من خیلی جا ها که برای پیاده سازی کانسپت اجایل و چارچوب هایی مثل اسکرام و کانبان با یه صورات کلی فرایند های اجایل حضور داشتم همیشه بحث استیمیت و لاگ تایم زدن و بحث های همیشگی نحوه تخمین دادن و تکنیک هاش بوده و الان هم توی کامینیتی های اجایل همیشه این بحثه باز هست و داغ. اما اگه سوال واقعی تر توی سازمان یا اون تیم این بوده که چقدر به گرفتن دیتا از توسعه دهنده ها و تیم لید هاشون متعهدیم یا بهتر بگم چقدر میشه انتظار داشت که افراد تیم دیتا های آپدیت شده مثل لاگ تایم ، میزان پیشرفت کار ها و ایستیمیشن ها رو وارد کنن تا واقعا به سمت Evidence Based تحلیل اسکوپ کاری بریم چی؟و از مسائل قبلی عبور کرده باشیم چی؟
. من بعد از مدت ها با تیمی در زمینه اجایل و پیاده سازی جیرا همکاری کردم که این موضوع خیلی جدی توش دنبال میشد و تمامی پرفورمنس تیم بر اساس دیتای وارد شده در ابزار سنجیده میشد و بعد از حدود 6 ماه به صورت یک کالچر غالب دراومده بود و تمامی اون صحبت هایی که توی خیلی از تیم ها میشنیدم که چقدر وقت مارو میگیرن با دیتا وارد کردن از بین رفته بود. من نشانه هایی از قهری بودن دیتا اینتری نمیدیدم و همگی به درک درستی از Visual بودن دیتا رسیده بودن.
اما مشکل وقتی جدی میشه که میخوای از این دادهها برای مدیریت مبتنی بر شواهد (Evidence-Based Management) استفاده کنی.
من توی یک پروژه واقعی با چند محصول و چند تیم فنی این موضوع رو جدی دنبال کردم. بعد از حدود ۶ ماه، چیزی که اول به نظر میرسید «بار اضافی» باشه، تبدیل شد به یک فرهنگ غالب تیمی. هیچکس حس نمیکرد دیتا اینتری اجبار یا قهره، بلکه همه فهمیده بودن که ویژوال بودن دیتا = شفافیت و تصمیمگیری بهتر.
۳ چالش اصلی
ما ۴ محصول و ۵ تیم داشتیم. اگر برای هر تیم پروژه جدا درست میکردیم، خیلی زود به آشفتگی میرسیدیم. راهحل:
هر محصول = یک پروژه
هر تیم = یک برد اسکرام + یک برد کانبان
یک Custom Field به اسم Team: فقط یکبار استوری رو در پروژه محصول خودش ثبت میکرد و با انتخاب تیم، همون استوری روی برد تیم مربوطه هم ظاهر میشد.
اینجا نقطه عطف ما بود. سه لایه داده تعریف کردیم:
تخمین با Story Point
ثبت روزانهی Log Time
ثبت Manual Progress توسط تیم لید
این سه لایه باعث شد بتونیم پیشرفت واقعی رو با پیشبینیها مقایسه کنیم.
ما علاوه بر Sprint، یک مفهوم به اسم Roadmap تعریف کردیم: بازههای زمانی بلندتر (مثلاً یک فصل) که روی Epicهای چند تیمی متمرکز میشد.
اینطوری علاوه بر مدیریت کوتاهمدت اسپرینت، تصویر کلان سهماهه هم داشتیم.
محاسبات سفارشی با ScriptRunner
برای این کار هیچ پلاگین آمادهای مثل BigPicture یا Advanced Roadmaps استفاده نکردیم. همهچیز با اسکریپتنویسی ScriptRunner روی خود Jira Issue ساخته شد.
