APIها همیشه برای برقراری ارتباط بین سرویسها و برنامههای نرمافزاری استفاده میشدند و صرفا یک رابط ساده بهحساب میآمدند. اما امروزه، این APIها تبدیل به اجزای اساسی و بنیادین سیستمهای نرمافزاری و حتی کسبوکارها شدند! امروزه نیاز داریم تا بتوانیم روی دستگاههای مختلف، به صورت یکپارچه و همزمان کار کنیم.
قبل از این رویکرد، برای ساخت نرمافزار، ابتدا بکاند ساخته میشد. یعنی ساخت پایگاه داده و نوشتن کدهای اصلی در اولویت بود و بعد از آن، برای اتصال بخشهای دیگر به این کدها API مربوطه ساخته میشد. ما تازه در این نقطه میتوانستیم بفهمیم که آیا نیازهای کاربر با کد نوشته شده و API، تطابق دارد یا نه. و اگر همخوانی نداشت، باید کل کدهای گذشته را از نو مینوشتیم!
برای اینکه این مشکل پیش نیاید، از رویکرد API-first Approach استفاده میشود. در اینجا، اولویت با APIهاست. دیگر رابطها یک محصول نهایی نیستند، بلکه قبل از نوشته شدن هر کدی، طراحی و ساخته میشوند. اینگونه دیگر تیم فرانتاند، نیازی ندارد تا منتظر اتمام کار تیم بکاند شود و میتواند بهطور موازی کار را پیش ببرد و استقلال در تیمها رعایت میشود. همین باعث ایجاد تجربه بهتر برای توسعهدهندگان(Developer Experience) میشود. چون ورودی و خروجیهای API از قبل مشخص شده است و همه چیز حول محور آنها میچرخد. مسئولین پروژه باهم به توافق رسیده و قراردادی برای توصیف APIها تنظیم میکنند. این کار توسعهپذیری را آسانتر و اجرای چرخهها(Iteration) سریعتر میکند و استفادهی مجدد را بالا میبرد.
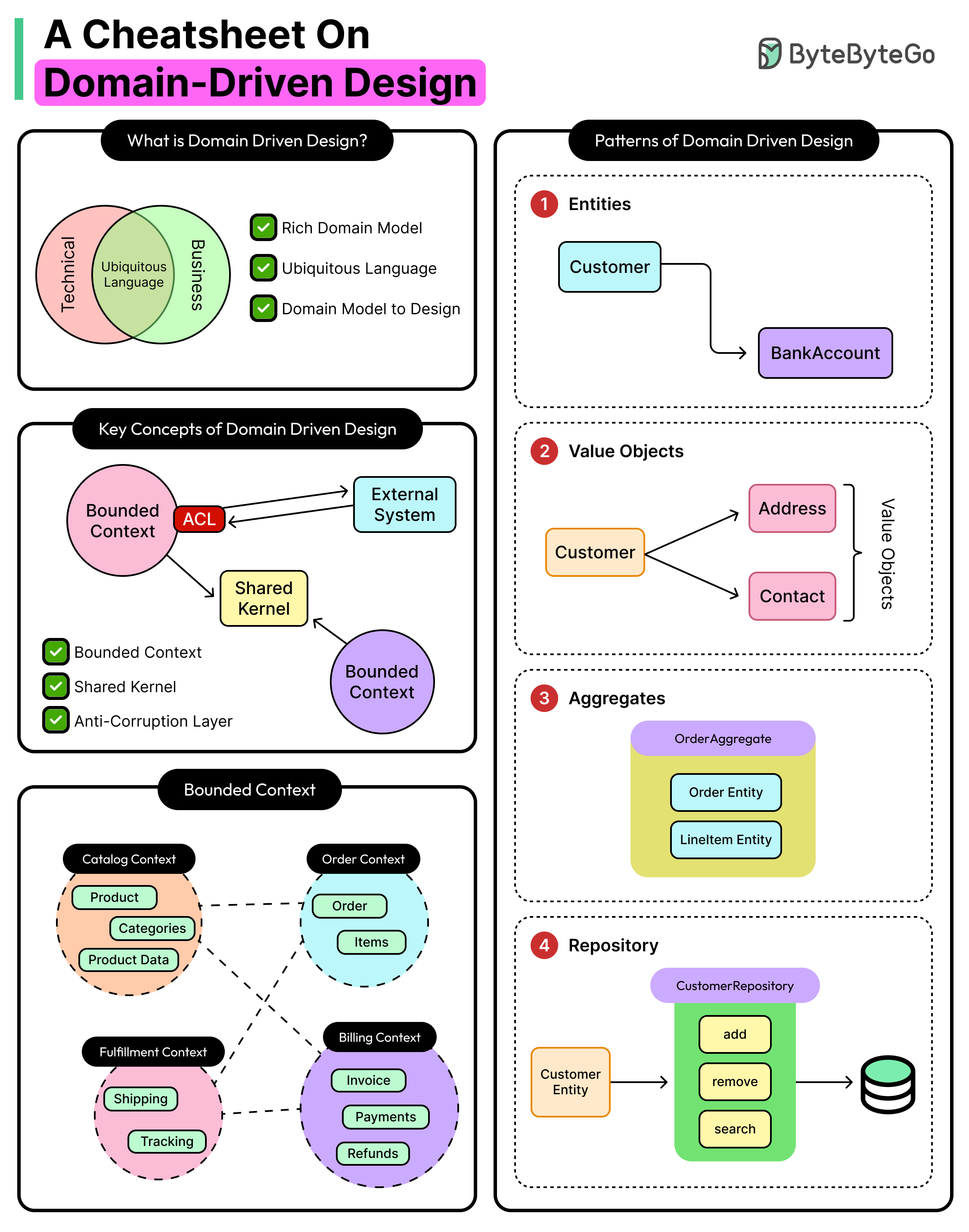
