داده و مجموعه داده ( Datasets)
در دنیای امروز، علم داده (Data Science) نقش بسیار مهمی ایفا میکند. علم داده به ما امکان میدهد تا از دادهها بینش و دانش استخراج کنیم و بر اساس آنها تصمیمگیری و نوآوری را در حوزههایی مانند کسبوکار، سلامت، سرگرمی و بسیاری زمینههای دیگر هدایت کنیم. همانطور که در مطالب قبل گفتم، این حوزه ریشه در ریاضیات، آمار و علوم کامپیوتر دارد، اما تنها از اوایل دهه ۲۰۰۰ و همزمان با گسترش دادههای دیجیتال و پیشرفت توان محاسباتی و فناوری، بهعنوان یک رشته مستقل شکل گرفت.
علم داده در اواسط تا اواخر دهه ۲۰۰۰، با ظهور کلانداده (Big Data) و نیاز به روشهای پیشرفته برای تحلیل و استخراج بینش از مجموعهدادههای بزرگ و پیچیده، رشد و توجه گستردهای پیدا کرد. از آن زمان تاکنون، روند تکامل آن بسیار سریع بوده است و همانطور که از مباحث قبلی مشخص است، این حوزه بهسرعت در حال تبدیل شدن به یکی از ارکان اصلی بسیاری از صنایع و حوزههاست.
البته خودِ داده پدیدهای جدید نیست. انسانها از آغاز تاریخ در حال جمعآوری داده و تولید مجموعهداده بودهاند. این روند از دوران سنگ ( عصر حجر ) آغاز شد؛ زمانی که انسانها نقشها و تصاویر سادهای به نام سنگنگارهها (Petroglyphs) را روی سنگها حک میکردند. این سنگنگارهها اطلاعات ارزشمندی درباره شکل ظاهری حیوانات و شیوه زندگی روزمره آنها در اختیار ما قرار میدهند که برای ما نوعی «داده» محسوب میشود.
مصریان باستان نخستین شکل کاغذ، یعنی پاپیروس را ابداع کردند تا دادههای خود را ثبت کنند. پاپیروس همچنین ذخیرهسازی حجم زیادی از دادهها را آسانتر کرد؛ از جمله فهرست کردن موجودیها، ثبت تراکنشهای مالی و ثبت داستانها برای انتقال به نسلهای آینده.
داده (Data)
کلمه «Data» جمعِ واژه لاتین “datum” است که به معنای «چیزی که داده شده یا استفاده میشود» است و معمولاً به یک مقدار واحد اطلاعات یا یک نقطه مرجع در یک مجموعهداده اشاره دارد.
وقتی کلمه «داده» را میشنویم، اغلب ذهنمان به سمت اعداد میرود و درست است که اعداد معمولاً داده محسوب میشوند، اما دادهها فقط اعداد نیستند. هر چیزی که بتوانیم آن را تحلیل کنیم و از آن اطلاعات و بینشهای مفید استخراج کنیم، در واقع داده است.
.سوال : فرض کنید در حال تصمیمگیری هستید که آیا ترم بعد یک درس خاص را بردارید یا نه. روند تصمیمگیری شما احتمالاً به این شکل خواهد بود:
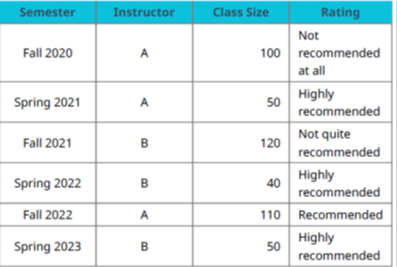
ابتدا ممکن است نظرسنجیهای دوره را بررسی کنید، مانند آنچه در جدول بالا نشان داده شده است. این جدول شامل چهار نوع داده است که بهصورت ستونها دستهبندی شدهاند: نیمسال (Semester)، مدرس (Instructor)، اندازه کلاس (Class Size) و امتیازدهی Rating) . در هر ستون، شش مقدار داده متفاوت وجود دارد، یکی در هر سطر. برای مثال، در ستون نیمسال شش مقدار متنی داریم: «Fall 2020»، «Spring 2021»، «Fall 2021»، «Spring 2022»، «Fall 2022» و «Spring 2023».
خودِ امتیازدهیها ( Rating ) به تنهایی به شما نمیگویند که آیا باید درس را ترم بعد بردارید یا نه؛ این امتیازها فقط عباراتی مثل “Highly recommended” یا “Not quite recommended” هستند که میزان توصیهشدن درس در آن نیمسال را نشان میدهند. برای تصمیمگیری، لازم است این دادهها را تحلیل کنید.
