به دلیل آسانتر و ارزانتر بودن آموزش و استقرار، به انتخاب بهتری نسبت به مدلهای یادگیری عمیق تبدیل میکند.
مدلهای یادگیری عمیق معمولاً به مهارتهای کامل آمادهسازی و پردازش دادهها نیاز دارند؛ از این رو، ممکن است مقاله ِ موجود در لینک روبرو، در مورد مصاحبههای مهندسی داده برای شما مفید باشد.
تصمیمگیری در مورد یک رویکرد یادگیری عمیق مناسب به عوامل مختلفی مانند ماهیت دادهها، پیچیدگی مسئله و منابع محاسباتی موجود بستگی دارد.
مراحل زیر دستورالعملی ساده اما مؤثر برای کمک به شما در انجام این انتخاب مهم هستند:
1- یک تحلیل کامل از ویژگیهای دادههای خود انجام دهید. آیا ساختار یافته هستند یا بدون ساختار؟ آیا وابستگیهای زمانی یا مکانی وجود دارد؟ متغیر(های) هدفی که میخواهید با مدل خود پیشبینی کنید کدامند؟
2 - بر اساس تحلیل دادهها، مناسبترین نوع معماری یادگیری عمیق را انتخاب کنید. به عنوان مثال، شبکههای عصبی کانولوشن (CNN) در پردازش دادههای بصری عالی هستند، در حالی که شبکههای عصبی بازگشتی (RNN) به ویژه در دادههای ترتیبی مؤثر هستند.
3 - عوامل دیگری مانند تفسیرپذیری مدل، مقیاسپذیری و در دسترس بودن دادههای برچسبگذاری شده برای آموزش را در نظر بگیرید. معماریهای مختلف یادگیری عمیق این جنبهها را تا درجات مختلفی در نظر میگیرند.

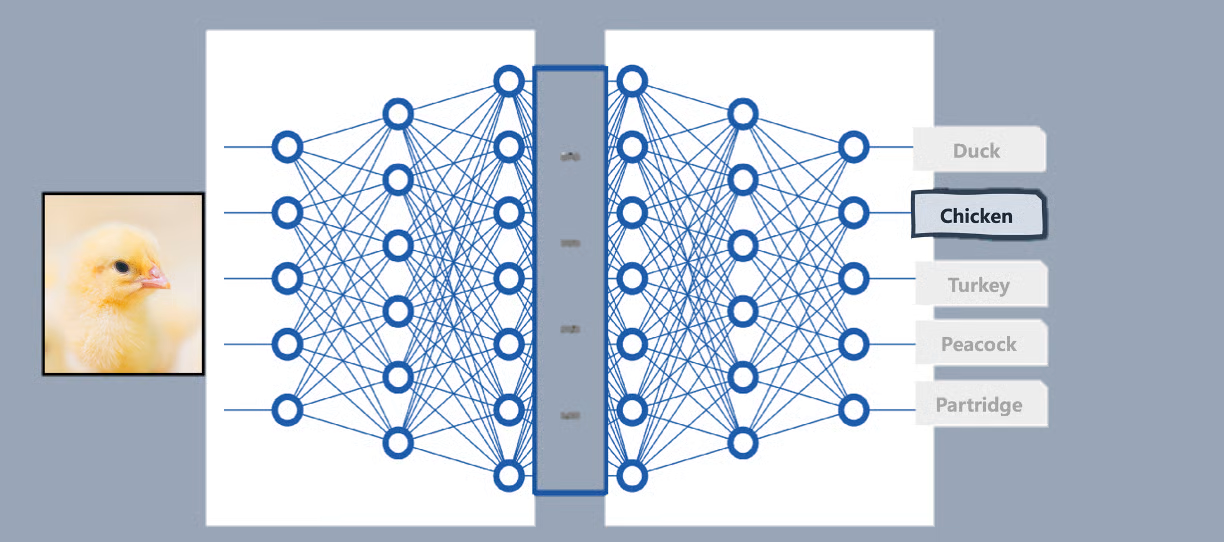
طراحی یک معماری یادگیری عمیق متناسب با یک کار خاص مانند طبقهبندی (classification) شامل انتخاب تعداد و اندازه مناسب لایههای نورونها و همچنین انتخاب توابع فعالسازی یا activation functions مناسب است.