رویکرد DDD، بیشتر درباره فهم عمیق کسبوکار است. در این رویکرد، ما با واقعیتِ پیچیدهی سازمان روبهرو هستیم که به آن Domain(دامنه) میگویند. نباید سعی کرد این سیستم پیچیده را یکجا بفهمیم. پس آن را به تکههای کوچکتر یا Subdomain(زیردامنه) میشکنیم:
Core Subdomain یا هسته مرکزی: آن مزیت رقابتی اصلی که کسبوکار روی آن بنا شده است. بیشترین زمان و توان مهندسی سیستم باید همینجا متمرکز شود.
Supporting / Generic Subdomains یا پشتیبانی: بخشهایی مثل سیستم حسابداری، احراز هویت یا انبارداری که برای بقای سیستم ضروریاند، اما بخش اصلی آن سازمان نیستند.
برای عبور از فضای مسئله به سمت کدنویسی، به دو ابزار نیاز داریم تا مطمئن شویم معماری سیستم با ساختار تیمها و فرآیندها در تضاد نیست:
Bounded Contexts یا محدودههای مرزبندیشده: هر زیردامنه، به یک محدوده نرمافزاری ایزوله تبدیل میشود. مثلا موجودیتِ کالا در سیستم انبارداری، ویژگیها و رفتارهای کاملا متفاوتی با همان کالا در سیستم فروش دارد. ما این دو مفهوم را در یک جدول یا کلاس با هم مخلوط نمیکنیم، بلکه برای هر کدام مرز میکشیم.
Ubiquitous Language یا زبان فراگیر: درون هر کدام از این محدودهها، تیم توسعه و افراد درگیر در سازمان باید یک فهم واحد داشته باشند تا هیچ سوءتفاهمی در ترجمهی نیازمندیها به کد پیش نیاید.
حال اجزای سازندهی مدل دامنه (Domain Model) که با اصول پیشرفتهی تفکیک لایهها و ایزولهسازی درگیر هستند را بررسی کنیم:
موجودیتها یا Entities: اشیائی که ID دارند و وضعیتشان در طول زمان تغییر میکند.
