این مقاله رو بر اساس تجربیات واقعی تیممون نوشتم، جایی که با چالشهای فنی روبرو شدیم و با همکاری نزدیک، راه حل های مناسبی پیدا کردیم. هدف ما این بود که قیمت های لحظه ای سهام و صندوق ها رو به صورت real-time روی اپلیکیشن مفید نمایش بدیم، تا کاربرانمون تجربه ای روان و به روز داشته باشن.
این تصمیم، آغازگر یک سفر فنی پرچالش بود. ما با حجم عظیمی از داده ها روبرو بودیم که باید با کمترین تأخیر ممکن (Latency) از هسته معاملات به صفحه نمایش کاربر میرسید. در ابتدای مسیر، ابهامات زیادی وجود داشت: نقطه شروع دقیق کجاست؟ چگونه باید گلوگاه ها را شناسایی و رفع کنیم؟ و چگونه معماری را طراحی کنیم که در اوج ترافیک بازار، پایدار بماند؟
در ظاهر، این خواسته ساده به نظر میرسد؛ اما در عمل، با چالش هایی رو به رو شدیم که اگر از ابتدا درست دیده نمیشدند، میتوانستند کل سیستم را به بن بست برسانند.
داده دقیقاً از کجا می آید؟
با چه نرخی تولید میشود؟
چقدر بزرگ میشود؟
و مهمتر از همه، چطور میشود این حجم داده را بدون قربانی کردن latency، پایداری و سادگی، به دست میلیون ها کاربر رساند؟
با چه روشی به سمت کلاینت داده ها ارسال شود؟
در این مقاله، قصد داریم تجربه تیم خود را در مواجهه با این چالشها، انتخابهای معماری، و راهکارهایی که برای دستیابی به این هدف پیاده سازی کردیم، به اشتراک بگذاریم.
اولین قدم، درک عمیق از منبع داده بود. قیمتهای لحظه ای کجا تولید میشوند و با چه نرخی؟
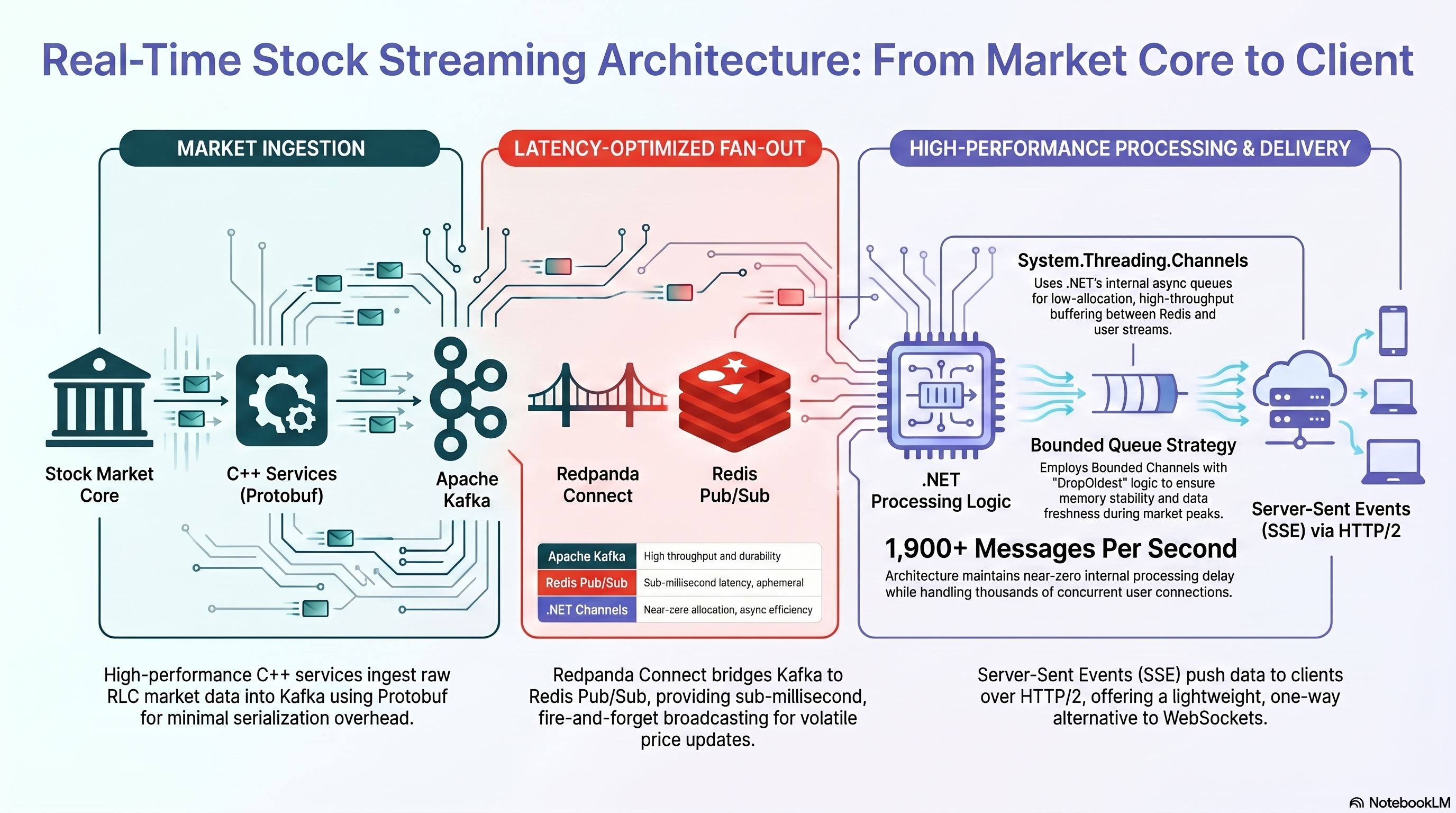
داده های حیاتی بازار، شامل قیمت لحظه ای سهام و صندوق ها، توسط هسته مرکزی سازمان بورس (RLC) تولید میشوند. برای دریافت این داده ها با حداکثر سرعت، یک تیم تخصصی دیگر در داخل مفید، وظیفه خواندن این جریان داده را بر عهده دارد. آنها برای این کار از زبان ++C استفاده کرده اند؛ انتخابی هوشمندانه که به دلیل نزدیکی به سخت افزار و پرفورمنس بالا، تأخیر در خواندن اطلاعات را به حداقل میرساند.
این تیم، پیام های دریافتی را پس از پردازش اولیه، در فرمت بهینه Protobuf (برای کاهش حجم و افزایش سرعت سریالیزیشن) داخل یک کلاستر Kafka قرار میدهند. تا این نقطه، ما یک خط لوله (Pipeline) بسیار سریع داشتیم که داده ها را از هسته بورس به Kafka منتقل میکرد.
سوال بعدی این بود: با چه حجمی از داده روبرو هستیم؟
