استانداردسازی دادهها , تبدیل و اعتبارسنجی مراحل مهمی در فرآیند پیشپردازش دادهها هستند . استانداردسازی دادهها فرآیند تبدیل سیستماتیک اطلاعات جمعآوریشده به فرمت سازگار و قابل مدیریت است . این روش شامل حذف تناقضات , خطاها و duplicates و همچنین تبدیل دادهها از منابع مختلف به فرمت یکپارچه است که اغلب به صورت نرمال ( که در بخش بعدی تعریف میشود ) نامیده میشود . تبدیل دادهها شامل اصلاح دادهها برای بهتر کردن آن برای تحلیل برنامهریزیشده است . اعتبار سنجی دادهها تضمین میکند که دادهها دقیق و سازگار بوده و با معیارها یا استانداردهای خاصی مطابقت دارند .
نرمال سازی داده ها (Data normalization)
اولین گام در استاندارد کردن دادهها ایجاد دستورالعملها و قوانین برای قالببندی و ساختاربندی دادهها است . این امر ممکن است شامل تعیین قراردادهای نامگذاری , انواع دادهها و قالببندی یک شکل نرمال ( NF) , یک راهنما یا مجموعهای از قوانین مورد استفاده در طراحی پایگاهداده باشد تا اطمینان حاصل شود که پایگاهداده بهخوبی ساختاریافته , سازمانیافته , و عاری از انواع خاصی از پیچیدگی است . رایجترین شکلهای طبیعی مورد استفاده عبارتند از : 1NF، 2NF، 3NF ( شکل اول , دوم و سوم نرمال ) و BCNF ( شکل نرمال بویس - Codd ) هستند.
نرمال سازی ، فرآیند اعمال این قوانین به پایگاهداده است . دادهها باید مرتب و تمیز شوند که شامل حذف دادههای تکراری و نادرست , پر کردن مقادیر گمشده و مرتب کردن منطقی دادهها است . برای پشتیبانی از استانداردسازی دادهها , اقدامات کنترل کیفیت منظم باید اجرا شوند , از جمله ممیزیهای دادههای دورهای برای تعیین صحت و سازگاری دادهها . همچنین مستندسازی فرآیند استانداردسازی از جمله دستورالعملها و رویههای دنبال شده مهم است . بازبینی و بهروزرسانی دورهای استانداردهای داده برای اطمینان از قابلیت اطمینان و ارتباط مداوم دادهها ضروری است .
نرمال سازی دادهها تضمین میکند که دادهها بدون توجه به منبع آن قابل نگه داری هستند . یک تیم بازاریابی را در نظر بگیرید که اطلاعات مربوط به رفتار خرید مشتریان خود را جمعآوری میکند تا آنها بتوانند در مورد محل قرارگیری محصول تصمیمگیری کنند . دادهها از منابع متعددی مانند تراکنش های فروش آنلاین , خریدهای داخل فروشگاه و نظرسنجیهای فیدبک مشتری جمعآوری میشوند . این دادهها به صورت خام میتوانند نامنظم و غیرقابلاعتماد باشند و تحلیل آن را دشوار میسازد . ترسیم بینشهای معنادار از دادههای بد سازمانیافته دشوار است .
برای نرمال کردن این دادهها , تیم بازاریابی چندین مرحله را طی میکند . ابتدا , آنها عناصر کلیدی داده مانند نام مشتری , محصول خریداریشده و تاریخ مبادله را شناسایی میکنند . سپس , آنها اطمینان حاصل میکنند که این عناصر به طور مداوم در تمام منابع داده قالببندی میشوند. برای مثال , آنها ممکن است از یک فرمت تاریخی مشابه در تمام منابع داده استفاده کنند یا نام مشتری را به نام اول و آخرین نام فیلدز استاندارد کنند . سپس , آنها هر عنصر دادهای اضافی یا بیربط را حذف خواهند کرد . در این مورد , اگر دادهها از خریدهای آنلاین و در فروشگاه جمعآوری شوند , ممکن است یکی یا دیگری را برای اجتناب از تکرار انتخاب کنند . تیم بازاریابی تضمین میکند که دادهها به درستی ساختاردهی و سازماندهی شدهاند . این میتواند شامل ایجاد یک جدول داده با دامنه برای هر عنصر داده , مانند شناسه مشتری , کد محصول و مقدار خرید باشد . با نرمال کردن دادهها , تیم بازاریابی میتواند به طور موثر رفتار خرید مشتریان , شناسایی الگوها و روندها را دنبال کرده و قضاوتهای مبتنی بر داده را برای افزایش سیستمهای بازاریابی خود انجام دهد .