اشیاء مقداری یا Value Objects: مفاهیمی که ID ندارند و فقط با مقادیرشان شناخته میشوند (مثل یک آدرس پستی یا یک واحد پول) و باید کاملاً غیرقابلتغییر(Immutable) باشند.
Aggregates: مرکز کنترلِ ثباتِ سیستم. شامل موجودیتها و اشیاء مقداری، که به عنوان یک واحد منفرد رفتار میکنند و یک موجودیت ریشه(Aggregate Root)، تمام تراکنشها و قوانین حاکم بر آنها را کنترل میکند.
این هستهی ایزولهشده، در نهایت از طریق مخازن(Repositories) با زیرساخت داده درگیر میشود و با انتشار Domain Events با سایر محدودهها ارتباط برقرار میکند تا اتصال بین سرویسها در سستترین حالت ممکن(Loose Coupling) باقی بماند.
حالا ببینیم این آزمایش چطور کار میکند:
۱. تعریف وضعیت پایدار (Steady State): ابتدا مشخص میکنیم که سیستم در حالت عادی چه رفتاری دارد. مثلا در هر ثانیه ۱۰۰ تراکنش موفق ثبت میشود.
۲. طرح فرضیه (Hypothesis): یک پیشبینی انجام میدهیم. مثلاً، فرضیهی ما این است که اگر سرویسِ بررسیِ موجودیِ انبار از کار بیفتد، کل سایت داون نمیشود؛ بلکه فقط دکمه افزودن به سبد خرید غیرفعال میشود.
۳. تزریق خطا (Fault Injection): حالا در محیط عملیاتی با کنترل دقیق شعاع تخریبی که مشتریان متوجه نشوند، به صورت عمدی، سرورِ سرویسِ انبار را خاموش میکنیم یا شبکه آن را کُند میکنیم.
۴. مشاهده و تحلیل (Observation): بررسی میکنیم که آیا سیستم طبق فرضیه ما رفتار کرد؟ یا برعکس، باعث یک «خرابی آبشاری» (Cascading Failure) شد و کل دیتابیس را درگیر کرد؟
۵. بهبود معماری: اگر سیستم شکست خورد، آزمایش متوقف میشود و تیم مهندسی شروع به اصلاح معماری و ایجاد مسیرهای جایگزین (Fallback) میکند.
شبنم جلیل پور : • مفهوم دوم: backend for frontend
در گذشته سیستمهای نرمافزاری، برای دسکتاپ طراحی میشدند؛ اما با گذشت زمان و آمدن گوشی های هوشمند و تغییر نیازهای تجاری، رابط کاربری موبایل هم به سیستمها اضافه شد. پس تمام کلاینتها مثل نسخه وب دسکتاپ و اپلیکیشنهای موبایل، مجبور بودند از یک سرویس بکاند استفاده کنند و دادههایشان را از همانجا تامین کنند. این مدل تا زمانی که فقط با یک رابط کاربری سروکار داشتیم، کارآمد بود. اما با ورود کلاینتهای مختلف، این معماریِ یکپارچه، به تدریج به مشکل خورد. اولین راهکار برای پشتیبانی از چند نوع رابط کاربری، ایجاد یک API همهمنظوره سمت سرور بود، که به مرور زمان عملکردهای جدیدی به آن اضافه میشد. اما مشکل جایی
بود که یک API همهمنظوره(The General-Purpose API Backend) مجبور بود پاسخگوی نیازهای کاملاً متفاوت باشد. مرورگر دسکتاپ، توان پردازشی بالا و اینترنت پایداری دارد، درحالی که موبایل با محدودیت باتری، صفحه نمایش کوچک و پهنای باند کمتر مواجه است و به دیتای بسیار سبکتر نیاز دارد. پس سرویس بکاند، باید به تمام این نیازهای متناقض پاسخ میداد. در نتیجه، این API واحد، به یک «گلوگاه توسعه»(Bottleneck) تبدیل میشد؛ به طوری که تیمهای فرانتاند، برای هر تغییر کوچکی در رابط کاربری، باید منتظر تیم بکاند میماندند تا تغییرات مربوطه در API اعمال شود. این وابستگی، سرعت توسعه را به شدت کاهش میداد و اصطکاک بالایی ایجاد میکرد.