نرخ تولید پیام ها رابطه مستقیمی با حجم معاملات روزانه بازار دارد. اما برای طراحی سیستم، ما نیاز به یک برآورد دقیق از وضعیت نرمال و پیک داشتیم. تحلیلهای ما نشان داد که ما به طور کلی با ۴ جریان (Queue) اصلی داده مواجه هستیم:
صف قیمتهای آخرین معامله: حدود ۱۰۰۰ پیام در ثانیه.
صف قیمتهای پایانی: حدود ۵۰۰ پیام در ثانیه.
صف تغییرات دارایی کاربر: حدود ۲۰۰ پیام در ثانیه.
صف تغییرات بازدهی کاربر: حدود ۲۰۰ پیام در ثانیه.
با یک محاسبه سرانگشتی، ما در حالت نرمال بازار باید حدود ۱۹۰۰ پیام در ثانیه را پردازش میکردیم. نکته حیاتی این بود که در روزهای پر نوسان بازار، این عدد به راحتی میتوانست در لحظاتی حدود ۲ تا ۳ برابر شود. معماری ما باید برای بدترین سناریو آماده می بود.
چالش اصلی در این مرحله، انتقال این حجم عظیم پیام از Kafka به لایه Backend سرویس خودمان با کمترین تأخیر ممکن بود. ما به ابزاری نیاز داشتیم که بتواند نقش یک واسط بسیار سریع را بازی کند. اینجا چند گزینه داشتیم: RabbitMQ Stream، Kafka و Redis Pub/Sub. برای انتخاب، ملاک هامون شامل throughput (حجم پیام در ثانیه)، latency (تأخیر)، scalability (قابلیت مقیاسپذیری)، ease of maintenance (نگهداری ساده)، و مصرف منابع بود. من خودم قبلاً در پروژههای قبلی با RabbitMQ کار کرده بودم و میدونستم که سرعت خوبی داره، اما میخواستیم مقایسه کاملی داشته باشیم.
پ.ن: جدول با کمک AI تولید شده.
انتخاب ما: Redis Pub/Sub
Kafka برای ingestion و نگهداری جریان اصلی داده انتخاب بسیار مناسبی بود؛ اما در لایه fan-out لحظهای به سرویسهای SSE، نیاز ما بیشتر به broadcast سریع، ساده و ephemeral بود تا replay و durability. به همین دلیل، در این نقطه از معماری Redis Pub/Sub را به عنوان یک لایه سبک و کم تاخیر بین Kafka و Backend انتخاب کردیم. ما Redis Pub/Sub را انتخاب کردیم. هدف ما در این لایه، نگهداری تاریخچه پیامها یا replay نبود؛ بلکه رساندن آخرین تغییرات قیمت با کمترین تأخیر به backend بود. Redis Pub/Sub با semantics از نوع at-most-once دقیقاً با ماهیت داده های ما سازگار بود: اگر قیمت چند ثانیه قبل از دست برود، با پیامهای بعدی جایگزین میشود. در مقابل، Kafka، Redis Streams و RabbitMQ Streams برای سناریوهایی مناسب ترند که replay، durability، consumer offset , acknowledgment یا پردازش قابل اطمینان تری لازم است.
