حتما تا به حال برایتان پیش آمده که یک برنامه روی لپتاپ خودتان درست کار کند، اما وقتی میخواهید آن را روی سرور اجرا کنید، با هزار خطا مواجه شوید. یا کتابخانه ای نیست، یا نسخه فرق دارد و... یا مثلا برای راهاندازی یک سرویس جدید، باید ساعتها پشت ترمینال بنشینید و دستورات تکراری را یکی یکی تایپ کنید. این مشکلات ریشه در یک چیز دارند: جدا بودن "توسعه" از "زیرساخت". در این نوشته به شش مفهومی میپردازیم که این جدایی را از بین میبرند و اجازه میدهند زیرساخت هم مثل کد رفتار کند.
در توسعه نرمافزار، نوشتن کد فقط نیمی از کار است. نیم دیگر، اجرای آن کد در جایی خارج از لپتاپ توسعه دهنده است. اینجاست که مشکلات بروز میکنند. برنامه در محیط توسعه کار میکند اما در محیط تولید از کار میافتد. راهاندازی سرور جدید روزها زمان میبرد، و با زیادشدن کاربران سیستم پاسخ نمیدهد. شش مفهوم زیر هرکدام به نوعی در حل این مشکلات کمک میکنند:
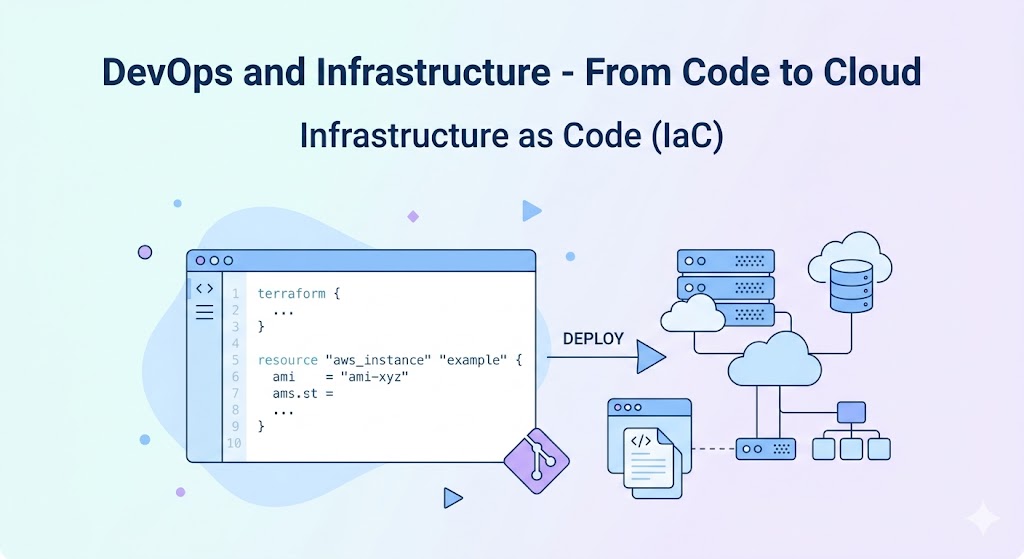
Infrastructure as Code (IaC)
زمانی که زیرساخت نرمافزاری مانند سرور، دیتابیس و شبکه به صورت دستی و با کلیک کردن در پنلهای مختلف راهاندازی میشود، دو مشکل بزرگ ایجاد میگردد: اول، هیچ مستند دقیقی از تنظیمات وجود ندارد. دوم، اگر آن سرور خراب شود، راهاندازی مجدد آن ساعتها یا روزها زمان میبرد.
IaC یعنی توصیف تمام زیرساخت به صورت فایلهای متنی که در سیستم کنترل نسخه مانند گیت ذخیره میشوند. در این روش، به جای آن که کسی دستورات را یکی یکی تایپ کند، ابزاری مانند Terraform یا Ansible تنظیمات را از روی همان فایلها اعمال میکند.
