مقدمه
در جهان نرمافزار، هرچه سامانهها بزرگتر و پیوستهتر میشوند، تصمیمهای معماری از سطح انتخاب ابزار فراتر میروند و به سطح شکلدادن به آیندهی سیستم میرسند؛ آیندهای که باید هم تابآور باشد و هم قابل تکامل. مجموعهی پیش رو با تمرکز بر مفاهیم و رویکردهایی چون مهندسی آشوب برای سنجش تابآوری، الگوهای طراحی و یکپارچهسازی مانند API Gateway و Service Mesh، معماریهای رویدادمحور و بدونسرور، و همچنین روشهای تفکیک مسئولیتها مانند CQRS و Event Sourcing، تلاش میکند تصویری دقیقتر از شیوههای مدرن ساخت و ادارهی سامانههای توزیعشده ارائه دهد. در کنار اینها، مباحثی نظیر API-first، طراحی دامنهمحور و معماری ششضلعی، ما را به سمت انضباط فکری در تعریف مرزها و قراردادها هدایت میکنند؛ و موضوعاتی مانند MLOps، AI4SE و SE4AI نشان میدهند که نرمافزار امروز، بیش از همیشه با داده و یادگیری ماشین گره خورده است. از سوی دیگر، IaC، کانتینرها و ارکستراسیون، پیامصفها، چندمستاجری، سکوهای کمکد/بیکد، BPMS و مهاجرت داده، بعد عملیاتی و سازمانی این جهان را آشکار میسازند؛ جایی که کیفیت، امنیت، مقیاسپذیری و حاکمیت، شرط بقا و رشد سامانهاند. در ادامه به برسی اجمالی موضوعات پرداخته خواهد شد.
Chaos Engineering
مهندسی آشوب رویکردی در معماری و بهرهبرداری از سامانههای نرمافزاری است که هدف آن، شناخت رفتار سیستم در شرایط غیرعادی و پیشبینینشده است. در این روش، بهجای آنکه منتظر بمانیم خطاها و اختلالها بهصورت واقعی و در بدترین زمان ممکن رخ دهند، تیم فنی بهطور کنترلشده و آگاهانه برخی بینظمیها را در سامانه ایجاد میکند تا میزان تابآوری، پایداری و آمادگی آن سنجیده شود. برای مثال، ممکن است قطع شدن یک سرویس، افزایش ناگهانی تأخیر شبکه، یا از دسترس خارج شدن یک سرور بهصورت عمدی شبیهسازی شود تا مشخص گردد آیا سیستم همچنان میتواند عملکرد اصلی خود را حفظ کند یا نه. مهندسی آشوب، برخلاف آنچه از نامش برمیآید، بهدنبال ایجاد هرجومرج نیست، بلکه میکوشد از دل آشفتگی کنترلشده، شناختی دقیقتر از نقاط ضعف سامانه به دست آورد. این رویکرد بهویژه در سامانههای توزیعشده، ابری و مبتنی بر ریزخدمات اهمیت زیادی دارد؛ زیرا در چنین محیطهایی، پیچیدگی بالا و وابستگیهای متعدد باعث میشود که یک خطای کوچک، پیامدهای گستردهای ایجاد کند. در مجموع، مهندسی آشوب به سازمانها کمک میکند تا پیش از وقوع بحران واقعی، آسیبپذیریهای پنهان را شناسایی کنند و سامانههایی مطمئنتر و مقاومتر بسازند.
Backend for Frontend
معمولاً بهاختصار BFF نامیده میشود، الگویی در معماری نرمافزار است که در آن برای هر نوع رابط کاربری یا هر گروه مشخصی از کاربران، یک لایهی پشتیبان اختصاصی طراحی میشود تا نیازهای همان رابط را بهصورت دقیق، ساده و بهینه پاسخ دهد. ایدهی اصلی این رویکرد از آنجا شکل میگیرد که یک سامانهی واحد معمولاً باید به چند نوع کاربر یا چند نوع واسط، مانند وب، موبایل و حتی پنلهای مدیریتی، خدمترسانی کند و طبیعی است که نیازهای این واسطها یکسان نباشد. در چنین وضعیتی، اگر همهی این بخشها مستقیماً از یک backend عمومی استفاده کنند، هم پیچیدگی افزایش مییابد و هم احتمال ناکارآمدی در تبادل داده بیشتر میشود. الگوی BFF این مشکل را با ایجاد یک لایهی میانی تخصصی حل میکند؛ لایهای که دادهها را متناسب با نیاز همان فرانتاند جمعآوری، فیلتر، ترکیب و آمادهسازی میکند. در نتیجه، رابط کاربری سبکتر، ارتباطات شبکه کارآمدتر و توسعهی مستقل بخشهای مختلف آسانتر میشود. البته این الگو در کنار مزایای خود، ممکن است باعث افزایش تعداد سرویسها و پیچیدگی مدیریتی نیز شود، اما در سامانههایی که چندین نوع کلاینت با نیازهای متفاوت دارند، رویکردی بسیار مفید و منطقی به شمار میآید.
AI4SE
مخفف عبارت Artificial Intelligence for Software Engineering است، به کاربرد روشها و ابزارهای هوش مصنوعی در بهبود فرایند مهندسی نرمافزار اشاره دارد؛ یعنی جایی که هوش مصنوعی نقش یار کمکی مهندس نرمافزار را بازی میکند تا کارها سریعتر، دقیقتر و نظاممندتر انجام شوند. در این رویکرد، از تکنیکهایی مانند یادگیری ماشین، پردازش زبان طبیعی و مدلهای مولد برای پشتیبانی از فعالیتهایی نظیر استخراج نیازمندیها از متن، پیشنهاد معماری مناسب، تولید یا تکمیل کد، کشف باگ، نوشتن تست، تحلیل تغییرات، بازبینی خودکار Pull Request و حتی پیشبینی ریسکهای پروژه استفاده میشود. ارزش اصلی AI4SE در این است که بسیاری از کارهای تکراری یا زمانبر که معمولاً کیفیت نهایی را هم تحت فشار قرار میدهند به کمک ابزارهای هوشمند قابل سادهسازی میشوند و تیم توسعه میتواند انرژی خود را بر تصمیمهای طراحی و حل مسائل پیچیدهتر متمرکز کند. البته باید توجه داشت که خروجی هوش مصنوعی همواره نیازمند ارزیابی انسانی است؛ زیرا مدلها ممکن است دچار اشتباه، خطای منطقی یا نادیده گرفتن قیود دامنه شوند. بنابراین، AI4SE زمانی بیشترین فایده را دارد که بهعنوان یک ابزار کمکی قابلاعتماد، در کنار استانداردهای مهندسی، بازبینی دقیق و مسئولیتپذیری حرفهای به کار گرفته شود.
SE4AI
در عصر حاضر که هوش مصنوعی (AI) با سرعتی شگرف در حال دگرگونی صنایع و زندگی است، ضرورت بهکارگیری اصول و شیوههای مهندسی نرمافزار (Software Engineering - SE) در توسعه و مدیریت سیستمهای هوشمند، بیش از پیش نمایان شده است. SE4AI یا مهندسی نرمافزار برای هوش مصنوعی، رهیافتی نوظهور است که در پی تلفیق این دو حوزه قدرتمند برمیآید. این رویکرد، بر این اصل استوار است که سیستمهای مبتنی بر هوش مصنوعی، بهرغم تفاوتهایشان با نرمافزارهای سنتی، نیازمند فرآیندهای مهندسیشده، ساختارمند و قابل اتکا در چرخه حیات توسعه خود هستند. از فاز جمعآوری و پیشپردازش دادهها، طراحی و آموزش مدلهای یادگیری ماشین، تا استقرار، پایش، نگهداری و بهروزرسانی مداوم این سیستمها در محیطهای عملیاتی، هر مرحله با چالشهای منحصر به فردی روبروست که صرفاً با اتکا به دانش سنتی مهندسی نرمافزار یا صرفاً دانش هوش مصنوعی قابل حل نیست. SE4AI به دنبال ارائه چارچوبها، متدولوژیها، ابزارها و بهترین شیوههایی است که تضمینکننده کیفیت، قابلیت اطمینان، مقیاسپذیری، امنیت و قابلیت نگهداری سیستمهای هوش مصنوعی باشند. این همگرایی، نه تنها به ارتقای کیفیت و پایداری محصولات مبتنی بر AI کمک میکند، بلکه مسیر را برای نوآوریهای سریعتر و مسئولانهتر در این عرصه هموار میسازد، تا اطمینان حاصل شود که قدرت فزاینده هوش مصنوعی در جهت منافع بشری و با رعایت اصول اخلاقی و حرفهای به کار گرفته میشود.
