وقتی یک سیستم کوچک است، پیدا کردن خطا معمولاً کار پیچیدهای نیست.
یک درخواست به سرور ارسال میشود، چند کوئری به دیتابیس اجرا میشود و نتیجه به کاربر برمیگردد. اگر مشکلی وجود داشته باشد، معمولاً با چند لاگ یا بررسی ساده میتوان دلیل آن را پیدا کرد.
اما با بزرگتر شدن سیستمها، داستان کاملاً تغییر میکند.
امروزه بسیاری از تیمها از معماری Microservice استفاده میکنند. هر درخواست ممکن است از چندین سرویس مختلف عبور کند، به دیتابیس متصل شود، با سرویسهای شخص ثالث ارتباط برقرار کند و در نهایت نتیجه را به کاربر برگرداند.
در چنین شرایطی وقتی کاربر میگوید:
«سایت کند شده»
یا
«پرداخت انجام نمیشود»
یا
«بعضی کاربران با خطا مواجه میشوند»
پیدا کردن دلیل اصلی مشکل دیگر ساده نیست.
بسیاری از تیمها هنگام بروز مشکل سراغ لاگها میروند.
لاگها اطلاعات ارزشمندی هستند، اما یک محدودیت مهم دارند:
آنها فقط اتفاقات را ثبت میکنند، نه ارتباط بین اتفاقات را.
فرض کنید یک درخواست برای پرداخت وارد سیستم میشود.
این درخواست:
از API Gateway عبور میکند
به سرویس احراز هویت میرسد
موجودی کاربر را بررسی میکند
با سرویس پرداخت ارتباط میگیرد
نتیجه را ذخیره میکند
حالا اگر این فرآیند به جای ۵۰۰ میلیثانیه، ۴ ثانیه طول بکشد، از روی لاگها همیشه مشخص نیست تأخیر دقیقاً در کدام مرحله ایجاد شده است.
بسیاری از تیمها از ابزارهای مانیتورینگ استفاده میکنند.
آنها میتوانند نشان دهند:
مصرف CPU افزایش پیدا کرده
حافظه بیشتر استفاده شده
تعداد خطاها بالا رفته
اما معمولاً نمیتوانند پاسخ دهند:
«کدام درخواست؟»
«کدام سرویس؟»
«کدام تابع؟»
«کدام کاربر؟»
در واقع Metrics به شما میگوید مشکلی وجود دارد، اما لزوماً دلیل آن را مشخص نمیکند.
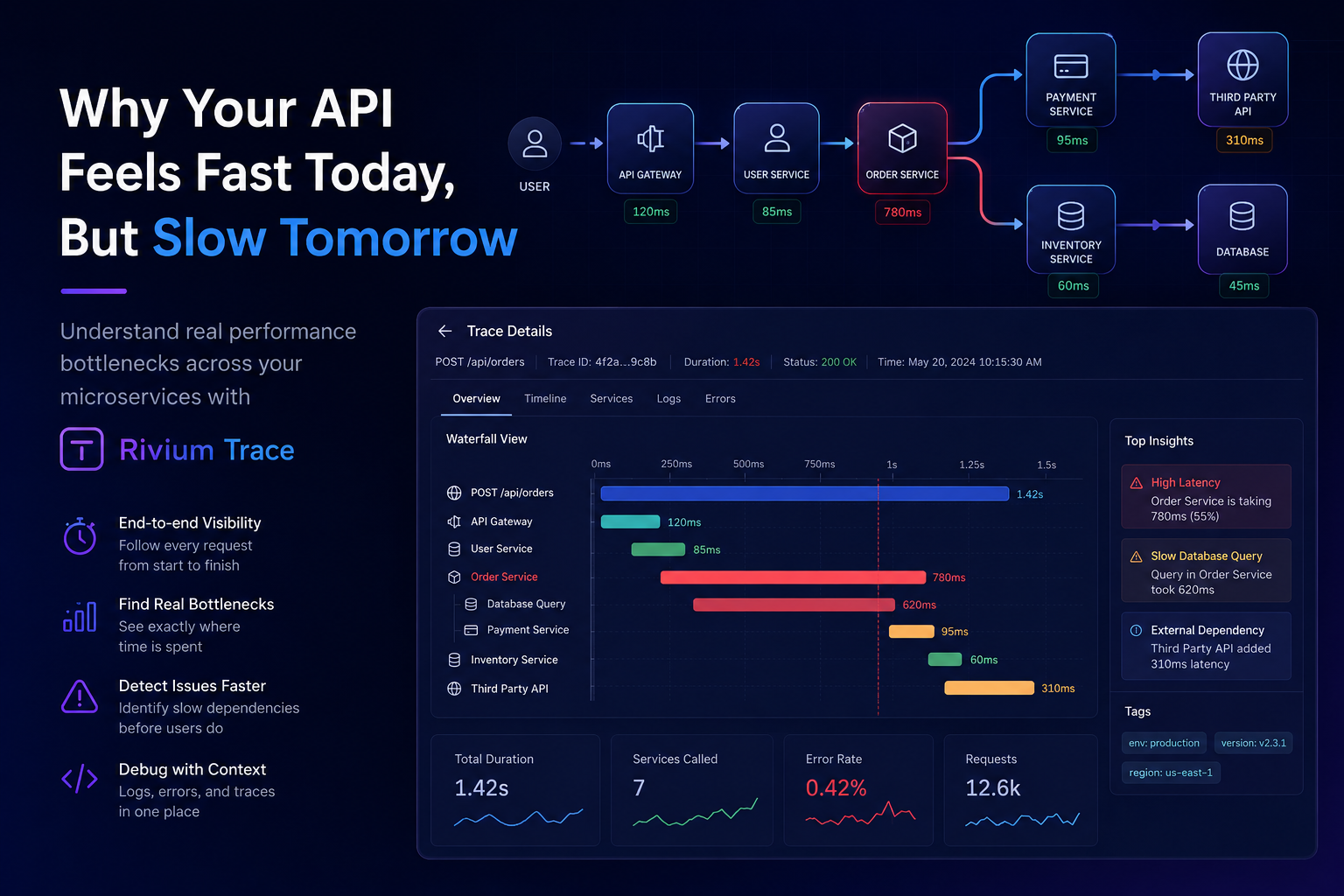
Distributed Tracing برای حل همین مسئله به وجود آمده است.
