در سیاهچالهٔ نرمافزار و معماری نرمافزار، هر عبارت میتواند دری به سوی دنیایی بیکران باز کند.
گاهی یک واژه آنقدر عمیق است که ماهها طول میکشد تا مفهوم آن را به صورت کامل لمس کنید.
در این پست، قصد دارم شما را به سفری دعوت کنم که در هر ایستگاه یکی از بیست مفهوم رایج، در معماری نرمافزار بیان میشود.
تمام تلاش من این بوده است که توضیحات، ساده و روان باشند، بدون اینکه از دقت و جزئیات علمی کم شود.در نهایت اگر پس از خواندن این نوشته، بهرهوری علمی و عملیتان بیشتر شود، به هدفم رسیدهام . این نوشته حاصل جستجو در منابع معتبر علمی (مقالات علمی، مستندات ابزارهای متنباز، و وبلاگهای مهندسی شرکتهای بزرگ) است.
ایستگاه اول : Chaos Engineering

نوشتهها و تجربههای منتشرشده از تیمهای بزرگی مثل نتفلیکس نشان میدهد که تابآوری یک سیستم توزیعشده هیچوقت قابل پیشبینی نیست. زیرا تعداد حالات خرابی آنقدر زیاد است که هیچ تست سنتی نمیتواند همه آنها را پوشش دهد.
Chaos Engineering دقیقاً برای همین مسئله طراحی شده است: این مفهوم برخلاف تصور عموم، به معنای خرابکاری تصادفی نیست، بلکه یک روش علمی و دقیق است. در این رویکرد، ابتدا حالت پایدار سیستم تعریف میشود، سپس فرضیهای مطرح میشود و پس از آن، خطای موردنظر به صورت کنترلشده با یک شعاع انفجار محدود، مانند واکسن تزریق میشود. در این آزمایش هدف نهایی فرض کردن تاب آوری نخواهد بود بلکه اثبات تابآوری است.
تفاوت مهندسی آشوب با تست سنتی در این است که اولی در محیط واقعی به صورت مداوم اجرا میشود، دومی در محیط تست، به صورت نقطهای انجام میشود.
یک مرور ادبیات گسترده که ۸۸ منبع را بین ژانویه ۲۰۱۹ تا آوریل ۲۰۲۴ بررسی کرده، نشان میدهد که سازمانهای متوسط و بزرگ بیشترین استفاده را از این روش دارند. ابزارهایی متنباز مثل Kubernetes امکان تعریف سناریوهای خرابی را به صورت Chaos-as-Code فراهم میکنند. سناریوهای کلاسیک شامل قطع ارتباط بین سرویسها مانند پارتیشنبندی شبکه، حذف تصادفی Podها، و تزریق تأخیر در پاسخ پایگاه داده است.
اگر سیستم شما آنقدر ساده است که همه حالتهای خرابی آن را از قبل میشناسی، یا اگر مشتریهای حقیقی کسب و کار شما تحمل قطعی حتی یک درصد را ندارند Chaos Engineering گزینه مناسبی برای شما، نخواهد بود.
Owotogbe, J., Kumara, I., Van Den Heuvel, W., & Tamburri, D. A. (2024). Chaos Engineering: A Multi-Vocal Literature Review. arXiv preprint arXiv:2412.01416.
Chaos Mesh. (n.d.). Chaos Mesh documentation: A Chaos Engineering platform for Kubernetes. CNCF Incubating Project. Retrieved from https://chaos-mesh.org
ایستگاه دوم : Backend for Frontend

فرض کنید، کسب و کار شما یک اپلیکیشن موبایل و یک نسخه وب دارد که هر دو از یک سرور یکسان داده دریافت میکنند. صفحه اصلی در موبایل فقط به سه فیلد از پاسخ نیاز دارد، در حالی که وب به پانزده فیلد نیازمند است. اگر هر دو از یک API واحد استفاده کنند، یکی از این دو یا داده اضافه میگیرد یا مجبور است چندین درخواست جداگانه بفرستد.
الگوی Backend for Frontend دقیقاً همین مشکل را حل میکند. به جای یک API Gateway عمومی، برای هر کلاینت یک backend اختصاصی ساخته میشود.
این الگو را سام نیومن، معمار مشهور، در کتاب و مقالاتش به تفصیل توضیح داده است.
باید توجه داشت که یک BFF فقط حاوی منطق ارائه است و نباید منطق دامین را در خود جای دهد. تیمی که مسئول frontend است، مالکیت BFF متناظر را نیز بر عهده دارد و هر دو با هم و همزمان deploy میشوند. در معماریهای پلیگلات،چندزبانه اهمیت BFF این الگو بیشتر هم میشود، زیرا میتواند تفاوتهای فنی بین پلتفرمها را پنهان کند. مثلاً BFF میتواند داده مخصوص IOS را به فرمتی تبدیل کند که کتابخانههای خاص این پلتفرم بهتر متوجه شوند.
BFF و API Gateway گاهی با هم اشتباه میشوند. یک راه متداول این است که API Gateway را به عنوان دروازه ورودی درنظرگرفته که درخواست را به BFF مناسب مثلاً BFF موبایل یا BFF وب هدایت کند. یعنی API Gateway مسیریابی میکند، BFF منطق ارائه را اجرا میکند. باید در نظر داشت که این دو رقیب هم نیستند بلکه به یکدیگر کمک میکنند. البته اگر فقط یک کلاینت وجود داشته باشد، BFF اضافه است و نیازی به استفاده از آن نیست.
با این الگو تعداد سرویسها افزایش مییابد و هزینه نگهداری و پیچیدگی افزایش مییابد. همچنین افزودن لایه منجر به تاخیر میشود. عوارض احتمالی دیگر تکرار کد است .
Microsoft Architecture Center. (n.d.). Backend for Frontend (BFF) pattern. Retrieved from https://learn.microsoft.com/en-us/azure/architecture/patterns/backends-for-frontends
Motia Framework. (n.d.). Motia documentation: Step-based BFF implementation. Retrieved from https://motia.dev
Newman, S. (2019). Building Microservices (2nd ed.). O'Reilly Media.
ایستگاه سوم : AI for Software Engineering

احتمالاً این روزها شنیدهاید که توسعهدهندگان با کمک هوش مصنوعی کد مینویسند. اما نکته قابل توجه این است که برخی سازمانها بیش از ۴۵ درصد کدهای جدید خود را با کمک هوش مصنوعی تولید میکنند.
این آمار فقط نوک کوه یخ است. نسل جدید AI for Software Engineering فراتر از تکمیل خودکار یک خط کد رفته است و از عاملهای هوشمندی و مدلهای بزرگ زبانی استفاده میکند که میتوانند یک وظیفه end-to-end را انجام دهند.
به طور مثال یک عامل هوشمند میتواند درخواست توسعهدهنده را بفهمد، کد را بنویسد، آن را کامپایل کند، تستهای مرتبط را اجرا کند و در نهایت commit را بزند.
نکته قابل توجه اینجاست که این ابزارها با استفاده از حافظه سازمانی و قوانین خاص هر کسب و کار، دانش و استانداردهای داخلی را جذب میکنند و خروجیهایشان را با آنها هماهنگ میسازند. و نقطه تمایز AI for Software Engineering در درک هدف است و فقط الگوی بعدی نمیپردازد.
نکته کلیدی این است که این ابزارها قرار نیست جای توسعهدهنده را بگیرند. بلکه مانند یک دستیار هوشمند عمل میکنند که کارهای تکراری و زمانبر را حذف میکند. تصمیمگیری معماری، درک محدودیتهای کسبوکار، و مسئولیت اخلاقی محصول همچنان بر عهده انسان است.
اول از همه این روش وابستگی به مدل زبانی خاص خود را دارد یعنی اگر مدل تغییر کند یا هزینه دسترسی به آن افزایش یابد، کل فرآیند توسعه تحت تأثیر قرار میگیرد. دوم، خطر تولید کدهای دارای خطاهای امنیتی یا نقض حق نشر است. مدلهای زبانی از دادههای عمومی آموزش دیدهاند و ممکن است کدی تولید کنند که کپی غیرمجاز باشد. و سوم، هزینه محاسباتی بالا برای اجرای مدلهای بزرگ در داخل سازمان است و همچنین، تیمها باید زمان بگذارند تا خروجی هوش مصنوعی را بازبینی و تأیید کنند که خود نوعی هزینه پنهان است.