برای استخراج اطلاعات مفید از این امتیازها، معمولاً همه دادهها را در نظر میگیرید: زمان ارائه درس، مدرس و اندازه کلاس . بررسی این رکوردها به شما کمک میکند تا تصمیم بگیرید که ترم بعد این درس را بردارید یا نه.
مسئله
فرض کنید میخواهید تصمیم بگیرید امروز ژاکت بپوشید یا نه. برای این کار، دمای بالاترین درجهها در پنج روز گذشته را بررسی میکنید و مشخص میکنید که در هر روز به ژاکت نیاز داشتید یا نه. در این سناریو، شما از چه دادههایی استفاده میکنید و چه اطلاعاتی میخواهید به دست آورید؟
پاسخ
دادههایی که استفاده میکنید شامل:
دمای هر روز
نیاز به ژاکت (بله/خیر) در هر یک از پنج روز گذشته
این دادهها به خودی خود چیزی درباره پوشیدن ژاکت امروز نمیگویند؛ آنها فقط پنج جفت داده هستند: عدد (دمای روز) و بله/خیر (نیاز به ژاکت)، که هر جفت نشاندهنده یک روز است.
با استفاده از این دادهها، شما اطلاعاتی استخراج میکنید که میتوانید آن را تحلیل کنید و تصمیم بگیرید امروز ژاکت بپوشید یا نه.
انواع دادهها
در بخشهای قبلی دیدیم که چقدر زندگی روزمره ما پر از داده است، خود زندگی روزمره چقدر داده تولید میکند و چقدر اغلب بدون اینکه متوجه شویم، تصمیماتمان مبتنی بر داده هستند. همچنین متوجه شدیم که دادهها انواع مختلفی دارند.
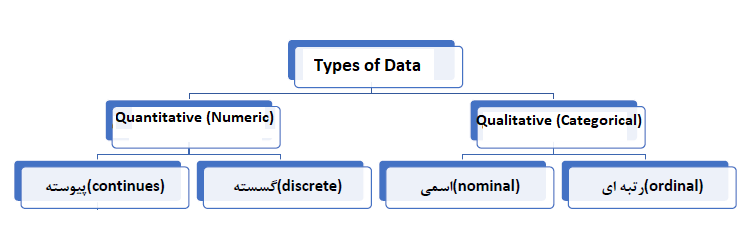
دادههای کمی (Quantitative Data) : این نوع دادهها با اعداد بیان میشوند و مقادیر و کمیتها را نشان میدهند. معمولاً با روشهای آماری تحلیل میشوند. مثال : قد، وزن، دما، ضربان قلب، ارقام فروش و غیره.
دادههای کیفی (Qualitative Data) : این دادهها عددی نیستند و معمولاً ویژگیها یا صفات ذهنی را توصیف میکنند. برای تحلیل آنها از روشهایی مانند تحلیل موضوعی (Thematic Analysis) یا تحلیل محتوا (Content Analysis) استفاده میشود. مثالها: توضیحات، مشاهدات، مصاحبهها، پاسخهای باز به نظرسنجیها، عکسها، پستهای ردیت ، ایسنتاگرام و غیره.
نوع دادهها معمولاً روش تحلیل داده را تعیین میکند، بنابراین تشخیص نوع داده مهم است.
برای مثال، دوباره به مثال تصمیمگیری درباره گرفتن یک درس ترم بعد نگاه کنیم. در این مثال، ما چهار نوع داده داشتیم که به شکلهای مختلف نمایش داده شدهاند: عدد، کلمه و نماد (symbol):
نیمسال ارائه درس : Fall 2020، Spring 2021، …، Fall 2022، Spring 2023
مدرس: A و B
اندازه کلاس: 100 ، 50، 120، 40، 110، 50
امتیاز دوره: «Not recommended at all» تا «Highly recommended»
دو نوع اصلی داده کمی (Quantitative Data) وجود دارد: عددی (Numeric) و دستهای (Categorical) که هرکدام خود به چند زیرنوع تقسیم میشوند.
دادههای عددی بهصورت اعداد نمایش داده میشوند و بیانگر مقادیر قابل اندازهگیری هستند. این اعداد ممکن است همراه با نمادهایی برای مشخص کردن واحد اندازهگیری باشند. دادههای عددی به دو دسته پیوسته (continuous) و گسسته (discrete) تقسیم میشوند.
در دادههای پیوسته، مقادیر میتوانند هر عددی باشند؛ بهعبارت دیگر، مقدار از یک مجموعه نامتناهی از اعداد انتخاب میشود. اما در دادههای گسسته، مقادیر دارای دقت مشخصی هستند و به همین دلیل، مجموعه مقادیر ممکن محدود و متناهی است.
