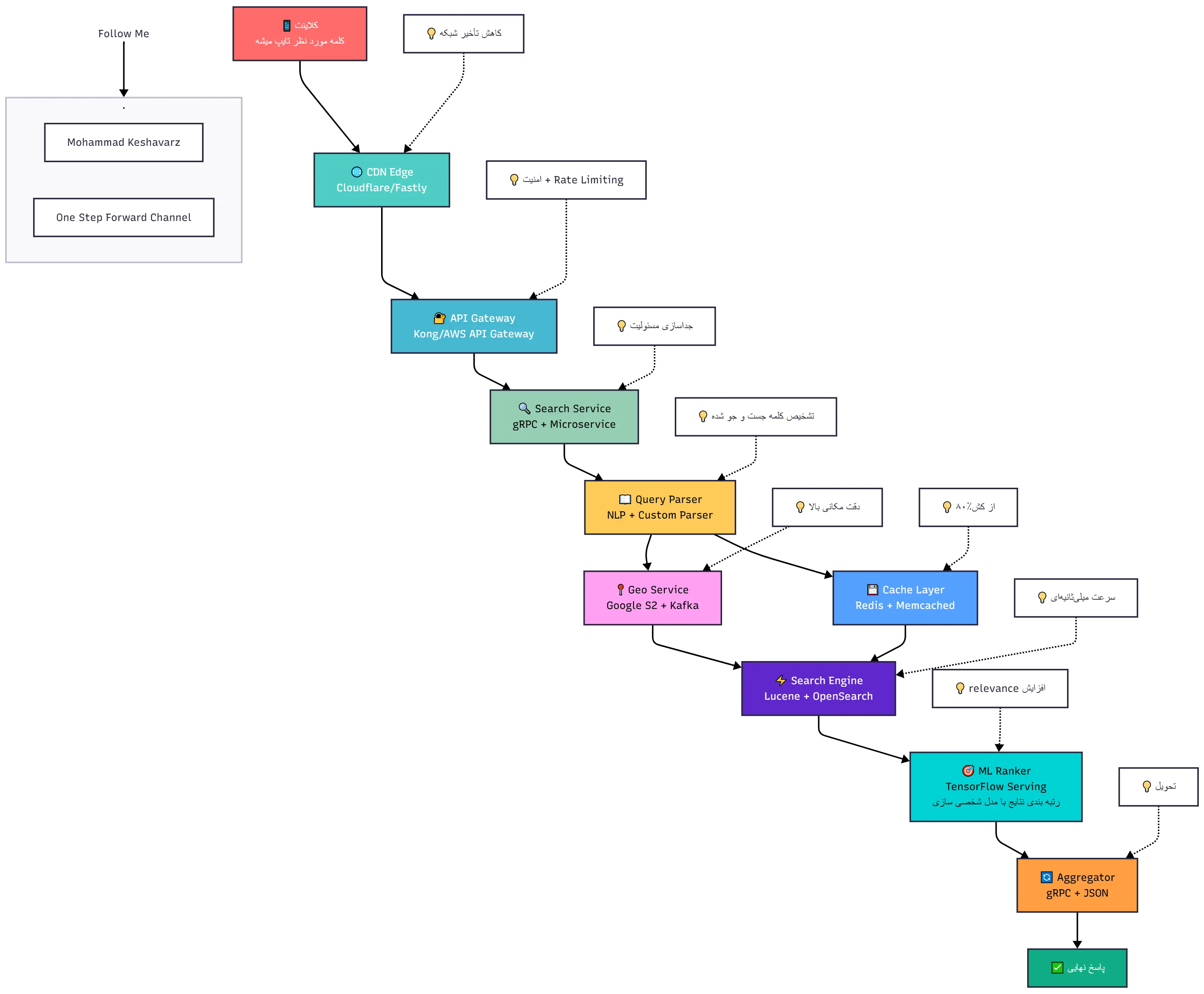
تو قسمت قبل خیلی کلی از اهمیت سرویس سرچ و ویژگی های کلی و ابزارهای معروفش صحبت کردیم. توی این قسمت با جزئیات بیشتری از مسیری که یک کلمه تا نمایش نتیجه نهایی رو بررسی میکنیم.
فرض کن تو اسنپ/تپسی فود هستی، ساعت ۸ شبه و کم کم داره گرسنه ات میشه، تایپ میکنی: "پیتزای سیر و استیک نزدیک من". این یک جمله ساده است، ولی پشتش یک سفر پیچیده و فوقالعاده سریع تو سیستمهای توزیع شده، دیتابیسها، کشها، سرچ انجین ها و هوش مصنوعی وجود داره. تو این قسمت از سری مقالهها، میریم تو دل یک سرویس واقعی، نه فقط تئوری، بلکه دقیقاً همون مسیری که یه کلمه طی میکنه تا به نتیجه تبدیل بشه. از لحظهای که انگشتمون دکمه Enter رو میزنه، تا لحظهای که ۱۰ تا رستوران جذاب با عکس، قیمت و زمان تحویل جلوت ظاهر میشه.