منابع
Awesome-AI4SE. (2021). GitHub repository. Retrieved from https://github.com/holunda-io/awesome-ai4se
AI-SE Research Group. (n.d.). Leipzig University. Retrieved from https://ai-se.github.io
Seerene. (n.d.). AI-powered software engineering analytics. Retrieved from
ایستگاه چهارم : Software Engineering for AI

حتماً این جمله را شنیدهاید که: داده، نفت جدید است. اما استخراج این نفت بدون مهندسی نرمافزار مناسب، غیرممکن است. سیستمهای مبتنی بر هوش مصنوعی با نرمافزارهای سنتی تفاوت بنیادی دارند. در نرمافزار معمولی، رفتار توسط کد تعیین میشود. اما در سیستمهای یادگیری ماشین، رفتار هم توسط کد و هم توسط داده شکل میگیرد.
داده میتواند در طول زمان تغییر کند و باعث پیری مدل (Model Degradation) یا تغییر مفهوم (Concept Drift) شود. یعنی مدلی که امروز با دقت ۹۵ درصد پاسخ میدهد، سه ماه بعد ممکن است دقتش به ۶۰ درصد برسد، بدون اینکه یک خط از کد آن تغییر کرده باشد.
در اینجا مفهوم Software Engineering for AI متولد شد. به زبان ساده، SE4AI یعنی استفاده از اصول مهندسی نرمافزار برای بهتر کردن سیستمهای مبتنی بر هوش مصنوعی است. هدف آن پل زدن بین دانشمندان داده و مهندسان نرمافزار است تا مدلهای یادگیری ماشین بتوانند در محیط تولید به صورت مقیاسپذیر و پایدار اجرا شوند. نمونه عملی این اصول شامل «تست واحد برای داده» (مثلاً بررسی ورودیها با معیارهای مشخص)، «مدیریت نسخه داده و مدل» با ابزارهایی مانند DVC، و «پایش مداوم عملکرد» (نظارت بر دقت و تأخیر) است. دوره معروف دانشگاه کارنگی ملون با عنوان «Software Engineering for AI-Enabled Systems» یکی از منابع اصلی یادگیری در این حوزه است.
باید توجه داشت که SE4AI با MLOps مرز مشترک دارد. اگر MLOps بگوید: چطور مدل را عملیاتی کنیم، SE4AI میگوید: چطور مدلی بسازیم که اصولاً قابلیت عملیاتی شدن داشته باشد. این دو مکمل یکدیگرند و گاهی با هم به کار میروند.
خیلی از پروژههای هوش مصنوعی در مرحله نمونه اولیه موفق هستند، اما وقتی نوبت به یکپارچهسازی با سیستمهایlegacy، تأمین امنیت، مدیریت نسخههای مختلف مدل، و پایش در تولید میرسد، شکست میخورند. دلیلش این است که دانشمندان داده معمولاً با اصول مهندسی نرمافزار مانند تستپذیری، قابلیت نگهداری، و مقیاسپذیری آشنا نیستند. مقاله کلاسیک گوگل با عنوان بدهی فنی پنهان در سیستمهای یادگیری ماشین (۲۰۱۵) نشان میدهد که کد مدل تنها بخش کوچکی از یک سیستم واقعی است و بیشتر پیچیدگی در زیرساخت داده، پایش، و وابستگیها پنهان است – دقیقاً جایی که SE4AI وارد میشود.
مدلها در محیط production به مرور زمان از کار میافتند بدون اینکه کسی متوجه شود. هزینه بالای بازآموزی و استقرار دستی مدلها به جای یک خط لوله خودکار است. و در آخر، افزایش بدهی فنی و دشواری نگهداری در بلندمدت میباشد.
Carnegie Mellon University. (n.d.). Software Engineering for AI-Enabled Systems. Retrieved from https://resources.sei.cmu.edu/library/asset-view.cfm?assetid=671076
Jönköping University. (n.d.). SE4AI Programme. Retrieved from https://ju.se/en/study-at-ju/our-programmes/masterprogramme/software-engineering-for-ai.html
Awesome-AI4SE. (2021). GitHub repository - SE4AI section. Retrieved from https://github.com/holunda-io/awesome-ai4se
ایستگاه پنجم : Machine Learning Operations
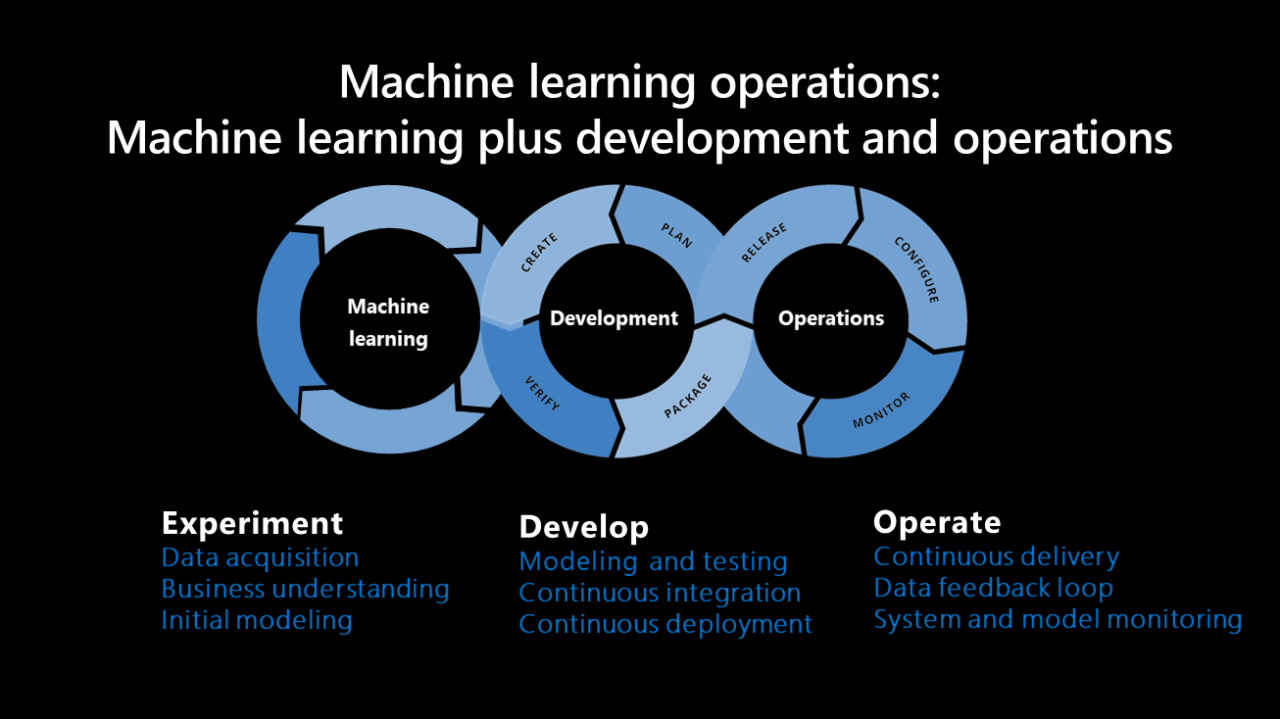
حتماً برایتان پیش آمده که یک مدل یادگیری ماشین را در Jupyter Notebook ساختهاید، همه چیز عالی کار میکند، اما وقتی میخواهید آن را در برنامه واقعی و برای کاربران حقیقی اجرا کنید، سروکله صدها مشکل پیدا میشود. مدل کند است، حجمش بالاست، ورودیهای دنیای واقعی با دادههای آموزشی فرق دارد، و هیچ کس نمیداند چطور باید نسخه بعدی مدل را جایگزین نسخه قبلی کند بدون اینکه سرویس از کار بیفتد.
Machine Learning Operations مجموعه شیوههایی است که این چرخه حیات را مدیریت میکند. اگر DevOps را برای نرمافزار سنتی در نظر بگیریم، Machine Learning Operations معادل آن برای دنیای ML است. اما یک تفاوت کلیدی وجود دارد: در MLOps، علاوه بر کد، داده و مدل هم باید نسخهگذاری شوند.
یک مقاله علمی در IEEE Xplore به چالش جالبی اشاره میکند. مدلهای ML اغلب توسط افراد مختلف با زبانها و فریم ورکهای مختلف ساخته میشوند. عملیاتیکردن این مدلهای ناهمگن کنار هم کار سادهای نیست. راهکار معرفیشده در آن مقاله، پلتفرم Acumos است که میتواند مدلهای سازگار را کشف کند، یک خط لوله از آنها بسازد، و کل را در یک کلیک روی AWS، GCP، Azure یا Kubernetes مستقر کند. خط لوله MLOps کامل شامل مراحلی مثل اسکن امنیتی image، تست دقت مدل، و پایش مدل در production است. Open Policy Agency (OPA) میتواند تصمیم بگیرد که مدل بر اساس امتیازات دقت، تأیید یا رد شود.