ما در استک فناوری خود از قبل Redis داشتیم و این انتخاب، پیچیدگی نگهداری یک تکنولوژی جدید را به تیم SRE تحمیل نمیکرد. توسعه آن نیز بسیار ساده بود.
پیاده سازی: با همکاری تیم SRE، ما از ابزار Redpanda Connect برای انتقال داده ها از تاپیکهای Kafka به کانال های Redis Pub/Sub استفاده کردیم. مزیت Redpanda Connect برای ما این بود که بدون نوشتن سرویس واسط اختصاصی، pipeline بین Kafka و Redis را declarative و قابل مانیتورینگ نگه داشتیم. برای به حداکثر رساندن سرعت، یک نود Redis اختصاصی را در حالت تماماً حافظه (Memory-Only) پیکربندی کردیم.
نکته در مورد قابلیت اطمینان: در این سناریو، اگر Redis ریست میشد، داده های چند لحظه از دست میرفت و قیمت ها برای چند ثانیه قطع میشدند. با توجه به اینکه دیتابیس اصلی در پس زمینه با تأخیری حدود ۵ دقیقه آپدیت میشد، این سطح از ریسک (Incident) برای نمایش قیمت لحظه ای قابل قبول بود.
وضعیت ریسورس های Redis در عملیات:
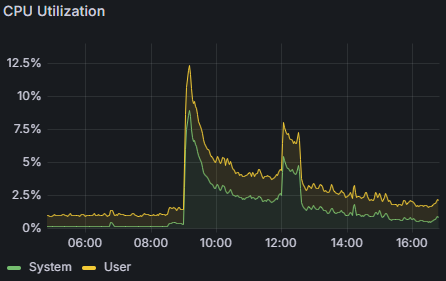
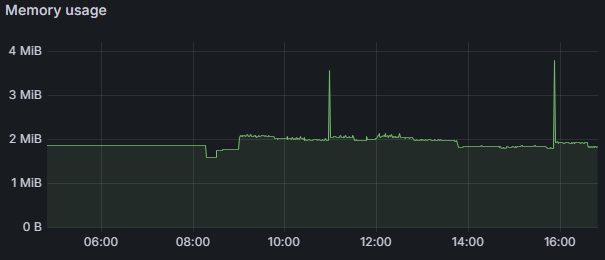
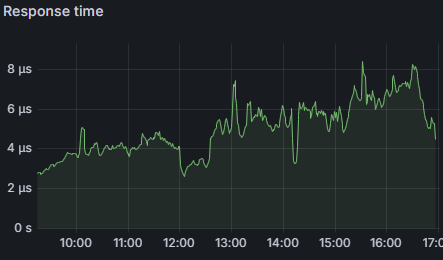
به نظر میرسد این لود برای Redis بیشتر شبیه به یک شوخی است!
اکنون دادهها با سرعت نور به Redis ما میرسیدند. چالش بزرگ بعدی، ارسال این ۱۹۰۰+ پیام در ثانیه به صد ها هزاران کلاینت (مرورگر و موبایل) متصل بود. ما گزینههای مختلفی برای ارتباط Real-Time با کلاینت بررسی کردیم، گزینهها SignalR، SocketIO، Lightstreamer و SSE بودن.
ما به تکنولوژیای نیاز داشتیم که:
مقیاسپذیری (Scalability) بالایی داشته باشد.
روی تمام مرورگرها و دیوایسها به راحتی اجرا شود.
ترجیحاً نیاز به کتابخانه سنگین سمت کلاینت نداشته باشد.
با استک .NET ما هماهنگ باشد.
توسعه سریع و راحت
پ.ن: جدول با کمک AI تولید شده.
انتخاب ما: (SSE (Server-Sent Events
انتخاب بین این گزینهها دشوار بود، اما ما ملاکهای روشنی داشتیم: رایگان بودن، سادگی در اسکیل شدن، نگهداری آسان، عدم تحریم، سازگاری کامل با استک NET. و اجرای بدون دردسر روی تمام دستگاهها. روی .Net نسخه 10 یه سری کلاس و قابلیت برای راحتی کار اضافه شده، اما این به این معنی نیست که در نسخه های قدیمی تر نتوانید استفاده کنید.
SSE برنده قاطع این مقایسه برای نیاز ما بود. برخلاف WebSockets که ارتباطی دوطرفه و پیچیدهتر ایجاد میکند، ما فقط نیاز داشتیم داده را از سرور به کلاینت ارسال (Push) دهیم. SSE یک استاندارد وب بسیار ساده است که روی HTTP کار میکند. نیاز به هیچ کتابخانه اضافی در سمت کلاینت ندارد (در جاوااسکریپت EventSource به صورت built-in وجود دارد)، به راحتی توسط Load Balancer ها مدیریت میشود و مکانیزمهای تلاش مجدد (Retry) داخلی دارد. از نظر سازگاری بسیار عالی هست و بخاطر سادگی پیاده سازی تقریبا از سال 2011 پشتیبانی میشه، طبق caniuse در سال های اخیر پشتیبانی 100% داره و پشتیبانی 96% به صورت Global داره.
