اگر بخواهم یک جمله دربارهی «کیورد کلاسترینگ» بگویم، این است:
کلاسترینگ یعنی تصمیم بگیریم هر کلمه کلیدی باید روی چه صفحهای بنشیند—تا هم Cannibalization نگیریم، هم ساختار سایتمان درست شکل بگیرد.
خیلیها کلاسترینگ را با «گروهبندی خوشگل در اکسل» اشتباه میگیرند؛ در حالی که کلاسترینگِ درست، پایهی معماری اطلاعات سایت، استراتژی محتوا و حتی برنامهی تولید لندینگپیجهاست.
در این مقاله سه رویکرد را با هم جلو میبریم:
کلاسترینگ دستی (Manual) — بهترین برای فهم بازار و شروع کار
کلاسترینگ معنایی با NLP / BERT — سریعتر، ولی خطاپذیر
کلاسترینگ بر اساس SERP Similarity — معتبرترین روش چون مستقیماً با نیت کاربر همراستاست
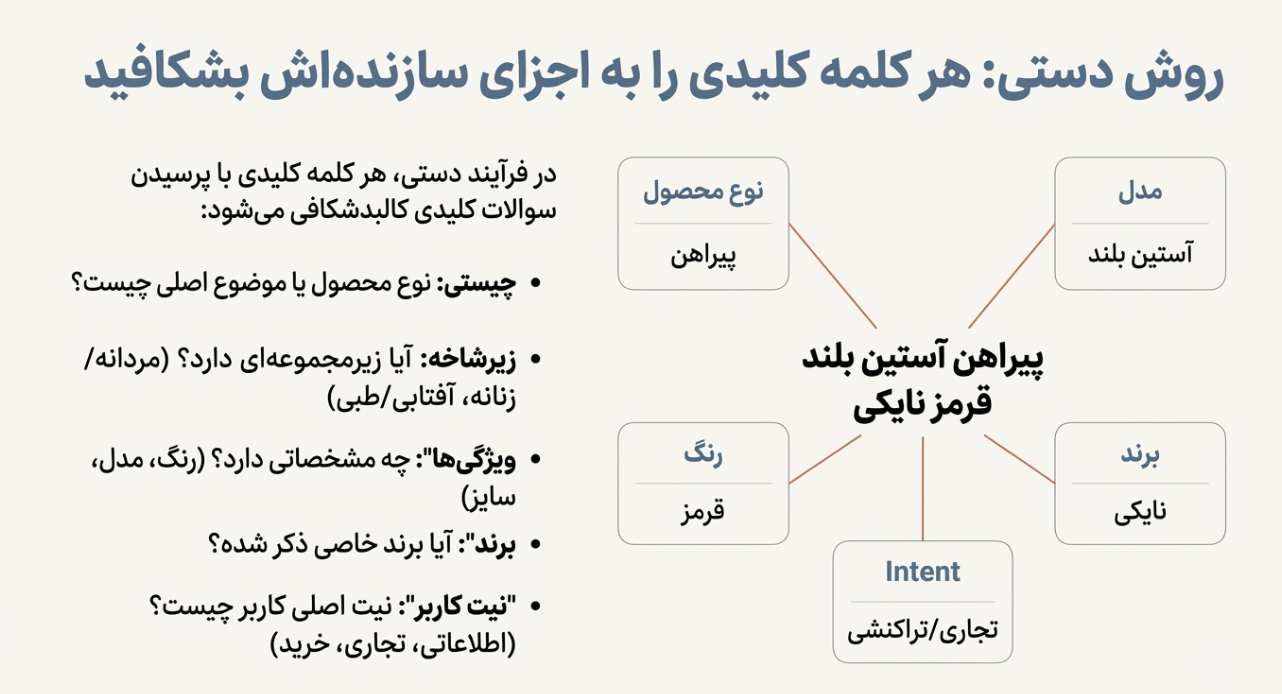
در روش دستی، شما هر کلمه را مثل یک جمله باز میکنید و میپرسید:
این کلمه دربارهی چی است؟ (نوع محصول/موضوع)
چه زیرشاخهای دارد؟ (مثلاً مردانه/زنانه، آفتابی/طبی…)
چه ویژگیهایی داخلش هست؟ (رنگ، مدل، سایز، جنس…)