اول، استقرار دستی و پرخطای مدلها هر بار که دانشمند داده یک مدل جدید میسازد. دوم، عدم امکان بازگشت به نسخه قبلی مدل وقتی مدل جدید مشکل دارد. سوم، دیر متوجه شدن از کار افتادن مدل در تولید چون هیچ پایش خودکاری وجود ندارد. همچنین، تیم عملیات (Ops) و تیم داده مدام به خاطر مشکلات استقرار و اجرا با هم درگیر میشوند و بهرهوری کلی پایین میآید.
اگر مدلها را یک بار در سال آموزش میدهید و تا یک سال بعد تغییری در داده یا برچسبها ایجاد نمیشود، تنظیم یک خط لوله MLOps کامل شبیه خریدن یک تراکتور برای باغچه حیات خلوت است. همان یک اسکریپت پایتونی که هر شش ماه یک بار دستی اجرایش میکنی، کافی است.
Bhattacharjee, A., et al. (2021). MLOps: Creating powerful AI pipelines by stitching together heterogeneous Machine Learning models.
Harness Developer Hub. (n.d.). MLOps documentation. Retrieved
Acumos Project. (n.d.). Acumos AI platform documentation. Retrieved
ایستگاه ششم : Infrastructure as Code
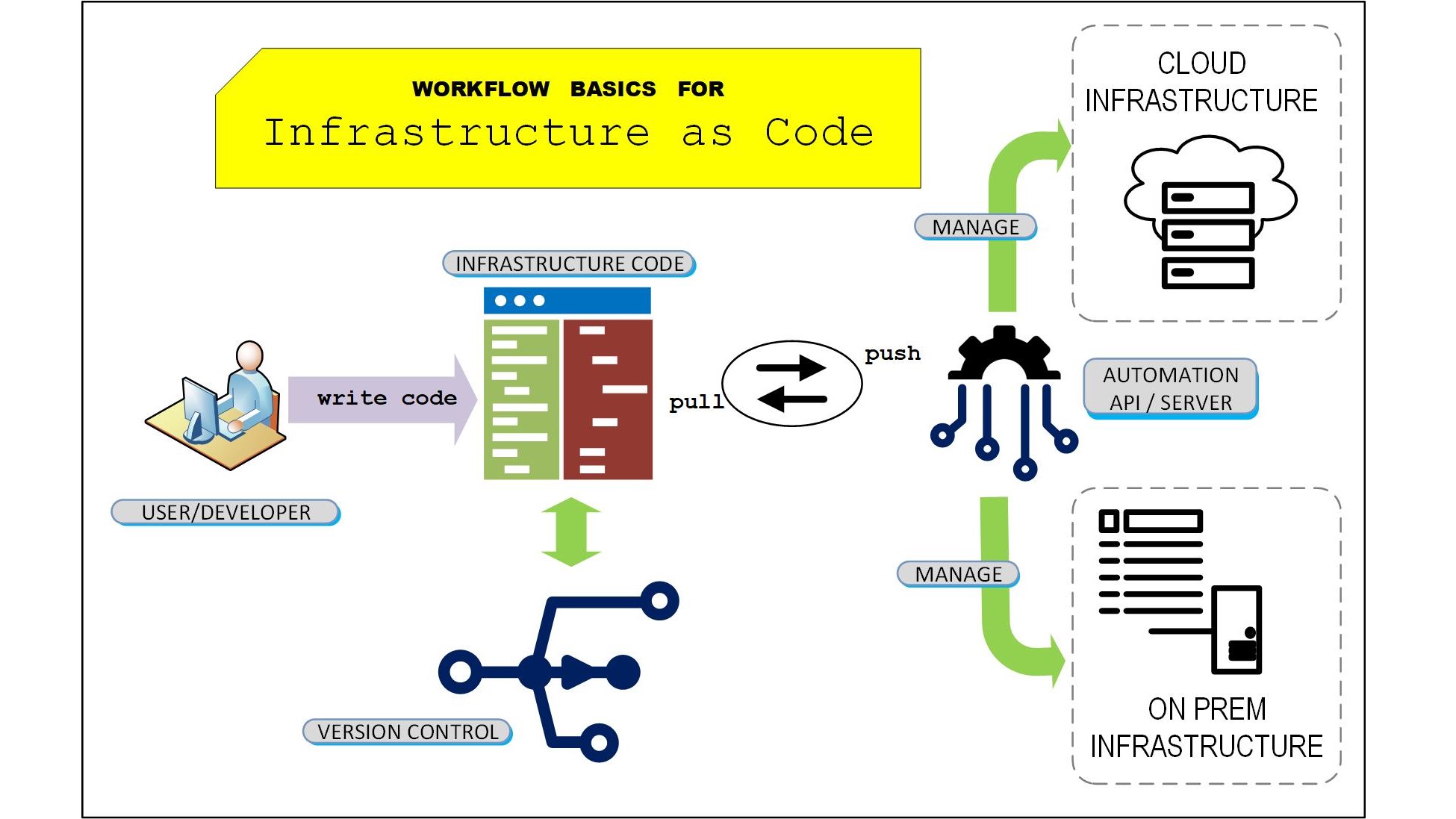
حتماً برایتان پیش آمده که برای راهاندازی یک سرور جدید، باید یک نفر ساعتها پای ترمینال بنشیند و دستورات را یکییکی تایپ کند. اگر آن شخص مرخصی برود یا مستنداتش را خوب ننوشته باشد، راهاندازی دوباره همان زیرساخت ممکن است روزها طول بکشد. این دقیقاً همان مشکلی است که Infrastructure as Code حل میکند.
طبق یک مقاله علمی در نشریه KHPI، فریمورکهای IaC به چهار دسته اصلی تقسیم میشوند: ابزارهای استقرار و مدیریت پیکربندی، ابزارهای تهیه زیرساخت، ابزارهای مجازیسازی و کانتینر، و چهارمی ابزارهای زمان اجرا است. اما مشکل اینجاست که در عمل، یک برنامه پیچیده اغلب نیاز به استفاده همزمان از چندین فریمورک دارد و دانش عمیق از همه آنها برای یک تیم سخت است.
باید توجه داشت که IaC به معنای نوشتن اسکریپتهای خطی نیست. بلکه توصیف اعلانی (declarative) از زیرساخت مورد نظر است. مثلاً در Terraform شما میگویید «من یک ماشین مجازی با ۴ گیگ رم و ۲ پردازنده میخواهم»، نه اینکه «اول این دستور را بزن، بعد آن دستور را بزن». ابزار خودش میفهمد چه چیزی کم و چه چیزی اضافه است.
برای یک سرور، بله اما برای ده سرور با محیطهای متفاوت (توسعه، تست، تولید)، جواب خیر است. اسکریپتهای bash خطی هستند و وضعیت فعلی زیرساخت را ردیابی نمیکنند. اگر یک دستور سه بار اجرا شود، ممکن است خراب شود. اما ابزارهای IaC مثل Terraform وضعیت زیرساخت را در یک فایل state ذخیره میکنند و فقط تغییرات لازم را اعمال میکنند.
اول، محیطهای توسعه، تست و تولید با هم فرق میکنند و باگها فقط در تولید ظاهر میشوند. دوم، راهاندازی مجدد زیرساخت پس از یک فاجعه (مثل آتشسوزی در دیتاسنتر) روزها یا هفتهها طول میکشد. سوم، هیچ مستند زندهای از زیرساخت وجود ندارد و دانش فقط در ذهن چند نفر خاص محبوس میشود. همچنین، هر تغییر زیرساخت نیاز به حضور آن افراد خاص دارد و تیم نمیتواند به صورت خودگردان عمل کند.
Wurster, M., Breitenbücher, U., Falkenthal, M., & Leymann, F. (2021). DOML: A new modeling approach for Infrastructure as Code. ScienceDirect.
HashiCorp. (n.d.). Terraform documentation.
Red Hat. (n.d.). Ansible documentation.