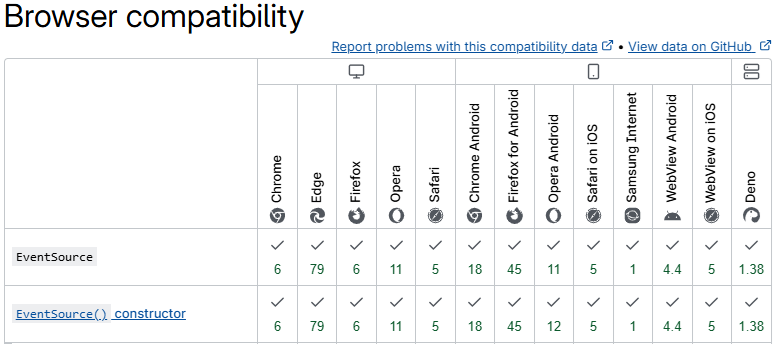
ما یک پروژه آزمایشی (POC) با کمک GitHub Copilot ایجاد کردیم. نتایج شگفتانگیز بود؛ سادگی پیادهسازی و عملکرد عالی آن، تصمیم ما را قطعی کرد.
نمونه کد بک اند
[HttpGet] public async Task GetPrices() { Response.Headers.Append("Content-Type", "text/event-stream"); Response.Headers.Append("Cache-Control", "no-cache"); Response.Headers.Append("Connection", "keep-alive"); Response.Headers.Append("X-Accel-Buffering", "no"); var id = Guid.NewGuid().ToString("N"); var cancellationToken = HttpContext.RequestAborted; var reader = SubscribersCoordinatorHostedService.Subscribe(id, cancellationToken); await foreach (var (eventName, eventData) in reader.ReadAllAsync(cancellationToken).ConfigureAwait(false)) { await Response.WriteAsync($"event: {eventName}\ndata: {eventData}\n\n", cancellationToken).ConfigureAwait(false); await Response.Body.FlushAsync(cancellationToken).ConfigureAwait(false); } }
نمونه کد فرانت اند
const source = new EventSource("/prices/stream"); source.onmessage = (event) => { const price = JSON.parse(event.data); render(price); }; source.onerror = () => { console.log("Retrying..."); };
برای پیادهسازی مکانیزم SSE در سمت کلاینت، چالشها دستکمی از بکاند نداشتند.ما روی این موضوع متمرکز شدیم تا این جریان مداوم داده را بدون افتِ کیفیتِ تجربه کاربری، به صفحه نمایش بیاوریم. ما در سمت کلاینت با ۶ چالش اساسی روبهرو بودیم که برای هر کدام استراتژی مشخصی چیدیم:
۱. محدودیت اتصالات همزمان در مرورگر (Connection Limit)
روی HTTP/1.1محدودیت ۶ عدد کانکشن همزمان باز به ازای هر دامنه وجود داره.
راهحل: خوشبختانه از آنجا که زیرساخت ما به طور کامل روی HTTP/2 سوار بود، این محدودیت به صورت پیشفرض به ۱۰۰ استریم همزمان (Multiplexing) افزایش پیدا کرده است. در نتیجه بدون نیاز به تغییر خاصی در کلاینت یا پیادهسازی SharedWorker، از این گلوگاه به سلامت عبور کردیم.
۲. چالش ارسال توکن و احراز هویت (Authentication)
کلاس پیشفرض EventSource در جاوااسکریپت، فقط از متد GET پشتیبانی میکند و متأسفانه هیچ راهِ سادهای برای تنظیم هدرهای سفارشی (مثل Authorization: Bearer) به ما نمیدهد. پس چطور باید کاربر را احراز هویت میکردیم؟
راهحل: ما سه راهکار پیش رو داشتیم:
راهکار اول: استفاده از فلگ withCredentials: true که کوکیها را همراه با درخواست ارسال میکند.
راهکار دوم: ارسال توکن به عنوان Query String در URL. این روش از نظر امنیتی اصلاً توصیه نمیشود، چون توکنها ممکن است در لاگهای سرور یا پراکسیها ذخیره شوند و نشت پیدا کنند.
راهکار سوم (انتخاب ما): استفاده از کتابخانههای ثالث مثل پکیج eventsource. این ابزارها با شبیهسازی استریم (اغلب با استفاده از Fetch API) به ما اجازه میدهند هم از متد POST استفاده کنیم و هم هدرهای سفارشی را کاملاً مدیریت کنیم. این کتابخانه دادهها را به صورت chunk-by-chunk میخواند و فرمت text/event-stream را به صورت دستی پارس میکند تا رفتار SSE را بازسازی کند.
