
امبدینگ نمایشی عددی از یک شیء یا داده (مانند متن، تصویر یا صوت) است که بهگونهای طراحی شده تا توسط مدلهای یادگیری ماشین و الگوریتمهای جستوجوی معنایی قابل درک و استفاده باشد.
در واقع، امبدینگ، مفاهیم پنهان در یک جمله، تصویر یا قطعه صدا را به شکل برداری از اعداد بیان میکند؛ برداری که تمام ویژگیهای مهم آن داده را فشردهسازی کرده و در قالبی قابل تحلیل در اختیار مدل قرار میدهد.
این یعنی مفهوم کامل یک تصویر یا متن در قالب یک بردار عددی خلاصه میشود — برداری که نزدیکی یا فاصلهاش با بردارهای دیگر، نشاندهنده میزان شباهت یا تفاوت مفهومی میان آنهاست.
بهبیان ساده، امبدینگ به مدل هوش مصنوعی امکان میدهد که شباهت معنایی میان دادهها را تشخیص دهد.
برای مثال، اگر یک تصویر یا سند متنی به مدل داده شود، مدلی که از امبدینگ استفاده میکند میتواند موردی با مفهوم مشابه را بازیابی کند.
از آنجا که امبدینگ توانایی رایانه در درک روابط میان مفاهیم را ممکن میسازد، یکی از پایههای اساسی هوش مصنوعی (AI) به شمار میرود.
در حوزه بینایی ماشین، امبدینگ تصاویر به مدلها امکان میدهد تا ویژگیهای بصری تصاویر را به بردارهای عددی تبدیل کنند. این بردارها نمایانگر اطلاعاتی مانند رنگ، شکل، بافت و سایر ویژگیهای تصویری هستند. با استفاده از این بردارها، مدلها میتوانند تصاویر مشابه را شناسایی کرده یا درک بهتری از محتوای تصویری داشته باشند.
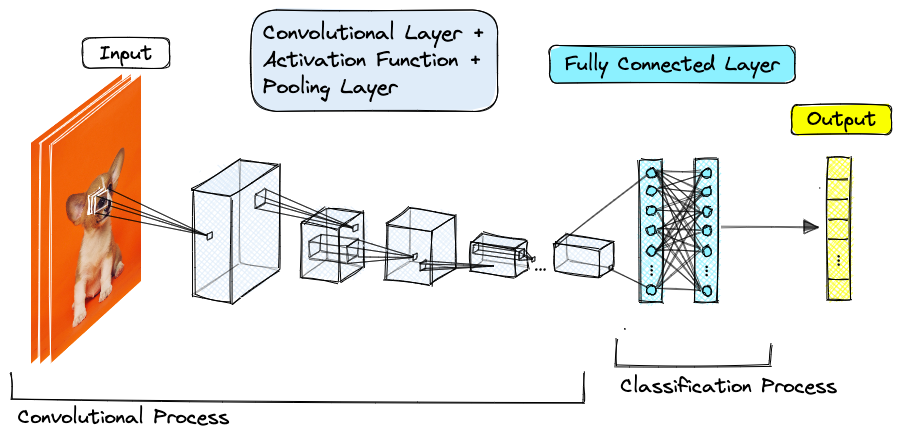
در پردازش زبان طبیعی (NLP)، امبدینگ متنی به مدلها کمک میکند تا کلمات، جملات یا اسناد را به بردارهای عددی تبدیل کنند که معنای آنها را حفظ میکند. این بردارها به مدلها امکان میدهند تا مفاهیم مشابه را شناسایی کرده، ترجمه کنند، خلاصهسازی انجام دهند یا پاسخهای مناسبی در چتباتها ارائه دهند.
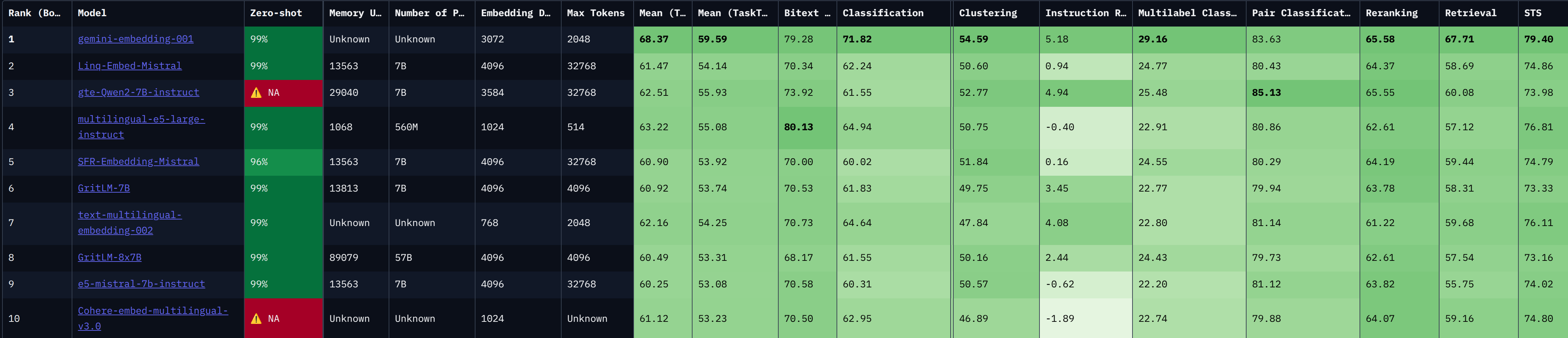
FaMTEB (Farsi Massive Text Embedding Benchmark) اولین بنچمارک جامع برای ارزیابی مدلهای تعبیه متن در زبان فارسی است. این بنچمارک بر پایه MTEB (Massive Text Embedding Benchmark) ساخته شده و شامل ۶۳ مجموعه داده در ۷ وظیفه مختلف است:
تعیین اینکه هر ورودی (مثل جمله یا سند) به کدام دسته تعلق دارد.
