من یک سری متن در https://dev.to/j4kh در مورد مدیریت حافظه پایتون (اگر بخوایم دقیقتر حرف بزنیم CPython) نوشتم که گفتم شاید بد نباشه خلاصهای از اون پستها رو با جزئیات کمتر و بخش Hands-on اونها، اینجا هم بنویسم.
این سری پستها وبلاگ در مورد این صحبت میکنن که:
پایتون چطور آبجکتها رو در حافظه میسازه و از بین میبره و Garbage collector توی پایتون چطور کار میکنه؛ چطوری حافظه Heap برای این کارها تخصیص داده میشه و Heap توی پایتون چه فرقهایی با زبانهای دیگه داره؛ در نهایت اون چیزی که نقش Stack رو توی پایتون بر عهده داره چیه و این بخش چطوری کار میکنه، Frame چیه و چرا Generatorها یک ساختار خیلی قدرتمند برای پایتون به حساب میآن.
وقتی ما توی پایتون یک متغیر رو تعریف میکنیم و مقدار میدیم، دقیقا پشت صحنه چه اتفاقی میافته؟ وقتی در یک متغیر از نوع عدد، یک String ذخیره میکنیم چی؟ پایتون چطور این اشیا رو مدیریت میکنه تا برنامهمون هنگ نکنه و حافظه رو درست آزاد کنه؟ بیایید با هم قدم به قدم بریم توی دل CPython (همون پیادهسازی اصلی پایتون) و این ماجرا رو بررسی کنیم.
اولین و مهمترین نکته اینه که توی پایتون، همه چیز یک شئ (Object) هست. حتی اعداد ساده (مثل عدد ۱ یا ۵) هم یک شئ هستن. این آبجکتها که بوسیله کدهای زبان C مدیر حافظه پایتون مدیریت میشن، به صورت یک struct به نامPyObject تعریف میشه.
این PyObject ها بسته به نوعشون میتونن متفاوت باشن، ولی حداقل این دو بخش خیلی مهم رو همیشه دارن:
1. یک شمارنده مرجع (ob_refcnt): که تعداد ارجاعها به این آبجکت رو نشون میده (تعداد جاهایی که از یک متغیر به این آبجکت ها اشاره کرده). پایتون از این شمارنده برای فهمیدن اینکه کی میتونه یه آبجکت رو از بین ببره استفاده میکنه.
2. یک اشارهگر به نوع آبجکت (ob_type): که مشخص میکنه این شئ از چه نوعیه (مثلاً int، list، dict). توی این ساختار نوع، اطلاعاتی مثل متدها و نحوه مدیریت حافظه اون نوع خاص ذخیره شده.
پس هر وقت یه آبجکت جدید میسازیم، یه تکه حافظه برای این ساختار پایهای و بعد هم برای دادههای خاص اون آبجکت (مثلاً بایت های عدد۱ یا ۵) در نظر گرفته میشه. ob_type همون چیزیه که امکان Dynamic Type بودن پایتون رو بوجود میاره. وقتی شما مقدار یک متغیر رو از int تبدیل میکنید به str، مقدار جدید یه رفرنس داره که علاوه بر مقدار ذخیره شده توی رم، به ob_type این مقدار اشاره میکنه که اونجا هم اطلاعات ob_type ذخیره شده.
با ob_refcnt هم جلوتر خیلی کار داریم، ولی فعلا همین رو اشاره میکنم که تعداد جاهایی هست که این مقدار در اونجا مورد استفاده قرار گرفته. (تعداد متغیرهایی که این مقدار رو دارن، attribute های یک آبجکت، درایه های یک لیست و ...).
malloc تا pymallocحالا این حافظهای که آبجکتها توش قرار میگیرن از کجا میاد؟ توی زبان C ( یا هر زبون سطح پایین که مستقیم با حافظه کار میکنه) برای گرفتن حافظه از تابعی به اسم malloc استفاده میشه. در واقع زبان C به سیستم عامل میگه که من یک بلوک حافظه به طول n بایت میخوام و سیستم عامل بعد از تخصیص حافظه، آدرس اول اون بلوک رو برمیگردونه به برنامه). اما malloc برای تعداد زیاد و سایزهای کوچیک خیلی هم بهینه نیست و میتونه باعث کندی و تکهتکه شدن حافظه بشه.