انتخاب ما استفاده از پکیچ Eventsource بود. ما نیاز داشتیم که یکسری پیچیدگی ها رو کم بکنیم و تمرکز اصلی رو بزاریم روی نحوه و بیزینس پیاده سازی. این پکیچ یکسری پیچیدگی ها رو کم میکنه و یکسری امکانات اضافه و ساده برای شما محیا میکنه.
۳. طوفان بهروزرسانیها
با توجه به نرخ بالای تولید پیام، اگر میخواستیم به ازای هر رویداد (Event) مستقیماً State صفحه را آپدیت کنیم، مرورگر درگیر رندرهای متوالی و سنگین میشد و باعث افزایش تعداد render ها و افت responsiveness رابط کاربری میشد.
راهحل: برای آپدیت همزمان چندین قیمت در صفحه، ما از استراتژی Batch Update (بهروزرسانی دستهای) استفاده کردیم. به این شکل که دادههای دریافتی را موقتاً داخل یک ref جمعآوری کرده و سپس در فواصل زمانی مشخص، کل دادههای جدید را یکجا به UI تزریق میکردیم. این کار تجربه کاربری را به شدت روان و بدون لگ کرد.
۴. مدیریت خطا و اتصال مجدد (Reconnect)
در دنیای واقعیِ اینترنت موبایل و وایفای، قطعی اتصال اجتنابناپذیر است.
راهحل: یکی از زیباییهای ذاتی SSE این است که مرورگر به صورت پیشفرض استراتژی خوبی برای Reconnect دارد. اما برای کنترل دقیقتر، ما تصمیم گرفتیم خودمان دست به کار شویم. در زمان بروز خطا (داخل متد onerror)، کانکشن را به صورت دستی close میکنیم و با استفاده از یک setTimeout (و در نظر گرفتن تاخیر منطقی برای جلوگیری از فشار به سرور)، اتصال را مجدداً برقرار میکنیم.
۵. مدیریت منابع هنگام جابهجایی در صفحات
وقتی کاربر در اپلیکیشن حرکت میکند و وارد جزئیات صندوقها یا سهمهای مختلف میشود، اتصالاتی که برای صفحات قبلی باز شدهاند دیگر اعتباری ندارند و فقط منابع کلاینت و سرور را هدر میدهند.
راهحل: مکانیزم پاکسازی (Cleanup). در زمان عوض شدن صفحه و صندوقها (هنگام unmount شدن کامپوننت)، ما فوراً متد close را برای اتصال فعلی صدا میزنیم و برای دیتای جدید در صفحه جدید، یک کانکشن تازه باز میکنیم. این کارِ به ظاهر ساده، تاثیر فوقالعادهای در بهینه ماندن مصرف مموری مرورگر و کاهش بار سرور داشت.
۶. چالش مقادیر اولیه
اتصال SSE فقط مسئول دیتاهای لحظهای بود. برای جلوگیری از inconsistency، کلاینت ابتدا snapshot آخرین وضعیت قیمتها را از API معمولی دریافت میکرد که کمی تاخیر داشت و سپس stream فقط تغییرات بعدی را اعمال میکرد. در reconnect هم همین snapshot/re-sync انجام میشد تا از دست رفتن پیامهای Redis Pub/Sub یا قطعی اینترنت باعث نمایش داده stale نشود.
اینجا به یکی از بزرگترین چالشهای فنی رسیدیم. ما توانسته بودیم داده را به Redis برسانیم و روش ارسال به کلاینت را هم انتخاب کرده بودیم. اما چگونه باید در سرویس NET. خود، این حجم عظیم داده (۱۹۰۰ پیام در ثانیه از چندین صف مختلف) را از Redis میخواندیم و به شکل کارآمدی بین کاربران توزیع میکردیم؟
ما با ترکیبی از دادههای عمومی (مثل قیمت سهم) و اختصاصی (مثل دارایی کاربر) روبرو بودیم. داده های عمومی برای همه کاربران یکسان بودند برای مثال قیمت یه سهم. داده های اختصاصی داده هایی بودند که مخصوص یک کاربر خاص هستند، برای مثال کاربر مقداری از دارایی خودش رو فروخته یا به مقدار اون اضافه کرده و خریده و باید در لحظه در دارایی خودش لحاظ شده ببینه. معماری ما باید این ترکیب دیتا رو ساپورت میکرد. همچنین معماری باید برای افزودن صفهای جدید در آینده انعطافپذیر میبود.
چالشها:
حجم بالای پیام در لحظه.
ترکیبی از دادههای عمومی (Public) و دادههای اختصاصی کاربر (Private).
لزوم مدیریت همزمانی (Concurrency) بالا.
نیاز به معماری توسعهپذیر برای افزودن صفهای جدید در آینده.
تعداد کاربر در لحظه بالا که نیاز به broadcast دارن
برای پیادهسازی این بخش حیاتی در NET.، ما دو الگوی اصلی TPL Dataflow و Channel را بررسی کردیم:
پ.ن: جدول با کمک AI تولید شده.