این تصمیمات معمولاً بر اساس ویژگیهای دادهها گرفته میشوند. برای طبقهبندی تصویر، ممکن است از مجموعهای از لایههای کانولوشنی در معماری خود برای ثبت الگوهای بصری مانند رنگها (یا ترکیبی از رنگها)، شکلها، لبهها و غیره استفاده کنید.
لایه بالایی که در انتهای معماری یادگیری عمیق شما (سر مدل) قرار دارد نیز به وظیفه شما بستگی دارد، زیرا باید برای تولید خروجی مطلوب طراحی شود.
به عنوان مثال، برای یک مسئله طبقهبندی تصویر مانند طبقهبندی تصاویر جوجهها به گونههای پرنده، این لایههای آخر باید یک تابع فعالسازی softmax داشته باشند که احتمالات کلاس را برای تعیین محتملترین کلاس گونههای پرندهای که تصویر مورد تجزیه و تحلیل به آن تعلق دارد، خروجی میدهد.
چالشهای رایجی که ممکن است مانع از کاربرد موفقیتآمیز مدلهای یادگیری عمیق در دنیای واقعی شوند، شامل بیشبرازش یا overfitting، گرادیانهای ناپدیدشونده و انفجاری یا vanishing and exploding gradients و لزوم وجود مقادیر زیادی از دادههای برچسبگذاریشده برای آموزش هستند. خبر خوب این است که به لطف تلاشهای تحقیقاتی مداوم، رویکردهایی برای رسیدگی به آنها وجود دارد.
بیشبرازش (Overfitting) زمانی اتفاق میافتد که یک مدل به گونهای یاد میگیرد که «بیش از حد» نحوه ظاهر شدن دادههای آموزشی را به خاطر میسپارد، بنابراین بعداً برای انجام استنتاجهای صحیح در مورد هرگونه داده آینده و نادیده، دچار مشکل میشود. برای رفع این مشکل، تکنیکهایی وجود دارد که بر کاهش پیچیدگی مدل، مانند منظمسازی (regularization) یا محدود کردن میزان یادگیری مدل از دادهها، مثلاً از طریق توقف زودهنگام (early stopping)، متمرکز هستند.
گرادیانهای ناپدید شونده و انفجاری (Vanishing and exploding gradients) مربوط به مسائل همگرایی به سمت راهحلهای غیربهینه در طول فرآیند بهروزرسانی وزن هستند که زیربنای فرآیند آموزش است. برش گرادیان
(Gradient clipping) و توابع فعالسازی (activation functions) پیشرفته میتوانند به کاهش این مشکل کمک کنند.
اگر چالش در دادههای برچسبگذاری شده محدود است، به ترتیب تکنیکهای یادگیری انتقالی (transfer learning) و افزودن داده (data augmentation) را برای مهار مدلهای از پیش آموزش دیده یا تولید دادههای مصنوعی بررسی کنید.
علاوه بر این راهحلهای خاص برای هر مشکل، مطمئن شوید که سازوکارهای منظم نظارت و تنظیم دقیق مدل را ایجاد کردهاید تا عملکرد خوب در دراز مدت تضمین شود.