ما پروژه ای مجزا داشتیم که توش میتونستیم رود مپ مربوط به هر بازه و تیم رو بسازیم با استفاده از دیتا هی کاستوم شده مربوط به همان تیم و در حقیقت بازه زمانی و ظرفیت تیم. بعد به صورت اتومات محاسبات انجام میشد
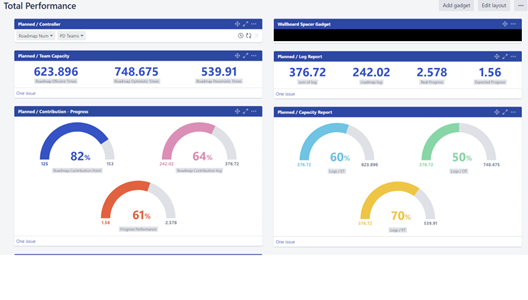
یکی از ارزشمندترین بخشها برای ما این بود که بتونیم ظرفیت واقعی تیمها رو هم بر اساس لاگ تایم و دادههای استوری پوینت اندازه بگیریم. برای همین سه متریک جدید تعریف کردیم:
Roadmap Efficient Times: 623.896 → زمان کارآمدی واقعی بر اساس لاگ تایم و پیشرفت کار.
Roadmap Optimistic Times: 748.675 → ظرفیت خوشبینانه (اگر همه افراد با حداکثر توان کار کنن).
Roadmap Pessimistic Times: 539.91 → ظرفیت بدبینانه (اگر وقفهها و کارهای غیرمنتظره زیاد باشه).
📊 با این سه شاخص میشد خیلی ساده ببینیم:
اگر با سرعت معمولی ادامه بدیم، چقدر زمان لازم داریم.
اگر تیم در شرایط ایدهآل کار کنه، زودترین زمان اتمام چقدره.
و اگر مشکلات زیادی پیش بیاد، چه تاخیری محتمل خواهد بود.
این دادهها به Product Ownerها و مدیرها کمک کرد که خیلی واقعبینانهتر برنامهریزی کنن. مثلاً وقتی یک Epic بزرگ به ۷۴۸ ساعت نیاز داشت ولی ظرفیت بدبینانه تیم فقط ۵۴۰ ساعت بود، تصمیمگیری درباره جابجایی اولویتها یا اضافه کردن نیرو خیلی سریعتر اتفاق میافتاد.
sum of log: 376.72
roadmap log: 242.02
Average Manual Progress: 34.33
Roadmap Manual Progress: 30.28
Expected Progress: 1.56
Real Progress: 2.578
Sum Story Points: 153
Logged Story Point: 125
SP Progress: 52.525
Logged SP Progress: 29.35
این مقادیر مستقیم روی Custom Fieldهای Issue ذخیره میشدن و بعد روی داشبورد قابل گزارشگیری بودن.
import com.atlassian.jira.component.ComponentAccessor
import com.atlassian.jira.issue.MutableIssue
import com.atlassian.jira.bc.issue.search.SearchService
import com.atlassian.jira.web.bean.PagerFilter
def cfm = ComponentAccessor.customFieldManager
def searchService = ComponentAccessor.getComponent(SearchService)
def user = ComponentAccessor.jiraAuthenticationContext.loggedInUser
final String SP_CF_NAME = "Story Points"
final String MANUAL_PROGRESS_CF = "Manual Progress"
final String OUTPUT_AVG_CF_NAME = "Average Manual Progress"
final String OUTPUT_SP_PROGRESS_CF_NAME = "SP Progress"
def cfSP = cfm.getCustomFieldObjectByName(SP_CF_NAME)
def cfManual = cfm.getCustomFieldObjectByName(MANUAL_PROGRESS_CF)
def cfOutputAvg = cfm.getCustomFieldObjectByName(OUTPUT_AVG_CF_NAME)
def cfOutputSP = cfm.getCustomFieldObjectByName(OUTPUT_SP_PROGRESS_CF_NAME)
def issue = issue as MutableIssue
def jql = "project = ${issue.projectObject.key} AND 'Roadmap Num' ~ '${issue.getCustomFieldValue(cfm.getCustomFieldObjectByName("Roadmap Num"))}'"
def parseResult = searchService.parseQuery(user, jql)
def searchResult = searchService.search(user, parseResult.query, PagerFilter.getUnlimitedFilter())
def issues = searchResult.issues
double totalSP = 0
double loggedSP = 0
double totalManual = 0
int countManual = 0
issues.each { i ->
def sp = i.getCustomFieldValue(cfSP) as Double ?: 0
totalSP += sp
if ((i.getTimeSpent() ?: 0) > 0) loggedSP += sp
def mp = i.getCustomFieldValue(cfManual) as Double ?: 0
if (mp > 0) {
totalManual += mp
countManual++
}
}
def avgManual = countManual > 0 ? (totalManual / countManual) : 0
def spProgress = totalSP > 0 ? (loggedSP / totalSP) * 100 : 0
issue.setCustomFieldValue(cfOutputAvg, avgManual)
issue.setCustomFieldValue(cfOutputSP, spProgress)
مثال واقعی: توسعهی API پرداخت
یک Epic در محصول B داشتیم: توسعهی سرویس پرداخت.