انتخاب ما: System.Threading.Channels
ملاکهای اصلی ما سادگی پیادهسازی، سرعت توسعه، کمترین تأخیر، بیشترین بازدهی و مدیریت بهینه رم و CPU بود. TPL Dataflow برای pipeline های پیچیدهتر، transform های چند مرحلهای، batching و مدل actor-like گزینه قدرتمندی است. اما کتابخانه System.Threading.Channels دقیقاً برای همین سناریوها طراحی شده است: انتقال داده بین Producer و Consumer با نهایت سرعت و کمترین سربار. Channels در .NET مثل یک لوله FIFO هوشمند و کاملاً asynchronous عمل میکند که مایکروسافت آن را در قلب دو موتور مهم خود Kestrel و SignalR استفاده کرده است. در تجربیات خودمون، عالی عمل کرد. این ساختار کاملاً thread-safe و lock-free است و در بسیاری از سناریوها تقریباً zero-allocation کار میکند، بدون اینکه نگران synchronization، race condition یا مدیریت دستی queue باشید. نتیجهاش کدی تمیزتر، مقیاسپذیرتر و با عملکرد بسیار بالاتر است.
طبق این بنچمارک، مصرف حافظه و سرعت Channel به مراتب بهتر از Dataflow هست.
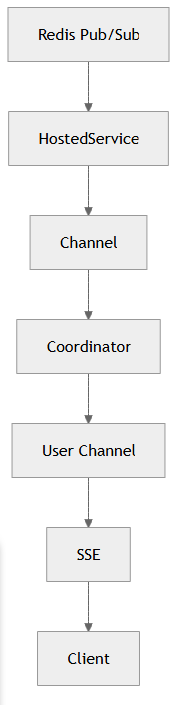
ما یک معماری لایه بندی شده و ماژولار طراحی کردیم، هر Redis Channel رو در HostedService گذاشتیم که پیام ها رو به Channel داخلی میریزه. برای جلوگیری از رشد بی نهایت صف ها، از BoundedChannel با ظرفیت ۱۰۰k و DropOldest استفاده کردیم. این به این معنی هست که حداکثر ظرفیت چنل ۱۰۰k هست به دو دلیل: دلیل اول اینکه بی نهایت نباشیم که اگر کند شدیم کلی پیام رو نگه نداریم. دوم اینکه مشخص شدن تعداد باعث افزایش سرعت عملیات رو چنل میشه. اگر هم پیام بیشتری بیاد چون DropOldest گذاشتیم باعث میشه قدیمی ترین پیام حذف بشه.
یه Coordinator هم گذاشتیم برای مدیریت Redis Channel ها . Coordinator میاد Channel ها رو مدیریت میکنه و برای هر کاربر Channelجدا میسازه.
ما همه پیام ها را کورکورانه به همه کاربران ارسال نمیکردیم. هر connection بر اساس context صفحه، دارایی ها یا watchlist کاربر فقط subset موردنیاز را دریافت میکرد. این filtering باعث شد fan-out واقعی کنترل شده بماند و تعداد eventهای خروجی با تعداد کل نمادهای بازار ضرب نشود.
این معماری scalable هست و برای صف های جدید آمادهست.
RLC → C++ Ingestion → Kafka/Protobuf → Redpanda Connect → Redis Pub/Sub → .NET Hosted Services → Coordinator → Per-user/per-subscription channels → SSE → Client batch renderer
وقتی این معماری رو توسعه دادیم و روی محیط های مختلف تست های سنگین مون رو با همراهی تیم SRE پاس کردیم، نوبت به لحظه نفسگیر انتشار رسید. استراتژی ما «برو بالا، نترس» بود، اما با کمربند ایمنی!
ما برای مدیریت این فرآیند از Unleash به عنوان ابزار Feature Toggle استفاده کردیم. در قدم اول، این فیچر رو فقط برای ۳۰ درصد از کاربران باز کردیم. همزمان چشم مون به مانیتورها و داشبوردهای گرافانا بود. خوشبختانه همه چیز عالی بود و هیچ مشکل یا افت پرفورمنسی در بک اند و زیرساخت ندیدیم.
اما تو همین فاز ۳۰ درصد، بازخورد مهمی از سمت کاربران و مدیر محصول تیم گرفتیم: افکت بصری تغییر قیمت ها روی صفحه چندان جذاب نبود و حس Real-time بودن رو به خوبی منتقل نمیکرد. اینجا بود که با یکی از توسعه دهنده های فرانت اند تیم دست به کار شدیم. ما تصمیم گرفتیم افکت تغییر قیمت پلتفرم TradingView رو الگو قرار بدیم؛ افکتی که در دنیا کاملاً شناخته شده و تست شده است و از نظر تجربه کاربری نتیجه ای عالی دارد.