راهکار چیست؟
الگوی Backend for Frontend دقیقاً برای رفع این مشکل معرفی شد. منطق این الگو ساده است: به جای یک بکاندِ یکپارچه برای هر رابط کاربری، یک بکاند اختصاصی میسازیم.
یعنی اپلیکیشن موبایل، BFF اختصاصی خودش را دارد که دادهها را از سرویسهای مختلف میگیرد و دقیقاً متناسب با سایز و نیاز موبایل پردازش و ارسال میکند، و نسخه وب هم BFF خودش را دارد.
مهمترین نقطه قوت این معماری در توزیع مسئولیتهاست؛ تیمی که فرانتاند موبایل را توسعه میدهد، مدیریت BFF مربوط به آن را نیز بر عهده میگیرد. این یعنی استقلال کامل در انتخاب زبان برنامهنویسی، زمانبندی انتشارها و رفع وابستگی به تیمهای دیگر را فراهم میکند.
البته در معماری هیچ راهکاری بیهزینه نیست. با پیادهسازی BFF، ما میپذیریم که بخشهایی از کد در سرویسهای مختلف تکرار شود(Code Duplication) و بار عملیاتی سیستم، برای نگهداری از چند سرویس جدا افزایش یابد.
شبنم جلیل پور : • مفهوم سوم و چهارم: AI4SE و SE4AI
این روزها شاید زیاد میشنویم که هوش مصنوعی قرار است جای برنامهنویسها را بگیرد؛ اما وقتی به توسعه سیستمهای نرمافزاری نگاه میکنیم، واقعیت متفاوت است.
حوزه AI4SE (استفاده از هوش مصنوعی در مهندسی نرمافزار)، به دنبال حذف نیروی انسانی نیست. مسئله اصلی این است که کارهای تکراری، خستهکننده و مستعد خطا، قرار است به ماشین سپرده شوند. وقتی این بار شناختیِ اضافه، از دوش توسعهدهندگان برداشته شود، ممکن است تازه فرصت پیدا کنند تا روی بخشهایی از مهندسی متمرکز شوند، که به خلاقیت و نوآوری انسانی نیاز دارند.
توسعه سیستمها پرهزینه است و وقتی در پروژهها با کمبود زمان و چالشهای زمانبندی مواجه میشویم، نتیجه این میشود که شکاف بزرگی بین معماریِ ایدهآلِ روی کاغذ و کدی که در نهایت اجرا میشود، شکل میگیرد. تحقیقاتی مثل پروژههایی که در مؤسسه SEI در حال انجام است، دقیقاً برای حل همین تلاش میکنند. ما به نسل جدیدی از اتوماسیون نیاز داریم که صرفاً کد ننویسد، بلکه بهعنوان یک پل ارتباطی، بهطور خودکار بررسی کند که آیا پیادهسازی سیستم، دقیقا منطبق با معماریِ اولیه پیش میرود یا خیر، و کدهای موجود را برای بهبود طراحی، بازآرایی کند.
مسیر آیندهی توسعه سیستمها، به سمت «مدلسازی دونفره» میرود. در این ساختار، ماشین صرفا یک تولیدکننده نیست، بلکه قرار است در تحلیل، شریکِ ما باشد و در مدیریت معماریِ کلانِ سیستم به ما کمک کند. در نهایت، ما باید بتوانیم اصولی، یک مشارکت درست بین تخصص انسانیِ خودمان و ابزارهای هوش مصنوعی ایجاد کنیم.