برای همین، CPython یه تخصیصدهنده حافظه اختصاصی به اسم pymalloc داره. pymalloc لایهای بین پایتون و سیستمعامل (و malloc) هست. کارش اینه که حافظه رو به صورت هوشمندانهای برای آبجکتهای کوچیک مدیریت کنه.
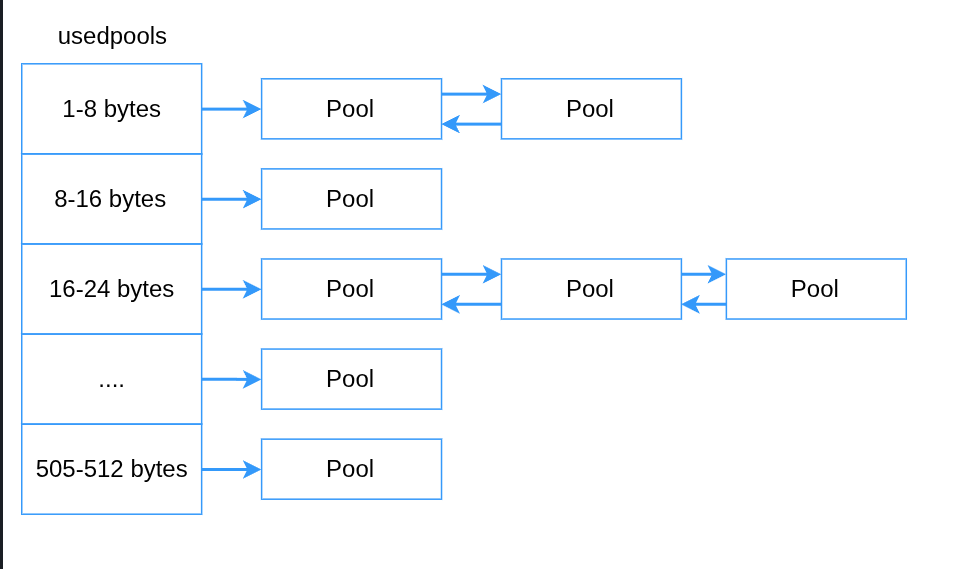
pymalloc: نقش Arena, Pool & Blockpymalloc حافظه رو به شکلی سازماندهی میکنه که بتونه سریع و کارآمد آبجکتهای کمتر از 512 بایتی رو توش جا بده. این سازماندهی با سه مفهوم اصلی انجام میشه:
Block: کوچکترین واحد حافظهست. هر بلوک سایز ثابتی داره (مثلاً ۸ بایت، ۱۶ بایت، ۳۲ بایت و ...). یه آبجکت کوچیک مثل یه عدد، دقیقاً توی یه بلوک با سایز مناسب خودش جا میگیره. وقتی برنامه شما میخواد یه مقدار رو در حافظه ذخیره کنه، مدیر حافظه پایتون دنبال یک بلوک بلااستفاده با اندازه مناسب میگرده و اون رو برای مقداری که برنامه میخواد اختصاص میده.
این بلوکها همیشه به شکل یه دسته حافظه هم اندازه (پر یا خالی) کنار هم هستن که پایتون اونها رو از مقدارهایی که برنامه شما میسازه و در بلوک های بزرگتر چند کیلوبایتی مدیریت میکنه که بهشون Pool گفته میشه. این بلوکها بعد از خالی شدن، به سیستم عامل برگردونده نمیشه، بلکه خود پایتون اونها رو به عنوان حافظه بلااستفاده برای استفادههای بعدی نگه میداره.