آیا برند دارد؟
مهمتر از همه: نیت کاربر چیست؟ اطلاعاتی؟ تجاری؟ خرید؟…
«پیراهن آستین بلند قرمز نایکی»
میتوانیم آن را در چند ستون تگ بزنیم:
نوع محصول: پیراهن
زیرشاخه: (اگر ذکر شده باشد: مردانه/زنانه/بچگانه…)
مدل/ویژگی: آستین بلند
رنگ: قرمز
برند: نایکی
Intent: غالباً تجاری/تراکنشی (کاربر احتمالاً دنبال خرید/مشاهده محصول است)
پس شما در گوگلشیت چند ستون میسازی و برای هر کیورد، تگ میزنی. این کار دو مزیت بزرگ دارد:
✅ بازار را میفهمی (نه فقط فایل تحویل بدهی)
✅ ساختار دستهبندی سایت از دل دیتا بیرون میآید
اما یک مشکل جدی دارد…
اگر پروژه ۵۰۰۰ تا ۵۰,۰۰۰ کلمه داشته باشد، تگزنی دستی زمانبر و فرسایشی میشود. تازه، هرچه دیتاست بزرگتر شود احتمال خطای انسانی هم بالا میرود.
اینجاست که خیلیها میروند سراغ روشهای ماشینی.
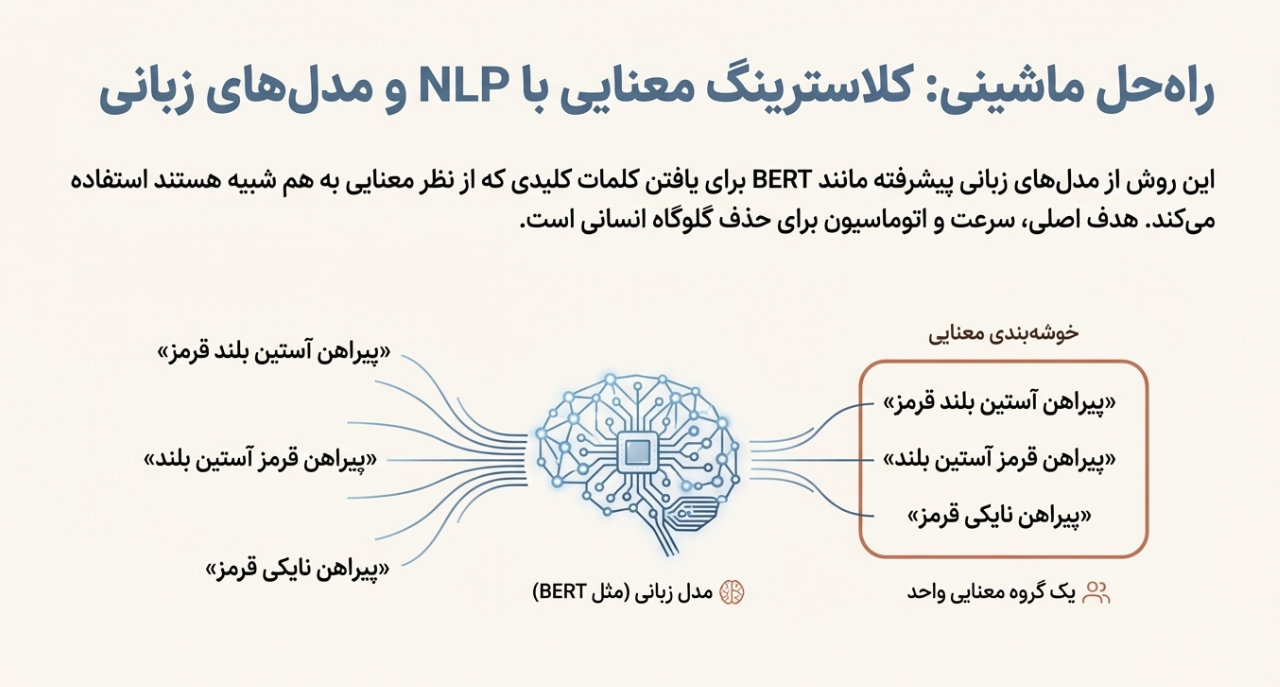
در روش معنایی، شما سعی میکنی با مدلهای زبانی (NLP) مثل BERT/Embeddingها بفهمی کدام کلمات از نظر معنا به هم نزدیکاند.