شبنم جلیل پور : اما ما همیشه از کارهایی که هوش مصنوعی میتواند برای مهندسی نرمافزار انجام دهد صحبت میکنیم؛ بیایید مسئله را برعکس کنیم: چرا مدلهای هوش مصنوعی، برای زنده ماندن در دنیای واقعی، به شدت به مهندسی نرمافزار(SE4AI) نیاز دارند؟
طبق تجربه شرکت های بزرگی مثل گوگل و مایکروسافت، کدهای مربوط به خودِ مدل هوش مصنوعی (الگوریتمهای یادگیری ماشین)، بخش بسیار کوچکی از کل سیستم را تشکیل میدهند. اطراف این بخش کوچک را، کدهای رابط (Glue Code)، مسیرهای پیچیده دادهها و زیرساختها فرا گرفتهاند.
در سیستمهای سنتی، کد، منطق برنامه را تعیین میکرد؛ اما در سیستمهای مبتنی بر هوش مصنوعی، این *دادهها* هستند که رفتار سیستم را شکل میدهند. دادهها مدام درحال تغییر و به روزرسانی هستند. در پی همین تغییرات، دادههای ورودیِ مدلهای هوش مصنوعی، در گذر زمان تغییر رفتار میدهند. پدیدهای که Data Drift نام دارد. اینجا همانجایی است که تکامل معماری نرمافزار با
چالش روبهرو میشود؛ اگر اصول SE4AI در معماری سیستم رعایت نشود، این تغییرات، باعث از بین رفتن یکپارچگی سیستم شده و یک «بدهی فنی پنهان» به بار میآورند که نگهداری و توسعه سیستم را بسیار سخت میکند.
بنابراین، نمیتوانیم بگوییو SE4AI صرفاً مجموعهای از ابزارهاست؛ بلکه یک تغییر نگرش است. ما به رویکردهای معماریِ جدیدی نیاز داریم تا مطمئن شویم این ساختارهای هوشمند و دائماً در حال تغییر، در محیط عملیاتی پایدار میمانند و به درستی با سایر اجزای فنی و انسانیِ سازمان یکپارچه شده و کار میکنند!
شبنم جلیل پور : • مفهوم پنجم: MLOps
انتقال یک پروژه نرمافزاری، از محیط آزمایشگاهی به محیط عملیاتی(Production)، همیشه با چالشهایی روبرو بوده است. حالا اگر این پروژه، یک مدلِ یادگیری ماشین باشد، چالش چندبرابر میشود. شاید عدهای فکر کنند وقتی یک مدل هوش مصنوعی با دقت بالا، روی سیستمشان اجرا شد، کار تمام است. اما واقعیت این است که یک مدل ایزوله، باید حتما با سیستمهای دیگر یکپارچه شده و بتواند در گذر زمان دوام بیاورد. اینجاست که نیاز به مفهومی به نام MLOps پیدا میکنیم.
برای درک این مفهوم، اول باید بدانیم چرا اصول سنتی توسعه نرمافزار برای هوش مصنوعی شکست میخورند. در مهندسی نرمافزار سنتی (DevOps)، دغدغه اصلی ما یکپارچگی کد و زیرساخت است. منطق نرمافزار ثابت است؛ اگر ما کدی را امروز بنویسیم و تغییر ندهیم، فردا هم همان خروجی را میدهد. اما در سیستمهای مبتنی بر یادگیری ماشین (MLOps)، ما با دادهها روبهرو هستیم!
پس رفتار و تصمیمات مدل هوش مصنوعی فقط به کد بستگی ندارد، بلکه مستقیماً به دادههایی وابسته است که از دنیای واقعی دریافت میکند. دنیای واقعی نیز مدام در حال تغییر است؛ بنابراین مدلی که امروز ۹۰ درصد دقت دارد، ممکن است ماه آینده به دلیل تغییر رفتار محیط و کاربران (Data Drift) دچار افت عملکرد شود.