آخر مطلب هم کل این مسیر رو به صورت یک دیاگرام کلی باهم میبینیم تا بهتر توی ذهنمون بمونه.
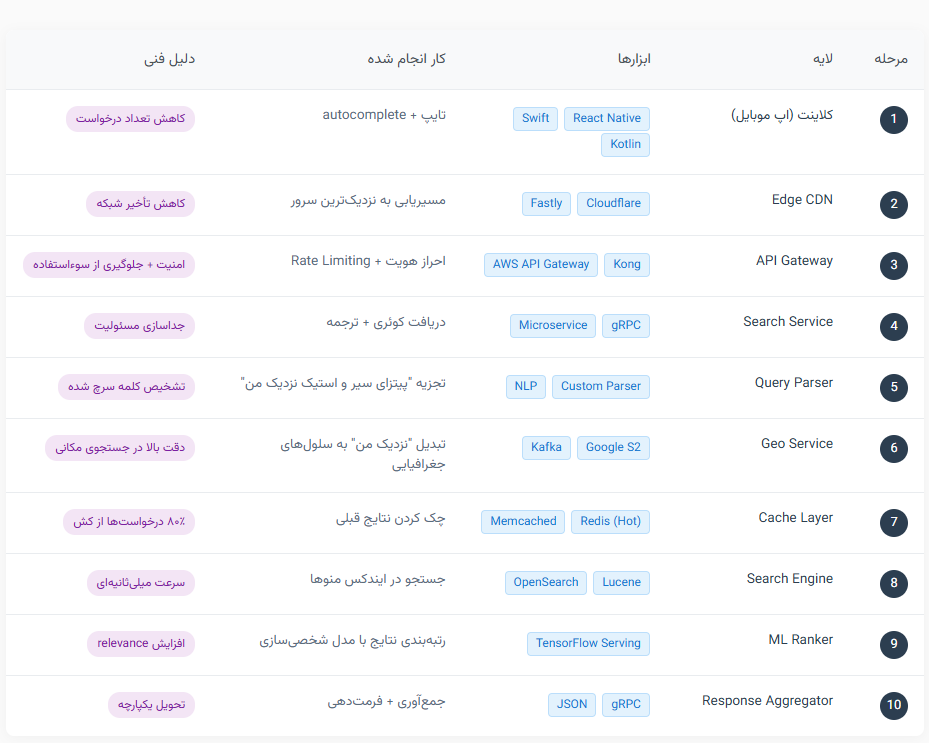
اینجا دقیقا چه اتفاقی میافته؟ کاربر حین تایپ، autocomplete میبینه (مثل "پیتزای گوشت"، "پیتزای سیر و استیک تهرانپارس"، "پیتزای سیر و استیک زعفرانیه").
خب چرا باید همیچن اتفاقی بیافته؟ برای کاهش تعداد درخواستهای کامل و افزایش سرعت و بهبود تجربه کاربر در جست و جوی چیزی که میخواد.
تو این قسمت برای کلاینت، ابزارهای مختلفی استفاده میشه که در این قسمت اهمیت بالایی نداره چون فقط یک محیط جذاب برای کاربر هست که بتونه سرچ کنه و کارش رو پیش ببره.
طراحی این قسمت برای پیشنهادهای سرچ به کاربر میتونه اثرگذاری خوبی روی انتخاب و پیش بینی رفتار کاربر و کاهش تعداد درخواست داشته باشه. به این صورت که دیتای لازم رو از کش بخونه و پردازش دوباره نداشته باشه.
درخواست از طریق CDN (مثل Cloudflare، ابرآروان) به نزدیکترین منطقه (مثل تهران، دبی یا فرانکفورت) هدایت میشه.
چرا داریم اینکارو میکنیم؟ جوابش ساده است، کاهش latency شبکه از ۲۰۰ms به ۲۰ms.
خب اینجا بحث یک مقداری میره سمت موضوعات زیرساخت و POP ها و مواردی که توی شبکه مدیریت میشه و اینجا برای سرویس سرچ ساده ای که محلی هست مثل اسنپ/تپسی این موضوعات توی همون محیط باید حل بشه اما برای سرویس های بین المللی مثل Uber یا امثالهم این مورد اهمیت بیشتری پیدا میکنه که بتونه جست و جوها رو در کشورهای مختلف مدیریت کنه.
درخواست با JWT Token احراز هویت میشه، Rate Limit هم روی این لایه داریم تا از حملات DDoS جلوگیری بشه (مثلاً ۱۰ درخواست در ثانیه).