مثلاً:
«پیراهن آستین بلند قرمز»
«پیراهن قرمز آستین بلند»
«پیراهن نایکی قرمز»
از نظر معنایی نزدیکاند، پس مدل میگوید “اینها یک خوشهاند”.
دو کیورد ممکن است خیلی شبیه باشند، اما SERP متفاوت داشته باشند.
مثلاً:
«بهترین کفش رانینگ نایکی» → بیشتر مقاله/راهنما (Informational/Commercial)
«خرید کفش رانینگ نایکی» → صفحه دستهبندی/محصول (Transactional)
از نظر “معنا” نزدیکاند، اما “نیت” متفاوت است.
پس اگر فقط با NLP کلاستر کنی، ممکن است دو Intent را قاطی کنی و بعداً در ساختار سایت به مشکل بخوری.
نتیجه: روش NLP خوب است برای پیشگروهبندی سریع، اما برای تصمیم نهایی، کافی نیست.
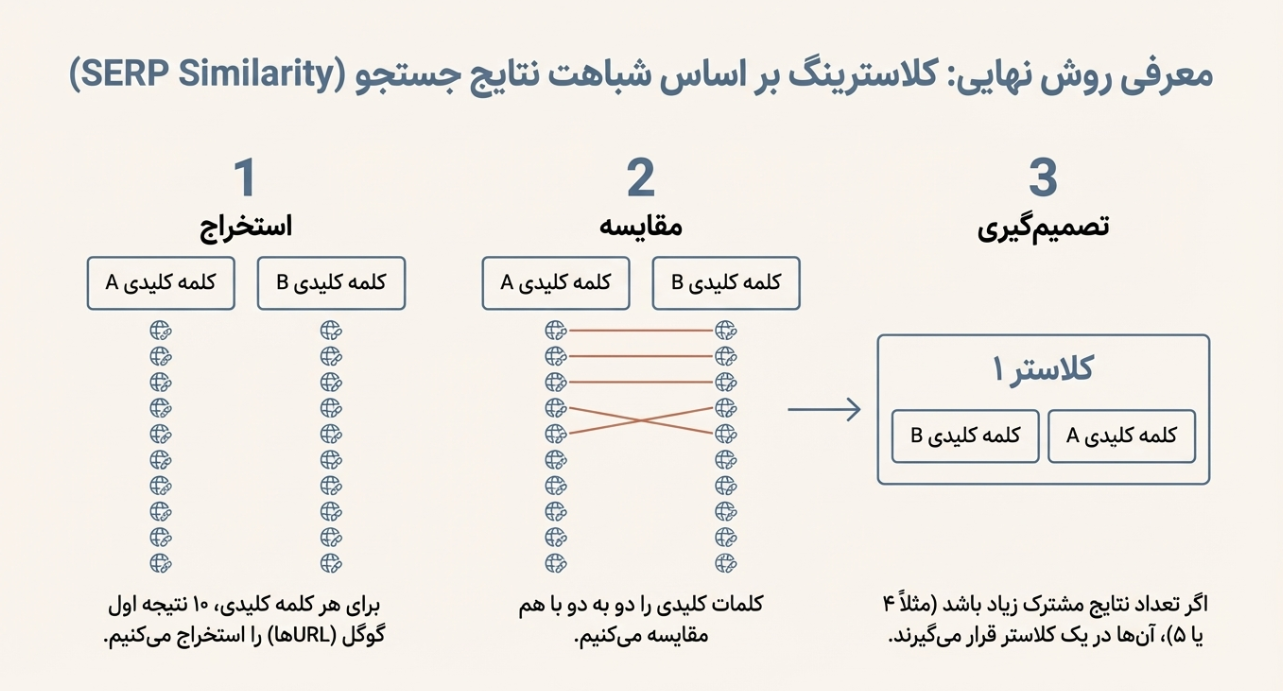
اینجا میرسیم به روشی که از نظر عملی، «واقعیترین» است:
اگر دو کلمه کلیدی، نتایج صفحه اول گوگلشان شبیه باشد، یعنی گوگل تشخیص داده نیت کاربرشان نزدیک است، پس باید در یک کلاستر باشند.