اگر سروری خراب شود، کافی است همان فایل را دوباره اجرا کرد. اگر تیم بزرگ شود، همه میتوانند ببینند زیرساخت دقیقا چگونه تنظیم شده است. این رویکرد خطای انسانی را نیز کاهش میدهد و راهاندازی مجدد زیرساخت را از چند روز به چند دقیقه میرساند.
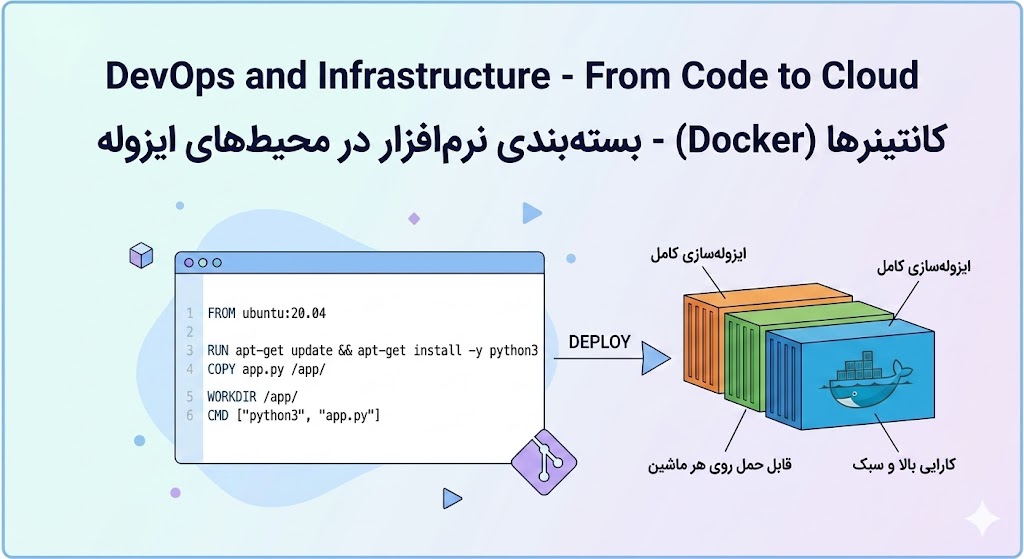
Containers (Docker)
یکی از رایجترین مشکلات در دنیای نرمافزار، تفاوت محیط اجراست. برنامه ای که روی لپتاپ توسعه دهنده درست کار میکند، روی سرور تولید خطا میدهد. دلیل این مشکل معمولا تفاوت نسخه کتابخانهها، سیستمعامل یا تنظیمات محیطی است.
Containerها این مشکل را حل میکنند. یک Container، برنامه و همه وابستگیهای آن را در یک بسته قابل حمل قرار میدهد. این بسته روی هر ماشینی که داکر نصب باشد، دقیقا به همان شکل اجرا میشود. تفاوتی که با ماشین مجازی دارد این است که Container ها هسته سیستمعامل میزبان را به اشتراک میگذارند، در نتیجه بسیار سبک تر هستند و در کسری از ثانیه اجرا میشوند. با استفاده از داکر، دیگر بهانه "IT WORKS ON MY MACHINE" قابل قبول نیست. اگر برنامه روی لپتاپ توسعه دهنده کار میکند، روی هر سرور دیگری هم کار خواهد کرد.