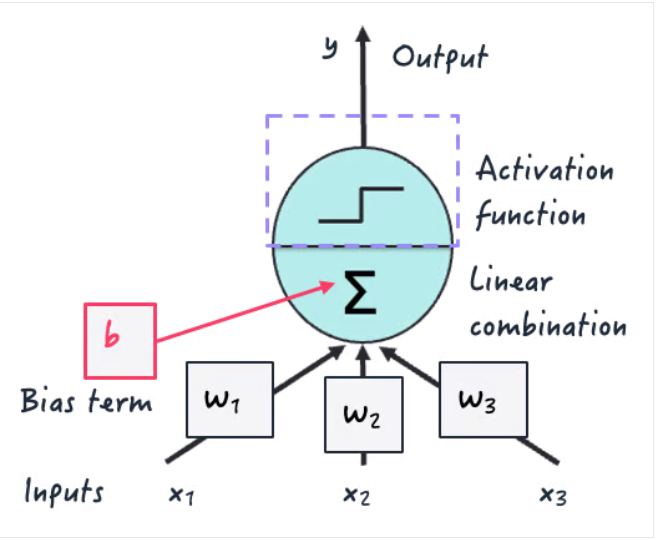
توابع فعالسازی (Activation functions) ، توابع ریاضی هستند که در تمام معماریهای مدرن شبکههای عصبی عمیق استفاده میشوند. این توابع در سطح نورون، در طول فرآیند نگاشت چندین ورودی نورون به یک مقدار خروجی که به نورونهای لایه بعدی ارسال میشود، رخ میدهند.
آنها در مدلهای یادگیری عمیق بسیار مهم هستند زیرا غیرخطی بودن را معرفی میکنند، که برای قادر ساختن آنها به یادگیری روابط و الگوهای پیچیده در دادهها در طول آموزش حیاتی است.
در غیر این صورت، آنها با اعمال ترکیبهای خطی متوالی از ورودیها، چیزی بیش از الگوهای خطی از دادهها یاد نمیگیرند - درست مانند مدلهای رگرسیون خطی کلاسیک!
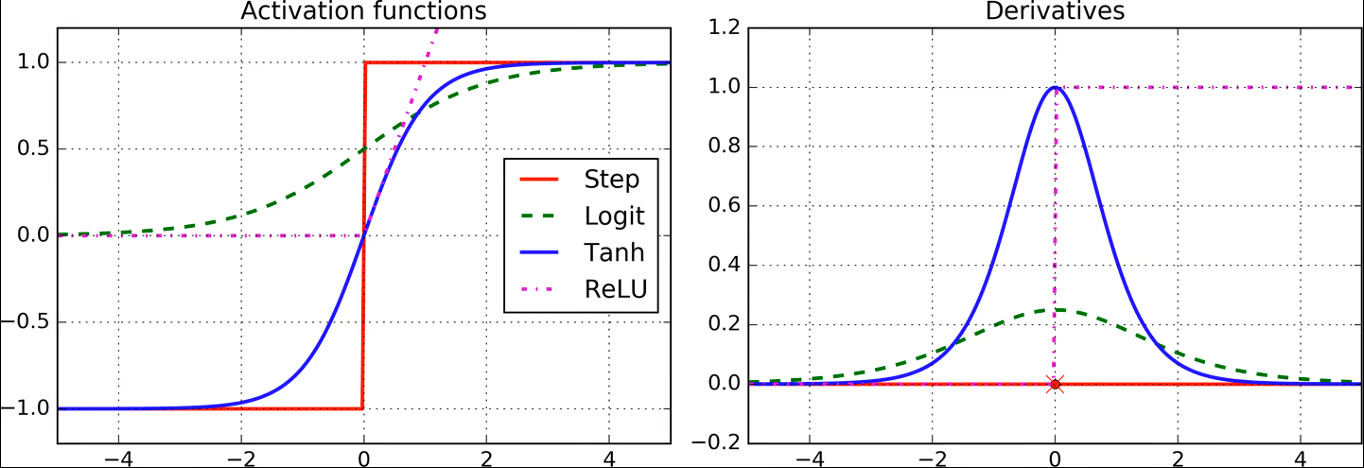
نمونههایی از توابع فعالسازی محبوب عبارتند از تابع فعالسازی لجستیک (logit)، تانژانت هیپربولیک (tanh) و واحد خطی یکسو شده (ReLU)، همانطور که در زیر نشان داده شده است.
عملکرد مدلهای یادگیری عمیق را میتوان با استفاده از معیارهای رایج یادگیری ماشین وابسته به وظیفه ارزیابی کرد.
برای طبقهبندی، معیارهایی مانند دقت، صحت، یادآوری، امتیاز F1 و مساحت زیر منحنی (AUC) را در نظر بگیرید. در همین حال، برای رگرسیون، میتوانیم از معیارهای خطا
مانند خطای جذر میانگین مربعات (RMSE) - Root Mean Square Error استفاده کنیم.