در مثال قبلی، ظرفیت کلاسها مانند ۱۰۰، ۱۵۰ و … اعدادی هستند که واحد ضمنی «دانشجو» را در خود دارند. همچنین این اعداد بیانگر کمیتهای قابل اندازهگیریاند، زیرا نشاندهنده تعداد افراد (سرشماری) هستند. بنابراین، اندازه کلاس یک نوع داده عددی محسوب میشود.
این دادهها در نگاه اول پیوسته به نظر میرسند، زیرا مقادیر ظرفیت کلاس میتوانند هر عدد طبیعی باشند و از یک مجموعه نامتناهی یعنی مجموعه اعداد طبیعی انتخاب شوند.
البته توجه داشته باشید که پیوسته یا گسسته بودن دادهها به بافت و شرایط مسئله نیز بستگی دارد. برای مثال، اگر دانشگاه قانونی وضع کند که همه کلاسها حداکثر ۲۰۰ نفر ظرفیت داشته باشند، در این صورت همین داده اندازه کلاس به یک داده گسسته تبدیل میشود. چنین محدودیتی باعث میشود مقادیر اندازه کلاس تنها از یک مجموعه متناهی شامل ۲۰۰ عدد ممکن انتخاب شوند:
1,2,3 … 197,198,200
دادههای دستهای (Categorical) میتوانند به شکلهای مختلفی مانند واژهها، نمادها و حتی اعداد نمایش داده شوند. یک مقدار دستهای از یک مجموعه متناهی از مقادیر انتخاب میشود و لزوماً بیانگر یک کمیت قابل اندازهگیری نیست.
دادههای دستهای به دو نوع اسمی (Nominal) و ترتیبی (Ordinal) تقسیم میشوند. در دادههای اسمی، مجموعه مقادیر ممکن هیچگونه مفهوم ترتیب یا اولویتی ندارد؛ در حالی که در دادههای ترتیبی، مقادیر دارای یک ترتیب یا سلسلهمراتب مشخص هستند.
سایر موارد یعنی نیمسال تحصیلی (Semester)، مدرس(Instructor) و امتیازدهی (Ratings) جزو دادههای دستهای هستند. این دادهها بهصورت نمادهایی مانند «Fall 2020» یا «A» و یا بهصورت واژههایی مانند «Highly recommended» نمایش داده میشوند و مقادیر آنها از یک مجموعه متناهی از همین نمادها و واژهها انتخاب میشود مثلاً A در مقابل B .
دو مورد اول، یعنی نیمسال و مدرس، دادههای اسمی (Nominal) محسوب میشوند، زیرا ترتیب خاصی میان مقادیر آنها وجود ندارد. اما امتیازدهی یک داده ترتیبی (Ordinal) است، چرا که مفهوم درجه یا شدت در آن وجود دارد از
«Not recommended at all» تا «Highly recommended»
البته میتوان استدلال کرد که نیمسال تحصیلی نیز میتواند دارای ترتیب زمانی باشد؛ برای مثال، Fall 2020 پیش از Spring 2021 قرار میگیرد و Fall 2021 پس از Fall 2020 میآید. اگر این مفهوم ترتیب را در تحلیل خود مهم بدانید، میتوانید داده نیمسال را نیز ترتیبی در نظر بگیرید. این ترتیب زمانی بهویژه زمانی اهمیت دارد که با یک مجموعهداده سری زمانی (Time Series )کار میکنید. در مطالب آینده که در ویرگول منتشر خواهم کرد به مبحث سریهای زمانی و پیشبینی بیشتر آشنا خواهید شد.
مسئله
سناریوی ژاکت را در مثال بالا در نظر بگیرید. در آن مثال به دو نوع داده اشاره شده است:
دمای هوا در سه روز گذشته
اینکه در هر یک از آن روزها به ژاکت نیاز داشتهاید یا نه — بله، خیر و …
سؤال:
نوع هر یک از این دادهها چیست؟
لطفا در نظرات جواب های خود را ارسال کنید.
مجموعه داده ( Datasets)
یک مجموعهداده (Datasets) مجموعهای از مشاهدات یا موجودیتهای دادهای است که برای تحلیل و تفسیر سازماندهی شدهاند، همانطور که در جدول انتخاب درس در بالا نشان دادیم. بسیاری از مجموعهدادهها را میتوان بهصورت یک جدول نمایش داد که در آن هر سطر نشاندهنده یک موجودیت دادهای منحصربهفرد و هر ستون بیانگر ساختار یا ویژگیهای آن موجودیتهاست.