MLOps
از ترکیب دو واژهی Machine Learning و Operations ساخته شده است، مجموعهای از اصول، ابزارها و فرایندهای مهندسی بهشمار میآید که هدف آن، تبدیل مدلهای یادگیری ماشین از یک نمونهی آزمایشگاهی به یک جزء قابلاتکا در محصول واقعی است. در بسیاری از پروژهها، ساختن یک مدل با دقت مناسب در محیط تحقیقاتی پایان کار نیست؛ مسئلهی اصلی از جایی آغاز میشود که باید دادهها بهصورت مستمر جمعآوری و پاکسازی شوند، مدل نسخهبندی شود، آموزش و ارزیابی آن قابل تکرار باشد، استقرار در محیط عملیاتی بدون اختلال انجام گیرد، و عملکرد مدل در طول زمان زیر نظر بماند. MLOps دقیقاً به همین نقاط اتصال میان توسعه و بهرهبرداری میپردازد و مفاهیمی مانند خط لولهی آموزش و استقرار (Pipeline)، یکپارچهسازی و تحویل مداوم (CI/CD)، پایش کیفیت داده و مدل، مدیریت انحراف داده و مفهوم (data drift concept drift)، و سازوکار بازآموزی دورهای را سامان میدهد. حاصل این رویکرد، کاهش ریسک، افزایش قابلیت اعتماد و شفافیت در چرخهی عمر مدل است؛ زیرا مدلها نیز مانند نرمافزار، در معرض تغییر، فرسودگی و خطا قرار دارند. به بیان دقیقتر، MLOps کمک میکند سیستمهای مبتنی بر هوش مصنوعی، نه صرفاً هوشمند، بلکه پایدار، قابل نگهداری و پاسخگو باشند.
Infrastructure as Code (IaC)
زیرساخت بهمثابه کد، رویکردی در مهندسی نرمافزار و رایانش ابری است که در آن اجزای زیرساختمانند سرورها، شبکه، توازندهندههای بار، پایگاهدادهها، دیوارههای آتش و تنظیمات امنیتیهجای پیکربندی دستی و موردی، با فایلهای متنی و قابلنسخهبندی تعریف و مدیریت میشوند. ایدهی محوری IaC این است که زیرساخت نیز باید همانند کد برنامهنویسی، قابل بازبینی، قابل بازگشت به نسخههای پیشین، قابل آزمون و قابل تکرار باشد؛ زیرا تغییرات دستی معمولاً مستعد خطا، فراموشی و ناهماهنگی میان محیطهای توسعه، آزمون و تولید است. با IaC میتوان محیطی استاندارد ساخت که در چند دقیقه روی یک بستر ابری یا مرکز داده ایجاد شود و دقیقاً همان ویژگیها را در اجراهای بعدی نیز حفظ کند. این رویکرد همچنین همکاری تیمی را سادهتر میکند، زیرا تغییرات زیرساخت در قالب درخواست تغییر (Pull Request) قابل بررسی و تأیید است. البته باید توجه داشت که IaC، اگر بدون نظم و کنترل دسترسی اجرا شود، میتواند خطا را نیز با سرعت بیشتری تکثیر کند؛ از همین رو، مدیریت نسخه، بازبینی دقیق و اعمال سیاستهای امنیتی، بخش جداییناپذیر استفادهی حرفهای از آن به شمار میآید.
API Gateway and Service Mesh
هر دو از مفاهیم کلیدی در معماری سامانههای توزیعشدهاند، اما نقش و جایگاه آنها یکسان نیست و درک تفاوتشان به طراحی صحیح کمک میکند. API Gateway در حکم دروازهی ورودی سامانه عمل میکند؛ یعنی درخواستهای کلاینتها مانند وب و موبایل ابتدا به این نقطه میرسند و سپس، بر اساس قوانین تعریفشده، به سرویسهای داخلی هدایت میشوند. در این مسیر، وظایفی مانند احراز هویت و مجوزدهی، محدودسازی نرخ درخواستها، تجمیع پاسخها، ثبت لاگ و مدیریت نسخههای API نیز میتواند در همین لایه انجام شود. در مقابل، Service Mesh بیشتر به ارتباطات درون سامانه میپردازد؛ یعنی زمانی که سرویسها با یکدیگر گفتگو میکنند. این الگو معمولاً با قرار دادن یک پراکسی سبک در کنار هر سرویس، امکانهایی مانند کشف سرویس، مسیریابی هوشمند، توازن بار، رمزنگاری ارتباطات، ردیابی توزیعشده و اعمال سیاستهای امنیتی را بهصورت یکپارچه فراهم میکند، بیآنکه لازم باشد این قابلیتها در کد هر سرویس تکرار شوند. بهبیان ساده، API Gateway نظم مرزهای بیرونی را برقرار میکند و Service Mesh انضباط و مشاهدهپذیری را به رگهای داخلی سیستم میآورد؛ انتخاب و ترکیب آنها نیز باید متناسب با اندازه، پیچیدگی و نیازهای عملیاتی پروژه انجام گیرد.
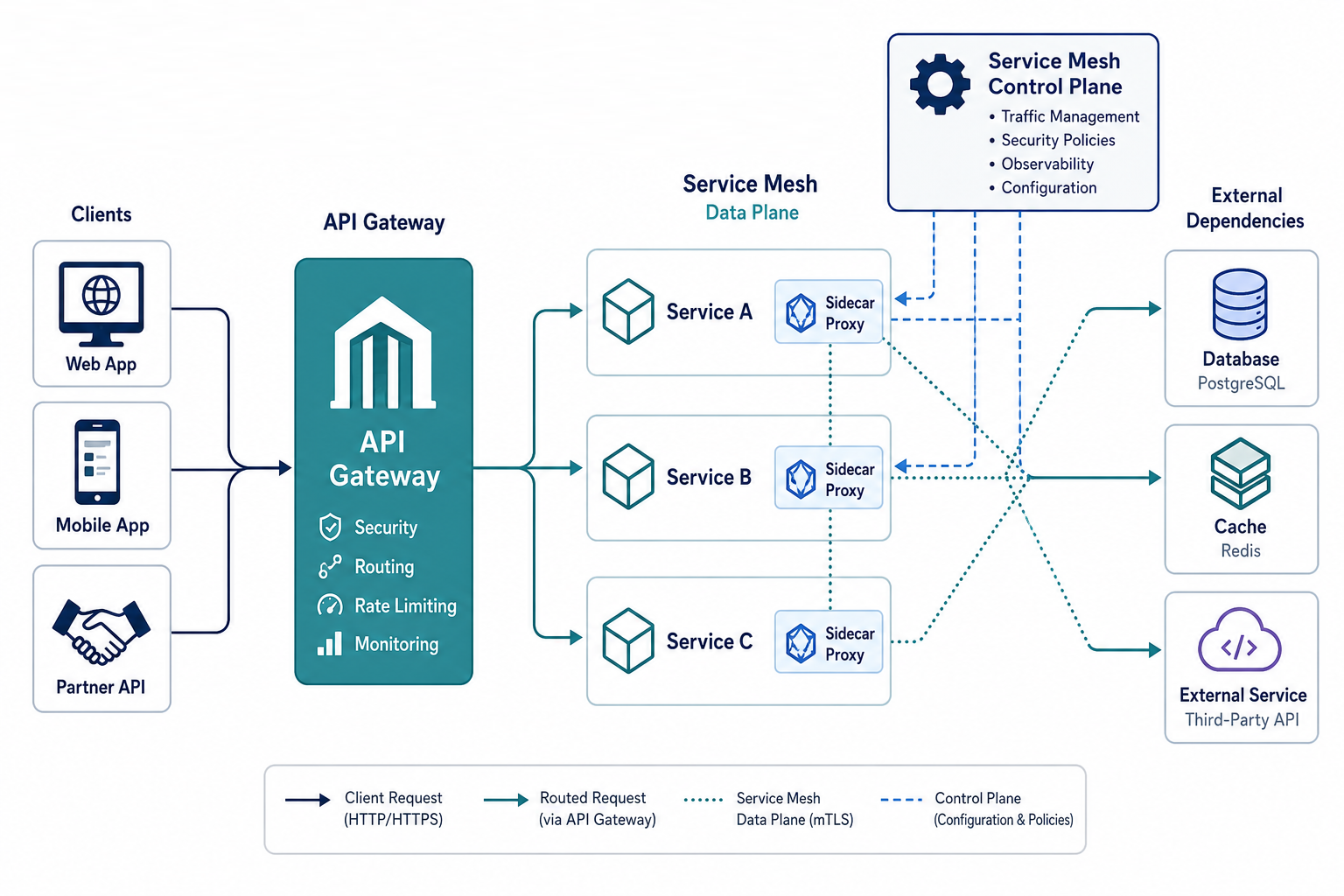
تصویر زیر نشان میدهد که API Gateway مسئول کنترل و نظم مرز بین بیرون و داخل و از طرف دیگر Service Mesh مسئول نظم و امنیت ارتباطات داخل سیستم است. در سمت چپ، چند نوع کلاینت مثل وب، موبایل و حتی API شریک تجاری داریم که همه درخواستهای خود را به یک نقطهی واحد یعنی API Gateway میسپارند. این دروازه، مرز رسمی سامانه است؛ جایی که پیش از ورود به قلمرو سرویسها، قواعد حاکم میشود مثل احراز هویت و مجوزدهی، محدودسازی نرخ درخواستها، ثبت و ردیابی لاگها، مدیریت نسخههای API و در صورت نیاز تجمیع پاسخها. سپس Gateway مانند راهنمایی دقیق، درخواست را به سرویس مناسب در بخش داخلی هدایت میکند تا پراکندگی و آشوب در نقطهی تماس با بیرون شکل نگیرد. در سوی دیگر تصویر، هنگامی که درخواست به سرویسها میرسد، نقش Service Mesh آغاز میشود؛ نه برای استقبال از بیرون، بلکه برای ساماندادن به گفتوگوی سرویسها با یکدیگر. کنار هر سرویس یک پراکسی سبک (Sidecar) قرار گرفته که همچون همراهی خاموش اما هوشیار، ارتباطات را از مسیر خود عبور میدهد؛ خطوط نقطهچین میان این پراکسیها، همان شبکهی کنترلشدهای است که کشف سرویس، مسیریابی هوشمند، توازن بار، رمزنگاری ارتباطات، اعمال سیاستهای امنیتی و ردیابی توزیعشده را یکپارچه میکند، بیآنکه این دغدغهها در کد هر سرویس تکرار و تکثیر شوند. حضور Control Plane در بالای تصویر نیز یادآور آن است که این نظم، با سیاستگذاری متمرکز و اجرا در لبهی هر سرویس تحقق مییابد. به بیان روشن، API Gateway پاسدار آستانه و تنظیمکنندهی رابطهی سامانه با بیرون است، و Service Mesh انضباط، امنیت و مشاهدهپذیری را در رگهای داخلی آن جاری میکند؛ ترکیب هوشمندانهی این دو، زمانی ارزشمند است که اندازه و پیچیدگی پروژه، چنین معماری منسجم و عملیاتی را توجیه کند.