Backend Team: پیادهسازی endpoint /api/v2/payment/transaction (POST + JSON شامل token, amount, callback).
Mobile Team: مصرف API در اپ اندروید، طراحی UI موفق/ناموفق و هندلینگ خطا.
قبلاً این یعنی چندین تیکت جدا در پروژههای مختلف.
ولی اینجا با ساختار جدید: یک استوری در پروژه محصول B + Sub-task با Team=Backend و Team=Mobile.
📌 نتیجه:
PO محصول B یک فیچر کامل رو end-to-end میدید.
تیم موبایل (که روی همه محصولات سرویس میداد) فقط برد خودش رو نگاه میکرد و همه کارها جمع بود.
داشبورد Roadmap دقیقاً درصد پیشرفت واقعی vs انتظار رو نشون میداد.
داشبوردهای تحلیلی با Rich Filter
آخرین بخش کار ما Visualization بود. فقط محاسبات کافی نبود، باید همه بتونن ببینن و تحلیل کنن.
فیلترهای دینامیک: Roadmap Num، Sprint، Priority، Project، Status.
امکان Drill Down روی هر بُعد.
ویجتهای متنوع برای مقایسهی Story Point و زمان صرفشده.
Story Point per Assignee: سهم هر فرد از Story Pointها. کمک کرد بار کاری متعادلتر بشه.
Time Spent per Assignee: نشون داد چه کسی واقعاً وقت گذاشته. جلوی mismatch بین تخمین و لاگ گرفته شد.
Story Point per Project: سهم تیمها بین محصولات مختلف مشخص شد. POها دیدن چه مقدار از ظرفیتشون روی کدوم پروژه مصرف میشه.
Filterهای سریع: امکان بررسی فقط High Priority، یا فقط Sprint جاری، یا فقط Roadmap خاص.