چرا این روش معتبرترین است؟
گوگل سالهاست با آزمون و خطا و دادههای رفتاری (کلیک، ماندگاری، بازگشت به SERP…) فهمیده برای هر کوئری چه نوع صفحهای باید نشان بدهد.
پس SERP عملاً تبدیل میشود به «خلاصهی نیت کاربر».
برای هر کیورد، ۱۰ نتیجه اول گوگل را برمیداریم (URLها یا دامنهها).
بعد دو به دو کیوردها را مقایسه میکنیم:
اگر مثلاً ۴ یا ۵ نتیجه مشترک داشتند → احتمالاً یک Intent دارند → یک کلاستر
اگر اشتراک کم بود → جدا
این یعنی کلاسترینگ بر اساس «شباهت SERP».
یک شیت ساده:
KeywordSERP_Top10_URLs…
ستون اول: کیوردها
ستون دوم: قرار است ۱۰ URL اول برای هر کیورد ذخیره شود.
اسکرپ مستقیم نتایج گوگل معمولاً با محدودیت/کپچا/ریسک مواجه میشود و ممکن است خلاف سیاستهای گوگل باشد.
راه حرفهایتر استفاده از SERP API است (مثل SerpAPI، DataForSEO، Zenserp و…).
این APIها دقیقاً برای همین کار ساخته شدهاند: گرفتن خروجی SERP تمیز، بدون کپچا، با پارامترهای کشور و زبان.
پارامترهای مهم برای فارسی/ایران:
hl=fa (زبان)
gl=ir (موقعیت)
num=10
بهترین حالت این است که برای هر کیورد، ۱۰ URL را با یک جداکننده (مثلاً |) داخل یک سلول ذخیره کنی.
مثل:
url1|url2|url3|...|url10
اینجا دو مدل رایج داریم:
مثلاً میگیم:
اگر اشتراک ≥ 4 → یک کلاستر
فرمول:
Jaccard = (تعداد مشترک) / (تعداد کل یونیک)
مثلاً اگر ۱۰ تا URL داریم و ۵ تا مشترک:
Jaccard = 5 / 15 = 0.33
معمولاً برای Top10، یک آستانههای رایج:
Overlap ≥ 4 یا
Jaccard ≥ 0.30 ~ 0.40
(عدد دقیق وابسته به حوزه و SERP volatility است، ولی این بازهها کاربردیاند.)
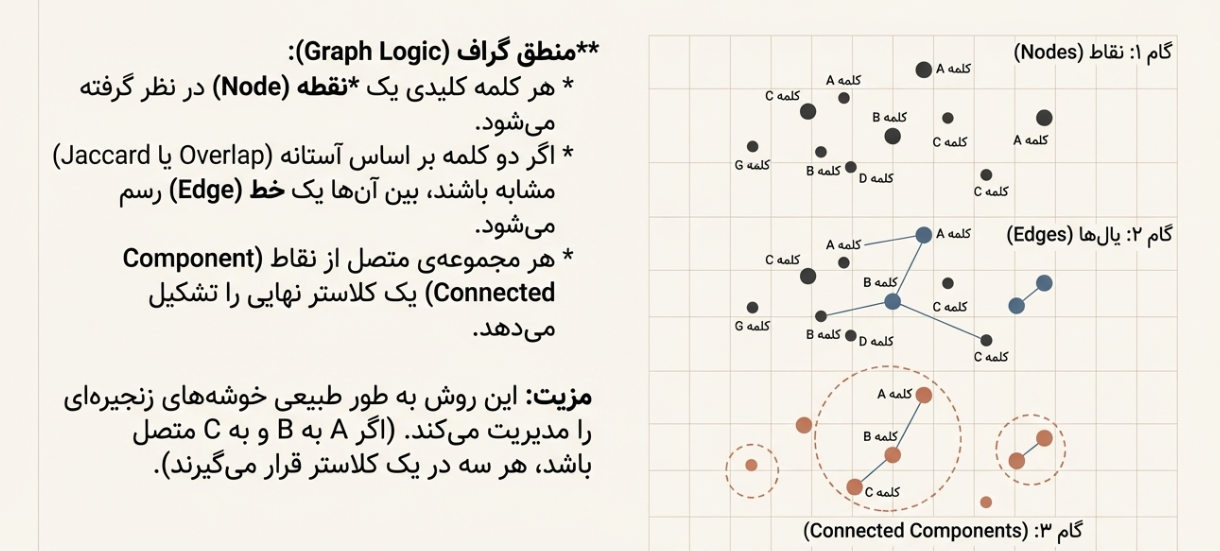
وقتی برای هر دو کیورد تصمیم گرفتی “مشابهاند یا نه”، میتوانی یک گراف بسازی:
هر کیورد = یک نود
اگر مشابه بودند = بینشان یال میگذاری
هر Connected Component میشود یک کلاستر
این روش حتی اگر A با B مشترک باشد و B با C مشترک باشد، A و C هم داخل همان خوشه میافتند (منطقی و طبیعی).