ایستگاه هفتم : API Gateway & Service Mesh

حتماً شنیدهاید که در معماری میکروسرویس، سرویسها باید با هم حرف بزنند. اما این «حرف زدن» دو نوع کاملاً متفاوت دارد. یکی ترافیک ورودی از بیرون به داخل مثل وقتی یک اپلیکیشن موبایل سرور را صدا میزند و دیگری ترافیک بین خود سرویسها در داخل دیتاسنتر مثل وقتی سرویس پرداخت با سرویس انبار حرف میزند. دو ابزار متفاوت برای این دو نوع ترافیک طراحی شدهاند:
API Gateway برای ترافیک شمال-جنوب (ورودی)
Service Mesh برای ترافیک شرق-غرب (داخلی)
API Gateway دروازه ورودی سیستم است. وقتی درخواستی از بیرون میآید، اول به آن میرسد. کارهایش شامل مسیریابی به سرویس مناسب، احراز هویت کاربر، محدود کردن نرخ درخواستها و جمع کردن پاسخ چند سرویس در یک پاسخ است. اما Service Mesh در لایه پایینتری کار میکند.
ایدیت لوین، بنیانگذار Solo.io، در مصاحبه با InfoQ گفت برخلاف Kubernetes که برنده قطعی orchestration شد، در حوزه service mesh احتمالاً هیچ برنده مشخصی وجود نخواهد داشت. پیادهسازیهایی مثل Istio، LinkerD، Consul Connect و AppMesh آمازون هرکدام نقاط قوت و ضعف خود را دارند. برای یکسان کردن زبان پیکربندی همه آنها، مشخصاتی به نام Service Mesh Interface تعریف شده است.
باید توجه داشت که API Gateway و Service Mesh رقیب هم نیستند. یک معماری بالغ میتواند هر دو را داشته باشد Gateway پشت لودبالانسر اصلی مینشیند و ترافیک ورودی را مدیریت میکند و Mesh در لایه پایینتر، بین سرویسها، امنیت و مشاهدهپذیری را تأمین میکند.
برای سیستمهای بزرگ با صدها سرویس که نیاز به رمزگذاری داخلی، قطعکننده مدار، و انتشار قناری دارند خیر، زیرا API Gateway
برای ترافیک ورودی بهینه شده و قرار دادن تمام منطق ارتباط بین سرویسها در آن، آن را به یک گلوگاه و نقطه شکست تبدیل میکند.
اول، امنیت ارتباط بین سرویسها به جای mTLS خودکار، به تنظیم دستی گواهیها وابسته است که به شدت خطاپذیر است. دوم، مشاهدهپذیری ترافیک داخلی محدود است و اشکالزدایی مشکلات بین سرویسها سخت میشود. سوم، پیادهسازی الگوهایی مانند قطعکننده مدار و انتشار قناری به صورت دستی در هر سرویس، کد تکراری و مستعد باگ ایجاد میکند. همچنین، تغییر در زیرساخت شبکه (مثل اضافه کردن رمزگذاری) نیاز به تغییر در تک تک سرویسها دارد.
Levine, I. (2020). Idit Levine on Gloo, Service Mesh Interface, and WebAssembly Hub. InfoQ Podcast.
Solo.io. (n.d.). Gloo Edge documentation.
Service Mesh Interface (SMI). (n.d.). SMI specification.
ایستگاه هشتم : Command Query Responsibility Segregation
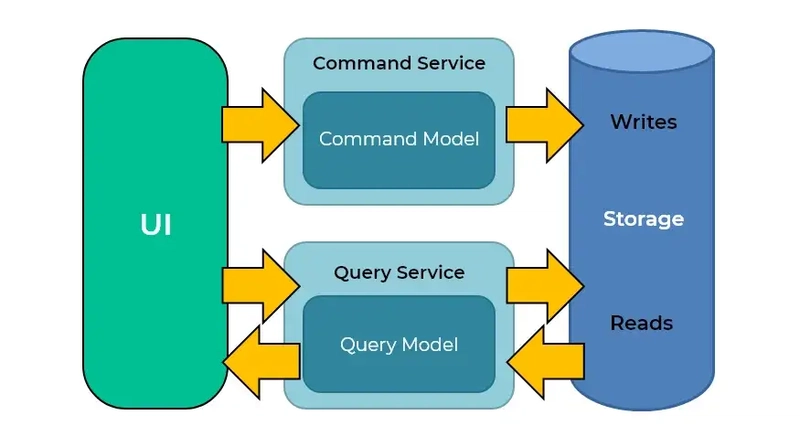
حتماً برایتان پیش آمده که در یک سیستم، تعداد درخواستهای خواندن چندین برابر درخواستهای نوشتن است. مثلاً در یک فروشگاه آنلاین، هزاران کاربر محصولات را میبینند، اما تعداد سفارشهای جدید شاید در همان لحظه فقط ده تا باشد. اگر از یک مدل داده واحد برای هر دو استفاده کنید، درخواستهای سنگین خواندن، سرعت نوشتن را پایین میآورند و برعکس این موضوع هم صادق است.
CQRS جدا کردن مدل نوشتن از مدل خواندن است. مدل Command مسئول تغییر وضعیت است مانند ایجاد سفارش جدید و از اصول Domain Driven Design پیروی میکند. مدل Query فقط برای نمایش داده بهینه شده و میتواند از یک دیتابیس کاملاً متفاوت مثل Elasticsearch استفاده کند.
پروژه Mixter که به چندین زبان پیاده شده، یک نمونه عملی از CQRS در کنار Event Sourcing است.
باید توجه داشت که این جداسازی هزینه دارد: همگامسازی بین دو مدل نیاز به رویدادها یا پیامهای غیرهمگام دارد.
اول، افزایش پیچیدگی کد و معماری. دوم، تأخیر در همگامسازی بین مدل خواندن و نوشتن سوم، نیاز به زیرساخت پیامرسان برای انتقال رویدادها بین دو مدل. همچنین، تیم باید با دو مدل داده جداگانه کار کند که درک و دیباگ کردن سیستم را سختتر میکند.
اگر شما یک سیستم سادهای مینویسید که نرخ خواندن و نوشتن به هم نزدیک است، و منطق دامین پیچیدگی خاصی ندارد، CQRS را فراموش کنید. هزینه جداسازی مدلها، همگامسازی بین آنها، و پیچیدگی ذهنی که به تیم تحمیل میکند، از هر سودی بیشتر است.
Mixter Project. (n.d.). CQRS and Event Sourcing in multiple languages. GitCode.
Fowler, M. (2011). CQRS. MartinFowler.com.
Microsoft Learn. (n.d.). CQRS pattern.
ایستگاه نهم : Event-Driven Architecture
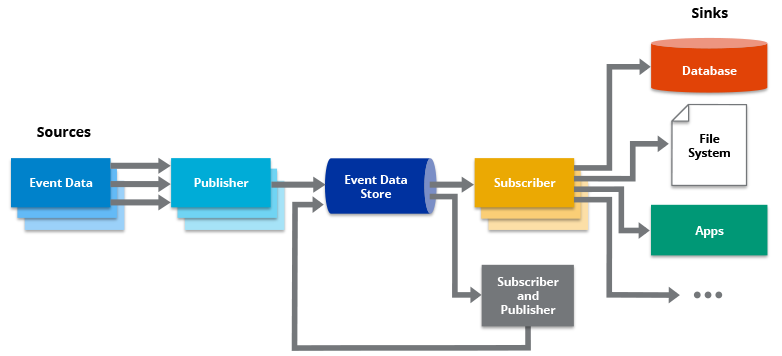
حتماً برایتان پیش آمده که در یک سیستم، سرویس A باید با سرویس B حرف بزند. در معماری سنتی، A مستقیم B را صدا میزند و منتظر میماند. اگر B پایین باشد، A هم مختل میشود. اگر B کند باشد، A هم کند میشود. این همان معماری درخواست-پاسخ همگام است.
معماری رویدادمحور این گره را باز میکند. درEDA، سرویس A به جای صدا زدن مستقیمB، یک رویداد منتشر میکند (مثلاً «سفارش جدید ثبت شد») و کارش تمام است. هر سرویسی که به این رویداد علاقه داشته باشد (پرداخت، انبار، ایمیل) آن را دریافت و پردازش میکند. تولیدکننده از مصرفکنندگان خبر ندارد و مصرفکنندهها هم از یکدیگر بیخبرند.
سه فناوری رایج در این حوزه نقشهای متفاوتی دارند. Kafka برای رویدادهای بلندمدت مناسب است (مثل تاریخچه ثبتنام کاربران) و پیام را برای همیشه نگه میدارد. RabbitMQ برای فرمانها و تسکها بهینه است (مثل ارسال ایمیل) و پیام را پس از تحویل حذف میکند. gRPC برای تماسهای همگام با تأخیر پایین (مثل اعتبارسنجی سریع) استفاده میشود. در یک سیستم واقعی، هر سه میتوانند کنار هم کار کنند.