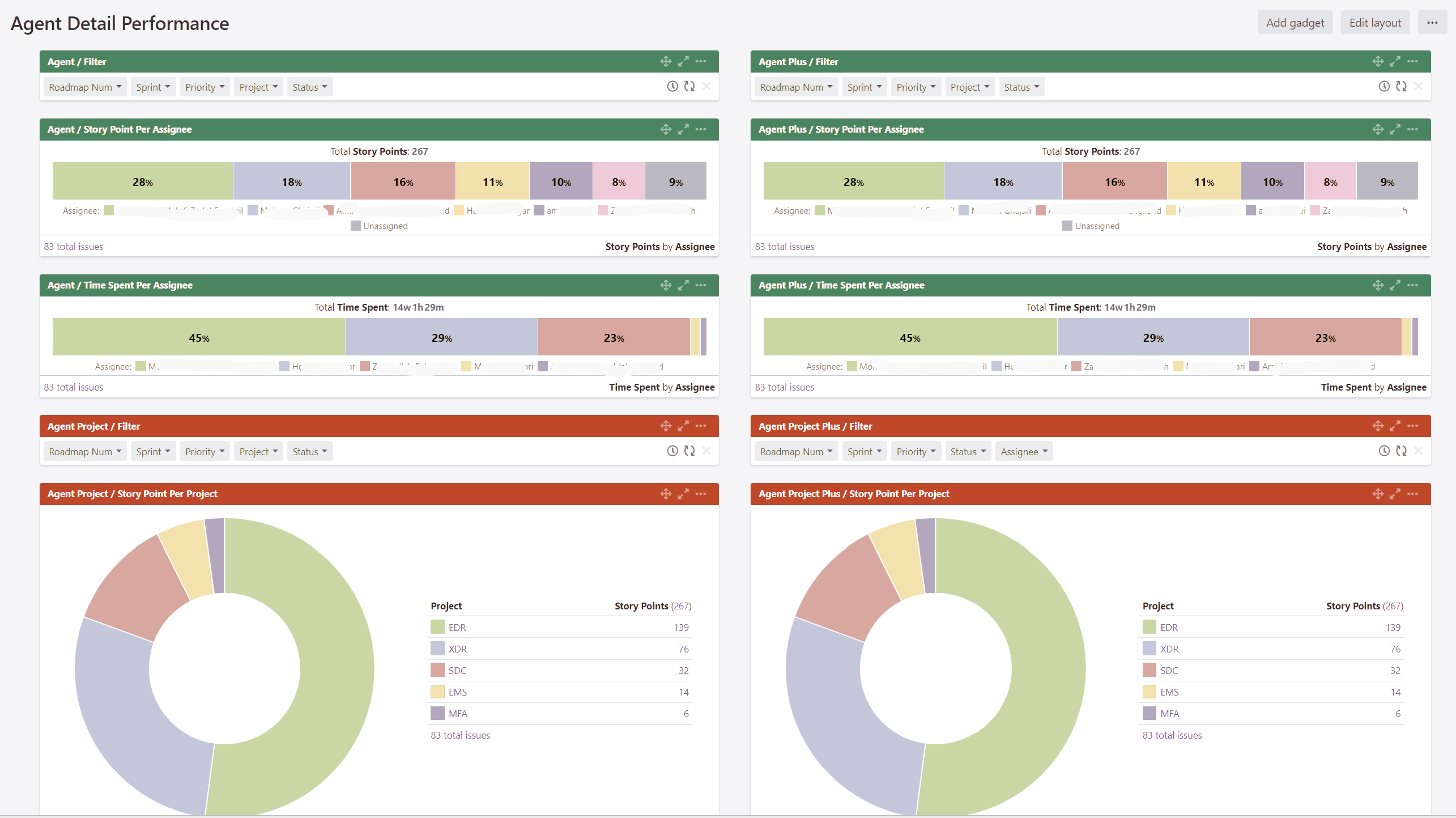
📊 نتیجه این شد که دادهها از سطح «گزارش به مدیریت» بالاتر رفت و تبدیل شد به ابزاری برای تصمیمگیری روزانه و مدیریت بار کاری تیم.
نتیجهگیری
بعد از ۶ ماه، این مدل برای ما یک Best Practice واقعی شد:
Product-centric projects
Team-centric boards
Scripted Metrics به جای پلاگینهای سنگین
Rich Filter Dashboards برای تحلیل
و از همه مهمتر: تغییر فرهنگ تیمی. دیتا اینتری از یک کار خستهکننده تبدیل شد به ابزاری برای شفافیت و مدیریت. هم تیمها راضی بودن، هم POها تصویر کلان داشتن، هم لیدها دادهی واقعی برای تصمیمگیری داشتن.
👉 حالا سؤال من برای شما: توی تیمتون چقدر به دادهی واقعی متعهدید؟ و آیا حاضرید به جای بحثهای بیپایان تخمین، یک بار برای همیشه ساختار و فرهنگ دیتا اینتری رو درست کنید؟