فرمول نرمال سازی یک فرمول آماری است که برای اندازهگیری یک مجموعه داده استفاده میشود که معمولا بین یک و صفر است . بزرگترین داده دارای یک مقدار نرمال است و کوچکترین نقطه داده صفر خواهد بود . توجه داشته باشید که وجود دادههای پرت میتواند تاثیر قابلتوجهی بر مقادیر محاسبهشده حداقل / حداکثر داشته باشد . بدین ترتیب , حذف هر داده پرت از مجموعه دادهها قبل از انجام نرمال سازی مهم است . این امر نتایج دقیقتر و نماینده را تضمین میکند .
فرمول نرمال سازی :
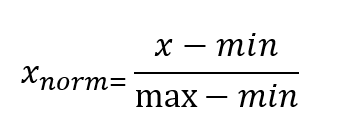
مسئله :
یک شرکت خردهفروشی با هشت شعبه میخواهد فروش محصول خود را تحلیل کند تا اقلام فروش بالا را شناسایی کند . شرکت دادهها را از هر شعبه جمعآوری میکند و در جدول ذخیره میکند و فروش و سود هر محصول را فهرست میکند . از گزارشهای قبلی , کشف شدهاست که محصولات فروش بالای آن جواهرات , لوازم جانبی تلویزیون , محصولات زیبایی , دی وی دی , اسباببازیهای کودکان , بازیهای ویدیویی , پوشاک بوتیک زنان و طراح و عینک آفتابی مد هستند . با این حال , شرکت میخواهد این محصولات را براساس بهترین فروش و سود از بالاترین تا پایینترین ترتیب دهد . تعیین کنید کدام محصول فروش بالا با نرمال کردن دادهها در جدول است .

راه حل :
با استفاده از فرمول نرمال سازی , حداکثر فروش 55,000 دلار و حداقل فروش 15,000 دلار است , همانطور که در آن نشانداده شدهاست .

به طور کلی , محصولات فروش برتر شرکت خردهفروشی بیشترین سود را برای شرکت تولید میکنند و " عینک آفتابی طراح و مد " بیشترین سود را در مقیاس نرمال سازی دارند . شرکت میتواند از این اطلاعات برای تمرکز بر ارتقا و بازسازی این اقلام در هر شعبه برای ادامه فروش و سود استفاده کند .
تبدیل داده ها (Data transformation )
تبدیل دادهها یک تکنیک آماری است که برای اصلاح ساختار اصلی دادهها به کار میرود تا آن را برای تحلیل مناسبتر کند . تبدیل دادهها میتواند شامل عملیاتهای ریاضی مختلفی مانند لگاریتمی , ریشه دوم یا تبدیلات نمایی باشد . یکی از دلایل اصلی تبدیل دادهها , پرداختن به مسائل مربوط به فرضیات آماری است . برای مثال , برخی مدلهای آماری فرض میکنند که دادهها معمولا توزیع میشوند . اگر دادهها بهطور معمول توزیع نشوند , این امر میتواند منجر به نتایج و تفاسیر نادرست شود . در چنین مواردی تبدیل دادهها میتواند به نزدیکتر کردن آن به توزیع نرمال و بهبود دقت تحلیل کمک کند .
یکی از روشهای رایج تبدیل دادهها , تبدیل لگاریتمی است که نیازمند لگاریتم مقادیر دادهها است . تبدیل لگاریتمی اغلب زمانی استفاده میشود که دادهها بسیار چوله باشند , به این معنی که بیشتر نقاط داده به یک انتهای توزیع میرسند .این امر میتواند موجب مشکلاتی در تحلیل دادهها شود زیرا دادهها ممکن است از توزیع نرمال تبعیت نکنند . با استفاده از لگاریتم مقادیر , توزیع میتواند به سمت شکل متقارن تری منتقل شود و تحلیل آن را آسانتر میکند .یکی دیگر از روشهای معمول تبدیل ریشه دوم است که شامل ریشه دوم مقادیر دادهها است .همانند تبدیل لگاریتمی , تبدیل ریشه مربع اغلب برای پرداختن به مسائل چولگی و توزیع نرمال دادهها استفاده میشود .تبدیل ریشه دوم نیز زمانی مفید است که دادهها دارای مقادیر نزدیک به صفر باشند , زیرا ریشه دوم این مقادیر میتواند آنها را به بقیه دادهها نزدیکتر کرده و تاثیر مقادیر حدی را کاهش دهد .تبدیلات نمایی شامل گرفتن توان مقادیر داده است .هر عملیات مورد استفاده , تبدیل دادهها میتواند ابزاری مفید برای تحلیل گران دادهها برای پرداختن به مسائل توزیع دادهها و بهبود دقت تحلیلهای آنها باشد .