Pool: مجموعهای از بلوکهای همسایز. معمولاً یه پول چند کیلوبایت (مثلاً ۴ کیلوبایت) حافظه داره که به بلوکهای یکسان تقسیم شده. همه بلوکهای یه پول، سایز یکسانی دارن.
Arena: بزرگترین واحد حافظهست. یه Arena شامل چندین Pool میشه (مثلاً ۲۵۶ کیلوبایت). پایتون حافظه Arena رو از سیستمعامل به صورت یکجا میگیره و یکجا آزادش میکنه.
نحوه مدیریت حافظه توی پایتون خیلی جذابه و من همیشه با جستجو توی اون چیزای جدید یاد گرفتم، به شما هم پیشنهاد میکنم اگر دوست داشتید حتما برید و در مورد بخونید (توی پست های انگلیسی چند تا لینک خوب هم در موردشون هست).
خلاصه این بحث اینکه وقتی شما مقدار int رو توی یک متغیر ذخیره میکنید، پایتون میره pool های با سایز مناسب توی Arena ها (که یک linked list هستن) رو نگاه میکنه تا یکی رو پیدا کنه که جای خالی داره و این مقدار رو توش بنویسه (اگر پیدا نکرد، یک pool خالی رو برای این سایز اختصاص میده و به انتهای linked list اضافه میکنه).
حالا که میدونیم آبجکتها چطور ساخته میشن و در حافظه جا میگیرن، سوال بعدی این هست که پایتون چه زمانی و چطور این آبجکتها را از بین میبره؟ این وظیفه بر عهده Garbage Collector هست. پایتون برای این کار از دو مکانیسم اصلی استفاده میکنه: Reference Counting و Generational Garbage Collection.
سادهترین و اصلیترین روش مدیریت حافظه در پایتون، شمارش مرجع هست. همانطور که قبلاً اشاره کردم، هر PyObject یک فیلد به نام ob_refcnt داره که تعداد ارجاعها به اون آبجکت رو نشون میده.
این شمارنده چطور کار میکنه؟
- وقتی یک ارجاع جدید به یک آبجکت ایجاد میشه (مثلاً با تخصیص متغیر a = ۵ یا اضافه کردن آن به یک لیست)، مقدار این شمارنده یک واحد افزایش پیدا میکنه.
- وقتی یک ارجاع از بین میره (مثلاً با دستور del a یا خروج متغیر از محدوده تابع در حال اجرا)، مقدار شمارنده یک واحد کاهش پیدا میکنه.
- وقتی شمارنده به صفر میرسه، یعنی در این لحظه هیچکس به اون آبجکت اشاره نمیکنه. در این حالت، حافظه اختصاص داده شده ( که اگر حافظه کوچیک باشه، حافظه بلوکی اون متغیر و اگر بزرگ باشه حافظهای که مستقیم از سیستم عامل براش اختصاص پیدا کرده) آزاد میشه.
این مکانیسم بسیار سریع و کارآمد هست و بیشتر آبجکتها در پایتون به همین سادگی از بین میرن. اما یک مشکل بزرگ دارد: ناتوانی در تشخیص ارجاع های پیچیده Reference Cycles.
چرخه رفرنس وقتی اتفاق میافته که دو یا چند آبجکت به هم ارجاع بدن. مثلاً یک لیست که به خودش اشاره میکند، یا دو آبجکت که هر کدام به دیگری ارجاع دارند. در این حالت، با پاک شدن متغیرها، شمارنده مرجع اونها هیچوقت صفر نمیشه (چون رفرنس همدیگر را نگه داشتهاند و اگر یکی کامل پاک بشه اون یکی هم شمارنده اش صفر میشه، ولی هر دو منتظر هستن اون یکی اول پاک بشه تا تعداد رفرنسهاشون صفر بشه و اینطوری جفتشون قفل میشن)، اما در عمل این آبجکتها دیگه قابل دسترسی نیستند و حافظه اونها باید آزاد بشه. اینجاست که پای جمعآوری نسلی به میان میآید.