CQRS
مخفف Command Query Responsibility Segregation است، الگویی در معماری نرمافزار محسوب میشود که پیشنهاد میکند مسئولیت تغییر دادن وضعیت سیستم و خواندن وضعیت سیستم از یکدیگر جدا شوند. در این نگاه، Commandها درخواستهایی هستند که داده را ایجاد، ویرایش یا حذف میکنند و معمولاً باید با قواعد کسبوکار، اعتبارسنجی و کنترل همزمانی سازگار باشند؛ در حالیکه Queryها صرفاً برای دریافت اطلاعات طراحی میشوند و نباید اثر جانبی بر سیستم بگذارند. جداسازی این دو مسیر باعث میشود هرکدام مطابق نیاز خود بهینه شوند یعنی بخش خواندن میتواند برای سرعت و انعطاف در گزارشگیری مدل دادهی مناسبتری داشته باشد، و بخش نوشتن میتواند بر صحت و یکپارچگی قوانین دامنه تمرکز کند. CQRS بهویژه در سامانههایی که حجم خواندن بسیار بیشتر از نوشتن است، یا نیاز به نماهای متفاوت از داده وجود دارد، مفید واقع میشود. البته این الگو هزینههایی هم دارد؛ از جمله افزایش پیچیدگی طراحی، نیاز به همگامسازی داده میان مدلهای خواندن و نوشتن، و در برخی پیادهسازیها پذیرش سازگاری نهایی بهجای سازگاری فوری. بنابراین CQRS زمانی انتخابی خردمندانه است که مسئلهی واقعی، آنقدر جدی باشد که این پیچیدگیِ اضافه، توجیه فنی و اقتصادی پیدا کند.
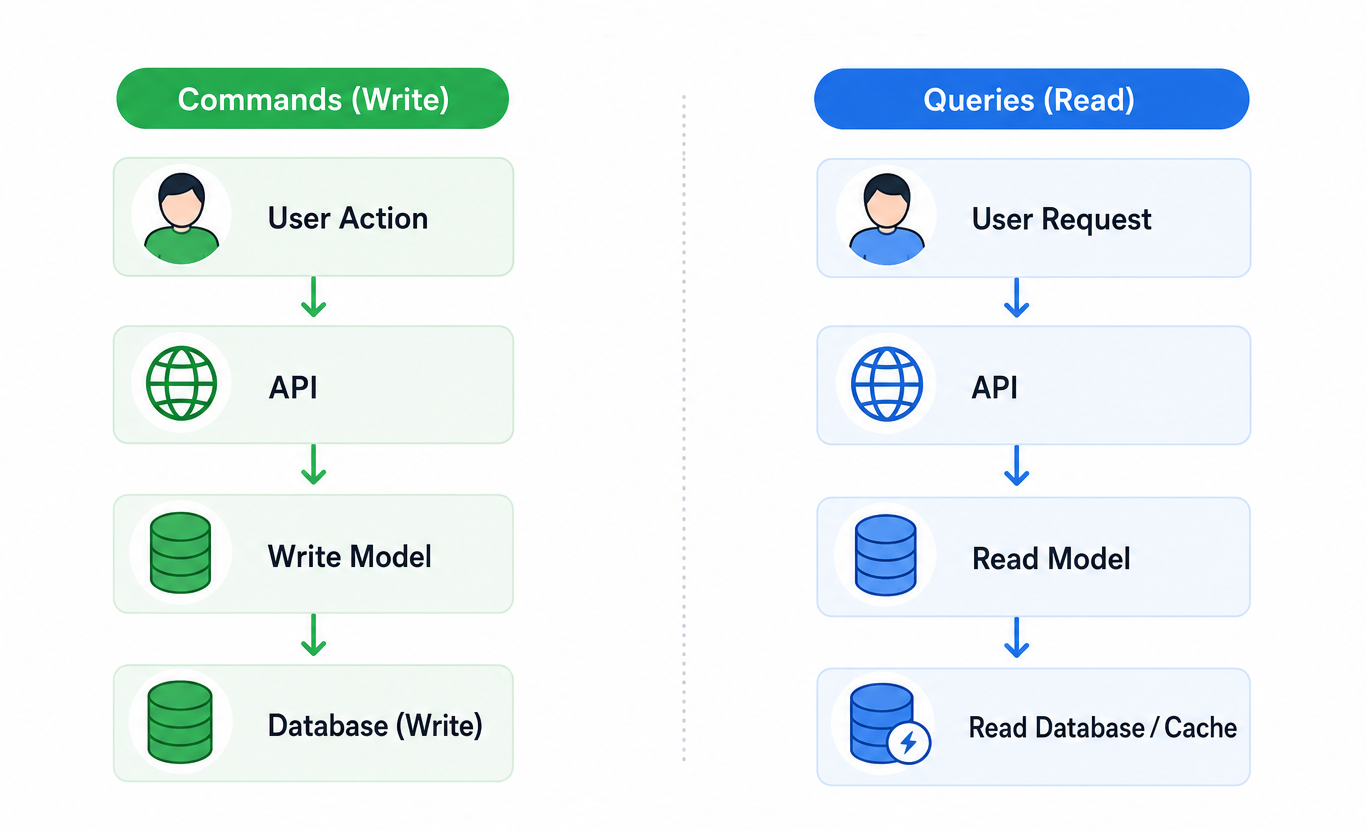
تصویر زیر مفهوم CQRS را با زبانی روشن و ساختاری دیداری بیان میکند؛ گویی سامانه از همان آغاز میپذیرد که خواندن و تغییر دادن داده، دو کار همجنس نیستند و نباید لزوماً از یک مسیر عبور کنند. در بخش مربوط به Commands (Write)، مسیر انجام عملهایی دیده میشود که وضعیت سیستم را دگرگون میکنند؛ مانند ایجاد، ویرایش یا حذف داده. این بخش، بهطور طبیعی، با دقت بیشتری به قواعد کسبوکار، اعتبارسنجی، کنترل همزمانی و حفظ انسجام دادهها وابسته است، زیرا هر تغییر نادرست میتواند تعادل کل سامانه را بر هم بزند. در سوی دیگر، مسیر Queries (Read) برای دریافت اطلاعات طراحی شده است؛ مسیری که قرار نیست چیزی را تغییر دهد، بلکه تنها باید داده را سریع، شفاف و متناسب با نیاز کاربر بازگرداند. همین جداسازی، که در تصویر با دو راه مستقل نشان داده شده، به ما یادآوری میکند که سامانه میتواند برای خواندن، مدلی سبکتر و سریعتر مثلاً مبتنی بر کش یا پایگاه دادهی مناسب گزارشگیری داشته باشد، در حالی که بخش نوشتن بر صحت و منطق دامنه متمرکز میماند. در حقیقت، CQRS نظمی آگاهانه در معماری پدید میآورد: هر مسیر، کار خود را انجام میدهد و بار دیگری را بر دوش نمیکشد. البته این نظم، بیهزینه به دست نمیآید؛ زیرا طراحی را پیچیدهتر میکند، همگامسازی میان مدل خواندن و نوشتن را ضروری میسازد و گاه مستلزم پذیرش سازگاری نهایی بهجای سازگاری فوری است. از همینرو، جمعبندی تصویر آن است که CQRS نسخهای همگانی نیست؛ بلکه زمانی معنا پیدا میکند که نیاز واقعی سامانه، هزینهی پیچیدگی آن را توجیه کند و زمانی ارزشمند میشود که مسئلهی سامانه، واقعاً آنقدر بزرگ و پرتقاضا باشد که این جداسازی، از نظر فنی و اقتصادی، به تصمیمی سنجیده و خردمندانه بدل شود.