باید توجه داشت که EDA شلشدگی و مقیاسپذیری میآورد، اما هزینهاش پیچیدگی دیباگ کردن است. وقتی یک رویداد چندین سرویس را زنجیرهوار تحریک میکند، فهمیدن اینکه «چرا این اتفاق نیفتاد» ساعتها وقت میبرد.
منابع
Java Code Geeks. (2021). Polyglot Event-Driven Systems with Kafka, RabbitMQ and gRPC. Retrieved from https://www.javacodegeeks.com/2021/03/polyglot-event-driven-systems-with-kafka-rabbitmq-and-grpc.html
Motia Framework. (n.d.). Event-driven step-based architecture. Retrieved from https://motia.dev
TNGlobal. (2024). Why Event-Driven Architecture is crucial for Agentic AI. Retrieved from https://tnGlobal.com
ایستگاه دهم : Serverless Architecture
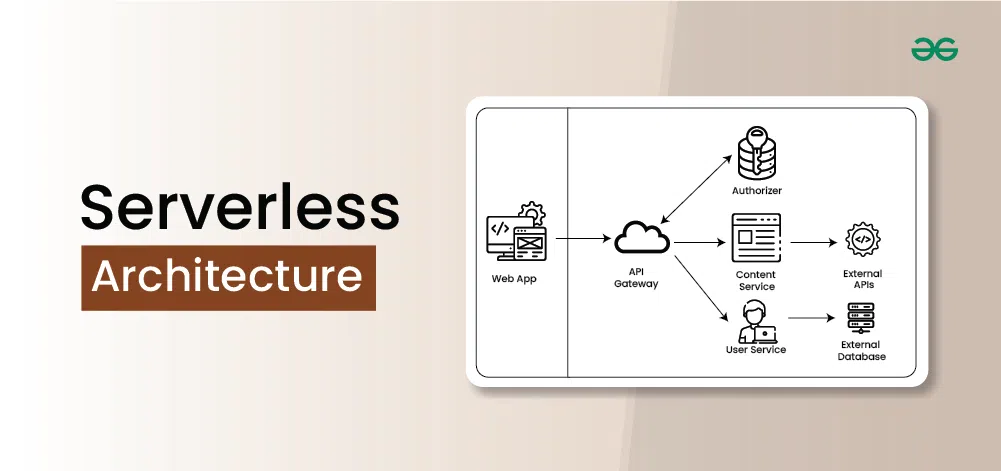
حتماً برایتان پیش آمده که برای اجرای یک تابع ساده، مجبورید یک سرور کامل راهاندازی کنید، سیستم عامل نصب کنید، و نگران مقیاسپذیری و در دسترس بودن آن باشید. Serverless فراموش کردن همه این دغدغهها است. شما فقط کدتان را میدهید، بقیه با ارائهدهنده ابراست.
Serverless بر دو پایه اصلی استوار است :
Function as a Service مثل AWS Lambda که واحد اجرا یک تابع است.
Backend as a Service مثل دیتابیسهای مدیریتشده است.
باید توجه داشت که Serverless به معنای نبودن سرور نیست. سرور همیشه هست، اما مدیریت آن به طور کامل بر عهده ارائهدهنده ابر است. همچنین هر تابع به طور مستقل مقیاس میشود. اگر تابع پردازش تصویر صد برابر شود، تابع احراز هویت تحت تأثیر قرار نمیگیرد.
یک راهنمای عملی از Pulumi نشان میدهد که یکی از جذابیتهای سرورلس، توانایی ترکیب زبانهای مختلف در یک پروژه است. مثلاً میتوانی یک تابع به زبان پایتون برای پردازش داده سنگین بنویسی، یک تابع به زبان Go برای API با کارایی بالا، و یک تابع TypeScript برای هندل کردن webhookها اما هر تابع به طور مستقل scale میشود. اگر ترافیک تابع پایتون صد برابر شود، روی تابع Go هیچ تأثیری نمیگذارد. هزینه هم فقط به ازای زمان اجرا و تعداد فراخوانی محاسبه میشود. برای توابعی که گاهی هفتهها فراخوانی نمیشوند، این مدل قیمتگذاری فوقالعاده به صرفه است. نکته دیگر اینکه آدرس HTTPS هر تابع در طول بهروزرسانیها ثابت میماند و نیازی به تغییر در سمت کلاینت نیست.
اگر برنامه شما همیشه روشن است و ترافیک ثابتی دارد، هزینه Serverless ممکن است از یک سرور سنتی بیشتر شود. همچنین cold start (تأخیر راهاندازی تابع پس از چند دقیقه بیکاری) میتواند برای برنامههای حساس به تأخیر کشنده باشد.
cold start تأخیر قابل توجهی به پاسخ اضافه میکند. وابستگی شدید به ارائهدهنده ابر و قفل شدن در آن. رخ میدهد. دیباگ کردن توابع توزیعشده سختتر از یک برنامه monolithic است. همچنین، محدودیتهایی در زمان اجرا (معمولاً ۱۵ دقیقه) و حافظه وجود دارد که همه workloadها را پشتیبانی نمیکند.
Pulumi. (n.d.). Deploy multi-language serverless functions on Google Cloud. Retrieved from https://www.pulumi.com/docs/guides/crosswalk/gcp/serverless/
Amazon Web Services. (n.d.). AWS Lambda documentation. Retrieved from https://docs.aws.amazon.com/lambda/
Serverless Architecture. Retrieved from https://developer.baidu.com
ایستگاه یازدهم : API-first Approach
حتماً برایتان پیش آمده که تیم فرانتاند و بکاند همزمان کار میکنند، اما وقتی زمان یکپارچهسازی میرسد، میبینند APIهایی که هرکدام ساختهاند با هم جور درنمیآید. API-first یعنی قبل از نوشتن هر کدی، اول مشخصات API را با استانداردی مثل OpenAPI (Swagger) طراحی و مستند کنید. همه تیمها روی آن توافق میکنند و بعد کدشان را مینویسند.
تیم Algolia که خدمات جستجو ارائه میدهد، با این روش توانسته، ده API و یازده زبان برنامهنویسی را با سه مهندس نگهداری کند. به این صورت: از روی مشخصات OpenAPI، هشتاد درصد کد SDKها به صورت خودکار تولید میشود. خط لوله تولید تا انتشار در npm، PyPI و Maven حدود ۲۰ دقیقه طول میکشد.
از نظر منAPI-first بیش از یک رویکرد فنی، یک قرارداد اجتماعی بین تیمهاست. میگوید: ما اول توافق میکنیم چطور حرف بزنیم، بعد هر کد میرویم کدمان را مینویسیم. بدون این توافق، دو تیم موازی ممکن است هفتهها کار کنند و آخر سر ببینند APIهایشان با هم جور درنمیآید.
برای یک تیم کوچک و یک پروژه ساده، بله اما برای چندین تیم که روی سرویسهای مختلف کار میکنند، دیر یا زود به تضاد و دوبارهکاری میرسید.
اول، دوبارهکاری و اتلاف وقت در یکپارچهسازی. دوم، مستندات قدیمی و بیاعتبار که با کد همخوانی ندارد. سوم، وابستگی تیمها به هم که پیشرفت را کند میکند. همچنین، تولید SDK برای زبانهای مختلف به صورت دستی غیرممکن میشود.
Algolia Engineering. (2021). How we generate 100+ SDKs.
OpenAPI Initiative. (n.d.). OpenAPI Specification (Swagger).
Anthropic. (2024). Model Context Protocol (MCP).
ایستگاه دوازدهم : Domain Driven Design

حتماً برایتان پیش آمده که یک تیم توسعه و متخصصان کسبوکار از یک واژه معنای متفاوتی میفهمند. مثلاً «مشتری» برای تیم فنی یک رکورد در دیتابیس است، اما برای تیم فروش معنای پیچیدهتری دارد. این اختلاف زبان، ریشه بسیاری از پروژههای شکستخورده است.
اریک ایوانز در کتاب معروفش (Blue Book) راهحلی به نام Domain Driven Design ارائه کرد. ایده مرکزی به این صورت است که: تیم توسعه باید با متخصصان دامین بنشیند و یک مدل مشترک از کسبوکار بسازد. این مدل به یک زبان یکپارچه تبدیل میشود که هم در جلسات و هم در کد استفاده میشود.
باید توجه داشت که DDD برای سیستمهایی با منطق کسبوکار پیچیده مثل بیمه و مالی طراحی شده، نه برای فرمهای ساده ثبتنام.
برای سیستمهای ساده مثل یک وبلاگ یا فروشگاه کوچک، DDD وزن اضافه است. پیادهسازی Aggregate و Repository و Value Object بدون داشتن منطق پیچیده، فقط کدزنی بینتیجه است و باعث پیچیدگی بیشتر کد و نیاز به حضور دائمی متخصص دامین در کنار تیم توسعه دارد.