پایتون برای حل مشکل مرجع های پیچیده، یک الگوریتم کمکی داره که به صورت دورهای اجرا میشه و به دنبال این رفرنسهای چرخشی میگرده. تا اینجا با هم همه چی خوبه، ولی این الگوریتم چیزی نیست که بشه بعد از هر خط کد پایتون تکرارش کرد، چون الگوریتم سنگینی هست. به همین خاطر یک اصل ساده در طراحی اون اعمال شده: بیشتر آبجکتها خیلی زود میمیرند!
بر این اساس، آبجکتها در سه نسل (Generation) دستهبندی میشن:
- نسل ۰: آبجکتهای تازه ساخته شده ابتدا به از این نسلحساب میشن.
- نسل ۱: آبجکتهایی که از یک مرحله جمعآوری نسل ۰ زنده بیرون آمده باشند توی اینجا قرار میگیرن.
- نسل ۲: آبجکتهایی که حداقل یک چرخه پاکسازی نسل ۱ رو پشت سر گذاشتن و احتمالش خیلی زیاده که جزو آبجکتهایی باشن به این زودی ها قرار نیست پاک بشن.
نحوه کار به این صورت هست:
1. جمعآوری زباله بیشتر روی نسلهای جوانتر (مخصوصاً نسل ۰) انجام میشه. این نسل به شکل دیفالت بعد از ۷۰۰ بار نوشتن مقادیر توی حافظه پایتون اجرا میشه و آبجکتهای اضافی رو پاک میکنه. هر آبجکتی که جون به در ببره، میره جزو نسل ۱ ایها.
2. هر ۱۰ دفعه که پاک کردن حافظه برای نسل ۰ اتفاق بیافته، یک بار هم روی نسل ۱ اعمال میشه و آبجکتها توی این نسل پاکسازی میشن و هر چی موند میره جزو نسل ۲.
3. بعد از هر ۱۰ دفعه پاک کردن آبجکتهای نسل ۱، یک بار هم این اتفاق برای نسل ۲ میافته و آبجکتهای بدون رفرنس توی این نسل هم پاک میشن.
یکی از استثناهای garbage collection، آبجکتهای Immortal هستند. بعضی از آبجکتهای خاص در پایتون، مثل None، True، False، و برخی آبجکتهای داخلی، هرگز از بین نمیرن. این آبجکتها موقع اجرای برنامه ساخته میشن و هیچوقت هم پاک نمیشن.
در نسخههای جدیدتر پایتون (از ۳.۱۲ به بعد)، یه تغییر کوچیک هم هست: این آبجکتها بهعنوان Immortal فلگ زده شده هستند. مکانیسم شمارش مرجع برای اونها کار نمیکنه و هر چقدر به اونها ارجاع داده بشه یا ارجاع ها از بین بره، شمارنده اونها تغییر نمیکنه.
تا اینجا هر چی گفتیم، یه جورایی در مورد حافظه ای بود که زبان های دیگه بهش میگن هیپ (Heap)، جایی که آبجکتها و دادهها زندگی میکنن. حالا نوبت به پشته (Stack) میرسه. پشته جاییه که اطلاعات مربوط به اجرای توابع (فراخوانیها) ذخیره میشه.
وقتی تابعی رو صدا میزنیم، پایتون یه شئ مخصوص به اسم فریم (Frame) میسازه. این فریم رو میتونیم مثل یه حافظه مخصوص برای اجرای تابع در نظر بگیریم که توش اینا هست:
- متغیرهای محلی (Local Variables) تابع.
- شئ Code Object که دستورالعملهای خود تابع رو داره (که از روی کدهای اون تابع ساخته شدن).
- اشارهگر f_back به فریم تابع قبلی که این تابع رو صدا زده.
- اشارهگر به شئ globalها و built-inها.