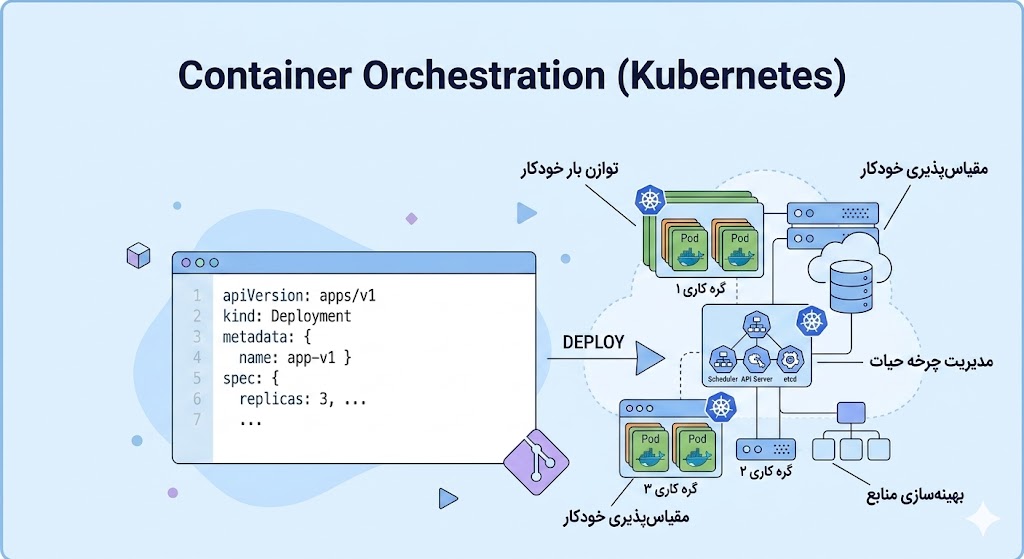
Container Orchestration (Kubernetes)
حال فرض کنیم نه فقط یکی بلکه تعداد زیادی ( برای مثال 50 تا) Container داریم. هرکدام باید روی کدام سرور برود؟ اگر یکی از آنها خراب شد چه کسی دوباره راهاندازیاش میکند؟ اگر ترافیک سایت ناگهان زیاد شد، چه کسی تعداد Containerها را زیاد میکند؟
Kubernetes دقیقا این کار را انجام میدهد. به آن میگوییم" سه نسخه از این Container را میخواهیم همواره روشن باشد" خودش تصمیم میگیرد هر کدام کجا برود. اگر یکی خراب شد بدون اطلاع ما آن را جایگزین میکند. اگر ترافیک زیاد شد، تعداد را زیاد میکند. Kubernetes مانند یک مدیر خودکار برای Containerها عمل میکند. به همین دلیل به استاندارد اجرای برنامه در شرکت های بزرگ تبدیل شده است.
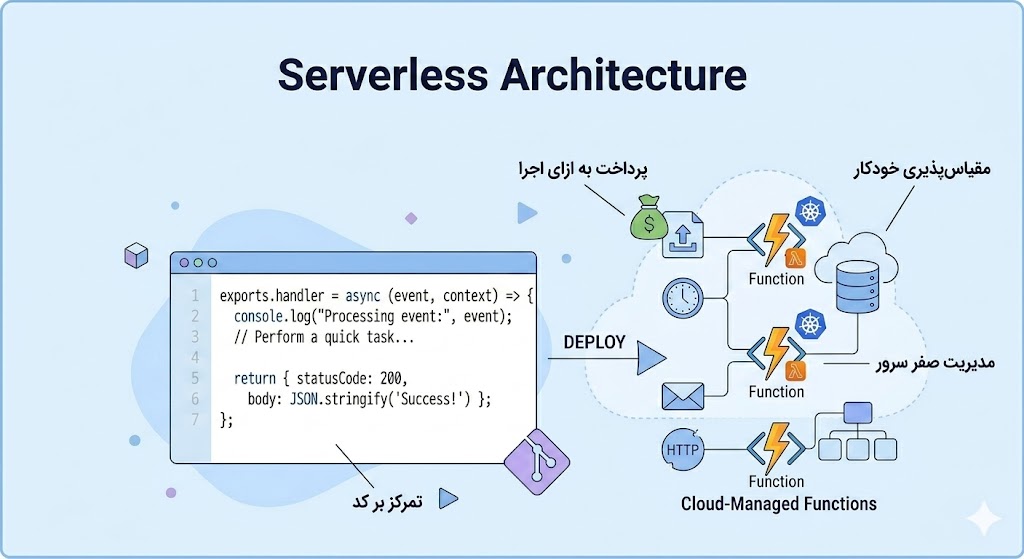
Serverless Architecture
گاهی پیش میآید که قصدمان فقط نوشتن یک تابع ساده است. مثلا تابعی که هرزمان عکسی آپلود شد، اندازه آن را تغییر دهد. برای کار های ساده چرا نیاز به خرید یک سرور کامل است؟ همیشه این هزینه را پرداخت کنیم حتی وقتی هیچ عکسی آپلود نمیشود!