Event-Driven Architecture (EDA)
معماری رویدادمحور سبکی از طراحی سامانههای نرمافزاری است که در آن، جریان اصلی تعاملات بر پایهی وقوع رویداد شکل میگیرد؛ یعنی هرگاه تغییری مهم در سیستم رخ دهد، آن رخداد بهصورت یک پیام یا اعلان منتشر میشود تا بخشهای دیگر، در صورت نیاز، به آن واکنش نشان دهند. در این معماری، بهجای آنکه اجزای مختلف سامانه بهطور مستقیم و تنگاتنگ یکدیگر را فراخوانی کنند، میان آنها نوعی ارتباط غیرمستقیم و منعطف برقرار میشود که وابستگی را کاهش میدهد و توسعهپذیری را افزایش میبخشد. برای نمونه، ثبت یک سفارش میتواند رویدادهایی مانند سفارش ایجاد شد یا پرداخت تأیید شد تولید کند و سرویسهای مستقلی چون انبار، ارسال، اعلان و گزارشگیری هرکدام متناسب با همان رویداد عمل کنند. این شیوه، مقیاسپذیری و انعطاف سامانه را بهویژه در محیطهای توزیعشده و ریزخدمتمحور بسیار تقویت میکند؛ اما در کنار این مزایا، چالشهایی مانند دشواری در ردیابی جریانها، مدیریت ترتیب رویدادها، تضمین تحویل پیام و پذیرش سازگاری نهایی نیز پدید میآید. از اینرو، معماری رویدادمحور زمانی بیشترین ارزش را دارد که نیاز به واکنش سریع، استقلال سرویسها و گسترش تدریجی سامانه، بر سادگی ظاهری ارتباطات مستقیم ترجیح داده شود.
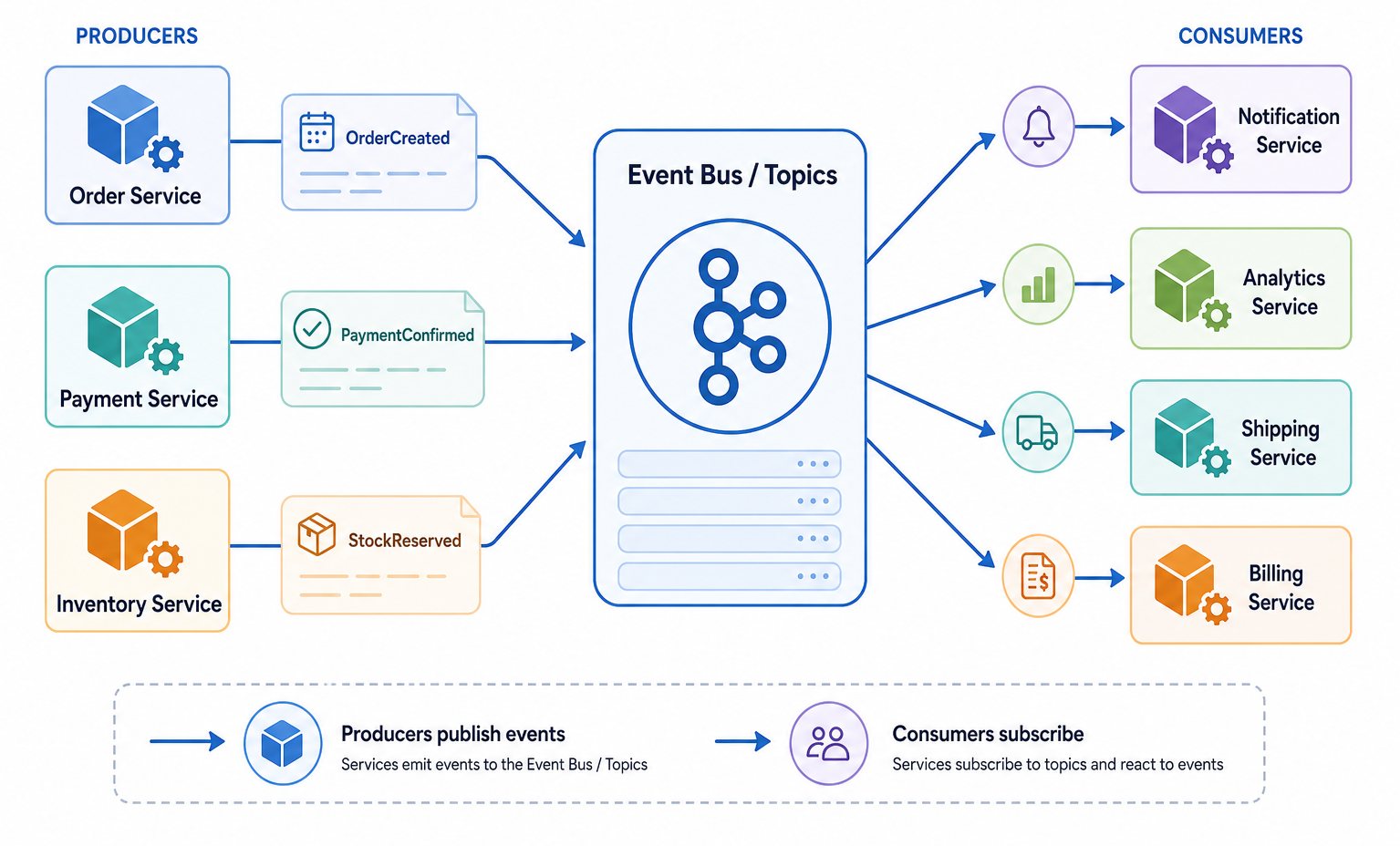
تصویر زیر معماری رویدادمحور (Event-Driven Architecture) را مانند یک میدان مرکزی پررفتوآمد ترسیم میکند که در آن، خبر رخدادها مهمتر از گفتوگوی مستقیم سرویسهاست. در سمت چپ، سرویسهای تولیدکننده مانند Order Service، Payment Service و Inventory Service هرگاه تغییر معناداری در کارشان اتفاق میافتد مثلاً OrderCreated یا PaymentConfirmed آن را به شکل یک کارت رویداد منتشر میکنند و به مرکز تصویر میفرستند. این مرکز، همان Event Bus / Topics است؛ شبیه تابلوی اعلاناتی عمومی که پیامها را نگه میدارد و به جای آنکه سرویسها یکدیگر را مستقیم صدا بزنند، امکان میدهد هر کس فقط رویداد را اعلام کند. در سمت راست، سرویسهای مصرفکننده مانند Notification، Analytics، Shipping و Billing بدون آنکه به تولیدکنندهها وابسته باشند، رویدادهای موردنیاز خود را مشترک میشوند و واکنش مناسب نشان میدهند. نتیجهی این الگو، کاهش وابستگی، افزایش انعطاف و تقویت مقیاسپذیری است؛ زیرا افزودن یک مصرفکنندهی جدید معمولاً نیازمند دستکاری سرویسهای قبلی نیست. با این حال، تصویر بهطور ضمنی یادآوری میکند که این آزادی، هزینه هم دارد یعنی ردیابی مسیر یک فرایند از ابتدا تا انتها دشوارتر میشود، مدیریت ترتیب رویدادها و تضمین تحویل پیام اهمیت حیاتی پیدا میکند و گاهی باید سازگاری نهایی را به جای سازگاری فوری پذیرفت. این نمودار میگوید EDA زمانی بهترین انتخاب است که سامانه به واکنش سریع، رشد تدریجی و استقلال سرویسها نیاز دارد و حاضر است در برابر این مزایا، پیچیدگی مدیریت رویدادها را نیز مسئولانه بپذیرد.