مقابله با دادههای نویزی (Dealing with Noisy Data )
دادههای نویزی به دادههایی اشاره دارند که خطاها , دادههای پرت یا اطلاعات نامربوط را حفظ میکنند که میتوانند الگوها و روابط واقعی درون مجموعه دادهها را پنهان کنند . وجود دادههای نویزی در مجموعه دادهها , موجب دشواری در ترسیم نتایج دقیق و پیشبینی از دادهها میشود . اغلب دادههای نویزی ناشی از خطاهای انسانی در ورود دادهها , خطاهای فنی در جمعآوری یا انتقال دادهها یا تغییرپذیری طبیعی در خود دادهها است . دادههای نویزی با شناسایی و تصحیح خطاها , حذف دادههای پرت و فیلتر اطلاعات نامربوط حذف و پاکسازی میشوند . دادههای نویزی میتوانند بر تحلیل و مدلسازی دادهها تاثیر منفی داشته باشند و ممکن است نشان دهند که مسائلی با ساختار یا فرضیات مدل وجود دارد . دادههای نویزی اطلاعات ناخواسته هستند که میتوانند حذف شوند .
راهکارهای کاهش دادههای نویزی شامل موارد زیر است:
پاکسازی دادهها
حذف دادههای تکراری یا نامرتبط (مثل حذف ردیفهای تکراری یا ورودیهای ناقص).
هموارسازی دادهها
حذف نویز برای آشکارسازی الگوهای اصلی (مثل میانگین متحرک ۷ روزه برای شاخص بازار سهام).
تخمین (Imputation)
تخمین دادههای گمشده بر اساس اطلاعات موجود (مثل تخمین سوابق پزشکی بیمار بر اساس شرایط و درمانهای گذشته).
دستهبندی (Binning)
گروهبندی دادهها به بازهها برای تحلیل سادهتر (مثل گروههای سنی ۱۰ ساله).
تبدیل دادهها
استفاده از تبدیلات ریاضی مانند لگاریتم برای کاهش چولگی (مثل تبدیل دادههای ۱۰۰۰، ۱۰۰۰۰، ۱۰۰۰۰۰ به ۳، ۴، ۵ با لگاریتم پایه ۱۰).
کاهش ابعاد
کاهش تعداد متغیرها با روشهایی مثل تحلیل مؤلفههای اصلی (PCA) برای شناسایی روندهای کلی.
روشهای جمعی (Ensemble Methods)
ترکیب چند مدل برای کاهش overfitting و افزایش دقت (مثل جنگل تصادفی که پیشبینی نهایی را از تجمیع درختهای تصمیم میگیرد).
اعتبار سنجی دادهها (Data Validation)
اعتبارسنجی دادهها فرآیند تضمین صحت و کیفیت دادههای مورد بررسی در برابر قوانین و استانداردهای تعریفشده است . این رویکرد شامل شناسایی و اصلاح هر گونه خطا یا ناسازگاری در دادههای جمعآوریشده و همچنین اطمینان از این است که دادهها برای تحلیل مناسب و قابلاعتماد هستند . اعتبار سنجی دادهها را میتوان از طریق روشهای مختلفی مانند چک دستی , دستورالعملهای خودکار و تحلیل آماری انجام داد . برخی از بازرسیهای معمول در اعتبارسنجی دادهها شامل بررسی مقادیر تکراری, بررسی مقادیر گمشده و تایید دادهها در مقابل منابع خارجی یا ارجاع ها است . قبل از جمعآوری دادهها , تعیین شرایط یا معیارهایی که دادهها باید برآورده شوند , مهم است . این امر میتواند شامل عواملی مانند دقت , کامل بودن , ثبات و به موقع باشد . برای مثال , یک شرکت ممکن است یک فرآیند اعتبارسنجی داده را راهاندازی کند تا اطمینان حاصل کند که تمام اطلاعات مشتری وارد پایگاهداده میشود که فرمت خاصی دارد . این کار شامل چک کردن spellings صحیح و قالببندی مناسب شمارهتلفن و آدرس دهی و اعتبار سنجی درستی نام و شماره حساب مشتری است . این دادهها همچنین در مقابل منابع خارجی مانند سوابق رسمی دولت برای تایید صحت اطلاعات بررسی میشوند . قبل از اینکه دادهها برای تحلیل یا اهداف تصمیمگیری مورد استفاده قرار گیرند , هر گونه اختلاف یا خطا برای تصحیح ثبت خواهد شد .از طریق این فرآیند اعتبارسنجی دادهها , شرکت میتواند اطمینان حاصل کند که دادههای مشتریان آن دقیق , قابلاعتماد و مطابق با استانداردهای صنعت است .