تو این قسمت به ابزارهایی مثل Kong یا AWS API Gateway با OAuth2 نیاز داریم تا بازهم از ارسال مستقیم درخواست روی سرورهای خودمون جلوگیری کنیم و بتونیم تعداد درخواست های خیلی خیلی زیادی رو مدیریت کنیم.
یک میکروسرویس اختصاصی، کوئری رو میگیره و به بخشهای مختلف میفرسته تا ادامه فرآیند پردازش درخواست جست و جوی کلمه انجام بشه.
اهمیت استفاده از میکروسرویس در این قسمت برای جداسازی مسئولیت (Separation of Concerns) هست که سرویس ها بتونن به صورت مستقل کارشون رو پیش ببرن. تو این قسمت موضوع سرعت اهمیت بالایی داره و برای ارتباط بین سرویس ها از gRPC استفاده میشه به دو دلیل! (دلایل دیگه رو خودتون سرچ کنید!)
payload در این نوع ارتباطی نسبت به REST/JSON کمتره و چون ما داریم در حد چند کلمه رو منتقل میکنیم و از طرف دیگه Real-Time هسا، این نوع ارتباط برامون مناسبتره.
عبارت "نزدیک من" با موقعیت GPS کاربر (از کلاینت) ترکیب میشه و از ترکیب و تشخیص این دیتا محل مورد نظر کاربر مشخص میشه. "پیتزای سیر و استیک" به توکنهای ["پیتزا", "سیر", "استیک"] تجزیه میشه چون میخواییم intent و entity رو به دست بیاریم.
تو این لایه Custom NLP Parser + Synonym Dictionary (مثل "پیتسا" = "پیتزا") برای پردازش و پیدا کردن نیت کاربر از این کلمه ای که سرچ کرده استفاده میشه.

یک نکته مهم اینجا اینکه این قسمت در سرویس های ایرانی با همون pop-up اولیه یا پروفایلی که شما توی اون سرویس دارید پر میکنید ازش گرفته میشه، مثل آدرس هایی که برای ارسال سفارش توی سیستم ثبت کردید و همینطور قسمت فیلتر شهر و منطقه مورد نظر برای مشاهده خدمات دهنده های همون منطقه.
موقعیت کاربر به سلول S2 (از Google S2 Library) تبدیل میشه. سلولهای اطراف (مثلاً شعاع ۵ کیلومتر) محاسبه میشن.
خب این جا از ویژگی های کافکا برای آپدیت کردن موقعیت رستوران ها بر اساس همون لوکیشن کاربر که به دست آوردیمش یا خودش بهمون داده استفاده میکنیم.(Google S2 + Kafka Stream)
سرویس S2.dev رو پیشنهاد میکنم مطالعه کنید.
لایه خیلی مهم بسیاری از سرویس ها کش هست، تو این قسمت سیستم چک میکنه: "آیا این جستجو تو ۵ دقیقه اخیر انجام شده؟" اگه جواب بله بود پس میره جواب رو از Redis میخونه و برمیگردونه.
تو مرحله قبلی اگه کش نبود، کوئری به OpenSearch (یا Lucene) میره. ایندکس منوها (میلیونها آیتم) اسکن میشه. این سرویس سرعت میلیثانیهای در دادههای عظیم داره و قابلیت های ویژه اون برای سرچ پرکاربرده.
ساختار ایندکس
Live Index: دادههای ۱ ساعت اخیر (در حافظه)
Snapshot Index: دادههای ۲۴ ساعت (روی دیسک)
Base Index: دادههای قدیمی (آرشیو)
۱۰۰ نتیجه اولیه از Lucene میاد، یک مدل ML (TensorFlow) اونا رو بر اساس یک سری معیارهایی دوباره رتبهبندی میکنه. معیارها:
فاصله
رتبه رستوران
سابقه سفارش کاربر (کاربر قدیمیه یا جدید)
زمان تحویل پیشبینیشده
این کار باعث افزایش relevance و conversion rate میشه یعنی همون چیزی که کاربر سرچ کرده تا بهش برسه. این بخش تو فروشگاه های خیلی بزرگ مثل آمازون یا دیجیکالا اهمیت زیادی داره چون خیلی مهمه که وقتی کاربر سرچ میکنه "شیر" منظورش چیه؟ آیا سرویس سریع میخواد و باید بفرستیمش سمت خوراکی ها و سوپرمارکت یا اینکه نه دنبال شیرآلات میگرده و پرواضحه که این دوتا سرویس کاملا باهم متفاوت هستن از شاپ/وندور و قیمت ها بگیر تا نحوه ارسال اون سفارش.
خب رسیدیم به مرحله آخر، تو اینجا ۱۰ نتیجه برتر با عکس، قیمت، زمان تحویل و دکمه "سفارش" برگردونده میشه و منتظر میشیم تا کاربر سفارشش رو بزاره و این سرویس زنده بمونه! :)