نکته فنی و جذاب این بخش این بود که ما نمیخواستیم برای این افکت بصری، کدهای جاوااسکریپت (JS) اضافه بنویسیم. درگیر کردن JS روی کلاینت برای پردازش های اینچنینی میتونست در مقیاس بالا برامون سربار (Overhead) ایجاد کنه. در نتیجه، بچه های فرانت اند با چند تا تریک ساده و تمیز CSS همون افکت TradingView رو پیاده سازی کردن که هم به شدت سبک بود و هم خروجی بینقصی داشت.
بعد از اعمال این تغییرات ظاهری و اطمینان کامل از پایداری سیستم، با خیال راحت فیچر رو برای ۵۰ درصد کاربران فعال کردیم. چند روزی در این وضعیت موندیم تا دیتای رفتار سیستم و کاربران به اندازه کافی جمع آوری بشه. وقتی مطمئن شدیم همه چیز سر جای خودشه، شیر رو بیشتر باز کردیم؛ اول به ۷۰ درصد رسیدیم و در نهایت، به ۱۰۰ درصد.
طراحی معماری روی کاغذ یک چیز است و عملکرد آن زیر بار واقعی چیز دیگر. یکی از نگرانی های اصلی ما، میزان مصرف منابع سرور بود. با توجه به اینکه قرار بود هزاران کانکشن باز (Open Connections) به صورت همزمان داشته باشیم، مدیریت حافظه حیاتی بود. یکی از بزرگترین ترس ها این بود: "نکند صف ها پر شده باشند و ما خبر نداریم؟".
نتیجه نهایی حتی برای خود ما هم شگفت انگیز بود. به لطف ساختار سبک SSE و مدیریت حافظه بهینه در .NET (به خصوص استفاده از System.Threading.Channels که سربار بسیار کمی دارد)، ما توانستیم با منابعی بسیار محدود، ترافیک عظیمی را مدیریت کنیم.
ما از Prometheus برای جمع آوری متریک ها و Grafana برای بصری سازی استفاده کردیم. اما متریک های پیشفرض کافی نبودند. ما متریکهای اختصاصی (Custom Metrics) را روی Channelها سوار کردیم تا سلامت جریان داده را لحظه به لحظه رصد کنیم:
Channel Depth (عمق کانال): چه تعداد پیام در صف منتظر پردازش هستند؟ اگر این عدد بالا برود، یعنی مصرف کننده (Consumer) کند شده است.
Ingest vs. Drain Rate: سرعت ورود داده به کانال در مقابل سرعت خروج.
Active SSE Connections: تعداد کاربران آنلاین و متصل به هر نود.
این داشبوردها به ما اجازه داد گلوگاهها را قبل از اینکه کاربر متوجه کندی شود، شناسایی کنیم.
نتیجه مانیتورینگ بسیار جالب بود. با وجود ورود ۱۹۰۰ پیام در ثانیه، به لطف سرعت بالای معماری، نمودارها نشان میدادند که در هر لحظه نهایتاً ۱۵ پیام داخل Channel باقی میماند و بلافاصله تخلیه میشد. این یعنی تأخیر پردازش داخلی ما عملاً صفر (Near Zero) بود. این نشون میده Channel چقدر عالیه ♥️
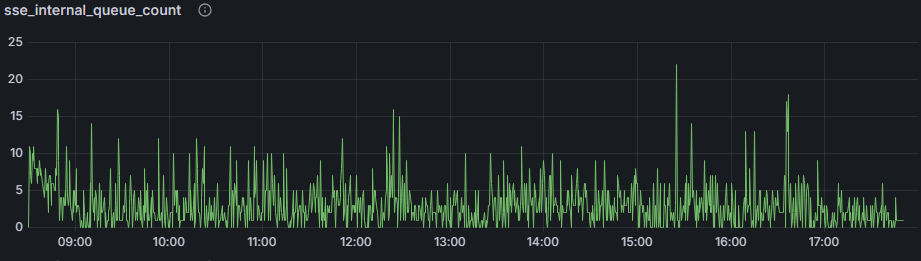
شاید بپرسید نتیجه این همه وسواس در انتخاب تکنولوژی (Redis In-Memory + SSE + Channels) چه بود؟ نتایج در محیط عملیاتی (Production) فراتر از انتظار ما بود.
معماری ما به شدت سبک (Lightweight) از آب درآمد. ما توانستیم با منابعی بسیار محدود، ترافیک عظیمی را هندل کنیم:
معماری: کلاستر کوبرنتیز شامل ۶ پاد (Pod) فعال.
مصرف رم: هر پاد به طور میانگین تنها ۵۵ مگابایت رم مصرف میکند.
مصرف پردازنده: در اوج ترافیک بازار، مصرف CPU هر پاد حدود ۲۰٪ است.
ظرفیت: این کلاستر کوچک، پاسخگوی چند ده هزار کانکشن باز همزمان است، بدون اینکه کلاینت ها افت سرعتی احساس کنند.