این معیارها باید برای مقایسه پیشبینیهای مدل با برچسبهای واقعی یا مدلهای مرجع استفاده شوند. برای مدلها و کاربردهای پیشرفتهتر مانند NLP، طیف وسیعی از معیارهای خاص وظیفه زبانی مانند امتیاز BLEU برای ترجمه، امتیاز ROUGE برای خلاصهسازی و غیره وجود دارد.
یادگیری عمیق در طیف گستردهای از کاربردهای دنیای واقعی استفاده میشود، که برخی از آنها عبارتند از:
تشخیص تصویر و اشیاء در جادهها برای وسایل نقلیه خودران
پردازش و درک زبان طبیعی برای چتباتهای پشتیبانی مشتری
تحلیلهای پیشبینیکننده برای توصیههای شخصیسازیشده در خردهفروشی
تشخیص پزشکی بر اساس تصاویر اشعه ایکس
سوالات مصاحبه برای یک نقش یادگیری عمیق با محوریت مهندسی، بر جنبههایی مانند چارچوبهای برنامهنویسی، کتابخانهها و ابزارها تمرکز خواهد داشت.
برای ساخت یک شبکه عصبی feedforward ساده برای طبقهبندی تصویر در Tensorflow، میتوانیم با تعریف لایه به لایه معماری مدل با استفاده از Tensorflow Sequential API شروع کنیم.
این شامل تعیین تعداد مناسب نورونها و توابع فعالسازی در هر لایه و تعریف لایه نهایی (لایه خروجی) با فعالسازی softmax میشود.
سپس، مدل را با مشخص کردن یک تابع زیان مناسب مانند
آنتروپی متقاطع دستهبندیشده (categorical cross-entropy) ، یک بهینهساز مانند Adam و معیارهای اعتبارسنجی، قبل از آموزش آن بر روی دادههای آموزشی در طول تعداد مشخصی از دورهها، کامپایل میکنیم. پس از ساخت مدل، عملکرد آن بر روی مجموعه اعتبارسنجی قابل ارزیابی است.
Tensorflow معمولاً همراه با Keras API استفاده میشود که
پس از تکمیل دوره Advanced Deep Learning with Keras میتوانید بر آن مسلط شوید.
برای مدیریت feedforward در یک مدل یادگیری عمیق که با PyTorch پیادهسازی شده است، یک استراتژی رایج، استفاده از تکنیکهای منظمسازی مانند منظمسازی L1 یا L2 با اضافه کردن عبارات جریمه به تابع زیان است.
از طرف دیگر، میتوان لایههای حذف را برای غیرفعال کردن تصادفی نورونها در طول آموزش معرفی کرد؛ این کار از اتکای بیش از حد مدل به ویژگیهای خاص استخراج شده از دادهها جلوگیری میکند.
این دو استراتژی را میتوان با توقف زودهنگام برای نهایی کردن آموزش، زمانی که عملکرد اعتبارسنجی شروع به کاهش میکند، ترکیب کرد.
آیا علاقهمند به تقویت مهارتهای PyTorch خود هستید؟ پس حتماً این مقدمهای بر یادگیری عمیق را در دوره PyTorch بررسی کنید.
VGG، BERT یا ResNet نمونههای شناختهشدهای از مدلهای از پیش آموزشدیده (pre-trained) هستند که میتوانند برای اهداف یادگیری انتقالی و تنظیم دقیق بارگذاری شوند. بهطور خاص، این فرآیند شامل جایگزینی سر مدل، یعنی لایه طبقهبندی نهایی، با یک لایه جدید متناسب با وظیفه هدف است.
پس از این تغییر ساختاری جزئی در معماری مدل، ما آن را با استفاده از نرخ یادگیری پایین، روی یک مجموعه داده جدید آموزش مجدد میدهیم تا وزنهای مدل را با وظیفه جدید تطبیق دهیم، در حالی که ویژگیهای اصلی که در ابتدا توسط مدلهای از پیش آموزش دیده آموخته شدهاند، عمدتاً حفظ میشوند.