بنابراین، تفاوت اصلی در این است، که در DevOps تمرکز ما روی CI/CD یا تست و استقرار مداومِ کد است، تا نرمافزار با سرعت و امنیت بهروزرسانی شود. در MLOps ، ما علاوه بر کد، باید روی دادهها و خود مدلها هم کنترل داشته باشیم. در اینجا مفهوم جدیدی به نام CT (Continuous Training یا آموزش مداوم) اضافه میشود. یعنی معماریِ سیستم، باید طوری باشد که افت کیفیت را تشخیص دهد و مدل را با دادههای جدید، به طور خودکار دوباره آموزش دهد. به عنوان جمع بندی اگر بخواهیم یک تعریف ساده ارائه دهیم، MLOps یعنی ترکیب ماشین لرنینگ و عملیات توسعه. وظیفه آن تبدیل کردنِ یک مدل هوش مصنوعی، از یک فایل کدِ ساده در محیط آزمایشگاهی، به یک نرمافزار مستقل و در حال کار است، که میتواند تصمیمگیری کند و به طور مداوم خودش را با شرایط جدید وفق دهد و با بخشهای مختلف سیستم یکپارچه شود.
شبنم جلیل پور : • مفهوم ششم: Infrastructure as Code
IaC به این معناست که پیکربندی و مدیریتِ زیرساختها، از حالت دستی خارج شود. برای مثال قرار است یک سیستم نرمافزاری را روی محیط وب بالا بیاوریم؛ در روش سنتی، باید تمام تنظیمات را دستی انجام دهیم و اگر سیستم بزرگ شود به مشکل میخوریم! پس به جای اینکه ادمینها، در پنلهای کاربری کلیک کنند، یا دستورات پراکنده در ترمینال بنویسند، تمام زیرساخت، اعم از سرور، دیتابیس و شبکهها، در قالب کد توصیف میشوند.
این به این معناست که مشخصاتِ سیستمی که نیاز داریم را، داخل کد مینویسیم. مثلاً در فایل مینویسیم: من ۳ سرور میخواهم که به ۱ پایگاه داده متصل باشند. ما فقط وضعیت نهایی که میخواهیم را در کد اعلام میکنیم!
وقتی زیرساخت، ماهیت نرمافزاری پیدا کند، تمام قوانین مهندسی نرمافزار روی آن قابل اجراست. این فایلهای زیرساختی، وارد سیستمهای کنترل نسخه مثل Gitمیشوند، تغییرات آن قابل بررسی است، و مهمتر از همه، کاملاً تکرارپذیرند. یعنی با اجرای مجدد این فایلِ کد، میتوان دقیقاً همین معماری پیچیده را در عرض چند دقیقه، چندین بار و بدون تفاوت یا خطای انسانی، در محیطهای دیگر مستقر کرد. در این حالت، خودِ کد تبدیل به دقیقترین و پویاترین مستندات معماری سیستم میشود.
شبنم جلیل پور : • مفهوم هفتم: API Gateway & Service Mesh
وقتی نرمافزار را از حالت یکپارچه(Monolith) خارج میکنیم و به چندین میکروسرویسِ مستقل تقسیم میکنیم، دو چالش اصلی شکل میگیرد:
یکی اینکه کلاینتها(کاربران موبایل و وب) چطور باید با این چند سرویسِ پراکنده ارتباط برقرار کنند؟
دوم اینکه، این سرویسهای پراکنده، چطور باید در محیط داخلی با یکدیگر ارتباط داشته باشند؟
API Gateway(مدیریت ترافیک خارجی) پاسخی به چالش اول است، و ترافیک شمال-جنوب (North-South) را مدیریت میکند؛ یعنی ارتباط دنیای بیرون با سرورها.
Service Mesh (مدیریت ترافیک داخلی) پاسخی به چالش دوم است و ترافیک شرق-غرب (East-West) را مدیریت میکند؛ یعنی ارتباطات داخلی بین خود میکروسرویسها.