یکی دیگر از روشهای ارزیابی دادهها , استفاده از منابع معتبر برای شناسایی هرگونه اختلاف یا خطا در دادههای جمعآوریشده است . برای اعتبارسنجی دادهها از ابزارها و تکنیکهایی استفاده میشود . این موارد میتوانند شامل تحلیل آماری , نمونهگیری داده , پروفایلینگ دادهها و حسابرسی دادهها باشند . شناسایی و حذف داده های پرت قبل از اعتبارسنجی دادهها مهم است . بررسیهای منطقی شامل استفاده از عقل سلیم برای بررسی منطقی بودن دادهها و منطقی بودن آنها است - برای مثال , بررسی اینکه آیا سن یک فرد در محدوده معقول است یا اینکه درآمد یک شرکت در محدوده معقولی برای صنعت آن قرار دارد . در صورت امکان , دادهها باید با منبع تایید شوند تا صحت آن تضمین شود . این میتواند شامل تماس با فرد یا سازمانی باشد که دادهها را فراهم کرده یا بر علیه سوابق رسمی چک میکند . همیشه ایده خوبی است که چندین عضو تیم یا متخصص را در فرآیند اعتبارسنجی درگیر کنید تا هر گونه خطا و یا ناسازگاری که ممکن است توسط یک فرد نادیده گرفته شدهباشند را به دست آورید . مستندسازی فرآیند اعتبارسنجی , شامل مراحل برداشتهشده و هر مساله شناساییشده , در ممیزیهای آتی داده یا اهداف مرجع مهم است . اعتبار سنجی دادهها یک فرآیند پیوسته است و دادهها باید برای اطمینان از صحت و اعتبار آن پایش و به روز شوند .
یک شرکت بازاریابی را در نظر بگیرید که بررسی رضایت مشتری برای راهاندازی محصول جدید را انجام میدهد . این شرکت اطلاعات را از 1,000 پاسخدهنده جمعآوری کرد , اما وقتی شرکت تجزیه و تحلیل دادهها را آغاز کرد , متوجه تناقضات متعدد و مقادیر گمشده شد . تحلیل گر دادههای شرکت متوجه شد که استانداردسازی دادهها و فرآیندهای اعتبار سنجی به اندازه کافی قبل از ثبت نتایج پیمایش انجام نگرفته است . برای تصحیح این مساله , تحلیلگر داده ابتدا همه ورودیهای تکراری را شناسایی و حذف کرد و تعداد کل پاسخها را به 900 کاهش داد . سپس , آنها از متنهای خودکار برای شناسایی و پر کردن مقادیر گمشده استفاده کردند , که پاسخ را در نظر گرفتند . سپس 805 پاسخ باقیمانده برای صحت دادهها با استفاده از تحلیل آماری بررسی شد .پس از استانداردسازی دادهها و فرآیند اعتبارسنجی , شرکت دارای مجموعه دادههای تمیز و قابلاعتماد از 805 پاسخ بود . نتایج نشان داد که میزان رضایت محصول85 درصد است که به طور معنیداری بیشتر از تحلیل اولیه 78 درصد است . در نتیجه این اصلاح , تیم بازاریابی توانست با اطمینان نرخ رضایت واقعی را گزارش کند و تصمیمات آگاهانه تری برای توسعه محصول آینده اتخاذ کند .
تجمیع دادهها (Data Aggregation)
تجمیع دادهها فرآیندی است که با آن اطلاعات از چندین مبدا جمعآوری و در یک مجموعه واحد ادغام میشوند که بینش و نتایج معناداری را فراهم میکند . این برنامه شامل جمعآوری , مدیریت و تحویل دادهها از منابع مختلف به شیوهای ساختاریافته برای تسهیل تحلیل و تصمیمگیری است . تجمیع دادهها را میتوان بهصورت دستی یا با استفاده از ابزارها و تکنیکهای خودکار انجام داد . از فرآیند تجمیع دادهها برای شناسایی الگوها و روندهای بین نقاط مختلف دادهها استفاده میشود که بینشهای ارزشمندی را استخراج میکند . برخی از انواع استاندارد تجمیع دادهها تجمیع مکانی , تجمیع آماری , تجمیع خصوصیت و تجمیع زمانی هستند . این روش معمولا در بازاریابی , تامین مالی , بهداشت و درمان و تحقیق برای تجزیه و تحلیل مجموعه بزرگی از دادهها عمل میکند . از تجمیع دادهها در صنایع مختلف برای ترکیب و تحلیل مجموعه بزرگی از دادهها استفاده میشود . مثالها شامل محاسبه کل فروش برای یک شرکت از بخشهای مختلف , تعیین متوسط دمای یک منطقه شامل چندین شهر و تحلیل ترافیک وب سایت توسط کشور است . همچنین در زمینههایی مانند شاخصهای بازار سهام , رشد جمعیت , نمرات رضایت مشتری , امتیازات اعتباری و تاخیر پرواز خطوط هوایی نیز استفاده میشود . دولتها و شرکتهای سودمند نیز از تجمیع دادهها برای مطالعه الگوهای مصرف انرژی استفاده میکنند .