در ادامه سوالات احتمالی که مصاحبهکننده ممکن است برای موقعیتی که شامل ساخت یا مدیریت راهحلهای یادگیری عمیق در بینایی کامپیوتر مانند برنامههای پردازش تصویر است، از شما بپرسند، آورده شده است.
CNNها معماریهای تخصصی یادگیری عمیق برای پردازش دادههای بصری هستند. لایههای کانولوشن روی هم قرار داده شده و عملیات اساسی آنها روی دادههای تصویر به گونهای طراحی شدهاند که از قشر بینایی در مغز حیوانات تقلید کنند.
CNNها در کارهایی مانند طبقهبندی تصویر، تشخیص اشیا و تقسیمبندی تصویر عالی عمل میکنند. در اینجا شرح مختصری از موارد استفاده برای هر یک از این کارها آمده است:
طبقهبندی تصویر یا Image classification : مشخص میکند که آیا یک تصویر سگ است یا گربه، تا سیستمهای شناسایی و نظارت خودکار حیوانات خانگی بتوانند از آن استفاده کنند.
تشخیص شیء یا Object detection : امکان مکانیابی و شناسایی عابران پیاده را به صورت بلادرنگ توسط وسایل نقلیه خودران فراهم میکند.
قطعه بندی تصویر یا Image segmentation: مرزهای تومور را در تصاویر پزشکی مشخص میکند تا بیماران سرطانی را به طور دقیق تشخیص داده و درمان کند.
لایههای کانولوشن (Convolution layers) در CNNها مسئول استخراج ویژگی از تصاویر ورودی هستند. آنها مجموعهای از وزنهای قابل یادگیری به نام فیلتر یا هسته (kernels) را برای تشخیص الگوها و ویژگیهایی مانند لبهها، شکلها و بافتها به همراه اطلاعات و روابط مکانی آنها اعمال میکنند و از این طریق نمایشهای بصری سلسله مراتبی را یاد میگیرند.
در همین حال، لایههای ادغام یا pooling layers ، نقشههای ویژگی (نمایشهای تصویر میانی) خروجی توسط لایههای کانولوشن را نمونهبرداری میکنند. به عبارت دیگر، ابعاد یا وضوح مکانی اصلی آنها کاهش مییابد در حالی که اطلاعات مهم استخراج شده حفظ میشوند.
ترکیب لایههای کانولوشن متوالی با لایههای ادغام در CNN به افزایش مقاومت در برابر تغییرات ورودیها، کاهش پیچیدگی محاسباتی در زمان آموزش و استنتاج و جلوگیری از مسائلی مانند بیشبرازش یا overfitting کمک میکند.
در میان چالشها و محدودیتهای معمول در مدلهای یادگیری عمیق، مثالهای زیر به ویژه در مدلهای بینایی کامپیوتر مانند CNNها برجسته میشوند:
کمیت و کیفیت دادهها: مدلهای یادگیری عمیق برای بینایی کامپیوتر برای آموزش صحیح به مجموعه دادههای برچسبگذاری شده بسیار بزرگی نیاز دارند. این دادهها همچنین باید کیفیت کافی داشته باشند: تصاویر با وضوح بالا و بدون نویز، عاری از مشکلاتی مانند تاری یا نوردهی بیش از حد و غیره.
برازش بیش از حد یا Overfitting : CNNها میتوانند مستعد به خاطر سپردن نویز یا جزئیات خاص (گاهی اوقات نامربوط) در دادههای آموزش بصری باشند که منجر به تعمیم ضعیف میشود.
منابع محاسباتی: آموزش معماریهای CNN عمیق به دلیل تعداد زیاد لایهها و پارامترهای قابل آموزش، به منابع محاسباتی قابل توجهی نیاز دارد. بسیاری از آنها برای آموزش روان به GPUها و ظرفیتهای حافظه زیاد نیاز دارند.
قابلیت تفسیر: درک چگونگی پیشبینی مدلها (به ویژه پیشبینیهای اشتباه) در کارهای پیچیدهای مانند تشخیص تصویر، همچنان یک چالش است.