معماری Serverless این پیچیدگی را از بین میبرد. در این روش، توسعهدهنده فقط کد خود را به صورت صورت یک تابع مینویسد و آن را در اختیار ارائهدهنده ابر مانند AWS Lambda قرار میدهد. ارائهدهنده ابر مسئولیت اجرا، مقیاسپذیری، و در دسترسبودن را برعهده میگیرد. هزینه نیز فقط به ازای تعداد دفعات اجرا و مدت زمان اجرا محاسبه میشود. اگر تابع یک میلیون بار اجرا شود، هزینه پرداخت میشود اگر یک روز اصلا اجرا نشود، هزینه صفر است. نام Serverless به نظرم کمی گمراه کننده است چرا که سرور وجود دارد، فقط توسعه دهنده آن را نمیبیند و مدیریت نمیکند.
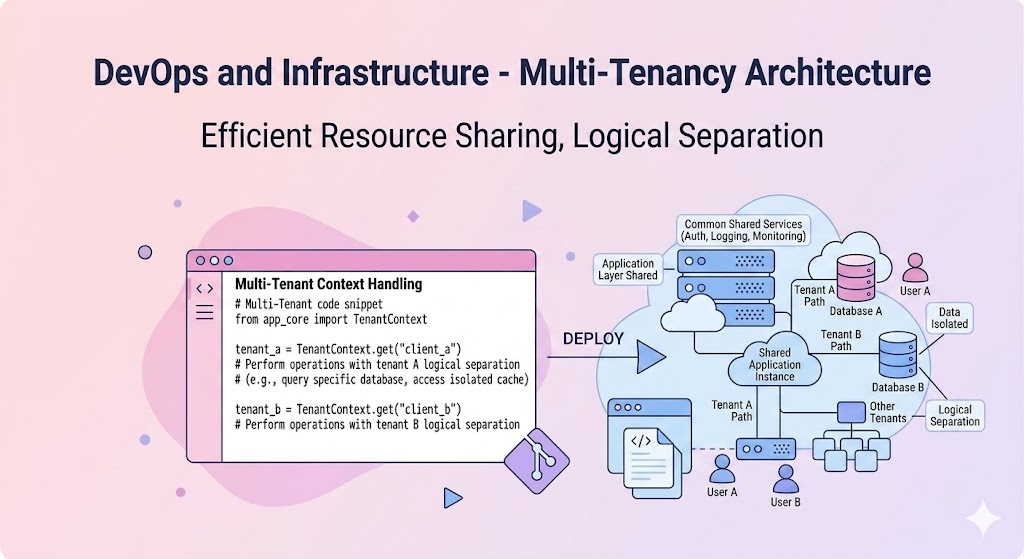
Multi-Tenancy Architecture
سرویسهایی مثل جیمیل را در نظر بگیرید. میلیاردها کاربر از یک نسخه واحد نرمافزار استفاده میکنند، اما هر کاربر فقط دادههای خود را میبیند. این طراحی همان معماری Multi-Tenancy نام دارد. در این معماری، یک نمونه نرمافزار به چندین مشتری سرویس میدهد، درحالی که دادههای آنها کاملا از یکدیگر جدا باقی میماند. سه سطح اصلی برای جداسازی داده ها در پیادهسازی چنین سرویس هایی وجود دارد:
سطح اول: یک دیتابیس جداگانه برای هر مشتری در نظر گرفته شود. این روش بالاترین امنیت را دارد اما با افزایش تعداد کاربران، تعداد دیتابیس ها بسیار زیاد شده و هزینه نگهداری بالا میرود.