Evans, E. (2003). Domain-Driven Design: Tackling Complexity in the Heart of Software. Addison-Wesley.
Vernon, V. (2013). Implementing Domain-Driven Design. Addison-Wesley.
Fowler, M. (n.d.). Domain Driven Design. MartinFowler.com.
ایستگاه سیزدهم : Hexagonal Architecture

حتماً برایتان پیش آمده که یک تغییر ساده در پایگاه داده یا سرویس خارجی، کل برنامه را تحت تأثیر قرار میدهد. مثلاً وقتی میخواهید از MySQL به PostgreSQL مهاجرت کنید، باید لایه business را هم تغییر دهید. مشکل از جایی است که لایهها به ترتیب به هم وابستهاند. این وابستگی باعث میشود تست کردن لایه business بدون پایگاه داده واقعی سخت شود و تغییر یک فناوری مثل عوض کردن دیتابیس از SQL به NoSQL کل برنامه را تحت تأثیر قرار دهد.
معماری هگزاگونال که Ports & Adapters هم نامیده میشود این وابستگی را برعکس میکند. لایه دامین یا منطق کسبوکار در مرکز قرار میگیرد و هیچ دانشی از دنیای خارج ندارد. ارتباط با خارج، تنها از طریق پورت interface تعریف میشود. «اداپتورها» کار تبدیل را انجام میدهند. مثلاً اداپتور REST درخواست HTTP را به فراخوانی متد مناسب تبدیل میکند. اداپتور دیتابیس پیادهسازی خاص ذخیرهسازی را فراهم میکند.
نکته جالب این است که: برای تست کردن دامین، فقط کافی است یک اداپتور تست بنویسید که به جای دیتابیس واقعی، داده را در حافظه ذخیره کند. برای تغییر دیتابیس هم فقط یک اداپتور جدید مینویسید؛ لایه دامین اصلاً عوض نمیشود.
باید توجه داشت که اسم «هگزاگونال» قراردادی است و ربطی به شش ضلع ندارد. میتواند سه پورت یا نه پورت داشته باشد. اصل این است که وابستگیها به سمت داخل اشاره میکنند.
اگر پروژهتان ساده است و احتمال تغییر زیرساخت در آینده نزدیک وجود ندارد، لایهبندی اضافه فقط زمان توسعه را میبرد. این معماری برای سیستمهایی با طول عمر بالا و نیاز به تستپذیری زیاد ارزش دارد. در غیر این صورت، تعداد کلاسها و فایلها افزایش مییابد،درک جریان داده برای تازهواردها سختتر است و برای پروژههای خیلی کوچک، زمان توسعه را افزایش میدهد. همچنین، ممکن است تیم حس کند برای کاری ساده، پیچیدگی زیادی ساخته است.
Cockburn, A. (2005). Hexagonal Architecture. AlistairCockburn.us.
Hombergs, T. (2018). Get Your Hands Dirty on Clean Architecture. Leanpub.
Graca, H. (n.d.). Hexagonal Architecture. HerbertoGraca.com.
ایستگاه چهاردهم : Event Sourcing
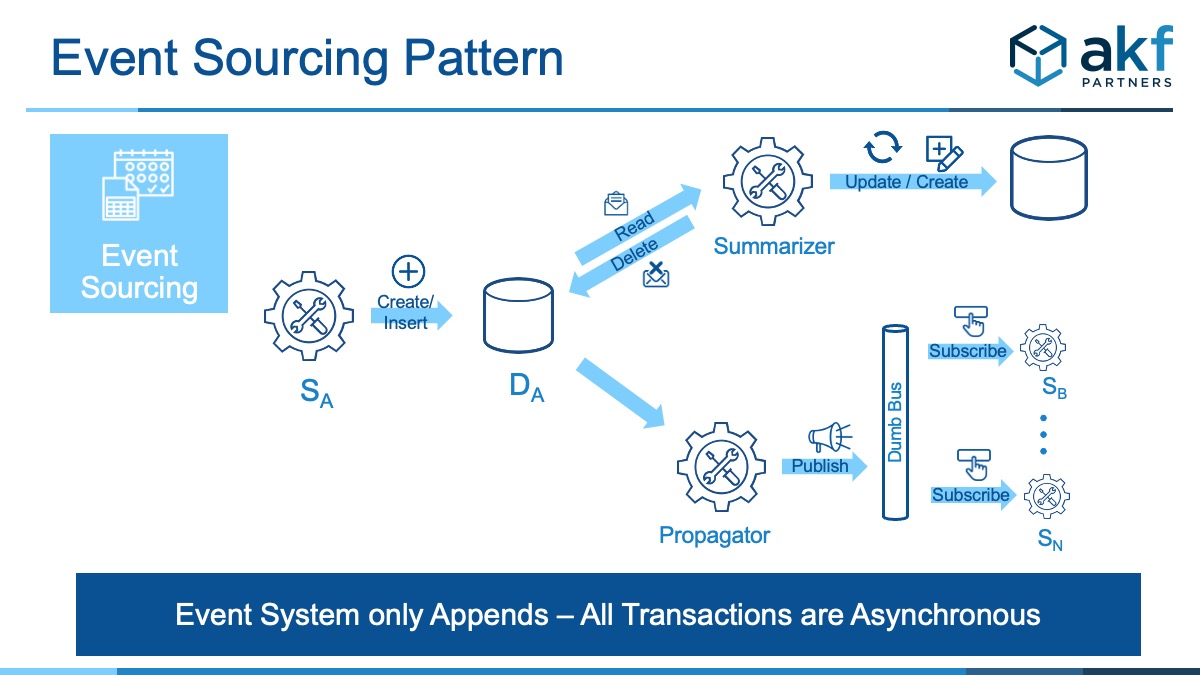
به جای ذخیره وضعیت فعلی یک شیء، تمام اتفاقاتی که برای آن شیء افتاده را ذخیره کن!
فرض کنید بخواهید بدانید که یک سفارش در طول زمان چه تغییراتی کرده است. در دیتابیس معمولی، فقط وضعیت فعلی را دارید برای حل این مشکل چه راهکاری دارید؟
Event Sourcing این مشکل را حل میکند. به جای ذخیره وضعیت فعلی، تمام اتفاقاتی که برای یک شیء افتاده را ذخیره میکند. به طور مثال برای یک حساب بانکی تمامی تغییرات و تاریخچه شی ذخیره میشود: «حساب با ۱۰۰۰ تومان افتتاح شد»، «۵۰۰ تومان برداشت شد»، «۲۰۰ تومان واریز شد».
وضعیت فعلی شی از بازپخش این رویدادها به دست میآید.
با این راهکار تاریخچه کامل و قابلیت ممیزی در دسترس شماست. میتوانید سیستم را در هر لحظه از گذشته بازسازی کنید.
برای جلوگیری از بازپخش طولانی، از «اسنپشات» (ذخیره وضعیت هر چند وقت یکبار) استفاده میشود.
باید توجه داشت که Event Sourcing اغلب با CQRS ترکیب میشود. رویدادها از Aggregate خارج و منتشر میشوند و مدل Query جداگانه از آنها Viewهای خود را میسازد.
Event Sourcing یک فناوری نیست، یک تعهد است. وقتی رویدادها را ذخیره کردید، دیگر نمیتوانید به راحتی ساختارشان را عوض کنید. هر تغییر در schema رویدادها باید backward compatible باشد یا migration بنویسید. اگر نیازی به تاریخچه و ممیزی ندارید، Event Sourcing فقط پیچیدگی اضافه میکند. وقتی رویدادها را ذخیره کردید، تغییر ساختارشان بسیار سخت است و نیاز به migration دارد.
Fowler, M. (2005). Event Sourcing. MartinFowler.com.
Young, G. (n.d.). Event Sourcing. CodeBetter.
Mixter Project. (n.d.). CQRS and Event Sourcing implementation. GitCode.
ایستگاه پانزدهم : Low-code/No-code platforms

حتماً برایتان پیش آمده که یک ایده ساده برای یک ابزار داخلی شرکت داشتهاید، اما پیادهسازی آن با کدنویسی سنتی چند هفته زمان میبرد. سکوهای Low-code و No-code این مشکل را حل میکنند. با کشیدن و رها کردن کامپوننتها و تعریف جریان کاری میتوانید در عرض چند روز یک اپلیکیشن کاربردی بسازید.
سکوی Low-code و No-code به کاربران اجازه میدهند برنامه بسازند بدون اینکه خطی کد بنویسند یا با کمترین کدنویسی ممکن برانامه خود را بسازند.