در اینجا چند سوال احتمالی وجود دارد که مصاحبهکننده ممکن است برای موقعیتی که شامل استفاده از فناوریهای یادگیری عمیق در برنامههای NLP است، از شما بپرسد.
ترنسفورمرها (Transformers) خانوادهای پیشرفته از معماریهای یادگیری عمیق و پیشرفتهترین فناوریهای فعلی برای پرداختن به طیف وسیعی از مسائل چالشبرانگیز NLP هستند. مکانیسمهای توجه (Attention mechanisms) برای معماریهای ترنسفورمر که زیربنای مدلهای زبان بزرگ (LLM) مانند BERT و GPT هستند، محوری هستند و تا حد زیادی مسئول موفقیت آنها میباشند.
ترنسفورمرها توانایی ثبت الگوهای پیچیده، اطلاعات زمینهای و وابستگیهای دوربرد بین عناصر یک متن ورودی را دارند و به طور قابل توجهی بر مشکلات موجود در راهحلهای قبلی مانند حافظه محدود در RNNها (شبکههای عصبی بازگشتی) غلبه میکنند.
مکانیزمهای توجه یا Attention mechanisms اساساً اهمیت هر نشانه را در یک توالی، بدون نیاز به پردازش آن به صورت نشانه به نشانه، میسنجند.
این جزء مهم ترنسفورمرها منجر به پیشرفتهای قابل توجهی در کارهایی مانند طبقهبندی متن، تولید زبان و خلاصهسازی متن شده است و حوزه LLMها و هوش مصنوعی را به طور کلی متحول کرده است.
دوره Datacamp در مورد مقدمهای بر LLMها در پایتون، شما را نه تنها به مهارتهای عملی برای ساخت و بهرهبرداری از LLMها، بلکه به درک کاملی از مفاهیم اصلی پیرامون LLMها و معماریهای ترانسفورماتور مجهز میکند.
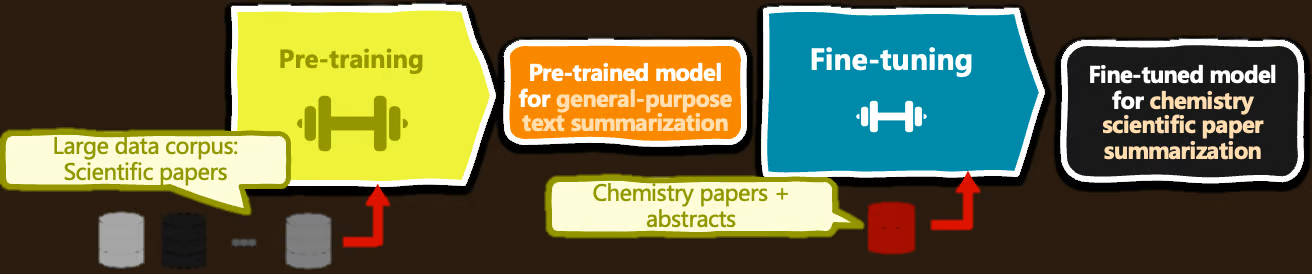
مدل پیشآموزش شده (Model pre-training) ، یک مدل یادگیری عمیق، مانند BERT، را برای طبقهبندی متن، روی مجموعهای بزرگ از دادههای متنی (میلیونها تا میلیاردها متن نمونه) آموزش میدهد تا نمایشهای زبانی را برای درک زبان عمومی یاد بگیرد.
مدل تنظیم دقیق شده (Model fine-tuning) از سوی دیگر، شامل گرفتن یک مدل از پیش آموزشدیده و تنظیم دقیق پارامترهای آموختهشده آن در یک برنامه NLP زمینه ای خاص، مانند تحلیل احساسات نظرات هتلها، و ... است.