Serverless Architecture
معماری بدونسرور رویکردی در طراحی سامانههای ابری است که در آن توسعهدهنده بهجای درگیری مستقیم با تهیه، پیکربندی و نگهداری سرورها، تمرکز خود را بر منطق کسبوکار و کد کاربردی میگذارد و مسئولیت مدیریت زیرساخت را تا حد زیادی به ارائهدهندهی سرویس ابری میسپارد. منظور از بدونسرور این نیست که سروری وجود ندارد، بلکه یعنی سرور برای تیم توسعه به یک جزئیات پنهان و مدیریتشده تبدیل میشود. رایجترین شکل این معماری، اجرای کد در قالب توابع رویدادمحور (Function as a Service) است؛ جایی که برنامه در واکنش به رخدادهایی مانند درخواست HTTP، پیام صف، یا تغییر در پایگاهداده اجرا میشود و سپس منابع آزاد میگردد. از مزایای مهم Serverless میتوان به مقیاسپذیری خودکار، پرداخت بهازای مصرف واقعی و سرعت بالای استقرار اشاره کرد؛ ویژگیهایی که برای پروژههای نوپا یا سرویسهای با ترافیک نوسانی بسیار ارزشمندند. بااینحال، چالشهایی مانند تأخیر شروع اولیه (cold start)، محدودیت در کنترل جزئیات محیط اجرا، دشواری برخی سناریوهای پایش و اشکالزدایی، و وابستگی بیشتر به پلتفرم ارائهدهنده نیز وجود دارد. بنابراین معماری بدونسرور زمانی انتخابی سنجیده است که هدف، چابکی و بهرهوری عملیاتی باشد و قیود فنی آن با نیازهای سامانه تعارض جدی نداشته باشد.
API-first Approach
رویکرد APIمحور، شیوهای در توسعهی نرمافزار است که در آن طراحی و تعریف رابطهای برنامهنویسی کاربردی، پیش از پیادهسازی جزئیات داخلی سامانه انجام میشود و API بهعنوان قرارداد اصلی میان اجزای سیستم در نظر گرفته میشود. در این رویکرد، تیم توسعه ابتدا مشخص میکند که سرویس چه قابلیتهایی باید در اختیار مصرفکنندگان قرار دهد، ساختار درخواست و پاسخ چگونه باشد، چه دادههایی مبادله شوند و خطاها با چه الگوی مشخصی مدیریت گردند. چنین نگاهی سبب میشود وابستگی میان تیمها کاهش یابد و توسعهی موازی بخشهای مختلف، از جمله فرانتاند، بکاند و حتی سرویسهای شخص ثالث، آسانتر شود؛ زیرا همه بر پایهی یک قرارداد روشن و مستند حرکت میکنند. API-first همچنین کیفیت مستندسازی، نسخهبندی، آزمونپذیری و قابلیت استفادهی مجدد را تقویت میکند و از تصمیمگیریهای شتابزدهای که در مراحل پایانی پروژه دردسرساز میشوند، جلوگیری بهعمل میآورد. البته این روش نیازمند دقت بیشتر در تحلیل نیازها و صرف زمان در مرحلهی طراحی است، اما همین تأمل اولیه معمولاً از بسیاری از ناهماهنگیها و دوبارهکاریهای پرهزینه در آینده جلوگیری میکند. بهبیان دیگر، API-first رویکردی است که توسعه را از سطح ساختن صرف به سطح طراحی سنجیدهی تعاملات ارتقا میدهد.
Domain Driven Design (DDD)
طراحی دامنهمحور رویکردی در تحلیل و طراحی نرمافزار است که تأکید میکند قلب سامانه باید بر مبنای منطق کسبوکار و واقعیتهای دامنهی مسئله شکل بگیرد، نه صرفاً بر پایهی جزئیات فنی یا سلیقهی پیادهسازی. در DDD، تیم توسعه میکوشد زبان مشترکی میان متخصصان کسبوکار و برنامهنویسان ایجاد کند؛ زبانی که به آن Ubiquitous Language گفته میشود و قرار است همان مفاهیمی را که در گفتگوهای روزمرهی دامنه به کار میرود، بهصورت دقیق و بدون ابهام در مدل نرمافزار نیز منعکس کند. همچنین DDD پیشنهاد میکند دامنههای پیچیده به بخشهایی با مرزهای روشن تقسیم شوند؛ این مرزها که Bounded Context نام دارند، کمک میکنند هر بخش مدل مفهومی متناسب با خود را داشته باشد و تداخل معنایی میان قسمتهای مختلف به حداقل برسد. در این چارچوب، مفاهیمی مانند Entity، Value Object، Aggregate، Repository و Domain Service برای ساختن مدلی منسجم و قابل نگهداری به کار میروند. مزیت مهم DDD این است که با تمرکز بر مدل دامنه، تغییرات کسبوکار بهتر جذب میشود و سیستم در برابر رشد و پیچیدگی، دیرتر فرسوده میگردد؛ بااینحال، اجرای موفق آن نیازمند گفتوگوی مستمر با خبرگان دامنه، انضباط در مرزبندی و پرهیز از پیچیدهسازی بیدلیل است.
Hexagonal Architecture
معماری ششضلعی رویکردی هوشمندانه در طراحی نرمافزار است که با هدف جداسازی منطق اصلی سامانه از وابستگیهای بیرونی شکل گرفته است. در این الگو، هستهی سیستم، که همان منطق دامنه و قواعد کسبوکار را در بر میگیرد، در مرکز توجه قرار دارد و اجزای خارجی مانند پایگاهداده، رابط کاربری، سرویسهای بیرونی یا چارچوبهای اجرایی، نه بهعنوان بخشهای تعیینکننده، بلکه در مقام ابزارهایی پیرامونی دیده میشوند. ایدهی بنیادین این معماری آن است که نرمافزار نباید اسیر فناوریهایی شود که هر لحظه ممکن است تغییر کنند؛ بلکه باید چنان طراحی شود که منطق اصلی آن مستقل، پایدار و آزمونپذیر باقی بماند. در این چارچوب، ارتباط میان هسته و جهان بیرون از طریق درگاهها و مبدلها انجام میشود؛ سازوکاری که امکان تعویض اجزای بیرونی را، بدون آسیبزدن به بنیان سامانه، فراهم میسازد. مزیت مهم معماری ششضلعی در افزایش انعطافپذیری، سهولت آزمون، و کاهش وابستگی به فناوریهای خاص است؛ زیرا تغییر پایگاهداده یا شیوهی ارائهی خدمات، لزوماً به معنای دستبردن در قلب سیستم نخواهد بود. البته پیادهسازی این الگو نیازمند درک دقیق مرزها و انضباط معماری است و اگر سطح پیچیدگی پروژه پایین باشد، ممکن است برای برخی تیمها اندکی بیش از حد مهندسیشده به نظر برسد؛ همان وضعیتی که گاهی برای شکار یک پشه، جلسهی راهبردی تشکیل میدهند. بااینهمه، در سامانههایی که پایداری، توسعهپذیری و استقلال از ابزارهای متغیر اهمیت دارد، Hexagonal Architecture انتخابی سنجیده و ارزشمند بهشمار میآید.