برای روشن شدن موضوع، به مثال DOML نگاه کنیم. در مقاله علمیDOML، محققان یک زبان مدلسازی به نام DOML طراحی کردهاند که یک لایه Low-code روی Infrastructure as Code است. یعنی کاربر که ممکن است متخصص زیرساخت نباشد میتواند با یک زبان ساده توصیف کند که اپلیکیشنش چه زیرساختی نیاز دارد. این یعنی کاربر بدون دانستن جزئیات Terraform یا Ansible، میتواند زیرساختش را روی چندین پلتفرم مختلف Provision کند.
تفاوت Low-code و No-code در مخاطب است. No-code برای "شهروندان توسعهدهنده" (افراد غیرفنی مثل تحلیلگران کسبوکار) طراحی شده و هیچ راهی برای خروج از جعبه ندارد. Low-code برای توسعهدهندگان حرفهای طراحی شده و امکان نوشتن کد سفارشی برای سناریوهای پیچیده را میدهد. نقطه ضعف اصلی هر دوی این سکوها وابستگی به فروشنده (Vendor Lock-in) است. وقتی برنامهات روی یک پلتفرم Low-code خاص ساخته شد، بیرون آوردن آن به سختی ممکن است. سرویسهایی مثل OutSystems، Mendix و Power Apps در این حوزه فعال هستند.
این سکوها برای MVP و ابزارهای داخلی عالی هستند.
تجربه نشان داده است که دیر یا زود به مرز سکو برخورد میکنید یعنی چیزی که سکو نمیتواند انجام دهد شما را گرفتار میکند.
Wurster, M., et al. (2021). DOML: A new modeling approach for Infrastructure as Code. ScienceDirect.
OutSystems. (n.d.). Low-code platform documentation.
Mendix. (n.d.). Low-code platform.
ایستگاه شانزدهم : Business Process Management Systems
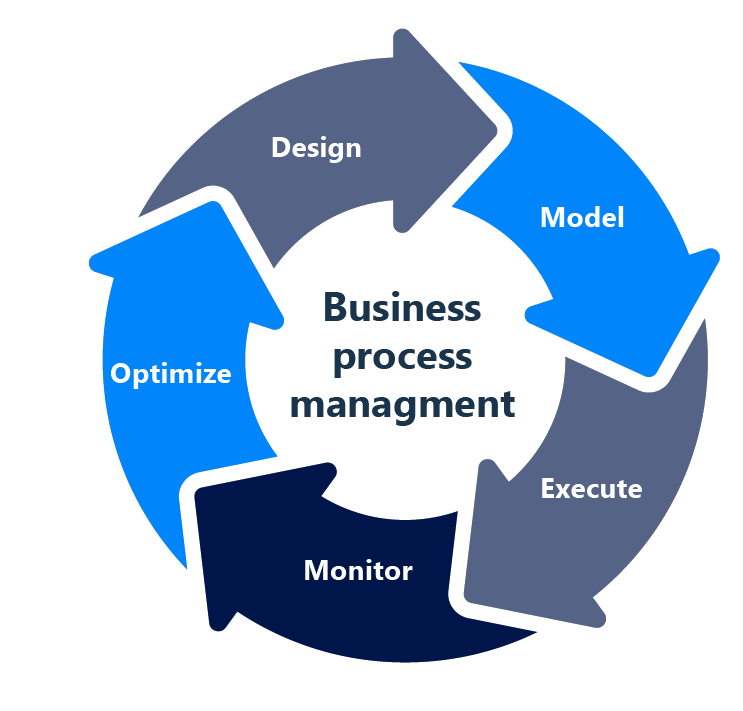
حتماً برایتان پیش آمده که یک فرآیند کسبوکار مثل «ثبت سفارش تا تحویل» را بررسی کردهاید. این فرآیند ممکن است دهها مرحله داشته باشد از تأیید اعتبار مشتری، چک کردن موجودی، تخصیص به انباردار، بستهبندی، ارسال تا پیامک به مشتری است. اگر بخواهید این را با کدنویسی سنتی پیاده کنید، خیلی زود درگیر پیچیدگی حالتهای مختلف میشوید: اگر موجودی نبود چه؟ اگر مشتری پولش را پس گرفت چه؟
BPMS با زبان استاندارد BPMN 2.0 این پیچیدگی را مدیریت میکند. فرآیند به صورت گرافیکی مدل میشود. تسکها دو نوع هستند: تسک انسانی مثلاً «مدیر تأیید کند» و تسک خودکار مثلاً «وضعیت سفارش را بهروز کن») موتور BPMS مثل Camunda، jBPM، مدل را اجرا و وضعیت هر نمونه را پیگیری میکند. وقتی یک تسک انسانی به پایان رسید، موتور به صورت خودکار مرحله بعد را شروع میکند. از دید معماری سازمانی، BPMS یک نقطه مرکزی برای دیدهشدن و بهینهسازی فرآیندهای بینسیستمی است. داشبوردهای BPMS نشان میدهند کدام مرحله گلوگاه شده، کدام کارمند بیشترین تسک را انجام داده، و چقدر از SLAها عقب هستیم. BPMSهای مدرن با معماری رویدادمحور و سرورلس ترکیب میشوند تا فرآیندهای مقیاسپذیر بسازند.
باید توجه داشت که BPMS زمانی میدرخشد که فرآیندها مدام تغییر میکنند. اگر هر ماه یک مرحله جدید به گردش کار اضافه میشود، با BPMS فقط مدل را عوض میکنید، بدون اینکه نیاز به deploy دوباره کل نرمافزار باشد.
اول، هزینه بالای پیادهسازی اولیه و خرید لایسنس (مخصوصاً نسخههای سازمانی). دوم، نیاز به تخصص در BPMN و موتورهای مربوطه. سوم، برای فرآیندهای بسیار ساده، BPMS وزن اضافه است. همچنین، ممکن است موتور BPMS برای سناریوهای با توان عملیاتی بسیار بالا (مثل میلیونها درخواست در ثانیه) گلوگاه شود.
Camunda. (n.d.). BPMN 2.0 Engine documentation.
jBPM. (n.d.). jBPM documentation. Red Hat.
OMG. (2011). Business Process Model and Notation (BPMN) Version 2.0.
ایستگاه هفدهم : Message Queue (Kafka, RabbitMQ)

Message Queue یک صف ارتباطی بین سرویسهاست. سرویس A پیام را در صف میگذارد و بدون اینکه منتظر بماند به کار خود ادامه میدهد. سرویس B یا چند سرویس وقتی وقت داشت میآید پیام را از صف برمیدارد و پردازش میکند. در معماریهای مبتنی بر میکروسرویس، Message Queue یک مؤلفه کلیدی است. اما همه Message Queueها یکسان نیستند. دو نمونه بسیار محبوب، RabbitMQ و Apache Kafka، تفاوتهای بنیادی دارند.
یک مقاله عملی از Java Code Geeks این تفاوت را شفاف توضیح داده است RabbitMQ یک صف سنتی است. پیام را از صف حذف میکند بعد از اینکه مصرفکننده آن را دریافت کرد. برای سناریوهایی که "پیام دقیقاً یک بار پردازش شود" مهم است، مثل دستورات (commands) و تسکها، مناسب است. در مقابل، Kafka یک commit log است. پیامها را برای همیشه یا برای مدت مشخصی نگه میدارد و مصرفکننده تعیین میکند از کجا شروع به خواندن کند. یعنی میتوانی یک پیام را چند بار بخوانی. برای رویدادهایی که "چه شد" مهم است و تاریخچه کامل آن ارزش دارد، مناسب است. در یک سیستم polyglot، اغلب هر دو را کنار هم میبینند: Kafka برای رویدادهایی مثل تاریخچه کاربران، چون میخواهی تاریخچه ثبت نام همه کاربران را داشته باشی وRabbitMQ برای فرمانهایی مثل ارسال ایمیل چون میخواهی ایمیل دقیقاً یک بار فرستاده شود.
باید توجه داشت که انتخاب اشتباه بین این دو هزینه بالایی دارد. کافکا مثل کامیون است؛ اگر فقط میخواهید یک پاکت نامه بفرستید، راهاندازی کامیون بیهوده است RabbitMQ برای بسیاری از موارد نه فقط کافی، بلکه بهینهتر است.
برای سیستمهای خیلی ساده با تعداد سرویس کم، بله اما به محض اینکه بیش از ۳ سرویس داشته باشید که باید غیرهمگام با هم ارتباط برقرار کنند، Message Queue تبدیل به یک ضرورت میشود.