از آنجایی که تنظیم دقیق (fine-tuning) معمولاً برای موارد استفاده خاص انجام میشود، نیاز به استفاده از یک مجموعه داده کوچک و مختص به دامنه از نمونههای متنی برچسبگذاری شده دارد، در نتیجه وزنها در بخشهایی از مدل برای یادگیری جزئیات وظیفه هدف و بهبود عملکرد مدل در آن زمینه خاص بدون هزینه محاسباتی و الزامات دادهای آموزش یک مدل از ابتدا، تطبیق داده میشوند.
معماری BERT نوع سادهشدهای از تانسفورمر رمزگذار-رمزگشای (encoder-decoder) اصلی است
که ترنسفورمر فقط انکد شده (encoder-only transformer) نامیده میشود.


پشته انکد (encoder stack) از چندین لایه انکد تشکیل شده است (به نمودار بالا مراجعه کنید). در هر لایه، (زیر)لایههایی از مکانیسمهای خودتوجهی (self-attention) و شبکههای عصبی feedforward وجود دارد. کلید فرآیند درک زبان که توسط BERT انجام میشود، در جریان توجه یا attention دو طرفه است که به صورت تکراری در انکدر اعمال میشود، به طوری که وابستگیهای بین کلمات در یک توالی ورودی در هر دو جهت ثبت میشوند. اتصالات عصبی feedforward ، این وابستگیهای آموخته شده را به الگوهای زبانی پیچیدهتر "به هم پیوند میدهند".
علاوه بر این ویژگی کلی مبدلهای فقط کد شده، BERT با ترکیب
یک رویکرد مدلسازی زبان ماسک شده Masked Language Modelling (MLM) مشخص میشود. این مکانیسم در طول پیشآموزش (pre-training) برای ماسک کردن (mask) برخی از کلمات به صورت تصادفی استفاده میشود و در نتیجه مدل را مجبور میکند تا پیشبینی کلمات ماسک شده (masked) را بر اساس درک زمینه اطراف آنها یاد بگیرد.
بیایید با سه سوالی که ممکن است در صورت درخواست برای یک نقش پیشرفته یادگیری عمیق از شما پرسیده شود، بحث را به پایان برسانیم.
استراتژی ترکیبی زیر را میتوان برای به حداکثر رساندن عملکرد مدل یادگیری عمیق در مواجهه با مشکل رایج دادههای آموزشی محدود پیادهسازی کرد:
با تنظیم دقیق مدلهای از پیش آموزشدیده (fine-tuning pre-trained) روی یک وظیفه مشابه با دامنه خاص که مدل اصلی برای آن آموزش دیده است، از یادگیری انتقالی transfer learning بهره ببرید.
یادگیری نیمهنظارتی semi-supervised و خودنظارتی self-supervised را برای به دست آوردن مجموعه دادههای بدون برچسب که بیشترین تعداد را دارند، بررسی کنید.
مدلهای افزودن داده Data augmentation و مولد generative models میتوانند به تولید نمونههای داده مصنوعی برای غنیسازی مجموعه برچسبگذاری شده اصلی کمک کنند.
روشهای یادگیری فعال Active learning را میتوان برای پرسوجو از کاربران برای به دست آوردن نمونههای برچسبگذاری شده اضافی بر روی مجموعهای از دادههای بدون برچسب استفاده کرد.
استقرار راهکارهای یادگیری عمیق در مقیاس وسیع در محیطهای تولیدی نیازمند توجه به ملاحظات متعددی است که سه مورد از آنها عبارتند از:
مقیاسپذیری و عملکرد مدل یا Model scalability and performance بسیار مهم هستند و نیازمند معماریهای کارآمد و رویکردهای بهینهسازی برای مقابله با جریانهای داده بزرگ در زمان واقعی میباشند.
استحکام و قابلیت اطمینان یا Robustness and reliability در ایجاد رویههای آزمایش و اعتبارسنجی برای تضمین عملکرد پایدار در طول زمان و بین سناریوهای مختلف بسیار مهم هستند.
تضمین استانداردهای حریم خصوصی و امنیت دادهها یا data privacy and security standards و همچنین رعایت مقررات یا regulatory compliance برای محافظت از اطلاعات حساس. اینها جنبههای حیاتی برای رعایت رفتار مسئولانه سیستم و استفاده از سیستم یادگیری عمیق و جلب اعتماد کاربران هستند.