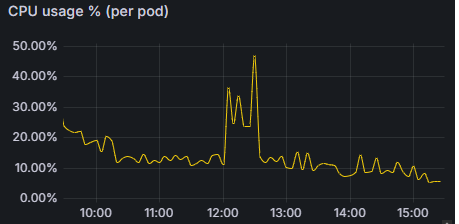
این بهره وری بالا (High Efficiency) به دلیل حذف سربارهای اضافی پروتکل هایی مثل WebSocket و استفاده بهینه از حافظه توسط System.Threading.Channels است.
این یعنی ما عملاً با سخت افزاری بسیار سبک، در حال سرویس دهی به ده ها هزار کاربر بدون هیچگونه افت کیفیت یا تأخیر هستیم.
در مسیر پیاده سازی، با چند دیوار محکم برخورد کردیم که تجربه آنها برای هر تیمی ارزشمند است:
چالش پراکسی (The Proxy Trap): وقتی اولین بار سرویس را بالا آوردیم، متوجه شدیم برخی کاربران دیتا را با تأخیر میگیرند یا کلا قطع میشوند. مشکل از کدهای ما نبود، بلکه از زیرساخت شبکه و پراکسیها (مثل Nginx یا پراکسیهای سازمانی) بود. تکنولوژی SSE یک اتصال باز طولانی است. بسیاری از پراکسی ها به طور پیشفرض پاسخ ها را "بافر" (Buffer) میکنند تا یکجا بفرستند، که این کار SSE را خراب میکند.
راه حل: ما هدرهای X-Accel-Buffering: no را تنظیم کردیم و مطمئن شدیم تنظیمات پراکسی ها اجازه عبور استریم های طولانی بدون بافرینگ را میدهند.
چالش نشت حافظه (Memory Leak): خطرناکترین سناریو در این معماری، کاربرانی هستند که اینترنت شان قطع میشود یا تب را میبندند، اما سرور هنوز دارد برایشان در Channel اختصاصی مینویسد. اگر این کانال ها پاک نشوند، سرور منفجر میشود.
راهحل: ما مکانیزم RequestAborted در HttpContext را به شدت جدی گرفتیم. به محض اینکه سیگنال قطع ارتباط از کلاینت بیاید (TCP FIN)، ما بلافاصله Channel مربوطه را Dispose کرده و از لیست Coordinator حذف میکنیم.
مقیاسپذیری (Scale): برای مدیریت روزهای شلوغ بازار اگر لود مون ۲ برابر شد چیکار کنیم ؟ آیا worst case رو دیدم برای مقیاس شدن.
راه حل: از HPA (Horizontal Pod Autoscaler) در کوبرنتیز استفاده کردیم. سیستم ما به گونهای تنظیم شده که با افزایش تعداد کاربران و بالا رفتن مصرف CPU و RAM، به طور خودکار تعداد پادها را افزایش میدهد تا همیشه پاسخگوی نیاز کاربران مفید باشد.
چالش قطع شدن کانکشن: وقتی کلاینت درخواست SSE رو ارسال میکنه ممکنه در اون لحظه ما دیتایی برای ارسال نداشته باشیم. برای مثال ممکنه یک سهم یا صندوق برای لحظاتی بسته شده و قیمت جدیدی وجود نداره. در این حالت مرورگر درخواست رو cancel میکنه و باعث retry و خطا میشه.
راه حل: ما از مکانیزم tcp ایده گرفتیم که در بازه های مختلف HB (heartbeat) ارسال میکنه که هم باعث میشه سلامت اتصال بررسی بشه هم باعث بسته نشدن اتصال و استفاده مجدد بشه. ما هم اومدیم در فاصله زمانی حدود 20 ثانیه از سمت سرور یک مسیج HB تولید میکنیم که اتصال پایدار بمونه.
این پروژه برای ما یادآوری کرد که در سیستمهای real-time همیشه پیچیدهترین ابزار، بهترین جواب نیست. Kafka را برای جایی نگه داشتیم که durability و replay مهم بود؛ Redis Pub/Sub را برای fan-out سریع و ephemeral انتخاب کردیم؛ در backend با System.Threading.Channels یک مسیر سبک و کمسربار برای توزیع پیامها ساختیم؛ و در سمت کلاینت با SSE، بدون نیاز به پروتکل دوطرفه، قیمتها را با latency پایین push کردیم.
نکتهی کلیدی این بود که قبل از انتخاب ابزار، ماهیت داده را درست فهمیدیم: قیمت لحظهای دادهای replaceable است، نه event غیرقابلازدسترفتن. همین تصمیم باعث شد بتوانیم در جاهایی مثل Redis Pub/Sub و DropOldest آگاهانه loss محدود را بپذیریم و در عوض freshness، سادگی و پایداری سیستم را حفظ کنیم.
در نهایت، موفقیت این معماری فقط نتیجهی انتخاب تکنولوژی نبود؛ نتیجهی ترکیب درست monitoring، rollout تدریجی، snapshot/re-sync، heartbeat، feature flag و همکاری نزدیک بین تیم محصول، backend، frontend و SRE بود.