توجه داشته باشید که مجموعهداده استفادهشده در جدول انتخاب درس شامل شش موجودیت (Entity) است که با نامهایی مانند آیتم، رکورد یا نمونه (instance ) نیز شناخته میشوند و این موجودیتها بر اساس نیمسال تحصیلی از یکدیگر متمایز شدهاند. هر موجودیت با ترکیبی از چهار ویژگی (attribute) یا مشخصه (characteristics) که به آنها Feature یا Variable نیز گفته میشود تعریف میشود:
نیمسال (Semester)، مدرس (Instructor)، ظرفیت کلاس (Class Size) و امتیاز (Rating)
در واقع، این ترکیب ویژگیهاست که هر رکورد یا ورودی را در یک مجموعهداده توصیف و متمایز میکند.
با وجود اینکه مقادیر واقعی ویژگیها در موجودیتهای مختلف متفاوت است، توجه داشته باشید که همه موجودیتها برای هر چهار ویژگی یک مقدار دارند. همین موضوع باعث میشود این مجموعهداده یک مجموعهداده ساختیافته (Structured Dataset ) باشد. در یک مجموعهداده ساختیافته، آیتمها را میتوان بهصورت یک جدول فهرست کرد، بهطوریکه هر آیتم در سطرهای جدول قرار میگیرد.
در مقابل، مجموعهداده بدون ساختار (Unstructured Dataset) مجموعهدادهای است که فاقد یک مدل دادهای از پیش تعریفشده یا سازمانیافته باشد. در حالی که مجموعهدادههای ساختیافته در قالب جداول با فیلدها و روابط مشخص سازماندهی میشوند، دادههای بدون ساختار اسکیما یا قالب ثابتی ندارند. این نوع دادهها معمولاً به شکل متن، تصویر، ویدئو، فایلهای صوتی یا سایر محتواهایی هستند که اطلاعات آنها بهراحتی در قالب سطر و ستون قرار نمیگیرد.
مجموعهدادههای بدون ساختار بسیار فراواناند؛ حتی برخی معتقدند تعداد آنها از مجموعهدادههای ساختیافته بیشتر است. بهعنوان مثال میتوان به نظرات کاربران آمازون درباره محصولات، توییتهای منتشرشده در سال گذشته، تصاویر عمومی اینستاگرام، و ویدئوهای کوتاه پرطرفدار در تیکتاک اشاره کرد. این مجموعهدادههای بدون ساختار معمولاً به دادههای ساختیافته تبدیل میشوند تا دانشمندان داده بتوانند آنها را تحلیل کنند. در مطالب اینده ای که در ویرگول منتشر خواهم کرد بیشتر در خصوص جمعآوری و آمادهسازی دادهها با تکنیکهای مختلف پردازش داده آشنا خواهید شد.
مسئله
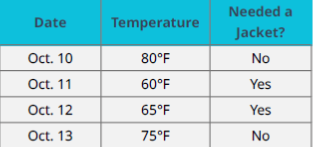
بیایید دوباره به مثال ژاکت برگردیم: تصمیمگیری درباره اینکه آیا برای رفتن به کلاس ژاکت بپوشیم یا نه. فرض کنید مجموعهداده مطابق جدول زیر باشد.
آیا این مجموعهداده ساختیافته است یا بدون ساختار؟
پاسخ
این یک مجموعهداده ساختیافته است، زیرا:
هر آیتم دادهای ساختار یکسانی دارد و شامل سه ویژگی ثابت است: تاریخ (Date)، دما (Temperature) و نیاز به ژاکت (Needed a Jacket)
هر مقدار بهطور دقیق در یک سلول از جدول قرار میگیرد.
مسئله
مجموعهداده مثال قبلی چند رکورد (Entry) و چند ویژگی (Attribute) دارد؟
پاسخ
این مجموعهداده شامل چهار رکورد است که هرکدام با یک تاریخ مشخص شناسایی میشوند.
همچنین این مجموعهداده دارای سه ویژگی است: تاریخ، دما و نیاز به ژاکت.
مسئله
یک مجموعهداده شامل فهرستی از کلیدواژههایی است که در هفته گذشته در یک موتور جستوجوی وب جستوجو شدهاند.
آیا این مجموعهداده ساختیافته است یا بدون ساختار؟
پاسخ
این مجموعهداده بدون ساختار است، زیرا هر ورودی میتواند یک متن آزاد باشد؛ از یک کلمه گرفته تا چند کلمه یا حتی چند جمله.
مسئله
مجموعهداده مثال قبلی پردازش شده و اکنون هر رکورد جستوجو بهصورت حداکثر سه کلمه، بههمراه زمان انجام جستوجو (Timestamp) خلاصه شده است.
آیا این مجموعهداده ساختیافته است یا بدون ساختار؟
پاسخ
این یک مجموعهداده ساختیافته است، زیرا همه ورودیها دارای ساختار یکسانی با دو ویژگی مشخص هستند: کلیدواژه کوتاه و برچسب زمانی (Timestamp)