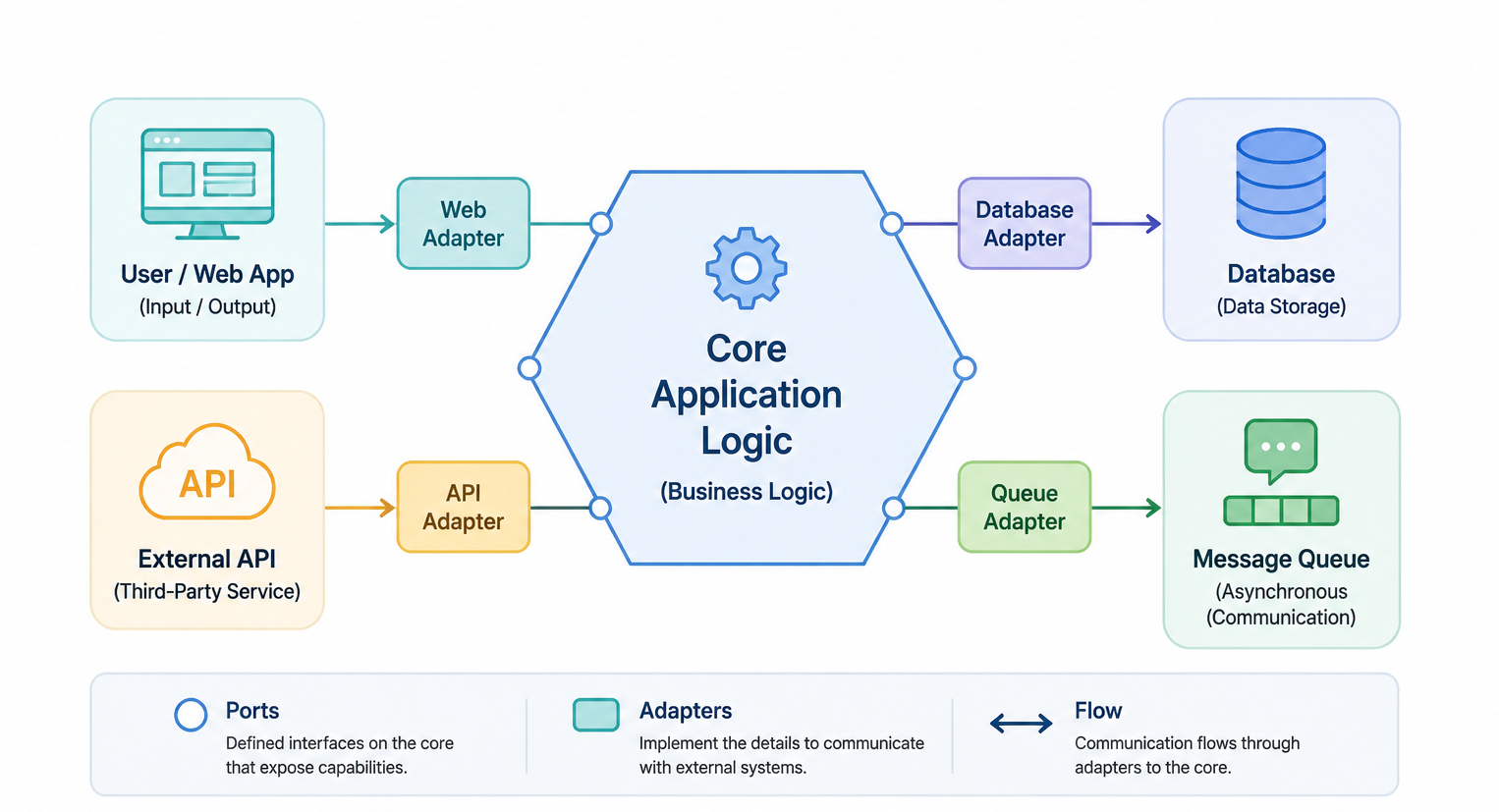
تصویر زیر معماری ششضلعی را نمایش میدهد؛ در مرکز این ساختار، هستهی مستقل سامانه قرار دارد؛ بخشی که بدون وابستگی مستقیم به عناصر بیرونی، منطق اصلی برنامه را در بر میگیرد. این هسته، مهمترین بخش سامانه است؛ جایی که قواعد واقعی کسبوکار، تصمیمها و رفتارهای اساسی نرمافزار شکل میگیرند. پیرامون این هسته، عناصر بیرونی مانند کاربر یا وباپلیکیشن، پایگاهداده، API خارجی و صف پیام دیده میشوند که هرکدام از راهی کنترلشده به مرکز متصل شدهاند. این اتصال مستقیم و بیواسطه نیست، بلکه از مسیر درگاهها و مبدلها انجام میشود؛ یعنی نرمافزار بهگونهای طراحی میشود که هستهی آن، وابسته ابزارهای بیرونی نباشد. پیام اصلی تصویر این است که آنچه باید پایدار بماند، منطق درونی سیستم است، نه فناوریهایی که ممکن است به زودی تغییر کنند. اگر روزی پایگاهداده عوض شود، یا شیوهی ارتباط با کاربر و سرویسهای خارجی دگرگون گردد، قرار نیست قلب سامانه از نو نوشته شود؛ زیرا مرزها از پیش با دقت تعریف شدهاند. همین جداسازی، آزمونپذیری را بیشتر میکند، توسعه را آسانتر میسازد و نرمافزار را در برابر تغییرات بیرونی مقاومتر نگه میدارد. البته این رویکرد، بهویژه در پروژههای کوچک، گاهی بیش از اندازه مهندسیشده به نظر میرسد. با این همه، در سامانههایی که دوام، انعطاف و استقلال از فناوریهای گذرا اهمیت دارد، معماری ششضلعی راهی سنجیده و حرفهای برای طراحی نرمافزار به شمار میآید.
Event Sourcing
رویدادمحوری در ذخیرهسازی وضعیت رویکردی در طراحی سامانههای نرمافزاری است که بهجای نگهداری صرف آخرین وضعیت دادهها، تمامی تغییرات رخداده در سیستم را بهصورت دنبالهای از رویدادهای ثبتشده ذخیره میکند. در این نگاه، حقیقت سامانه نه در یک تصویر ایستا از اکنون، بلکه در تاریخچهی دقیق و قابلردیابی تحول آن نهفته است. بهبیان دیگر، هر تغییر مهم، از ایجاد یک موجودیت تا اصلاح یا حذف آن، بهصورت یک رویداد مستقل ثبت میشود و وضعیت فعلی سیستم از بازسازی همین رویدادها بهدست میآید. این رویکرد مزایای چشمگیری دارد از جمله قابلیت حسابرسی دقیق، امکان بازسازی گذشته، تحلیل رفتار سیستم در طول زمان، و هماهنگی مناسب با معماریهای توزیعشده و رویدادمحور. Event Sourcing همچنین درک عمیقتری از منطق کسبوکار فراهم میآورد، زیرا نشان میدهد چه اتفاقی افتاده است، نه فقط اکنون چه وضعی برقرار است. بااینحال، اجرای آن نیازمند دقت فراوان در طراحی رویدادها، مدیریت نسخهها، و کنترل پیچیدگی بازسازی وضعیت است؛ چراکه اگر این تاریخچه بیضابطه انباشته شود، سیستم از یک دفتر ثبت وقایع دقیق به انباری شلوغ از خاطرات دیجیتال تبدیل خواهد شد. ازاینرو، Event Sourcing بیشتر برای سامانههایی مناسب است که ردیابی، شفافیت، و اهمیت تاریخچه در آنها نقشی اساسی دارد، نه برای هر مسئلهای که صرفاً اسم معماریاش مدرن به نظر میرسد.
Low-code/No-code Platforms
سکوهای کمکد/بیکد پاسخی عملی به نیاز روزافزون سازمانها برای تولید سریع نرمافزار و خودکارسازی فرایندهاست؛ سکوهایی که بهجای تکیهی کامل بر برنامهنویسی سنتی، امکان ساخت برنامه را با ابزارهای بصری، اجزای آماده و پیکربندیهای قابلدرک فراهم میکنند. در این رویکرد، بخش قابلتوجهی از منطق کاربردی با کشیدن و رهاکردن مؤلفهها، تعریف گردشکارها، و تنظیم قوانین انجام میشود و تنها در صورت نیاز، با کدنویسی محدود تکمیل میگردد. مزیت برجستهی این پلتفرمها، کوتاهکردن فاصلهی میان ایده و محصول است؛ بهگونهای که تیمها میتوانند نمونهی اولیه را سریع بسازند، بازخورد بگیرند و نسخههای بعدی را بیدرنگ اصلاح کنند. افزون بر این،Low-code/No-code فرصت میدهد برخی نیازهای سادهتر توسط کاربران کسبوکار یا شهروند-توسعهدهندگان پیگیری شود و فشار از دوش تیمهای فنی کاهش یابد. بااینحال، این سکوها همیشه بیهزینه نیستند یعنی محدودیت در سفارشیسازی عمیق، وابستگی به فروشنده، چالشهای مقیاسپذیری و حتی ملاحظات امنیتی و حاکمیت داده، از نکاتی است که باید پیش از انتخاب آنها سنجیده شود. در نهایت، این پلتفرمها زمانی ارزش واقعی خود را نشان میدهند که با نگاه معماری، استانداردهای کنترل کیفیت و چارچوبهای حاکمیتی همراه شوند؛ وگرنه ممکن است به جای چابکی، انبوهی از راهکارهای پراکنده و ناهمگون به میراث بگذارند.