گذرگاه API، اولین نقطهای است که درخواست کاربر به آن میرسد. در این مرحله، سیستم قوانینی که از پیش تعریف شده، مثل احراز هویت، محدودیت ترافیک یا فیلترهای امنیتی را روی درخواست اعمال میکند و سپس تصمیم میگیرد که این درخواست باید به کدام سرویس داخلی هدایت شود. پس کلاینت اصلا درگیر آدرسهای داخلی شبکه نمیشود. در معماریهای توزیعشده، گاهی اطلاعاتی که کاربر میخواهد در چند سرویس مختلف پخش شده است. به جای اینکه فرانتاند مجبور باشد به تکتک آن سرویسها درخواست جداگانه بفرستد، یک درخواستِ واحد به Gateway میفرستد. این گذرگاه، خودش پشتصحنه با چندین میکروسرویس صحبت میکند، جوابها را جمعآوری میکند و یک خروجی نهایی و یکپارچه را به کاربر برمیگرداند.
اما در Service Mesh، وقتی سرویس A، میخواهد دیتایی از سرویس B بگیرد، برنامهنویس نباید درگیر نوشتن کدهای پیچیده برای مدیریت قطعیِ شبکه یا رمزنگاری شود. Service Mesh یک واسط کوچک (به نام Sidecar Proxy) کنار هر سرویس قرار میدهد، که تمام این ارتباطات شبکهای را بهطور مستقل مدیریت میکند.
شبنم جلیل پور : • مفهوم هشتم: CQRS
اینکه بتوانیم مدلِ بهروزرسانی اطلاعات را، از مدلِ خواندن اطلاعات جدا کنیم، میتواند در برخی شرایط بسیار ارزشمند باشد. این همان ایدهی مفهوم cqrs، یا جداسازیِ مسئولیتِ خواندن و نوشتن است.
در سیستمهای معمولی، ما از یک مدلِ واحد برای همهچیز استفاده میکنیم؛ یعنی همان ساختاری که داده را در دیتابیس ذخیره(Write) میکند، همان هم داده را برای کاربر میخواند(Read). تا زمانی که سیستم ساده است، این روش درست کار میکند. اما وقتی منطق نرمافزار پیچیده شود، دچار مشکل میشویم.
مثلا در زمان نوشتن سیستم، باید قوانین سفتوسخت تجاری را چک کند (مثلاً اعتبارسنجیها قبل از ثبت یک سفارش). و در زمان خواندن سیستم، اصلاً کاری به قوانین ندارد؛ فقط میخواهد دادهها را از چند جای مختلف ترکیب کند و در سریعترین زمان ممکن، به فرانتاند بفرستد.
اصرار بر استفاده از یک مدل مشترک، برای این دو نیاز متفاوت، باعث تولید کدهای درهمتنیده و کاهش Performance میشود. الگوی CQRS، این مشکل را با جدا کردن فیزیکی یا منطقیِ این دو بخش حل میکند:
بخش Command یا دستورات: صرفا مسئول نوشتن و تغییر وضعیت است. اینجا تمام قوانین کسبوکار با دقت اجرا میشوند.
بخش Query: فقط مسئول خواندن است.
در دنیای واقعی، کاربران، صدهابار یک صفحه را میبینند(Read)، اما شاید فقط یک بار روی دکمه ثبت(Write) کلیک کنند. با این جداسازی، میتوان سرورها و منابع بخش خواندن را، کاملا مستقل از بخش نوشتن افزایش داد(Independent Scaling).
شبنم جلیل پور : • مفهوم نهم: Event-Driven Architecture
عموما در سیستمها، سرویسها مستقیما با هم صحبت میکنند. مثلاً وقتی کاربری خریدی انجام میدهد، سرویس سفارش، مستقیما یک API Call به سرویس انبار میزند و منتظر میماند تا انبار تایید کند. اما این دو سرویس به شدت به هم گره خوردهاند(Tight Coupling). اگر سرویس انبار قطع شود یا کند کار کند، سرویس سفارش هم از کار میافتد. برای رفع این مشکل از معماری رویداد محور یا EDA استفاده میکنیم.