سایر ملاحظات مهم برای استقرار مدلهای یادگیری عمیق در محیط عملیاتی شامل زیرساختهای سختافزاری و شبکه، نظارت بر سیستم و ادغام یکپارچه با چارچوبهای نرمافزاری موجود است.
پیشرفتهای اخیر در یادگیری عمیق، پتانسیل تغییر عمیق صنایع متعدد و حتی ایجاد صنایع جدید را دارند.
مکانیسمهای توجه یا Attention mechanisms مورد استفاده در معماریهای ترنسفورمر transformer architectures پشت LLMها، انقلابی در حوزهی NLP ایجاد میکنند، مرزهای وظایف NLP را به طور قابل توجهی جابجا میکنند و تعاملات پیچیدهتر انسان و ماشین را از طریق راهحلهای هوش مصنوعی مکالمهای، پاسخ به پرسش و موارد دیگر امکانپذیر میسازند. گنجاندن اخیر Retrieval Augmented Generation (RAG) در این معادله، به LLMها در تولید زبان صادقانه و مبتنی بر شواهد کمک بیشتری میکند.
یادگیری تقویتی یا Reinforcement learning یکی از نویدبخشترین روندهای هوش مصنوعی است، زیرا اصول آن از اصول اولیه یادگیری انسان تقلید میکند. ادغام آن با معماریهای یادگیری عمیق، به ویژه مدلهای مولد (generative models) مانند شبکههای مولد تخاصمی یا generative adversarial networks ، امروزه در خط مقدم تحقیقات علمی قرار دارد. نامهای بزرگی مانند OpenAI، گوگل و مایکروسافت، این دو حوزه هوش مصنوعی را در جدیدترین راهحلهای نوآورانه خود که قادر به تولید محتوای «شبیه به واقعیت» در قالبهای مختلف هستند، ترکیب میکنند.
این پیشرفتها و سایر پیشرفتهای اخیر، استفاده از هوش مصنوعی توسط جامعه را به طرز چشمگیری دموکراتیک کردهاند، از این رو، میتوان اخلاق، جنبههای قانونی و مقررات هوش مصنوعی را به عنوان یک موضوع کلیدی برای کار بر روی آن در نظر گرفت تا تأثیر مفید راهحلهای یادگیری عمیق در سراسر جامعه تضمین شود.
برای نتیجهگیری از این بررسی سوالات رایج مصاحبه یادگیری عمیق، یک نکته واضح این است که کلید موفقیت به ترکیبی از مبانی نظری، تسلط قوی بر مهارتهای عملی و بهروز ماندن با آخرین پیشرفتها بستگی دارد.
یادگیری عمیق فقط مربوط به الگوریتمها، مدلها و انتخابهای طراحی معماری نیست. این در مورد شناسایی بهترین راهحلها برای حل مشکلات دادههای دنیای واقعی است.
و یادگیری مداوم کلید اصلی است. دیتاکمپ یک مسیر کامل مهارتهای یادگیری عمیق در پایتون و همچنین دو مسیر یادگیری عمیق با محوریت کاربرد ارائه میدهد: پردازش تصویر و پردازش زبان طبیعی. این مسیرها یک نقشه راه ساختاریافته برای افزایش مهارتهای یادگیری عمیق شما ارائه میدهند و آمادگی برای مصاحبه بعدی شما را تضمین میکنند.
در نهایت، اگر به دنبال دستورالعملهای کلی در مورد نحوه آماده شدن برای مصاحبه یادگیری عمیق خود هستید، بخشهای پایانی این مقاله در مورد سوالات مصاحبه یادگیری ماشین را بررسی کنید. از آنجایی که یادگیری عمیق زیرمجموعهای از یادگیری ماشین است، ترکیب این دستورالعملهای کلی با 20 سوال یادگیری عمیق که در اینجا بررسی کردهایم، مطمئناً به آمادهسازی شما کمک خواهد کرد.
نویسنده: Iván Palomares Carrascosa
منبع: لینک datacamp.com