Java Code Geeks. (2021). Polyglot Event-Driven Systems with Kafka, RabbitMQ and gRPC.
Apache Kafka. (n.d.). Documentation.
RabbitMQ. (n.d.). Documentation.
ایستگاه هجدهم : Containers (Docker) , Container Orchestration (Kubernetes)

حتماً برایتان پیش آمده که یک برنامه روی دستگاه شما کار میکند، اما روی دستگاه همکارتان از کار میافتد. مشکل وابستگیهاست. کتابخانهای که شما دارید، او ندارد یا نسخهاش فرق میکند. کانتینرها این مشکل را حل میکنند. برنامه و همه وابستگیهایش در یک بسته قابل حمل به اسم Image جمع میشود. هر جا که Docker نصب باشد، Image دقیقاً یکسان اجرا میشود.
تفاوت کانتینر با ماشین مجازی در این است که کانتینرها هسته سیستمعامل میزبان را به اشتراک میگذارند. نتیجه: کانتینرها در کسری از ثانیه بالا میآیند (در مقابل VM چند دقیقه زمان میبرد.
حالا فرض کنید صدها کانتینر دارید. چه کسی تصمیم میگیرد هر کدام روی کدام سرور برود؟ اگر کانتینری خراب شد، چه کسی دوباره راهاندازیاش کند؟ اگر ترافیک بالا رفت، چه کسی تعداد کانتینرها را زیاد کند؟ اینجاست که Kubernetes وارد میشود Kubernetes یک ارکستراتور کانتینر است که تمام این کارها را خودکار میکند: زمانبندی، خودترمیمی، مقیاس خودکار، rolling update بدون قطعی، و سرویسدیسکاوری.
باید توجه داشت که Kubernetes یک راهحل جادویی نیست. اگر فقط یک اپلیکیشن ساده روی یک سرور دارید، Kubernetes یعنی پیچیدگی بیش از حد و همین یک سرور با systemd و یک binary کافی است.
برای تیمهای کوچک با کمتر از ۵ سرویس، کانتینر ممکن است مفید باشد اما Kubernetes تقریباً همیشه زیاد است. Kubernetes زمانی معنا پیدا میکند که تیم شما بیش از ۵ نفر است، بیش از ۱۰ سرویس دارید، و نیاز به استقرار مکرر و مقیاس خودکار دارید.
Docker. (n.d.). Docker documentation.
Kubernetes. (n.d.). Kubernetes documentation.
Wurster, M., et al. (2021). DOML: A new modeling approach for Infrastructure as Code. ScienceDirect.
ایستگاه نوزدهم : Multi-Tenancy Architecture
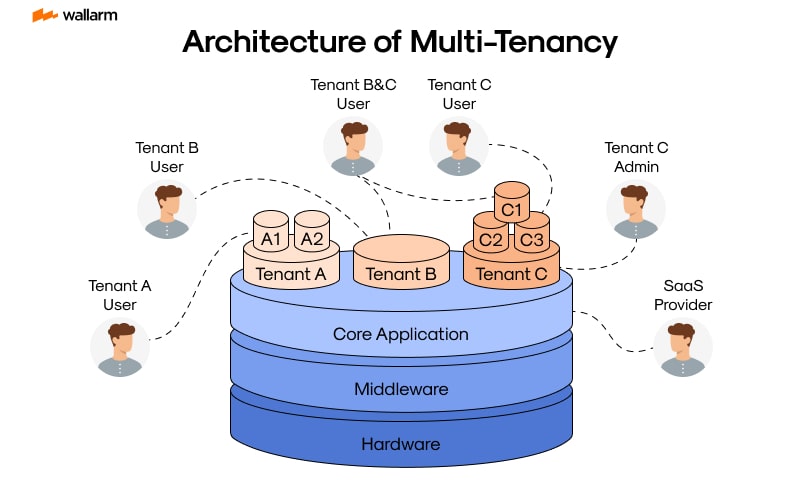
حتماً از جیمیل استفاده کردهاید. میلیاردها کاربر از یک برنامه واحد استفاده میکنند، اما هرکس فقط ایمیلهای خودش را میبیند. این همان معماری (Multi-Tenancy) است: یک نمونه از نرمافزار به چندین مشتری سرویس میدهد و دادهها کاملاً از هم جدا میمانند.
سه سطح اصلی برای پیادهسازی وجود دارد:
دیتابیس جداگانه برای هر مشتری: بالاترین ایزولهسازی، اما تعداد دیتابیسها زیاد میشودو هزینه بالا میرود.
اسکیماهای جداگانه در یک دیتابیس مشترک:در این سرای ایزولهسازی خوب و هزینه متوسط است اما مدیریت backup پیچیدهتر است.
یک اسکیما با فیلدtenant_id: بالاترین بهرهوری از منابع اما سختترین پیادهسازی را دارد هر کوئری باید شامل tenant_id باشد تا کسی به داده دیگری دسترسی پیدا نکند.
باید توجه داشت که انتخاب سطح multi-tenancy یکی از اولین و مهمترین تصمیمها در طراحی یک SaaS است. این تصمیم غیرقابل برگشت است؛ مهاجرت از دیتابیس جدا به اسکیماهای مشترک بسیار سخت و پرریسک است.
فقط برای یک مستأجر، برای چند مستأجر،دیر یا زود دادهها قاطی میشوند و جداسازی آنها غیرممکن میگردد.
اول، اگر ایزولهسازی را خیلی بالا بگیرید، هزینه زیرساخت و نگهداری افزایش مییابد. دوم، اگر خیلی پایین بگیرید خطر نشت داده بین مستأجرها به دلیل خطای برنامهنویسی وجود دارد. سوم، مهاجرت بین سطوح بسیار دشوار و زمانبر است. همچنین، پشتیبانگیری و بازیابی داده در سطوح مختلف پیچیدگی متفاوتی دارد.
Microsoft Learn. (n.d.). Multi-tenant architecture patterns.
AWS SaaS Factory. (n.d.). Multi-tenant patterns.
Fowler, M. (n.d.). Multi-Tenancy. MartinFowler.com.
ایستگاه بیستم : Data Migration
حتماً برایتان پیش آمده که بخواهید دیتابیس خود را از Oracle به PostgreSQL منتقل کنید، یا معماری برنامه را از monolithic به microservices تغییر دهید. در هر دو حالت، باید دادهها را از یک سیستم به سیستم دیگر منتقل کنید. این همان Data Migration است.
فرآیند مهاجرت داده پنج مرحله اصلی دارد:
کشف و پروفایل: ببینید چه دادهای دارید و کیفیت آن چطور است؟
طراحی هدف: مدل داده جدید را مشخص کنید.
توسعه: کدهای ETL بنویسید Extract, Transform, Load
تست: بررسی کنید همه داده درست منتقل شده باشد.
اجرا: مرحله نهایی برش اجرا است.
چالشهای اصلی شامل دادههای ناسازگار مثل فرمتهای مختلف آدرس، زمان از کار افتادگی در حینcutover، و حفظ یکپارچگی ارجاعی بین جداول است.
ابزارهایی مثل Liquibase و Flyway برای مهاجرت ساختار دیتابیس در طول زمان محبوب هستند همچنین AWS DMSو Azure Database Migration Service برای مهاجرتهای ابری مناسب است. جالب اینجاست که Event Sourcing میتواند مهاجرت را ساده کند به صورتی که اگر داده به صورت رویداد ذخیره شده باشد، کافی است رویدادها را در دیتابیس جدید بازپخش کنید تا وضعیت نهایی ساخته شود.
باید توجه داشت که آزمایش در محیط production در مهاجرت داده، یک فاجعه است. تیمهای حرفهای معمولاً مهاجرت را سه بار تمرین میکنند (dry-run) قبل از اینکه بار چهارم اجرای واقعی را انجام دهند.
در الگوی dual-write، همزمان در دیتابیس قدیم و جدید نوشته میشود. ابتدا دادههای تاریخی منتقل میشود، سپس برنامه به صورت همزمان در هر دو مینویسد، و بعد از اطمینان از هماهنگی، خواندن هم به دیتابیس جدید منتقل میشود. این روش downtime را به حداقل میرساند اما پیچیدگی بیشتری دارد.
اول، خطر از دست رفتن داده یا خراب شدن یکپارچگی ارجاعی دارد. دوما، زمان از کار افتادگی (downtime) در روشهای ساده است.
Microsoft Learn. (n.d.). Data migration overview.
AWS Database Migration Service. (n.d.). DMS documentation.
Liquibase. (n.d.). Database migration tool.
Fowler, M. (n.d.). Data Migration Patterns. MartinFowler.com.