معماری رویدادمحور، از رویدادها(Events) برای ارتباط بین سرویسهای مستقل و مجزا (Decoupled) استفاده میکند.
رویدادها، تغییرات یا بروزرسانیِ وضعیت در سیستم را نشان میدهند. مثلا وقتی کاربر بخواهد در یک سیستم فروشگاهی، کالایی را در سبد خرید خود اضافه کند، دو نوع رویداد شکل میگیرد:
رویدادی که دادههای وضعیت را دارد: مثل مشخصات کالای خریداریشده، قیمت و آدرس ارسال؛
و رویدادی که شامل شناسه یا اعلان است: مثلاً اعلانی که میگوید «یک سفارش ارسال شد».
درواقع در معماری رویدادمحور، ما ارتباط مستقیم سرویس ها را را حذف میکنیم و رویداد را جایگزین آن میکنیم.
این معماری، سیستم را به سه بخشِ کاملا مستقل تقسیم میکند:
تولیدکننده(Producer): سرویس سفارش، کار خودش را میکند و فقط میگوید «یک سفارش ثبت شد!». او اصلا نمیداند چه کسی قرار است این پیام را بخواند و منتظر هیچ جوابی هم نمیماند.
واسطه(Broker / Event Router): یک سیستم مرکزی(مثل Kafka یا RabbitMQ)، که پیامها را دریافت کرده و در صفهای مشخص نگه میدارد.
مصرفکننده(Consumer): سرویسهایی مثل انبار، ارسال ایمیل یا حسابداری، همگی به این واسطه گوش میدهند. به محض اینکه رویداد ثبت سفارش را دیدند، آن را برمیدارند و کار خودشان را در پسزمینه انجام میدهند.
شبنم جلیل پور : • مفهوم دهم: Serverless Architecture
معماری Serverless، به این معنا نیست که در سیستم هیچ سروری وجود نداشته باشد؛ بلکه این ایده را دنبال میکند که مدیریت سرور، دیگر دغدغه ما نیست.
برای درک بهتر، آن را با روش سنتی مقایسه کنیم:
در معماری سنتی، شما یک سرور اجاره میکنید. وظیفه تامین امنیت، آپدیت سیستمعامل و مدیریت منابع با شماست. مهمتر از همه، چه نرمافزار شما، در طول روز کاربر داشته باشد و چه نداشته باشد، شما باید هزینه ۲۴ ساعتهی روشن بودن آن سرور را پرداخت کنید.
در رویکرد Serverless (مثل سرویس AWS Lambda)، شما فقط کدهای منطق تجاری خود را مینویسید و در پلتفرم ابری قرار میدهید. ارائهدهنده ابری، تمام زیرساختها را در پسزمینه مدیریت میکند.
این معماری دو ویژگی مهم دارد:
پرداخت به ازای مصرف(Pay-as-you-go): کد شما در حالت عادی غیرفعال است. فقط زمانی که یک رویداد مثلا درخواست کاربر رخ دهد، پلتفرم ابری منابع را به کد اختصاص داده و آن را اجرا میکند. شما فقط هزینه همان چند میلیثانیه پردازش را میدهید؛ اگر درخواستی نباشد، هزینهای هم نیست.
مقیاسپذیری خودکار و بینهایت(Auto-scaling): اگر ترافیک سیستم، ناگهان زیاد شود، زیرساخت ابری به صورت خودکار هزاران نمونه از کد شما را همزمان اجرا میکند تا سیستم دچار اختلال نشود و پس از پایان ترافیک، دوباره آنها را خاموش میکند.
در معماری Serverless، تیم توسعهدهنده، تمام زمان خود را صرف خلق ارزش و نوشتن کد میکند و قرار نیست درگیر تنظیمات فیزیکی یا مجازیِ زیرساخت شود.