برای اینکه مقاله کاملاً آموزشی باشد، اینجا یک اسکلت قابل فهم میدهم.
(برای استفاده واقعی، باید API Key سرویس SERP خودت را جایگزین کنی.)
function fetchSerpTop10() { const sheet = SpreadsheetApp.getActiveSpreadsheet().getActiveSheet(); const lastRow = sheet.getLastRow(); const keywords = sheet.getRange(2, 1, lastRow - 1, 1).getValues(); // Col A const apiKey = 'YOUR_API_KEY'; for (let i = 0; i < keywords.length; i++) { const kw = keywords[i][0]; if (!kw) continue; // نمونهی فرضی: باید با API واقعی جایگزین شود const url = 'https://serpapi.example.com/search?q=' + encodeURIComponent(kw) + '&num=10&hl=fa&gl=ir&api_key=' + apiKey; const res = UrlFetchApp.fetch(url); const json = JSON.parse(res.getContentText()); // فرض: json.organic_results شامل نتایج ارگانیک است const urls = (json.organic_results || []) .slice(0, 10) .map(r => r.link) .join('|'); sheet.getRange(i + 2, 2).setValue(urls); // Col B } }
function overlapCount(urlsA, urlsB) { const setA = new Set(urlsA.split('|').filter(Boolean)); const setB = new Set(urlsB.split('|').filter(Boolean)); let count = 0; setA.forEach(u => { if (setB.has(u)) count++; }); return count; }
میتوانی یک شیت دوم بسازی که برای هر جفت کیورد:
Overlap را محاسبه کند
اگر ≥ 4 بود، در ستون “SameCluster=1” بزند
بعد با یک اسکریپت سادهتر، کلاسترها را با DFS/BFS بسازی و خروجی بدهی.
اگر ۱۰,۰۰۰ کیورد داشته باشی:
10000² = 100 میلیون مقایسه
غیرواقعی برای شیت.
✅ راهحل عملی:
ابتدا کیوردها را با روش معنایی یا دستی پیشگروهبندی کن (مثلاً بر اساس برند/نوع محصول)
سپس SERP Similarity را داخل هر گروه کوچک اجرا کن
این بهترین ترکیب دقت + مقیاس است.
نتایج گوگل ممکن است با زمان/لوکیشن/دستگاه فرق کند.
پس پارامترهای hl و gl را ثابت نگه دار و زمان استخراج را هم نزدیک به هم انجام بده.
گاهی بهتر است به جای URL کامل، دامنه را معیار بگیری (مثلاً digikala.com).
چون ممکن است دو نتیجه از یک دامنه ولی صفحات مختلف باشند و هنوز نشاندهندهی Intent مشابه باشند.
دستی: بهترین برای فهم بازار و ساخت Taxonomy (ولی کند)
NLP/BERT: سریع برای پیشگروهبندی (ولی ممکن است Intent را قاطی کند)
SERP Similarity: دقیقترین روش چون مستقیماً از تصمیمهای گوگل روی Intent استفاده میکند
اگر بخواهی واقعاً “کلاسترینگ حرفهای” انجام بدهی، بهترین ترکیب این است:
✅ دستی/معنایی برای پیشگروهبندی
✅ SERP Similarity برای تصمیم نهایی و ساخت خوشههای واقعی