- مقدار بازگشتی.
نکته جالب اینه که فریمها توی پایتون واقعا یک آبجکت هستن و توی همون حافظه ای ذخیره میشن که آبجکتهای دیگه ذخیره میشن و شما میتونید توی کد خودتون به اونها مثل یک متغیر عادی دسترسی داشته باشید!
این فریمها روی یه پشته (Call Stack) قرار میگیرن. هر بار تابعی صدا زده میشه، فریم جدیدش میره بالای پشته، و وقتی تابع تموم شد، فریمش از پشته حذف میشه. فقط یه فرق کوچیک بین پایتون و زبانهایی مثل C هست: توی پایتون Call Stack یک آرایه LIFO نیست، بلکه یک Linked List هست که هر فریم با رفرنس f_back به فریم قبلی توی استک وصل میشه. این همون چیزی هست که به پایتون اجازه میده ساختار انعطاف پذیری مثل generator و coroutine رو داشته باشه.
اینجاست که به قدرت مفهوم Generator میرسیم. Generator ها توابعی هستن که به جای return از yield استفاده میکنن. تفاوتشون چیه؟
وقتی یه تابع معمولی با return کارش تموم میشه، کل فریمش از روی پشته حذف میشه و اطلاعاتش (مثل مقدار متغیرهای محلی) برای همیشه از بین میره. اما generator وقتی به yield میرسه، یه مقدار برمیگردونه و بعد... متوقف میشه. اما نه به قیمت از دست رفتن اطلاعات!
Generator چیزی هست که یه اشارهگر به فریم خودش رو نگه میداره. وقتی جنریتور متوقف میشه، فریمش از پشته اصلی حذف میشه (چون دیگه اون تابع در حال اجرا نیست)، اما خود فریم به عنوان یه شئ توی حافظه زنده میمونه. تمام متغیرهای محلی و وضعیت اجرا توی این فریم ذخیره شدن.
وقتی دوباره با متدnextسراغ جنریتور میریم، پایتون این فریم رو از توی حافظه برمیداره و دوباره میچسبونه به پشته تا اجراش از همون جایی که متوقف شده بود ادامه پیدا کنه.
این قابلیت که یه تابع بتونه وضعیت خودش رو بین فراخوانیها حفظ کنه به خاطر جداسازی مفهوم فریم از پشته هست.
با اینکه پایتون در کل یک زبون Stacked به حساب میاد (که یعنی توابعاش فقط اجازه اجرای توابع نرمال با return رو بدن)، ولی این مفهوم اجازه میده بتونه گاهی رفتار یک زبان Stackless رو هم داشته باشه(همین توابعی که yield میکنن). این ساختار به ما اجازه میده کارهای زیادی باهاش بکنیم، مثلا:
- پردازش جریان داده (Streams) رو خیلی راحتتر و مدیریت حافظه رو به کمک Generator ها خیلی بهینهتر میکنه.
- توابع همروال (Coroutines) داشته باشیم که میتونن چندبار ورودی و خروجی داشته باشن و با هم همکاری کنن.
- صرفهجویی در حافظه از این طریق به جای ساختن لیستهای عظیم، مقادیر رو به کمک Generator ها یکی یکی تولید کنیم.
مدیریت حافظه در پایتون حاصل یک لایهبندی هوشمندانه است. در پایینترین سطح، آبجکتها با ساختار PyObject تعریف میشن. برای تخصیص حافظه، pymalloc با استفاده از ساختار Arena، Pool و Block، کار malloc رو برای آبجکتهای کوچیک بهینه میکنه. برای اجرای کد، فریمها روی پشته قرار میگیرن. و در نهایت، Genrator ها با نگه داشتن فریمها در Heap، قابلیت نگهداری وضعیت و اجرای ناهمزمان رو ممکن میکنن. این طراحی زیبا و لایهلایه، پایتون رو همزمان هم ساده و هم قدرتمند کرده.