مثال:
یک جمله پشتیبانی کاربر مانند «میخواهم هزینه اشتراکم را تمدید کنم» باید به دسته «پشتیبانی» و جملهای مثل «میخواهم اشتراک بخرم» به دسته «خرید» برچسب بخورد.
در یک سیستم خبرخوان، تشخیص اینکه یک خبر درباره «ورزش»، «سیاست» یا «فنآوری» است.
گروهبندی دادهها بر اساس شباهت معنایی بدون استفاده از برچسبهای از پیش تعیین شده.
مثال:
نظرات کاربران: اگر ۱۰۰ دیدگاه درباره یک گوشی جمعآوری شود، خوشهبندی میتواند آنها را به گروههایی مثل «کیفیت دوربین»، «عمر باتری» و «قیمت» تقسیم کند.
سازماندهی مقالات تحقیقاتی: متنها را بر اساس موضوع (مثل NLP، computer vision، robotics) دستهبندی میکند .
بررسی اینکه آیا دو ورودی (جملات یا اسناد) از نظر معنایی مشابه هستند یا خیر.
مثال:
تشخیص اینکه «امروز باران میبارد» و «هوا امروز بارانی است» معنایی مشابه دارند یا نه.
در سیستم Q&A، بررسی اینکه آیا پاسخ ارائهشده دقیقا همان پرسش کاربر را پاسخ میدهد.
گرفتن یک لیست از نتایج جستوجو (برحسب کلیدواژه) و مرتب کردن مجدد آنها بر اساس شباهت معنایی دادهها.
مثال:
پس از دریافت نتایج اولیه جستوجو برای «بهترین رستورانهای تهران»، مدل مبتنی بر امبدینگ آنها را بر اساس شباهت معنایی با پرسش اولیه رتبهبندی میکند، نتیجهای که مربوطتر و دقیقتر است در بالا قرار میگیرد .
یافتن مستندات یا جملههای مرتبط با یک پرسش با پرسش و دادهها هر دو به بردار تبدیل میشوند، سپس نزدیکترینها انتخاب میشوند.
مثال:
از یک بانک مقالات فارسی، با پرسش «اثرات تغییرات اقلیمی بر کشاورزی»، مقالات مرتبط بیرون کشیده میشوند.
در یک سیستم چتبات RAG، برای پاسخ به سوالهای چت، اسناد مرتبط فراخوانده میشوند .
انتخاب بهترین خلاصه برای یک متن طولانی از میان چند گزینه، با استفاده از بردارهای امبدینگ.
مثال:
برای یک مقاله تحقیقی، سه خلاصه خودکار تولید شده؛ سیستم آنها را امبد میکند و بردار آنها را با بردار مقاله اصلی مقایسه میکند تا نزدیکترین و مرتبطترین خلاصه را انتخاب کند.
معمولاً با اندازهگیری بردارهای مرکزی یا معیارهای لحاظشده شباهت، مانند استفاده از Medoid برای انتخاب نمایندهترین مورد.
محاسبه تعداد یا نمرهی شباهت عددی بین دو متن، معمولا عددی بین ۰ تا ۱، که نشاندهنده میزان معنایی بودن آنها است.
مثال:
دو جمله مثل «هوای امروز گرم است» و «امروز گرما زیاد بود» میتوانند امتیاز ۰.9 دریافت کنند.
STS کاربردهایی مثل امتیازدهی کیفیت ترجمه ماشین، خودارزیابی چتبات یا تشخیص دوبارهگویی دارند .
از این ۶۳ مجموعه داده، ۳۹ مجموعه جدید هستند که با استفاده از روشهای مختلفی مانند جمعآوری از وب، ترجمه مجموعههای داده انگلیسی و تولید دادههای مصنوعی با استفاده از مدلهای زبانی بزرگ (LLMs) ایجاد شدهاند.
یکی از ویژگیهای منحصربهفرد FaMTEB، تمرکز بر ارزیابی مدلها در زمینه چتباتها و سیستمهای تولید تقویتشده با بازیابی (RAG) است. این بنچمارک برای اولین بار مجموعه دادههایی برای ارزیابی عملکرد مدلها در این زمینهها ارائه میدهد.
FaMTEB یک بنچمارک متنباز است که شامل مجموعه دادهها، کدها و یک لیدربورد عمومی برای مقایسه عملکرد مدلهای مختلف است. این بنچمارک گامی مهم در جهت ارتقاء پردازش زبان طبیعی در زبان فارسی محسوب میشود.
لینک مقاله: FaMTEB: Massive Text Embedding Benchmark in Persian Language
لینک لیدربورد: FaMTEB Leaderboard