Business Process Management Systems (BPMS)
سامانههای مدیریت فرایندهای کسبوکار مجموعهای از ابزارها و رویکردهای نرمافزاری هستند که با هدف مدلسازی، اجرا، پایش و بهینهسازی فرایندهای سازمانی طراحی شدهاند. این سامانهها به سازمان کمک میکنند تا فعالیتهای پراکنده، تصمیمهای تکرارشونده و جریانهای کاری پیچیده را از حالت سلیقهای و نامنظم خارج کرده و در قالب فرایندهایی شفاف، قابلکنترل و قابلاندازهگیری سامان دهد. در BPMS، فرایندها تنها توصیف نمیشوند، بلکه بهصورت عملیاتی اجرا شده و دادههای مرتبط با عملکرد آنها نیز ثبت و تحلیل میگردد؛ ازاینرو، مدیران میتوانند گلوگاهها، تأخیرها، دوبارهکاریها و نقاط اتلاف منابع را با دقت بیشتری شناسایی کنند. یکی از مزایای مهم این سامانهها آن است که میان اهداف کسبوکار و زیرساخت نرمافزاری پلی منظم برقرار میکنند و امکان میدهند تغییرات فرایندی با سرعت بیشتر و آشفتگی کمتر اعمال شود. با اینحال، استقرار موفق BPMS تنها به خرید یک ابزار وابسته نیست؛ بلکه نیازمند شناخت دقیق فرایندها، مشارکت ذینفعان، فرهنگ سازمانی آماده و نگاه تحلیلی به بهبود مستمر است. در غیر این صورت، سامانهای که قرار بود نظم بیاورد، ممکن است صرفاً آشفتگیهای قدیمی را با ظاهری مدرنتر و دکمههایی براقتر بازتولید کند. از همین رو، BPMS زمانی بیشترین اثربخشی را دارد که نه بهعنوان یک نرمافزار صرف، بلکه بهمنزلهی سازوکاری برای فهم، هدایت و بلوغ فرایندهای سازمانی در نظر گرفته شود.
Message Queue
صف پیام مفهومی بنیادی در معماری سامانههای توزیعشده است که با هدف ساماندادن به تبادل داده میان اجزای مختلف، بهویژه در شرایط بار بالا و نیاز به استقلال سرویسها، به کار گرفته میشود. در این الگو، تولیدکنندهی پیام بهجای آنکه مستقیماً سرویس مقصد را فراخوانی کند، پیام را در یک صف یا کارگزار پیام قرار میدهد و مصرفکننده در زمان مناسب آن را دریافت و پردازش میکند. حاصل این میانجیگری، کاهش وابستگی زمانی و اجرایی میان اجزا، افزایش تابآوری در برابر اختلالها، و امکان مقیاسپذیری مستقل بخشهای مختلف سیستم است؛ زیرا اگر مصرفکننده موقتاً کند یا غیرفعال شود، پیامها از بین نمیروند و در صف باقی میمانند. فناوریهایی مانند RabbitMQ معمولاً برای الگوهای صفمحور و مسیریابی منعطف پیامها مناسباند، در حالی که Kafka بیشتر بهعنوان یک سکوی ثبت و جریاندادن رخدادها شناخته میشود و در سناریوهایی که حجم عظیم داده، پردازش جریانی و نگهداری تاریخچهی پیامها اهمیت دارد، میدرخشد. با این حال، بهرهگیری از صف پیام بیچالش نیست یعنی مدیریت ترتیب پیامها، تضمین تحویل، تکرارپذیری پردازش، و طراحی مناسب برای خطا و تکرار نیازمند دقت معماری است. در نهایت، Message Queue زمانی ارزش واقعی خود را نشان میدهد که بهعنوان ابزاری برای نظم بخشی به ارتباطات و مهار پیچیدگی در سامانههای بزرگ به کار رود، نه صرفاً بهعنوان یک فناوری جذاب که بیحساب به هر پروژهای الصاق شود.
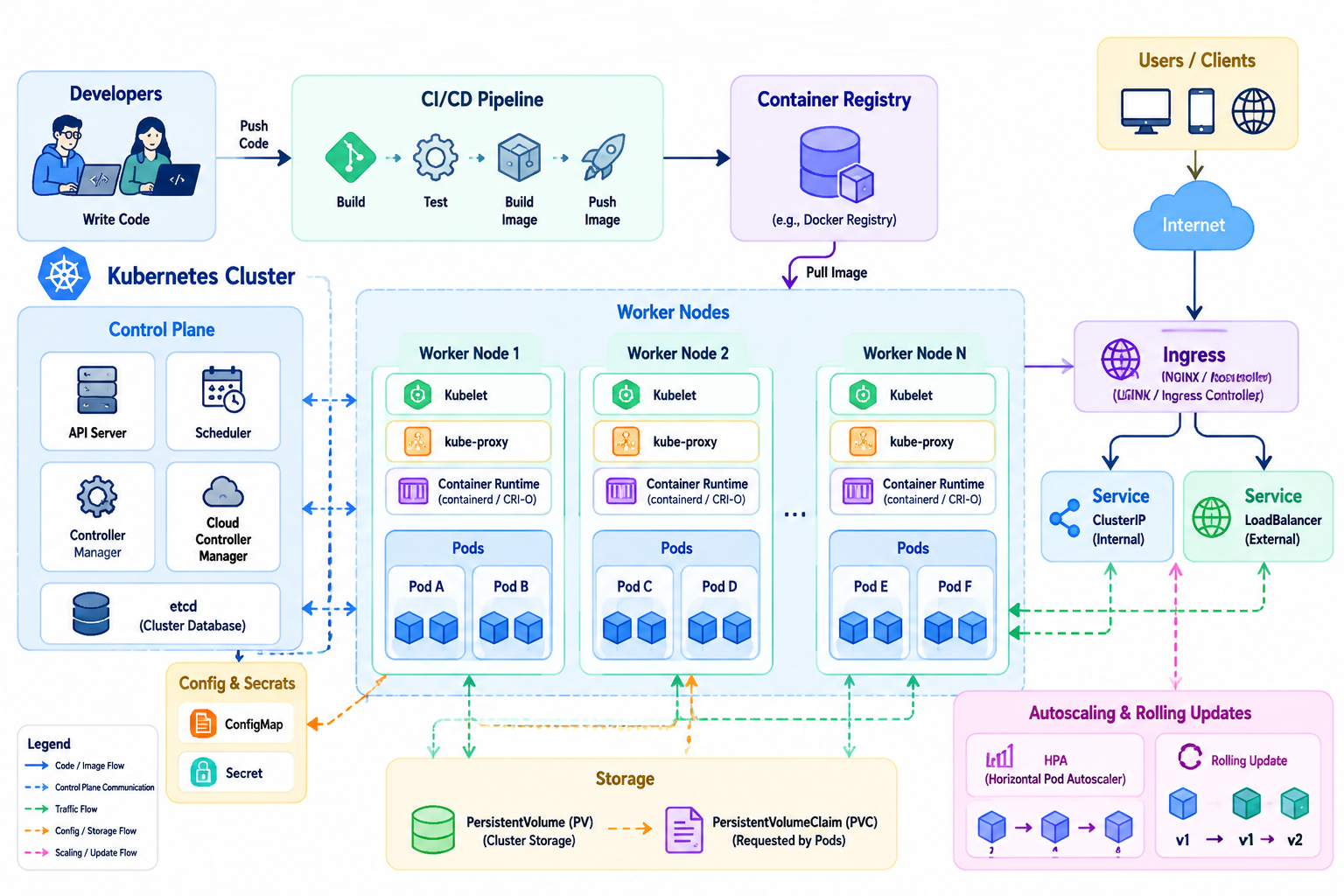
Containers
کانتینرها روشی نوین و کارآمد برای بستهبندی و اجرای نرمافزارند که در آن، برنامه بههمراه وابستگیها، کتابخانهها و تنظیمات موردنیازش در یک واحد سبک و قابل حمل قرار میگیرد تا در محیطهای گوناگون با رفتاری یکسان اجرا شود. ابزارهایی مانندDocker این امکان را فراهم میکنند که فاصلهی آزاردهندهی میان روی سیستم من کار میکند و روی سرور مشکل دارد تا حد زیادی از میان برداشته شود؛ زیرا کانتینر، اجرا را به یک محیط استاندارد و تکرارپذیر گره میزند. با این حال، هنگامی که تعداد کانتینرها زیاد میشود و سامانه به چندین سرویس و نمونه تقسیم میگردد، مسئلهی مدیریت، مقیاسدهی، شبکه، کشف سرویسها و بازیابی پس از خطا به چالشی جدی تبدیل میشود. در اینجاست که Container Orchestration یا ارکستراسیون کانتینرها معنا پیدا میکند؛ یعنی بهکارگیری سکوهایی مانند Kubernetes برای خودکارسازی استقرار، توزیع بار، افزایش یا کاهش مقیاس، پایش سلامت و جایگزینی خودکار سرویسهای معیوب. ترکیب کانتینر و ارکستراسیون، معماری را به سمت چابکی و پایداری سوق میدهد و زمینه را برای توسعهی میکروسرویسها و انتشار سریع نسخهها فراهم میسازد. با این وجود، این مسیر نیازمند بلوغ عملیاتی، دانش شبکه و رصد دقیق است؛ چراکه Kubernetes اگرچه نظم میآورد، اما همزمان پیچیدگیهای خاص خود را نیز وارد میدان میکند. در مجموع، کانتینرها و ارکستراسیون، وقتی آگاهانه و متناسب با نیاز انتخاب شوند، به جای شتابزدگی فنی، به سامانه انضباط، انعطاف و توان رشد میبخشند.