به جای اینکه فقط لاگ یا متریک جمعآوری شود، مسیر کامل یک درخواست در سیستم ثبت میشود.
در نتیجه میتوان مشاهده کرد:
درخواست از کجا شروع شده است
از چه سرویسهایی عبور کرده است
هر سرویس چه مدت زمان پردازش داشته است
خطا دقیقاً در کدام بخش رخ داده است
به جای حدس زدن، تیم میتواند مسیر واقعی درخواست را مشاهده کند.
فرض کنید کاربران گزارش میدهند که فرآیند پرداخت بسیار کند شده است.
هیچ خطایی ثبت نشده.
CPU و RAM نیز وضعیت طبیعی دارند.
در نگاه اول همه چیز سالم به نظر میرسد.
اما با بررسی Trace مشخص میشود:
سرویس پرداخت ۱۲۰ میلیثانیه زمان مصرف کرده
سرویس احراز هویت ۸۰ میلیثانیه زمان مصرف کرده
اما یک API خارجی بیش از ۳ ثانیه تأخیر داشته است
در این حالت تیم ظرف چند دقیقه علت اصلی مشکل را پیدا میکند؛ در حالی که بدون Trace ممکن بود ساعتها زمان صرف بررسی لاگها شود.
بسیاری از ابزارهای Observability مطرح دنیا برای شرکتهای ایرانی چالشهایی ایجاد میکنند:
هزینه دلاری
محدودیتهای دسترسی
پیچیدگی در راهاندازی
نیاز به زیرساختهای جانبی متعدد
در نتیجه بسیاری از تیمها یا اصلاً از این ابزارها استفاده نمیکنند یا تنها بخش کوچکی از قابلیتهای آنها را به کار میگیرند.
در حالی که با رشد سیستمها، نیاز به مشاهدهپذیری (Observability) دیگر یک قابلیت دور از دسترس نیست؛ بلکه بخشی ضروری از فرآیند توسعه و نگهداری نرمافزار محسوب میشود.
هرچه سیستمها بزرگتر میشوند، پیدا کردن علت اصلی مشکلات دشوارتر میشود.
لاگها مهم هستند.
متریکها مهم هستند.
اما زمانی که بخواهیم دقیقاً بفهمیم یک درخواست چه مسیری را طی کرده و دلیل واقعی کندی یا خطا چیست، Distributed Tracing به یکی از مهمترین ابزارهای تیمهای فنی تبدیل میشود.
سؤال دیگر این نیست که «آیا سیستم ما مشکل دارد؟»
سؤال این است که «چقدر سریع میتوانیم علت واقعی آن را پیدا کنیم؟»