سطح دوم: اسکیماهای جداگانه در یک دیتابیس مشترک در نظر گرفته شود. این روش تعادل خوبی بین هزینه و ایزولهسازی ایجاد میکند.
سطح سوم: همه مشتریان در یک اسکیما با یک فیلد شناسه مشتری. این روش بیشترین بهرهوری از منابع را دارد اما اگر در کوئری زدن شرط فیلد شناسه فراموش شود و داده های کاربران با هم قاطی شود خطرناک است.
مشخص است که انتخاب سطح مناسب در طراحی سرویس های اشتراکی اهمیت زیادی دارد.
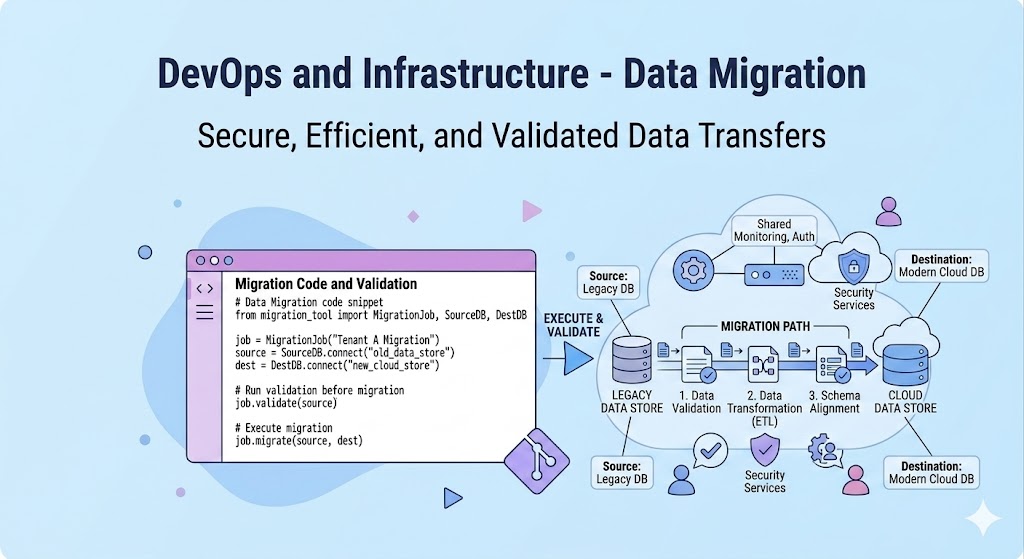
Data Migration
هنگامی که شرکتی تصمیم میگیرد دیتابیس خود را از سیستمی به سیستم دیگر منتقل کند، یا معماری برنامه را از یک حالت یکپارچه به میکروسرویس تغییر دهد، ناگزیر است داده های قبلی را به یک سیستم جدید انتقال دهد. به این فرایند مهاجرت داده گویند.
این کار به آن سادگی که به نظر میرسد نیست! چالش هایی در این مسیر وجود دارد. برای مثال تفاوت در فرمت داده ها ( برای مثال داده های تاریخی ممکن است در سیستم های مختلف با فرمت های مختلفی ثبت شده باشند.) همچنین در زمان انتقال ممکن است سایت چند دقیقه از کار بیفتد.
در مهاجرت داده هدف این است که در این تغییر( دیتابیس یا معماری) داده های قبلی نباید از بین برود.
منابع :
Terraform Docs
Docker Docs
Kubernetes Docs
AWS Lambda Docs