تصویر زیر نمایانگر جهانی است که در آن نرمافزار دیگر محدود به یک ماشین نیست؛ بلکه با کانتینرها، برنامهها همراه با تمام متعلقاتشان اعم از کتابخانهها، وابستگیها، و تنظیمات در واحدهایی سبک و مستقل بستهبندی میشوند. این همان رویکردی است که با ابزارهایی چون Docker، مشکل روی سیستم من کار میکرد را به حداقل میرساند، چون محیط اجرا همیشه یکسان و تکرارپذیر است. اما وقتی این کانتینرها زیاد میشوند و یک سامانه را تشکیل میدهند، مدیریتشان از جمله توزیع بار، مقیاسدهی، شبکهبندی، کشف سرویسها و بازیابی در صورت خطا به چالشی بزرگ بدل میگردد. اینجاست که نقش Kubernetes به عنوان یکContainer Orchestration برجسته وارد میشود؛ سکویی قدرتمند که استقرار، مقیاسدهی، پایش سلامت و جایگزینی خودکار کانتینرهای در حال اجرا را خودکار میکند. تصویر زیر نشان میدهد که چگونه Control Plane شامل API Server، Scheduler، Controller Manager و etc برWorker Nodes که هرکدام Kubelet ،kube-proxy ،Container Runtime و Podها را در خود جای دادهاند نظارت میکند. Podها، که واحدهای کوچکتری هستند و میتوانند شامل یک یا چند کانتینر باشند، توسط Kubernetes مدیریت میشوند. همچنین، جریان تصویر نشان میدهد که توسعهدهندگان چگونه کد را از طریق CI/CD Pipeline ساخته، تست و ایمیج میکنند و سپس این ایمیجها درContainer Registry ذخیره شده و توسط Worker Nodes کشیده میشوند. مدیریت Config & Secrets، Storage (PersistentVolume و PersistentVolumeClaim) و قابلیتهای Autoscaling & Rolling Updates که توسط Horizontal Pod Autoscaler (HPA) و مکانیزم Rolling Update فراهم میشوند، همگی بخشی از اکوسیستم Kubernetes هستند که به این معماری نظم، انعطاف و پایداری میبخشند. در نهایت، Ingress Service (Internal - External) نحوهی دسترسی کاربران و کلاینتها از طریق اینترنت به سرویسهای درون کلاستر را مدیریت میکنند. این ترکیب، یعنی کانتینرها و ارکستراسیون، اگرچه پیچیدگیهای خاص خود را دارد، اما برای ساخت سامانههای توزیعشده، چابک، مقیاسپذیر و پایا، ابزاری بنیادین و بسیار قدرتمند محسوب میشود.
Multi-Tenancy Architecture
معماری چندمستاجری الگویی در طراحی سامانههای نرمافزاری، بهویژه در محصولات ابری و نرمافزارهای خدمتمحور، است که در آن یک نمونهی واحد از سامانه بهطور همزمان به چندین مشتری، سازمان یا گروه کاربری خدمترسانی میکند، بیآنکه مرزهای منطقی و امنیتی میان دادهها و تنظیمات آنها از میان برود. در این رویکرد، کاربران مختلف اگرچه از زیرساخت و هستهی اجرایی مشترکی بهره میبرند، اما هر مستاجر باید تجربه، داده و پیکربندی مخصوص به خود را داشته باشد؛ گویی هر یک در فضایی مستقل فعالیت میکند. مزیت اصلی این معماری در بهرهوری بالاتر منابع، کاهش هزینههای عملیاتی، سهولت بهروزرسانی و مدیریت متمرکز سامانه نهفته است؛ زیرا بهجای نگهداری نسخهای جداگانه برای هر مشتری، یک بستر مشترک با قابلیت تفکیک منطقی اداره میشود. با این حال، طراحی صحیح Multi-Tenancy نیازمند حساسیت بسیار در حوزههایی چون امنیت، کنترل دسترسی، جداسازی داده، مقیاسپذیری، سفارشیسازی و نظارت بر عملکرد است؛ چراکه کوچکترین ضعف در مرزبندی میتواند اعتماد و یکپارچگی سامانه را مخدوش سازد. از اینرو، معماری چندمستاجری صرفاً روشی برای اشتراک منابع نیست، بلکه هنری در ایجاد تعادل میان صرفهجویی، انعطافپذیری و حفظ استقلال هر مشتری است؛ هنری که اگر ناشیانه اجرا شود، از صرفهجویی وعدهدادهشده تنها دردسرهای مشترک برای همه بر جای خواهد گذاشت.
Data Migration
مهاجرت داده فرایندی حساس و سرنوشتساز در چرخهی عمر سامانههای نرمافزاری است که طی آن، دادهها از یک پایگاهداده، قالب، یا بستر عملیاتی به مقصدی جدید منتقل میشوند؛ خواه این مقصد نسخهای تازه از همان سامانه باشد، خواه زیرساختی متفاوت مانند انتقال از محیط محلی به ابر، یا از یک موتور پایگاهداده به موتوری دیگر. مهاجرت داده صرفاً جابهجایی فایلها نیست؛ بلکه نوعی بازآرایی دقیق معنا و ساختار اطلاعات است، بهگونهای که یکپارچگی، سازگاری و قابلیت اتکای دادهها حفظ شود و سیستم جدید بتواند بدون مشکل به کار ادامه دهد. در این مسیر، گامهایی مانند تحلیل کیفیت داده، نگاشت فیلدها، پاکسازی، تبدیل قالبها، مدیریت کلیدها و روابط، و طراحی راهبردهای آزمون و بازگشت (rollback) نقشی حیاتی دارند. چالشهای اصلی نیز معمولاً از دل جزئیات بیرون میآیند: دادههای ناقص یا تکراری، تفاوت مدلهای مفهومی، محدودیت زمان توقف سرویس، و ریسک از دسترفتن تاریخچه یا معنای اطلاعات. ازاینرو، مهاجرت موفق زمانی رخ میدهد که با برنامهریزی مرحلهای، اجرای آزمایشی، پایش دقیق و مستندسازی منظم همراه باشد؛ زیرا در جهان داده، یک انتقال بیدقت میتواند بهسادگی به بازسازی پرهزینهی اعتماد تبدیل شود.
نتیجهگیری
مباحث مذکور نشان میدهد معماری نرمافزار نه یک نقشهی ثابت، بلکه مجموعهای از انتخابهای آگاهانه برای مدیریت پیچیدگی، کاهش ریسک و افزایش قابلیت اعتماد است؛ انتخابهایی که از طراحی قراردادهای شفاف و مرزبندی درست آغاز میشوند و تا خودکارسازی عملیات، پایش پیوسته و پذیرش تغییر ادامه مییابند. الگوهایی مانند API-first، DDD و Hexagonal Architecture ما را به سمت هستهای پایدار و قابل فهم سوق میدهند؛ در حالی که EDA، Message Queue، CQRS و Event Sourcing راههایی برای مقیاسپذیری، تفکیک دغدغهها و ثبت دقیق واقعیتهای رخداده فراهم میکنند. Serverless، کانتینرها و Kubernetes، همراه با IaC، چهرهی اجرای نرمافزار را صنعتیتر و قابل تکرارتر میسازند؛ و مباحث مرتبط با هوش مصنوعی و MLOps یادآور میشوند که کیفیت سیستم، تنها در کد خلاصه نمیشود و به داده، چرخهی استقرار مدل و نظارت پس از انتشار نیز وابسته است. نهایتاً، موضوعاتی مانند چندمستاجری و مهاجرت داده تأکید میکنند که معماری موفق، هم زمان باید به نیازهای کسبوکار، امنیت، هزینه و تجربهی کاربر پاسخ دهد؛ و همین تلفیق ظریف معنا، فناوری و انضباط است که از یک سیستم صرفاً کارکردی یک سامانهی واقعاً قابل اتکا میسازد.
منابع
Gremline - What is Chaos Engineering?
dynatrace - What is Chaos Engineering?
learn Microsoft - backends for frontends, event sourting, data migration
mobilelive - why backend for frontend application architecture
wikipedia - MLOps, Hexagonal architecture
ibm - infrastructure a code, low code vs no code, business process management, kubernetes vs docker, multi tennat
geeksforgeeks - gateway vs service mesh, event driven architecture system design
martinfowler bliki - CQRS, DomainDrivenDesign